Bild av författare
Det finns många kurser och resurser tillgängliga om maskininlärning och datavetenskap, men väldigt få om datateknik. Detta väcker några frågor. Är det ett svårt område? Erbjuder det låg lön? Anses det inte vara lika spännande som andra tekniska roller? Men verkligheten är att många företag aktivt söker datatekniktalanger och erbjuder betydande löner, ibland över 200,000 XNUMX USD. Dataingenjörer spelar en avgörande roll som arkitekter för dataplattformar, designar och bygger de grundläggande systemen som gör det möjligt för datavetare och maskininlärningsexperter att fungera effektivt.
För att ta itu med denna branschklyfta har DataTalkClub introducerat en transformativ och gratis bootcamp, "Data Engineering Zoomcamp". Den här kursen är utformad för att ge nybörjare eller proffs som vill byta karriär, med nödvändiga färdigheter och praktisk erfarenhet inom datateknik.
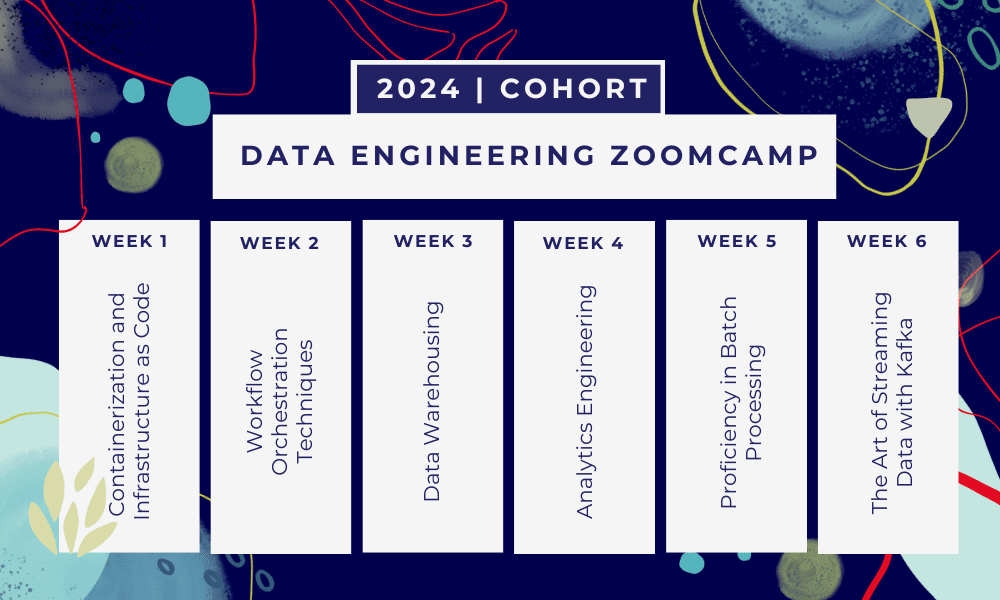
Detta är en 6 veckors bootcamp där du kommer att lära dig genom flera kurser, läsmaterial, workshops och projekt. I slutet av varje modul kommer du att få hemläxor för att öva på det du har lärt dig.
- Vecka 1: Introduktion till GCP, Docker, Postgres, Terraform och miljöinställningar.
- Vecka 2: Arbetsflödesorkestrering med Mage.
- Vecka 3: Datalager med BigQuery och maskininlärning med BigQuery.
- Vecka 4: Analytisk ingenjör med dbt, Google Data Studio och Metabase.
- Vecka 5: Batchbearbetning med Spark.
- Vecka 6: Streamar med Kafka.
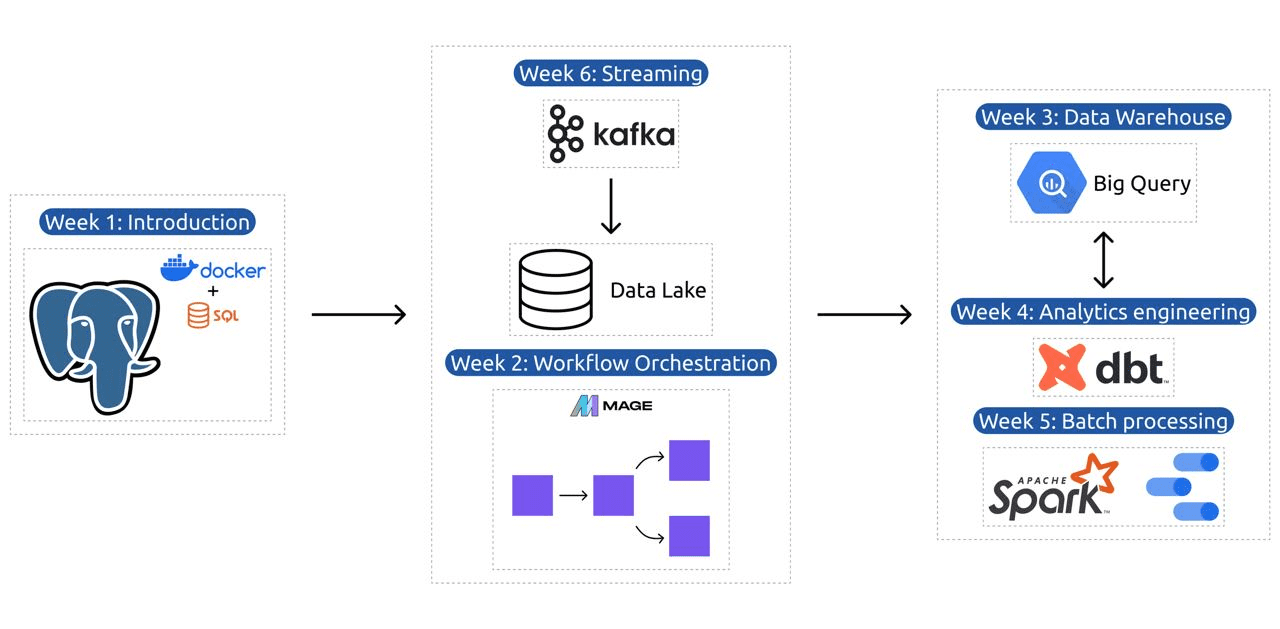
Bild från DataTalksClub/data-engineering-zoomcamp
Kursplanen innehåller 6 moduler, 2 workshops och ett projekt som täcker allt som behövs för att bli en professionell dataingenjör.
Modul 1: Bemästra containerisering och infrastruktur som kod
I den här modulen kommer du att lära dig om Docker och Postgres, börja med grunderna och gå vidare genom detaljerade tutorials om att skapa datapipelines, köra Postgres med Docker och mer.
Modulen täcker också viktiga verktyg som pgAdmin, Docker-compose och SQL-uppdateringsämnen, med valfritt innehåll om Docker-nätverk och en speciell genomgång för Windows-undersystem Linux-användare. I slutändan introducerar kursen dig till GCP och Terraform, vilket ger en holistisk förståelse av containerisering och infrastruktur som en kod, väsentlig för moderna molnbaserade miljöer.
Modul 2: Arbetsflödesorkestreringstekniker
Modulen erbjuder en djupgående utforskning av Mage, ett innovativt hybridramverk med öppen källkod för datatransformation och integration. Den här modulen börjar med grunderna för orkestrering av arbetsflöden och går vidare till praktiska övningar med Mage, inklusive att konfigurera den via Docker och bygga ETL-pipelines från API till Postgres och Google Cloud Storage (GCS) och sedan till BigQuery.
Modulens blandning av videor, resurser och praktiska uppgifter säkerställer en omfattande inlärningsupplevelse, vilket ger eleverna färdigheter att hantera sofistikerade dataarbetsflöden med Mage.
Workshop 1: Dataintagsstrategier
I den första workshopen kommer du att bemästra att bygga effektiva pipelines för dataintag. Workshopen fokuserar på viktiga färdigheter som att extrahera data från API:er och filer, normalisera och ladda data och inkrementella laddningstekniker. Efter att ha genomfört denna workshop kommer du att kunna skapa effektiva datapipelines som en senior dataingenjör.
Modul 3: Datalager
Modulen är en djupgående utforskning av datalagring och analys, med fokus på Data Warehousing med hjälp av BigQuery. Den täcker nyckelbegrepp som partitionering och klustring, och dyker in i BigQuerys bästa praxis. Modulen går vidare till avancerade ämnen, särskilt integrationen av Machine Learning (ML) med BigQuery, belyser användningen av SQL för ML och tillhandahåller resurser för hyperparameterjustering, funktionsförbearbetning och modelldistribution.
Modul 4: Analysteknik
Analysteknikmodulen fokuserar på att bygga ett projekt med hjälp av dbt (Data Build Tool) med ett befintligt datalager, antingen BigQuery eller PostgreSQL.
Modulen täcker inställning av dbt i både moln och lokala miljöer, introduktion av analyskoncept, ETL vs ELT, och datamodellering. Den täcker även avancerade dbt-funktioner som inkrementella modeller, taggar, krokar och ögonblicksbilder.
I slutändan introducerar modulen tekniker för att visualisera transformerad data med hjälp av verktyg som Google Data Studio och Metabase, och den tillhandahåller resurser för felsökning och effektiv dataladdning.
Modul 5: Färdighet i batchbearbetning
Den här modulen täcker batchbearbetning med Apache Spark, och börjar med introduktioner till batchbearbetning och Spark, tillsammans med installationsinstruktioner för Windows, Linux och MacOS.
Det inkluderar att utforska Spark SQL och DataFrames, förbereda data, utföra SQL-operationer och förstå Sparks interna funktioner. Slutligen avslutas det med att köra Spark i molnet och integrera Spark med BigQuery.
Modul 6: Konsten att strömma data med Kafka
Modulen börjar med en introduktion till koncept för strömbehandling, följt av en djupgående utforskning av Kafka, inklusive dess grunder, integration med Confluent Cloud och praktiska tillämpningar som involverar producenter och konsumenter.
Modulen täcker också Kafka-konfiguration och strömmar, och tar upp ämnen som strömanslutningar, testning, fönster och användningen av Kafka ksqldb & Connect. Dessutom utökar den sitt fokus till Python- och JVM-miljöer, med Faust för Python-strömbehandling, Pyspark – Structured Streaming och Scala-exempel för Kafka Streams.
Workshop 2: Streama bearbetning med SQL
Du kommer att lära dig att bearbeta och hantera strömmande data med RisingWave, som ger en kostnadseffektiv lösning med en PostgreSQL-liknande upplevelse för att stärka dina strömbehandlingsapplikationer.
Projekt: Real-World Data Engineering Application
Målet med detta projekt är att implementera alla koncept vi har lärt oss i den här kursen för att konstruera en datapipeline från slut till ände. Du kommer att skapa för att skapa en instrumentpanel som består av två brickor genom att välja en datauppsättning, bygga en pipeline för att bearbeta data och lagra den i en datasjö, bygga en pipeline för att överföra bearbetade data från datasjön till ett datalager, transformera data i datalagret och förbereda det för instrumentpanelen, och slutligen bygga en instrumentpanel för att presentera data visuellt.
2024 Kohort Detaljer
- Registrering: Gå med nu
- Startdatum: 15 januari 2024, klockan 17:00 CET
- Lärande i egen takt med guidat stöd
- Kohortmapp med läxor och deadlines
- Interactive Slack Community för kamratlärande
Förutsättningar
- Grundläggande kunskaper om kodning och kommandorad
- Foundation i SQL
- Python: fördelaktigt men inte obligatoriskt
Expertinstruktörer som leder din resa
- Ankush Khanna
- Victoria Perez Mola
- Alexey Grigorev
- Matt Palmer
- Luis Oliveira
- Michael skomakare
Gå med i vår 2024 års kohort och börja lära dig med en fantastisk datateknikgemenskap. Med expertledd utbildning, praktisk erfarenhet och en läroplan som är skräddarsydd för branschens behov, utrustar denna bootcamp dig inte bara med nödvändiga färdigheter utan placerar dig också i framkant av en lukrativ och efterfrågad karriärväg. Anmäl dig idag och förvandla dina ambitioner till verklighet!
Abid Ali Awan (@1abidaliawan) är en certifierad datavetare som älskar att bygga modeller för maskininlärning. För närvarande fokuserar han på att skapa innehåll och skriva tekniska bloggar om maskininlärning och datavetenskap. Abid har en magisterexamen i Technology Management och en kandidatexamen i telekommunikationsteknik. Hans vision är att bygga en AI-produkt med hjälp av ett grafiskt neuralt nätverk för studenter som kämpar med psykisk ohälsa.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer?utm_source=rss&utm_medium=rss&utm_campaign=the-only-free-course-you-need-to-become-a-professional-data-engineer
- : har
- :är
- :inte
- :var
- $UPP
- 000
- 1
- 15%
- 17
- 2024
- a
- Able
- Om oss
- aktivt
- Dessutom
- adresse
- avancerat
- Vidare
- Efter
- AI
- Alla
- längs
- också
- fantastiska
- an
- analys
- Analytisk
- analytics
- och
- och infrastruktur
- Apache
- Apache Spark
- api
- API: er
- tillämpningar
- arkitekter
- ÄR
- Konst
- AS
- At
- tillgänglig
- Grunderna
- BE
- blir
- passande
- Nybörjare
- fördelaktigt
- BÄST
- bästa praxis
- BigQuery
- Blandning
- bloggar
- båda
- SLUTRESULTAT
- Byggnad
- men
- by
- Karriär
- karriärer
- Certifierad
- cloud
- Cloud Storage
- klustring
- koda
- Kodning
- Kohort
- samfundet
- Företag
- fullborda
- omfattande
- Begreppen
- avslutar
- konfiguration
- Konfluenta
- Kontakta
- anses
- Bestående
- konstruera
- konsumenter
- innehåller
- innehåll
- innehållsskapande
- Naturligtvis
- kurser
- omfattar
- skapa
- Skapa
- skapande
- avgörande
- För närvarande
- Curriculum
- instrumentbräda
- datum
- dataingenjör
- datasjö
- datavetenskap
- datavetare
- datalagring
- datalagret
- Datum
- Examen
- utplacering
- utformade
- design
- detaljerad
- svårt
- Hamnarbetare
- varje
- effektivt
- effektiv
- antingen
- ge
- möjliggöra
- änden
- början till slut
- ingenjör
- Teknik
- Ingenjörer
- registrera
- säkerställer
- Miljö
- miljöer
- väsentlig
- Eter (ETH)
- allt
- exempel
- spännande
- befintliga
- erfarenhet
- experter
- utforskning
- Utforska
- sträcker
- Leverans
- Funktioner
- Med
- få
- fält
- Filer
- Slutligen
- Förnamn
- Fokus
- fokuserar
- fokusering
- följt
- För
- förgrunden
- foundational
- Ramverk
- Fri
- från
- fungera
- Fundamentals
- spalt
- GCP
- ges
- Google Cloud
- diagram
- Graph Neural Network
- guidad
- praktisk
- Har
- he
- belysa
- hans
- innehar
- helhetssyn
- läxor
- krokar
- Men
- HTTPS
- Hybrid
- Inställning av hyperparameter
- sjukdom
- genomföra
- in
- djupgående
- innefattar
- Inklusive
- steg
- industrin
- Infrastruktur
- innovativa
- Installationen
- instruktioner
- Integrera
- integrering
- in
- introducerade
- Introducerar
- införa
- Beskrivning
- introduktioner
- involverar
- IT
- DESS
- Januari
- Fogar
- kafka
- KDnuggets
- Nyckel
- sjö
- ledande
- LÄRA SIG
- lärt
- studerande
- inlärning
- tycka om
- linje
- linux
- läser in
- lokal
- du letar
- älskar
- Låg
- lukrativ
- Maskinen
- maskininlärning
- Mac OS
- hantera
- ledning
- obligatoriskt
- många
- Master
- Mastering
- material
- mentala
- Mental sjukdom
- ML
- modell
- modellering
- modeller
- Modern Konst
- modul
- Moduler
- mer
- multipel
- nödvändigt för
- Behöver
- behövs
- behov
- nät
- nätverk
- neural
- neurala nätverk
- mål
- of
- erbjuda
- Erbjudanden
- on
- endast
- öppen källkod
- Verksamhet
- or
- orkestrering
- Övriga
- vår
- Palmer
- särskilt
- bana
- Betala
- jämlikar
- utför
- rörledning
- Plattformar
- plato
- Platon Data Intelligence
- PlatonData
- Spela
- positioner
- PostgreSQL
- Praktisk
- Praktiska tillämpningar
- praktiken
- praxis
- förbereda
- presentera
- process
- bearbetade
- bearbetning
- producenter
- Produkt
- professionell
- yrkesmän/kvinnor
- skrider
- projektet
- projekt
- ger
- tillhandahålla
- Python
- frågor
- höjer
- Läsning
- verkliga världen
- Verkligheten
- Resurser
- Roll
- roller
- rinnande
- s
- löner
- Skala
- Vetenskap
- Forskare
- vetenskapsmän
- söker
- väljer
- senior
- inställning
- inställning
- färdigheter
- slak
- lösning
- några
- ibland
- sofistikerade
- Gnista
- speciell
- SQL
- starta
- Starta
- förvaring
- ström
- streaming
- strömmar
- strukturerade
- Kämpar
- Studenter
- studio
- väsentlig
- sådana
- stödja
- Växla
- System
- skräddarsydd
- Talang
- uppgifter
- tech
- Teknisk
- tekniker
- Tekniken
- Teknologi
- telekommunikation
- Terraform
- Testning
- den där
- Smakämnen
- Grunderna
- sedan
- detta
- Genom
- till
- i dag
- verktyg
- verktyg
- ämnen
- Utbildning
- Överföra
- Förvandla
- Transformation
- transformativ
- transformerad
- omvandla
- självstudiekurser
- två
- förståelse
- USD
- användning
- användare
- med hjälp av
- Ve
- mycket
- via
- Video
- syn
- visuellt
- vs
- Warehouse
- Lagring
- we
- Vad
- som
- VEM
- kommer
- fönster
- med
- arbetsflöde
- arbetsflöden
- verkstad
- Workshops
- skrivning
- dig
- Din
- zephyrnet










