Under 2010-decenniet började fördelarna med Moores lag falla isär. Moores lag angav att transistortätheten fördubblades vartannat år, kostnaden för beräkning skulle krympa med motsvarande 50%. Förändringen i Moores lag beror på ökad designkomplexitet utvecklingen av transistorstrukturen från plana enheter till Finfets. Finfets behöver flera mönster för litografi för att uppnå enhetsdimensioner till noder under 20 nm.
I början av detta decennium har datorbehoven exploderat, mest på grund av spridningen av datacenter och på grund av mängden data som genereras och bearbetas. Faktum är att antagandet av artificiell intelligens (AI) och tekniker som Machine Learning (ML) nu används för att bearbeta ständigt ökande data och har lett till att servrar avsevärt har ökat sin beräkningskapacitet.
Servrar har lagt till många fler CPU-kärnor, har integrerat större GPU:er som används exklusivt för ML, används inte längre för grafik och har inbäddade anpassade ASIC AI-acceleratorer eller kompletterande, FPGA-baserad AI-behandling. Tidiga AI-chipdesigner implementerades med hjälp av större monolitiska SoCs, några av dem nådde storleksgränsen som infördes av hårkorset, cirka 700 mm2.
Vid denna tidpunkt verkar uppdelning till en mindre SoC plus olika dator- och IO-chiplets vara den rätta lösningen. Flera chiptillverkare, som Intel, AMD eller Xilinx, har valt detta alternativ för produkter som går i produktion. I den utmärkta vitboken från The Linley Group, "Chiplets Gain Rapid Adoption: Why Big Chips Are Getting Small", visades det att detta alternativ leder till bättre kostnader jämfört med monolitiska SoCs, på grund av avkastningseffekten av större.
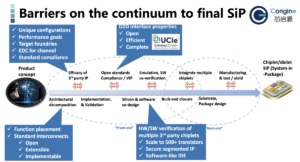
Den stora effekten av denna trend på IP-leverantörer är mestadels på de sammankopplingsfunktioner som används för att länka SoC:er och chiplets. Vid denna tidpunkt (Q3 2021) finns det flera protokoll som används, där industrin försöker bygga formaliserade standarder för många av dem.
Nuvarande ledande D2D-standarder inkluderar i) Advanced Interface Bus (AIB, AIB2) som ursprungligen definierades av Intel, och har nu erbjudit royaltyfri användning, ii) High Bandwidth Memory (HBM) där DRAM-matriser staplas på varandra ovanpå en kiselmellanläggare och är anslutna med hjälp av TSV, iii) Open Domain-Specific Architecture (ODSA) undergrupp, en industrigrupp, har definierat två andra gränssnitt, Bunch of Wires (BoW) och OpenHBI.
Heterogen chipletdesign gör att vi kan rikta in oss på olika applikationer eller marknadssegment genom att modifiera eller lägga till bara relevanta chiplets samtidigt som resten av systemet hålls oförändrat. Nya utvecklingar skulle kunna lanseras snabbare på marknaden, med betydligt lägre investeringar, eftersom omdesign endast kommer att påverka paketets substrat som används för att hysa chipletarna.
Till exempel kan beräkningschiplet designas om från TSMC 5nm till TSMC 3nm för att integrera större L1-cache eller högre presterande CPU-kärnor, samtidigt som resten av systemet hålls oförändrat. I den motsatta änden av spektrumet kan bara den chiplet som integrerar SerDes omdesignas för snabbare hastigheter på nya processnoder som erbjuder mer IO-bandbredd för bättre marknadspositionering.
Intel PVC är ett perfekt exempel på heterogen integration (olika funktionella chiplets, CPU, switchar, etc.) som vi skulle kunna kalla vertikal integration, när samma chiptillverkare äger de olika chipletkomponenterna (förutom minnesenheter).
Chiptillverkare som utvecklar SoC:er för avancerade applikationer, såsom HPC, datacenter, AI eller nätverk, kommer sannolikt att vara tidiga användare för chiplet-arkitekturer. Specifika funktioner, som SRAM-minnen för större L3-cache eller AI-acceleratorer, antingen Ethernet-, PCIe- eller CXL-standarder bör vara den första gränssnittskandidaten för chipletdesigner.
När dessa tidiga användare har visat giltigheten hos heterogena chiplets som utnyttjar flera olika affärsmodeller, och uppenbarligen tillverkningsmöjligheten för test och förpackning, kommer det att skapa ett ekosystem som är avgörande för att stödja denna nya teknik. Vid det här laget kan vi förvänta oss ett bredare marknadsantagande, inte bara för högpresterande applikationer.
Vi skulle kunna tänka oss att heterogena produkter kan gå längre, om en chiptillverkare kommer att lansera ett system tillverkat av olika chiplets som är inriktat på dator- och IO-funktionalitet. Detta tillvägagångssätt gör konvergens på ett D2D-protokoll obligatoriskt, eftersom en IP-leverantör som erbjuder chiplets med ett internt D2D-protokoll inte är attraktivt för branschen.
En analogi till detta är SoC-byggnaden på 2000-talet, där halvledarföretag övergår till att integrera olika design-IP:er som kommer från olika källor. 2000-talets IP-leverantörer kommer oundvikligen att bli 2020-talets chiplet-leverantörer. För vissa funktioner, såsom avancerade SerDes eller komplexa protokoll, som PCIe, Ethernet eller CXL, har IP-leverantörer det bästa kunnandet för att implementera det på kisel.
För komplex design-IP, även om simuleringsverifiering har körts innan leverans till kunder, måste leverantörer validera IP:n på kisel för att garantera prestanda. För digital IP kan funktionen implementeras i FPGA eftersom det är snabbare och mycket billigare än att göra ett testchip. För blandar-signal IP, som en SerDes-baserad PHY, väljer leverantörer alternativet Test Chip (TC) som tillåter kisel så att de kan karakterisera IP:n i kisel innan de skickas till kunden.
Även om en chiplet inte bara är en TC, eftersom den kommer att testas och kvalificeras i stor utsträckning innan den används på fältet, är mängden inkrementellt arbete som måste utföras av leverantören för att utveckla en produktionschiplet mycket mindre. Med andra ord är IP-leverantören bäst positionerad för att snabbt släppa en chiplet byggd från sin egen IP och erbjuda bästa möjliga TTM och minimera risken.
Affärsmodellen för heterogen integration är positiv till att olika chiplets tillverkas av den relevanta IP-leverantören (t.ex. ARM för ARM-baserade CPU-chiplets, Si-Five för Risc-V-baserade datorchiplets och Alphawave för höghastighets-SerDes-chiplets) sedan de är ägare till Design IP.
Inget av detta hindrar chiptillverkare att designa sina egna chiplets och källkoda komplexa design-IP:er för att skydda sina unika arkitekturer eller implementera egentillverkade sammankopplingar. I likhet med SoC Design IP på 2000-talet, kommer beslutet att köpa eller ta för chiplets att vägas mellan kärnkompetensskydd och inköp av icke-differentierande funktioner.
Vi har sett att den historiska och moderna design-IP-verksamhetens tillväxt sedan 2000-talet har upprätthållits av kontinuerlig användning av externa inköp. Båda modellerna kommer att samexistera (chiplet designad internt eller av en IP-leverantör) men historien har visat att köpbeslutet så småningom tar över.
Det råder nu konsensus i branschen om att ett maniskt fokus på att uppnå Moores lag inte längre är giltigt för avancerade teknologinoder, t.ex. 7nm och lägre. Chipintegration pågår fortfarande, med fler transistorer som läggs till per mmXNUMX vid varje ny teknologinod. Men kostnaden per transistor växer också högre för varje ny nod.
Chipletteknologi är ett nyckelinitiativ för att driva ökad integration för den huvudsakliga SoC-enheten samtidigt som äldre noder används för annan funktionalitet. Denna hybridstrategi minskar både kostnaden och designrisken förknippad med integrering av annan design-IP direkt på huvud-SoC.
IPnest tror att denna trend kommer att ha två huvudsakliga effekter i gränssnitts-IP-verksamheten, den ena kommer att vara den starka tillväxten av D2D IP-intäkter snart (2021-2025), och den andra är skapandet av den heterogena chipletmarknaden för att förstärka high-end kisel IP-marknaden.
Denna marknad förväntas bestå av komplexa protokollfunktioner som PCIe, CXL eller Ethernet. IP-leverantörer som levererar gränssnitts-IP integrerad i I/O SoCs (USB, HDMI, DP, MIPI, etc.) kan välja att leverera I/O-chiplets istället.
De andra IP-kategorierna som påverkas av denna revolution kommer att vara SRAM-minneskompilator-IP-leverantörer för L3-cache. Av naturen förväntas cachestorleken variera beroende på processorn. Ändå kan design av L3-cachechiplet vara ett sätt för IP-leverantörer att öka Design IP-intäkter genom att erbjuda en ny produkttyp.
Dessutom kan NVM IP-kategorin påverkas positivt, eftersom NVM IP inte längre är integrerade i SoCs designade på avancerade processnoder. Det skulle vara ett sätt för NVM IP-leverantörer att skapa nya affärer genom att erbjuda chiplets.
Vi tror att FPGA- och AI-acceleratorchiplets kommer att bli en ny inkomstkälla för ASSP-chiptillverkare, men vi tror inte att de strikt kan rankas som IP-leverantörer.
Om Interface IP-leverantörer kommer att vara stora aktörer i denna kiselrevolution kommer kiselgjuterier som adresserar de mest avancerade noderna som TSMC och Samsung också att spela en nyckelroll. Vi tror inte att gjuterier kommer att designa chiplets, men de kan fatta beslutet att stödja IP-leverantörer och driva dem att designa chiplets för att användas med SoCs i 3nm, som de gör idag när de stödjer avancerade IP-leverantörer för att marknadsföra sina avancerade SerDes. lika hård IP i 7nm och 5nm.
Intels senaste övergång till 3rd partigjuterier förväntas också utnyttja tredje parts IP-adresser, såväl som heterogena chiplet-antaganden av halvledar tungviktare. I det här fallet, ingen tvekan om att Hyperscalars som Microsoft, Amazon och Google också kommer att anta chiplet-arkitekturer ... om de inte föregår Intel i chiplet-antagande.
By Erik Esteve (PhD.) Analytiker, ägare IPnest
Dela det här inlägget via: Källa: https://semiwiki.com/semiconductor-services/ipnest/303790-chiplet-are-you-ready-for-next-semiconductor-revolution/
- 2021
- accelerator
- acceleratorer
- Antagande
- Advanced Technology
- AI
- tillåta
- amason
- AMD
- analytiker
- tillämpningar
- arkitektur
- ARM
- artificiell intelligens
- Konstgjord intelligens (AI)
- ASIC
- BÄST
- SLUTRESULTAT
- Byggnad
- Bunch
- Bussen
- företag
- affärsmodell
- Köp
- Ring
- Kapacitet
- byta
- chip
- Pommes frites
- kommande
- Företag
- Compute
- databehandling
- Konsensus
- Kostar
- Kunder
- datum
- leverera
- Designa
- utveckla
- enheter
- digital
- Tidig
- tidiga adoptörer
- ekosystemet
- etc
- Utvecklingen
- Förnamn
- Fokus
- FPGA
- Fri
- fungera
- GPUs
- Grupp
- Odling
- Tillväxt
- Hög
- historia
- Huset
- HTTPS
- Hybrid
- Inverkan
- Öka
- industrin
- Initiativ
- integrering
- Intel
- Intelligens
- investering
- IP
- IT
- hålla
- Nyckel
- lansera
- Lag
- ledande
- inlärning
- Led
- Hävstång
- LINK
- maskininlärning
- större
- tillverkare
- Framställning
- Produktion
- marknad
- Microsoft
- ML
- modell
- nätverk
- ny produkt
- noder
- erbjudanden
- erbjuda
- öppet
- Alternativet
- Övriga
- ägaren
- förpackning
- Papper
- prestanda
- Produkt
- Produktion
- Produkter
- skydda
- skydd
- rates
- redesign
- REST
- Risk
- Körning
- Samsung
- halvledare
- Frakt & Leverans
- simulering
- Storlek
- standarder
- Strategi
- stödja
- Växla
- system
- Målet
- tekniker
- Teknologi
- testa
- topp
- us
- usb
- försäljare
- Verifiering
- vitt papper
- ord
- Arbete
- år
- Avkastning