Bild av författare
När du kommer igång med maskininlärning är logistisk regression en av de första algoritmerna du lägger till i din verktygslåda. Det är en enkel och robust algoritm som vanligtvis används för binära klassificeringsuppgifter.
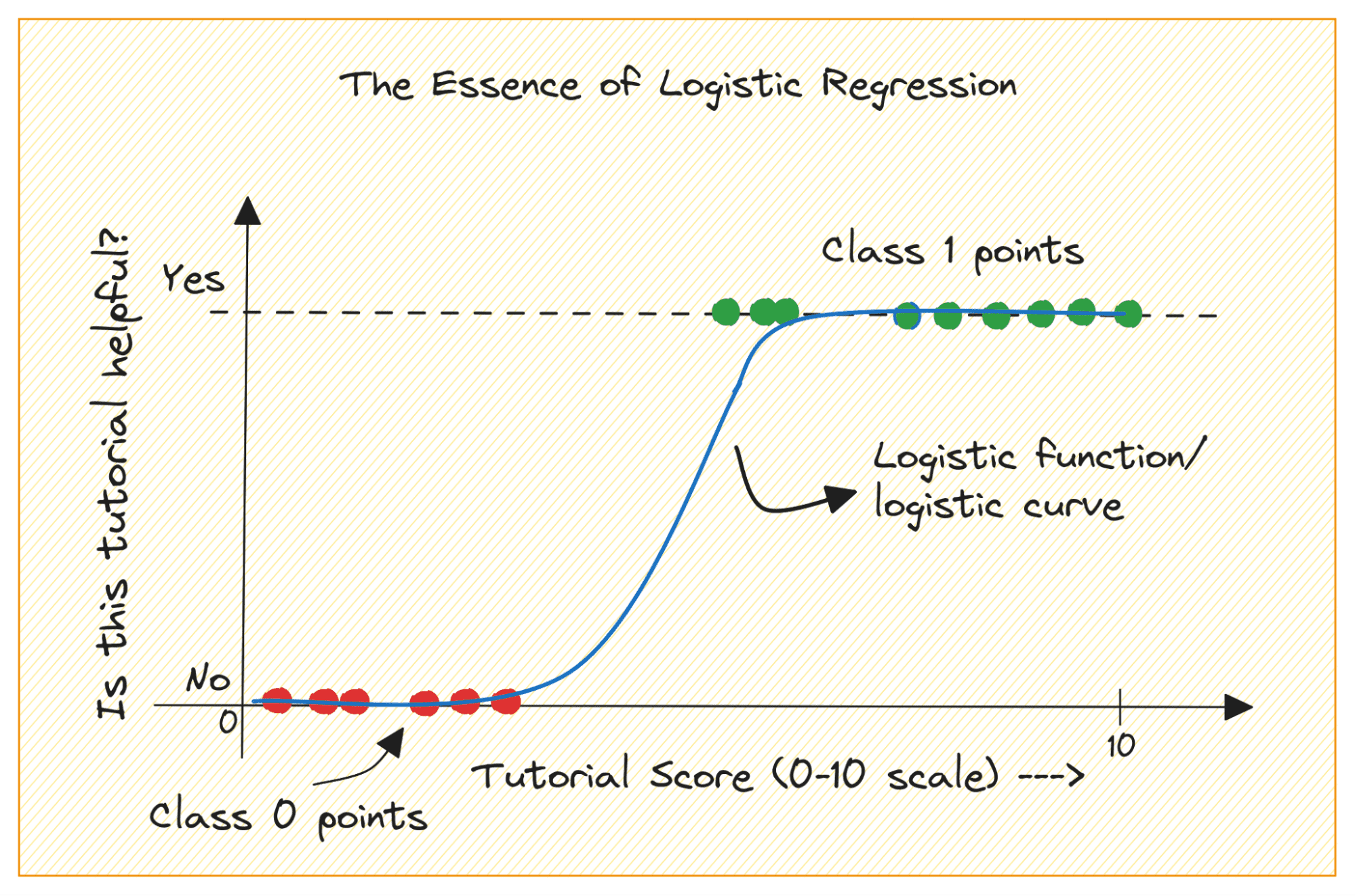
Tänk på ett binärt klassificeringsproblem med klasserna 0 och 1. Logistisk regression anpassar en logistisk eller sigmoidfunktion till indata och förutsäger sannolikheten för en frågedatapunkt som tillhör klass 1. Intressant, ja?
I den här handledningen lär vi oss om logistisk regression från grunden och täcker:
- Den logistiska (eller sigmoid) funktionen
- Hur vi går från linjär till logistisk regression
- Hur logistisk regression fungerar
Slutligen kommer vi att bygga en enkel logistisk regressionsmodell för att klassificera RADAR-retur från jonosfären.
Innan vi lär oss mer om logistisk regression, låt oss se över hur den logistiska funktionen fungerar. Den logistiska (eller sigmoidfunktionen) ges av:

När du plottar sigmoid-funktionen ser det ut så här:
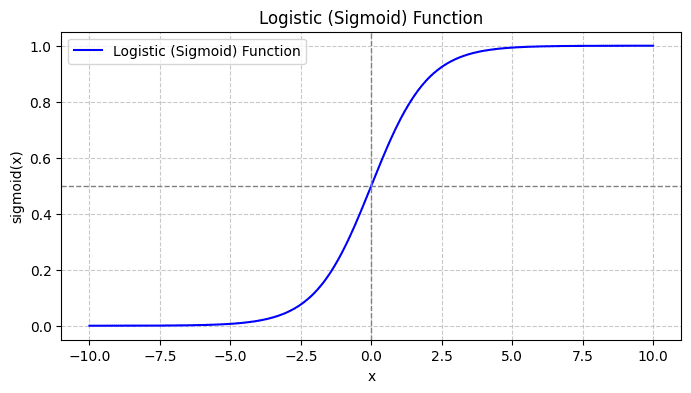
Från handlingen ser vi att:
- När x = 0 får σ(x) värdet 0.5.
- När x närmar sig +∞ närmar sig σ(x) 1.
- När x närmar sig -∞ närmar sig σ(x) 0.
Så för alla verkliga ingångar pressar sigmoid-funktionen dem för att anta värden i området [0, 1].
Låt oss först diskutera varför vi inte kan använda linjär regression för ett binärt klassificeringsproblem.
I ett binärt klassificeringsproblem är utgången kategorisk etikett (0 eller 1). Eftersom linjär regression förutsäger kontinuerligt värderade utdata som kan vara mindre än 0 eller större än 1, är det inte vettigt för det aktuella problemet.
Dessutom kanske en rak linje inte passar bäst när utdataetiketterna tillhör någon av de två kategorierna.
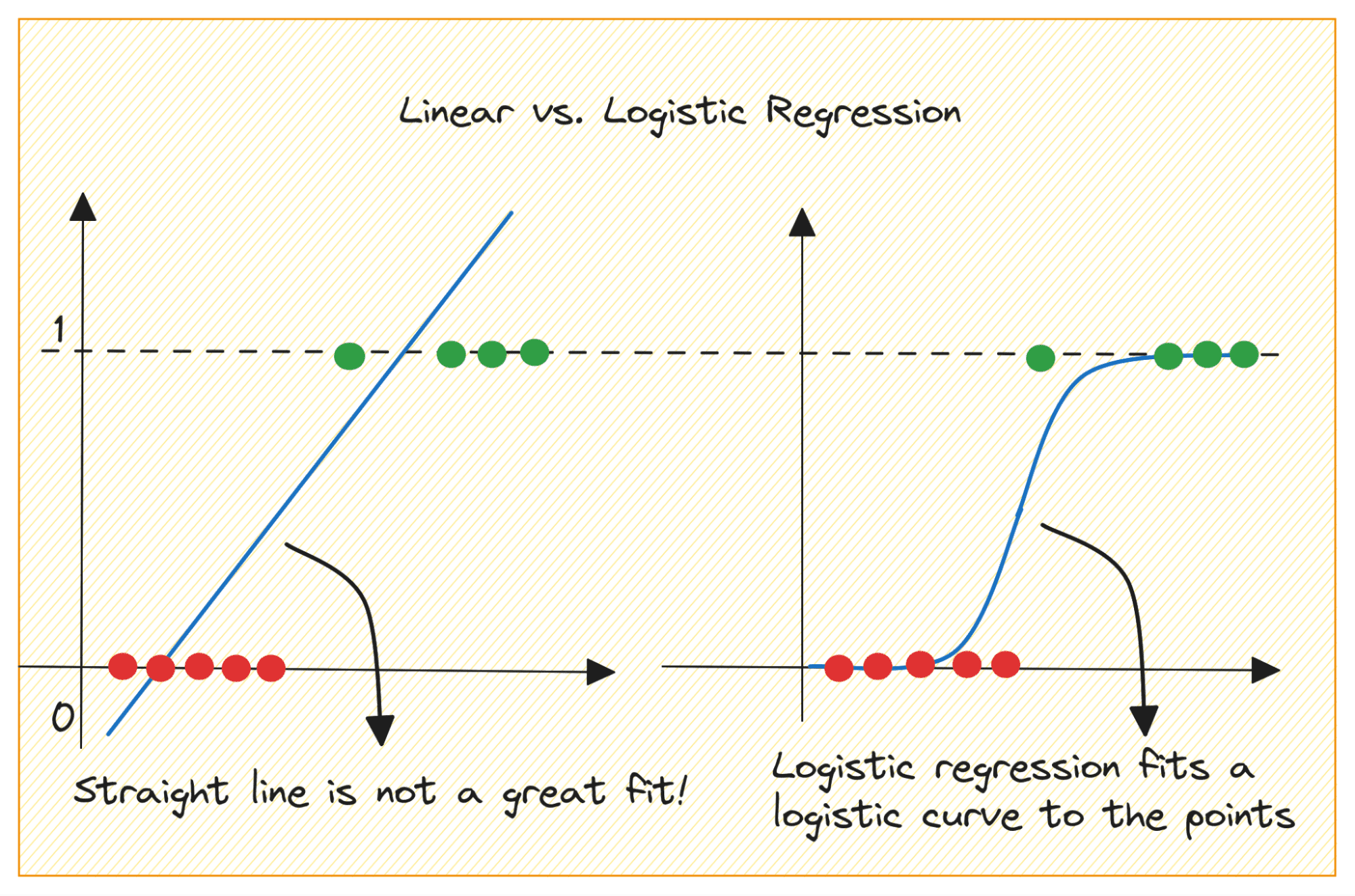
Bild av författare
Så hur går vi från linjär till logistisk regression? I linjär regression ges den förutsagda uteffekten av:
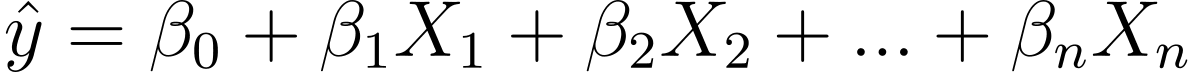
Där βs är koefficienterna och X_is är prediktorerna (eller egenskaperna).
Utan förlust av allmänhet, låt oss anta X_0 = 1:

Så vi kan ha ett mer kortfattat uttryck:
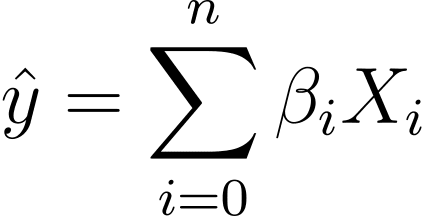
I logistisk regression behöver vi den förutsagda sannolikheten p_i i intervallet [0,1]. Vi vet att logistikfunktionen klämmer in ingångar så att de antar värden i intervallet [0,1].
Så om vi kopplar in det här uttrycket i logistikfunktionen har vi den förutspådda sannolikheten som:
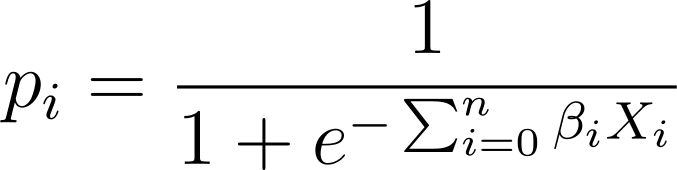
Så hur hittar vi den logistiska kurvan som passar bäst för den givna datamängden? För att svara på detta, låt oss förstå maximal sannolikhetsuppskattning.
Maximum Likelihood Estimation (MLE) används för att uppskatta parametrarna för den logistiska regressionsmodellen genom att maximera sannolikhetsfunktionen. Låt oss bryta ner processen för MLE i logistisk regression och hur kostnadsfunktionen är formulerad för optimering med hjälp av gradient descent.
Uppdelning av maximal sannolikhetsuppskattning
Som diskuterats modellerar vi sannolikheten att ett binärt utfall inträffar som en funktion av en eller flera prediktorvariabler (eller funktioner):
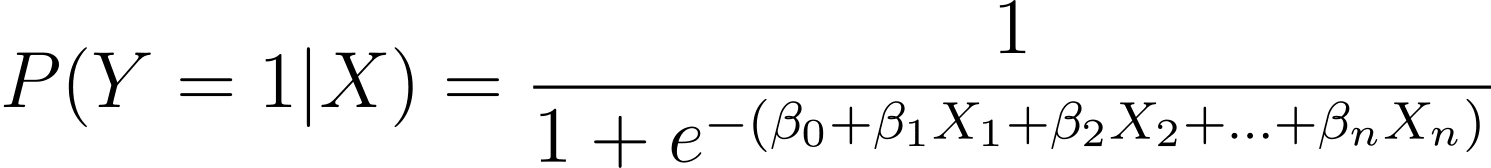
Här är βs modellens parametrar eller koefficienter. X_1, X_2,…, X_n är prediktorvariablerna.
MLE syftar till att hitta värden på β som maximerar sannolikheten för de observerade data. Sannolikhetsfunktionen, betecknad som L(β), representerar sannolikheten att observera de givna resultaten för de givna prediktorvärdena under den logistiska regressionsmodellen.
Formulera Log-Likelihood-funktionen
För att förenkla optimeringsprocessen är det vanligt att arbeta med log-likelihood-funktionen. Eftersom den omvandlar produkter av sannolikheter till summor av log sannolikheter.
Log-likelihood-funktionen för logistisk regression ges av:
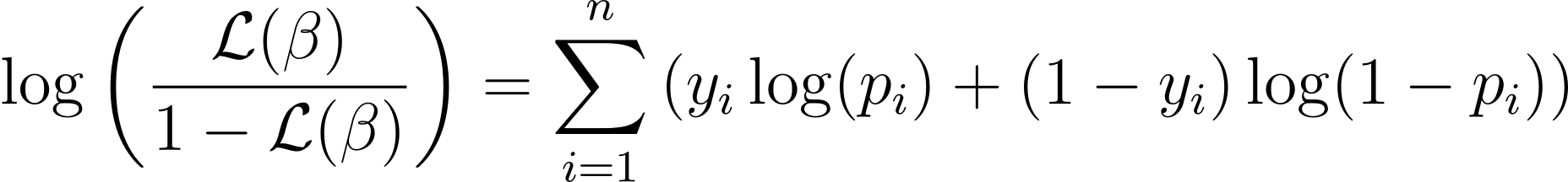
Nu när vi vet essensen av log-sannolikhet, låt oss fortsätta att formulera kostnadsfunktionen för logistisk regression och därefter gradientnedstigning för att hitta de bästa modellparametrarna
Kostnadsfunktion för logistisk regression
För att optimera den logistiska regressionsmodellen måste vi maximera loggsannolikheten. Så vi kan använda den negativa log-sannolikheten som kostnadsfunktionen för att minimera under utbildning. Den negativa log-sannolikheten, ofta kallad logistisk förlust, definieras som:
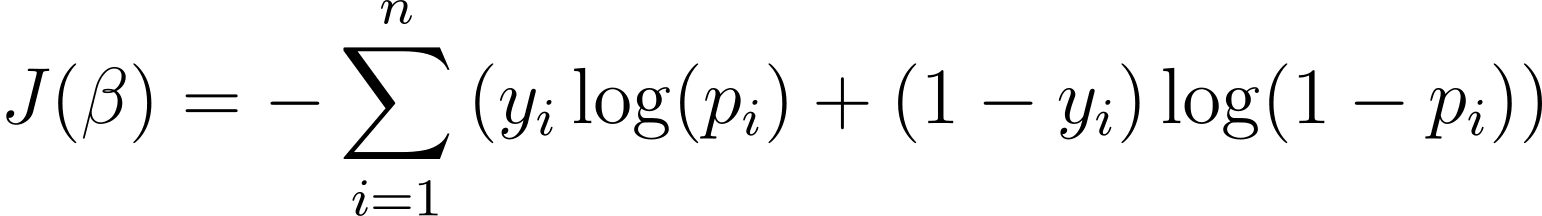
Målet med inlärningsalgoritmen är därför att hitta värdena för ? som minimerar denna kostnadsfunktion. Gradient descent är en vanlig optimeringsalgoritm för att hitta minimum av denna kostnadsfunktion.
Gradient Descent i logistisk regression
Övertoning är en iterativ optimeringsalgoritm som uppdaterar modellparametrarna β i motsatt riktning av gradienten för kostnadsfunktionen med avseende på β. Uppdateringsregeln i steg t+1 för logistisk regression med användning av gradientnedstigning är som följer:
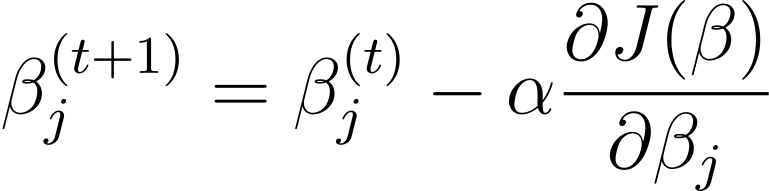
Där α är inlärningshastigheten.
De partiella derivatorna kan beräknas med hjälp av kedjeregeln. Gradient descent uppdaterar parametrarna iterativt – fram till konvergens – i syfte att minimera den logistiska förlusten. När den konvergerar hittar den de optimala värdena för β som maximerar sannolikheten för de observerade data.
Nu när du vet hur logistisk regression fungerar, låt oss bygga en prediktiv modell med hjälp av scikit-learn-biblioteket.
Vi använder jonosfärdatauppsättning från UCIs maskininlärningsförråd för denna handledning. Datauppsättningen består av 34 numeriska funktioner. Utdata är binär, en av "bra" eller "dålig" (betecknad med "g" eller "b"). Utdataetiketten "bra" hänvisar till RADAR-returer som har upptäckt någon struktur i jonosfären.
Steg 1 – Ladda datauppsättningen
Ladda först ner datasetet och läs in det i en pandas dataram:
import pandas as pd
import urllib
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/iphere.data"
data = urllib.request.urlopen(url)
df = pd.read_csv(data, header=None)Steg 2 – Utforska datamängden
Låt oss ta en titt på de första raderna i dataramen:
# Display the first few rows of the DataFrame
df.head()
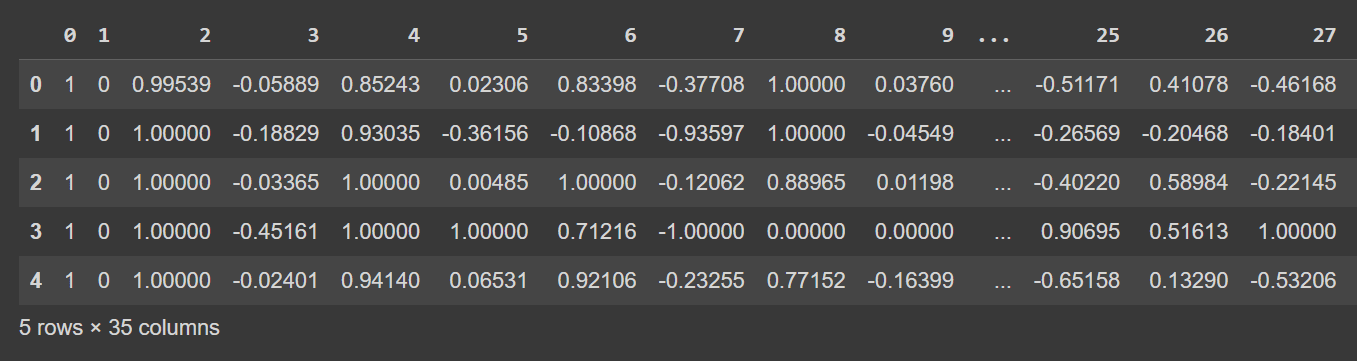
Trunkerad utdata från df.head()
Låt oss få lite information om datamängden: antalet icke-nullvärden och datatyperna för var och en av kolumnerna:
# Get information about the dataset
print(df.info())
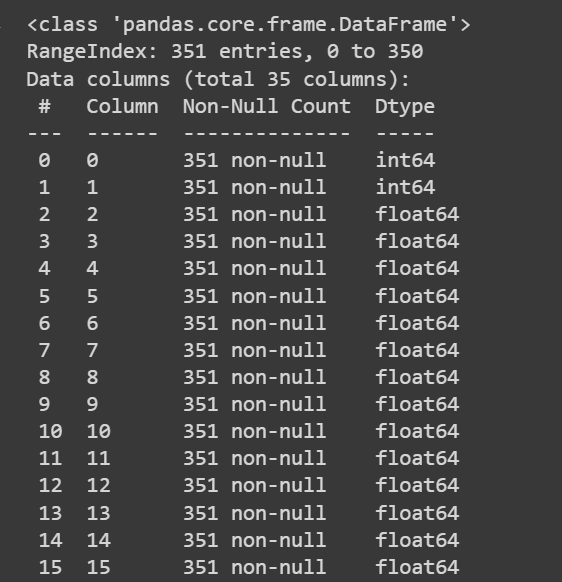 Trunkerad utdata från df.info()
Trunkerad utdata från df.info()
Eftersom vi har alla numeriska funktioner kan vi också få lite beskrivande statistik med hjälp av describe() metod på dataramen:
# Get descriptive statistics of the dataset
print(df.describe())
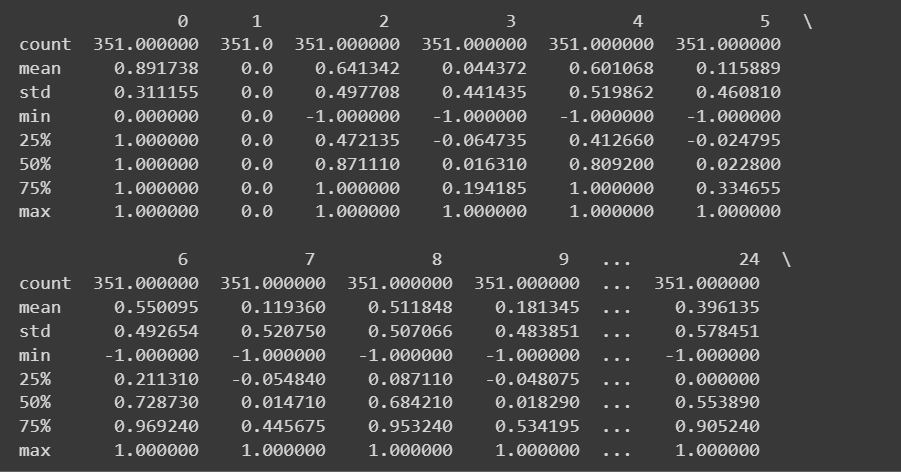
Trunkerad utdata för df.describe()
Kolumnnamnen är för närvarande 0 till 34 – inklusive etiketten. Eftersom datamängden inte tillhandahåller beskrivande namn för kolumnerna, hänvisar den bara till dem som attribut_1 till attribut_34 om du vill kan du byta namn på kolumnerna i dataramen som visas:
column_names = [
"attribute_1", "attribute_2", "attribute_3", "attribute_4", "attribute_5",
"attribute_6", "attribute_7", "attribute_8", "attribute_9", "attribute_10",
"attribute_11", "attribute_12", "attribute_13", "attribute_14", "attribute_15",
"attribute_16", "attribute_17", "attribute_18", "attribute_19", "attribute_20",
"attribute_21", "attribute_22", "attribute_23", "attribute_24", "attribute_25",
"attribute_26", "attribute_27", "attribute_28", "attribute_29", "attribute_30",
"attribute_31", "attribute_32", "attribute_33", "attribute_34", "class_label"
]
df.columns = column_names
Obs: Detta steg är helt valfritt. Du kan fortsätta med standardkolumnnamnen om du föredrar det.
# Display the first few rows of the DataFrame
df.head()
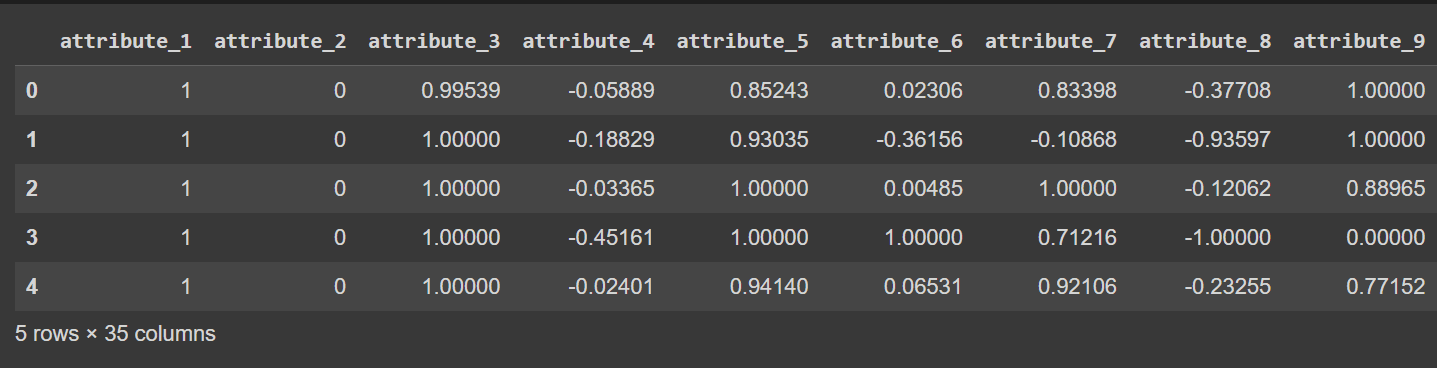
Trunkerad utdata från df.head() [Efter byte av kolumner]
Steg 3 – Byta namn på klassetiketter och visualisera klassdistribution
Eftersom utdataklassetiketterna är 'g' och 'b' måste vi mappa dem till 1 respektive 0 . Du kan göra det med hjälp av map() or replace():
# Convert the class labels from 'g' and 'b' to 1 and 0, respectively
df["class_label"] = df["class_label"].replace({'g': 1, 'b': 0})
Låt oss också visualisera fördelningen av klassetiketterna:
import matplotlib.pyplot as plt
# Count the number of data points in each class
class_counts = df['class_label'].value_counts()
# Create a bar plot to visualize the class distribution
plt.bar(class_counts.index, class_counts.values)
plt.xlabel('Class Label')
plt.ylabel('Count')
plt.xticks(class_counts.index)
plt.title('Class Distribution')
plt.show()
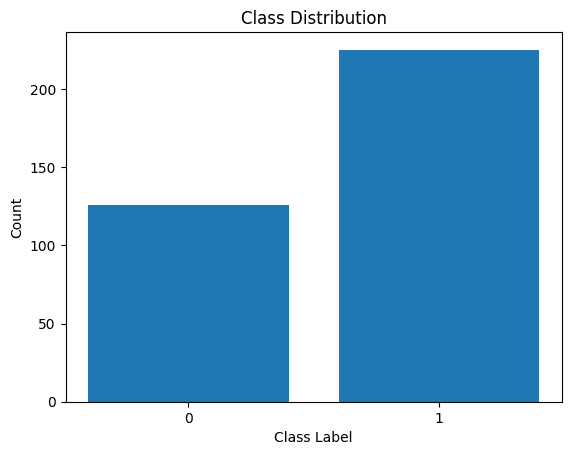
Distribution av klassetiketter
Vi ser att det finns en obalans i fördelningen. Det finns fler poster som tillhör klass 1 än klass 0. Vi kommer att hantera denna klassobalans när vi bygger den logistiska regressionsmodellen.
Steg 5 – Förbearbetning av datamängden
Låt oss samla funktionerna och utdataetiketterna så här:
X = df.drop('class_label', axis=1) # Input features
y = df['class_label'] # Target variable
Efter att ha delat upp datamängden i tåg- och testuppsättningarna måste vi förbehandla datamängden.
När det finns många numeriska funktioner – var och en i en potentiellt olika skala – måste vi förbehandla de numeriska funktionerna. En vanlig metod är att transformera dem så att de följer en fördelning med noll medelvärde och enhetsvarians.
Smakämnen StandardScaler från scikit-learns förbearbetningsmodul hjälper oss att uppnå detta.
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Get the indices of the numerical features
numerical_feature_indices = list(range(34)) # Assuming the numerical features are in columns 0 to 33
# Initialize the StandardScaler
scaler = StandardScaler()
# Normalize the numerical features in the training set
X_train.iloc[:, numerical_feature_indices] = scaler.fit_transform(X_train.iloc[:, numerical_feature_indices])
# Normalize the numerical features in the test set using the trained scaler from the training set
X_test.iloc[:, numerical_feature_indices] = scaler.transform(X_test.iloc[:, numerical_feature_indices])Steg 6 – Bygga en logistisk regressionsmodell
Nu kan vi instansiera en logistisk regressionsklassificerare. De LogisticRegression klass är en del av scikit-learns linear_model-modul.
Lägg märke till att vi har ställt in class_weight parametern till "balanserad". Detta kommer att hjälpa oss att redogöra för klassobalansen. Genom att tilldela vikter till varje klass – omvänt proportionell mot antalet poster i klasserna.
Efter att ha instansierat klassen kan vi anpassa modellen till träningsdataset:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(class_weight='balanced')
model.fit(X_train, y_train)Steg 7 – Utvärdering av den logistiska regressionsmodellen
Du kan ringa predict() metod för att få modellens förutsägelser.
Utöver noggrannhetspoängen kan vi också få en klassificeringsrapport med mätvärden som precision, återkallelse och F1-poäng.
from sklearn.metrics import accuracy_score, classification_report
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
classification_rep = classification_report(y_test, y_pred)
print("Classification Report:n", classification_rep)
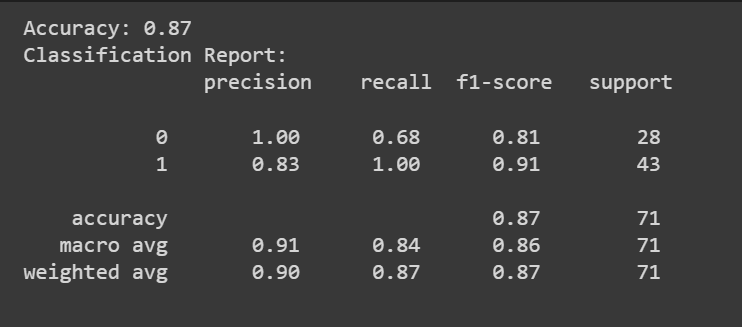
Grattis, du har kodat din första logistiska regressionsmodell!
I den här handledningen lärde vi oss om logistisk regression i detalj: från teori och matematik till att koda en logistisk regressionsklassificerare.
Som nästa steg, försök att bygga en logistisk regressionsmodell för en lämplig datauppsättning som du väljer.
Ionosphere-datauppsättningen är licensierad under en Creative Commons Attribution 4.0 International (CC BY 4.0)-licens:
Sigillito, V., Wing, S., Hutton, L. och Baker, K.. (1989). Jonosfär. UCI Machine Learning Repository. https://doi.org/10.24432/C5W01B.
Bala Priya C är en utvecklare och teknisk skribent från Indien. Hon gillar att arbeta i skärningspunkten mellan matematik, programmering, datavetenskap och innehållsskapande. Hennes intresseområden och expertis inkluderar DevOps, datavetenskap och naturlig språkbehandling. Hon tycker om att läsa, skriva, koda och fika! För närvarande arbetar hon med att lära sig och dela sin kunskap med utvecklargemenskapen genom att skriva självstudier, guider, åsiktsartiklar och mer.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.kdnuggets.com/building-predictive-models-logistic-regression-in-python?utm_source=rss&utm_medium=rss&utm_campaign=building-predictive-models-logistic-regression-in-python
- :är
- :inte
- $UPP
- 1
- 10
- 11
- 13
- 20
- 33
- 7
- 9
- a
- Om oss
- Konto
- noggrannhet
- Uppnå
- lägga till
- Dessutom
- Efter
- Syftet
- algoritm
- algoritmer
- Alla
- också
- an
- och
- svara
- tillvägagångssätt
- ÄR
- områden
- AS
- utgå ifrån
- At
- författarskap
- b
- bagare
- Balanserad
- bar
- BE
- därför att
- som tillhör
- BÄST
- Ha sönder
- SLUTRESULTAT
- Byggnad
- by
- Ring
- KAN
- kan inte
- kategorier
- kedja
- val
- klass
- klasser
- klassificering
- kodad
- Kodning
- samla
- Kolumn
- Kolonner
- Gemensam
- vanligen
- Commons
- samfundet
- innefattar
- koncis
- innehåll
- innehållsskapande
- konvertera
- Pris
- beläggning
- skapa
- skapande
- För närvarande
- kurva
- datum
- datapunkter
- datavetenskap
- datauppsättning
- Standard
- definierade
- Derivat
- detalj
- detekterad
- Utvecklare
- DevOps
- olika
- riktning
- diskutera
- diskuteras
- Visa
- fördelning
- do
- gör
- ner
- ladda ner
- under
- varje
- huvudsak
- uppskatta
- utvärdering
- expertis
- Utforska
- Uttrycket
- Funktioner
- få
- hitta
- finna
- fynd
- Förnamn
- passa
- följer
- följer
- För
- RAM
- från
- fungera
- skaffa sig
- få
- ges
- Go
- Målet
- större
- Marken
- Guider
- sidan
- hantera
- Har
- hjälpa
- hjälper
- här
- Hur ser din drömresa ut
- HTTPS
- ICS
- if
- obalans
- importera
- in
- innefattar
- index
- indien
- index
- informationen
- ingång
- ingångar
- intresse
- intressant
- skärning
- in
- IT
- bara
- KDnuggets
- Vet
- kunskap
- etikett
- Etiketter
- språk
- LÄRA SIG
- lärt
- inlärning
- mindre
- Låt
- Bibliotek
- Licens
- Licensierade
- tycka om
- sannolikhet
- gillar
- linje
- läser in
- log
- se
- ser ut som
- förlust
- Maskinen
- maskininlärning
- göra
- många
- karta
- matte
- matplotlib
- Maximera
- maximera
- maximal
- Maj..
- betyda
- metod
- Metrics
- minimera
- minsta
- modell
- modeller
- modul
- mer
- flytta
- namn
- Natural
- Naturligt språk
- Naturlig språkbehandling
- Behöver
- negativ
- Nästa
- antal
- observerad
- of
- Ofta
- on
- ONE
- Yttrande
- motsatt
- optimala
- optimering
- Optimera
- or
- Resultat
- utfall
- produktion
- utgångar
- pandor
- parameter
- parametrar
- del
- bitar
- plato
- Platon Data Intelligence
- PlatonData
- Punkt
- poäng
- potentiellt
- Precision
- förutsagda
- Förutsägelser
- prediktiva
- Predictor
- Förutspår
- föredra
- Sannolikheten
- Problem
- Fortsätt
- process
- bearbetning
- Produkter
- Programmering
- ge
- rent
- Python
- radarn
- område
- Betygsätta
- Läsa
- Läsning
- verklig
- register
- avses
- hänvisar
- regression
- rapport
- Repository
- representerar
- begära
- avseende
- respektive
- återgår
- översyn
- robusta
- Regel
- s
- Vetenskap
- scikit lära
- göra
- se
- känsla
- in
- uppsättningar
- delning
- hon
- visas
- Enkelt
- förenkla
- So
- några
- delas
- igång
- statistik
- Steg
- rakt
- struktur
- Senare
- sådana
- lämplig
- summor
- Ta
- tar
- Målet
- uppgifter
- Teknisk
- testa
- Testning
- än
- den där
- Smakämnen
- Dem
- Teorin
- Där.
- därför
- de
- detta
- Genom
- till
- Verktygslåda
- Tåg
- tränad
- Utbildning
- Förvandla
- transformer
- prova
- handledning
- självstudiekurser
- två
- typer
- under
- förstå
- enhet
- Uppdatering
- Uppdateringar
- URL
- us
- USA-konto
- användning
- Begagnade
- med hjälp av
- värde
- Värden
- visualisera
- we
- när
- som
- varför
- wikipedia
- kommer
- Vinge
- med
- Arbete
- arbetssätt
- fungerar
- skulle
- författare
- skrivning
- X
- ja
- dig
- Din
- zephyrnet
- noll-







