Företag har tillgång till enorma mängder data, varav mycket är svårt att upptäcka eftersom datan är ostrukturerad. Konventionella metoder för att analysera ostrukturerade data använd sökords- eller synonymmatchning. De fångar inte hela sammanhanget i ett dokument, vilket gör dem mindre effektiva när det gäller att hantera ostrukturerad data.
Däremot använder textinbäddningar maskininlärning (ML) förmåga att fånga innebörden av ostrukturerad data. Inbäddningar genereras av representativa språkmodeller som översätter text till numeriska vektorer och kodar kontextuell information i ett dokument. Detta möjliggör applikationer som semantisk sökning, Retrieval Augmented Generation (RAG), ämnesmodellering och textklassificering.
Till exempel i den finansiella tjänstesektorn inkluderar applikationer att extrahera insikter från resultatrapporter, söka efter information från bokslut och analysera sentiment om aktier och marknader som finns i finansiella nyheter. Textinbäddningar gör det möjligt för branschfolk att extrahera insikter från dokument, minimera fel och öka deras prestanda.
I det här inlägget visar vi upp en applikation som kan söka och fråga i finansiella nyheter på olika språk med hjälp av Coheres Bädda och Rangordna om modeller med Amazonas berggrund.
Coheres flerspråkiga inbäddningsmodell
Cohere är en ledande AI-plattform för företag som bygger stora språkmodeller (LLM) i världsklass och LLM-drivna lösningar som låter datorer söka, fånga mening och konversera i text. De ger användarvänlighet och starka säkerhets- och integritetskontroller.
Coheres flerspråkiga inbäddningsmodell genererar vektorrepresentationer av dokument för över 100 språk och är tillgänglig på Amazon Bedrock. Detta tillåter AWS-kunder att komma åt det som ett API, vilket eliminerar behovet av att hantera den underliggande infrastrukturen och säkerställer att känslig information förblir säkert hanterad och skyddad.
Den flerspråkiga modellen grupperar text med liknande betydelser genom att tilldela dem positioner som ligger nära varandra i ett semantiskt vektorrum. Med en flerspråkig inbäddningsmodell kan utvecklare bearbeta text på flera språk utan att behöva växla mellan olika modeller, som illustreras i följande figur. Detta gör bearbetningen mer effektiv och förbättrar prestandan för flerspråkiga applikationer.

Följande är några av höjdpunkterna i Coheres inbäddningsmodell:
- Fokus på dokumentkvalitet – Typiska inbäddningsmodeller är tränade för att mäta likheter mellan dokument, men Coheres modell mäter även dokumentkvalitet
- Bättre hämtning för RAG-applikationer – RAG-applikationer kräver ett bra hämtningssystem, vilket Coheres inbäddningsmodell utmärker sig med
- Kostnadseffektiv datakomprimering – Cohere använder en speciell, kompressionsmedveten träningsmetod, vilket resulterar i avsevärda kostnadsbesparingar för din vektordatabas
Använd fall för textinbäddning
Textinbäddningar gör ostrukturerad data till en strukturerad form. Detta gör att du objektivt kan jämföra, dissekera och härleda insikter från alla dessa dokument. Följande är exempel på användningsfall som Coheres inbäddningsmodell möjliggör:
- Semantisk sökning – Möjliggör kraftfulla sökapplikationer i kombination med en vektordatabas, med utmärkt relevans baserat på sökfrasens betydelse
- Sökmotor för ett större system – Hittar och hämtar den mest relevanta informationen från anslutna företagsdatakällor för RAG-system
- Textklassificering – Stöder avsiktsigenkänning, sentimentanalys och avancerad dokumentanalys
- Ämnesmodellering – Förvandlar en samling dokument till distinkta kluster för att avslöja nya ämnen och teman
Förbättrade söksystem med Rerank
I företag där konventionella sökordssökningssystem redan finns, hur introducerar man moderna semantiska sökmöjligheter? För sådana system som har varit en del av ett företags informationsarkitektur under lång tid är en fullständig migrering till en inbäddningsbaserad metod i många fall helt enkelt inte genomförbar.
Cohere's Rerank endpoint är utformad för att överbrygga detta gap. Det fungerar som det andra steget i ett sökflöde för att ge en rangordning av relevanta dokument per en användares fråga. Företag kan behålla ett befintligt nyckelord (eller till och med semantiskt) system för hämtning i första steget och höja kvaliteten på sökresultat med Rerank endpoint i andra steget omrankning.
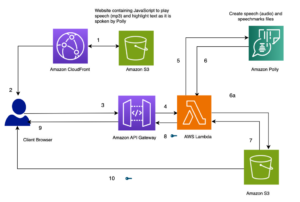
Rerank ger ett snabbt och enkelt alternativ för att förbättra sökresultaten genom att introducera semantisk sökteknik i en användares stack med en enda kodrad. Slutpunkten kommer också med flerspråkigt stöd. Följande figur illustrerar arbetsflödet för hämtning och omplacering.

Lösningsöversikt
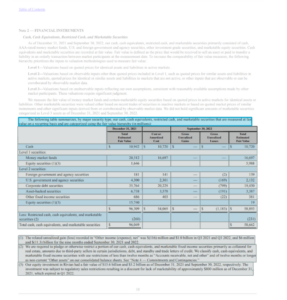
Finansanalytiker behöver smälta mycket innehåll, såsom finansiella publikationer och nyhetsmedier, för att hålla sig informerade. Enligt Association for Financial Professionals (AFP), spenderar finansanalytiker 75 % av sin tid på att samla in data eller administrera processen istället för mervärdesanalys. Att hitta svaret på en fråga i en mängd olika källor och dokument är tidskrävande och tråkigt arbete. Cohere-inbäddningsmodellen hjälper analytiker att snabbt söka i flera artikeltitlar på flera språk för att hitta och rangordna de artiklar som är mest relevanta för en viss fråga, vilket sparar enormt mycket tid och ansträngning.
I följande användningsexempel visar vi hur Coheres Embed-modell söker och frågar över finansiella nyheter på olika språk i en unik pipeline. Sedan visar vi hur du kan förbättra resultaten ytterligare genom att lägga till Rerank till din inbäddningshämtning (eller lägga till den i en äldre lexikal sökning).
Den stödjande anteckningsboken finns tillgänglig på GitHub.
Följande diagram illustrerar applikationens arbetsflöde.

Aktivera modellåtkomst via Amazon Bedrock
Amazon Bedrock-användare måste begära tillgång till modeller för att göra dem tillgängliga för användning. För att begära tillgång till ytterligare modeller, välj Modellåtkomst navigeringsrutan på Amazonas berggrund trösta. För mer information, se Modellåtkomst. För den här genomgången måste du begära tillgång till Cohere Embed Multilingual-modellen.

Installera paket och importera moduler
Först installerar vi de nödvändiga paketen och importerar modulerna vi kommer att använda i det här exemplet:
Importera dokument
Vi använder en datauppsättning (MultiFIN) som innehåller en lista med verkliga artikelrubriker som täcker 15 språk (engelska, turkiska, danska, spanska, polska, grekiska, finska, hebreiska, japanska, ungerska, norska, ryska, italienska, isländska och svenska ). Detta är en datauppsättning med öppen källkod som är kurerad för finansiell naturlig språkbehandling (NLP) och är tillgänglig på en GitHub repository.
I vårt fall har vi skapat en CSV-fil med MultiFINs data samt en kolumn med översättningar. Vi använder inte den här kolumnen för att mata modellen; vi använder den för att hjälpa oss följa med när vi skriver ut resultaten för dem som inte talar danska eller spanska. Vi pekar på den CSV-filen för att skapa vår dataram:
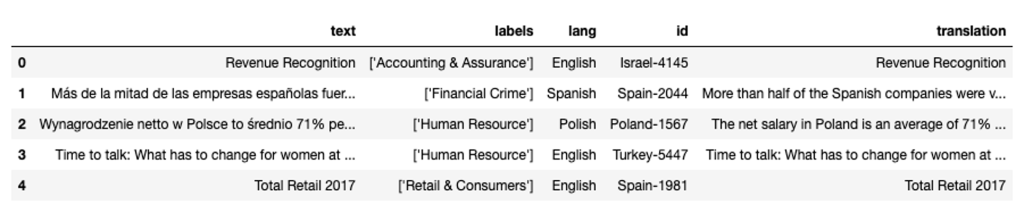
Välj en lista över dokument att fråga efter
MultiFIN har över 6,000 15 skivor på XNUMX olika språk. I vårt exempel fokuserar vi på tre språk: engelska, spanska och danska. Vi sorterar även rubrikerna efter längd och väljer de längsta.
Eftersom vi väljer de längsta artiklarna säkerställer vi att längden inte beror på upprepade sekvenser. Följande kod visar ett exempel där så är fallet. Vi kommer att städa upp det.
df['text'].iloc[2215]
Vår lista över dokument är snyggt fördelad över de tre språken:
Följande är den längsta artikelrubriken i vår datauppsättning:
Bädda in och indexera dokument
Nu vill vi bädda in våra dokument och lagra inbäddningarna. Inbäddningarna är mycket stora vektorer som kapslar in den semantiska innebörden av vårt dokument. I synnerhet använder vi Coheres embed-multilingual-v3.0-modell, som skapar inbäddningar med 1,024 XNUMX dimensioner.
När en fråga skickas bäddar vi också in frågan och använder hnswlib-biblioteket för att hitta de närmaste grannarna.
Det tar bara några rader kod för att skapa en Cohere-klient, bädda in dokumenten och skapa sökindexet. Vi håller också reda på språket och översättningen av dokumentet för att berika visningen av resultaten.
Bygg ett hämtningssystem
Därefter bygger vi en funktion som tar en fråga som indata, bäddar in den och hittar de fyra rubrikerna som är närmare relaterade till den:
Fråga efter hämtningssystemet
Låt oss utforska vad vårt system gör med ett par olika frågor. Vi börjar med engelska:
Resultaten är följande:
Lägg märke till följande:
- Vi ställer relaterade, men lite annorlunda frågor, och modellen är tillräckligt nyanserad för att presentera de mest relevanta resultaten överst.
- Vår modell utför inte sökordsbaserad sökning, utan semantisk sökning. Även om vi använder en term som "datavetenskap" istället för "AI" kan vår modell förstå vad som efterfrågas och returnera det mest relevanta resultatet överst.
Vad sägs om en fråga på danska? Låt oss titta på följande fråga:
I det föregående exemplet står den engelska förkortningen "PP&E" för "property, plant and equipment", och vår modell kunde koppla den till vår fråga.
I det här fallet är alla returnerade resultat på danska, men modellen kan returnera ett dokument på ett annat språk än frågan om dess semantiska betydelse är närmare. Vi har full flexibilitet och med några rader kod kan vi specificera om modellen endast ska titta på dokument på språket för frågan, eller om den ska titta på alla dokument.
Förbättra resultaten med Cohere Rerank
Inbäddningar är mycket kraftfulla. Men vi ska nu titta på hur vi kan förfina våra resultat ytterligare med Cohere's Rerank endpoint, som har tränats för att bedöma relevansen av dokument mot en fråga.
En annan fördel med Rerank är att den kan fungera ovanpå en äldre sökmotor för sökord. Du behöver inte byta till en vektordatabas eller göra drastiska ändringar i din infrastruktur, och det tar bara några rader kod. Rerank finns tillgänglig i Amazon SageMaker.
Låt oss prova en ny fråga. Vi använder SageMaker den här gången:
I det här fallet kunde en semantisk sökning hämta vårt svar och visa det i resultaten, men det är inte överst. Men när vi skickar frågan igen till vår Rerank endpoint med listan över dokument hämtade, kan Rerank visa det mest relevanta dokumentet högst upp.
Först skapar vi klienten och Rerank endpoint:
När vi skickar dokumenten till Rerank kan modellen välja den mest relevanta exakt:
Slutsats
Det här inlägget presenterade en genomgång av att använda Coheres flerspråkiga inbäddningsmodell i Amazon Bedrock i domänen för finansiella tjänster. I synnerhet visade vi ett exempel på ett flerspråkigt sökprogram för finansiella artiklar. Vi såg hur inbäddningsmodellen möjliggör effektiv och korrekt upptäckt av information och därigenom höjer produktiviteten och utdatakvaliteten hos en analytiker.
Coheres flerspråkiga inbäddningsmodell stöder över 100 språk. Det tar bort komplexiteten i att bygga applikationer som kräver att man arbetar med en samling dokument på olika språk. De Cohere Embed-modell är utbildad för att leverera resultat i verkliga tillämpningar. Den hanterar bullriga data som indata, anpassar sig till komplexa RAG-system och levererar kostnadseffektivitet från sin kompressionsmedvetna träningsmetod.
Börja bygga med Coheres flerspråkiga inbäddningsmodell i Amazon Bedrock idag.
Om författarna
 James Yi är senior AI/ML Partner Solutions Architect i Technology Partners COE Tech-team på Amazon Web Services. Han brinner för att arbeta med företagskunder och partners för att designa, distribuera och skala AI/ML-applikationer för att få affärsvärde. Utanför jobbet tycker han om att spela fotboll, resa och umgås med sin familj.
James Yi är senior AI/ML Partner Solutions Architect i Technology Partners COE Tech-team på Amazon Web Services. Han brinner för att arbeta med företagskunder och partners för att designa, distribuera och skala AI/ML-applikationer för att få affärsvärde. Utanför jobbet tycker han om att spela fotboll, resa och umgås med sin familj.
 Gonzalo Betegon är en lösningsarkitekt på Cohere, en leverantör av banbrytande teknologi för naturlig språkbehandling. Han hjälper organisationer att möta sina affärsbehov genom att använda stora språkmodeller.
Gonzalo Betegon är en lösningsarkitekt på Cohere, en leverantör av banbrytande teknologi för naturlig språkbehandling. Han hjälper organisationer att möta sina affärsbehov genom att använda stora språkmodeller.
 Meor Amer är en Developer Advocate på Cohere, en leverantör av banbrytande teknik för naturlig språkbehandling (NLP). Han hjälper utvecklare att bygga banbrytande applikationer med Coheres stora språkmodeller (LLM).
Meor Amer är en Developer Advocate på Cohere, en leverantör av banbrytande teknik för naturlig språkbehandling (NLP). Han hjälper utvecklare att bygga banbrytande applikationer med Coheres stora språkmodeller (LLM).
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/build-financial-search-applications-using-the-amazon-bedrock-cohere-multilingual-embedding-model/
- : har
- :är
- :inte
- :var
- $UPP
- 000
- 1
- 10
- 100
- 11
- 13
- 15%
- 16
- 2030
- 22
- 29
- 33
- 7
- 8
- 80
- 9
- a
- Able
- Om oss
- tillgång
- Enligt
- Konto
- exakt
- exakt
- Uppnå
- tvärs
- handlingar
- anpassar sig
- tillsats
- Annat
- adress
- avancerat
- Fördel
- förespråkare
- AFP
- igen
- mot
- AI
- AI-plattform
- AI / ML
- Alla
- tillåter
- tillåter
- längs
- redan
- också
- amason
- Amazon Web Services
- mängd
- mängder
- an
- analys
- analytiker
- analytiker
- analys
- och
- svara
- api
- Ansökan
- tillämpningar
- tillvägagångssätt
- tillvägagångssätt
- arkitektur
- ÄR
- Artikeln
- artiklar
- AS
- be
- At
- augmented
- tillgänglig
- AWS
- baserat
- därför att
- varit
- Där vi får lov att vara utan att konstant prestera,
- Bättre
- mellan
- Block
- lyft
- öka
- Brexit
- BRO
- SLUTRESULTAT
- Byggnad
- bygger
- företag
- Företagsledare
- företag
- men
- by
- KAN
- kapacitet
- fånga
- Vid
- fall
- tak
- ekonomichefer
- utmanar
- utmaningar
- byta
- Förändringar
- Välja
- klassificering
- rena
- klient
- Stäng
- nära
- närmare
- CO
- koda
- samling
- Kolumn
- kommer
- Företag
- Företagets
- jämföra
- fullborda
- komplex
- Komplexiteten
- datorer
- aktuella
- Kontakta
- anslutna
- innehåll
- sammanhang
- kontextuella
- Däremot
- kontroller
- konventionell
- Företag
- Pris
- kostnadsbesparingar
- kunde
- Par
- kopplad
- beläggning
- Covid-19
- skapa
- skapas
- skapar
- kredit
- kris
- kriterier
- kurerad
- Aktuella
- Kunder
- allra senaste
- Cybersäkerhet
- danska
- datum
- datavetenskap
- Databas
- de
- tidsfrist
- som handlar om
- dedicerad
- del
- leverera
- leverera resultat
- levererar
- demonstrera
- demonstreras
- Den
- distribuera
- utplacering
- insättningar
- härleda
- Designa
- utformade
- Utvecklare
- utvecklare
- Utveckling
- olika
- svårt
- Smälta
- dimensioner
- Upptäck
- Upptäckten
- Visa
- distinkt
- distribueras
- fördelning
- do
- dokumentera
- dokument
- gör
- domän
- inte
- ner
- driv
- grund
- e
- varje
- Tidig
- Resultat
- lätta
- enkel användning
- ekonomi
- Effektiv
- effektiv
- ansträngning
- el
- eliminerar
- annars
- embed
- inbäddning
- smärgel
- utsläpp
- Anställd
- möjliggöra
- möjliggör
- änden
- Slutpunkt
- ingrepp
- Motor
- Engelska
- enorm
- tillräckligt
- berika
- säkerställa
- säkerställer
- Företag
- företagskunder
- företag
- Miljö
- Utrustning
- fel
- ESG
- etablera
- Eter (ETH)
- Även
- exempel
- utmärkt
- befintliga
- erfaren
- utforska
- extrahera
- Falls
- familj
- SNABB
- möjlig
- få
- Figur
- Fil
- finansiella
- finansiella nyheter
- finansiella tjänster
- hitta
- finna
- fynd
- finsk
- fem
- Flexibilitet
- flöda
- Fokus
- följer
- efter
- följer
- För
- formen
- hittade
- fyra
- Frist
- från
- full
- fungera
- ytterligare
- spalt
- GAS
- samla
- BNP
- genereras
- genererar
- Välgörenhet
- Global ekonomi
- Go
- Mål
- kommer
- god
- grekisk
- Gruppens
- styra
- Handtag
- Har
- he
- headers
- Rubriker
- hebrew
- hjälpa
- hjälper
- höjdpunkter
- hans
- Träffa
- Hur ser din drömresa ut
- How To
- Men
- html
- HTTPS
- ungerska
- i
- if
- illustrerar
- genomföra
- importera
- förbättra
- förbättrar
- förbättra
- in
- innefattar
- Öka
- index
- industrin
- info
- informationen
- informeras
- Infrastruktur
- ingång
- ingångar
- insikter
- installera
- istället
- integrera
- integrering
- uppsåt
- in
- införa
- införa
- IP
- IT
- italienska
- DESS
- Januari
- japanska
- Lediga jobb
- jpg
- bara
- Ha kvar
- liggande
- LÅNG
- språk
- Språk
- Large
- större
- största
- LAS
- Efternamn
- senaste
- ledare
- ledande
- leasing
- Legacy
- Lagstiftande
- lagstiftningsförslag
- Längd
- mindre
- Bibliotek
- tycka om
- linje
- rader
- Lista
- Noterade
- Lån
- Lång
- länge sedan
- se
- den
- Lot
- Huvudsida
- göra
- GÖR
- Framställning
- människa
- hantera
- förvaltade
- ledning
- många
- karta
- Mars
- marknad
- marknadspris
- Marknader
- massiv
- matchande
- betyder
- betydelser
- mäta
- åtgärder
- Media
- Möt
- möte
- bara
- metod
- migration
- minimera
- ML
- Mode
- modell
- modellering
- modeller
- Modern Konst
- Moduler
- mer
- mer effektiv
- mest
- mycket
- multipel
- namn
- Natural
- Naturligt språk
- Naturlig språkbehandling
- Navigering
- nödvändigt för
- Behöver
- behov
- grannar
- Nya
- nyheter
- nyhetsmedier
- Nästa
- nlp
- Nej
- norska
- anteckningsbok
- nu
- talrik
- NY
- NYE
- NYT
- objektivt
- of
- on
- ONE
- ettor
- endast
- angrepp
- öppet
- öppen källkod
- Alternativet
- or
- beställa
- organisationer
- ursprungliga
- OS
- Övriga
- vår
- produktion
- utanför
- över
- paket
- paket
- pandor
- panelen
- del
- särskilt
- partnern
- partner
- passera
- Godkänd
- brinner
- betalning
- Lön
- för
- utföra
- prestanda
- plocka
- plockning
- rörledning
- Planen
- växt
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- i
- podcast
- Punkt
- polska
- positioner
- Inlägg
- potentiell
- den mäktigaste
- föregående
- presentera
- presenteras
- Principal
- Skriva ut
- privatpolicy
- process
- bearbetning
- produktivitet
- yrkesmän/kvinnor
- Framsteg
- egenskapen
- förslag
- skyddad
- ge
- leverantör
- ger
- publikationer
- Syftet
- PWC
- kvalitet
- sökfrågor
- fråga
- frågor
- snabbt
- R
- höja
- rangordna
- Rankning
- RE
- redo
- verkliga världen
- erkännande
- register
- minska
- referens
- förfina
- Reform
- region
- relaterad
- relevans
- relevanta
- förblir
- resterna
- avlägsnar
- åter öppna
- upprepade
- ersätta
- Rapportering
- Rapport
- begära
- kräver
- resultera
- resulterande
- Resultat
- behålla
- avkastning
- tillbaka
- ryska
- s
- sagemaker
- sparande
- Besparingar
- såg
- Skala
- Vetenskap
- göra
- Sök
- sökmotor
- sök
- söka
- SEC
- Andra
- säkert
- säkerhet
- se
- vald
- senior
- känslig
- känsla
- Tjänster
- session
- aktieägare
- skall
- visa
- Visar
- liknande
- enda
- Områden
- något annorlunda
- Långsamt
- Fotboll
- Lösningar
- några
- Källa
- Källor
- Utrymme
- spanska
- tala
- speciell
- spendera
- Spendera
- stapel
- Personal
- Etapp
- standard
- står
- starta
- Starta
- uttalanden
- bo
- lager
- aktiemarknaden
- Aktier
- lagra
- okomplicerad
- Strategi
- stark
- strukturerade
- väsentlig
- sådana
- stödja
- Som stöds
- Stödjande
- Stöder
- yta
- Undersökning
- Hållbarhet
- hållbart
- Hållbar utveckling
- svenska
- Växla
- Synonym
- system
- System
- tar
- mål
- skatt
- skattelättnad
- grupp
- tech
- Teknologi
- termin
- text
- Textklassificering
- än
- den där
- Smakämnen
- deras
- Dem
- sedan
- Där.
- vari
- Dessa
- de
- detta
- de
- tre
- Genom
- tid
- titlar
- till
- i dag
- topp
- ämne
- ämnen
- spår
- tränad
- Utbildning
- Översätt
- Översättning
- Översättningar
- Traveling
- prova
- turkiska
- SVÄNG
- vänder
- typisk
- UN
- avslöja
- underliggande
- förstå
- unika
- URL
- us
- användning
- användningsfall
- användare
- användningar
- med hjälp av
- värde
- mängd
- mycket
- genomgång
- vill
- var
- Våg
- Sätt..
- we
- webb
- webbservice
- VÄL
- Vad
- när
- om
- som
- VEM
- kommer
- med
- utan
- Arbete
- arbetsflöde
- arbetssätt
- världen
- världsklass
- år
- ännu
- dig
- Din
- zephyrnet