Att förbättra hur användare upptäcker nytt innehåll är avgörande för att öka användarnas engagemang och tillfredsställelse på medieplattformar. Enbart nyckelordssökning har utmaningar att fånga semantik och användaravsikter, vilket leder till resultat som saknar relevant sammanhang; till exempel att hitta date night eller filmer med jultema. Detta kan leda till lägre lagringsfrekvens om användare inte på ett tillförlitligt sätt kan hitta det innehåll de vill ha. Dock med stora språkmodeller (LLMs), finns det en möjlighet att lösa dessa semantiska och användaravsiktsutmaningar. Genom att kombinera inbäddningar som fångar semantik med en teknik som kallas Retrieval Augmented Generation (RAG), kan du generera mer relevanta svar baserat på hämtat sammanhang från dina egna datakällor.
I det här inlägget visar vi dig hur du säkert skapar en filmchattbot genom att implementera RAG med din egen data med hjälp av kunskapsbaser för Amazonas berggrund. Vi använder IMDb och Box Office Mojo dataset för att simulera en katalog för medie- och underhållningskunder och visa upp hur du kan bygga din egen RAG-lösning i bara ett par steg.
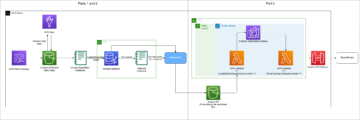
Lösningsöversikt
Smakämnen IMDb och Box Office Mojo Movies/TV/OTT licenserbart datapaket tillhandahåller ett brett utbud av underhållningsmetadata, inklusive över 1.6 miljard användarbetyg; krediter för mer än 13 miljoner skådespelare och besättningsmedlemmar; 10 miljoner film-, TV- och underhållningstitlar; och globala kassarapportdata från mer än 60 länder. Många AWS media- och underhållningskunder licensierar IMDb-data genom AWS datautbyte för att förbättra innehållsupptäckten och öka kundernas engagemang och retention.
Introduktion till kunskapsbaser för Amazon Bedrock
För att utrusta en LLM med uppdaterad proprietär information använder organisationer RAG, en teknik som involverar att hämta data från företagets datakällor och berika uppmaningen med den informationen för att leverera mer relevanta och korrekta svar. Kunskapsbaser för Amazon Bedrock möjliggör en fullständigt hanterad RAG-kapacitet som låter dig anpassa LLM-svar med kontextuella och relevanta företagsdata. Kunskapsbaser automatiserar RAG-arbetsflödet från början till slut, inklusive inmatning, hämtning, snabba ökningar och citeringar, vilket eliminerar behovet av att skriva anpassad kod för att integrera datakällor och hantera frågor. Kunskapsbaser för Amazon Bedrock möjliggör också konversationer med flera svängar så att LLM kan svara på komplexa användarfrågor med rätt svar.
Vi använder följande tjänster som en del av denna lösning:
Vi går igenom följande steg på hög nivå:
- Förbehandla IMDb-data för att skapa dokument från varje filmpost och ladda upp data till en Amazon enkel lagringstjänst (Amazon S3) hink.
- Skapa en kunskapsbas.
- Synkronisera din kunskapsbas med din datakälla.
- Använd kunskapsbasen för att svara på semantiska frågor om filmkatalogen.
Förutsättningar
IMDb-data som används i det här inlägget kräver en kommersiell innehållslicens och betald prenumeration på IMDb och Box Office Mojo Movies/TV/OTT-licenspaket på AWS Data Exchange. För att fråga om en licens och få tillgång till exempeldata, besök developer.imdb.com. För att komma åt datauppsättningen, se Effektrekommendation och sökning med hjälp av en IMDb-kunskapsgraf – Del 1 och följ Få åtkomst till IMDb-data sektion.
Förbehandla IMDb-data
Innan vi skapar en kunskapsbas måste vi förbehandla IMDb-datauppsättningen till textfiler och ladda upp dem till en S3-bucket. I det här inlägget simulerar vi en kundkatalog med hjälp av IMDb-datauppsättningen. Vi tar 10,000 XNUMX populära filmer från IMDb-datauppsättningen för katalogen och bygger datauppsättningen.
Använd följande anteckningsbok för att skapa datasetet med ytterligare information som skådespelare, regissör och producentnamn. Vi använder följande kod för att skapa en enda fil för en film med all information lagrad i filen i en ostrukturerad text som kan förstås av LLM:er:
När du har data i .txt-format kan du ladda upp data till Amazon S3 med följande kommando:
Skapa IMDb Knowledge Base
Utför följande steg för att skapa din kunskapsbas:
- Välj på Amazon Bedrock-konsolen Kunskapsbas i navigeringsfönstret.
- Välja Skapa kunskapsbas.
- För Kunskapsbasens namn, stiga på
imdb. - För Kunskapsbasbeskrivning, ange en valfri beskrivning, till exempel kunskapsbas för inmatning och lagring av imdb-data.
- För IAM-behörigheter, Välj Skapa och använd en ny tjänstroll, ange sedan ett namn för din nya tjänstroll.
- Välja Nästa.
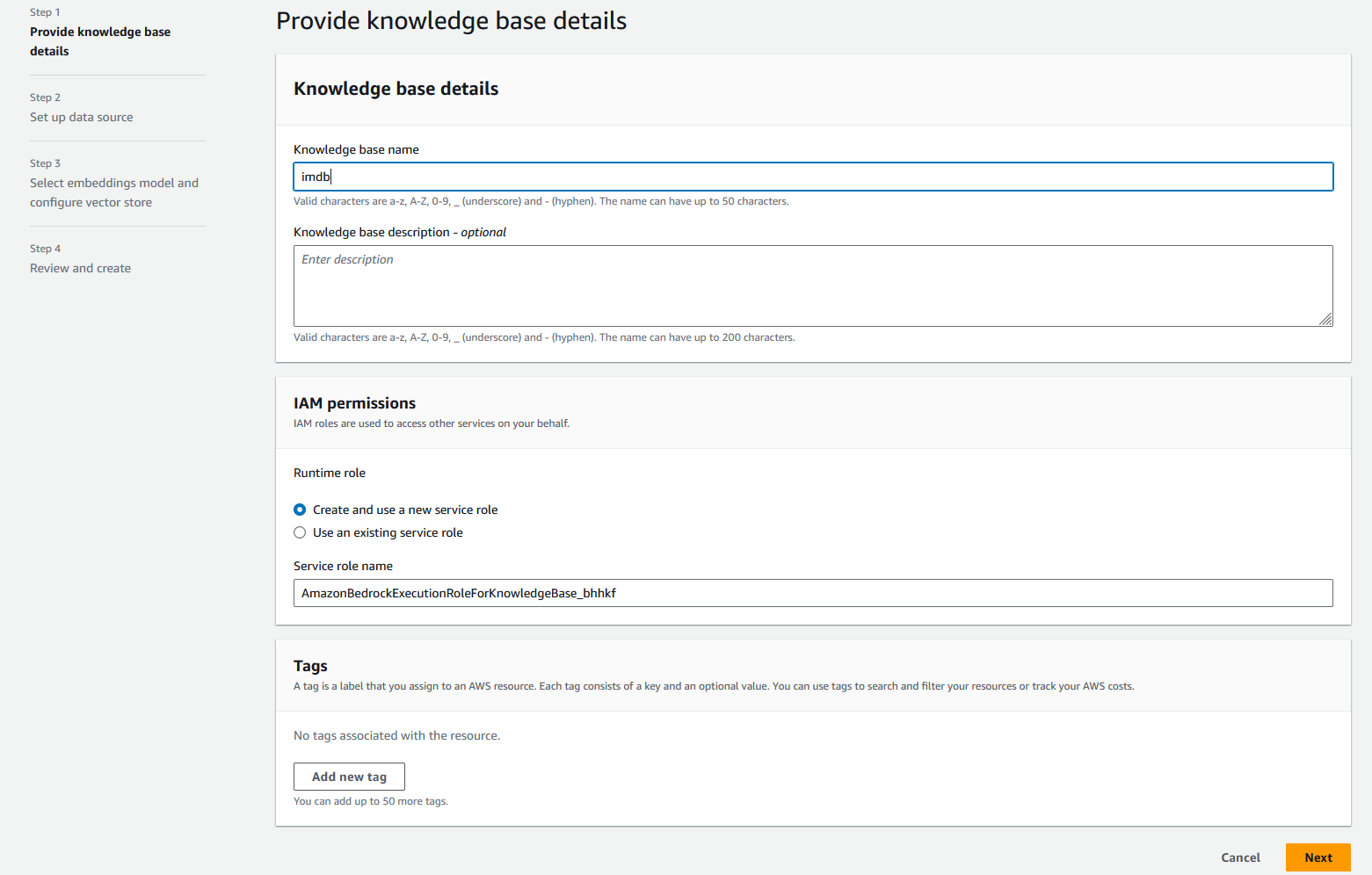
- För Datakällans namn, stiga på
imdb-s3. - För S3 URI, ange S3 URI som du laddade upp data till.
- I Avancerade inställningar – valfritt avsnitt, för Chunking strategiväljer Ingen chunking.
- Välja Nästa.
Kunskapsbaser gör att du kan dela upp dina dokument i mindre segment för att göra det enkelt för dig att bearbeta stora dokument. I vårt fall har vi redan delat in data i ett mindre dokument (ett per film).
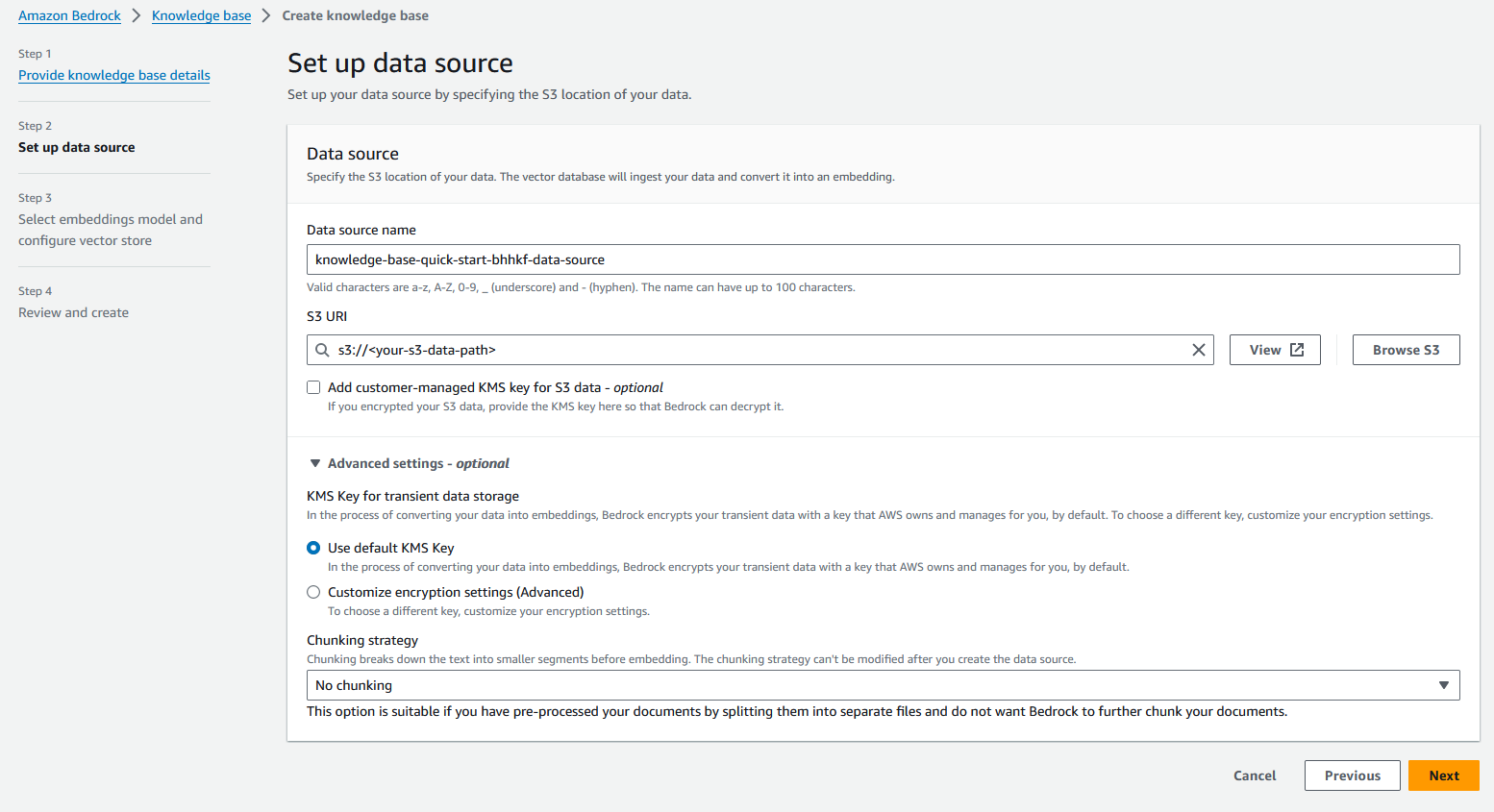
- I Vektor databas avsnitt, välj Skapa snabbt en ny vektorbutik.
Amazon Bedrock kommer automatiskt att skapa en fullständigt hanterad OpenSearch Serverless vektorsökningssamling och konfigurera inställningarna för att bädda in dina datakällor med den valda Titan Embedding G1 – Textinbäddningsmodell.
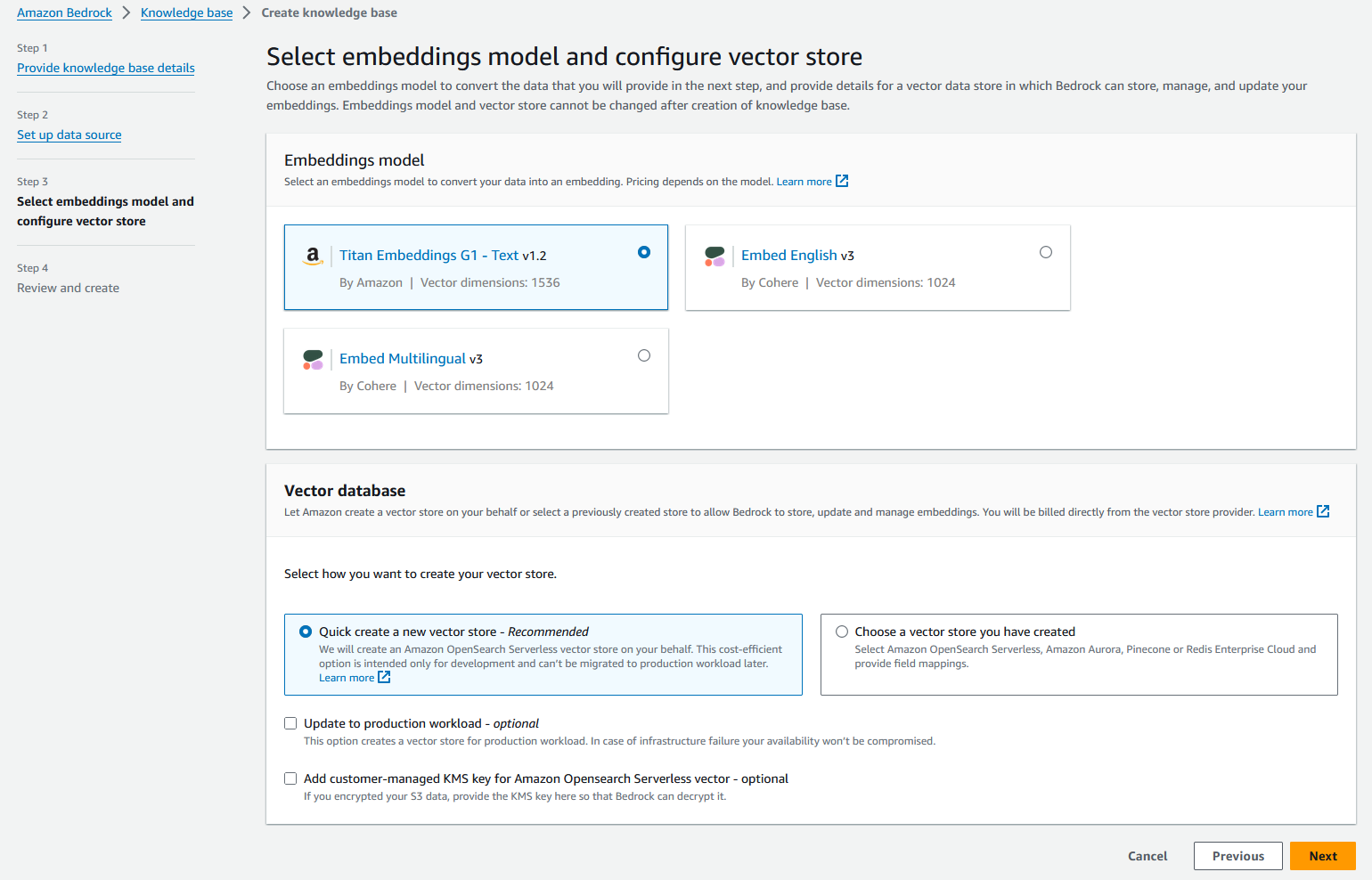
- Välja Nästa.
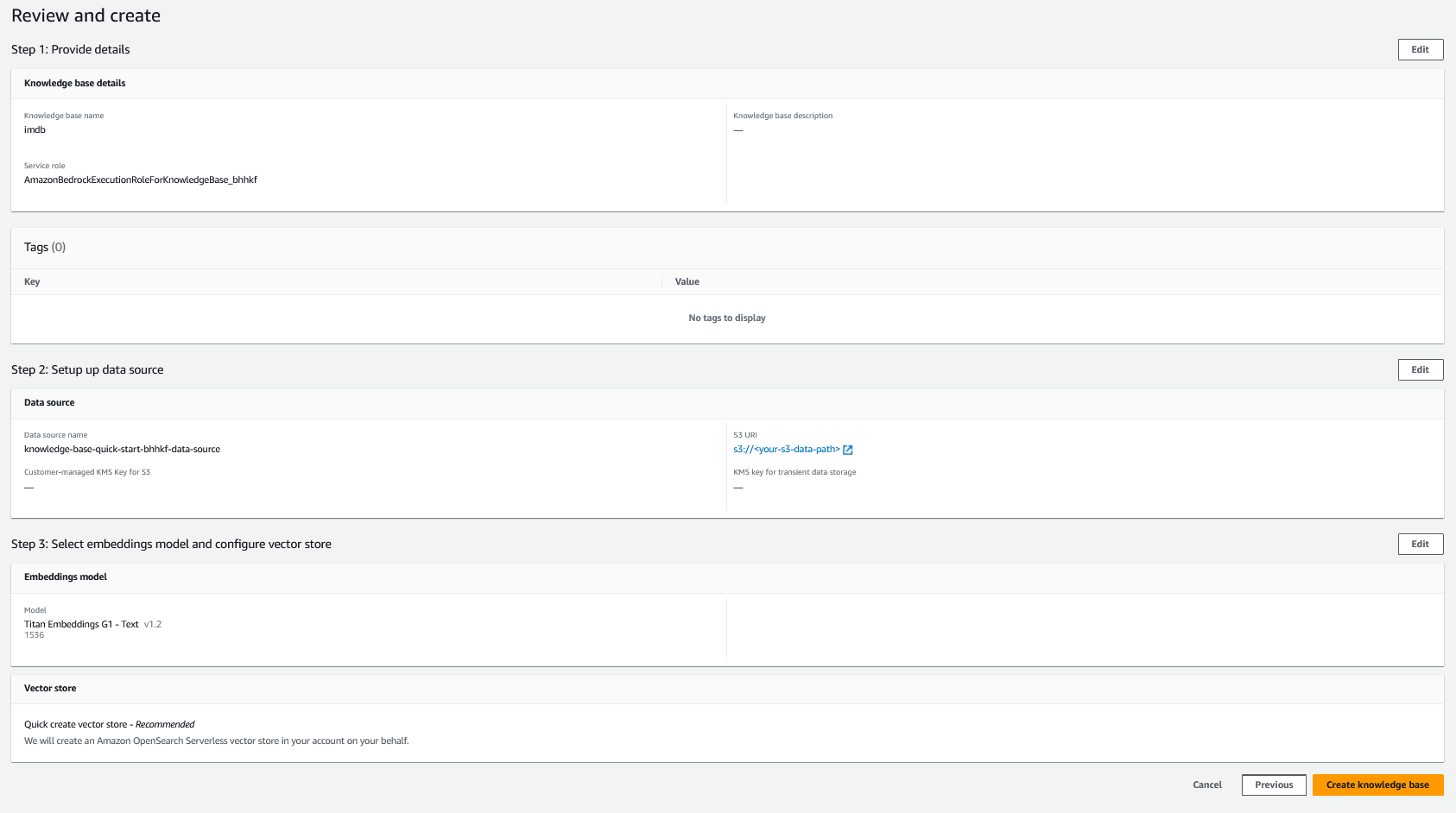
- Granska dina inställningar och välj Skapa kunskapsbas.
Synkronisera dina data med kunskapsbasen
Nu när du har skapat din kunskapsbas kan du synkronisera kunskapsbasen med dina data.
- På Amazon Bedrock-konsolen, navigera till din kunskapsbas.
- I Datakälla avsnitt väljer Synkronisera.

När datakällan har synkroniserats är du redo att fråga efter data.
Förbättra sökningen med hjälp av semantiska resultat
Utför följande steg för att testa lösningen och förbättra din sökning med hjälp av semantiska resultat:
- På Amazon Bedrock-konsolen, navigera till din kunskapsbas.
- Välj din kunskapsbas och välj Testa kunskapsbas.
- Välja Välj modell, och välj Antropisk Claude v2.1.
- Välja Ansök.
Nu är du redo att fråga efter data.
Vi kan ställa några semantiska frågor, som "Rekommendera mig några filmer med jultema."
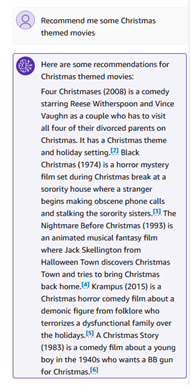
Kunskapsbassvaren innehåller citat som du kan utforska för korrekthet och fakta.
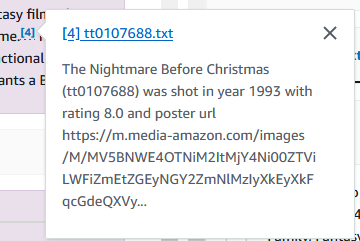
Du kan också gå igenom all information du behöver från dessa filmer. I följande exempel frågar vi "vem regisserade mardröm innan jul?"

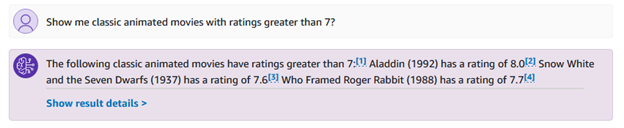
Du kan också ställa mer specifika frågor relaterade till genrer och betyg, som "visa mig klassiska animerade filmer med betyg över 7?"
Utöka din kunskapsbas med agenter
Agenter för Amazon Bedrock hjälpa dig att automatisera komplexa uppgifter. Agenter kan dela upp användarfrågan i mindre uppgifter och anropa anpassade API:er eller kunskapsbaser för att komplettera information för att köra åtgärder. Med Agents for Amazon Bedrock kan utvecklare integrera intelligenta agenter i sina appar, påskynda leveransen av AI-drivna applikationer och spara veckors utvecklingstid. Med agenter kan du utöka din kunskapsbas genom att lägga till mer funktionalitet som rekommendationer från Amazon Anpassa för användarspecifika rekommendationer eller att utföra åtgärder som att filtrera filmer baserat på användarnas behov.
Slutsats
I det här inlägget visade vi hur man bygger en konversationsfilmchattbot med hjälp av Amazon Bedrock i några steg för att svara på semantiska sökningar och konversationsupplevelser baserat på dina egna data och IMDb och Box Office Mojo Movies/TV/OTT-licensierade dataset. I nästa inlägg går vi igenom processen att lägga till mer funktionalitet till din lösning med hjälp av Agents for Amazon Bedrock. För att komma igång med kunskapsbaser om Amazon Bedrock, se Kunskapsbaser för Amazon Bedrock.
Om författarna
 Gaurav Rele är Senior Data Scientist vid Generative AI Innovation Center, där han arbetar med AWS-kunder över olika vertikaler för att påskynda deras användning av generativ AI och AWS Cloud-tjänster för att lösa deras affärsutmaningar.
Gaurav Rele är Senior Data Scientist vid Generative AI Innovation Center, där han arbetar med AWS-kunder över olika vertikaler för att påskynda deras användning av generativ AI och AWS Cloud-tjänster för att lösa deras affärsutmaningar.
 Divya Bhargavi är en Senior Applied Scientist Lead vid Generative AI Innovation Center, där hon löser affärsproblem med högt värde för AWS-kunder med hjälp av generativa AI-metoder. Hon arbetar med bild-/videoförståelse & hämtning, kunskapsdiagram utökade stora språkmodeller och personliga reklamanvändningsfall.
Divya Bhargavi är en Senior Applied Scientist Lead vid Generative AI Innovation Center, där hon löser affärsproblem med högt värde för AWS-kunder med hjälp av generativa AI-metoder. Hon arbetar med bild-/videoförståelse & hämtning, kunskapsdiagram utökade stora språkmodeller och personliga reklamanvändningsfall.
 Suren Gunturu är en Data Scientist som arbetar i Generative AI Innovation Center, där han arbetar med olika AWS-kunder för att lösa affärsproblem med högt värde. Han är specialiserad på att bygga ML-pipelines med hjälp av stora språkmodeller, främst genom Amazon Bedrock och andra AWS-molntjänster.
Suren Gunturu är en Data Scientist som arbetar i Generative AI Innovation Center, där han arbetar med olika AWS-kunder för att lösa affärsproblem med högt värde. Han är specialiserad på att bygga ML-pipelines med hjälp av stora språkmodeller, främst genom Amazon Bedrock och andra AWS-molntjänster.
 Vidya Sagar Ravipati är Science Manager på Generative AI Innovation Center, där han utnyttjar sin stora erfarenhet av distribuerade system i stor skala och sin passion för maskininlärning för att hjälpa AWS-kunder över olika branschvertikaler att påskynda deras AI- och molnintroduktion.
Vidya Sagar Ravipati är Science Manager på Generative AI Innovation Center, där han utnyttjar sin stora erfarenhet av distribuerade system i stor skala och sin passion för maskininlärning för att hjälpa AWS-kunder över olika branschvertikaler att påskynda deras AI- och molnintroduktion.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/machine-learning/build-a-movie-chatbot-for-tv-ott-platforms-using-retrieval-augmented-generation-in-amazon-bedrock/
- : har
- :är
- :var
- $ 10 miljoner
- 000
- 1
- 10
- 100
- 11
- 118
- 12
- 13
- 360
- 385
- 60
- 7
- a
- Om oss
- accelerera
- accelererande
- tillgång
- exakt
- tvärs
- åtgärder
- aktörer
- tillsats
- Annat
- Antagande
- reklam
- medel
- AI
- AI-powered
- Alla
- tillåter
- ensam
- redan
- också
- amason
- Amazon Web Services
- an
- och
- svara
- svar
- vilken som helst
- API: er
- tillämpningar
- tillämpas
- appar
- ÄR
- AS
- be
- At
- förstärka
- augmented
- automatisera
- automatiskt
- AWS
- bas
- baserat
- BE
- innan
- Miljarder
- Box
- box office
- Ha sönder
- SLUTRESULTAT
- Byggnad
- företag
- by
- Ring
- kallas
- KAN
- kapacitet
- fånga
- Fångande
- Vid
- fall
- katalog
- Centrum
- utmaningar
- chatbot
- Välja
- valda
- Jul
- klassiska
- cloud
- moln adoption
- molntjänster
- koda
- samling
- kombinera
- kommersiella
- företag
- komplex
- Konsol
- innehålla
- innehåll
- sammanhang
- kontextuella
- konversera
- konversationer
- korrekt
- länder
- Par
- skapa
- skapas
- krediter
- besättning
- kritisk
- beställnings
- kund
- Kundförlovning
- Kunder
- skräddarsy
- datum
- Datautbyte
- datavetare
- Datum
- leverera
- leverans
- beskrivning
- detaljer
- utvecklare
- Utveckling
- olika
- riktad
- Direktör
- Direktörer
- Upptäck
- Upptäckten
- distribueras
- distribuerade system
- dokumentera
- dokument
- ner
- driv
- eliminera
- inbäddning
- möjliggöra
- början till slut
- ingrepp
- berikande
- ange
- Underhållning
- Eter (ETH)
- Varje
- exempel
- utbyta
- erfarenhet
- Erfarenheter
- utforska
- få
- Fil
- Filer
- filtrering
- hitta
- finna
- följer
- efter
- För
- format
- från
- fullständigt
- funktionalitet
- g1
- generera
- generering
- generativ
- Generativ AI
- genrer
- skaffa sig
- Välgörenhet
- Go
- diagram
- större
- Har
- he
- hjälpa
- högnivå
- hans
- Hur ser din drömresa ut
- How To
- Men
- html
- http
- HTTPS
- if
- genomföra
- förbättra
- in
- Inklusive
- Öka
- industrin
- info
- informationen
- Innovation
- fråga
- integrera
- Intelligent
- uppsåt
- in
- innebär
- IT
- jpg
- bara
- kunskap
- Brist
- språk
- Large
- storskalig
- leda
- ledande
- inlärning
- hävstångs
- Licens
- Licensierade
- Licens
- tycka om
- llm
- lokal
- läge
- lägre
- Maskinen
- maskininlärning
- göra
- hantera
- förvaltade
- chef
- många
- me
- Media
- Medlemmar
- metadata
- metoder
- miljon
- ML
- modell
- modeller
- mojo
- mer
- film
- Filmer
- namn
- namn
- Navigera
- Navigering
- Behöver
- behov
- Nya
- Nästa
- natt
- of
- Office
- on
- ONE
- Möjlighet
- or
- organisationer
- Övriga
- vår
- över
- egen
- paket
- sida
- betalas
- panelen
- del
- brinner
- bana
- för
- utför
- personlig
- Plattformar
- plato
- Platon Data Intelligence
- PlatonData
- komplott
- Populära
- Inlägg
- Affisch
- primärt
- problem
- process
- producent
- producenter
- proprietary
- ger
- sökfrågor
- fråga
- frågor
- trasa
- område
- rates
- betyg
- betyg
- redo
- rekommenderar
- Rekommendation
- rekommendationer
- post
- hänvisa
- relaterad
- relevanta
- Rapportering
- Kräver
- respons
- svar
- Resultat
- retentionstid
- hämtning
- avkastning
- Roll
- RAD
- rinnande
- tillfredsställande
- sparande
- Vetenskap
- Forskare
- Sök
- §
- säkert
- segment
- välj
- semantisk
- semantik
- senior
- Server
- service
- Tjänster
- inställningar
- hon
- skott
- show
- visa
- visade
- Enkelt
- simulera
- enda
- Storlek
- mindre
- So
- lösning
- LÖSA
- Löser
- några
- Källa
- Källor
- specialiserat
- specifik
- igång
- Steg
- förvaring
- lagra
- lagras
- okomplicerad
- prenumeration
- sådana
- komplettera
- synkronisera.
- System
- Ta
- uppgifter
- Tekniken
- testa
- text
- än
- den där
- Smakämnen
- den information
- deras
- Dem
- tema
- sedan
- Där.
- Dessa
- de
- detta
- Genom
- tid
- titan
- titlar
- till
- tv
- förståelse
- förstått
- ostrukturerad
- TIDSENLIG
- uppladdad
- URI
- URL
- användning
- Begagnade
- Användare
- användare
- med hjälp av
- olika
- Omfattande
- vertikaler
- Besök
- W
- gå
- vill
- var
- we
- webb
- webbservice
- veckor
- bred
- Brett utbud
- kommer
- med
- arbetsflöde
- arbetssätt
- fungerar
- skriva
- X
- år
- dig
- Din
- zephyrnet