AWS Lim Studio är nu integrerad med AWS Lim DataBrew. AWS Glue Studio är ett grafiskt gränssnitt som gör det enkelt att skapa, köra och övervaka extrahera, transformera och ladda (ETL) jobb i AWS-lim. DataBrew är ett visuellt dataförberedande verktyg som gör att du kan rensa och normalisera data utan att skriva någon kod. De över 200 transformationerna som den tillhandahåller är nu tillgängliga för att användas i ett visuellt jobb i AWS Glue Studio.
I DataBrew, a Receptet är en uppsättning datatransformationssteg som du kan skapa interaktivt i dess intuitiva visuella gränssnitt. I det här inlägget kommer du att se hur du använder bygga ett recept i DataBrew och sedan tillämpa det som en del av ett visuellt ETL-jobb i AWS Glue Studio.
Befintliga DataBrew-användare kommer också att dra nytta av denna integration – du kan nu köra dina recept som en del av ett större visuellt arbetsflöde med alla andra komponenter som AWS Glue Studio tillhandahåller, förutom att du kan använda avancerad jobbkonfiguration och den senaste versionen av AWS Glue Engine .
Denna integration ger distinkta fördelar för de befintliga användarna av båda verktygen:
- Du har en centraliserad vy i AWS Glue Studio av det övergripande ETL-diagrammet, från början till slut
- Du kan interaktivt definiera ett recept, se värden, statistik och distribution på DataBrew-konsolen och sedan återanvända den testade och versionerade bearbetningslogiken i AWS Glue Studio visuella jobb
- Du kan orkestrera flera DataBrew-recept i ett AWS Glue ETL-jobb eller till och med flera jobb med AWS Glue-arbetsflöden
- DataBrew-recept kan nu använda AWS Limjobb-funktioner som bokmärken för inkrementell databearbetning, automatiska försök, automatisk skalning eller gruppering av små filer för större effektivitet
Lösningsöversikt
I vårt fiktiva användningsfall är kravet att rensa upp en syntetisk datauppsättning för medicinska påståenden som skapats för det här inlägget, som har några datakvalitetsproblem introducerade avsiktligt för att demonstrera DataBrew-funktionerna vid databeredning. Sedan matas anspråksdata in i katalogen (så att den är synlig för analytiker), efter att den berikats med några relevanta detaljer om motsvarande medicinska leverantörer som kommer från en separat källa.
Lösningen består av ett AWS Glue Studio visuellt jobb som läser två CSV-filer med anspråk respektive leverantörer. Jobbet tillämpar ett recept av det första för att lösa kvalitetsproblemen, välja kolumner från det andra, slå samman båda datamängderna och slutligen lagra resultatet på Amazon enkel lagringstjänst (Amazon S3), skapa en tabell i katalogen så att utdata kan användas av andra verktyg som Amazonas Athena.
Skapa ett DataBrew-recept
Börja med att registrera datalagret för skadefilen. Detta gör att du kan bygga receptet i dess interaktiva redigerare med hjälp av faktiska data så att du kan utvärdera resultatet av transformationerna när du definierar dem.
- Ladda ner CSV-filen för anspråk via följande länk: alabama_claims_data_Jun2023.csv.
- Välj på DataBrew-konsolen dataset i navigeringsfönstret och välj sedan Anslut ny dataset.
- Välj alternativet Filuppladdning.
- För Datasetnamn, stiga på
Alabama claims. - För Välj en fil att ladda upp, välj filen du just laddade ner till din dator.
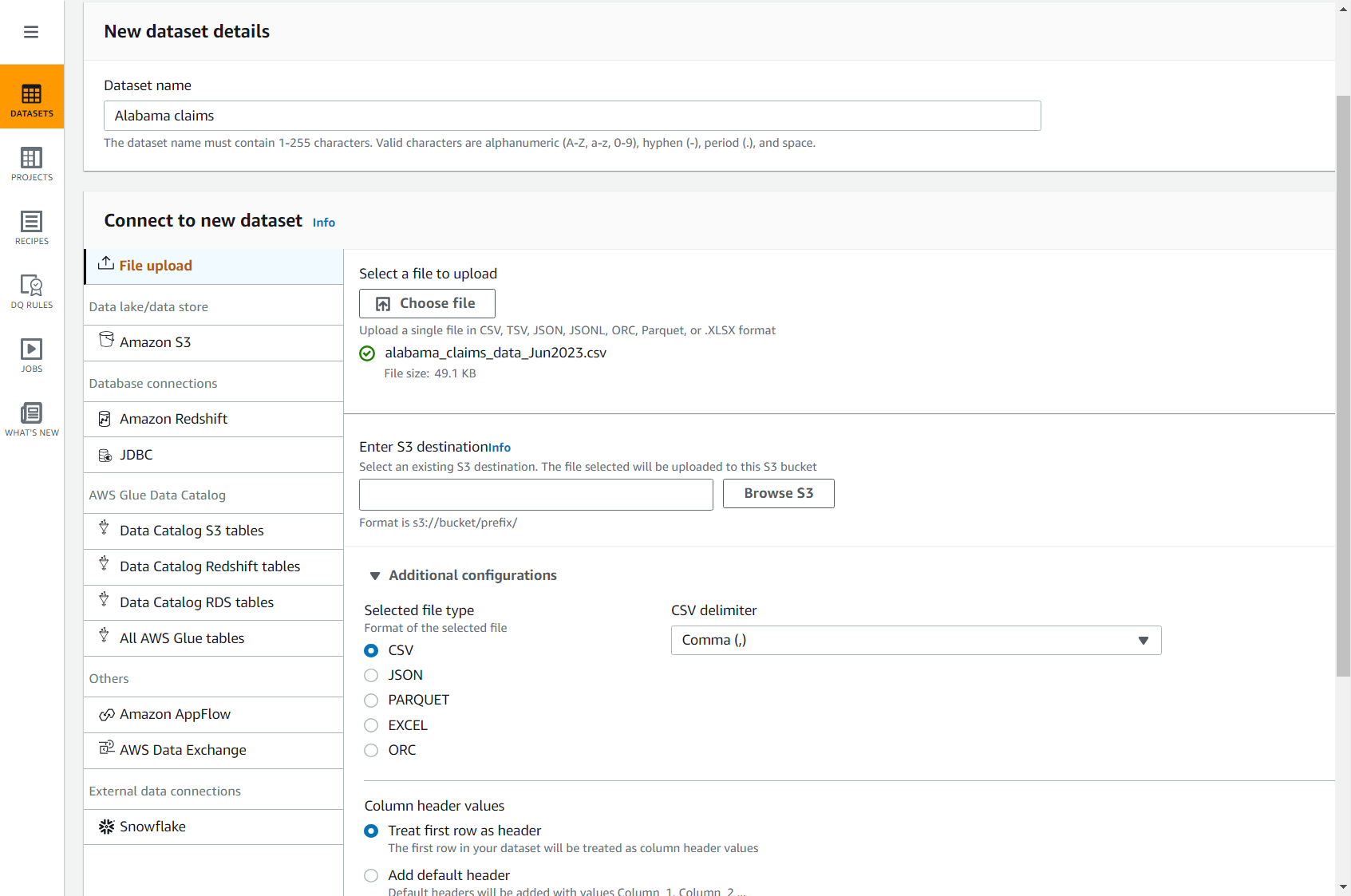
- För Ange S3 destination, ange eller bläddra till en hink i ditt konto och din region.
- Lämna resten av alternativen som standard (CSV separerad med kommatecken och med rubrik) och slutför skapandet av datamängden.
- Välja Projekt i navigeringsfönstret och välj sedan Skapa projekt.
- För Projektnamn, namnge det
ClaimsCleanup. - Enligt Receptdetaljer, För Bifogat receptväljer Skapa nytt recept, namnge det
ClaimsCleanup-recipeoch väljAlabama claimsdatauppsättning du just skapade.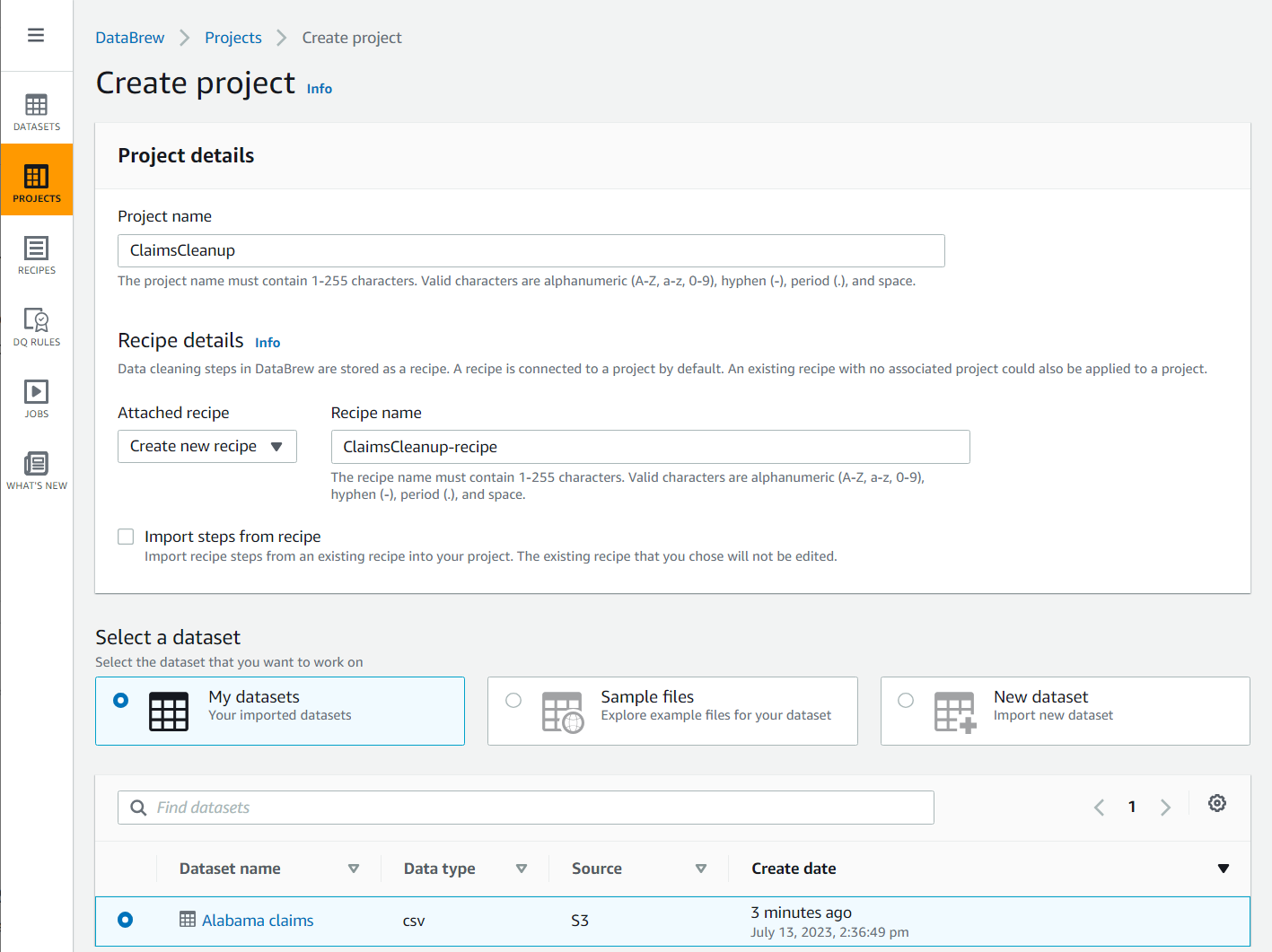
- Välj en roll lämplig för DataBrew eller skapa en ny och slutför projektskapandet.
Detta kommer att skapa en session med en konfigurerbar delmängd av data. När den har initierat sessionen kan du märka att några av cellerna har ogiltiga eller saknade värden.
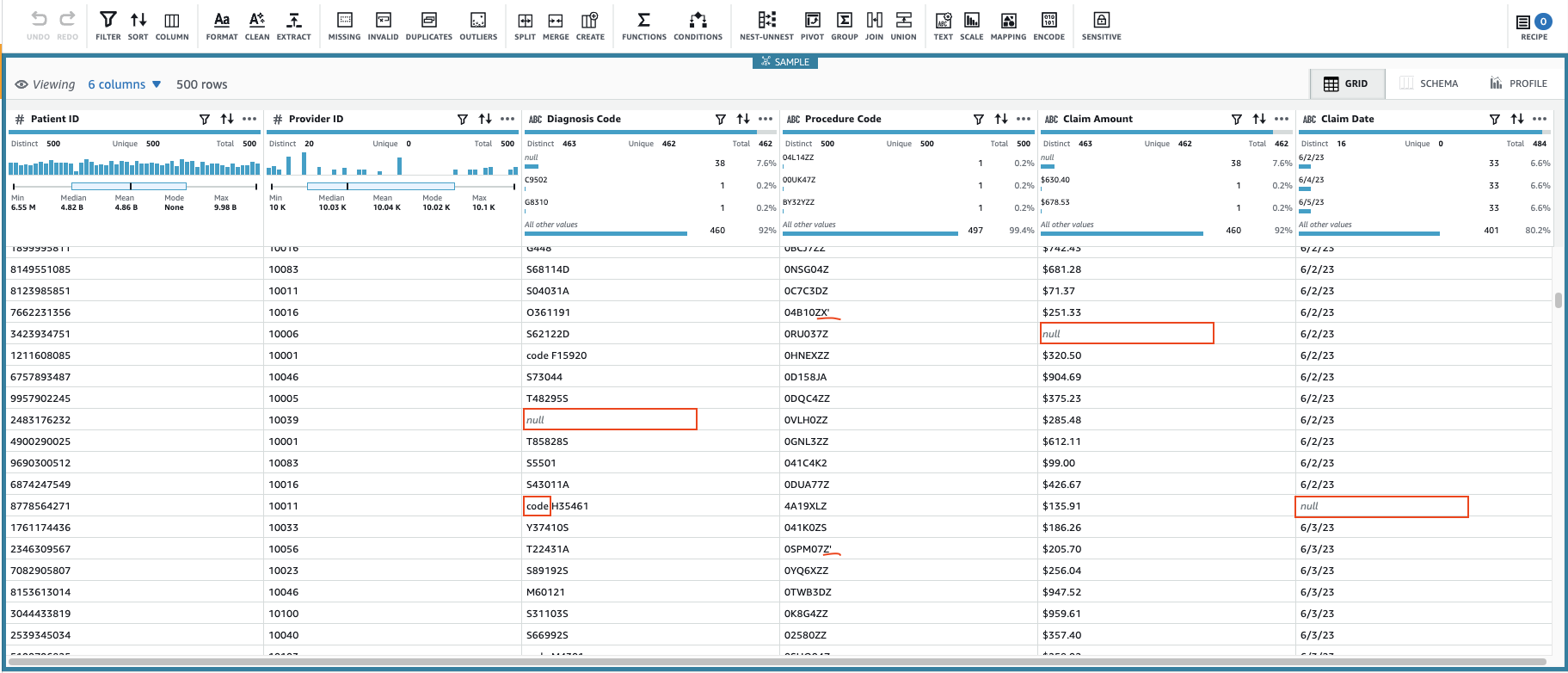
Förutom de saknade värdena i kolumnerna Diagnoskod, Anspråksbeloppoch Anspråksdatum, vissa värden i data har några extra tecken: Diagnoskod värden föregås ibland med "kod" (mellanslag ingår), och Procedurkod värden följs ibland av enstaka citattecken.
Anspråksbelopp värden kommer sannolikt att användas för vissa beräkningar, så konvertera till tal, och Gör anspråk på data bör konverteras till datumtyp.
Nu när vi identifierat datakvalitetsproblemen att ta itu med måste vi bestämma hur vi ska hantera varje fall.
Det finns flera sätt att lägga till receptsteg, inklusive att använda kolumnkontextmenyn, verktygsfältet högst upp eller från receptsammanfattningen. Med den sista metoden kan du söka efter den angivna stegtypen för att replikera receptet som skapades i det här inlägget.
Anspråksbelopp är avgörande för detta användningsfall, och beslutet är att ta bort sådana rader.
- Lägg till steget Ta bort saknade värden.
- För Källkolumnenväljer Anspråksbelopp.
- Lämna standardåtgärden Ta bort rader med saknade värden Och välj Ansök att spara den.
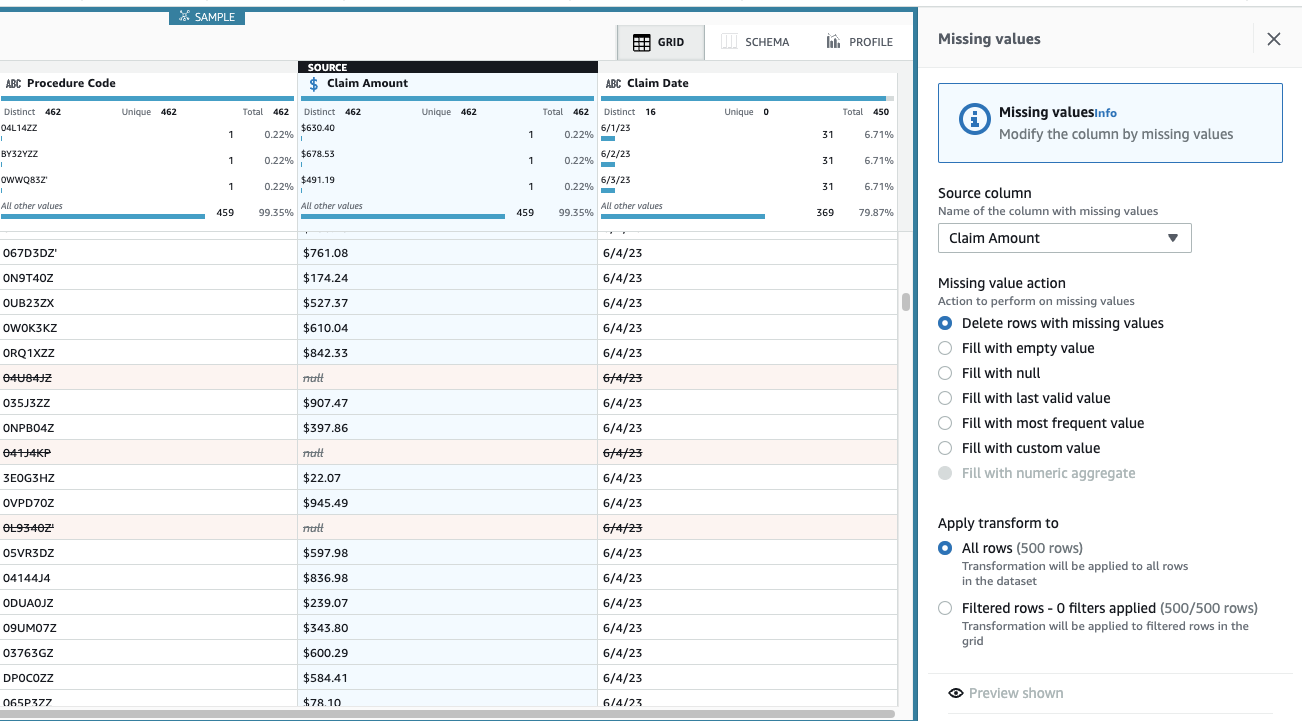
Vyn är nu uppdaterad för att återspegla stegapplikationen och raderna med saknade belopp finns inte längre där.
Diagnoskod kan vara tom så detta accepteras, men i fallet med Anspråksdatum, vi vill ha en rimlig uppskattning. Raderna i data är sorterade i kronologisk ordning, så att du kan tillskriva saknade datum med hjälp av det giltiga värdet för förhandsvisningar från föregående rader. Om man antar att varje dag har anspråk, skulle det största felet vara att tilldela den till förhandsgranskningsdagen om det var det första anspråket den dagen som saknade datumet; i illustrationssyfte, låt oss betrakta det potentiella felet som acceptabelt.
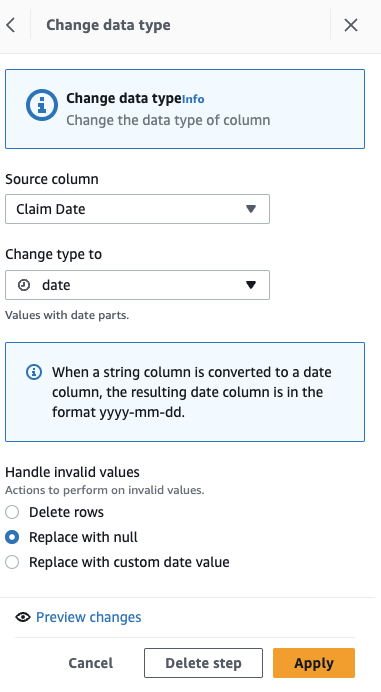
Konvertera först kolumnen från sträng till datumtyp.
- Lägg till steget Ändra typ.
- Välja Anspråksdatum som kolumnen och datum som typ och välj sedan Ansök.
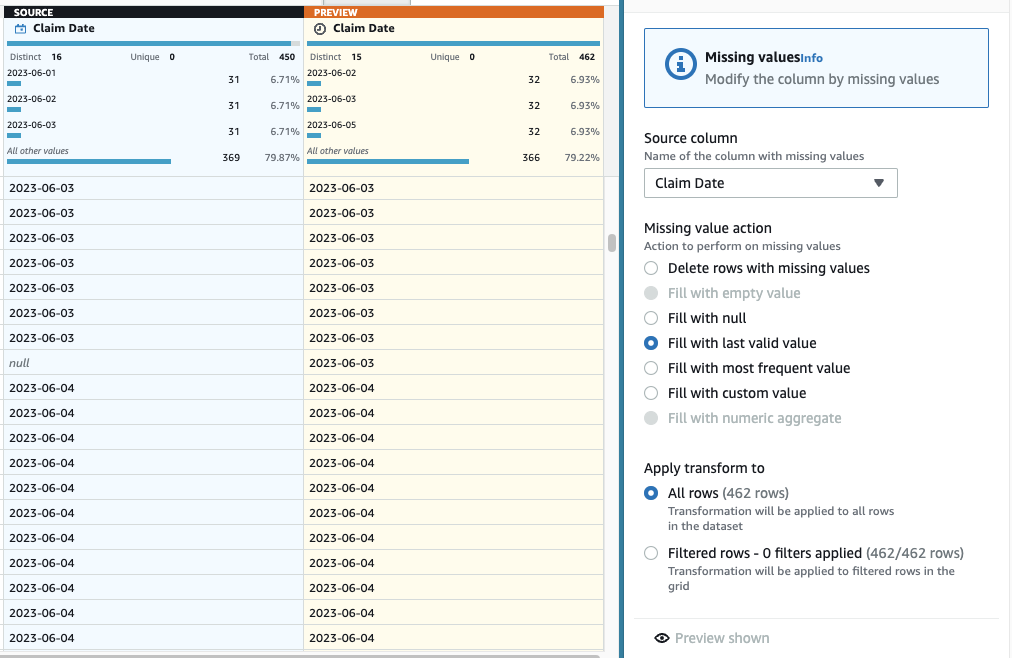
- Lägg nu till steget för att göra tillskrivningen av saknade datum Fyll i eller tillskriv saknade värden.
- Välj Fyll med senaste giltiga värde som åtgärd och välj Anspråksdatum som källa.
- Välja Förhandsgranska ändringar för att validera det och välj sedan Ansök för att spara steget.
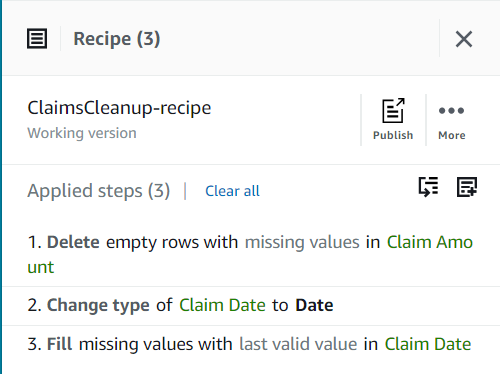
Hittills bör ditt recept ha tre steg, som visas i följande skärmdump.
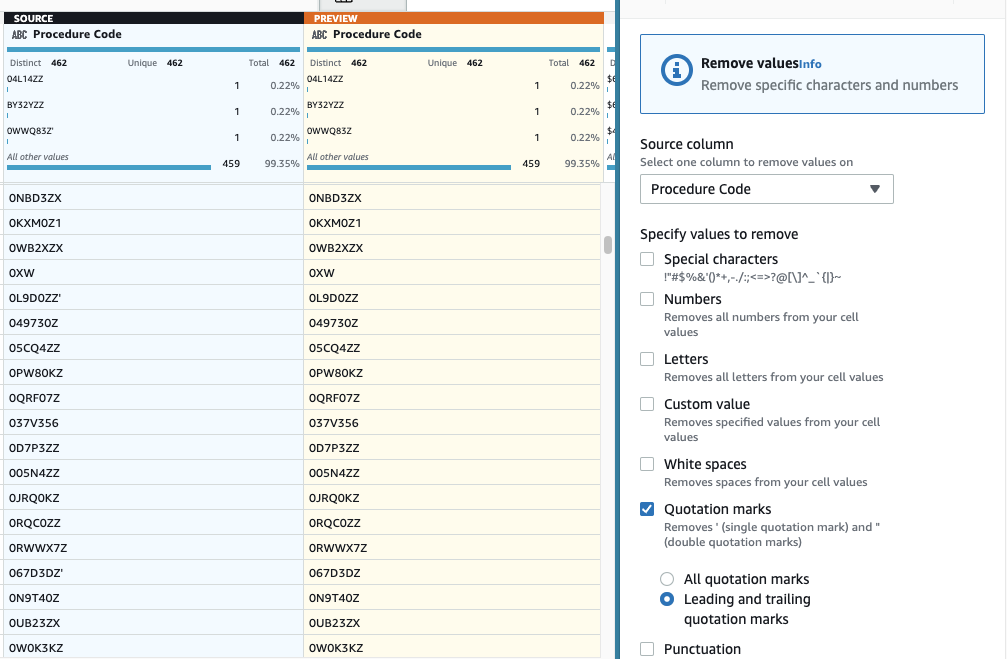
- Lägg sedan till steget Ta bort citattecken.
- Välj Procedurkod kolumn och välj Ledande och efterföljande citattecken.
- Förhandsgranska för att verifiera att det har önskad effekt och tillämpa det nya steget.
- Lägg till steget Ta bort specialtecken.
- Välj Anspråksbelopp kolumn och för att vara mer specifik, välj Anpassade specialtecken och skriv in
$för Ange anpassade specialtecken.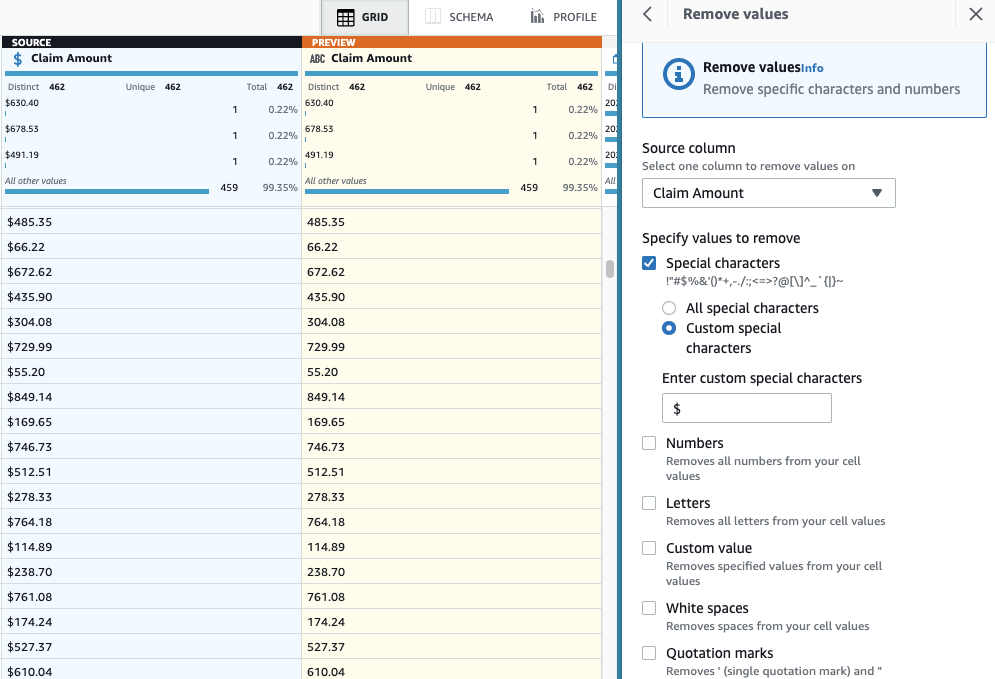
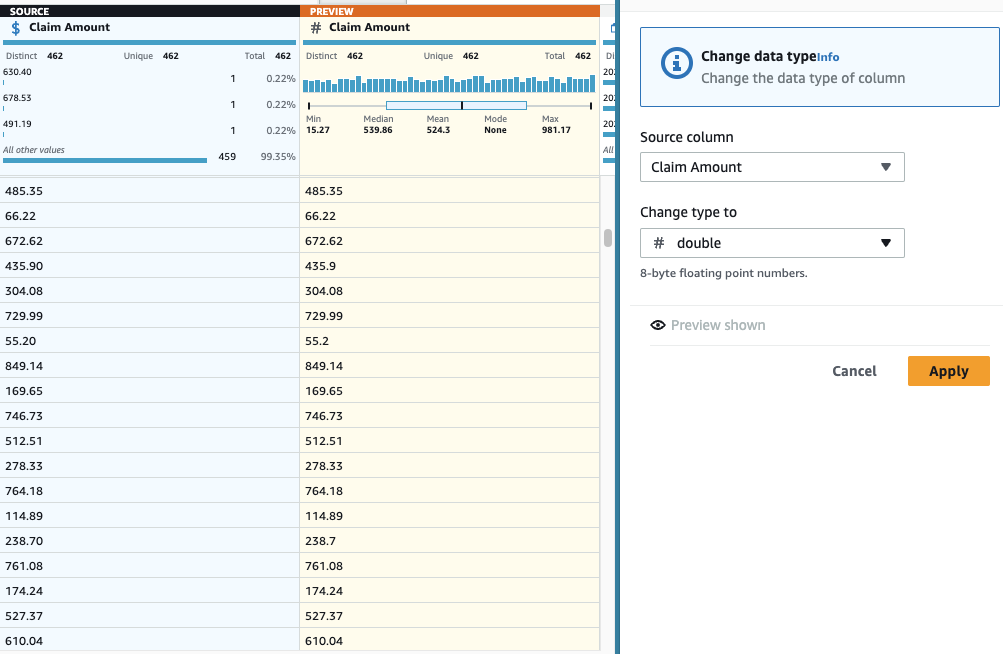
- Lägg till Ändra typ kliva på kolumnen Anspråksbelopp Och välj dubbla som typen.
- Som sista steg, för att ta bort det överflödiga prefixet "kod", lägg till en Byt ut värde eller mönster steg.
- Välj kolumnen DiagnoskodOch för Ange anpassat värde, stiga på
code(med ett mellanslag i slutet).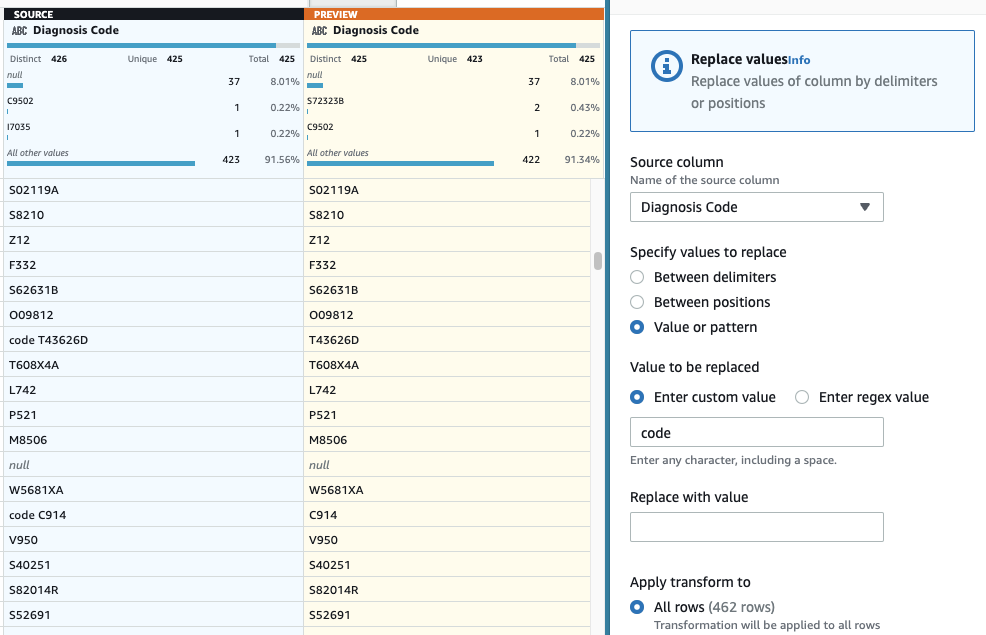
Nu när du har åtgärdat alla datakvalitetsproblem som identifierats på provet, publicera projektet som ett recept.
- Välja Publicera i Receptet skriv in en valfri beskrivning och slutför publikationen.
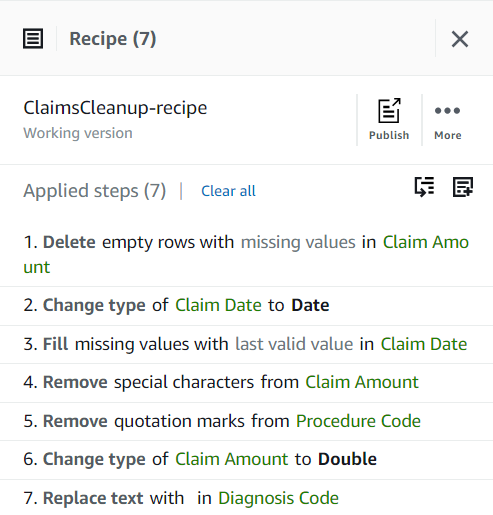
Varje gång du publicerar skapas en annan version av receptet. Senare kommer du att kunna välja vilken version av receptet du ska använda.
Skapa ett visuellt ETL-jobb i AWS Glue Studio
Därefter skapar du jobbet som använder receptet. Slutför följande steg:
- Välj på AWS Glue Studio-konsolen Visuell ETL i navigeringsfönstret.
- Välja Visual med en tom duk och skapa det visuella jobbet.
- Överst i jobbet byter du ut "Untitled job" med ett valfritt namn.
- På jobb~~POS=TRUNC Detaljer fliken, ange en roll som jobbet ska använda.
Detta måste vara en AWS identitets- och åtkomsthantering (JAG ÄR) roll lämplig för AWS Glue med behörigheter till Amazon S3 och AWS Glue Data Catalog. Observera att rollen som tidigare användes för DataBrew inte är användbar för körningsjobb, så den kommer inte att listas på IAM-roll rullgardinsmenyn här.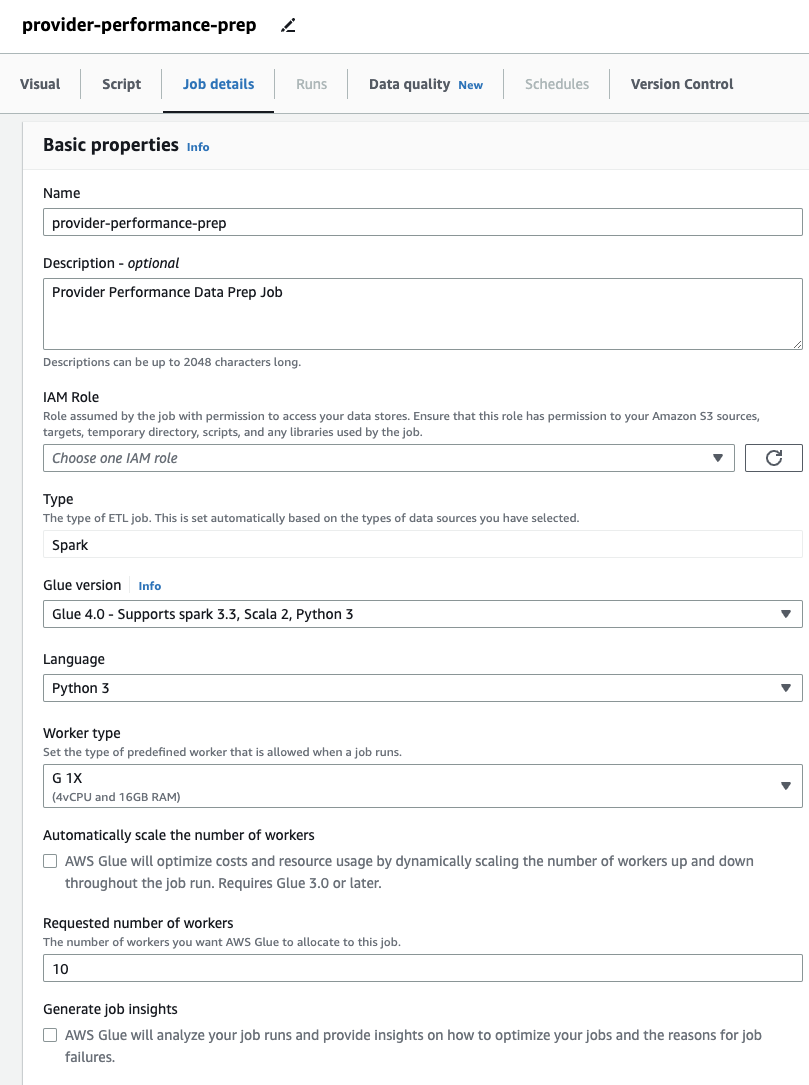
Om du bara använt DataBrew-jobb tidigare, lägg märke till att i AWS Glue Studio kan du välja prestanda- och kostnadsinställningar, inklusive arbetarstorlek, automatisk skalning och Flexibelt utförande, samt använda den senaste AWS Glue 4.0-körtiden och dra nytta av de betydande prestandaförbättringar det ger. För det här jobbet kan du använda standardinställningarna, men minska det begärda antalet anställda i sparsamhetens intresse. För det här exemplet kommer två arbetare att göra. - På Visuell lägg till en S3-källa och namnge den
Providers. - För S3 URL, stiga på
s3://awsglue-datasets/examples/medicare/Medicare_Hospital_Provider.csv.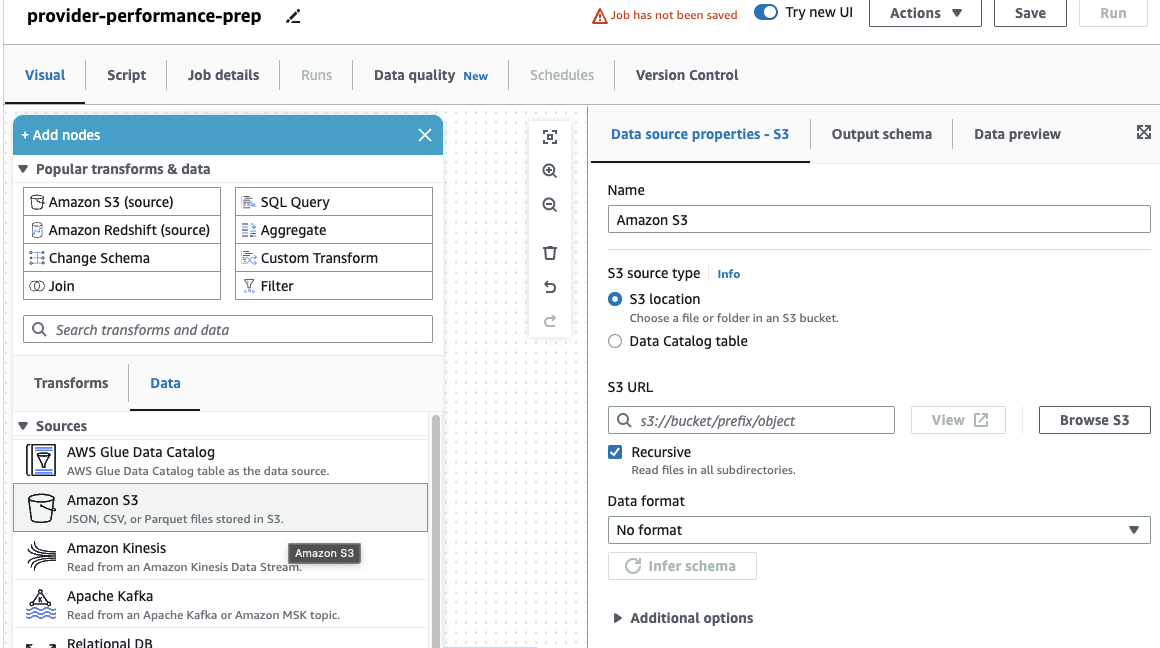
- Välj format som CSV Och välj Härleda schema.
Nu är schemat listat på Utgångsschema fliken med hjälp av filhuvudet.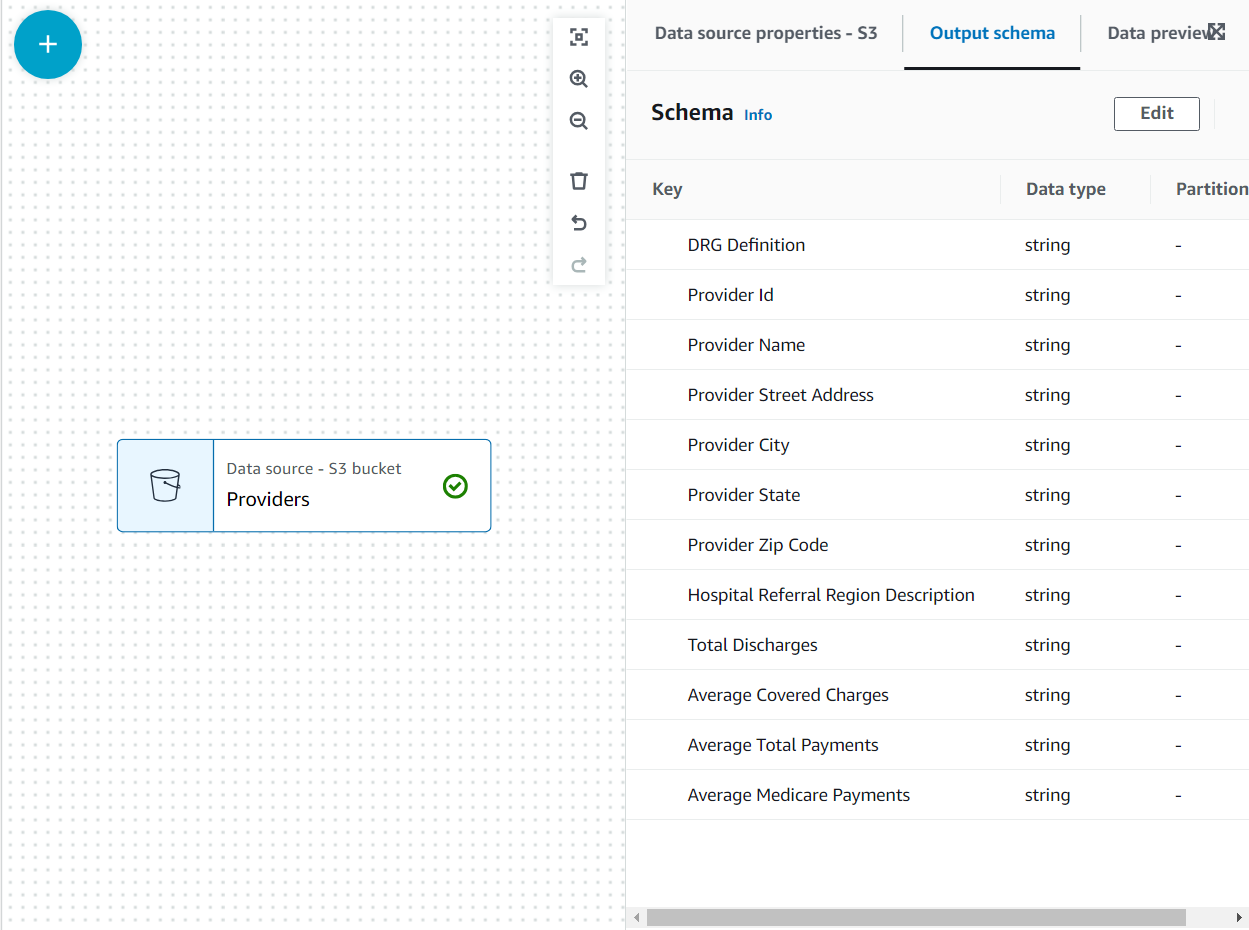
I det här användningsfallet är beslutet att inte alla kolumner i leverantörens datauppsättning behövs, så vi kan kassera resten.
- Med leverantörer nod vald, lägg till en Släpp fält transform (om du inte valde den överordnade noden, kommer den inte att ha någon; i så fall tilldela nodföräldern manuellt).
- Välj alla fält efter Leverantörens postnummer.
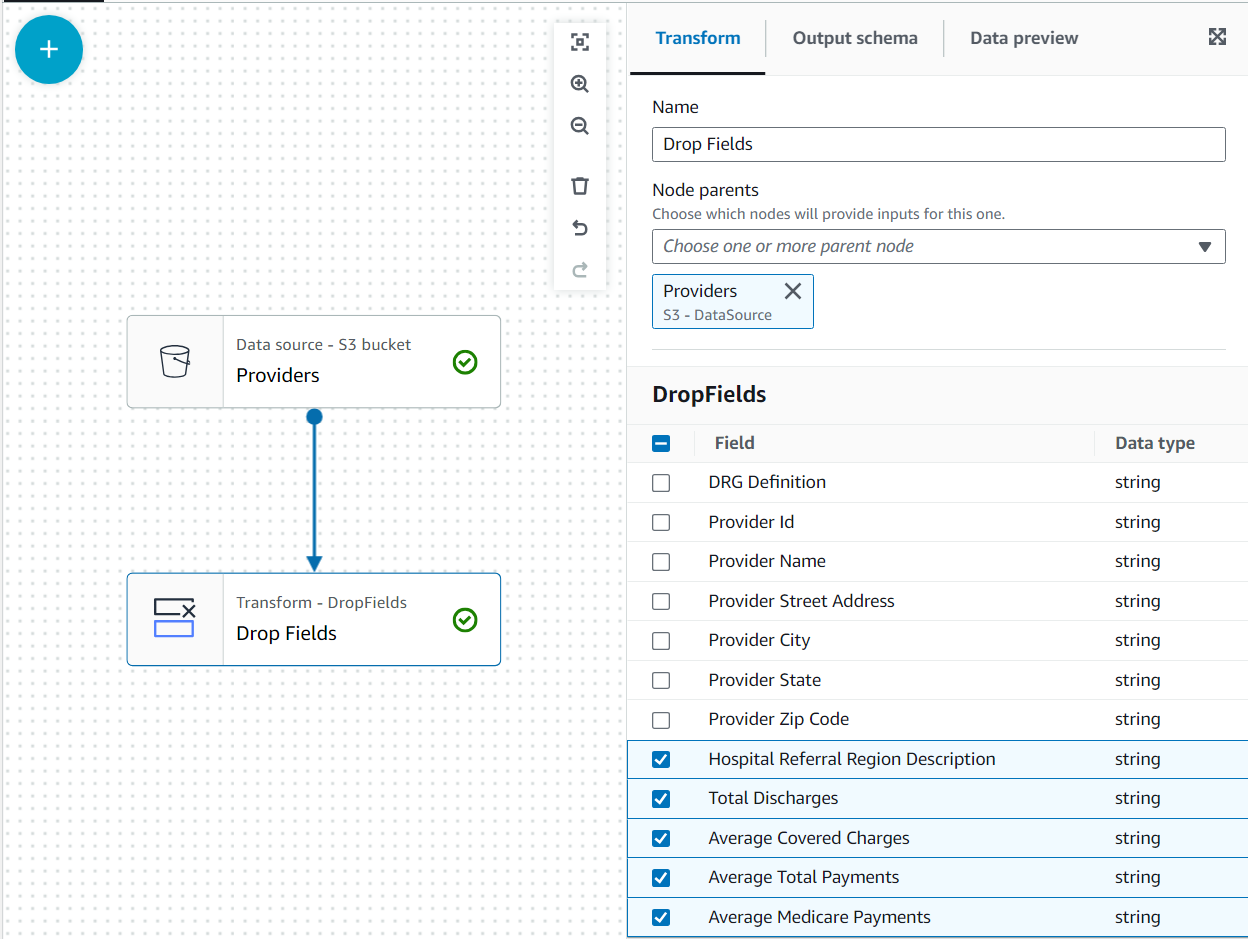
Senare kommer dessa uppgifter att förenas av anspråken för staten Alabama genom att använda leverantören; den andra datamängden har dock inte det angivna tillståndet. Vi kan använda kunskap om data för att optimera sammanfogningen genom att filtrera den data vi verkligen behöver.
- Lägg till Filter förvandla som ett barn av Släpp fält.
- Namnge det
Alabama providersoch lägg till ett villkor som staten måste matchaAL.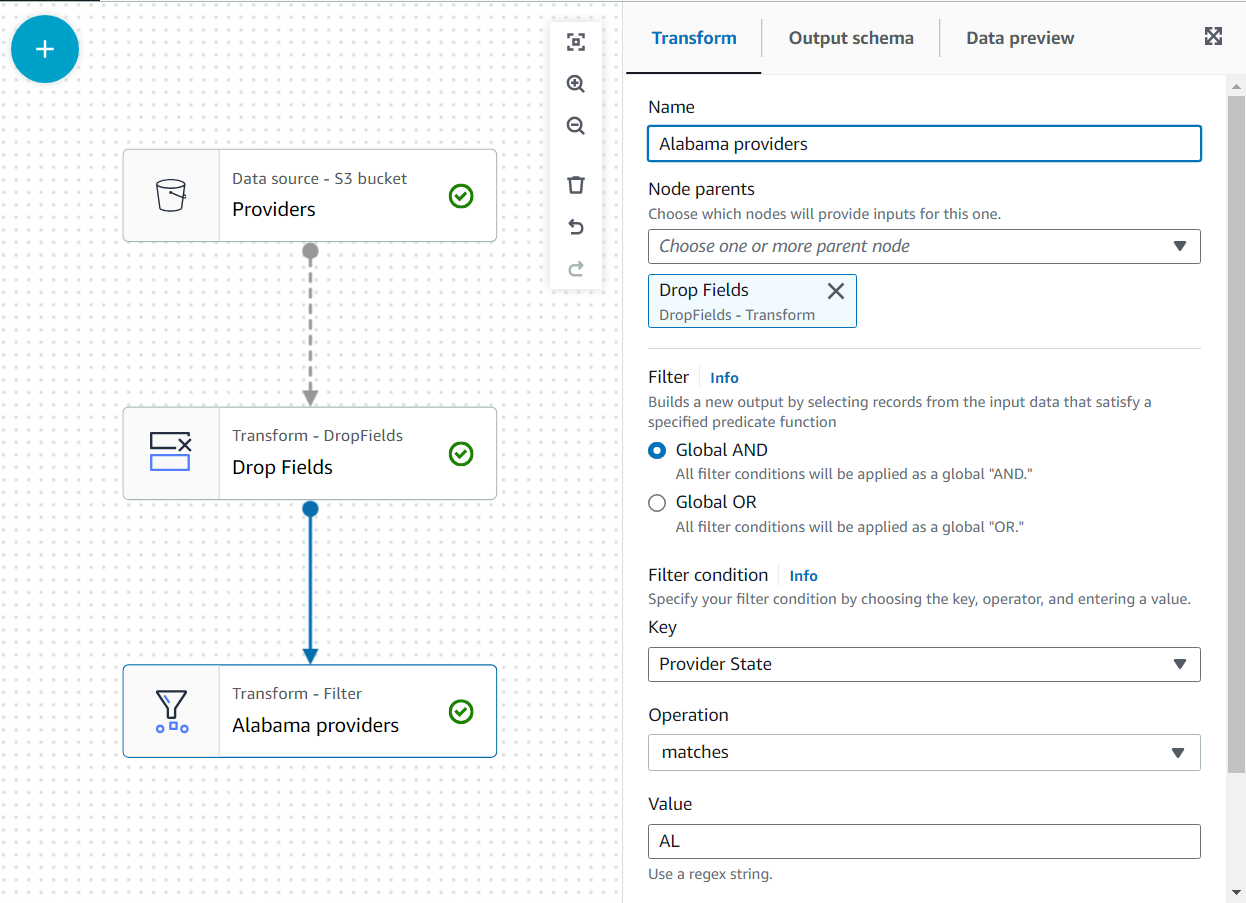
- Lägg till den andra källan (en ny S3-källa) och namnge den
Alabama claims. - För att gå in i S3 URL, öppna DataBrew på en separat webbläsarflik, välj Dataset i navigeringsfönstret och kopiera platsen som visas i tabellen i tabellen för Alabama hävdar (kopiera texten som börjar med s3://, inte http-länken som är associerad). Sedan tillbaka på det visuella jobbet, klistra in det som S3 URL; om det är korrekt ser du i Utgångsschema flik de listade datafälten.
- Välj CSV-format och härleda schemat som du gjorde med den andra källan.
- Som barn till denna källa, sök i Lägg till noder meny för
recipeOch välj Databeredningsrecept.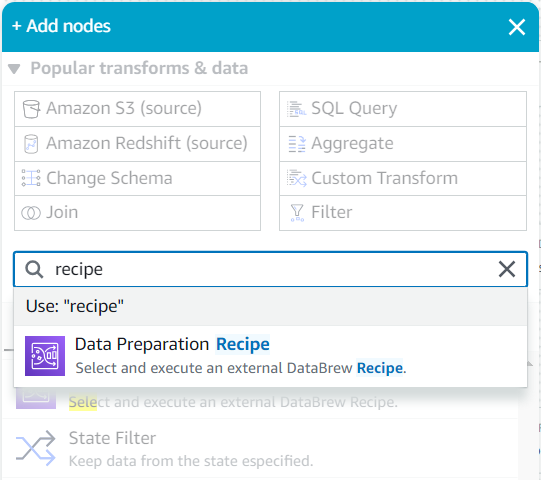
- I den nya nodens egenskaper, ge den namnet
Claim cleanup recipeoch välj receptet och versionen du publicerat tidigare. - Du kan granska receptstegen här och använda länken till DataBrew för att göra ändringar om det behövs.
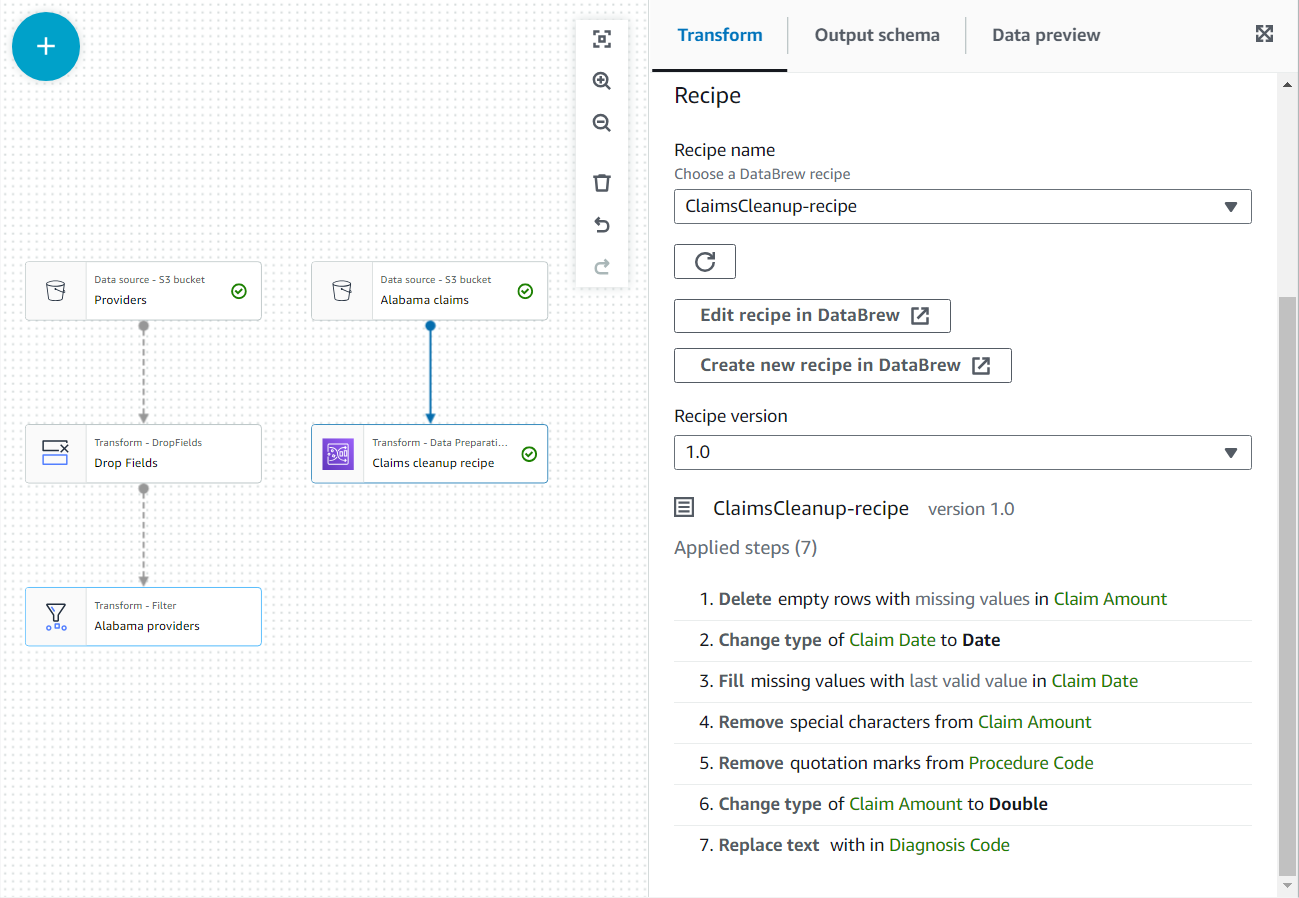
- Lägg till Ansluta sig nod och välj båda Alabama-leverantörer och Gör anspråk på rengöringsrecept som förälder.
- Lägg till ett anslutningsvillkor som motsvarar leverantörs-ID från båda källorna.
- Som det sista steget lägger du till en S3-nod som mål (notera att den första som visas när du söker är källan; se till att du väljer versionen som är listad som mål).
- I nodkonfigurationen, lämna standardformatet JSON och ange en S3-URL som jobbrollen har behörighet att skriva på.
Gör dessutom datautgången tillgänglig som en tabell i katalogen.
- I Alternativ för uppdatering av datakatalog väljer du det andra alternativet Skapa en tabell i datakatalogen och vid efterföljande körningar, uppdatera schemat och lägg till nya partitioner, välj sedan en databas där du har behörighet att skapa tabeller.
- Tilldela
alabama_claimssom namnet och välj Anspråksdatum som partitionsnyckel (detta är i illustrationssyfte; en liten tabell som denna behöver egentligen inte partitioner om ytterligare data inte kommer att läggas till senare).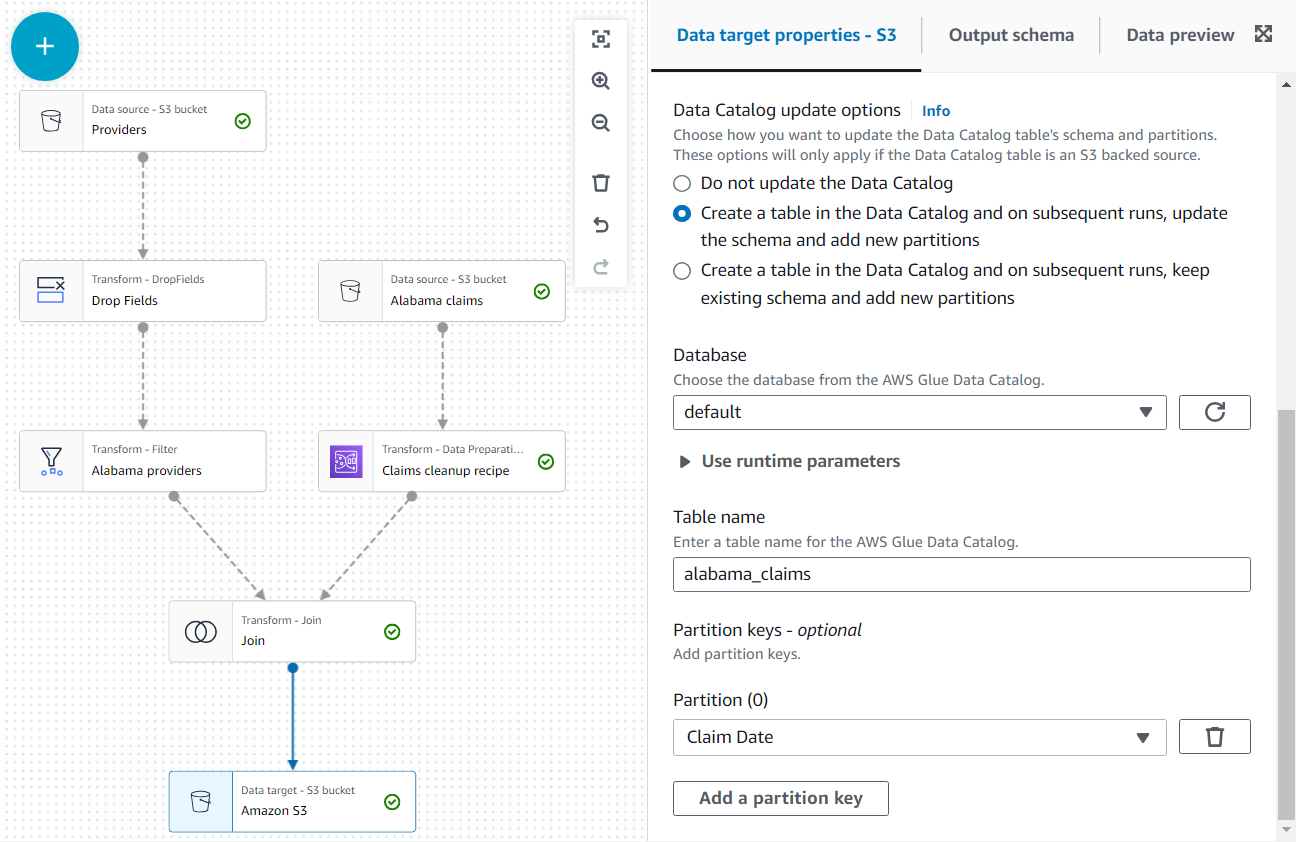
- Nu kan du spara och köra jobbet.
- På Körs fliken kan du hålla reda på processen och se detaljerad jobbstatistik med hjälp av länken jobb-ID.
Jobbet bör ta några minuter att slutföra.
- När jobbet är klart, navigera till Athena-konsolen.
- Sök efter tabellen
alabama_claimsi databasen du valde och välj med hjälp av snabbmenyn Förhandsgranskningstabell, som kommer att köra en enkel SELECT * SQL-sats på tabellen.
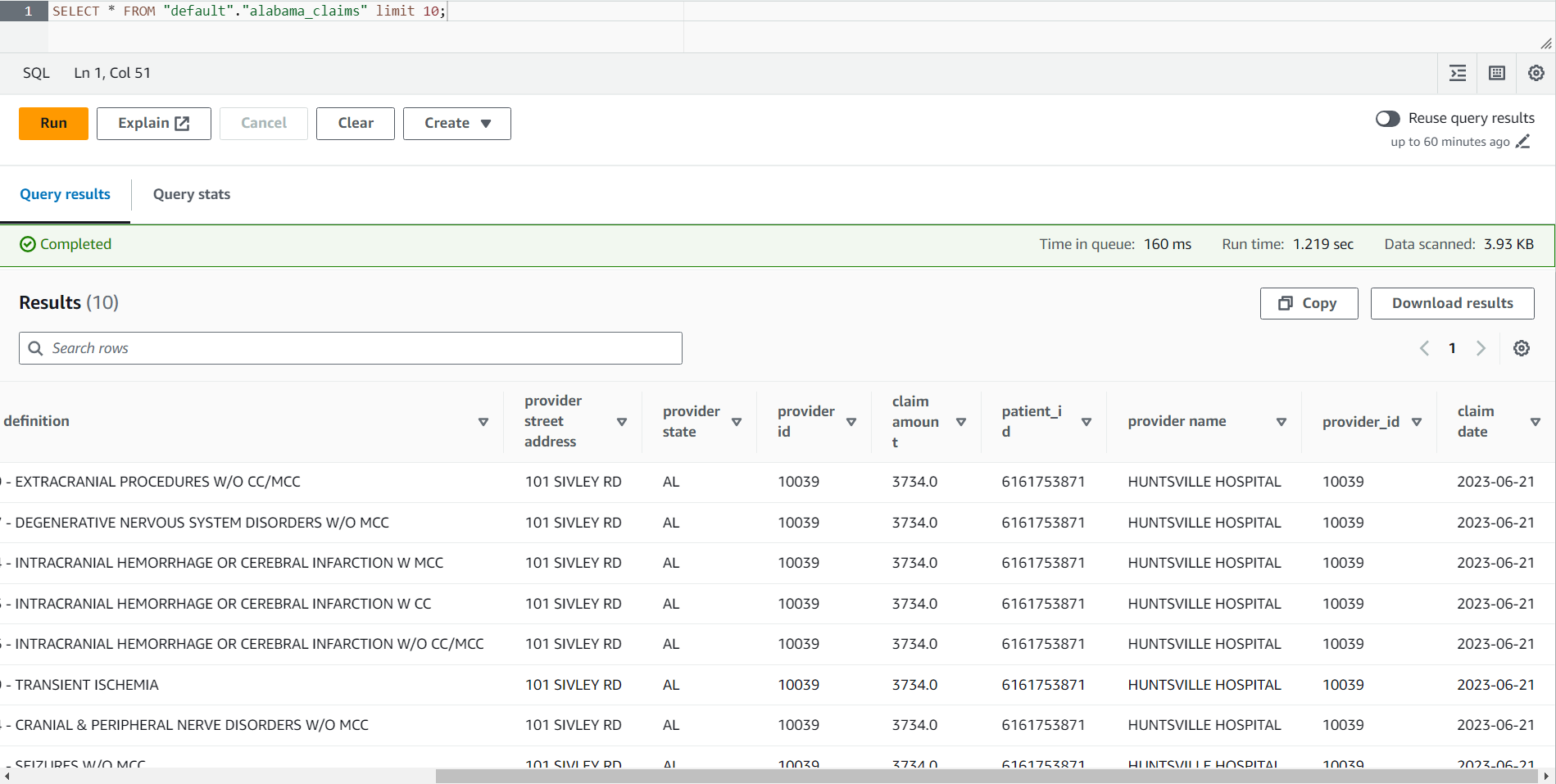
Du kan se i resultatet av jobbet att data rensades av DataBrew-receptet och berikades av AWS Glue Studio-anslutningen.
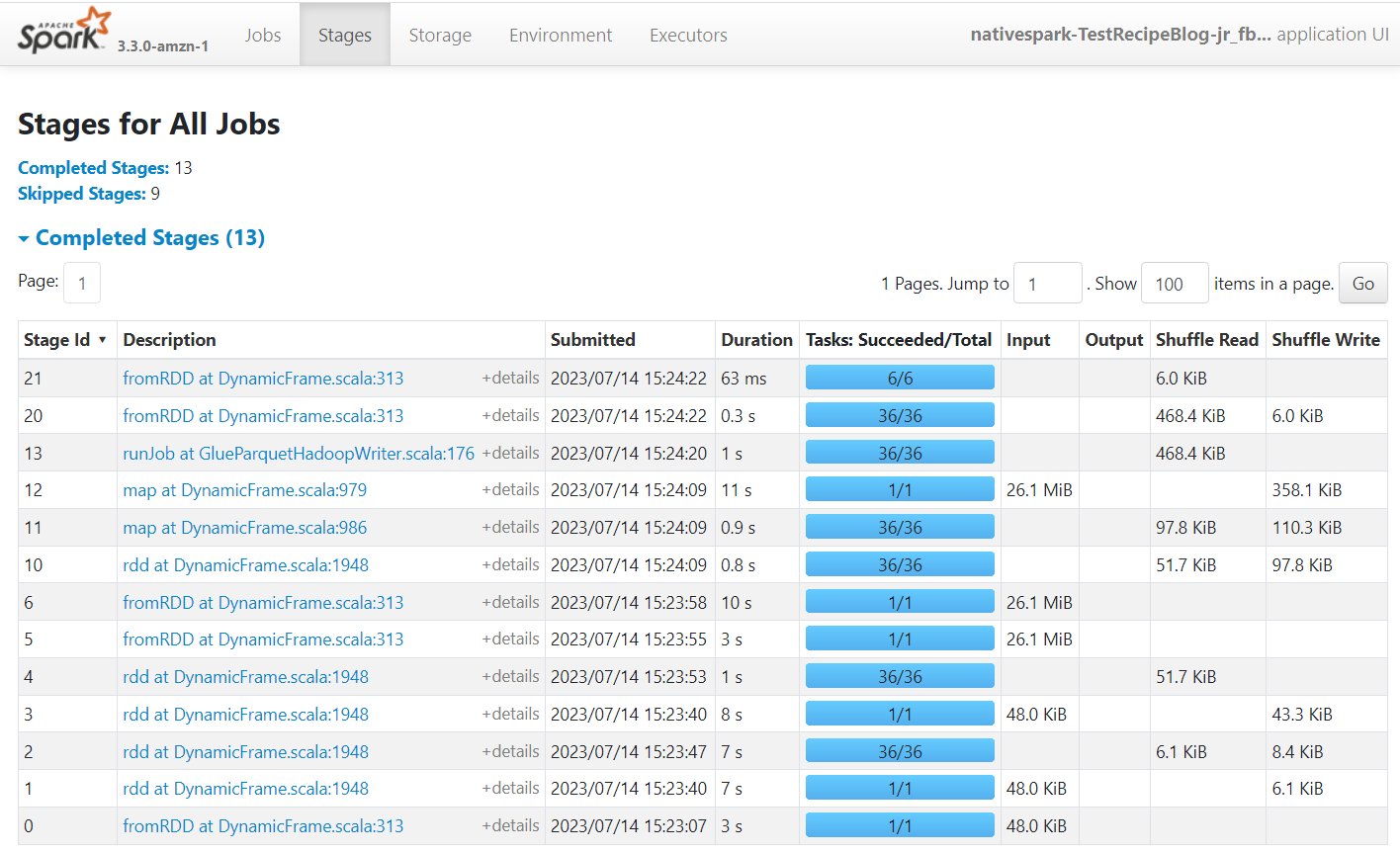
Apache Spark är motorn som kör jobben som skapats på AWS Glue Studio. Genom att använda Spark-gränssnittet i händelseloggarna som det producerar kan du se insikter om jobbplanen och körningen, vilket kan hjälpa dig att förstå hur ditt jobb presterar och potentiella flaskhalsar i prestanda. Till exempel, för det här jobbet på en stor datamängd, kan du använda den för att jämföra effekten av att filtrera explicit leverantörens tillstånd innan du gör kopplingen, eller identifiera om du kan dra nytta av att lägga till en autobalansomvandling för att förbättra parallelliteten.
Som standard lagrar jobbet Apache Spark-händelseloggarna under sökvägen s3://aws-glue-assets-<your account id>-<your region name>/sparkHistoryLogs/. För att se jobben måste du installera en historikserver med hjälp av en av de tillgängliga metoderna.
Städa upp
Om du inte längre behöver den här lösningen kan du ta bort filerna som skapats på Amazon S3, tabellen skapad av jobbet, DataBrew-receptet och AWS Glue-jobbet.
Slutsats
I det här inlägget visade vi hur du kan använda AWS DataBrew för att bygga ett recept med den medföljande interaktiva redigeraren och sedan använda det publicerade receptet som en del av ett visuellt ETL-jobb i AWS Glue Studio. Vi inkluderade några exempel på vanliga uppgifter som krävs när man gör dataförberedelser och matar in data i AWS Glue Catalog-tabeller.
Det här exemplet använde ett enda recept i det visuella jobbet, men det är möjligt att använda flera recept vid olika delar av ETL-processen, samt att återanvända samma recept på flera jobb.
Dessa AWS Glue-lösningar låter dig effektivt skapa avancerade ETL-pipelines som är enkla att bygga och underhålla, allt utan att skriva någon kod. Du kan börja skapa lösningar som kombinerar båda verktygen idag.
Om författarna
 Mikhail Smirnov är Sr. Software Dev Engineer i AWS Glue-teamet och en del av AWS Glue DataBrews utvecklingsteam. Utanför jobbet är hans intressen bland annat att lära sig spela gitarr och resa med familjen.
Mikhail Smirnov är Sr. Software Dev Engineer i AWS Glue-teamet och en del av AWS Glue DataBrews utvecklingsteam. Utanför jobbet är hans intressen bland annat att lära sig spela gitarr och resa med familjen.
 Gonzalo herreros är Sr. Big Data Architect i AWS Glue-teamet. Baserad i Dublin, Irland, hjälper han kunder att lyckas med big data-lösningar baserade på AWS Glue. På fritiden tycker han om brädspel och cykling.
Gonzalo herreros är Sr. Big Data Architect i AWS Glue-teamet. Baserad i Dublin, Irland, hjälper han kunder att lyckas med big data-lösningar baserade på AWS Glue. På fritiden tycker han om brädspel och cykling.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Fordon / elbilar, Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- BlockOffsets. Modernisera miljökompensation ägande. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/use-aws-glue-databrew-recipes-in-your-aws-glue-studio-visual-etl-jobs/
- : har
- :är
- :inte
- $UPP
- 10
- 100
- 12
- 15%
- 20
- 200
- 22
- 26
- 28
- 500
- 7
- 8
- a
- Able
- Om oss
- godtagbart
- accepterade
- tillgång
- Konto
- Handling
- faktiska
- lägga till
- lagt till
- tillsats
- Dessutom
- adress
- avancerat
- Efter
- Alabama
- Alla
- tillåter
- också
- amason
- Amazon Web Services
- mängder
- an
- analytiker
- och
- vilken som helst
- Apache
- Apache Spark
- Ansökan
- Ansök
- ÄR
- AS
- associerad
- At
- Författaren
- bil
- Automat
- tillgänglig
- AWS
- AWS-lim
- tillbaka
- baserat
- BE
- innan
- Där vi får lov att vara utan att konstant prestera,
- fördel
- Fördelarna
- Stor
- Stora data
- blank
- ombord
- Brädspel
- bokmärken
- båda
- Bringar
- webbläsare
- SLUTRESULTAT
- men
- by
- KAN
- kapacitet
- Vid
- katalog
- Celler
- centraliserad
- byta
- Förändringar
- tecken
- barn
- val
- Välja
- patentkrav
- hävdar
- koda
- Kolumn
- Kolonner
- kombinera
- kommande
- Gemensam
- jämföra
- fullborda
- komponenter
- dator
- tillstånd
- konfiguration
- Tänk
- består
- Konsol
- sammanhang
- konvertera
- konverterad
- korrekt
- Motsvarande
- Pris
- kunde
- skapa
- skapas
- Skapa
- skapande
- beställnings
- Kunder
- datum
- Förberedelse av data
- databehandling
- Datakvalitet
- Databas
- datauppsättningar
- Datum
- Datum
- dag
- behandla
- beslutar
- Beslutet
- Standard
- demonstrera
- beskrivning
- önskas
- detaljerad
- detaljer
- dev
- Utveckling
- utvecklingsteam
- DID
- olika
- distinkt
- fördelning
- do
- inte
- gör
- Dollar
- dubbla
- Drop
- Dublin
- varje
- lätt
- redaktör
- effekt
- effektivt
- möjliggör
- änden
- Motor
- ingenjör
- berikad
- berikande
- ange
- fel
- väsentlig
- Eter (ETH)
- utvärdera
- Även
- händelse
- Varje
- varje dag
- exempel
- exempel
- befintliga
- extra
- extrahera
- familj
- långt
- Funktioner
- få
- Fält
- Fil
- Filer
- fylla
- filtrera
- filtrering
- Slutligen
- Förnamn
- följt
- efter
- För
- format
- från
- ytterligare
- Games
- genereras
- Ge
- större
- Har
- he
- hjälpa
- hjälper
- här.
- hans
- historia
- Hur ser din drömresa ut
- How To
- Men
- html
- http
- HTTPS
- IAM
- ID
- identifierade
- identifiera
- Identitet
- if
- Inverkan
- förbättra
- förbättringar
- in
- innefattar
- ingår
- Inklusive
- indikerade
- ingång
- insikter
- installera
- exempel
- integrerade
- integrering
- interaktiva
- intresse
- intressen
- Gränssnitt
- in
- introducerade
- intuitiv
- irland
- problem
- IT
- DESS
- Jobb
- Lediga jobb
- delta
- fogade
- jpg
- json
- bara
- Ha kvar
- Nyckel
- kunskap
- Large
- större
- största
- Efternamn
- senare
- senaste
- inlärning
- Lämna
- tycka om
- sannolikt
- LINK
- Noterade
- läsa in
- läge
- Logiken
- längre
- bibehålla
- göra
- GÖR
- manuellt
- Match
- medicinsk
- Meny
- metod
- metoder
- Metrics
- minuter
- saknas
- Övervaka
- mer
- multipel
- måste
- namn
- Navigera
- Navigering
- Behöver
- behövs
- behov
- Nya
- Nej
- nod
- Lägga märke till..
- nu
- antal
- of
- on
- ONE
- endast
- öppet
- Optimera
- Alternativet
- Tillbehör
- or
- beställa
- Övriga
- vår
- produktion
- utanför
- över
- övergripande
- panelen
- del
- reservdelar till din klassiker
- bana
- prestanda
- utför
- tillstånd
- behörigheter
- Planen
- plato
- Platon Data Intelligence
- PlatonData
- Spela
- möjlig
- Inlägg
- potentiell
- beredning
- Förhandsvisning
- Smakprov
- process
- bearbetning
- producerar
- projektet
- egenskaper
- förutsatt
- leverantör
- leverantörer
- ger
- Offentliggörande
- publicera
- publicerade
- Syftet
- syfte
- kvalitet
- citat
- verkligen
- rimlig
- Receptet
- recept
- minska
- reflektera
- region
- registrera
- relevanta
- ta bort
- ersätta
- begärda
- Obligatorisk
- krav
- respektive
- REST
- resultera
- Resultat
- återanvända
- översyn
- Roll
- Körning
- kör
- Samma
- Save
- Skala
- skalning
- Sök
- Andra
- §
- se
- se
- vald
- separat
- Tjänster
- session
- in
- inställningar
- skall
- visade
- visas
- signera
- signifikant
- Enkelt
- enda
- Storlek
- Small
- So
- än så länge
- Mjukvara
- lösning
- Lösningar
- några
- Källa
- Källor
- Utrymme
- Gnista
- speciell
- specifik
- specificerade
- SQL
- starta
- Starta
- Ange
- .
- statistik
- Steg
- Steg
- förvaring
- lagra
- okomplicerad
- Sträng
- studio
- senare
- lyckas
- sådana
- lämplig
- SAMMANFATTNING
- säker
- syntetisk
- bord
- Ta
- Målet
- uppgifter
- grupp
- testade
- den där
- Smakämnen
- källan
- Staten
- Dem
- sedan
- Där.
- detta
- tre
- tid
- till
- i dag
- verktyg
- verktyg
- topp
- spår
- Förvandla
- Transformation
- transformationer
- Traveling
- två
- Typ
- ui
- under
- förstå
- Uppdatering
- uppdaterad
- URL
- användbar
- användning
- användningsfall
- Begagnade
- användare
- användningar
- med hjälp av
- BEKRÄFTA
- värde
- Värden
- verifiera
- version
- utsikt
- synlig
- vill
- var
- sätt
- we
- webb
- webbservice
- VÄL
- były
- när
- som
- kommer
- med
- utan
- Arbete
- arbetstagaren
- arbetare
- arbetsflöde
- skulle
- skriva
- skrivning
- dig
- Din
- zephyrnet
- Postnummer