Amazon EMR är glada att kunna tillkännage integration med Amazon Simple Storage Service (Amazon S3) Access Grants som förenklar Amazon S3-behörighetshantering och låter dig upprätthålla granulär åtkomst i stor skala. Med denna integration kan du skala jobbbaserad Amazon S3-åtkomst för Apache Spark-jobb över alla Amazon EMR-distributionsalternativ och genomdriva granulär Amazon S3-åtkomst för bättre säkerhetsställning.
I det här inlägget går vi igenom några olika scenarier för hur man använder Amazon S3 Access Grants. Innan vi börjar gå igenom Amazon EMR- och Amazon S3 Access Grants-integreringen kommer vi att konfigurera och konfigurera S3 Access Grants. Sedan använder vi AWS molnformation mall nedan för att skapa en Amazon EMR på Amazon Elastic Compute Cloud (Amazon EC2) Cluster, en EMR-serverlös applikation och två olika jobbroller.
Efter installationen kommer vi att köra några scenarier för hur du kan använda Amazon EMR med S3 Access Grants. Först kör vi ett batchjobb på EMR på Amazon EC2 för att importera CSV-data och konvertera till Parkett. För det andra kommer vi att använda Amazon EMR Studio med en interaktiv EMR Serverless-applikation för att analysera data. Slutligen kommer vi att visa hur du ställer in åtkomst över flera konton för Amazon S3 Access Grants. Många kunder använder olika konton i sin organisation och även utanför sin organisation för att dela data. Amazon S3 Access Grants gör det enkelt att ge åtkomst över flera konton till dina data även när du filtrerar efter olika prefix.
Förutom det här inlägget kan du lära dig mer om Amazon S3 Access Grants från Skala dataåtkomst med Amazon S3 Access Grants.
Förutsättningar
Innan du startar AWS CloudFormation-stacken, se till att du har följande:
- Ett AWS-konto som ger åtkomst till AWS-tjänster
- Den senaste versionen av AWS Command Line Interface (AWS CLI)
- En AWS Identity and Access Management (AWS IAM) användare med en åtkomstnyckel och hemlig nyckel för att konfigurera AWS CLI, och behörigheter att skapa en IAM-roll, IAM-policyer och stackar i AWS CloudFormation
- Ett andra AWS-konto om du vill testa funktionen för flera konton
genomgång
Skapa resurser med AWS CloudFormation
För att kunna använda Amazon S3 Access Grants behöver du ett kluster med Amazon EMR 6.15.0 eller senare. För mer information, se dokumentationen för att använda Amazon S3 Access Grants med en Amazon EMR-kluster, En Amazon EMR på EKS-kluster, Och en Amazon EMR Serverlös applikation. I detta inläggs syfte antar vi att du har två olika typer av dataåtkomstanvändare i din organisation – analytiker med läs- och skrivåtkomst till data i hinken och affärsanalytiker med skrivskyddad åtkomst. Vi kommer att använda två olika AWS IAM-roller, men du kan också koppla din egen identitetsleverantör direkt till IAM Identity Center om du vill.
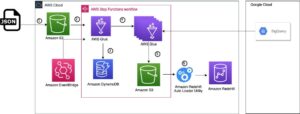
Här är arkitekturen för denna första del. AWS CloudFormation-stacken skapar följande AWS-resurser:
- En virtuell privat molnstack (VPC) med privata och offentliga undernät att använda med EMR Studio, rutttabeller och NAT-gateway (Network Address Translation).
- En Amazon S3-hink för EMR-artefakter som loggfiler, Spark-kod och Jupyter-anteckningsböcker.
- En Amazon S3-hink med exempeldata att använda med S3 Access Grants.
- Ett Amazon EMR-kluster konfigurerat att använda runtime roller och S3 Access Grants.
- En Amazon EMR-serverlös applikation konfigurerad för att använda S3 Access Grants.
- En Amazon EMR Studio där användare kan logga in och skapa arbetsyta anteckningsböcker med EMR Serverless-applikationen.
- Två AWS IAM-roller vi kommer att använda för våra EMR-jobbkörningar: en för Amazon EC2 med skrivåtkomst och en annan för serverlös med läsbehörighet.
- En AWS IAM-roll som kommer att användas av S3 Access Grants för att få åtkomst till bucket-data (d.v.s. rollen som ska användas när du registrerar en plats med S3 Access Grants. S3 Access Grants använder den här rollen för att skapa tillfälliga referenser).
Gör så här för att komma igång:
- Välj Launch Stack:

- Acceptera standardinställningarna och välj Jag medger att denna mall kan skapa IAM-resurser.
AWS CloudFormation-stacken tar cirka 10–15 minuter att slutföra. När stacken är klar, gå till fliken utgångar där du hittar information som behövs för följande steg.
Skapa Amazon S3 Access Grants-resurser
Först kommer vi att skapa en Amazon S3 Access Grants-resurser på vårt konto. Vi skapar en S3 Access Grants-instans, en S3 Access Grants-plats som refererar till vår databucket skapad av AWS CloudFormation-stacken som endast är tillgänglig för vår databucket AWS IAM-roll, och ger olika åtkomstnivåer till våra läsar- och skribentroller.

För att skapa de nödvändiga S3 Access Grants-resurserna, använd följande AWS CLI-kommandon som administrativ användare och ersätt något av fälten mellan pilarna med utdata från din CloudFormation-stack.
Därefter skapar vi en ny S3 Access Grants-plats. Vad är en plats? Amazon S3 Access Grants fungerar genom att sälja AWS IAM-referenser med åtkomst till ett visst S3-prefix. En S3 Access Grants-plats kommer att associeras med en AWS IAM-roll från vilken dessa tillfälliga sessioner kommer att skapas.
I vårt fall kommer vi att omfånga AWS IAM-rollen till hinken som skapats med vår AWS CloudFormation-stack och ge tillgång till den datahinkroll som skapas av stacken. Gå till utdatafliken för att hitta värdena som ska ersättas med följande kodavsnitt:
Notera AccessGrantsLocationId värde i svaret. Vi behöver det för nästa steg där vi går igenom att skapa de nödvändiga S3 Access Grants för att begränsa läs- och skrivåtkomsten till din bucket.
- För läs/skrivanvändaren, använd
s3-control create-access-grantför att tillåta READWRITE-åtkomst till prefixet "output/*": - För den lästa användaren, använd
s3control create-access-grantigen för att endast tillåta LÄS-åtkomst till samma prefix:
Demoscenario 1: Amazon EMR på EC2 Spark Job för att generera parkettdata
Nu när vi har konfigurerat våra Amazon EMR-miljöer och beviljat åtkomst till våra roller via S3 Access Grants är det viktigt att notera att de två AWS IAM-rollerna för vårt EMR-kluster och EMR Serverless-applikation har en IAM-policy som endast tillåter åtkomst till vår EMR artefakter hink. De har ingen IAM-åtkomst till vår S3-databucket och använder istället S3 Access Grants för att hämta kortlivade autentiseringsuppgifter omfångade till hinken och prefixet. Specifikt ges rollerna s3:GetDataAccess och s3:GetDataAccessGrantsInstanceForPrefix behörigheter att begära åtkomst via den specifika S3 Access Grants-instans som skapats i vår region. Detta gör att du enkelt kan hantera din S3-åtkomst på ett ställe på ett mycket omfattande och detaljerat sätt som förbättrar din säkerhetsställning. Genom att kombinera S3 Access Grants med jobbroller på EMR på Amazon Elastic Kubernetes Service (Amazon EX) och EMR Serverless samt runtime roller för Amazon EMR-steg Från och med EMR 6.7.0 kan du enkelt hantera åtkomstkontroll för enskilda jobb eller frågor. S3 Access Grants är tillgängliga på EMR 6.15.0 och senare. Låt oss först köra ett Spark-jobb på EMR på EC2 som vår analysingenjör för att konvertera några exempeldata till Parquet.
För detta använder du exempelkoden som finns i converter.py. Ladda ner filen och kopiera den till EMR_ARTIFACTS_BUCKET skapad av AWS CloudFormation-stacken. Vi lämnar in vårt jobb med rollen ReadWrite AWS IAM. Observera att för EMR-klustret konfigurerade vi S3 Access Grants för att falla tillbaka till IAM-rollen om åtkomst inte tillhandahålls av S3 Access Grants. De DATA_WRITER_ROLE har läsåtkomst till EMR-artefakter-bucket genom en IAM-policy så att den kan läsa vårt skript. Som tidigare, ersätt alla värden med <> symboler från Utgångarna fliken i din CloudFormation-stack.
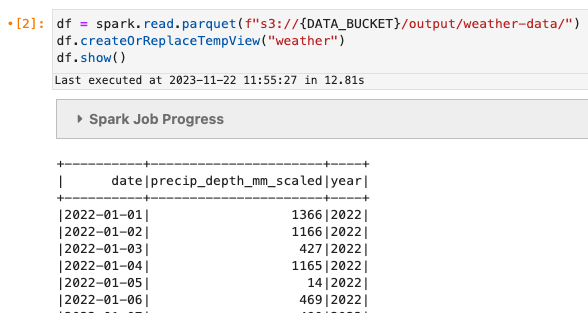
När jobbet är klart bör vi se lite parkettdata s3://<DATA_BUCKET>/output/weather-data/. Du kan se status för jobbet i Steg fliken på EMR-konsol.
Demoscenario 2: EMR Studio med en interaktiv EMR-serverlös applikation för att analysera data
Låt oss nu gå vidare och logga in på EMR Studio och ansluta till din EMR Serverless-applikation med ReadOnly runtime-rollen för att analysera data från scenario 1. Först måste vi aktivera den interaktiva slutpunkten på din Serverless-applikation.
- Välj EMRStudioURL i Fliken Utgångar av din AWS CloudFormation-stack.
- Välja Applikationer under Server avsnitt på vänster sida.

- Välj EMRBlog ansökan, sedan Handling rullgardinsmenyn och Configure.
- Expandera Interaktiv slutpunkt avsnitt och se till att Aktivera interaktiv slutpunkt är kontrollerad.

- Bläddra ner och klicka Konfigurera applikation för att spara dina ändringar.
- Tillbaka på applikationssidan, välj EMRBlog ansökan, sedan Starta applikationen knapp.
Skapa sedan en ny arbetsyta i vår Studio.
- Välja arbetsytor på vänster sida, sedan Skapa arbetsyta knapp.
- Ange ett arbetsytanamn, lämna kvar de återstående standardinställningarna och välj Skapa arbetsyta.
- Efter att ha skapat arbetsytan bör den startas på en ny flik om några sekunder.
Anslut nu din Workspace till din EMR Serverless-applikation.
- Välj EMR Compute knappen på vänster sida som visas i följande kod.
- Välja EMR-serverlös som beräkningstyp.
- Välj EMRBlog applikation och runtime-rollen som börjar med EMRBlog.
- Välja Bifoga. Fönstret kommer att uppdateras och du kan öppna en ny PySpark anteckningsbok och följ med nedan. För att köra koden själv, ladda ner AccessGrantsReadOnly.ipynb anteckningsbok och ladda upp den till din arbetsyta med hjälp av Ladda upp filer knappen i filläsaren.
Låt oss göra en snabb läsning av data.
Vi gör en enkel räkning(*):

Du kan också se att om vi försöker skriva data till utdataplatsen får vi ett Amazon S3-fel.

Även om du också kan ge liknande åtkomst via AWS IAM-policyer, kan Amazon S3 Access Grants vara användbart för situationer där din organisation har vuxit ur hanteringen av åtkomst via IAM, vill mappa S3 Access Grants till IAM Identity Center-huvudmän eller roller, eller tidigare har använt EMR Filsystem (EMRFS) rollmappningar. S3 Access Grants-uppgifter är också tillfälliga och ger säkrare åtkomst till dina data. Dessutom, som visas nedan, gynnas åtkomst över flera konton också av enkelheten med S3 Access Grants.
Demoscenario 3 – Åtkomst över flera konton
Ett av de andra vanligare åtkomstmönstren är åtkomst till data över konton. Detta mönster har blivit allt vanligare med uppkomsten av datanät, där dataproducenter och konsumenter är decentraliserade över olika AWS-konton.
Tidigare krävde åtkomst över flera konton att du konfigurerade komplexa rollåtgärder över flera konton och leverantörer av anpassade autentiseringsuppgifter när du konfigurerar ditt Spark-jobb. Med S3 Access Grants behöver vi bara göra följande:
- Skapa en Amazon EMR-jobbroll och kluster i ett andra datakonsumentkonto
- Dataproducentkontot ger åtkomst till datakonsumentkontot med en ny instansresurspolicy
- Dataproducentkontot skapar ett åtkomstbidrag för rollen datakonsumentjobb
Och det är allt! Om du har ett andra konto till hands, fortsätt och distribuera denna AWS CloudFormation-stack i datakonsumentkontot för att skapa en ny EMR-serverlös applikation och jobbroll. Om inte, följ bara med nedan. AWS CloudFormation-stacken ska skapas på mindre än en minut. Låt oss sedan gå vidare och ge vår datakonsument tillgång till S3 Access Grants-instansen i vårt dataproducentkonto.
- ersätta
<DATA_PRODUCER_ACCOUNT_ID>och<DATA_CONSUMER_ACCOUNT_ID>med relevanta 12-siffriga AWS-konto-ID:n. - Du kan också behöva ändra region i kommandot och policyn.
- Och ge sedan LÄS-åtkomst till utdatamappen till vår EMR Serverless-jobbroll i datakonsumentkontot.
Nu när vi har gjort det kan vi läsa data i datakonsumentkontot från hinken i dataproducentkontot. Vi kör bara en enkel COUNT(*) igen. Ersätt <APPLICATION_ID>, <DATA_CONSUMER_JOB_ROLE>och <DATA_CONSUMER_LOG_BUCKET> med värdena från fliken Utgångar på AWS CloudFormation-stacken som skapats i ditt andra konto.
Och byt ut <DATA_PRODUCER_BUCKET> med hinken från ditt första konto.
Vänta tills jobbet når ett slutfört tillstånd och hämta sedan standardloggen från din hink och ersätt <APPLICATION_ID>, <JOB_RUN_ID> från jobbet ovan, och <DATA_CONSUMER_LOG_BUCKET>.
Om du är på en unix-baserad maskin och har dragkedja installerat, då kan du använda följande kommando som din administrativa användare.
Observera att det här kommandot endast använder AWS IAM-rollpolicyer, inte Amazon S3 Access Grants.
Annars kan du använda få-dashboard-för-jobbkörning kommandot och öppna den resulterande URL:en i din webbläsare för att visa drivrutinsloggarna på fliken Executors i Spark UI.
Städar upp
För att undvika framtida kostnader för exempelresurser i dina AWS-konton, var noga med att ta följande steg:
- Du måste manuellt ta bort Amazon EMR Studio-arbetsytan som skapades i den första delen av inlägget
- Töm Amazon S3-hinkarna som skapats av AWS CloudFormation-stackarna
- Se till att du tar bort Amazon S3 Access Grants, resurspolicyer och S3 Access Grants-platsen som skapats i stegen ovan med hjälp av
delete-access-grant,delete-access-grants-instance-resource-policy,delete-access-grants-locationochdelete-access-grants-instancekommandon. - Ta bort AWS CloudFormation-stackarna som skapats i varje konto
Jämförelse med AWS IAM-rollmappning
Under 2018 introducerade EMR EMRFS rollmappning som ett sätt att tillhandahålla auktorisering på lagringsnivå genom att konfigurera EMRFS med flera IAM-roller. Även om rollmappningen var effektiv, krävde rollmappningen att man hanterade användare eller grupper lokalt på ditt EMR-kluster utöver att bibehålla mappningarna mellan dessa identiteter och deras motsvarande IAM-roller. I kombination med runtime roller på EMR på EC2 och arbetsroller för EMR på EKS och EMR-serverlös, är det nu enklare att ge åtkomst till dina uppgifter på S3 direkt till den relevanta huvudmannen per jobb.
Slutsats
I det här inlägget visade vi dig hur du ställer in och använder Amazon S3 Access Grants med Amazon EMR för att enkelt hantera dataåtkomst för dina Amazon EMR-arbetsbelastningar. Med S3 Access Grants och EMR kan du enkelt konfigurera åtkomst till data på S3 för IAM-identiteter eller använda din företagskatalog i IAM Identity Center som din identitetskälla. S3 Access Grants stöds över EMR på EC2, EMR på EKS och EMR Serverless från och med EMR release 6.15.0.
Att lära sig mer, se S3 Access Grants och EMR-dokumentation och ställ gärna frågor i kommentarerna!
Om författaren
 Damon Cortesi är en huvudansvarig för utvecklare med Amazon Web Services. Han bygger verktyg och innehåll för att underlätta livet för dataingenjörer. När han inte jobbar hårt bygger han fortfarande datapipelines och delar loggar på fritiden.
Damon Cortesi är en huvudansvarig för utvecklare med Amazon Web Services. Han bygger verktyg och innehåll för att underlätta livet för dataingenjörer. När han inte jobbar hårt bygger han fortfarande datapipelines och delar loggar på fritiden.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/use-amazon-emr-with-s3-access-grants-to-scale-spark-access-to-amazon-s3/
- : har
- :är
- :inte
- :var
- $UPP
- 1
- 10
- 100
- 107
- 11
- 1232
- 15%
- 20
- 2018
- 500
- 7
- 8
- a
- Om Oss
- ovan
- tillgång
- Behörighets förvaltning
- Tillgång till data
- tillgänglig
- åtkomst
- Konto
- konton
- bekräfta
- tvärs
- Handling
- åtgärder
- Dessutom
- adress
- administrativa
- förespråkare
- igen
- framåt
- Alla
- tillåter
- tillåter
- längs
- också
- amason
- Amazon EC2
- Amazon Elastic Kubernetes-tjänst
- Amazon EMR
- Amazon Web Services
- an
- analytiker
- analytics
- analysera
- och
- Meddela
- Annan
- vilken som helst
- Apache
- Apache Spark
- Ansökan
- tillämpningar
- cirka
- arkitektur
- ÄR
- AS
- be
- associerad
- utgå ifrån
- At
- tillstånd
- tillgänglig
- undvika
- AWS
- AWS molnformation
- tillbaka
- grund
- BE
- blir
- innan
- Börjar
- nedan
- Fördelarna
- Bättre
- mellan
- webbläsare
- bygger
- företag
- men
- Knappen
- by
- KAN
- Vid
- Centrum
- byta
- Förändringar
- kontrollerade
- Välja
- klick
- klient
- cloud
- kluster
- koda
- kombination
- kombinera
- Gemensam
- fullborda
- Avslutade
- komplex
- Compute
- konfigurerad
- konfigurering
- Kontakta
- Konsumenten
- konsumenter
- innehåll
- fortsätta
- kontroll
- konvertera
- Företag
- Motsvarande
- Kostar
- skapa
- skapas
- skapar
- Skapa
- referenser
- beställnings
- Kunder
- datum
- datatillgång
- decentraliserad
- Standard
- defaults
- distribuera
- utplacering
- Utvecklare
- olika
- direkt
- do
- dokumentation
- gjort
- ner
- ladda ner
- chaufför
- e
- varje
- lättare
- lätt
- lätt
- effekt
- Effektiv
- uppkomst
- möjliggöra
- Slutpunkt
- förstärka
- ingenjör
- Ingenjörer
- Förbättrar
- säkerställa
- miljöer
- fel
- Eter (ETH)
- Även
- exempel
- exekvera
- Höst
- Mode
- känna
- få
- Fält
- Fil
- Filer
- filtrering
- Slutligen
- hitta
- slut
- Förnamn
- följer
- efter
- För
- Fri
- från
- framtida
- nätbryggan
- generera
- skaffa sig
- Ge
- Go
- kommer
- fick
- bevilja
- beviljats
- bidrag
- Grupp
- Gruppens
- praktisk
- Hård
- Har
- he
- hjälpa
- höggradigt
- hans
- Bikupa
- Hur ser din drömresa ut
- How To
- html
- HTTPS
- i
- IAM
- ID
- identiteter
- Identitet
- identitets- och åtkomsthantering
- ids
- if
- importera
- med Esport
- in
- alltmer
- individuellt
- informationen
- exempel
- istället
- integrering
- interaktiva
- Gränssnitt
- in
- introducerade
- IT
- Jobb
- Lediga jobb
- jpg
- bara
- Nyckel
- Kubernetes
- senare
- senaste
- lansera
- LÄRA SIG
- Lämna
- nivåer
- tycka om
- BEGRÄNSA
- linje
- Bor
- lokalt
- läge
- log
- logga in
- Maskinen
- upprätthålla
- göra
- hantera
- ledning
- hantera
- manuellt
- många
- karta
- kartläggning
- Maj..
- maska
- minut
- minuter
- mer
- multipel
- måste
- namn
- nödvändigt för
- Behöver
- nät
- Nya
- Nästa
- Nej
- Notera
- anteckningsbok
- bärbara datorer
- nu
- of
- on
- gång
- ONE
- endast
- öppet
- Tillbehör
- or
- beställa
- organisation
- Övriga
- vår
- produktion
- utgångar
- utanför
- egen
- sida
- del
- särskilt
- Mönster
- mönster
- tillstånd
- behörigheter
- Plats
- plato
- Platon Data Intelligence
- PlatonData
- nöjd
- Strategier
- policy
- Inlägg
- tidigare
- Principal
- uppdragsgivare
- privat
- producent
- producenter
- ge
- förutsatt
- leverantör
- leverantörer
- ger
- tillhandahålla
- allmän
- Syftet
- sökfrågor
- frågor
- Snabbt
- nå
- Läsa
- Läsare
- hänvisar
- region
- registrera
- frigöra
- relevanta
- Återstående
- ersätta
- begära
- Obligatorisk
- resurs
- Resurser
- respons
- resulterande
- Roll
- roller
- Rutt
- Körning
- kör
- Samma
- Save
- Skala
- scenario
- scenarier
- omfattning
- skript
- Andra
- sekunder
- Secret
- §
- säkra
- säkerhet
- se
- välj
- Server
- service
- Tjänster
- sessioner
- in
- inställning
- inställning
- Dela
- skall
- show
- visade
- visas
- sida
- liknande
- Enkelt
- enkelhet
- förenklar
- situationer
- kodavsnitt
- So
- några
- Källa
- Gnista
- specifik
- specifikt
- Delar upp
- SQL
- stapel
- Stacks
- igång
- Starta
- startar
- Ange
- .
- status
- Steg
- Fortfarande
- förvaring
- studio
- skicka
- subnät
- framgång
- Som stöds
- säker
- system
- Ta
- tar
- mall
- temporär
- testa
- den där
- Smakämnen
- deras
- sedan
- Dessa
- de
- detta
- de
- Genom
- tid
- till
- verktyg
- Översättning
- prova
- två
- Typ
- typer
- ui
- under
- URL
- användning
- Begagnade
- Användare
- användare
- användningar
- med hjälp av
- utnyttja
- värde
- Värden
- version
- via
- utsikt
- Virtuell
- gå
- gående
- vill
- Sätt..
- we
- Väder
- webb
- webbservice
- VÄL
- Vad
- Vad är
- när
- som
- medan
- kommer
- fönster
- med
- Arbete
- fungerar
- skriva
- författare
- jaml
- år
- dig
- Din
- själv
- zephyrnet