AWS-drivna datasjöar, som stöds av den oöverträffade tillgängligheten av Amazon enkel lagringstjänst (Amazon S3), kan hantera skalan, smidigheten och flexibiliteten som krävs för att kombinera olika data- och analysmetoder. Eftersom datasjöar har vuxit i storlek och mognat i användning, kan en betydande mängd ansträngning läggas på att hålla data överens med affärshändelser. För att säkerställa att filer uppdateras på ett transaktionsmässigt konsekvent sätt, använder ett växande antal kunder transaktionstabellformat med öppen källkod som t.ex. Apache isberg, Apache Hudioch Linux Foundation Delta Lake som hjälper dig att lagra data med höga komprimeringshastigheter, integrera med dina applikationer och ramverk och förenkla inkrementell databehandling i datasjöar byggda på Amazon S3. Dessa format möjliggör ACID-transaktioner (atomicitet, konsistens, isolering, hållbarhet), upserts och borttagningar och avancerade funktioner som tidsresor och ögonblicksbilder som tidigare bara var tillgängliga i datalager. Varje lagringsformat implementerar denna funktion på lite olika sätt; för en jämförelse, se Att välja ett öppet tabellformat för din transaktionsdatasjö på AWS.
2023, AWS meddelade allmän tillgänglighet för Apache Iceberg, Apache Hudi och Linux Foundation Delta Lake i Amazon Athena för Apache Spark, vilket tar bort behovet av att installera en separat anslutning eller tillhörande beroenden och hantera versioner, och förenklar konfigurationsstegen som krävs för att använda dessa ramverk.
I det här inlägget visar vi dig hur du använder Spark SQL i Amazonas Athena anteckningsböcker och arbeta med bordsformat Iceberg, Hudi och Delta Lake. Vi demonstrerar vanliga operationer som att skapa databaser och tabeller, infoga data i tabellerna, fråga efter data och titta på ögonblicksbilder av tabellerna i Amazon S3 med Spark SQL i Athena.
Förutsättningar
Fyll i följande förutsättningar:
Ladda ner och importera exempel anteckningsböcker från Amazon S3
För att följa med, ladda ner anteckningsböckerna som diskuteras i det här inlägget från följande platser:
När du har laddat ner anteckningsböckerna importerar du dem till din Athena Spark-miljö genom att följa För att importera en anteckningsbok avsnitt i Hantera anteckningsbokfiler.
Navigera till det specifika avsnittet Öppna tabellformat
Om du är intresserad av Iceberg bordsformat, navigera till Arbeta med Apache Iceberg-bord sektion.
Om du är intresserad av Hudi-tabellformat, navigera till Arbeta med Apache Hudi-bord sektion.
Om du är intresserad av Delta Lake-tabellformat, navigera till Arbeta med Linux Foundation Delta Lake-tabeller sektion.
Arbeta med Apache Iceberg-bord
När du använder Spark-anteckningsböcker i Athena kan du köra SQL-frågor direkt utan att behöva använda PySpark. Det gör vi genom att använda cellmagi, som är speciella rubriker i en anteckningsbokscell som ändrar cellens beteende. För SQL kan vi lägga till %%sql magi, som kommer att tolka hela cellinnehållet som en SQL-sats som ska köras på Athena.
I det här avsnittet visar vi hur du kan använda SQL på Apache Spark för Athena för att skapa, analysera och hantera Apache Iceberg-tabeller.
Ställ in en anteckningsbok-session
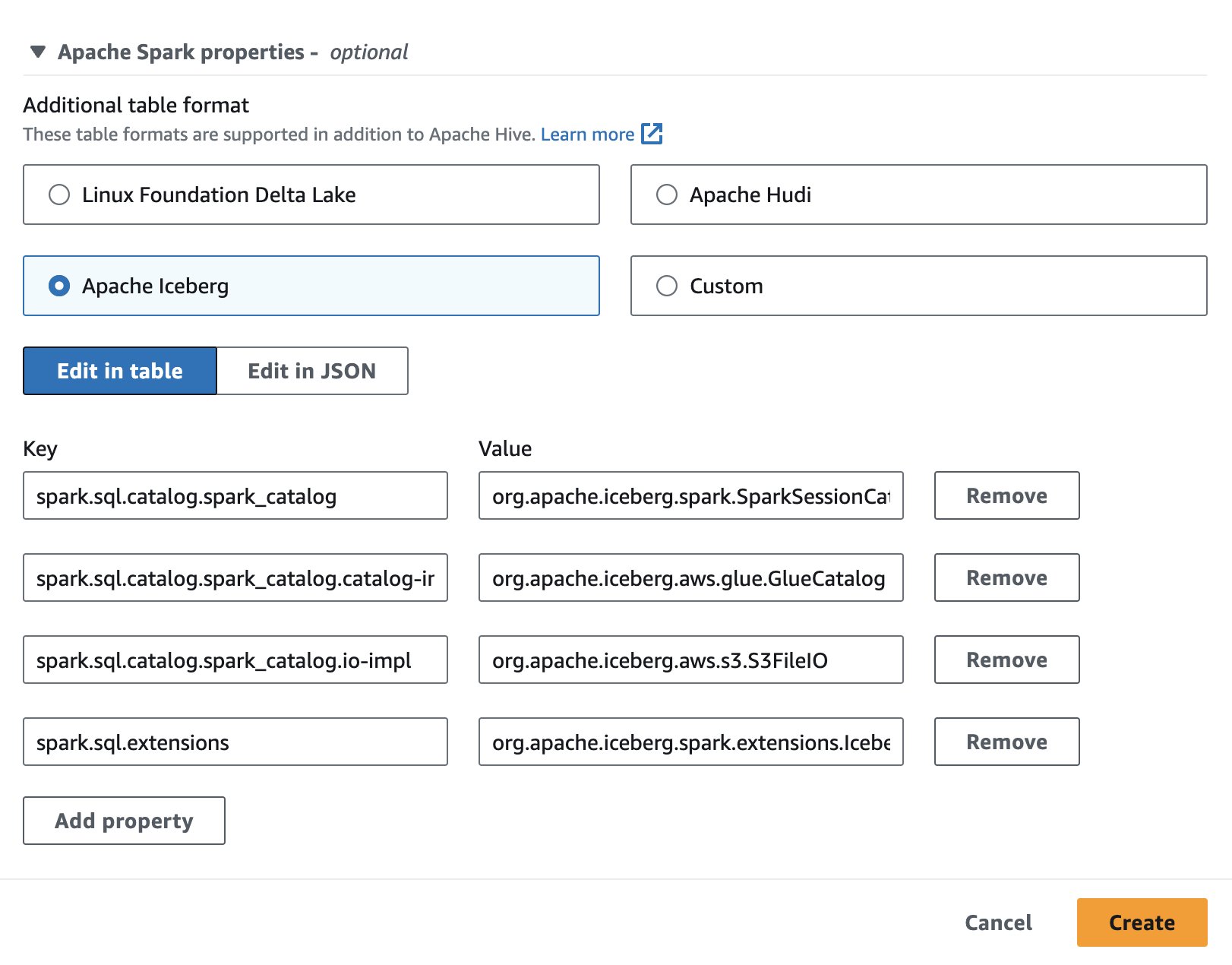
För att använda Apache Iceberg i Athena, medan du skapar eller redigerar en session, välj Apache isberg alternativet genom att utöka Apache Spark egenskaper sektion. Det kommer att förbefolka egenskaperna som visas i följande skärmdump.
För steg, se Redigera sessionsdetaljer or Skapa din egen anteckningsbok.
Koden som används i det här avsnittet är tillgänglig i SparkSQL_iceberg.ipynb fil för att följa med.
Skapa en databas och isbergstabell
Först skapar vi en databas i AWS Glue Data Catalog. Med följande SQL kan vi skapa en databas som heter icebergdb:
Därefter i databasen icebergdb, skapar vi ett Iceberg-bord som heter noaa_iceberg pekar på en plats i Amazon S3 där vi kommer att ladda data. Kör följande uttalande och ersätt platsen s3://<your-S3-bucket>/<prefix>/ med din S3 hink och prefix:
Infoga data i tabellen
Att befolka noaa_iceberg Isbergsbord, vi lägger in data från Parkettbordet sparkblogdb.noaa_pq som skapades som en del av förutsättningarna. Du kan göra detta med en INSERT IN uttalande i Spark:
Alternativt kan du använda SKAPA TABELL SOM SELECT med ANVÄNDA isbergssatsen för att skapa en isbergstabell och infoga data från en källtabell i ett steg:
Fråga isbergsbordet
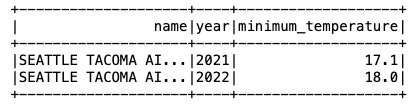
Nu när data infogas i Iceberg-tabellen kan vi börja analysera den. Låt oss köra en Spark SQL för att hitta den lägsta registrerade temperaturen per år för 'SEATTLE TACOMA AIRPORT, WA US' Plats:
Vi får följande utdata.
Uppdatera data i Iceberg-tabellen
Låt oss titta på hur du uppdaterar data i vår tabell. Vi vill uppdatera stationsnamnet 'SEATTLE TACOMA AIRPORT, WA US' till 'Sea-Tac'. Med Spark SQL kan vi köra en UPPDATERING uttalande mot isbergsbordet:
Vi kan sedan köra den föregående SELECT-frågan för att hitta den lägsta registrerade temperaturen för 'Sea-Tac' Plats:
Vi får följande resultat.

Kompakta datafiler
Öppna tabellformat som Iceberg fungerar genom att skapa deltaändringar i fillagring och spåra versionerna av rader genom manifestfiler. Fler datafiler leder till mer metadata som lagras i manifestfiler, och små datafiler orsakar ofta en onödig mängd metadata, vilket resulterar i mindre effektiva frågor och högre åtkomstkostnader för Amazon S3. Kör Iceberg's rewrite_data_files Proceduren i Spark for Athena kommer att komprimera datafiler och kombinera många små deltaändringsfiler till en mindre uppsättning läsoptimerade Parquet-filer. Att komprimera filer påskyndar läsoperationen när de efterfrågas. För att köra komprimering på vårt bord, kör följande Spark SQL:
rewrite_data_files erbjuder alternativ för att specificera din sorteringsstrategi, vilket kan hjälpa till att omorganisera och komprimera data.
Lista tabellöversikter
Varje skriv-, uppdaterings-, raderings-, uppsättnings- och komprimeringsoperation på ett Iceberg-bord skapar en ny ögonblicksbild av en tabell samtidigt som den gamla data och metadata behålls för ögonblicksbildsisolering och tidsresor. För att lista ögonblicksbilderna av en Iceberg-tabell, kör följande Spark SQL-sats:
Utgå gamla ögonblicksbilder
Regelbundet utgående ögonblicksbilder rekommenderas för att radera datafiler som inte längre behövs och för att hålla storleken på tabellmetadata liten. Det kommer aldrig att ta bort filer som fortfarande krävs av en ögonblicksbild som inte har löpt ut. I Spark for Athena kör du följande SQL för att förfalla ögonblicksbilder för tabellen icebergdb.noaa_iceberg som är äldre än en specifik tidsstämpel:
Observera att tidsstämpelvärdet anges som en sträng i formatet yyyy-MM-dd HH:mm:ss.fff. Utdata kommer att ge en räkning av antalet raderade data- och metadatafiler.
Släpp tabellen och databasen
Du kan köra följande Spark SQL för att rensa upp Iceberg-tabellerna och tillhörande data i Amazon S3 från den här övningen:
Kör följande Spark SQL för att ta bort databasen icebergdb:
För att lära dig mer om alla operationer du kan utföra på Iceberg-bord med Spark for Athena, se Spark Queries och Gnistprocedurer i Iceberg-dokumentationen.
Arbeta med Apache Hudi-bord
Därefter visar vi hur du kan använda SQL på Spark för Athena för att skapa, analysera och hantera Apache Hudi-tabeller.
Ställ in en anteckningsbok-session
För att använda Apache Hudi i Athena, medan du skapar eller redigerar en session, välj Apache Hudi alternativet genom att utöka Apache Spark egenskaper sektion.
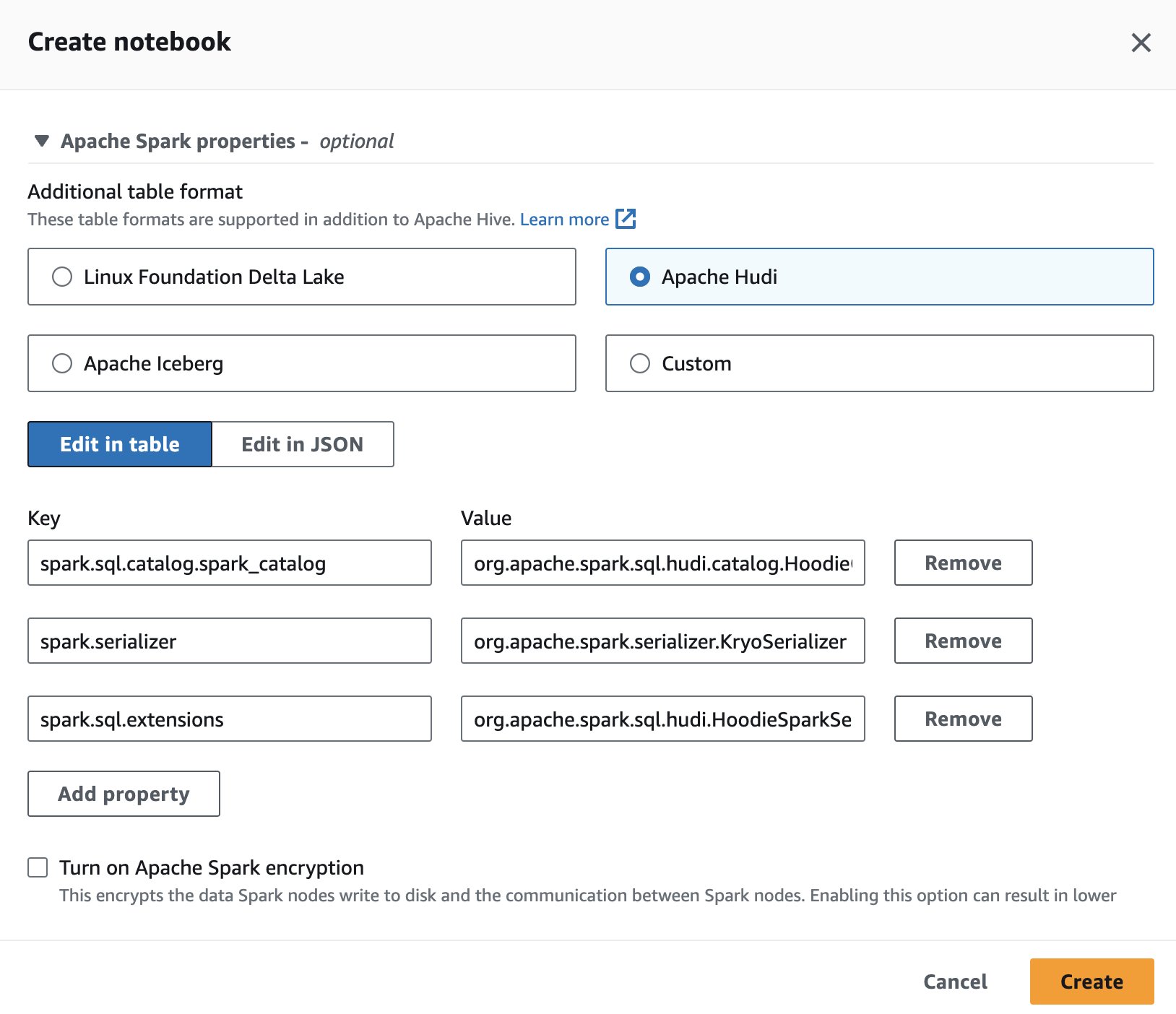
För steg, se Redigera sessionsdetaljer or Skapa din egen anteckningsbok.
Koden som används i det här avsnittet bör vara tillgänglig i SparkSQL_hudi.ipynb fil för att följa med.
Skapa en databas och Hudi-tabell
Först skapar vi en databas som heter hudidb som kommer att lagras i AWS Glue Data Catalog följt av att Hudi-tabellen skapas:
Vi skapar en Hudi-tabell som pekar på en plats i Amazon S3 där vi kommer att ladda data. Observera att tabellen är av kopia-på-skriv typ. Den definieras av type= 'cow' i tabellen DDL. Vi har definierat station och datum som de multipla primärnycklarna och preCombinedField som år. Dessutom är bordet uppdelat på år. Kör följande uttalande och ersätt platsen s3://<your-S3-bucket>/<prefix>/ med din S3 hink och prefix:
Infoga data i tabellen
Precis som med Iceberg använder vi INSERT IN för att fylla i tabellen genom att läsa data från sparkblogdb.noaa_pq tabell skapad i föregående inlägg:
Fråga Hudi-tabellen
Nu när tabellen har skapats, låt oss köra en fråga för att hitta den maximala registrerade temperaturen för 'SEATTLE TACOMA AIRPORT, WA US' Plats:
Uppdatera data i Hudi-tabellen
Låt oss ändra stationens namn 'SEATTLE TACOMA AIRPORT, WA US' till 'Sea–Tac'. Vi kan köra ett UPDATE-uttalande på Spark för Athena uppdatering register över noaa_hudi tabell:
Vi kör den föregående SELECT-frågan för att hitta den maximala registrerade temperaturen för 'Sea-Tac' Plats:
Kör frågor om tidsresor
Vi kan använda tidsresefrågor i SQL på Athena för att analysera tidigare dataögonblicksbilder. Till exempel:
Den här frågan kontrollerar temperaturdata från Seattle Airport från en specifik tidpunkt i det förflutna. Tidsstämpelsatsen låter oss resa tillbaka utan att ändra aktuella data. Observera att tidsstämpelvärdet anges som en sträng i formatet yyyy-MM-dd HH:mm:ss.fff.
Optimera frågehastigheten med klustring
För att förbättra frågeprestanda kan du utföra klustring på Hudi-tabeller med SQL i Spark för Athena:
Kompakta bord
Komprimering är en tabelltjänst som används av Hudi specifikt i Merge On Read (MOR)-tabeller för att periodiskt slå samman uppdateringar från radbaserade loggfiler till motsvarande kolumnbaserade basfil för att producera en ny version av basfilen. Komprimering är inte tillämpligt på Copy On Write (COW)-tabeller och gäller endast MOR-tabeller. Du kan köra följande fråga i Spark for Athena för att utföra komprimering på MOR-tabeller:
Släpp tabellen och databasen
Kör följande Spark SQL för att ta bort Hudi-tabellen du skapade och tillhörande data från Amazon S3-platsen:
Kör följande Spark SQL för att ta bort databasen hudidb:
För att lära dig om alla operationer du kan utföra på Hudi-bord med Spark for Athena, se SQL DDL och Förfaranden i Hudi-dokumentationen.
Arbeta med Linux Foundation Delta Lake-tabeller
Därefter visar vi hur du kan använda SQL på Spark för Athena för att skapa, analysera och hantera Delta Lake-tabeller.
Ställ in en anteckningsbok-session
För att använda Delta Lake i Spark for Athena, medan du skapar eller redigerar en session, välj Linux Foundation Delta Lake genom att utöka Apache Spark egenskaper sektion.
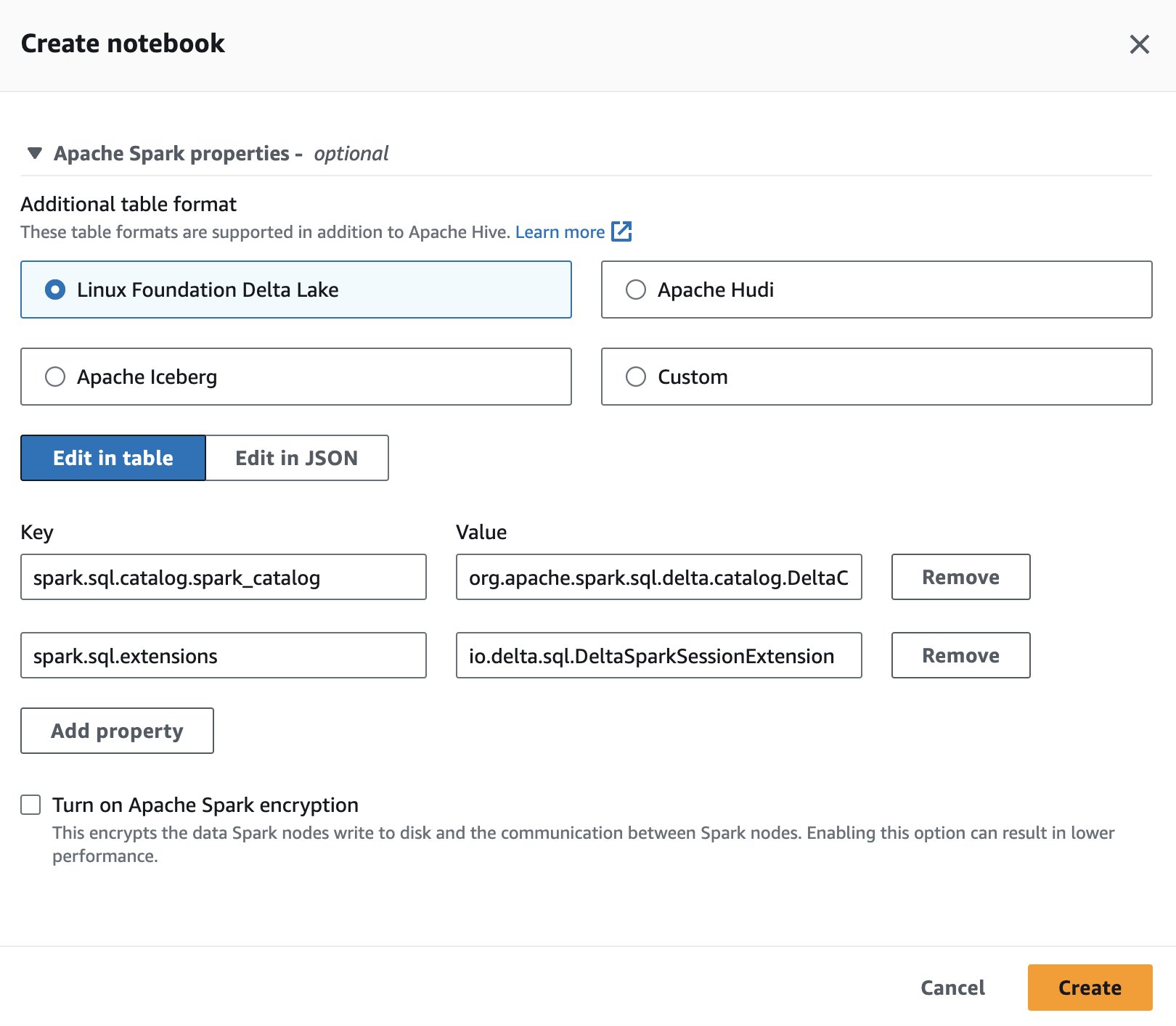
För steg, se Redigera sessionsdetaljer or Skapa din egen anteckningsbok.
Koden som används i det här avsnittet bör vara tillgänglig i SparkSQL_delta.ipynb fil för att följa med.
Skapa en databas och Delta Lake-tabell
I det här avsnittet skapar vi en databas i AWS Glue Data Catalog. Genom att använda följande SQL kan vi skapa en databas som heter deltalakedb:
Därefter i databasen deltalakedb, skapar vi ett Delta Lake-bord som heter noaa_delta pekar på en plats i Amazon S3 där vi kommer att ladda data. Kör följande uttalande och ersätt platsen s3://<your-S3-bucket>/<prefix>/ med din S3 hink och prefix:
Infoga data i tabellen
Vi använder en INSERT IN för att fylla i tabellen genom att läsa data från sparkblogdb.noaa_pq tabell skapad i föregående inlägg:
Du kan också använda CREATE TABLE AS SELECT för att skapa en Delta Lake-tabell och infoga data från en källtabell i en fråga.
Fråga Delta Lake-tabellen
Nu när data har infogats i Delta Lake-tabellen kan vi börja analysera dem. Låt oss köra en Spark SQL för att hitta den lägsta registrerade temperaturen för 'SEATTLE TACOMA AIRPORT, WA US' Plats:
Uppdatera data i deltasjötabellen
Låt oss ändra stationens namn 'SEATTLE TACOMA AIRPORT, WA US' till 'Sea–Tac'. Vi kan köra en UPPDATERING uttalande om Spark för Athena att uppdatera register över noaa_delta tabell:
Vi kan köra den föregående SELECT-frågan för att hitta den lägsta registrerade temperaturen för 'Sea-Tac' plats, och resultatet bör vara detsamma som tidigare:
Kompakta datafiler
I Spark for Athena kan du köra OPTIMIZE på Delta Lake-tabellen, vilket komprimerar de små filerna till större filer, så att frågorna inte belastas av den lilla filoverheaden. För att utföra komprimeringsoperationen, kör följande fråga:
Hänvisa till Optimeringar i Delta Lake-dokumentationen för olika tillgängliga alternativ när du kör OPTIMIZE.
Ta bort filer som inte längre refereras av en Delta Lake-tabell
Du kan ta bort filer lagrade i Amazon S3 som inte längre refereras av en Delta Lake-tabell och som är äldre än retentionströskeln genom att köra VACCUM-kommandot på bordet med Spark for Athena:
Hänvisa till Ta bort filer som inte längre refereras till av en deltatabell i Delta Lake-dokumentationen för tillgängliga alternativ med VACUUM.
Släpp tabellen och databasen
Kör följande Spark SQL för att ta bort Delta Lake-tabellen du skapade:
Kör följande Spark SQL för att ta bort databasen deltalakedb:
Att köra DROP TABLE DDL på Delta Lake-tabellen och databasen raderar metadata för dessa objekt, men raderar inte automatiskt datafilerna i Amazon S3. Du kan köra följande Python-kod i anteckningsbokens cell för att radera data från S3-platsen:
För att lära dig mer om SQL-satserna som du kan köra på en Delta Lake-tabell med Spark for Athena, se quick i Delta Lake-dokumentationen.
Slutsats
Det här inlägget demonstrerade hur man använder Spark SQL i Athena-anteckningsböcker för att skapa databaser och tabeller, infoga och fråga data och utföra vanliga operationer som uppdateringar, komprimering och tidsresor på Hudi-, Delta Lake- och Iceberg-tabeller. Öppna tabellformat lägger till ACID-transaktioner, upserts och raderingar till datasjöar, vilket övervinner begränsningarna för lagring av råobjekt. Genom att ta bort behovet av att installera separata kontakter, minskar Spark on Athenas inbyggda integration konfigurationssteg och administrationskostnader när du använder dessa populära ramverk för att bygga tillförlitliga datasjöar på Amazon S3. För att lära dig mer om hur du väljer ett öppet tabellformat för dina datasjöarbetsbelastningar, se Att välja ett öppet tabellformat för din transaktionsdatasjö på AWS.
Om författarna
![]() Pathik Shah är en Sr. Analytics-arkitekt på Amazon Athena. Han började på AWS 2015 och har fokuserat på big data analytics-området sedan dess, och hjälpt kunder att bygga skalbara och robusta lösningar med hjälp av AWS analytics-tjänster.
Pathik Shah är en Sr. Analytics-arkitekt på Amazon Athena. Han började på AWS 2015 och har fokuserat på big data analytics-området sedan dess, och hjälpt kunder att bygga skalbara och robusta lösningar med hjälp av AWS analytics-tjänster.
![]() Raj Devnath är produktchef på AWS på Amazon Athena. Han brinner för att bygga produkter som kunderna älskar och hjälpa kunder att extrahera värde från deras data. Hans bakgrund är att leverera lösningar för flera slutmarknader, såsom finans, detaljhandel, smarta byggnader, hemautomation och datakommunikationssystem.
Raj Devnath är produktchef på AWS på Amazon Athena. Han brinner för att bygga produkter som kunderna älskar och hjälpa kunder att extrahera värde från deras data. Hans bakgrund är att leverera lösningar för flera slutmarknader, såsom finans, detaljhandel, smarta byggnader, hemautomation och datakommunikationssystem.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/use-amazon-athena-with-spark-sql-for-your-open-source-transactional-table-formats/
- : har
- :är
- :inte
- :var
- $UPP
- 000
- 1
- 10
- 100
- 107
- 11
- 12
- 13
- 16
- 2015
- 2023
- 23
- 300
- 41
- 43
- 53
- 58
- 7
- 8
- 9
- a
- Om oss
- tillgång
- lägga till
- avancerat
- mot
- flygplats
- Alla
- längs
- också
- amason
- Amazonas Athena
- Amazon Web Services
- mängd
- an
- analytics
- analysera
- analys
- och
- meddelade
- Apache
- Apache Spark
- tillämplig
- tillämpningar
- applicerar
- tillvägagångssätt
- ÄR
- runt
- AS
- associerad
- At
- automatiskt
- Automation
- tillgänglighet
- tillgänglig
- AWS
- AWS-lim
- tillbaka
- bakgrund
- bas
- BE
- varit
- beteende
- Stor
- Stora data
- SLUTRESULTAT
- Byggnad
- byggt
- inbyggd
- företag
- men
- by
- Ring
- kallas
- KAN
- katalog
- Orsak
- cellen
- byta
- Förändringar
- Kontroller
- rena
- koda
- kombinera
- kombinera
- Gemensam
- Kommunikation
- kommunikationssystem
- kompakt
- jämförelse
- konfiguration
- konsekvent
- innehåll
- Motsvarande
- Kostar
- räkna
- skapa
- skapas
- skapar
- Skapa
- skapande
- Aktuella
- Kunder
- datum
- Data Analytics
- datasjö
- databehandling
- datalager
- Databas
- databaser
- Datum
- definierade
- leverera
- Delta
- demonstrera
- demonstreras
- beroenden
- olika
- direkt
- diskuteras
- do
- dokumentation
- inte
- ladda ner
- Drop
- hållbarhet
- varje
- Tidigare
- redigering
- effektiv
- ansträngning
- anställd
- möjliggöra
- änden
- säkerställa
- Hela
- Miljö
- Eter (ETH)
- händelser
- exempel
- Motionera
- expanderande
- extrahera
- Funktioner
- Fil
- Filer
- finansiering
- hitta
- Förnamn
- Flexibilitet
- fokusering
- följer
- följt
- efter
- För
- format
- fundament
- ramar
- från
- funktionalitet
- Allmänt
- skaffa sig
- Ge
- Grupp
- Odling
- vuxen
- hantera
- Har
- har
- he
- headers
- hjälpa
- hjälpa
- hh
- Hög
- högre
- hans
- Hem
- Home Automation
- Hur ser din drömresa ut
- How To
- html
- http
- HTTPS
- bild
- redskap
- importera
- förbättra
- in
- steg
- installera
- integrering
- intresserad
- Gränssnitt
- in
- isolering
- IT
- fogade
- jpg
- Ha kvar
- hålla
- nycklar
- sjö
- sjöar
- större
- latitud
- Leads
- LÄRA SIG
- mindre
- Lets
- tycka om
- begränsningar
- linux
- linux foundation
- Lista
- läsa in
- läge
- platser
- log
- längre
- se
- du letar
- älskar
- magi
- hantera
- ledning
- chef
- sätt
- många
- Marknader
- max
- maximal
- Sammanfoga
- metadata
- min
- minsta
- mer
- multipel
- namn
- natively
- Navigera
- Behöver
- behövs
- aldrig
- Nya
- Nej
- Notera
- anteckningsbok
- bärbara datorer
- antal
- objektet
- Objektförvaring
- objekt
- of
- Erbjudanden
- Ofta
- Gamla
- äldre
- on
- ONE
- endast
- OP
- öppet
- öppen källkod
- drift
- Verksamhet
- Optimera
- Alternativet
- Tillbehör
- or
- beställa
- vår
- produktion
- övervinna
- egen
- del
- brinner
- Tidigare
- utföra
- prestanda
- plato
- Platon Data Intelligence
- PlatonData
- Populära
- Inlägg
- förutsättningar
- föregående
- tidigare
- primär
- förfaranden
- bearbetning
- producera
- Produkt
- produktchef
- Produkter
- egenskaper
- Python
- sökfrågor
- rates
- Raw
- Läsa
- Läsning
- rekommenderas
- registreras
- register
- minskar
- hänvisa
- refererade
- pålitlig
- ta bort
- avlägsnar
- bort
- ersätta
- Obligatorisk
- resultera
- resulterande
- detaljhandeln
- retentionstid
- robusta
- Körning
- rinnande
- Samma
- skalbar
- Skala
- Seattle
- Andra
- §
- se
- välj
- väljer
- separat
- service
- Tjänster
- session
- in
- skall
- show
- visas
- Visar
- signifikant
- Enkelt
- förenklar
- förenkla
- eftersom
- Storlek
- något annorlunda
- SLP
- Small
- mindre
- smarta
- Snapshot
- So
- Lösningar
- Källa
- Utrymme
- Gnista
- speciell
- specifik
- specifikt
- specificerade
- fart
- hastigheter
- spent
- SQL
- starta
- .
- uttalanden
- stationen
- Steg
- Steg
- Fortfarande
- förvaring
- lagra
- lagras
- Strategi
- Sträng
- sådana
- Som stöds
- system
- System
- bord
- Tacoma
- än
- den där
- Smakämnen
- deras
- Dem
- sedan
- Dessa
- detta
- tröskelvärde
- Genom
- tid
- tidsresor
- tidsstämpel
- till
- Spårning
- transaktion
- Transaktioner
- färdas
- Typ
- oöverträffad
- Uppdatering
- uppdaterad
- Uppdateringar
- us
- Användning
- användning
- Begagnade
- med hjälp av
- Vakuum
- värde
- version
- versioner
- vill
- var
- sätt
- we
- webb
- webbservice
- były
- när
- som
- medan
- kommer
- med
- utan
- Arbete
- skriva
- år
- dig
- Din
- zephyrnet