Funderar på att extrahera tabeller från PDF-filer och konvertera dem till excel formatera? Prova Nanonets PDF-bordextraktor att extrahera tabelldata gratis och konvertera dem till Excel.
Beskrivning
Stora företags funktion/verksamhet är tätt kopplad till användningen av kalkylblad/Excel-filer; från listan över sökande organiserad via Google Sheets och uppgiftsuppdelningen för enskilda anställda till hela företagets ekonomiska och budgetmässiga prognoser, företag förlitar sig på tabellformer mycket mer än trott. Men medan vi har slagit ner på den enhetliga Excel-representationen för våra data, kan konvertering av information från olika medium till sådana format innebära intensiva arbetstimmar som annars kan användas för andra uppgifter.

Framstegen inom datorseende och tekniker för textförståelse har i slutändan lett till att ompröva dataextraktionsprocesser – hur kan vi utnyttja djupinlärningstekniker för att hjälpa oss att förstå, extrahera och organisera data till matematiskt beräkningsbara Excel-format?
Den här artikeln diskuterar de stora framsteg som gjorts under det senaste decenniet med automatiserade metoder för att extrahera PDF-data och konvertering till CSV-filer, med en kort höjdpunkt på metoderna för djupinlärning, handledningar och befintliga lösningar på marknaden för att utföra denna uppgift.
Innan man dyker in i kärnextraktionsprocessen bör man först förstå vilken "typ" av data vi strävar efter att få. Det finns många datastrukturer i PDF-filer, av vilka tabeller och nyckel-värde-par (KVP) är de vanligaste och uppenbara.
Tabellformat
Data i tabellformat kan verka trivialt för extrahering, men det är faktiskt en utmanande uppgift på grund av det inneboende lagringsformatet för PDF-filer.
I många PDF-filer presenteras texter och tabeller som pixlar snarare än maskinkodade ord. Med andra ord är de bara svarta och vita, ostrukturerade pixlar som alla andra bilder. Därför kräver extrahering av tabelldata ofta tabell- och textdetektering innan verklig ordförståelse.
Nyckel-värde par
Ibland kan kategorisk information inte presenteras explicit med tabelllinjer, utan istället som KVP:er, två länkade dataobjekt som en nyckel och ett värde, där nyckeln är en unik identifierare för värdet. Några exempel på detta inkluderar de uppgifter som presenteras på pass. Även om dessa data följaktligen kan konverteras till tabeller till Excel-filer, presenterades de ursprungligen som KVP istället för synliga tabeller. Extrahering av sådan data är därför mycket svårare och kan kräva ytterligare toppmoderna djupinlärningstekniker.
Behöver du en gratis OCR online för att extrahera och konvertera tabeller från PDF-filer, bilder till Excel? Kolla in Nanonets och bygg anpassade OCR-modeller och extrahera/konvertera tabeller till Excel gratis!
Tekniker bakom extraktion och bordsomvandling

Även om konverteringen av datastrukturer till CSV-filer som kan importeras direkt till Excel-filer är okomplicerad, kan dataextrahering i sig vara svårt på grund av de ovan nämnda skälen. Detta avsnitt beskriver kortfattat begreppet artificiell intelligens och maskininlärning, särskilt djupinlärning i datorseende för optisk teckenigenkänning (OCR).
Konstgjord intelligens och maskininlärning
Människor associerar ofta de två termerna omväxlande, men de undanhåller faktiskt en subtil skillnad i betydelse. Artificiell intelligens är den breda termen för att beskriva all maskinstödd programvara som kan vara till hjälp att utföra baserat på beslut, oavsett om beslutet utfördes via regelbaserade eller inlärda inställningar.
Maskininlärning, å andra sidan, beskriver specifikt tillvägagångssättet att använda indata och angivna resultat för att "lära sig" det mellanliggande systemet för framtida beslutsfattande/förutsägelser. En sådan inställning kan låta konstigt till en början, eftersom traditionell datorprogramvara syftar till att designa det mellanliggande systemet så att indata, genom systemet, kan ge korrekta resultat. Maskininlärning har dock visat sig vara framgångsrik när det mellanliggande systemet är för svårt att designa på grund av de komplexa uppgifter vi utför. Exempel på applikationer inkluderar svåra bildrelaterade uppgifter som bildklassificering, objektdetektering och naturligtvis teckenigenkänning.
Djupt lärande i datorseende
Deep learning är en ännu mer specifik gren av maskininlärning, där vi designar multi-perceptronlager, eller neurala nätverk, för att approximera det mellanliggande systemet.
Neurala nätverk är arkitekturer inspirerade av det biologiska neurala nätverket, som består av flera lager av neuroner som fungerar som aktiveringsfunktioner när en input matas in i nätverket. Baserat på sanningsförutsägelsen uppdateras neuronvikterna i enlighet med detta så att endast de "korrekta" aktiveringarna utförs, vilket fattar korrekta beslut. Vi hänvisar ofta till denna process som backpropagation.
Denna arkitektur föreslogs i början av 1970-talet, men utvecklingen blev lidande på grund av den höga beräkningskapacitet som krävdes som först nyligen löstes med ökningen av GPU:s beräkningskraft.

Med de starka modelleringsresultaten av djupinlärning stöds nästan alla datorseendeuppgifter (dvs uppgiften att låta datorer förstå bilder) helt eller åtminstone delvis av djupinlärning. En speciell typ av neurala nätverk som används för datorseende är de konvolutionella neurala nätverken (CNN), som introducerar traditionella konvolutionella kärnor som glider genom bilder för att extrahera funktioner. Tillsammans med traditionella nätverkslager har aktuell forskning uppnått toppmoderna resultat för att klassificera och detektera objekt i en bild, för att inte tala om dess fantastiska noggrannhet i OCR.
OCR
Traditionellt sker processen att extrahera bokstäver från ett dokument och konvertera dem till maskinkodade texter genom regelbaserad skanning. Detta har snabbt gett vika för de tidigare nämnda metoderna för djupinlärning som kunde anpassa sig till olika typsnitt, stilar och ibland till och med handskrivna karaktärer.
Dessutom, med hjälp av utsedda nätverksarkitekturer såsom långtidsminnen, kan klassificering av tecken bli mycket mer exakt med förståelsen av sammanhanget från bokstäver före eller efter tecknet (t.ex. efter "d" och "o", "g" är ett mycket mer troligt tecken än "z").
Pipeline
Med en kort förståelse för djupinlärningstekniken introducerar vi sedan pipelinen för att konvertera tabelldata från PDF-filer till Excel-filer:
- Upptäck alla ord i PDF-filen via OCR
- Upptäcker alla begränsningsrutor på PDF:en
- Baserat på de explicita begränsningsrutorna och PDF-filerna, konvertera data till datastrukturer som listor och ordböcker
- Exportera listor och ordböcker till CSV-filer för Excel-bearbetning.
Behöver du en gratis OCR online för att extrahera och konvertera tabeller från PDF-filer, bilder till Excel? Kolla in Nanonets och bygg anpassade OCR-modeller och extrahera/konvertera tabeller till Excel gratis!
Handledning
Handledningen består av två komponenter: OCR-konverteringen och CSV-exporten. Med enkla ord kräver processen att konvertera tabeller från PDF-filer till Excel och tabeller först bra extrahering av orden och tabellerna från PDF-filer, följt av exportsteget.
Handledningen kommer mestadels att vara i Python, med hjälp av Google API och några inbyggda bibliotek Python erbjuder för PDF-konvertering och export
Handledning Del 1 – OCR-konvertering
För att först utföra OCR kan man behöva konvertera PDF till bildformat. Detta kan uppnås via pdf2image-biblioteket genom att installera följande
pip install pdf2imageDe två sätten att konvertera från sökväg och från byte listas som följande.
from pdf2image import convert_from_path, convert_from_bytes
from pdf2image.exceptions import ( PDFInfoNotInstalledError, PDFPageCountError, PDFSyntaxError
) images = convert_from_path('example.pdf')
images = convert_from_bytes(open('example.pdf','rb').read())För mer information om koden kan du hänvisa till den officiella dokumentationen i https://pypi.org/project/pdf2image/
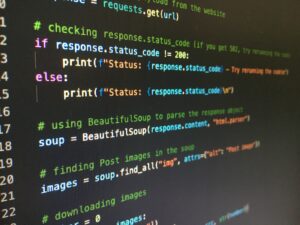
Efteråt kan du hänvisa till Google Vision API för OCR-hämtning. Stora företag som Google och Amazon gynnas av den massiva crowdsourcingen på grund av sin stora kundbas. Därför, istället för att träna din personliga OCR, kan användningen av deras tjänster ha mycket högre noggrannhet.
Hela Google Vision API är enkelt att installera, man kan hänvisa till dess officiella vägledning om https://cloud.google.com/vision/docs/quickstart-client-libraries för den detaljerade installationsproceduren.
Följande är koden för OCR-hämtning:
def detect_document(path): """Detects document features in an image.""" from google.cloud import vision import io client = vision.ImageAnnotatorClient() with io.open(path, 'rb') as image_file: content = image_file.read() image = vision.Image(content=content) response = client.document_text_detection(image=image) for page in response.full_text_annotation.pages: for block in page.blocks: print('nBlock confidence: {}n'.format(block.confidence)) for paragraph in block.paragraphs: print('Paragraph confidence: {}'.format( paragraph.confidence)) for word in paragraph.words: word_text = ''.join([ symbol.text for symbol in word.symbols ]) print('Word text: {} (confidence: {})'.format( word_text, word.confidence)) for symbol in word.symbols: print('tSymbol: {} (confidence: {})'.format( symbol.text, symbol.confidence)) if response.error.message: raise Exception( '{}nFor more info on error messages, check: ' 'https://cloud.google.com/apis/design/errors'.format( response.error.message))Observera att document_text_detection är en av funktionerna de erbjöd som är specialiserade på mycket komprimerade texter som oftast förekommer i PDF-filer. Om din PDF har ord som är något mer knapphändig, kan det vara bättre att använda deras andra textdetekteringsfunktion som fokuserar mer på in-the-wild bilder. Fler koder angående användningen av Google API kan hämtas här: https://cloud.google.com/vision; du kan också referera till koder på andra språk (t.ex. Java) om du är mer bekant med dem.
Det finns också andra OCR-tjänster/API:er från Amazon och Microsoft, och du kan alltid använda PyTesseract bibliotek för att träna på din modell för specifika ändamål.
Handledning Del 2 – CSV-export
CSV-export från Python är den sista och kanske enklare delen av hela processen. I Python, när din data lagras som listor kanske som följande:
# field names fields = ['FirstName', 'Surname', 'Year', 'CGPA'] # data rows rows = [ ['Nikhil', 'John', '2', '9.0'], ['Sam', 'Cheng', '2', '9.1'], ['Adi', 'Travolta', '2', '9.3'], ['Lorenzo', 'Thomas', '1', '9.5'], ['Stuart', 'Ali', '3', '7.8'], ['Saz', 'TY', '2', '9.1']] Du kan helt enkelt lägga in dem i CSV-filer via en CSV-skribent så här:
with open('people.csv', 'w') as f: write = csv.writer(f) write.writerow(fields) write.writerows(rows)Om du kör koden kommer du att ha en people.csv-fil i katalogen, som du direkt kan öppna den med Excel för vidare bearbetning.
Du kan också använda f = öppen... följt av f.close() om det finns mycket bearbetning mellan skrivningen av rader.
Behöver du en gratis OCR online för att extrahera och konvertera tabeller från PDF-filer, bilder till Excel? Kolla in Nanonets och bygg anpassade OCR-modeller och extrahera/konvertera tabeller till Excel gratis!
Lösningar på marknaden
Fler och fler företag hoppas nu kunna omvandla sina datakonverteringsprocesser till automatiserade pipelines. Därför erbjuder många företag (t.ex. Google, Amazon) nu API:er för att utföra sådana uppgifter. Här listar vi några populära lösningar som erbjuder OCR och tabelldetektering och deras för- och nackdelar:
*Sidoanmärkning: Det finns flera OCR-tjänster som är inriktade på uppgifter som bilder i naturen. Vi hoppade över dessa tjänster eftersom vi för närvarande fokuserar på att endast läsa PDF-dokument.
- Googles API — Googles oslagbara resultat inom datautvinning beror på den massiva crowdsourcingen av datamängder från deras sökmotor. De erbjuder gratis provperioder för personligt bruk men priset ökar snart när samtalen stiger till affärsskala.
- Djupläsare — Deep Reader är ett forskningsarbete som publicerades i ACCV Conference 2019. Det använder flera toppmoderna nätverksarkitekturer för att utföra uppgifter som dokumentmatchning, texthämtning och försämring av bilder. Det finns ytterligare funktioner som tabeller och nyckel-värde-par-extraktioner som gör att data kan hämtas och sparas på ett organiserat sätt.
- Nanonetter — Med ett mycket skickligt team för djupinlärning är Nanonets PDF OCR helt mall- och regeloberoende. Därför kan Nanonets inte bara fungera på specifika typer av PDF-filer, det kan också appliceras på vilken dokumenttyp som helst för texthämtning. Uppgifter som att extrahera tabeller är också inbyggda, vilket möjliggör flexibel men mycket exakt hämtning från alla typer av dokument.
Nanonetter — Enkelt men ändå elegant
En av höjdpunkterna med Nanonets är den enkelhet tjänsten ger. Man kan välja dessa tjänster utan någon programmeringsbakgrund och enkelt extrahera tabelldata med den senaste tekniken. Följande är en kort beskrivning av hur lätt det är att komma åt Nanonets för att konvertera tabeller från PDF-filer till Excel:
steg 1
Gå till nanonets.com och registrera/logga in.

steg 2
Efter registrering, gå till området "Välj att komma igång", där alla förbyggda extraktorer är gjorda och klicka på fliken "Tabell" för extraktorn som är utformad för att extrahera tabelldata.

steg 3
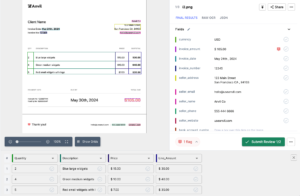
Efter några sekunder dyker sidan för extraktdata upp och säger att den är klar. Ladda upp filen för extraktion.

steg 4
Efter bearbetning kan Nanonets extrahera all tabellinformation korrekt, till och med hoppa över de tomma utrymmena!

Behöver du en gratis OCR online för att extrahera och konvertera tabeller från PDF-filer, bilder till Excel? Kolla in Nanonets och bygg anpassade OCR-modeller och extrahera/konvertera tabeller till Excel gratis!
Slutsats
Den här artikeln ger några insikter i processen att extrahera och konvertera tabeller från PDF-filer och ytterligare exportera dem till CSV-filer för att öppna via Excel. De två handledningarna fungerar förhoppningsvis som en ingång till hur mycket bekvämlighet en sådan automatiserad process kan ge.
- '
- "
- 2019
- 7
- 9
- tillgång
- Annat
- sikta
- Alla
- tillåta
- amason
- api
- API: er
- tillämpningar
- arkitektur
- OMRÅDE
- Artikeln
- artificiell intelligens
- Konstgjord intelligens och maskininlärning
- Automatiserad
- Svart
- SLUTRESULTAT
- företag
- företag
- karaktärigenkänning
- klassificering
- cloud
- koda
- Gemensam
- Företag
- företag
- Computer Software
- Datorsyn
- datorer
- Konferens
- förtroende
- innehåll
- Konvertering
- Företag
- Crowdsourcing
- Aktuella
- datum
- djupt lärande
- Designa
- Detektering
- Utveckling
- dokument
- Tidig
- kant
- anställda
- excel
- export
- extraktion
- Funktioner
- Fed
- Fält
- finansiella
- Förnamn
- format
- Fri
- fungera
- framtida
- god
- GPU
- här.
- Hög
- Markera
- Hur ser din drömresa ut
- HTTPS
- bild
- info
- informationen
- insikter
- Intelligens
- IT
- java
- Nyckel
- Arbetsmarknad
- Språk
- Large
- inlärning
- Led
- Hävstång
- Bibliotek
- Lista
- listor
- maskininlärning
- större
- Framställning
- marknad
- Medium
- Microsoft
- modell
- namn
- nät
- nätverk
- neural
- neurala nätverk
- neurala nätverk
- Objektdetektion
- OCR
- erbjudanden
- Erbjudanden
- tjänsteman
- nätet
- öppet
- optisk teckenigenkänning
- Övriga
- Personer
- Populära
- kraft
- förutsägelse
- pris
- Programmering
- Python
- höja
- Läsare
- Läsning
- skäl
- Registrering
- forskning
- respons
- Resultat
- Körning
- Skala
- scanning
- Sök
- sökmotor
- Tjänster
- inställning
- Enkelt
- So
- Mjukvara
- Lösningar
- framgångsrik
- system
- tekniker
- Teknologi
- Utbildning
- handledning
- självstudiekurser
- us
- värde
- syn
- W
- inom
- ord
- Arbete
- författare
- skrivning
- år