Bild av Freepik
Conversational AI hänvisar till virtuella agenter och chatbots som efterliknar mänskliga interaktioner och kan engagera människor i konversation. Att använda konversations-AI håller snabbt på att bli en livsstil – från att fråga Alexa till "hitta närmaste restaurang” att be Siri att "skapa en påminnelse" virtuella assistenter och chatbots används ofta för att svara på konsumenternas frågor, lösa klagomål, göra reservationer och mycket mer.
Att utveckla dessa virtuella assistenter kräver stor ansträngning. Men att förstå och ta itu med de viktigaste utmaningarna kan effektivisera utvecklingsprocessen. Jag har använt min förstahandserfarenhet av att skapa en mogen chatbot för en rekryteringsplattform som en referenspunkt för att förklara viktiga utmaningar och deras motsvarande lösningar.
För att bygga en AI-chatbot för konversation kan utvecklare använda ramverk som RASA, Amazons Lex eller Googles Dialogflow för att bygga chatbotar. De flesta föredrar RASA när de planerar anpassade ändringar eller boten är i det mogna stadiet eftersom det är ett ramverk med öppen källkod. Andra ramar är också lämpliga som utgångspunkt.
Utmaningarna kan klassificeras som tre huvudkomponenter i en chatbot.
Naturligt språkförståelse (NLU) är en bots förmåga att förstå mänsklig dialog. Den utför avsiktsklassificering, enhetsextraktion och hämtar svar.
Dialogansvarig är ansvarig för en uppsättning åtgärder som ska utföras baserat på den nuvarande och tidigare uppsättningen av användarinmatningar. Den tar avsikt och entiteter som input (som en del av föregående konversation) och identifierar nästa svar.
Generering av naturligt språk (NLG) är processen att generera skrivna eller talade meningar från given data. Det ramar in svaret, som sedan presenteras för användaren.
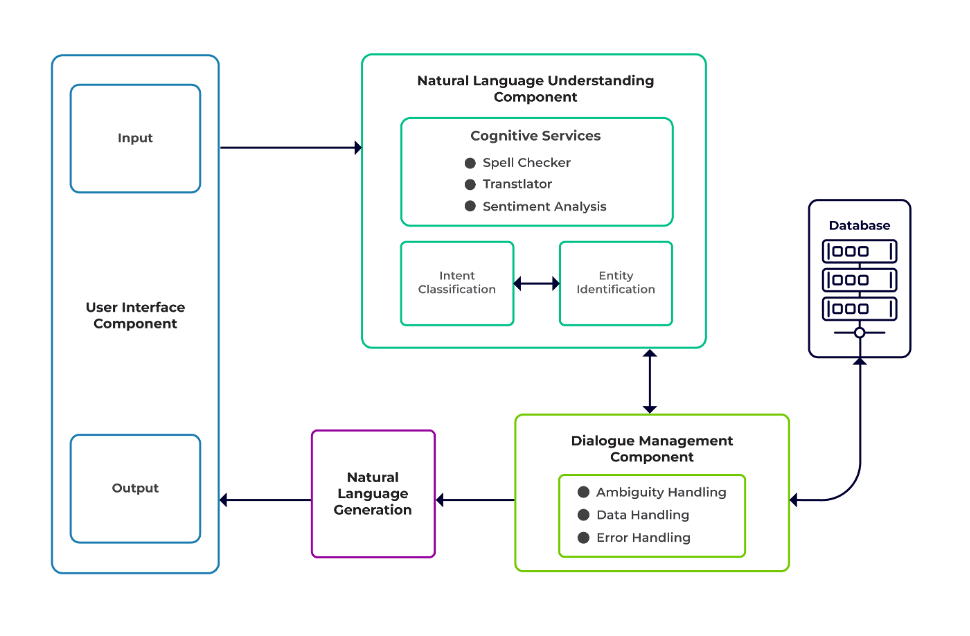
Bild från Talentica Software
Otillräcklig data
När utvecklare ersätter vanliga frågor eller andra supportsystem med en chatbot får de en anständig mängd träningsdata. Men detsamma händer inte när de skapar boten från början. I sådana fall genererar utvecklare träningsdata syntetiskt.
Vad göra?
En mallbaserad datagenerator kan generera en anständig mängd användarfrågor för utbildning. När chatboten är klar kan projektägare exponera den för ett begränsat antal användare för att förbättra träningsdata och uppgradera den under en period.
Olämpligt modellval
Lämplig modellval och träningsdata är avgörande för att få bästa resultat för avsikts- och enhetsextraktion. Utvecklare tränar vanligtvis chatbots på ett specifikt språk och en viss domän, och de flesta av de tillgängliga förtränade modellerna är ofta domänspecifika och tränade på ett enda språk.
Det kan också finnas fall av blandade språk där människor är polyglotta. De kan skriva in frågor på ett blandat språk. Till exempel, i en franskdominerad region kan människor använda en typ av engelska som är en blandning av både franska och engelska.
Vad göra?
Att använda modeller som är utbildade på flera språk kan minska problemet. En förtränad modell som LaBSE (Language-agnostic Bert sentence inbäddning) kan vara till hjälp i sådana fall. LaBSE är utbildad i mer än 109 språk på en meningslikhetsuppgift. Modellen kan redan liknande ord på ett annat språk. I vårt projekt fungerade det riktigt bra.
Felaktig utvinning av entitet
Chatbots kräver att enheter identifierar vilken typ av data användaren söker. Dessa entiteter inkluderar tid, plats, person, objekt, datum, etc. Bots kan dock misslyckas med att identifiera en entitet från naturligt språk:
Samma sammanhang men olika enheter. Till exempel kan bots förväxla en plats som en enhet när en användare skriver "Namn på studenter från IIT Delhi" och sedan "Namn på studenter från Bengaluru."
Scenarier där enheterna är felförutsägda med lågt självförtroende. Till exempel kan en bot identifiera IIT Delhi som en stad med lågt självförtroende.
Partiell enhetsextraktion genom maskininlärningsmodell. Om en användare skriver "studenter från IIT Delhi" kan modellen bara identifiera "IIT" endast som en enhet istället för "IIT Delhi."
Enordsinmatningar som inte har något sammanhang kan förvirra maskininlärningsmodellerna. Till exempel kan ett ord som "Rishikesh" betyda både namnet på en person och en stad.
Vad göra?
Att lägga till fler träningsexempel kan vara en lösning. Men det finns en gräns efter vilken det inte skulle hjälpa att lägga till mer. Dessutom är det en oändlig process. En annan lösning kan vara att definiera regexmönster med hjälp av fördefinierade ord för att hjälpa till att extrahera enheter med en känd uppsättning möjliga värden, som stad, land, etc.
Modeller delar lägre förtroende när de inte är säkra på entitetsförutsägelse. Utvecklare kan använda detta som en utlösare för att anropa en anpassad komponent som kan korrigera den svaga enheten. Låt oss överväga exemplet ovan. Om IIT Delhi förutspås som en stad med lågt självförtroende, då kan användaren alltid söka efter den i databasen. Efter att ha misslyckats med att hitta den förutsagda enheten i Stad tabell, skulle modellen gå vidare till andra tabeller och så småningom hitta den i Institute tabell, vilket resulterar i entitetskorrigering.
Fel avsiktsklassificering
Varje användarmeddelande har en avsikt kopplad till sig. Eftersom avsikter härleder nästa handlingssätt för en bot, är korrekt klassificering av användarfrågor med avsikt avgörande. Utvecklare måste dock identifiera avsikter med minimal förvirring mellan avsikter. Annars kan det uppstå fall av förvirring. Till exempel, "Visa mig lediga positioner” vs. "Visa mig lediga positionskandidater”.
Vad göra?
Det finns två sätt att skilja på förvirrande frågor. För det första kan en utvecklare införa underavsikt. För det andra kan modeller hantera frågor baserade på identifierade enheter.
En domänspecifik chatbot bör vara ett slutet system där den tydligt ska identifiera vad den kan och inte är kapabel till. Utvecklare måste göra utvecklingen i faser samtidigt som de planerar för domänspecifika chatbots. I varje fas kan de identifiera chatbotens funktioner som inte stöds (via avsikter som inte stöds).
De kan också identifiera vad chatboten inte kan hantera i avsikt "utanför räckvidden". Men det kan finnas fall där boten är förvirrad utan stöd och avsikt utanför räckvidden. För sådana scenarier bör en reservmekanism finnas på plats där, om avsiktsförtroendet ligger under ett tröskelvärde, modellen kan arbeta elegant med en reservuppsåt för att hantera förvirringsfall.
När boten identifierar syftet med en användares meddelande måste den skicka ett svar tillbaka. Bot bestämmer svaret baserat på en viss uppsättning definierade regler och berättelser. Till exempel kan en regel vara så enkel som fullkomlig "god morgon" när användaren hälsar "Hej". Men oftast omfattar konversationer med chatbots uppföljande interaktion, och deras svar beror på konversationens övergripande kontext.
Vad göra?
För att hantera detta matas chatbots med riktiga konversationsexempel som kallas Stories. Användare interagerar dock inte alltid som avsett. En mogen chatbot bör hantera alla sådana avvikelser på ett elegant sätt. Designers och utvecklare kan garantera detta om de inte bara fokuserar på en lycklig väg när de skriver berättelser utan också arbetar på olyckliga vägar.
Användarnas engagemang med chatbots är starkt beroende av chatbot-svaren. Användare kan tappa intresset om svaren är för robotiserade eller för bekanta. Till exempel kanske en användare inte gillar ett svar som "Du har skrivit fel fråga" för en felaktig inmatning även om svaret är korrekt. Svaret här stämmer inte överens med en assistents persona.
Vad göra?
Chatboten fungerar som en assistent och bör ha en specifik persona och tonfall. De ska vara välkomnande och ödmjuka, och utvecklare bör utforma konversationer och yttranden därefter. Svaren ska inte låta robotiska eller mekaniska. Till exempel kan boten säga, "Tyvärr, det verkar som att jag inte har några detaljer. Kan du snälla skriva in din fråga igen?" för att åtgärda en felaktig inmatning.
LLM (Large Language Model) baserade chatbots som ChatGPT och Bard är spelförändrande innovationer och har förbättrat kapaciteten hos konversations-AI: er. De är inte bara bra på att göra öppna mänskliga konversationer utan kan utföra olika uppgifter som textsammanfattning, styckeskrivning, etc., som tidigare bara kunde uppnås med specifika modeller.
En av utmaningarna med traditionella chatbot-system är att kategorisera varje mening i avsikter och bestämma svaret därefter. Detta tillvägagångssätt är inte praktiskt. Svar som "Förlåt, jag kunde inte få dig" är ofta irriterande. Avsiktslösa chatbotsystem är vägen framåt, och LLM:er kan göra detta till verklighet.
LLM:er kan enkelt uppnå toppmoderna resultat i allmänt namngiven enhetsigenkänning med undantag för viss domänspecifik enhetsigenkänning. Ett blandat tillvägagångssätt för att använda LLM med alla chatbot-ramverk kan inspirera till ett mer moget och robust chatbotsystem.
Med de senaste framstegen och kontinuerlig forskning inom konversations-AI blir chatbots bättre för varje dag. Områden som att hantera komplexa uppgifter med flera avsikter, som "Boka ett flyg till Mumbai och ordna en taxi till Dadar", får mycket uppmärksamhet.
Snart kommer personliga samtal att äga rum baserat på användarens egenskaper för att hålla användaren engagerad. Till exempel, om en bot upptäcker att användaren är missnöjd, omdirigerar den konversationen till en riktig agent. Dessutom, med ständigt ökande chatbot-data, kan djupinlärningstekniker som ChatGPT automatiskt generera svar för frågor med hjälp av en kunskapsbas.
Suman Saurav är en dataforskare på Talentica Software, ett företag för utveckling av mjukvaruprodukter. Han är en alumn från NIT Agartala med över 8 års erfarenhet av att designa och implementera revolutionerande AI-lösningar med hjälp av NLP, Conversational AI och Generative AI.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.kdnuggets.com/3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them?utm_source=rss&utm_medium=rss&utm_campaign=3-crucial-challenges-in-conversational-ai-development-and-how-to-avoid-them
- : har
- :är
- :inte
- :var
- 8
- a
- förmåga
- Om oss
- ovan
- i enlighet med detta
- Uppnå
- uppnås
- tvärs
- åtgärder
- tillsats
- Dessutom
- adress
- adresse
- framsteg
- Efter
- Recensioner
- medel
- AI
- AI chatbot
- alexa
- Alla
- redan
- också
- alumn
- alltid
- mängd
- an
- och
- Annan
- svara
- vilken som helst
- tillvägagångssätt
- ÄR
- områden
- AS
- be
- Assistent
- assistenter
- associerad
- At
- uppmärksamhet
- automatiskt
- tillgänglig
- undvika
- tillbaka
- bas
- baserat
- BE
- passande
- varelser
- nedan
- BÄST
- Bättre
- Bot
- båda
- botar
- SLUTRESULTAT
- men
- by
- Ring
- kallas
- KAN
- kan inte
- kapacitet
- kapabel
- fall
- kategorisera
- vissa
- utmaningar
- Förändringar
- egenskaper
- chatbot
- chatbots
- ChatGPT
- Stad
- klassificering
- klassificerad
- klart
- stängt
- företag
- klagomål
- komplex
- komponent
- komponenter
- förstå
- förtroende
- förväxlas
- förvirrande
- förvirring
- Tänk
- sammanhang
- kontinuerlig
- Konversation
- konversera
- konversations AI
- konversationer
- korrekt
- korrekt
- Motsvarande
- kunde
- land
- Naturligtvis
- skapa
- Skapa
- avgörande
- Aktuella
- beställnings
- datum
- datavetare
- Databas
- Datum
- dag
- anständiga
- Avgörande
- djup
- djupt lärande
- definiera
- definierade
- delhi
- bero
- härleda
- Designa
- konstruktörer
- design
- detaljer
- Utvecklare
- utvecklare
- Utveckling
- dialogflöde
- dialog
- olika
- skilja
- do
- inte
- domän
- inte
- varje
- Tidigare
- lätt
- ansträngning
- inbäddning
- Endless
- engagera
- ingrepp
- ingrepp
- Engelska
- förbättra
- ange
- enheter
- enhet
- etc
- Även
- så småningom
- ständigt ökande
- Varje
- varje dag
- exempel
- exempel
- erfarenhet
- Förklara
- extrahera
- extraktion
- MISSLYCKAS
- inte
- bekant
- SNABB
- Funktioner
- Fed
- hitta
- fynd
- flyg
- Fokus
- För
- Framåt
- Ramverk
- ramar
- franska
- från
- Allmänt
- generera
- generera
- generering
- generativ
- Generativ AI
- Generatorn
- skaffa sig
- få
- ges
- god
- Googles
- garanti
- hantera
- Arbetsmiljö
- hända
- lyckligt
- Har
- har
- he
- kraftigt
- hjälpa
- hjälp
- här.
- Hur ser din drömresa ut
- How To
- Men
- HTTPS
- humant
- ringa
- i
- identifierade
- identifierar
- identifiera
- if
- genomföra
- förbättras
- in
- innefattar
- innovationer
- ingång
- ingångar
- inspirerar
- exempel
- istället
- avsedd
- uppsåt
- interagera
- interaktion
- interaktioner
- intresse
- in
- införa
- IT
- jpg
- bara
- KDnuggets
- Ha kvar
- Nyckel
- Snäll
- kunskap
- känd
- vet
- språk
- Språk
- Large
- senaste
- inlärning
- livet
- tycka om
- BEGRÄNSA
- Begränsad
- förlorar
- Låg
- lägre
- Maskinen
- maskininlärning
- större
- göra
- Framställning
- Match
- mogen
- Maj..
- me
- betyda
- mekanisk
- mekanism
- meddelande
- kanske
- minimum
- Blanda
- blandad
- modell
- modeller
- mer
- Dessutom
- mest
- mycket
- multipel
- Mumbai
- måste
- my
- namn
- Som heter
- Natural
- Naturligt språk
- Nästa
- NLG
- nlp
- NLU
- Nej
- antal
- of
- Ofta
- on
- gång
- endast
- öppet
- öppen källkod
- or
- Övriga
- annat
- vår
- över
- övergripande
- ägare
- del
- bana
- banor
- mönster
- Personer
- utföra
- utfört
- utför
- perioden
- personen
- personlig
- fas
- Faserna
- Plats
- Planen
- planering
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- snälla du
- Punkt
- placera
- besitter
- möjlig
- Praktisk
- förutsagda
- förutsägelse
- föredra
- presenteras
- föregående
- Problem
- Fortsätt
- process
- Produkt
- produktutveckling
- projektet
- sökfrågor
- frågor
- R
- lopp
- redo
- verklig
- Verkligheten
- verkligen
- erkännande
- rekrytering
- minska
- referens
- hänvisar
- region
- förlita
- påminnelse
- ersätta
- kräver
- Kräver
- forskning
- Lös
- respons
- svar
- ansvarig
- resulterande
- Resultat
- revolutionerande
- robusta
- Regel
- regler
- Samma
- säga
- scenarier
- Forskare
- repa
- Sök
- söka
- verkar
- Val
- sända
- mening
- serverar
- in
- Dela
- skall
- liknande
- Enkelt
- eftersom
- enda
- syria
- Mjukvara
- lösning
- Lösningar
- några
- ljud
- specifik
- talat
- Etapp
- Starta
- state-of-the-art
- Upplevelser för livet
- effektivisera
- Studenter
- väsentlig
- sådana
- lämplig
- stödja
- Stödsystem
- säker
- syntetiskt
- system
- System
- T
- bord
- Ta
- tar
- uppgift
- uppgifter
- tekniker
- text
- än
- den där
- Smakämnen
- deras
- Dem
- sedan
- Där.
- Dessa
- de
- detta
- fastän?
- tre
- tröskelvärde
- tid
- till
- TON
- Röstton
- alltför
- traditionell
- Tåg
- tränad
- Utbildning
- utlösa
- två
- Typ
- typer
- förståelse
- uppgradera
- användning
- Begagnade
- Användare
- användare
- med hjälp av
- vanligen
- Värden
- via
- Virtuell
- Röst
- vs
- W
- Sätt..
- sätt
- välkomnande
- VÄL
- Vad
- när
- närhelst
- som
- medan
- kommer
- med
- ord
- ord
- Arbete
- arbetade
- skulle
- skrivning
- skriven
- Fel
- år
- dig
- Din
- zephyrnet