Klicka för att lära dig mer om författare Kendall Clark.
Mandatet för IT att leverera affärsnytta har aldrig varit starkare. Faktiskt, 76% av cheferna anser att IT måste vara en aktiv partner i att utveckla affärsstrategin. Agility är nyckeln till framgång här. Men de flesta företag hämmas av datastrategier som lämnar team plattfota när marknaden förändras eller nya utmaningar uppstår.
Ta strukturerade datahanteringssystem, till exempel. Det här alternativet fungerade bra när företagsdatalandskapet i sig till övervägande del var strukturerat. Men världen är annorlunda nu, och företagsdatalandskapet domineras nu av hybrid, varierad och föränderlig data. Framväxten av Internet of Things (IoT), ökningen av ostrukturerad datavolym, ökande relevans för externa datakällor och trenden mot hybridmiljöer med flera moln är hinder för att tillfredsställa varje ny dataförfrågan. De gammal datastrategi, centrerad kring relationsdatasystem, är fundamentalt trasig. Så hur kan företag övergå från en reaktiv till en responsiv datastrategi?
Enterprise Data Fabrics: The Path Forward
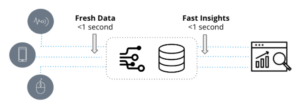
Organisationer idag funderar på att bygga en datatyg för att driva samarbetande, tvärfunktionella projekt och produkter och för att undkomma reaktiva arbetsflöden med en motståndskraftig digital grund – ingen rip-and-replace krävs. Datatyger väver samman data från interna datasilos och externa källor och skapar ett nätverk av information för att driva appar, AI och analyser. Helt enkelt stödjer de hela bredden av datautmaningar i dagens komplexa, uppkopplade företag.
Till skillnad från äldre, statiska dataintegrationstekniker är nyckelprinciperna för dataväv att de kan:
- Svara på oförutsedda frågor och anpassa dig till nya krav
- Ge data mening, vilket leder till bättre insikt
- Aktivera frågor över datasilos och externa källor, oavsett datastruktur
- Modernisera befintliga system så att ingen rip-and-replace behövs
- Anslut data vid beräkningsskiktet, inte vid lagringslagret, så att datasilos kan anslutas utan att skapa ytterligare silos
Datatyger stöder också de tvärfunktionella dataanslutningar som är nyckeln till att skapa och försvara konkurrensfördelar och möjliggöra samarbete över hela företaget och med externa partners. Ta som exempel utmaningarna kring innovation i supply chain. Konventionella datasystem för försörjningskedjan är ett relälopp, som arbetar med linjära överlämningar och siloförsedda peer-to-peer-länkar mellan systemen. Vi såg de förutsägbara resultaten när covid-19 slog till och globala leveranskedjor kollapsade. En viss påfrestning eller till och med delvis kollaps var oundviklig, men konsekvenserna förvärrades av otillräckliga datastrategier som behandlade försörjningskedjan som ett stel system. I verkligheten är försörjningskedjan ett komplext nätverk av aktörer som måste vara helt synkroniserade för att anpassa sig efter behov.
Med ett digitalt försörjningsnätverk som drivs av en dataväv kan företag svara på komplexa frågor som de tidigare var blinda för, till exempel "visa mig alla massor av råvaror och tillhörande leverantörer som är involverade i produktionen av färdig produktparti 123." Eller "hur jämför COGS för produkt A mellan dessa två regioner?" Eller "vilka tillverkare levererade råvarorna i detta kundklagomål?"
Att sy ihop ett framgångsrikt datatyg börjar med att förstå dess material
Till skillnad från andra tillvägagångssätt väver datatyger samman befintliga datahanteringssystem och applikationer. Så det är inte konstigt att datastrukturer snabbt ses som nästa steg framåt i utvecklingen av dataintegrationsutrymmet. Detta händer eftersom datastrukturer kan:
1. Avslöja dold betydelse: Datastrukturer förändrar status quo genom att leverera mening, inte bara data, över hela företaget. Denna betydelse vävs samman från många källor: data och metadata, interna och externa källor och moln och on-prem system. Meningen fångas inom och av utvidgbara, kunskapsgrafdrivna datamodeller, med all kontext på varje datatillgång fullt närvarande och tillgänglig, i maskinförståelig form. Med ett datatyg kan människor och algoritmer fatta bättre beslut, samtidigt som de minskar sannolikheten och risken för datamissbruk eller feltolkning.
2. Svara på svåra frågor: Datatyger levererar svar via kraftfulla fråge-, sök- och inlärningsmöjligheter. Snarare än en statisk enhet baserad på att flytta eller kopiera data, tillhandahåller en datavävsplattform ett dynamiskt "frågbart" datalager som samlar in svar från hela världen datasilo. Tidigare dataintegrationsstrategier byggde på att skapa en ny datamodell för att stödja varje nytt användningsfall och sedan flytta eller kopiera data för att fylla i den datamodellen. Med en dataväv är datamodeller återanvändbara, så när oförutsedda frågor uppstår är det lätt för team att anpassa sig för att möta verksamhetens behov.
3. Stödja tvärfunktionella datahanteringsprojekt: Datatyger väver samman befintliga datahanteringssystem, vilket berikar alla anslutna appar. De ersätter äldre system som samlade in eller katalogiserade ett företags tillgångar men som inte lyckades göra data användbar. Tidigare lösningar misslyckades också delvis på grund av deras oförmåga att hantera hybrid, varierad och föränderlig data men också på grund av organisatorisk pushback. Datavävnader är dock byggda för samarbete, utnyttjande och sammankoppling av befintliga tillgångar och för att driva en ny sort av tvärfunktionella datahanteringsprojekt.
Modernisera befintliga investeringar
De flesta av oss kommer ihåg hur datasjöar en gång hade löftet om att centralisera ett företags datatillgångar. Men många datasjöar misslyckas med att leverera på sin hype just för att de samlar data vid lagringsskiktet snarare än att ansluta det till beräkningsskiktet. De utnyttjar data baserat på dess plats snarare än baserat på dess affärsinnebörd. Hela premissen bakom en dataväv är att fysisk samlokalisering av data inte i sig åstadkommer dataanslutning eller ger mening eller sammanhang. Äldre generationer av lagringsbaserade integrationssystem som datalagret är faktiskt ännu mindre kapabla än datasjöar, eftersom de endast enkelt hanterar strukturerad data till att börja med, vilket lämnar de semistrukturerade och ostrukturerade datasilorna helt oadresserade och frånkopplade. Företag vände sig snabbt till datakataloger för att försöka ta itu med den förvirrande mångfalden i sina datalandskap bara för att lära sig att katalogisering ensam inte leder till ett uppkopplat företag.
Även om dessa teknologier lovade att avsluta datasilos, är sanningen att de är oundvikliga och existerar av mycket goda skäl. De möjliggör lokal kontroll och styrning när det är viktigt för en viss del av verksamheten, eftersom vissa data måste lagras åtskilda från andra data för att följa lagbestämmelser eller helt enkelt av äldre affärsskäl. Konventionell dataintegration fokuserad på eliminering
ng silos genom mastering, migration, konsolidering eller styrning. Men datatyger erbjuder ett praktiskt alternativ. Istället för att arbeta mot datasilos utnyttjar en dataväv dem utan att kräva ytterligare kopior av data. Istället för att ersätta äldre teknologier fungerar en dataväv tillsammans med befintliga investeringar och förbättrar deras användbarhet. Detta beror på att en dataväv är en arkitektonisk design som arbetar i beräkningsskiktet och fokuserar på att ansluta data varhelst den finns och därmed faktiskt förbättrar befintliga fysiskt konsoliderade datalagringstillgångar som datasjöar, datakataloger, lager, MDM och andra.
Kunskapsdiagram: The Missing Stitch to a Successful Data Fabric
Kunskapsdiagram kan representera hela mångfalden och komplexiteten hos företagsdata eftersom de fungerar som ett universellt format för mening, oavsett datakällans struktur, plats eller format. En kunskapsgraf ersätter den nuvarande mödosamma processen för att integrera företagsdata, som vanligtvis involverar extraktion, översättning, modellering, kartläggning och sedan rörliga data mellan olika applikationer. Den anpassade koden som krävs för modellering och kartläggning blir snabbt svårhanterlig i stor skala, vilket saktar ner innovations- och insiktstakten.
Kunskapsdiagram är en integrerad del av en effektiv dataväv, eftersom de skapar ett återanvändbart nätverk av kunskap och enkelt representerar data av olika strukturer och stödjer flera scheman. Genom att skapa en frågebar, återanvändbar semantisk förståelse av företags- och tredjepartsdata, fungerar kunskapsdiagram som kärnan i dataväven: berikar och accelererar befintliga investeringar och ger kritisk tillgång till affärsinsikt.
Precis som en vanlig struktur som överensstämmer med vad den än omsluter, lägger en företagsdataväv över befintliga datatillgångar och ansluter till dem via individuella trådar och väver samman dessa källor till ett enhetligt lager. Genom att göra det förstärker datastrukturer faktiskt affärsvärdet av befintliga investeringar.
- tillgång
- aktiv
- Annat
- Fördel
- AI
- algoritmer
- analytics
- tillämpningar
- appar
- runt
- tillgång
- Tillgångar
- SLUTRESULTAT
- företag
- byta
- cloud
- koda
- samverkan
- Företag
- Luktämne
- Compute
- Anslutningar
- konsolidering
- Covid-19
- Skapa
- Aktuella
- datum
- dataintegration
- datahantering
- datalagring
- datstrategi
- datalagret
- leverera
- Designa
- digital
- Mångfald
- drivande
- Effektiv
- Företag
- extraktion
- tyg
- formen
- format
- Framåt
- full
- Välgörenhet
- god
- styrning
- här.
- Hur ser din drömresa ut
- HTTPS
- Hybrid
- informationen
- Innovation
- integrerad
- integrering
- Internet
- sakernas Internet
- Investeringar
- involverade
- iot
- IT
- Nyckel
- kunskap
- Large
- leda
- LÄRA SIG
- inlärning
- Adress
- Hävstång
- lokal
- läge
- ledning
- marknad
- material
- modell
- modellering
- nät
- erbjudanden
- drift
- Alternativet
- Övriga
- Övrigt
- partnern
- Personer
- plattform
- kraft
- presentera
- Produkt
- Produktion
- Produkter
- projekt
- Lopp
- Raw
- Verkligheten
- skäl
- reglering
- Resultat
- Risk
- Skala
- Sök
- skifta
- saktar
- So
- Lösningar
- Utrymme
- status
- förvaring
- Strategi
- framgång
- framgångsrik
- leverantörer
- leverera
- leveranskedjan
- Försörjningskedjor
- stödja
- system
- System
- Tekniken
- Översättning
- avslöja
- Universell
- us
- verktyg
- värde
- volym
- Warehouse
- Weave
- inom
- fungerar
- världen