Apache Hudi är ett öppet tabellformat som ger databas- och datalagerfunktioner till datasjöar. Apache Hudi hjälper dataingenjörer att hantera komplexa utmaningar, som att hantera kontinuerligt utvecklade datauppsättningar med transaktioner samtidigt som frågeprestanda bibehålls. Dataingenjörer använder Apache Hudi för strömmande arbetsbelastningar samt för att skapa effektiva inkrementella datapipelines. Hudi tillhandahåller Tabellerna, transaktioner, effektiva upp- och borttagningar, avancerade index, tjänster för intag av streaming, data klustring och kompaktering optimeringar och samtidighetskontroll, allt samtidigt som dina data behålls i filformat med öppen källkod. Hudis avancerade prestandaoptimeringar gör analytiska arbetsbelastningar snabbare med någon av de populära frågemotorerna, inklusive Apache Spark, Presto, Trino, Hive, och så vidare.
Många AWS-kunder använde Apache Hudi på sina datasjöar som byggdes ovanpå Amazon S3 med hjälp av AWS-lim, en serverlös dataintegrationstjänst som gör det lättare att upptäcka, förbereda, flytta och integrera data från flera källor för analys, maskininlärning (ML) och applikationsutveckling. AWS limkrypare är en komponent i AWS Glue, som låter dig skapa tabellmetadata från datainnehåll automatiskt utan att kräva manuell definition av metadata.
AWS Glue-sökrobotar stöder nu Apache Hudi-tabeller, vilket förenklar antagandet av AWS limdatakatalog som katalogen för Hudi-bord. Ett typiskt användningsfall är att registrera Hudi-tabeller, som inte har en katalogtabelldefinition. Ett annat typiskt användningsfall är migrering från andra Hudi-kataloger, såsom Hive metastore. När du migrerar från andra Hudi-kataloger kan du skapa och schemalägga en AWS Glue-crawler och tillhandahålla en eller flera Amazon S3-sökvägar där Hudi-tabellfilerna finns. Du har möjlighet att tillhandahålla det maximala djupet på Amazon S3-vägar som AWS Glue-sökroboten kan korsa. Med varje körning kommer AWS Glue-sökrobotar att extrahera schema- och partitionsinformation och uppdatera AWS Glue Data Catalog med schema- och partitionsändringarna. AWS Glue-sökrobotar uppdaterar den senaste metadatafilplatsen i AWS Glue Data Catalog som AWS analytiska motorer kan använda direkt.
Med den här lanseringen kan du skapa och schemalägga en AWS Glue-crawler för att registrera Hudi-tabeller i AWS Glue Data Catalog. Du kan sedan tillhandahålla en eller flera Amazon S3-vägar där Hudi-tabellerna finns. Du har möjlighet att tillhandahålla det maximala djupet på Amazon S3-vägar som sökrobotar kan korsa. Med varje sökrobot som körs inspekterar sökroboten var och en av S3-sökvägarna och katalogiserar schemainformationen, såsom nya tabeller, raderingar och uppdateringar av scheman i AWS Glue Data Catalog. Sökrobotar inspekterar partitionsinformation och lägger till nyligen tillagda partitioner till AWS Glue Data Catalog. Sökrobotar uppdaterar också den senaste metadatafilplatsen i AWS Glue Data Catalog som AWS analytiska motorer kan använda direkt.
Det här inlägget visar hur denna nya förmåga att genomsöka Hudi-tabeller fungerar.
Hur AWS Glue Crawler fungerar med Hudi-bord
Hudi-tabeller har två kategorier, med specifika konsekvenser för var och en:
- Kopiera vid skrivning (CoW) – Data lagras i ett kolumnformat (Parquet), och varje uppdatering skapar en ny version av filer under en skrivning.
- Slå samman vid läsning (MoR) – Data lagras med en kombination av kolumnära (Parquet) och radbaserade (Avro) format. Uppdateringar loggas till radbaserade
deltafiler och komprimeras efter behov för att skapa nya versioner av kolumnfilerna.
Med CoW-datauppsättningar, varje gång det sker en uppdatering av en post, skrivs filen som innehåller posten om med de uppdaterade värdena. Med en MoR-datauppsättning, varje gång det sker en uppdatering, skriver Hudi endast raden för den ändrade posten. MoR lämpar sig bättre för skriv- eller ändringstunga arbetsbelastningar med färre läsningar. CoW lämpar sig bättre för lästunga arbetsbelastningar på data som ändras mer sällan.
Hudi tillhandahåller tre frågetyper för åtkomst till data:
- Ögonblicksbildsfrågor – Frågor som ser den senaste ögonblicksbilden av tabellen som av en given commit eller komprimeringsåtgärd. För MoR-tabeller exponerar ögonblicksbildsfrågor tabellens senaste tillstånd genom att slå samman bas- och deltafilerna för den senaste fildelen vid tidpunkten för frågan.
- Inkrementella frågor – Frågor ser bara ny data som skrivs till tabellen, eftersom en given commit eller komprimering. Detta ger effektivt förändringsströmmar för att möjliggöra inkrementella datapipelines.
- Läs optimerade frågor – För MoR-tabeller ser frågor de senaste data komprimerade. För CoW-tabeller, se frågor de senaste uppgifterna.
För kopiera-på-skriv-tabeller skapar sökrobotar en enda tabell i AWS Glue Data Catalog med ReadOptimized Serde org.apache.hudi.hadoop.HoodieParquetInputFormat.
För merge-on-read-tabeller skapar sökrobotar två tabeller i AWS Glue Data Catalog för samma tabellplats:
- En tabell med suffix
_ro, som använder ReadOptimized Serdeorg.apache.hudi.hadoop.HoodieParquetInputFormat - En tabell med suffix
_rt, som använder RealTime Serde som tillåter Snapshot-frågor:org.apache.hudi.hadoop.realtime.HoodieParquetRealtimeInputFormat
Under varje genomsökning, för varje tillhandahållen Hudi-sökväg, gör sökrobotar ett Amazon S3 list API-anrop, filter baserat på .hoodie mappar och hitta den senaste metadatafilen under den Hudi-tabellens metadatamapp.
Genomsök ett Hudi CoW-bord med hjälp av AWS Glue-crawler
Låt oss i det här avsnittet gå igenom hur man genomsöker en Hudi CoW med hjälp av AWS Glue-crawlers.
Förutsättningar
Här är förutsättningarna för denna handledning:
- Installera och konfigurera AWS-kommandoradsgränssnitt (AWS CLI).
- Skapa din S3 hink om du inte har den.
- Skapa din IAM-roll för AWS Glue om du inte har det. Du behöver
s3:GetObjectförs3://your_s3_bucket/data/sample_hudi_cow_table/. - Kör följande kommando för att kopiera Hudi-exemplet till din S3-hink. (Byta ut
your_s3_bucketmed ditt S3-hinknamn.)
Den här instruktionen vägleder dig att kopiera exempeldata, men du kan enkelt skapa alla Hudi-tabeller med AWS Glue. Läs mer i Vi introducerar inbyggt stöd för Apache Hudi, Delta Lake och Apache Iceberg på AWS Glue for Apache Spark, del 2: AWS Glue Studio Visual Editor.
Skapa en Hudi-sökrobot
I den här instruktionen skapar du sökroboten via konsolen. Utför följande steg för att skapa en Hudi-sökrobot:
- Välj på AWS Lim-konsolen crawlers.
- Välja Skapa sökrobot.
- För Namn , stiga på
hudi_cow_crawler. Välj Nästa. - Enligt Konfiguration av datakälla, välj Lägg till datakälla.
- För Datakällaväljer Hudi.
- För Inkludera hudi-tabellbanor, stiga på
s3://your_s3_bucket/data/sample_hudi_cow_table/. (Byta utyour_s3_bucketmed ditt S3-hinknamn.) - Välja Lägg till Hudi-datakälla.
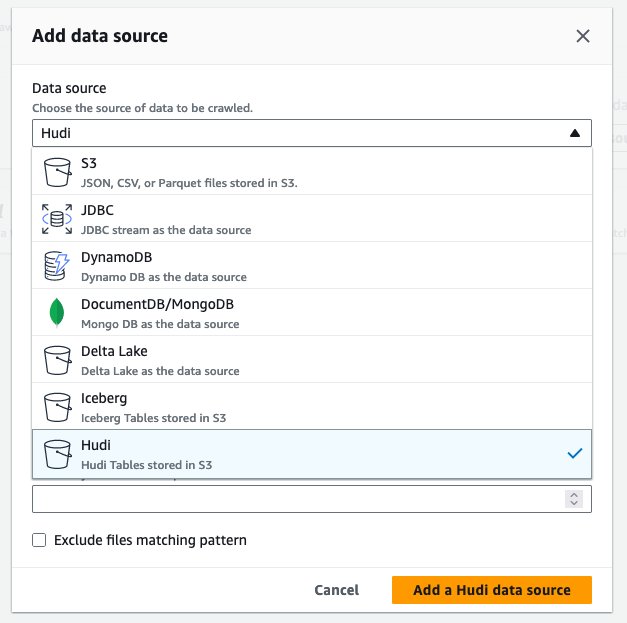
- Välja Nästa.
- För Befintlig IAM-roll, välj din IAM-roll och välj sedan Nästa.
- För Måldatabasväljer Lägg till databas, sedan Lägg till databas dialogrutan visas. För Databas namn, stiga på
hudi_crawler_blogOch välj sedan Skapa. Välj Nästa. - Välja Skapa sökrobot.
Nu har en ny Hudi-sökrobot skapats framgångsrikt. Sökroboten kan utlösas för att köra genom konsolen eller genom SDK eller AWS CLI med hjälp av StartCrawl API. Det kan också schemaläggas via konsolen för att utlösa sökrobotarna vid specifika tidpunkter. I den här instruktionen kör du sökroboten genom konsolen.
- Välja Kör sökrobot.
- Vänta tills sökroboten är klar.
Efter att sökroboten har körts kan du se Hudi-tabelldefinitionen i AWS Glue-konsolen:
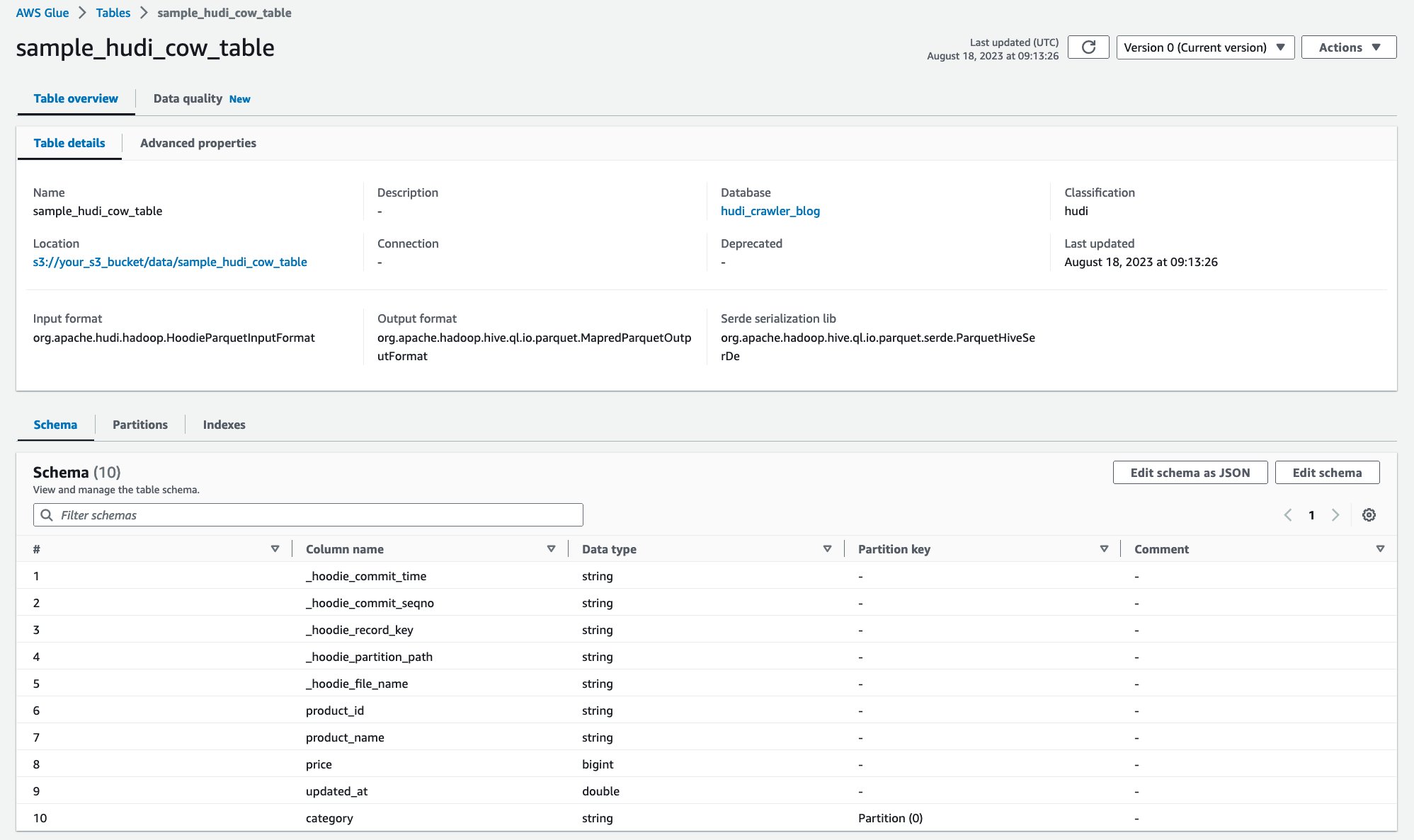
Du har framgångsrikt genomsökt Hudi CoR-tabellen med data på Amazon S3 och skapat en AWS Glue Data Catalog-tabell med schemat ifyllt. När du har skapat tabelldefinitionen i AWS Glue Data Catalog kan AWS-analystjänster som Amazon Athena fråga Hudi-tabellen.
Slutför följande steg för att starta frågor om Athena:
- Öppna Amazon Athena-konsolen.
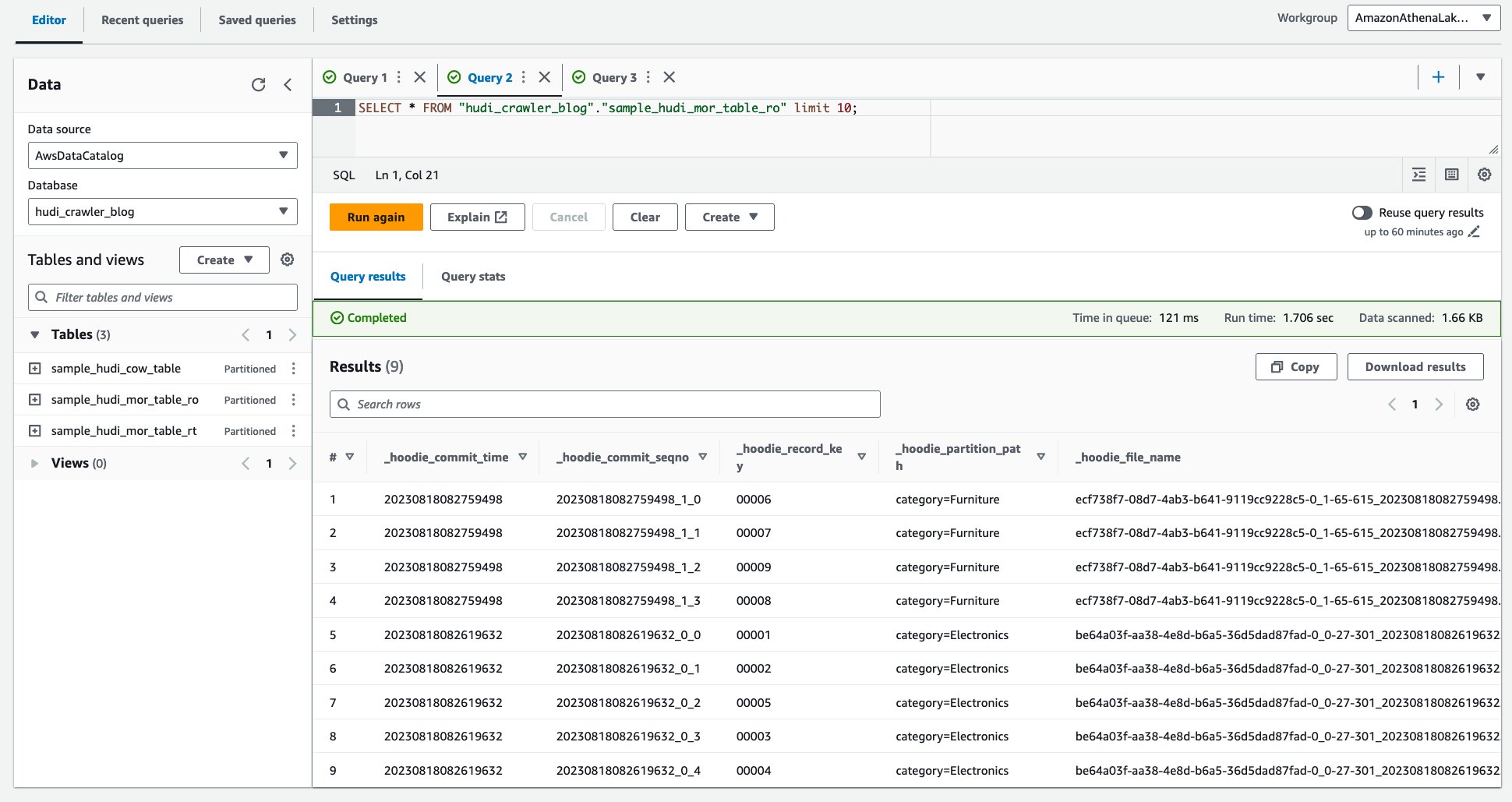
- Kör följande fråga.
Följande skärmdump visar vår produktion:
Genomsök en Hudi MoR-tabell med AWS Glue-crawler med AWS Lake Formation-databehörigheter
Låt oss i det här avsnittet gå igenom hur man genomsöker ett Hudi MoR-bord med hjälp av AWS Glue. Den här gången använder du AWS Lake Formation-databehörighet för att genomsöka Amazon S3-datakällor istället för IAM- och Amazon S3-behörighet. Detta är valfritt, men det förenklar behörighetskonfigurationer när din datasjö hanteras av AWS Lake Formation-behörigheter.
Förutsättningar
Här är förutsättningarna för denna handledning:
- Installera och konfigurera AWS-kommandoradsgränssnitt (AWS CLI).
- Skapa din S3 hink om du inte har den.
- Skapa din IAM-roll för AWS Glue om du inte har det. Du behöver
lakeformation:GetDataAccess. Men du behöver intes3:GetObjectförs3://your_s3_bucket/data/sample_hudi_mor_table/eftersom vi använder Lake Formations databehörighet för att komma åt filerna. - Kör följande kommando för att kopiera Hudi-exemplet till din S3-hink. (Byta ut
your_s3_bucketmed ditt S3-hinknamn.)
Utöver bearbetningsstegen, slutför du följande steg för att uppdatera AWS Glue Data Catalog-inställningarna för att använda Lake Formation-behörigheter för att kontrollera katalogresurser istället för IAM-baserad åtkomstkontroll:
- Logga in på Lake Formation-konsolen som datasjöadministratör.
- Om det här är första gången du använder Lake Formation-konsolen, lägg till dig själv som datasjöadministratör.
- Enligt Administrationväljer Datakataloginställningar.
- För Standardbehörigheter för nyskapade databaser och tabeller, avmarkera Använd endast IAM-åtkomstkontroll för nya databaser och Använd endast IAM-åtkomstkontroll för nya tabeller i nya databaser.
- För Versionsinställning för flera kontonväljer version 3.
- Välja Save.
Nästa steg är att registrera din S3-skopa i Lake Formations datasjöplatser:
- Välj på Lake Formation-konsolen Data sjö platser, och välj Registrera plats.
- För Amazon S3-väg, stiga på
s3://your_s3_bucket/. (Byta utyour_s3_bucketmed ditt S3-hinknamn.) - Välja Registrera plats.
Ge sedan Glue-sökrobotrollåtkomst till dataplats så att sökroboten kan använda Lake Formation-behörighet för att komma åt data och skapa tabeller på platsen:
- Välj på Lake Formation-konsolen Dataplatser Och välj Grant.
- För IAM-användare och roller, välj den IAM-roll du använde för sökroboten.
- För Lagringsplats, stiga på
s3://your_s3_bucket/data/. (Byta utyour_s3_bucketmed ditt S3-hinknamn.) - Välja Grant.
Ge sedan sökrobotrollen för att skapa tabeller under databasen hudi_crawler_blog:
- Välj på Lake Formation-konsolen Data Lake-behörigheter.
- Välja Grant.
- För Mainväljer IAM-användare och roller, och välj sökrobotrollen.
- För LF-taggar eller katalogresurserväljer Namngivna datakatalogresurser.
- För Databas, välj databasen
hudi_crawler_blog. - Enligt Databasbehörigheter, Välj Skapa tabell.
- Välja Grant.
Skapa en Hudi-sökrobot med Lake Formation-databehörigheter
Utför följande steg för att skapa en Hudi-sökrobot:
- Välj på AWS Lim-konsolen crawlers.
- Välja Skapa sökrobot.
- För Namn , stiga på
hudi_mor_crawler. Välj Nästa. - Enligt Konfiguration av datakälla, välj Lägg till datakälla.
- För Datakällaväljer Hudi.
- För Inkludera hudi-tabellbanor, stiga på
s3://your_s3_bucket/data/sample_hudi_mor_table/. (Byta utyour_s3_bucketmed ditt S3-hinknamn.) - Välja Lägg till Hudi-datakälla.
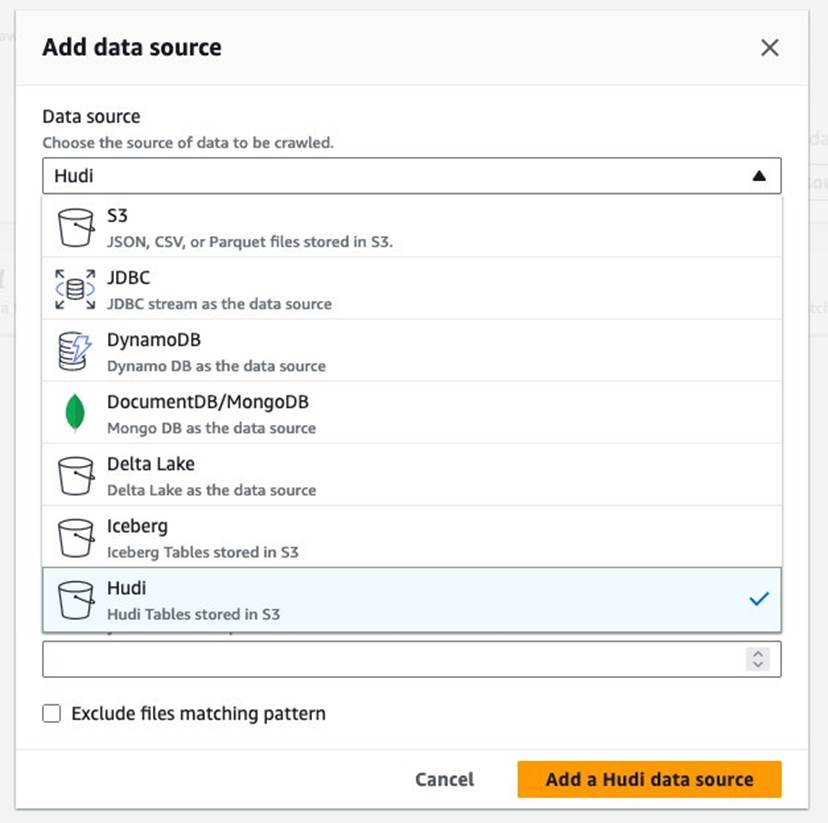
- Välja Nästa.
- För Befintlig IAM-roll, välj din IAM-roll.
- Enligt Lake Formation konfiguration – valfritt, Välj Använd Lake Formation-uppgifter för att genomsöka S3-datakällan.
- Välja Nästa.
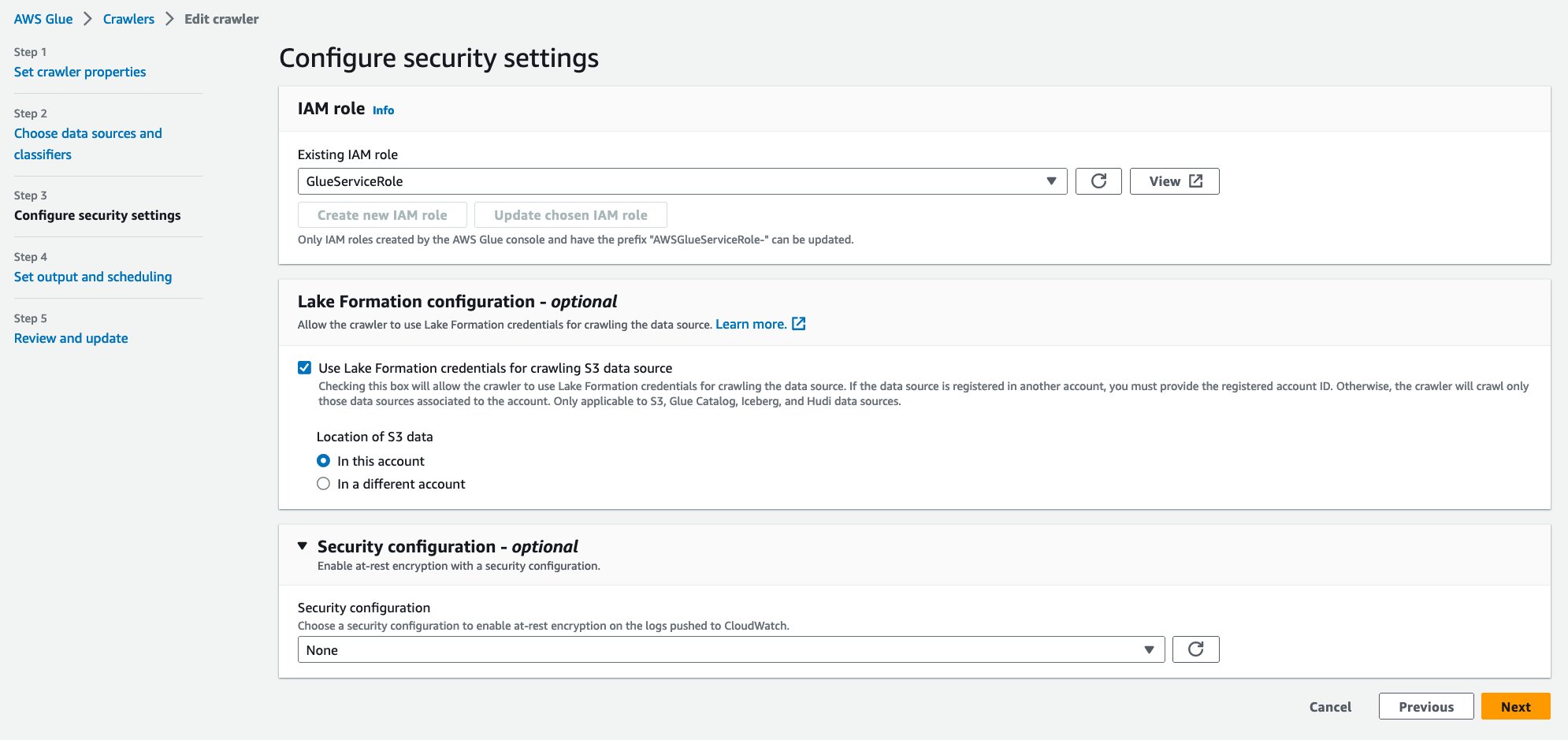
- För Måldatabasväljer
hudi_crawler_blog. Välj Nästa. - Välja Skapa sökrobot.
Nu har en ny Hudi-sökrobot skapats framgångsrikt. Sökroboten använder Lake Formation-uppgifter för att genomsöka Amazon S3-filer. Låt oss köra den nya sökroboten:
- Välja Kör sökrobot.
- Vänta tills sökroboten är klar.
Efter att sökroboten har körts kan du se två tabeller av Hudi-tabelldefinitionen i AWS Glue-konsolen:
sample_hudi_mor_table_ro(läs optimerad tabell)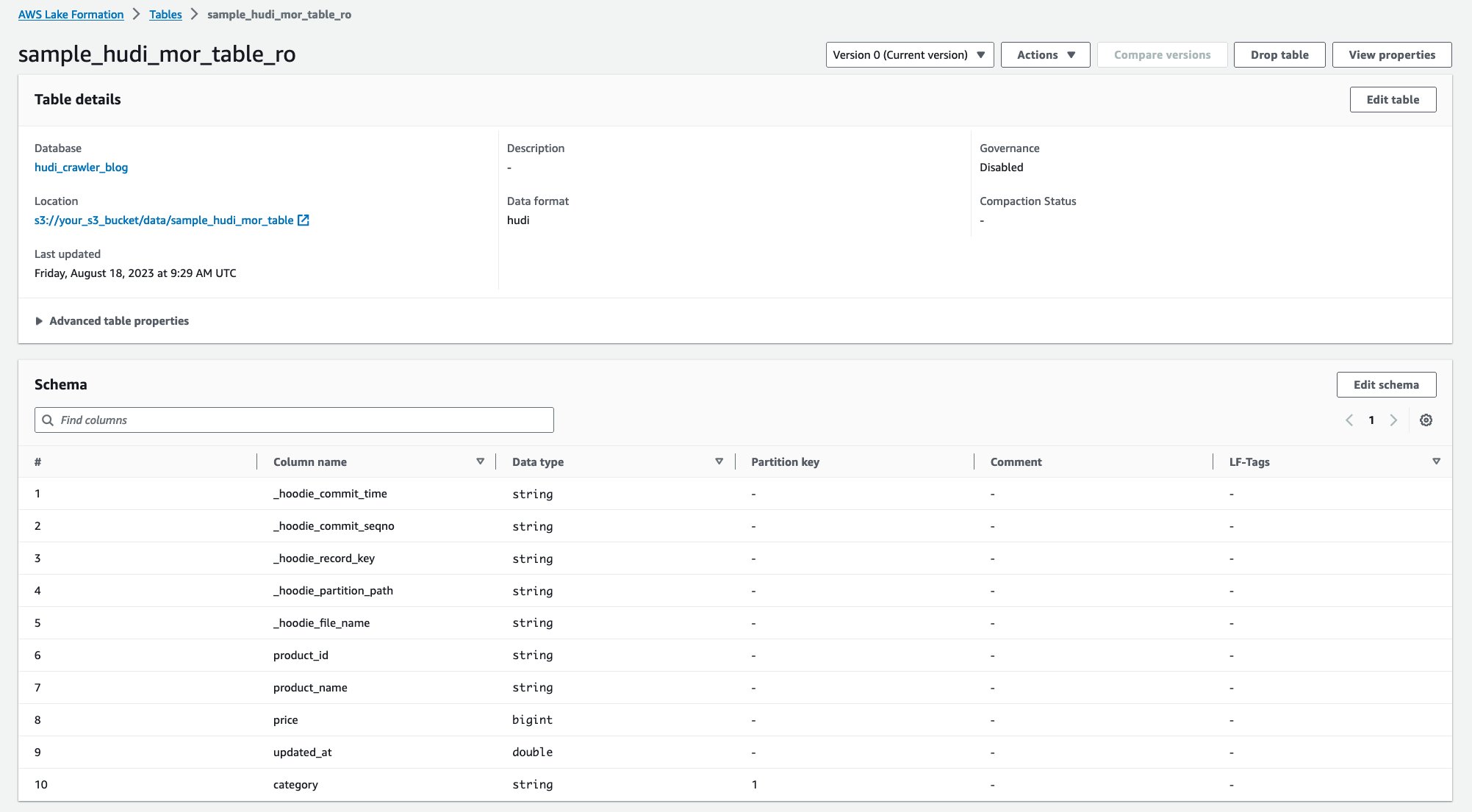
sample_hudi_mor_table_rt(realtidstabell)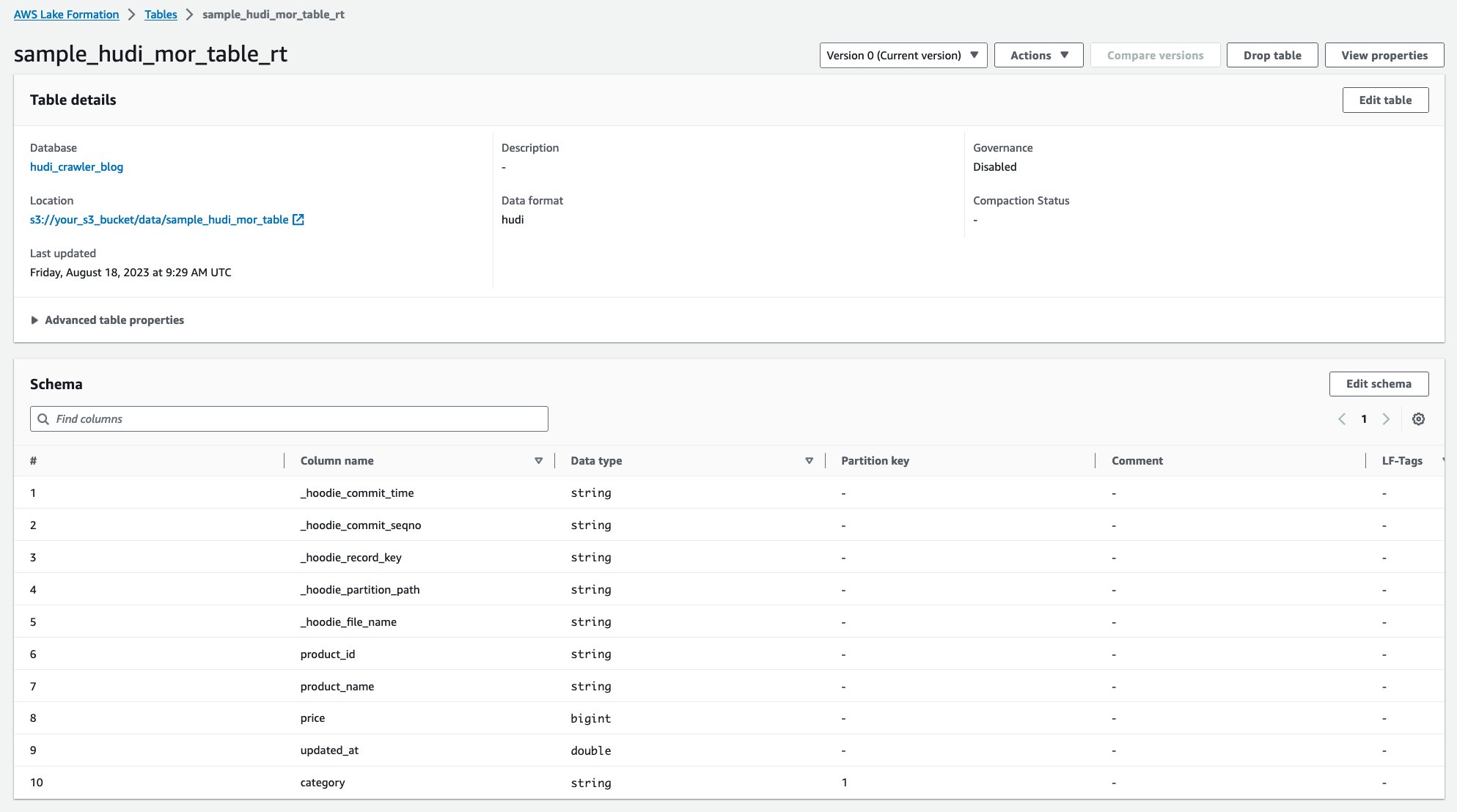
Du registrerade datalake-bucket med Lake Formation och aktiverade genomsökningsåtkomst till datasjön med Lake Formation-behörigheter. Du har framgångsrikt genomsökt Hudi MoR-tabellen med data på Amazon S3 och skapat en AWS Glue Data Catalog-tabell med schemat ifyllt. När du har skapat tabelldefinitionerna i AWS Glue Data Catalog kan AWS-analystjänster som Amazon Athena fråga Hudi-tabellen.
Slutför följande steg för att starta frågor om Athena:
- Öppna Amazon Athena-konsolen.
- Kör följande fråga.
Följande skärmdump visar vår produktion:
- Kör följande fråga.
Följande skärmdump visar vår produktion:
Finkornig åtkomstkontroll med AWS Lake Formation-behörigheter
För att tillämpa finkornig åtkomstkontroll på Hudi-bordet kan du dra nytta av AWS Lake Formation-behörigheter. Lake Formation-behörigheter tillåter dig att begränsa åtkomst till specifika tabeller, kolumner eller rader och sedan fråga Hudi-tabellerna genom Amazon Athena med finkornig åtkomstkontroll. Låt oss konfigurera Lake Formation-behörighet för Hudi MoR-tabellen.
Förutsättningar
Här är förutsättningarna för denna handledning:
- Slutför föregående avsnitt Genomsök en Hudi MoR-tabell med AWS Glue-crawler med AWS Lake Formation-databehörigheter.
- Skapa en IAM-användare DataAnalyst, som har AWS-hanterad policy AmazonAthenaFull Access.
Skapa ett datacellfilter för Lake Formation
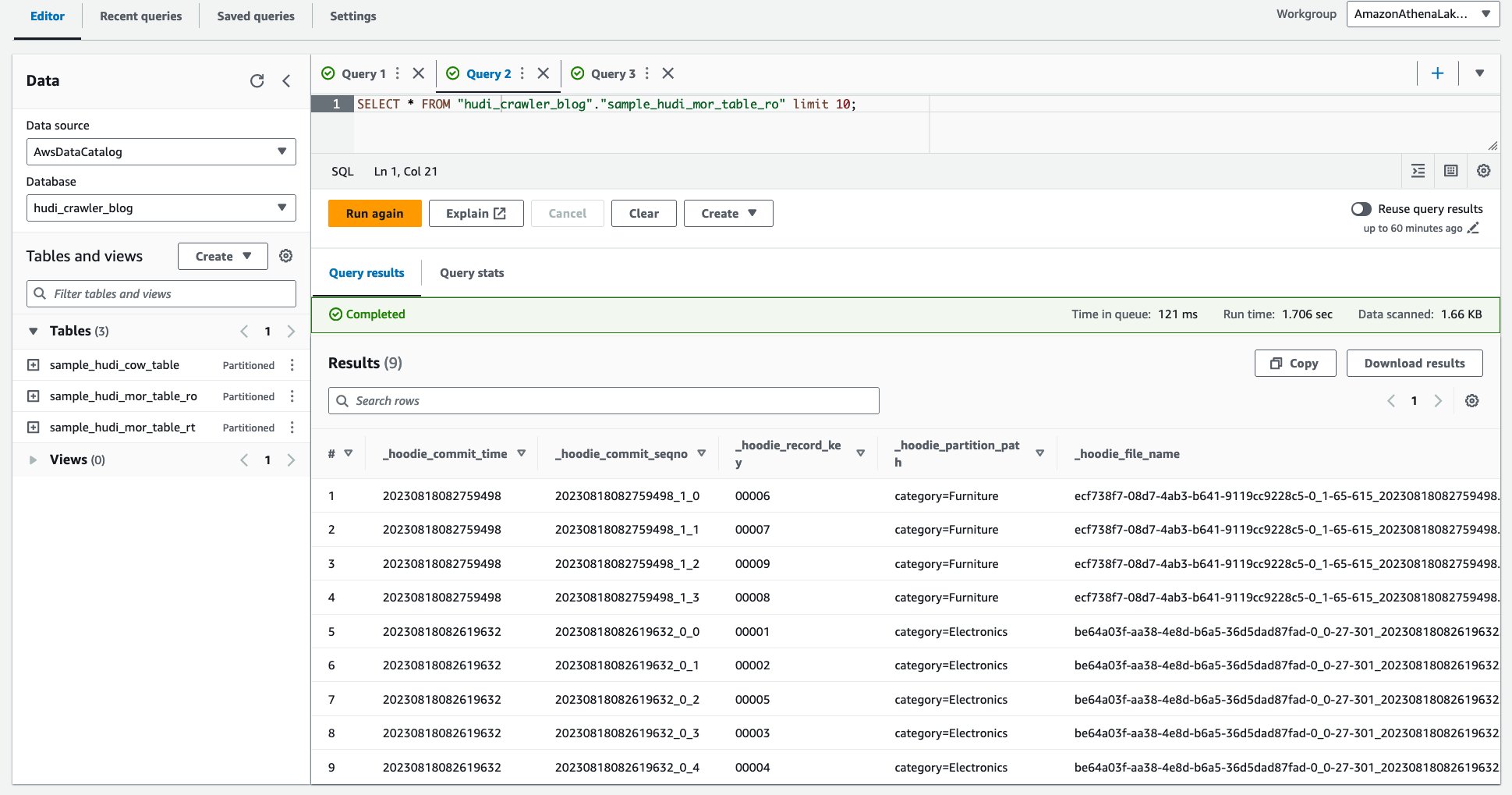
Låt oss först ställa in ett filter för den MoR-läsoptimerade tabellen.
- Logga in på Lake Formation-konsolen som datasjöadministratör.
- Välja Datafilter.
- Välja Skapa nytt filter.
- För Datafilternamn, stiga på
exclude_product_price. - För Måldatabas, välj databasen
hudi_crawler_blog. - För Måltabell, välj bordet
sample_hudi_mor_table_ro. - För Kolumnnivå åtkomst, välj Uteslut kolumner, och välj kolumnpriset.
- För Radfilteruttryck, stiga på
true. - Välja Skapa filter.
Ge Lake Formation-behörigheter till DataAnalyst-användaren
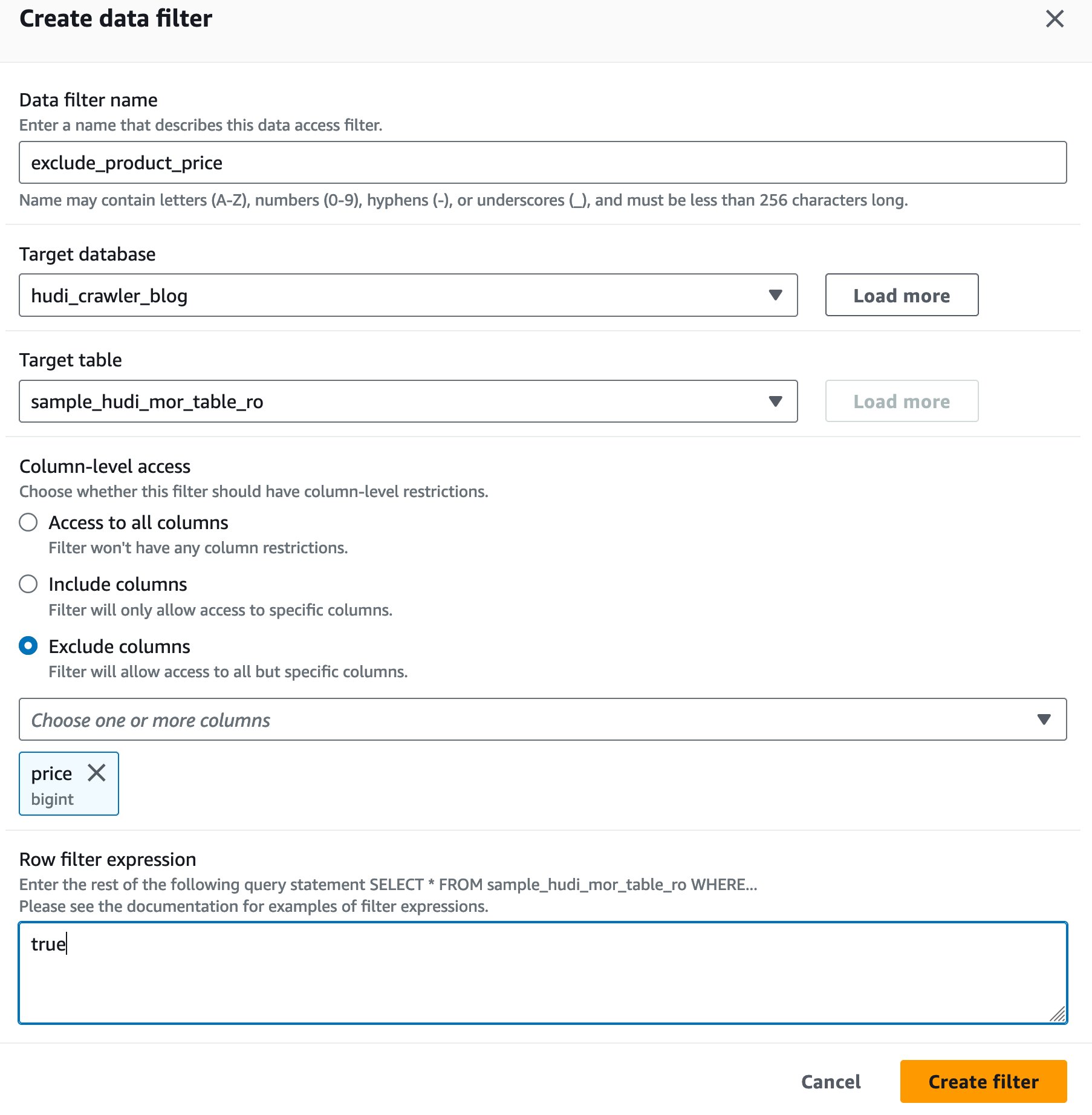
Slutför följande steg för att ge Lake Formation tillstånd till DataAnalyst användare
- Välj på Lake Formation-konsolen Data Lake-behörigheter.
- Välja Grant.
- För Mainväljer IAM-användare och roller, och välj användaren
DataAnalyst. - För LF-taggar eller katalogresurserväljer Namngivna datakatalogresurser.
- För Databas, välj databasen
hudi_crawler_blog. - För Bord – valfritt, välj bordet
sample_hudi_mor_table_ro. - För Datafilter – valfritt, Välj
exclude_product_price. - För Datafilterbehörigheter, Välj Välja.
- Välja Grant.
Du gav Lake Formation tillstånd för databasen hudi_crawler_blog och bordet sample_hudi_mor_table_ro, exklusive kolumnen price till DataAnalyst-användaren. Låt oss nu validera användaråtkomst till data med Athena.
- Logga in på Athena-konsolen som DataAnalyst-användare.
- Kör följande fråga i frågeredigeraren:
Följande skärmdump visar vår produktion:
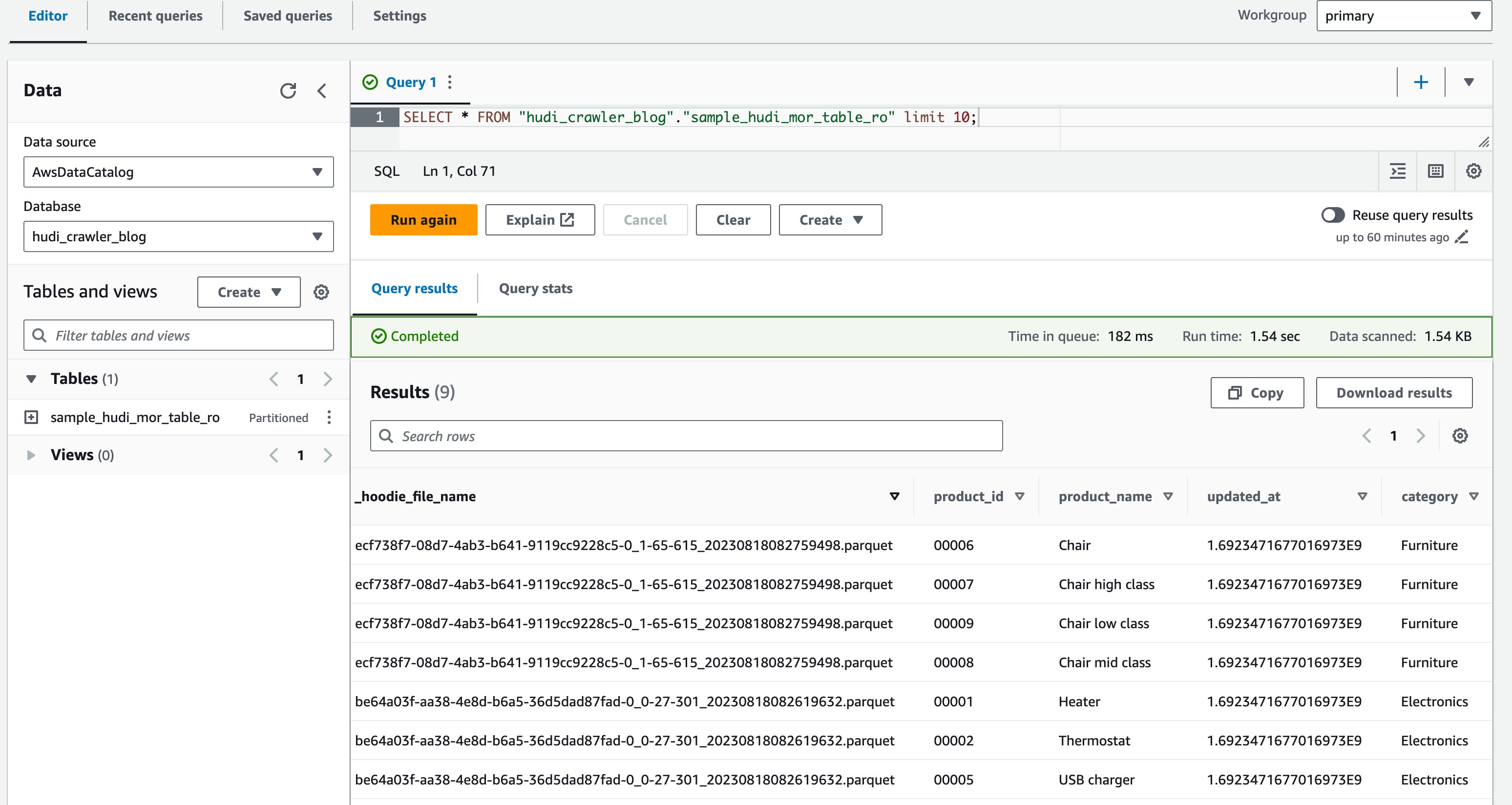
Nu har du bekräftat att kolumnen price visas inte, men de andra kolumnerna product_id, product_name, update_atoch category visas.
Städa upp
För att undvika oönskade avgifter på ditt AWS-konto, radera följande AWS-resurser:
- Ta bort AWS Glue-databas
hudi_crawler_blog. - Ta bort AWS Glue crawlers
hudi_cow_crawlerochhudi_mor_crawler. - Ta bort Amazon S3-filer under
s3://your_s3_bucket/data/sample_hudi_cow_table/ochs3://your_s3_bucket/data/sample_hudi_mor_table/.
Slutsats
Det här inlägget demonstrerade hur AWS Glue-crawlers fungerar för Hudi-bord. Med stödet för Hudi-sökroboten kan du snabbt gå över till att använda AWS Glue Data Catalog som din primära Hudi-tabellkatalog. Du kan börja bygga din serverlösa transaktionsdatasjö med Hudi på AWS med AWS Glue, AWS Glue Data Catalog och Lake Formation finkorniga åtkomstkontroller för tabeller och format som stöds av AWS analytiska motorer.
Om författarna
 Noritaka Sekiyama är en främsta Big Data Architect i AWS Glue-teamet. Han arbetar baserat i Tokyo, Japan. Han är ansvarig för att bygga mjukvaruartefakter för att hjälpa kunder. På fritiden tycker han om att cykla med sin landsvägscykel.
Noritaka Sekiyama är en främsta Big Data Architect i AWS Glue-teamet. Han arbetar baserat i Tokyo, Japan. Han är ansvarig för att bygga mjukvaruartefakter för att hjälpa kunder. På fritiden tycker han om att cykla med sin landsvägscykel.
 Kyle Duong är en mjukvaruutvecklingsingenjör i AWS Glue and Lake Formation-teamet. Han brinner för att bygga big data-teknologier och distribuerade system.
Kyle Duong är en mjukvaruutvecklingsingenjör i AWS Glue and Lake Formation-teamet. Han brinner för att bygga big data-teknologier och distribuerade system.
 Sandeep Adwankar är Senior Technical Product Manager på AWS. Baserad i California Bay Area arbetar han med kunder över hela världen för att översätta affärsmässiga och tekniska krav till produkter som gör det möjligt för kunder att förbättra hur de hanterar, säkrar och får tillgång till data.
Sandeep Adwankar är Senior Technical Product Manager på AWS. Baserad i California Bay Area arbetar han med kunder över hela världen för att översätta affärsmässiga och tekniska krav till produkter som gör det möjligt för kunder att förbättra hur de hanterar, säkrar och får tillgång till data.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/introducing-apache-hudi-support-with-aws-glue-crawlers/
- : har
- :är
- :inte
- :var
- $UPP
- 10
- 100
- 11
- 13
- 17
- 67
- 7
- 8
- 9
- a
- Able
- Om oss
- tillgång
- Tillgång till data
- åtkomst
- Konto
- Handling
- lägga till
- lagt till
- Dessutom
- antagen
- Antagande
- avancerat
- Efter
- Alla
- tillåter
- tillåta
- tillåter
- också
- amason
- Amazonas Athena
- Amazon Web Services
- an
- Analytisk
- analytics
- och
- Annan
- vilken som helst
- Apache
- Apache Spark
- api
- visas
- Ansökan
- Application Development
- Ansök
- ÄR
- OMRÅDE
- runt
- AS
- At
- automatiskt
- undvika
- AWS
- AWS-lim
- AWS Lake Formation
- bas
- baserat
- bukt
- BE
- därför att
- varit
- fördel
- Bättre
- Stor
- Stora data
- Bringar
- Byggnad
- byggt
- företag
- men
- by
- kalifornien
- Ring
- KAN
- kapacitet
- kapacitet
- Vid
- katalog
- kataloger
- kategorier
- cellen
- utmaningar
- byta
- ändrats
- Förändringar
- avgifter
- Välja
- Kolumn
- Kolonner
- kombination
- förbinda
- engagerad
- fullborda
- komplex
- komponent
- konfiguration
- Konsol
- innehåller
- innehåll
- kontinuerligt
- kontroll
- kontroller
- kunde
- sökrobot
- skapa
- skapas
- skapar
- referenser
- Kunder
- datum
- dataintegration
- datasjö
- datalagret
- Databas
- databaser
- datauppsättningar
- definition
- definitioner
- Delta
- demonstreras
- demonstrerar
- djup
- Utveckling
- direkt
- Upptäck
- distribueras
- distribuerade system
- do
- gör
- under
- varje
- lättare
- lätt
- redaktör
- effektivt
- effektiv
- möjliggöra
- aktiverad
- ingenjör
- Ingenjörer
- Motorer
- ange
- Eter (ETH)
- utvecklas
- exklusive
- extrahera
- snabbare
- färre
- Fil
- Filer
- filtrera
- filter
- hitta
- Förnamn
- första gången
- efter
- För
- format
- bildning
- ofta
- från
- ges
- globen
- Go
- bevilja
- beviljats
- Guider
- Hadoop
- Har
- he
- hjälpa
- hjälper
- hans
- Bikupa
- Hur ser din drömresa ut
- How To
- html
- HTTPS
- IAM
- if
- implikationer
- förbättra
- in
- Inklusive
- steg
- informationen
- istället
- integrera
- integrering
- Gränssnitt
- in
- införa
- IT
- Japan
- jpg
- hålla
- sjö
- sjöar
- senaste
- lansera
- LÄRA SIG
- inlärning
- mindre
- BEGRÄNSA
- linje
- Lista
- belägen
- läge
- platser
- inloggad
- Maskinen
- maskininlärning
- upprätthålla
- göra
- GÖR
- hantera
- förvaltade
- chef
- hantera
- manuell
- maximal
- sammanslagning
- metadata
- migrerande
- migration
- ML
- mer
- mest
- flytta
- multipel
- namn
- nativ
- Behöver
- behövs
- Nya
- nytt
- Nästa
- nu
- of
- on
- ONE
- endast
- öppet
- öppen källkod
- optimerad
- Alternativet
- or
- Övriga
- vår
- produktion
- del
- brinner
- bana
- banor
- prestanda
- tillstånd
- behörigheter
- plato
- Platon Data Intelligence
- PlatonData
- Populära
- befolkad
- Inlägg
- Förbered
- förutsättningar
- föregående
- pris
- primär
- Principal
- bearbetning
- Produkt
- produktchef
- Produkter
- ge
- förutsatt
- ger
- sökfrågor
- snabbt
- Läsa
- verklig
- realtid
- realtid
- senaste
- post
- registrera
- registrerat
- ersätta
- Krav
- Resurser
- ansvarig
- begränsa
- väg
- Roll
- RAD
- Körning
- Samma
- tidtabellen
- planerad
- sDK
- §
- säkra
- se
- välj
- senior
- Server
- service
- Tjänster
- in
- inställningar
- visas
- Visar
- förenklar
- eftersom
- enda
- Skiva
- Snapshot
- So
- Mjukvara
- mjukvaruutveckling
- Källa
- Källor
- Gnista
- specifik
- starta
- Ange
- Steg
- Steg
- lagras
- streaming
- strömmar
- studio
- Framgångsrikt
- sådana
- stödja
- Som stöds
- synkronisera.
- System
- bord
- grupp
- Teknisk
- Tekniken
- den där
- Smakämnen
- deras
- sedan
- Där.
- de
- detta
- tre
- Genom
- tid
- gånger
- till
- Tokyo
- topp
- transaktion
- Transaktioner
- Översätt
- korsa
- utlösa
- triggas
- handledning
- två
- typer
- typisk
- under
- oönskade
- Uppdatering
- uppdaterad
- Uppdateringar
- användning
- användningsfall
- Begagnade
- Användare
- användare
- användningar
- med hjälp av
- BEKRÄFTA
- validerade
- Värden
- version
- visuell
- Warehouse
- we
- webb
- webbservice
- VÄL
- när
- som
- medan
- VEM
- kommer
- med
- utan
- Arbete
- fungerar
- skriva
- skriven
- dig
- Din
- själv
- zephyrnet