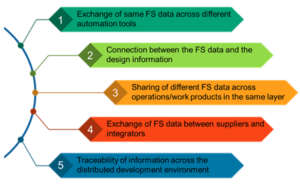
I marschen mot mer kapabla, snabbare, mindre och lägre effektsystem gav Moores lag mjukvaran en gratis resa i över 30 år eller så enbart på halvledarprocessutveckling. Compute-hårdvara levererade förbättrade prestanda/area/effektmått varje år, vilket gjorde det möjligt för mjukvara att expandera i komplexitet och leverera mer kapacitet utan nackdelar. Sedan blev de lätta vinsterna mindre lätta. Mer avancerade processer fortsatte att leverera högre gate-antal per ytenhet men ökningar i prestanda och effekt började plana ut. Eftersom våra förväntningar på innovation inte upphörde, har framsteg inom hårdvaruarkitekturen blivit viktigare för att ta upp slacket.

Drivrutiner för att öka antalet kärnor
Ett tidigt steg i denna riktning använde flerkärniga processorer för att accelerera den totala genomströmningen genom att tråda eller virtualisera en blandning av samtidiga uppgifter över kärnor, vilket minskade strömmen efter behov genom att gå på tomgång eller stänga av inaktiva kärnor. Multi-core är standard idag och en trend inom många kärnor (ännu fler processorer på ett chip) är redan uppenbar i serverinstansalternativ tillgängliga i molnplattformar från AWS, Azure, Alibaba och andra.
Fler-/mångakärniga arkitekturer är ett steg framåt, men parallellitet genom CPU-kluster är grovkornig och har sina egna prestanda- och effektgränser, tack vare Amdahls lag. Arkitekturerna blev mer heterogena och lade till acceleratorer för bild, ljud och andra specialiserade behov. AI-acceleratorer har också drivit på finkornig parallellism och flyttat till systoliska arrayer och andra domänspecifika tekniker. Vilket fungerade ganska bra tills ChatGPT dök upp med 175 miljarder parametrar med GPT-3 som utvecklades till GPT-4 med 100 biljoner parametrar – storleksordningar mer komplexa än dagens AI-system – vilket tvingar fram ännu mer specialiserade accelerationsfunktioner inom AI-acceleratorer.
På en annan front integreras nu multisensorsystem i biltillämpningar i enstaka SoCs för förbättrad miljömedvetenhet och förbättrad PPA. Här är nya nivåer av autonomi inom bilindustrin beroende av sammanslagning av ingångar från flera sensortyper inom en enda enhet, i delsystem som replikerar med 2X, 4X eller 8X.
Enligt Michał Siwinski (CMO på Arteris) antyder provtagningar under en månad av diskussioner med flera designteam över ett brett spektrum av applikationer att dessa team aktivt vänder sig till högre kärnantal för att uppfylla kapacitets-, prestanda- och kraftmål. Han berättar att de också ser denna trend accelerera. Processframsteg hjälper fortfarande till med SoC-grindräkningar, men ansvaret för att uppfylla prestanda- och effektmål ligger nu fast i händerna på arkitekterna.
Fler kärnor, mer sammankoppling
Fler kärnor på ett chip innebär fler dataanslutningar mellan dessa kärnor. Inom en accelerator mellan närliggande bearbetningselement, till lokal cache, till acceleratorer för gles matris och annan specialiserad hantering. Lägg till hierarkisk anslutning mellan acceleratorbrickor och bussar på systemnivå. Lägg till anslutningsmöjligheter för viktlagring på chipet, dekompression, sändning, insamling och omkomprimering. Lägg till HBM-anslutning för fungerande cache. Lägg till en fusionsmotor om det behövs.
Det CPU-baserade kontrollklustret måste ansluta till vart och ett av dessa replikerade delsystem och till alla vanliga funktioner – codecs, minneshantering, säkerhetsö och root of trust om så är lämpligt, UCIe om det är en implementering av flera chip, PCIe för I/O med hög bandbredd , och Ethernet eller fiber för nätverk.
Det är mycket sammankoppling, med direkta konsekvenser för produktens säljbarhet. I processer under 16nm bidrar NoC-infrastrukturen nu med 10-12% i yta. Ännu viktigare, eftersom kommunikationsmotorvägen mellan kärnor kan ha betydande inverkan på prestanda och kraft. Det finns en verklig risk att en suboptimal implementering kommer att slösa bort förväntad arkitekturprestanda och effektvinster, eller ännu värre, resultera i att många omdesignade loopar konvergerar. Men att hitta en bra implementering i en komplex SoC-planlösning beror fortfarande på långsamma trial-and-error-optimeringar i redan snäva designscheman. Vi måste ta steget till fysiskt medveten NoC-design, för att garantera full prestanda och kraftstöd från komplexa NoC-hierarkier och vi måste göra dessa optimeringar snabbare.
Fysiskt medvetna NoC-designer håller Moores lag på rätt spår
Moores lag kanske inte är död men framsteg i prestanda och kraft idag kommer från arkitektur och NoC-interconnect snarare än från process. Arkitektur driver fler acceleratorkärnor, fler acceleratorer inom acceleratorer och fler subsystemreplikering på chipet. Allt ökar komplexiteten hos chipinterconnect. När konstruktioner ökar antalet kärnor och går över till processgeometrier vid 16 nm och lägre, kan de många NoC-sammankopplingarna som spänner över SoC och dess undersystem endast stödja den fulla potentialen hos dessa komplexa konstruktioner om de implementeras optimalt mot fysiska begränsningar och tidsbegränsningar – genom fysiskt medvetna nätverk på chipdesign.
Om du också oroar dig för dessa trender kanske du vill lära dig mer om Arteris FlexNoC 5 IP-teknik HÄR.
Dela det här inlägget via:
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://semiwiki.com/artificial-intelligence/326727-interconnect-under-the-spotlight-as-core-counts-accelerate/
- :är
- $UPP
- 100
- a
- Om oss
- accelerera
- accelererande
- acceleration
- accelerator
- acceleratorer
- tvärs
- aktivt
- avancerat
- framsteg
- mot
- AI
- AI-system
- alibaba
- Alla
- tillåta
- redan
- och
- syntes
- tillämpningar
- lämpligt
- arkitektur
- ÄR
- OMRÅDE
- AS
- At
- audio
- fordonsindustrin
- tillgänglig
- medvetenhet
- AWS
- Azure
- Bandbredd
- BE
- blir
- nedan
- mellan
- Miljarder
- sända
- bussar
- by
- cache
- KAN
- kapabel
- ChatGPT
- chip
- cloud
- kluster
- CMO
- komma
- Kommunikation
- komplex
- Komplexiteten
- Compute
- konkurrent
- Kontakta
- Anslutningar
- Anslutningar
- Konsekvenser
- begränsningar
- fortsatte
- kontroll
- konvergerar
- Kärna
- CPU
- FARA
- datum
- döda
- leverera
- levereras
- beror
- Designa
- mönster
- anordning
- olika
- rikta
- riktning
- diskussioner
- ner
- nackdelar
- varje
- Tidig
- element
- Motor
- Miljö
- Även
- Varje
- Utvecklingen
- utvecklas
- Bygga ut
- förväntningar
- förväntat
- snabbare
- Funktioner
- finna
- fast
- För
- Framåt
- Fri
- från
- främre
- full
- funktioner
- sammansmältning
- resultat
- Mål
- god
- garanti
- Arbetsmiljö
- händer
- hårdvara
- Har
- hjälpa
- här.
- Hög
- högre
- Huvudväg
- HTTPS
- bild
- Inverkan
- genomförande
- genomföras
- med Esport
- förbättras
- in
- inaktiv
- Öka
- ökande
- Infrastruktur
- Innovation
- exempel
- Integrera
- IP
- ö
- IT
- DESS
- hoppa
- Lag
- LÄRA SIG
- Nivå
- nivåer
- gränser
- lokal
- Lot
- göra
- ledning
- Mars
- Matris
- max-bredd
- Möt
- möte
- Minne
- Metrics
- kanske
- Månad
- mer
- flytta
- rörliga
- multipel
- Behöver
- behövs
- behov
- nät
- nätverk
- Nya
- talrik
- of
- on
- Tillbehör
- ordrar
- Övriga
- Övrigt
- egen
- parametrar
- prestanda
- fysisk
- Fysiskt
- Plattformar
- plato
- Platon Data Intelligence
- PlatonData
- Inlägg
- potentiell
- kraft
- Strömförsörjning
- pretty
- process
- processer
- bearbetning
- Produkt
- rent
- sköt
- Tryckande
- område
- snarare
- verklig
- reducerande
- replikeras
- replikation
- ansvaret
- resultera
- Rider
- rot
- Säkerhet
- halvledare
- signifikant
- eftersom
- enda
- slak
- långsam
- mindre
- So
- Mjukvara
- gles matris
- specialiserad
- Spotlight
- standard
- igång
- Steg
- Fortfarande
- Sluta
- förvaring
- Föreslår
- stödja
- system
- System
- uppgifter
- lag
- tekniker
- Teknologi
- berättar
- den där
- Smakämnen
- Dessa
- Genom
- genomströmning
- Tidpunkten
- till
- i dag
- dagens
- Totalt
- Trend
- Trender
- Biljon
- Litar
- Vrida
- typer
- under
- enhet
- via
- vikt
- VÄL
- som
- bred
- Brett utbud
- kommer
- Vinner
- med
- inom
- arbetssätt
- år
- år
- zephyrnet