
Bild från författaren | Bing Image Creator
dolly 2.0 är en öppen källkod, instruktionsföljd, stor språkmodell (LLM) som finjusterades på en mänskligt genererad datauppsättning. Den kan användas för både forsknings- och kommersiella ändamål.
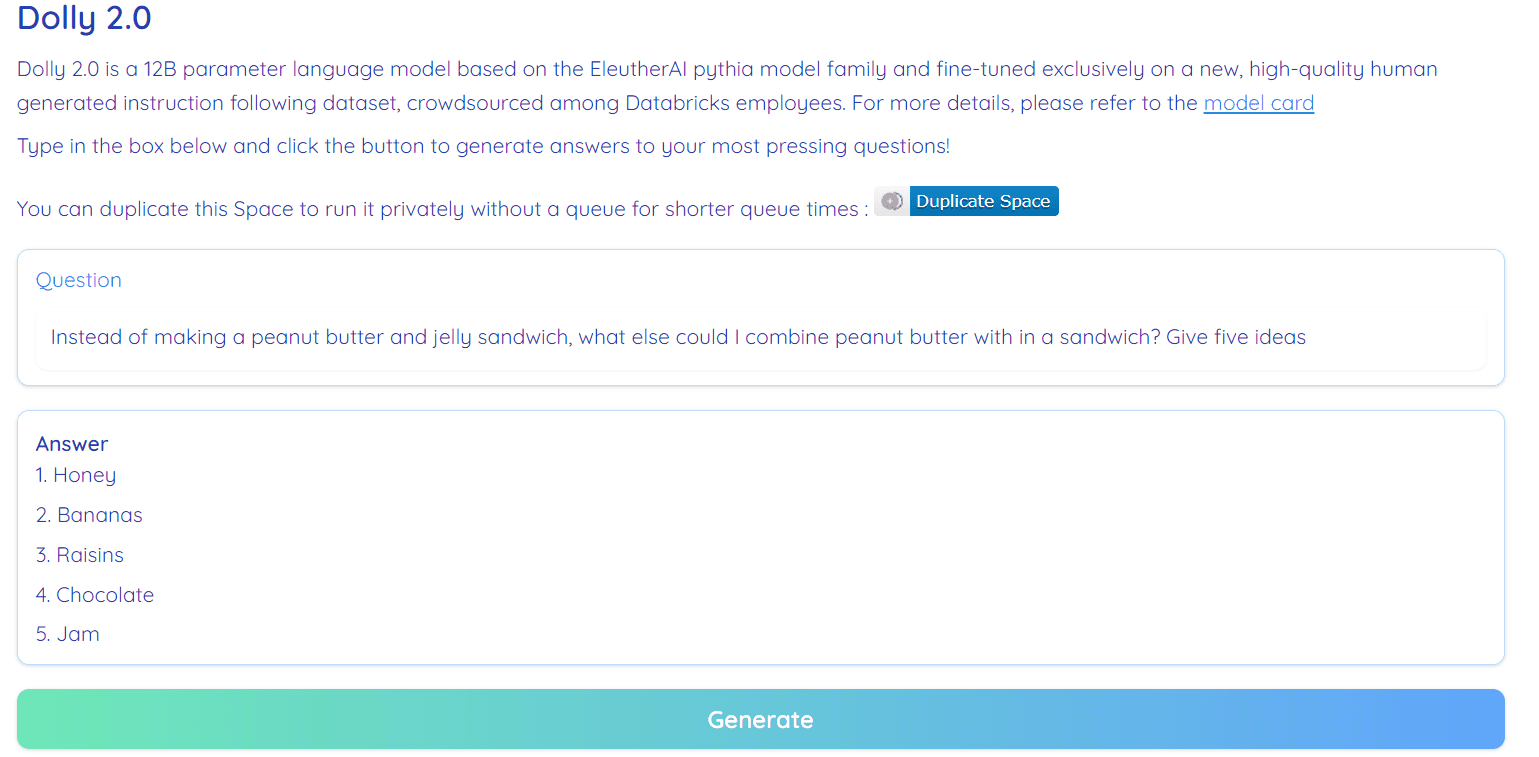
Bild från Hugging Face Space av RamAnanth1
Tidigare släppte Databricks-teamet dolly 1.0, LLM, som uppvisar ChatGPT-liknande instruktioner efter förmåga och kostar mindre än $30 att träna. Den använde Stanford Alpaca-teamdatasetet, som var under en begränsad licens (endast forskning).
Dolly 2.0 har löst det här problemet genom att finjustera 12B-parameterspråkmodellen (Pythia) på en högkvalitativ människogenererad instruktion i följande datauppsättning, som märktes av en Datbricks-anställd. Både modell och datauppsättning är tillgängliga för kommersiellt bruk.
Dolly 1.0 tränades på en Stanford Alpaca-datauppsättning, som skapades med OpenAI API. Datauppsättningen innehåller utdata från ChatGPT och hindrar någon från att använda den för att konkurrera med OpenAI. Kort sagt, du kan inte bygga en kommersiell chatbot eller språkapplikation baserad på denna datauppsättning.
De flesta av de senaste modellerna som släppts under de senaste veckorna led av samma problem, modeller som Alpacka, Koala, GPT4Alloch Vicuna. För att komma runt måste vi skapa nya högkvalitativa datamängder som kan användas för kommersiellt bruk, och det är vad Databricks-teamet har gjort med databricks-dolly-15k-datasetet.
Den nya datamängden innehåller 15,000 XNUMX högkvalitativa människomärkta prompt/svar-par som kan användas för att designa instruktionsjustering av stora språkmodeller. De databricks-dolly-15k dataset medföljer Creative Commons Erkännande-Dela Lika 3.0 Unported-licens, som tillåter vem som helst att använda den, modifiera den och skapa en kommersiell applikation på den.
Hur skapade de databricks-dolly-15k datasetet?
OpenAI-forskningen papper anger att den ursprungliga InstructGPT-modellen tränades på 13,000 13 uppmaningar och svar. Genom att använda denna information började Databricks-teamet arbeta på det, och det visade sig att det var en svår uppgift att generera 5,000 XNUMX frågor och svar. De kan inte använda syntetisk data eller AI-generativ data, och de måste generera originalsvar på varje fråga. Det är här de har beslutat att använda XNUMX XNUMX anställda hos Databricks för att skapa mänskligt genererad data.
The Databricks har arrangerat en tävling, där de 20 främsta etiketterna skulle få ett stort pris. I den här tävlingen deltog 5,000 XNUMX Databricks-anställda som var mycket intresserade av LLM
Dolly-v2-12b är inte en toppmodern modell. Den presterar sämre än dolly-v1-6b i vissa utvärderingsriktmärken. Det kan bero på sammansättningen och storleken på de underliggande finjusteringsdatauppsättningarna. Dolly-modellfamiljen är under aktiv utveckling, så du kan se en uppdaterad version med bättre prestanda i framtiden.
Kort sagt har dolly-v2-12b-modellen presterat bättre än EleutherAI/gpt-neox-20b och EleutherAI/pythia-6.9b.

Bild från Gratis Dolly
Dolly 2.0 är 100 % öppen källkod. Den levereras med träningskod, datauppsättning, modellvikter och slutledningspipeline. Alla komponenter är lämpliga för kommersiellt bruk. Du kan prova modellen på Hugging Face Spaces Dolly V2 av RamAnanth1.
Bild från Kramande ansikte
Resurs:
Dolly 2.0 Demo: Dolly V2 av RamAnanth1
Abid Ali Awan (@1abidaliawan) är en certifierad datavetare som älskar att bygga modeller för maskininlärning. För närvarande fokuserar han på att skapa innehåll och skriva tekniska bloggar om maskininlärning och datavetenskap. Abid har en magisterexamen i Technology Management och en kandidatexamen i telekommunikationsteknik. Hans vision är att bygga en AI-produkt med hjälp av ett grafiskt neuralt nätverk för studenter som kämpar med psykisk ohälsa.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Minting the Future med Adryenn Ashley. Tillgång här.
- Källa: https://www.kdnuggets.com/2023/04/dolly-20-chatgpt-open-source-alternative-commercial.html?utm_source=rss&utm_medium=rss&utm_campaign=dolly-2-0-chatgpt-open-source-alternative-for-commercial-use
- : har
- :är
- :inte
- $UPP
- 000
- 1
- 20
- a
- förmåga
- aktiv
- AI
- Alla
- tillåter
- alternativ
- an
- och
- svar
- någon
- api
- Ansökan
- ÄR
- runt
- Författaren
- tillgänglig
- utmärkelse
- baserat
- BE
- riktmärken
- Berkeley
- Bättre
- Stor
- bing
- bloggar
- båda
- SLUTRESULTAT
- Byggnad
- by
- KAN
- kan inte
- Certifierad
- chatbot
- ChatGPT
- koda
- kommersiella
- Commons
- konkurrera
- komponenter
- innehåller
- innehåll
- innehållsskapande
- tävling
- Kostar
- skapa
- skapas
- skapande
- För närvarande
- datum
- datavetenskap
- datavetare
- Databrickor
- datauppsättningar
- beslutade
- Examen
- demo
- Designa
- Utveckling
- DID
- svårt
- Dolly
- Anställd
- anställda
- Teknik
- utvärdering
- Varje
- utställningar
- Ansikte
- familj
- få
- fokusering
- efter
- För
- från
- framtida
- generera
- generera
- generativ
- skaffa sig
- diagram
- Graph Neural Network
- Har
- he
- hög kvalitet
- innehar
- html
- HTTPS
- sjukdom
- bild
- in
- informationen
- intresserad
- fråga
- problem
- IT
- jpg
- KDnuggets
- språk
- Large
- Efternamn
- senaste
- inlärning
- Licens
- tycka om
- Maskinen
- maskininlärning
- ledning
- Master
- mentala
- Mental sjukdom
- kanske
- modell
- modeller
- modifiera
- Behöver
- nät
- neural
- neurala nätverk
- Nya
- of
- on
- endast
- öppet
- öppen källkod
- OpenAI
- or
- ursprungliga
- produktion
- par
- parameter
- deltog
- prestanda
- rörledning
- plato
- Platon Data Intelligence
- PlatonData
- Produkt
- professionell
- syfte
- fråga
- frågor
- frigörs
- forskning
- löst
- begränsad
- s
- Samma
- Vetenskap
- Forskare
- in
- Kort
- Storlek
- So
- några
- Källa
- Utrymme
- utrymmen
- stanford
- igång
- state-of-the-art
- Stater
- Kämpar
- Studenter
- lämplig
- syntetisk
- syntetiska data
- uppgift
- grupp
- Teknisk
- Tekniken
- Teknologi
- telekommunikation
- än
- den där
- Smakämnen
- Framtiden
- de
- detta
- till
- topp
- Tåg
- tränad
- Utbildning
- under
- underliggande
- uppdaterad
- användning
- Begagnade
- med hjälp av
- version
- syn
- var
- we
- veckor
- były
- Vad
- som
- VEM
- med
- Arbete
- skulle
- skrivning
- dig
- zephyrnet










