Amazon RedShift är ett fullt hanterat och petabyte-skala molndatalager som används av tiotusentals kunder för att bearbeta exabyte data varje dag för att driva deras analysarbete. Du kan strukturera din data, mäta affärsprocesser och få värdefulla insikter snabbt kan göras genom att använda en dimensionell modell. Amazon Redshift tillhandahåller inbyggda funktioner för att påskynda processen med modellering, orkestrering och rapportering från en dimensionell modell.
I det här inlägget diskuterar vi hur man implementerar en dimensionell modell, specifikt Kimball metodik. Vi diskuterar implementeringsdimensioner och fakta inom Amazon Redshift. Vi visar hur man utför extrahera, transformera och ladda (ELT), en integrationsprocess fokuserad på att få in rådata från en datasjö till ett iscensättningslager för att utföra modelleringen. Sammantaget kommer inlägget att ge dig en tydlig förståelse för hur du använder dimensionsmodellering i Amazon Redshift.
Lösningsöversikt
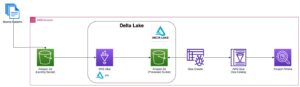
Följande diagram illustrerar lösningsarkitekturen.

I de följande avsnitten diskuterar och demonstrerar vi först nyckelaspekterna av den dimensionella modellen. Efter det skapar vi en datamart med Amazon Redshift med en dimensionell datamodell inklusive dimensions- och faktatabeller. Data laddas och iscensätts med hjälp av KOPIA kommandot laddas data i dimensionerna med hjälp av SAMMANFOGA uttalande, och fakta kommer att sammanfogas med de dimensioner som insikter härrör från. Vi schemalägger laddningen av dimensionerna och fakta med hjälp av Amazon Redshift Query Editor V2. Till sist använder vi Amazon QuickSight för att få insikter om den modellerade datan i form av en QuickSight-instrumentpanel.
För den här lösningen använder vi en exempeldatauppsättning (normaliserad) från Amazon Redshift för försäljning av evenemangsbiljetter. För det här inlägget har vi begränsat datasetet för enkelhets- och demonstrationssyfte. Följande tabeller visar exempel på data för biljettförsäljning och spelplatser.


Enligt Kimball dimensionell modellering metodik, det finns fyra nyckelsteg i att utforma en dimensionell modell:
- Identifiera affärsprocessen.
- Deklarera kärnan i dina data.
- Identifiera och implementera dimensionerna.
- Identifiera och implementera fakta.
Dessutom lägger vi till ett femte steg för demonstrationsändamål, vilket är att rapportera och analysera affärshändelser.
Förutsättningar
För detta genomgång bör du ha följande förutsättningar:
Identifiera affärsprocessen
Enkelt uttryckt är att identifiera affärsprocessen att identifiera en mätbar händelse som genererar data inom en organisation. Vanligtvis har företag någon form av operativt källsystem som genererar deras data i sitt råformat. Detta är en bra utgångspunkt för att identifiera olika källor för en affärsprocess.
Affärsprocessen fortsätter sedan som en data mart i form av dimensioner och fakta. Om vi tittar på vårt exempeldataset som nämnts tidigare, kan vi tydligt se att affärsprocessen är försäljningen som görs för en given händelse.
Ett vanligt misstag är att använda avdelningar i ett företag som affärsprocess. Data (affärsprocessen) måste integreras över olika avdelningar, i detta fall kan marknadsföring komma åt försäljningsdata. Att identifiera den korrekta affärsprocessen är avgörande – att få det här steget fel kan påverka hela datamarknaden (det kan leda till att kornen dupliceras och felaktiga mätvärden i slutrapporterna).
Deklarera kärnan i dina data
Att deklarera korn är handlingen att unikt identifiera en post i din datakälla. Kornet används i faktatabellen för att noggrant mäta data och göra det möjligt för dig att rulla upp ytterligare. I vårt exempel kan detta vara en rad i försäljningsprocessen.
I vårt användningsfall kan en försäljning identifieras unikt genom att titta på transaktionstiden då försäljningen ägde rum; detta kommer att vara den mest atomära nivån.

Identifiera och implementera dimensionerna
Din dimensionstabell beskriver din faktatabell och dess attribut. När du identifierar det beskrivande sammanhanget för din affärsprocess lagrar du texten i en separat tabell, med faktatabellen i åtanke. När du kopplar dimensionstabellen till faktatabellen ska det bara finnas en enda rad kopplad till faktatabellen. I vårt exempel använder vi följande tabell för att separeras i en dimensionstabell; dessa fält beskriver de fakta som vi kommer att mäta.
När du utformar strukturen för den dimensionella modellen (schemat) kan du antingen skapa en stjärna or snöflinga schema. Strukturen bör vara i nära linje med affärsprocessen; därför passar ett stjärnschema bäst för vårt exempel. Följande figur visar vårt Entity Relationship Diagram (ERD).

I följande avsnitt beskriver vi stegen för att implementera dimensionerna.
Iscensätt källdata
Innan vi kan skapa och ladda dimensionstabellen behöver vi källdata. Därför placerar vi källdata till en iscensättning eller tillfällig tabell. Detta kallas ofta för mellanlagringsskikt, som är råkopian av källdata. För att göra detta i Amazon Redshift använder vi COPY kommando för att ladda data från den offentliga S3-skopan för dimensionsmodellering-i-amazon-rödförskjutning som finns på us-east-1 Område. Observera att kommandot COPY använder en AWS identitets- och åtkomsthantering (IAM) roll med tillgång till Amazon S3. Rollen måste vara kopplat till klustret. Utför följande steg för att iscensätta källdata:
- Skapa
venuekälltabell:
- Ladda platsdata:
- Skapa
saleskälltabell:
- Ladda försäljningskällans data:
- Skapa
calendartabell:
- Ladda kalenderdata:
Skapa måtttabellen
Utformningen av dimensionstabellen kan bero på ditt företags krav – till exempel behöver du spåra ändringar av data över tid? Det finns sju olika dimensionstyper. För vårt exempel använder vi typ 1 eftersom vi inte behöver spåra historiska förändringar. För mer om typ 2, se Förenkla datainläsning i typ 2 långsamt ändrande dimensioner i Amazon Redshift. Dimensionstabellen kommer att avnormaliseras med en primärnyckel, surrogatnyckel och några tillagda fält för att indikera ändringar i tabellen. Se följande kod:
Några anteckningar om hur du skapar dimensionstabellen:
- Fältnamnen förvandlas till företagsvänliga namn
- Vår primära nyckel är
VenueID, som vi använder för att unikt identifiera en plats där försäljningen ägde rum - Två ytterligare rader kommer att läggas till, vilket indikerar när en post infogades och uppdaterades (för att spåra ändringar)
- Vi använder en AUTO distributionsstil att ge Amazon Redshift ansvaret att välja och justera distributionsstilen
En annan viktig faktor att tänka på vid dimensionsmodellering är användningen av surrogatnycklar. Surrogatnycklar är konstgjorda nycklar som används i dimensionsmodellering för att unikt identifiera varje post i en dimensionstabell. De genereras vanligtvis som ett sekventiellt heltal, och de har ingen betydelse i affärsdomänen. De erbjuder flera fördelar, som att säkerställa unikhet och förbättra prestanda i kopplingar, eftersom de vanligtvis är mindre än naturliga nycklar och som surrogatnycklar förändras de inte över tiden. Detta gör att vi kan vara konsekventa och lättare sammanfoga fakta och dimensioner.
I Amazon Redshift skapas surrogatnycklar vanligtvis med nyckelordet IDENTITY. Till exempel skapar den föregående CREATE-satsen en dimensionstabell med en VenueSkey surrogatnyckel. De VenueSkey kolumnen fylls automatiskt i med unika värden när nya rader läggs till i tabellen. Denna kolumn kan sedan användas för att sammanfoga lokalbordet till FactSaleTransactions tabell.
Några tips för att designa surrogatnycklar:
- Använd en liten datatyp med fast bredd för surrogatnyckeln. Detta kommer att förbättra prestandan och minska lagringsutrymmet.
- Använd nyckelordet IDENTITY eller generera surrogatnyckeln med ett sekventiellt eller GUID-värde. Detta kommer att säkerställa att surrogatnyckeln är unik och inte kan ändras.
Ladda dimbordet med MERGE
Det finns många sätt att ladda ditt dimbord. Vissa faktorer måste beaktas – till exempel prestanda, datavolym och kanske SLA-laddningstider. Med SAMMANFOGA uttalande utför vi en upsert utan att behöva ange flera insert- och update-kommandon. Du kan ställa in SAMMANFOGA uttalande i a lagrad procedur för att fylla i uppgifterna. Du schemalägger sedan den lagrade proceduren att köras programmatiskt via frågeredigeraren, vilket vi visar senare i inlägget. Följande kod skapar en lagrad procedur som kallas SalesMart.DimVenueLoad:
Några anmärkningar om dimensionsladdningen:
- När en post infogas för första gången kommer det infogade datumet och det uppdaterade datumet att fyllas i. När några värden ändras uppdateras data och det uppdaterade datumet återspeglar datumet då det ändrades. Det infogade datumet finns kvar.
- Eftersom data kommer att användas av företagsanvändare måste vi ersätta NULL-värden, om några, med mer affärslämpliga värden.
Identifiera och implementera fakta
Nu när vi har förklarat vår spannmål vara händelsen för en försäljning som ägde rum vid en specifik tidpunkt, kommer vår faktatabell att lagra numeriska fakta för vår affärsprocess.
Vi har identifierat följande numeriska fakta att mäta:
- Antal sålda biljetter per försäljning
- Provision för försäljningen
Implementering av faktum
Det finns tre typer av faktatabeller (transaktionsfaktatabell, periodisk ögonblicksbildfaktatabell och ackumulerande ögonblicksbildfaktatabell). Var och en har olika syn på affärsprocessen. För vårt exempel använder vi en transaktionsfaktatabell. Slutför följande steg:
- Skapa faktatabellen
Ett infogat datum med ett standardvärde läggs till, vilket anger om och när en post laddades. Du kan använda detta när du laddar om faktatabellen för att ta bort redan inlästa data för att undvika dubbletter.
Att ladda faktatabellen består av en enkel infogningssats som sammanfogar dina tillhörande dimensioner. Vi går med från DimVenue tabell som skapades, som beskriver våra fakta. Det är bästa praxis men valfritt att ha kalenderdatum dimensioner, som gör att slutanvändaren kan navigera i faktatabellen. Data kan antingen laddas när det finns en ny försäljning, eller dagligen; det är här det infogade datumet eller laddningsdatumet är praktiskt.
Vi laddar faktatabellen med en lagrad procedur och använder en datumparameter.
- Skapa den lagrade proceduren med följande kod. För att behålla samma dataintegritet som vi tillämpade i dimensionsladdningen, ersätter vi NULL-värden, om några, med mer affärsmässiga värden:
- Ladda data genom att anropa proceduren med följande kommando:
Schemalägg dataladdningen
Vi kan nu automatisera modelleringsprocessen genom att schemalägga de lagrade procedurerna i Amazon Redshift Query Editor V2. Slutför följande steg:
- Vi anropar först dimensionsbelastningen och efter att dimensionsbelastningen har körts framgångsrikt börjar faktaladdningen:
Om dimensionsbelastningen misslyckas kommer faktabelastningen inte att köras. Detta säkerställer konsistens i data eftersom vi inte vill ladda faktatabellen med föråldrade dimensioner.
- För att schemalägga laddningen, välj tidtabell i Query Editor V2.

- Vi schemalägger att frågan ska köras varje dag kl. 5.
- Alternativt kan du lägga till felmeddelanden genom att aktivera Amazon enkel meddelandetjänst (Amazon SNS) aviseringar.

Rapportera och analysera data i Amazon Quicksight
QuickSight är en business intelligence-tjänst som gör det enkelt att leverera insikter. Som en helt hanterad tjänst låter QuickSight dig enkelt skapa och publicera interaktiva instrumentpaneler som sedan kan nås från vilken enhet som helst och bäddas in i dina applikationer, portaler och webbplatser.
Vi använder vår datamart för att visuellt presentera fakta i form av en instrumentpanel. För att komma igång och ställa in QuickSight, se Skapa en datauppsättning med hjälp av en databas som inte är autoupptäckt.
När du har skapat din datakälla i QuickSight sammanfogar vi den modellerade datan (datamart) baserat på vår surrogatnyckel skey. Vi använder denna datauppsättning för att visualisera datamart.

Vår slutinstrumentpanel kommer att innehålla datamarknadens insikter och svara på affärskritiska frågor, såsom total provision per plats och datum med den högsta försäljningen. Följande skärmdump visar slutprodukten av datamarknaden.

Städa upp
För att undvika framtida avgifter, radera alla resurser du skapat som en del av det här inlägget.
Slutsats
Vi har nu framgångsrikt implementerat en datamart med vår DimVenue, DimCalendaroch FactSaleTransactions tabeller. Vårt lager är inte komplett; eftersom vi kan utöka datamarknaden med mer fakta och implementera fler mars, och eftersom affärsprocessen och kraven växer över tiden, så kommer även datalagret att växa. I det här inlägget gav vi en helhetssyn på att förstå och implementera dimensionell modellering i Amazon Redshift.
Kom igång med din Amazon RedShift dimensionell modell idag.
Om författarna
 Bernard Verster är en erfaren molningenjör med många års exponering för att skapa skalbara och effektiva datamodeller, definiera dataintegrationsstrategier och säkerställa datastyrning och säkerhet. Han brinner för att använda data för att skapa insikter, samtidigt som han anpassar sig till affärskrav och mål.
Bernard Verster är en erfaren molningenjör med många års exponering för att skapa skalbara och effektiva datamodeller, definiera dataintegrationsstrategier och säkerställa datastyrning och säkerhet. Han brinner för att använda data för att skapa insikter, samtidigt som han anpassar sig till affärskrav och mål.
 Abhishek Pan är en WWSO Specialist SA-Analytics som arbetar med AWS India Public sector-kunder. Han samarbetar med kunder för att definiera datadriven strategi, tillhandahålla djupdykningssessioner om analytiska användningsfall och designa skalbara och effektiva analytiska applikationer. Han har 12 års erfarenhet och brinner för databaser, analys och AI/ML. Han är en ivrig resenär och försöker fånga världen genom sin kameralins.
Abhishek Pan är en WWSO Specialist SA-Analytics som arbetar med AWS India Public sector-kunder. Han samarbetar med kunder för att definiera datadriven strategi, tillhandahålla djupdykningssessioner om analytiska användningsfall och designa skalbara och effektiva analytiska applikationer. Han har 12 års erfarenhet och brinner för databaser, analys och AI/ML. Han är en ivrig resenär och försöker fånga världen genom sin kameralins.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Fordon / elbilar, Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- BlockOffsets. Modernisera miljökompensation ägande. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/dimensional-modeling-in-amazon-redshift/
- : har
- :är
- :inte
- :var
- $UPP
- 1
- 100
- 12
- 15%
- 16
- 17
- 20
- 28
- 30
- 300
- 7
- 8
- 9
- a
- Om oss
- accelerera
- tillgång
- Accessed
- exakt
- tvärs
- Agera
- lägga till
- lagt till
- Annat
- Efter
- AI / ML
- rikta
- inriktnings
- tillåter
- tillåter
- redan
- am
- amason
- Amazon Web Services
- an
- analys
- Analytisk
- analytics
- analysera
- och
- svara
- vilken som helst
- tillämpningar
- tillämpas
- lämpligt
- arkitektur
- ÄR
- konstgjord
- AS
- aspekter
- associerad
- At
- attribut
- bil
- automatisera
- automatiskt
- undvika
- AWS
- b
- baserat
- BE
- därför att
- börja
- Fördelarna
- BÄST
- inbyggd
- företag
- business intelligence
- Affärsprocess
- affärsprocesser
- men
- by
- Kalender
- Ring
- kallas
- anropande
- rum
- KAN
- fånga
- Vid
- fall
- Orsak
- vissa
- byta
- ändrats
- Förändringar
- byte
- karaktär
- avgifter
- Välja
- klar
- klart
- nära
- cloud
- koda
- Kolumn
- kommer
- provision
- Gemensam
- Företag
- företag
- fullborda
- Tänk
- konsekvent
- består
- sammanhang
- korrekt
- kunde
- skapa
- skapas
- skapar
- Skapa
- skapande
- kritisk
- Kunder
- dagligen
- instrumentbräda
- instrumentpaneler
- datum
- dataintegration
- datasjö
- datalagret
- data driven
- Datadriven strategi
- Databas
- databaser
- Datum
- Datum
- datum Tid
- dag
- djup
- djupdykning
- Standard
- definierande
- leverera
- demonstrera
- avdelningar
- Härledd
- beskriva
- Designa
- design
- detalj
- anordning
- olika
- Dimensionera
- dimensioner
- diskutera
- distinkt
- fördelning
- do
- domän
- gjort
- inte
- ner
- driv
- dubbletter
- varje
- Tidigare
- lätt
- lätt
- redaktör
- effektiv
- antingen
- inbäddade
- möjliggöra
- möjliggör
- änden
- början till slut
- ingriper
- ingenjör
- säkerställa
- säkerställer
- säkerställa
- Hela
- enhet
- Eter (ETH)
- händelse
- händelser
- Varje
- varje dag
- exempel
- exempel
- Bygga ut
- erfarenhet
- erfaren
- Exponering
- extrahera
- Faktum
- faktor
- faktorer
- fakta
- misslyckas
- Misslyckande
- Funktioner
- få
- fält
- Fält
- femte
- Figur
- filtrera
- slutlig
- Förnamn
- första gången
- passa
- fokuserade
- efter
- För
- formen
- format
- fyra
- från
- fullständigt
- ytterligare
- framtida
- Få
- generera
- genereras
- genererar
- skaffa sig
- få
- Ge
- ges
- god
- styrning
- Väx
- praktisk
- Har
- he
- högsta
- hans
- historisk
- Semester
- Hur ser din drömresa ut
- How To
- html
- http
- HTTPS
- IAM
- identifierade
- identifiera
- identifiera
- Identitet
- if
- illustrerar
- Inverkan
- genomföra
- genomföras
- genomföra
- med Esport
- förbättra
- förbättra
- in
- Inklusive
- indien
- indikerar
- indikerar
- info
- insikter
- integrerade
- integrering
- integritet
- Intelligens
- interaktiva
- in
- IT
- DESS
- delta
- fogade
- sammanfogning
- Fogar
- jpg
- Ha kvar
- hålla
- Nyckel
- nycklar
- sjö
- språk
- senare
- senaste
- lager
- vänster
- Lins
- Lets
- Nivå
- linje
- läsa in
- läser in
- laster
- belägen
- du letar
- gjord
- GÖR
- förvaltade
- Marknadsföring
- matchas
- betyder
- mäta
- nämnts
- Sammanfoga
- Metrics
- emot
- misstag
- modell
- modellering
- modellering
- modeller
- Månad
- mer
- mest
- multipel
- namn
- Natural
- Navigera
- Behöver
- behöver
- behov
- Nya
- Anmärkningar
- anmälan
- anmälningar
- nu
- talrik
- mål
- of
- erbjudanden
- Ofta
- on
- endast
- operativa
- or
- organisation
- vår
- över
- övergripande
- parameter
- del
- brinner
- för
- utföra
- prestanda
- kanske
- periodisk
- Plats
- plato
- Platon Data Intelligence
- PlatonData
- Punkt
- befolkad
- Inlägg
- kraft
- praktiken
- förutsättningar
- presentera
- primär
- förfaranden
- förfaranden
- process
- processer
- Produkt
- ge
- förutsatt
- ger
- allmän
- publicera
- syfte
- frågor
- snabbt
- höja
- Raw
- rådata
- post
- register
- minska
- avses
- Reflekterar
- region
- relation
- resterna
- ta bort
- ersätta
- rapport
- Rapportering
- Rapport
- Krav
- Resurser
- ansvaret
- Roll
- Rulla
- RAD
- Körning
- kör
- Till Salu
- försäljning
- Samma
- Exempeldatauppsättning
- skalbar
- tidtabellen
- schemaläggning
- sektioner
- sektor
- säkerhet
- se
- separat
- serverar
- service
- Tjänster
- sessioner
- in
- flera
- skall
- show
- Visar
- Enkelt
- enkelhet
- enda
- Långsamt
- Small
- mindre
- Snapshot
- So
- säljs
- lösning
- några
- Källa
- Källor
- Utrymme
- specialist
- specifik
- specifikt
- Etapp
- staging
- Stjärna
- igång
- Starta
- .
- Steg
- Steg
- förvaring
- lagra
- lagras
- strategier
- Strategi
- struktur
- framgångsrik
- Framgångsrikt
- sådana
- system
- bord
- temporär
- tiotals
- villkor
- än
- den där
- Smakämnen
- källan
- världen
- deras
- sedan
- Där.
- därför
- Dessa
- de
- detta
- tusentals
- Genom
- biljett
- biljettförsäljning
- biljetter
- tid
- gånger
- tidsstämpel
- Tips
- till
- i dag
- tillsammans
- tog
- Totalt
- spår
- transaktion
- Förvandla
- transformerad
- resenär
- Typ
- typer
- typiskt
- förståelse
- unika
- unikt
- unikhet
- okänd
- Uppdatering
- uppdaterad
- us
- Användning
- användning
- användningsfall
- Begagnade
- användare
- användningar
- med hjälp av
- vanligen
- Värdefulla
- värde
- Värden
- olika
- Mötesplats
- arenor
- via
- utsikt
- volym
- genomgång
- vill
- Warehouse
- var
- sätt
- we
- webb
- webbservice
- webbsidor
- vecka
- när
- som
- medan
- kommer
- med
- inom
- utan
- arbetssätt
- världen
- Fel
- år
- år
- dig
- Din
- zephyrnet