Automatiserad dataanalys (ADA) på AWS är en AWS-lösning som gör att du kan få meningsfulla insikter från data på några minuter genom ett enkelt och intuitivt användargränssnitt. ADA erbjuder en AWS-native dataanalysplattform som är redo att användas direkt av dataanalytiker för en mängd olika användningsfall. Med ADA kan team mata in, transformera, styra och söka olika datauppsättningar från en rad datakällor utan att kräva specialistkompetens. ADA tillhandahåller en uppsättning av förbyggda kontakter att få in data från ett brett spektrum av källor, inklusive Amazon enkel lagringstjänst (Amazon S3), Amazon Kinesis dataströmmar, amazoncloudwatch, Amazon CloudTrailoch Amazon DynamoDB liksom många andra.
ADA tillhandahåller en grundläggande plattform som kan användas av dataanalytiker i en mängd olika användningsfall inklusive IT, ekonomi, marknadsföring, försäljning och säkerhet. ADA:s out-of-the-box CloudWatch-dataanslutning tillåter dataintag från CloudWatch-loggar i samma AWS-konto som ADA har distribuerats på, eller från ett annat AWS-konto.
I det här inlägget visar vi hur en applikationsutvecklare eller applikationstestare kan använda ADA för att få operativa insikter om applikationer som körs i AWS. Vi visar också hur du kan använda ADA-lösningen för att ansluta till olika datakällor i AWS. Vi först implementera ADA-lösningen till ett AWS-konto och konfigurera ADA-lösningen genom att skapa dataprodukter använder dataanslutningar. Vi använder sedan ADA Query Workbench för att sammanfoga de separata datamängderna och fråga efter korrelerade data, med hjälp av välbekanta Structured Query Language (SQL), för att få insikter. Vi visar också hur ADA kan integreras med Business Intelligence (BI)-verktyg som Tableau för att visualisera data och för att skapa rapporter.
Lösningsöversikt
I det här avsnittet presenterar vi lösningsarkitekturen för demon och förklarar arbetsflödet. I demonstrationssyfte simuleras den skräddarsydda applikationen med en AWS Lambda funktion som avger inloggningar Apache-loggformat med ett förinställt intervall med hjälp av Amazon EventBridge. Detta standardformat kan produceras av många olika webbservrar och läsas av många logganalysprogram. Applikationsloggarna (Lambda-funktion) skickas till en CloudWatch-logggrupp. De historiska applikationsloggarna lagras i en S3-hink för referens och för frågeändamål. En uppslagstabell med en lista över HTTP-statuskoder tillsammans med beskrivningarna lagras i en DynamoDB-tabell. Dessa tre fungerar som källor från vilka data tas in i ADA för korrelation, sökning och analys. Vi implementera ADA-lösningen till ett AWS-konto och ställ in ADA. Vi skapar sedan dataprodukter inom ADA för CloudWatch-logggrupp, S3 hinkoch DynamoDB. När dataprodukterna konfigureras tillhandahåller ADA datapipelines för att få in data från källorna. Med ADA Query Workbench kan du fråga intagna data med vanlig SQL för applikationsfelsökning eller problemdiagnos.
Följande diagram ger en översikt över arkitekturen och arbetsflödet för att använda ADA för att få insikter i applikationsloggar.
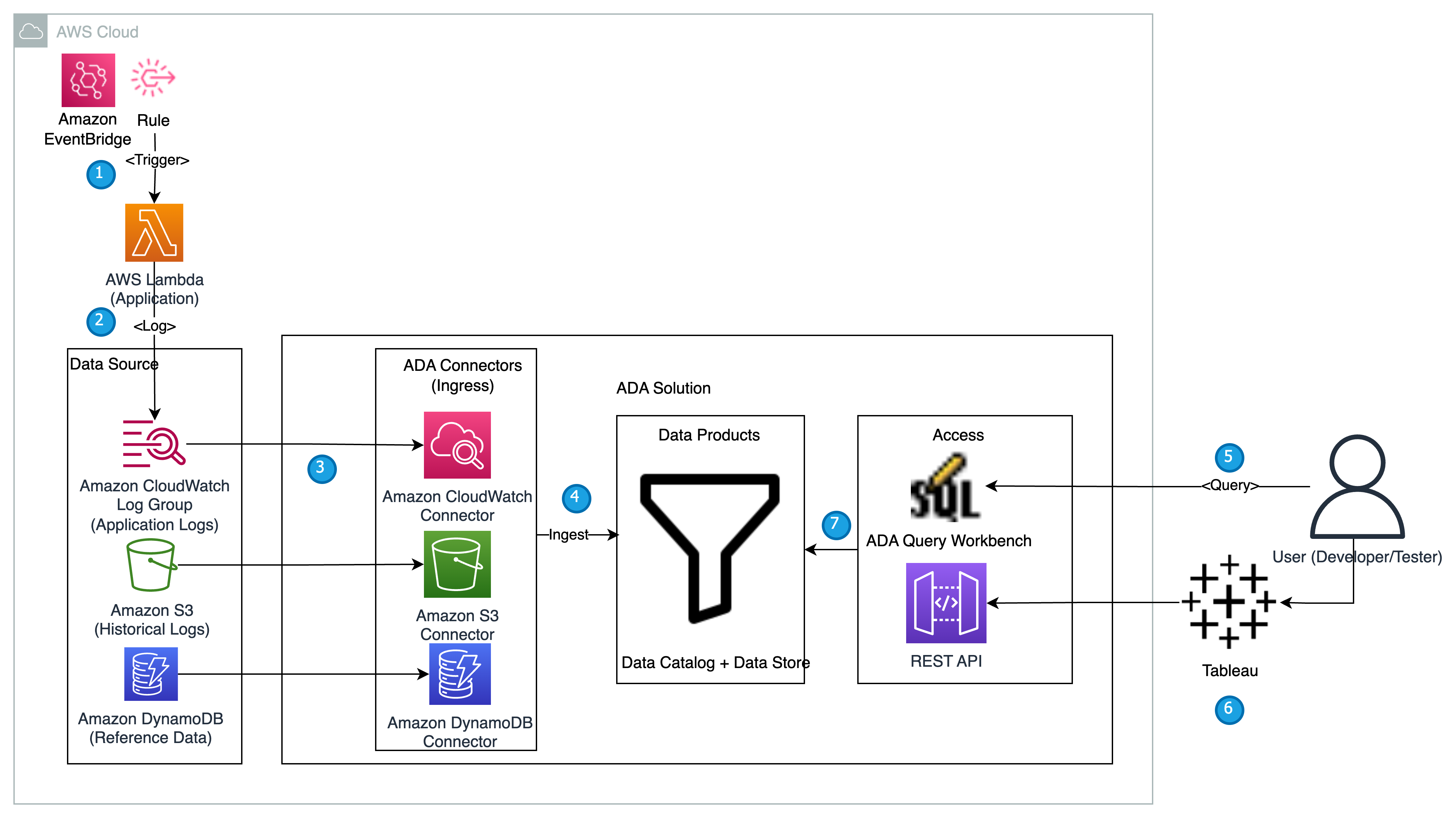
Arbetsflödet innehåller följande steg:
- En lambdafunktion är planerad att triggas med 2 minuters intervall med EventBridge.
- Lambdafunktionen avger loggar som lagras i en angiven CloudWatch-logggrupp under
/aws/lambda/CdkStack-AdaLogGenLambdaFunction. Applikationsloggarna genereras med Apache Log Format-schemat men lagras i CloudWatch-logggruppen i JSON-format. - Dataprodukterna för CloudWatch, Amazon S3 och DynamoDB skapas i ADA. CloudWatch-dataprodukten ansluter till CloudWatch-logggruppen där applikationsloggarna (Lambda-funktion) lagras. Amazon S3-kontakten ansluts till en S3-hinkmapp där de historiska loggarna lagras. DynamoDB-anslutningen ansluter till en DynamoDB-tabell där statuskoderna som hänvisas till av applikationen och historiska loggar lagras.
- För var och en av dataprodukterna distribuerar ADA datapipeline-infrastrukturen för att få in data från källorna. När datainmatningen är klar kan du skriva frågor med SQL via ADA Query Workbench.
- Du kan logga in på ADA-portalen och skapa SQL-frågor från Query Workbench för att få insikter i applikationsloggarna. Du kan valfritt spara frågan och dela frågan med andra ADA-användare på samma domän. ADA-frågefunktionen drivs av Amazonas Athena, som är en serverlös, interaktiv analystjänst som tillhandahåller ett förenklat, flexibelt sätt att analysera petabyte med data.
- Tableau är konfigurerad för att komma åt ADA-dataprodukterna via ADA-utgångsändpunkter. Du skapar sedan en instrumentpanel med två diagram. Det första diagrammet är en värmekarta som visar förekomsten av HTTP-felkoder korrelerade med applikationens API-slutpunkter. Det andra diagrammet är ett stapeldiagram som visar de 10 bästa applikations-API:erna med ett totalt antal HTTP-felkoder från historiska data.
Förutsättningar
För det här inlägget måste du uppfylla följande förutsättningar:
- installera AWS-kommandoradsgränssnitt (AWS CLI), AWS Cloud Development Kit (AWS CDK) förutsättningar, TypeScript-specifik förutsättningaroch gå.
- Distribuera ADA-lösningen i ditt AWS-konto i
us-east-1Område.- Ange en admin-e-post när du startar ADA AWS molnformation stack. Detta behövs för att ADA ska skicka rootanvändarlösenordet. Ett administratörstelefonnummer krävs för att få ett engångslösenordsmeddelande om multifaktorautentisering (MFA) är aktiverad. MFA är inte aktiverat för denna demo.
- Bygg och distribuera exempelapplikationen (tillgänglig på GitHub repo) lösning så att följande resurser kan tillhandahållas på ditt konto i
us-east-1Region:- En Lambda-funktion som simulerar loggningsapplikationen och en EventBridge-regel som anropar applikationsfunktionen med 2 minuters intervall.
- En S3-bucket med relevanta bucket-policyer och en CSV-fil som innehåller de historiska programloggarna.
- En DynamoDB-tabell med uppslagsdata.
- Relevant AWS identitets- och åtkomsthantering (IAM) roller och behörigheter som krävs för tjänsterna.
- Alternativt, installera Tablå skrivbord, en tredjeparts BI-leverantör. För det här inlägget använder vi Tableau Desktop version 2021.2. Det medför en kostnad att använda en licensierad version av Tableau Desktop-applikationen. För ytterligare information, se Tableau licensiering information.
Distribuera och konfigurera ADA
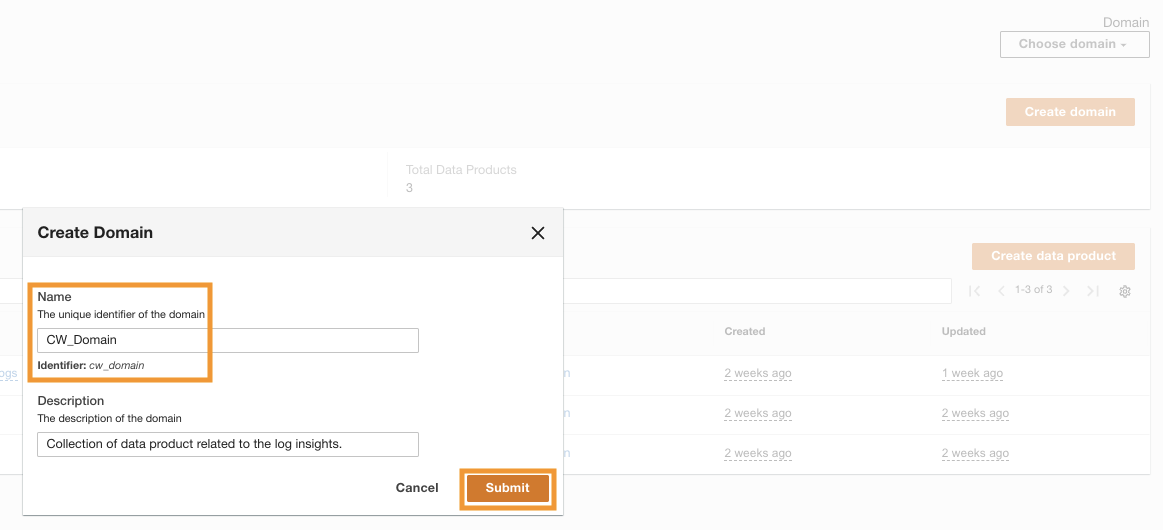
När ADA har implementerats framgångsrikt kan du logga in med admin-e-postadressen som du fick under installationen. Du skapar sedan en domän som heter CW_Domain. En domän är en användardefinierad samling av dataprodukter. En domän kan till exempel vara ett team eller ett projekt. Domäner tillhandahåller ett strukturerat sätt för användare att organisera sina dataprodukter och hantera åtkomstbehörigheter.
- Välj på ADA-konsolen domäner i navigeringsfönstret.
- Välja Skapa domän.
- Ange ett namn (
CW_Domain) och beskrivning, välj sedan Skicka.
Konfigurera exempelapplikationens infrastruktur med AWS CDK
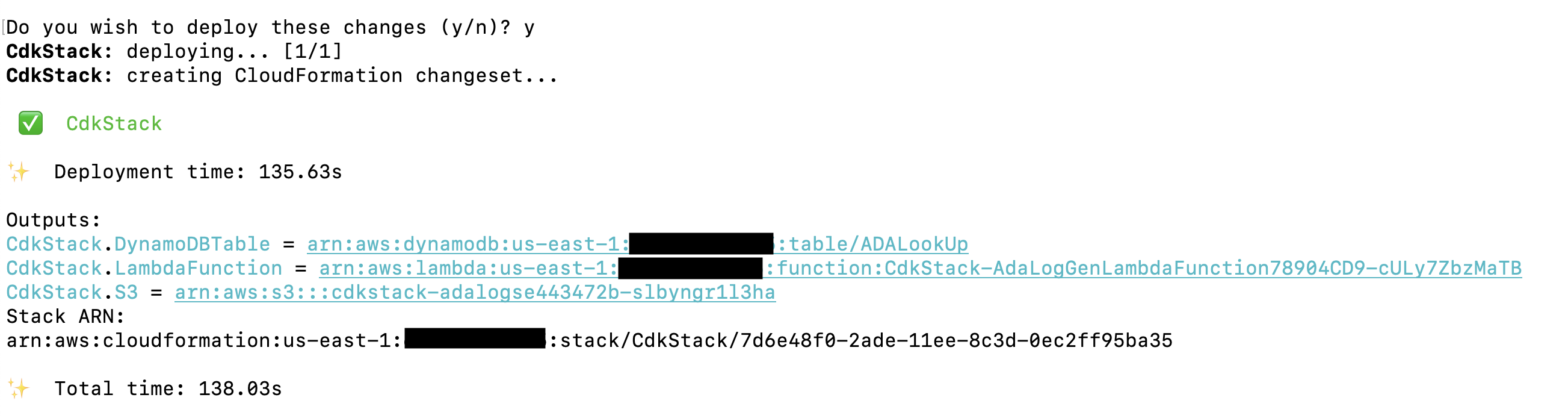
AWS CDK-lösningen som distribuerar demoapplikationen är värd GitHub. Stegen för att klona repet och ställa in AWS CDK-projektet beskrivs i detta avsnitt. Innan du kör dessa kommandon, se till att göra det konfigurera dina AWS-uppgifter. Skapa en mapp, öppna terminalen och navigera till mappen där AWS CDK-lösningen behöver installeras. Kör följande kod:
Dessa steg utför följande åtgärder:
- Installera biblioteksberoenden
- Bygg projektet
- Skapa en giltig CloudFormation-mall
- Distribuera stacken med AWS CloudFormation i ditt AWS-konto
Implementeringen tar cirka 1–2 minuter och skapar DynamoDB-uppslagstabellen, Lambda-funktionen och S3-bucket som innehåller de historiska loggfilerna som utdata. Kopiera dessa värden till ett textredigeringsprogram, till exempel Anteckningar.
Skapa ADA-dataprodukter
Vi skapar tre olika dataprodukter för den här demon, en för varje datakälla som du kommer att fråga för att få operativa insikter. En dataprodukt är en datauppsättning (en samling av data som en tabell eller en CSV-fil) som framgångsrikt har importerats till ADA och som kan frågas.
Skapa en CloudWatch-dataprodukt
Först skapar vi en dataprodukt för applikationsloggarna genom att ställa in ADA för att inta CloudWatch-logggruppen för exempelapplikationen (Lambda-funktion). Använd CdkStack.LambdaFunction ut för att få Lambda-funktionen ARN och lokalisera motsvarande CloudWatch-logggrupp ARN på CloudWatch-konsolen.
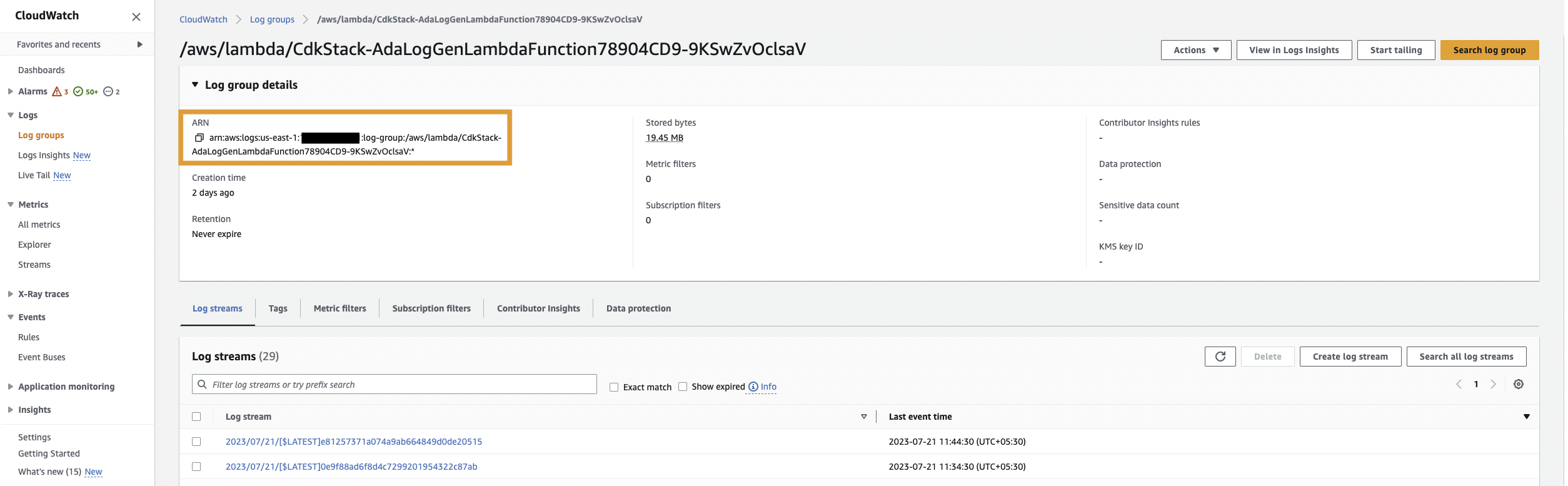
Gör sedan följande steg:
- På ADA-konsolen, navigera till ADA-domänen och skapa en CloudWatch-dataprodukt.
- För Namn ¸ ange ett namn.
- För Källtyp, välja amazoncloudwatch.
- inaktivera Automatisk PII.
ADA har en funktion som automatiskt upptäcker personligt identifierbar information (PII) data under import som är aktiverad som standard. För den här demon inaktiverar vi det här alternativet för dataprodukten eftersom upptäckten av PII-data inte omfattas av den här demon.
- Välja Nästa.
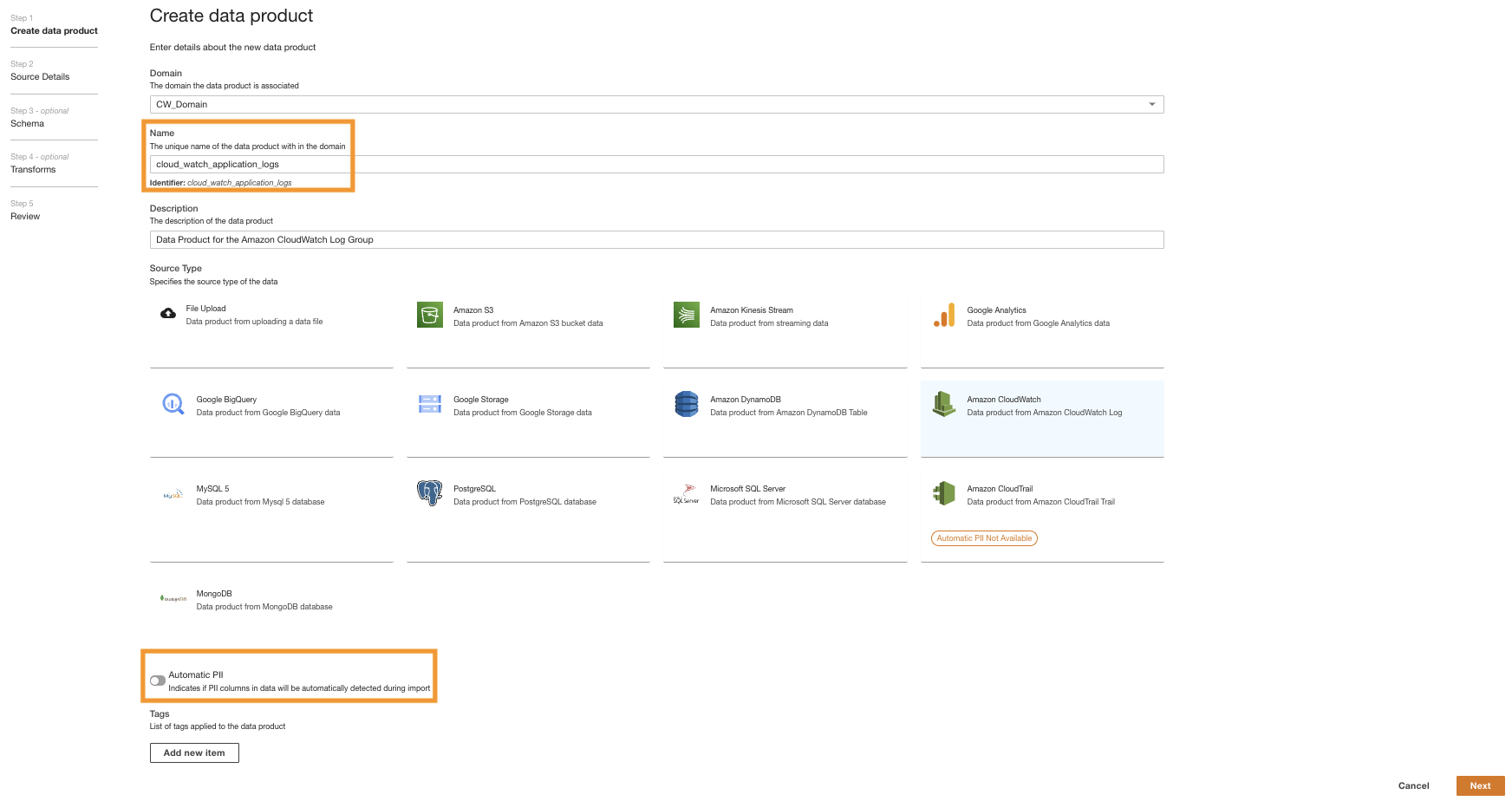
- Sök efter och välj CloudWatch-logggruppen ARN som kopierades från föregående steg.

- Kopiera logggruppen ARN.
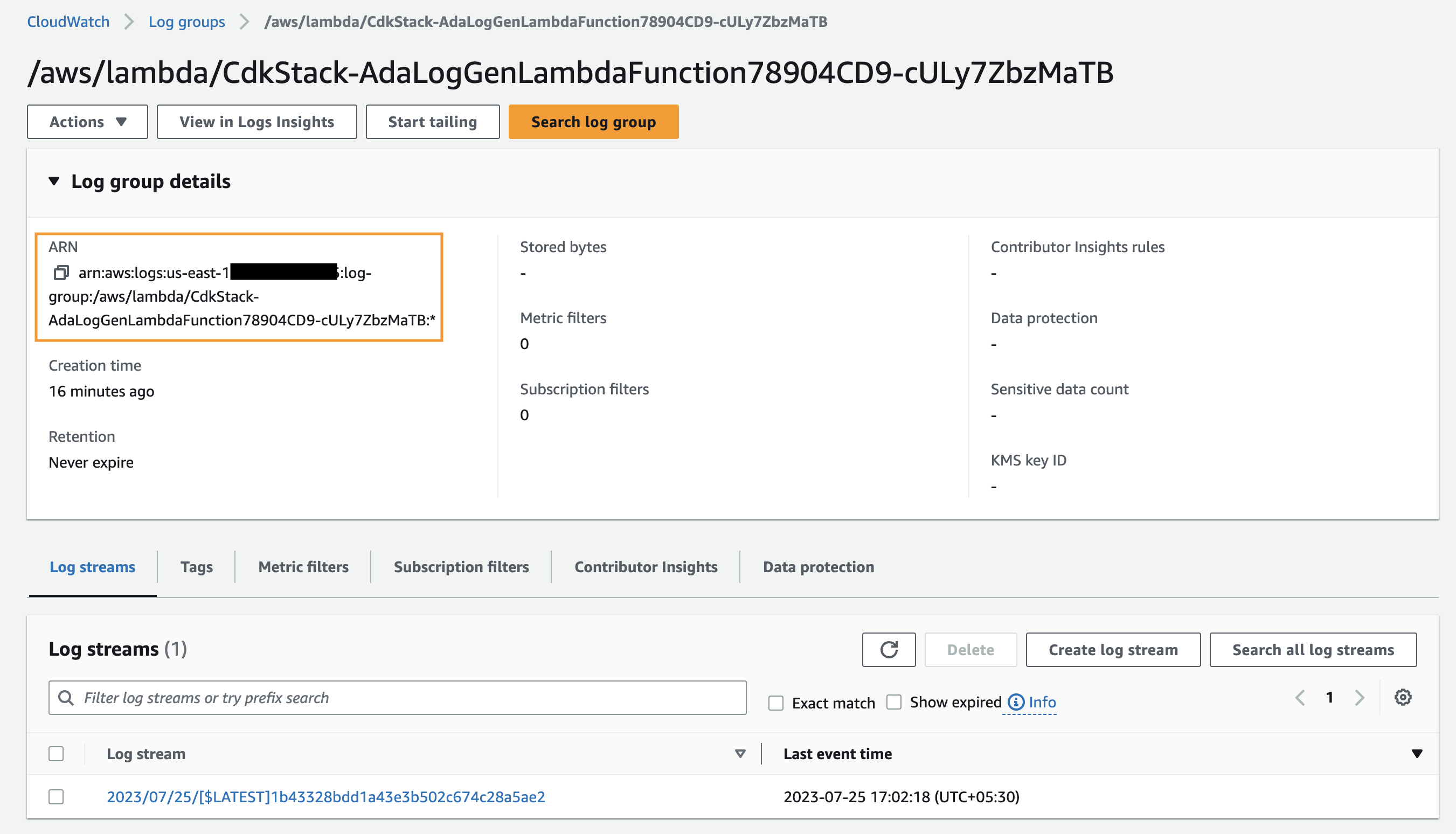
- På dataproduktsidan anger du logggruppen ARN.
- För CloudWatch-fråga, ange en fråga som du vill att ADA ska få från logggruppen.
I den här demon frågar vi fältet @meddelande eftersom vi är intresserade av att få applikationsloggarna från logggruppen.
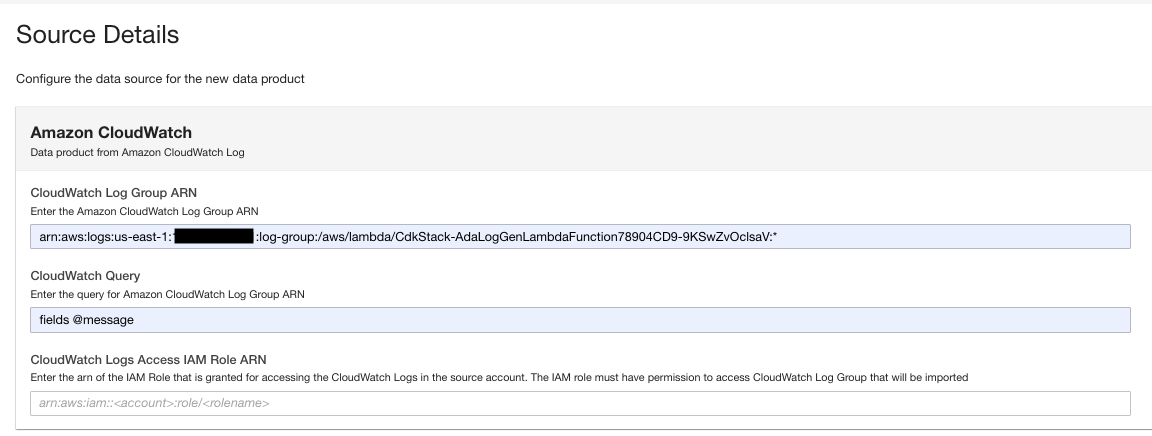
- Välj hur datauppdateringarna ska triggas efter den första importen.
ADA kan konfigureras för att ta emot data från källan med flexibla intervall (upp till 15 minuter eller senare) eller på begäran. För demon ställer vi in datauppdateringarna att köras varje timme.
- Välja Nästa.
Därefter kommer ADA att ansluta till logggruppen och fråga efter schemat. Eftersom loggarna är i Apache-loggformat omvandlar vi loggarna till separata fält så att vi kan köra frågor på de specifika loggfälten. ADA ger fyra standard transformationer och stöder anpassad transformation genom ett Python-skript. I denna demo kör vi ett anpassat Python-skript för att omvandla JSON-meddelandefältet till Apache-loggformatfält.
- Välja Förvandla schema.
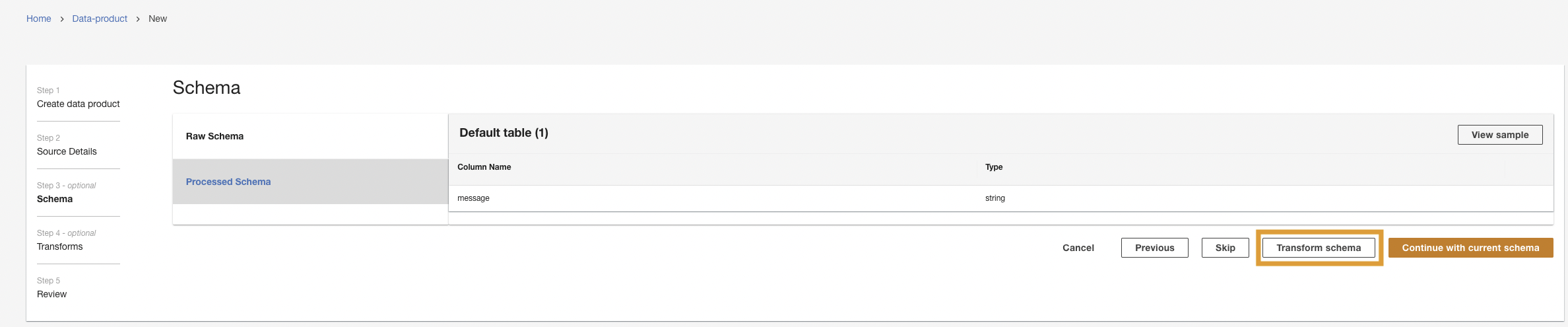
- Välja Skapa ny transformation.
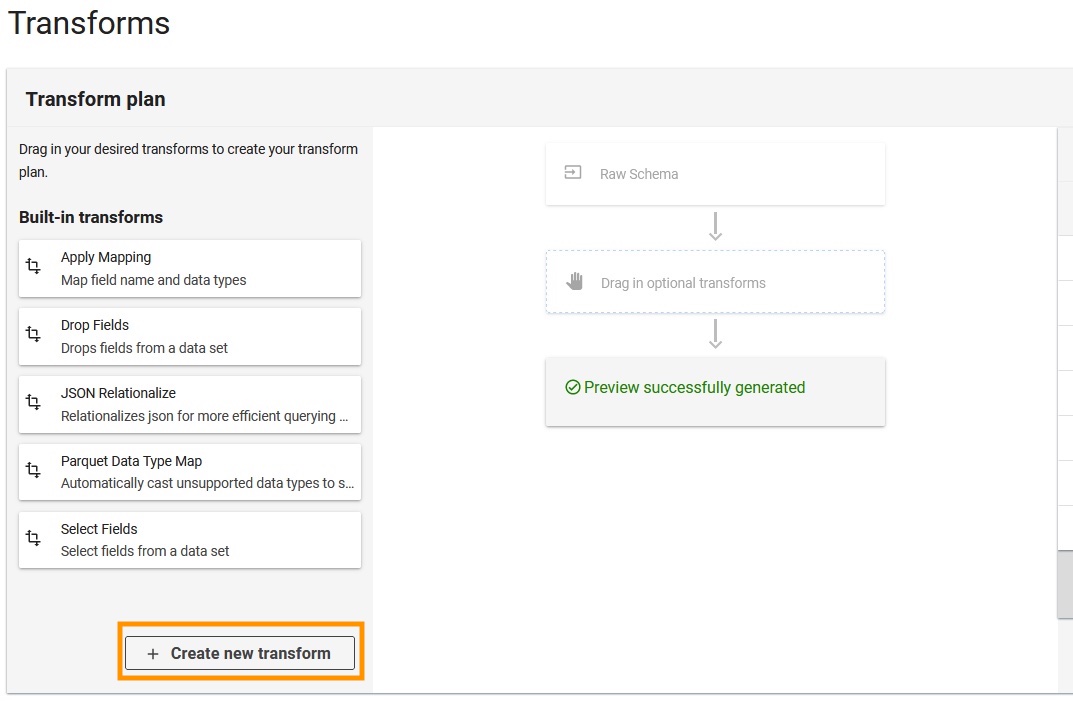
- Ladda upp
apache-log-extractor-transform.pymanus från/asset/transform_logs/mapp. - Välja Skicka.
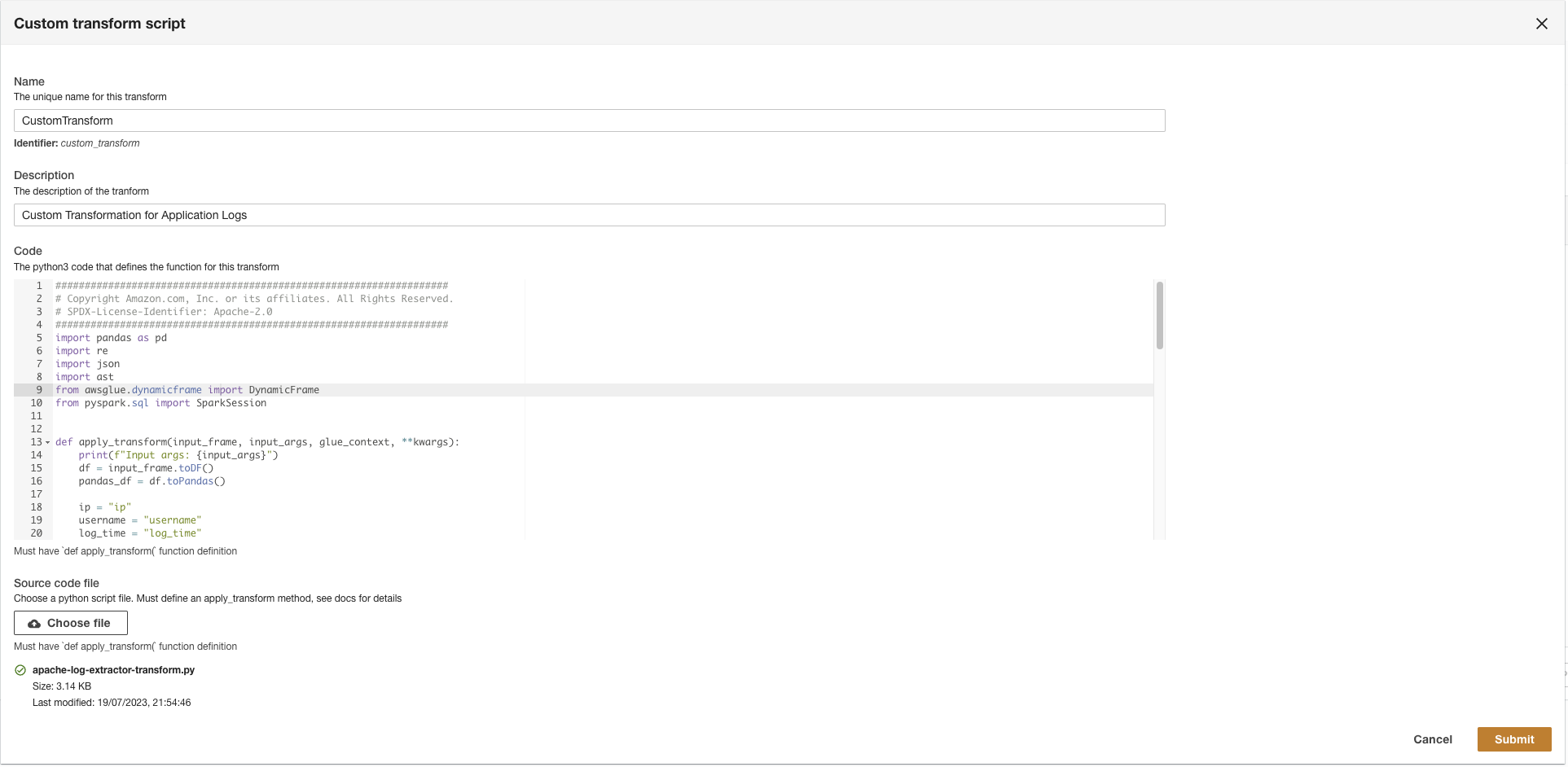
ADA kommer att omvandla CloudWatch-loggarna med hjälp av skriptet och presentera det bearbetade schemat.
- Välja Nästa.
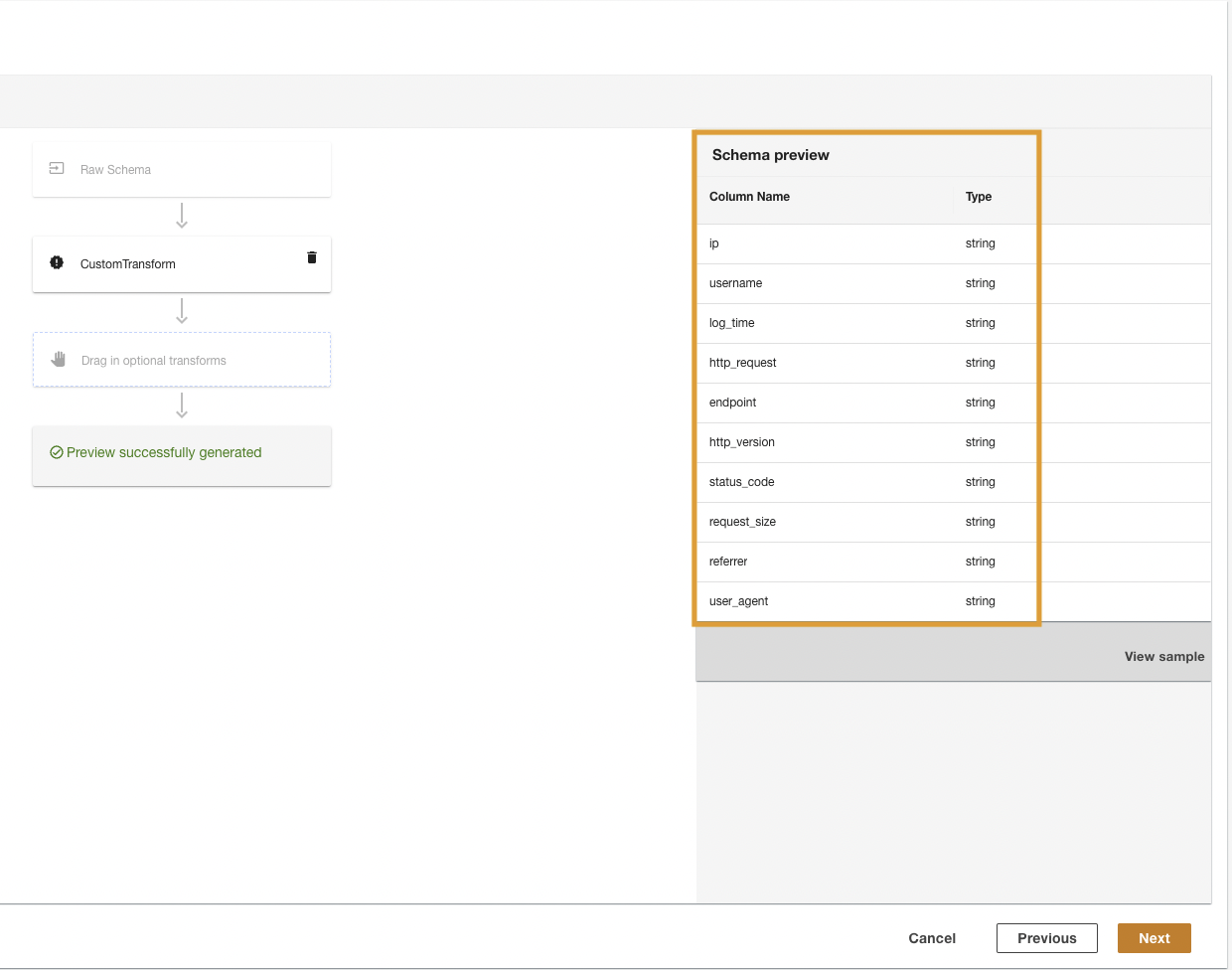
- I det sista steget, granska stegen och välj Skicka.
ADA kommer att starta databehandlingen, skapa datapipelines och förbereda CloudWatch-logggrupperna för att frågas från Query Workbench. Denna process tar några minuter att slutföra och kommer att visas på ADA-konsolen under Dataprodukter.
Skapa en Amazon S3-dataprodukt
Vi upprepar stegen för att lägga till de historiska loggarna från Amazon S3-datakällan och slå upp referensdata från DynamoDB-tabellen. För dessa två datakällor skapar vi inte anpassade transformationer eftersom dataformaten är i CSV (för historiska loggar) och nyckelattribut (för referensuppslagsdata).
- Skapa en ny dataprodukt på ADA-konsolen.
- Ange ett namn (
hist_logs) och välj Amazon S3.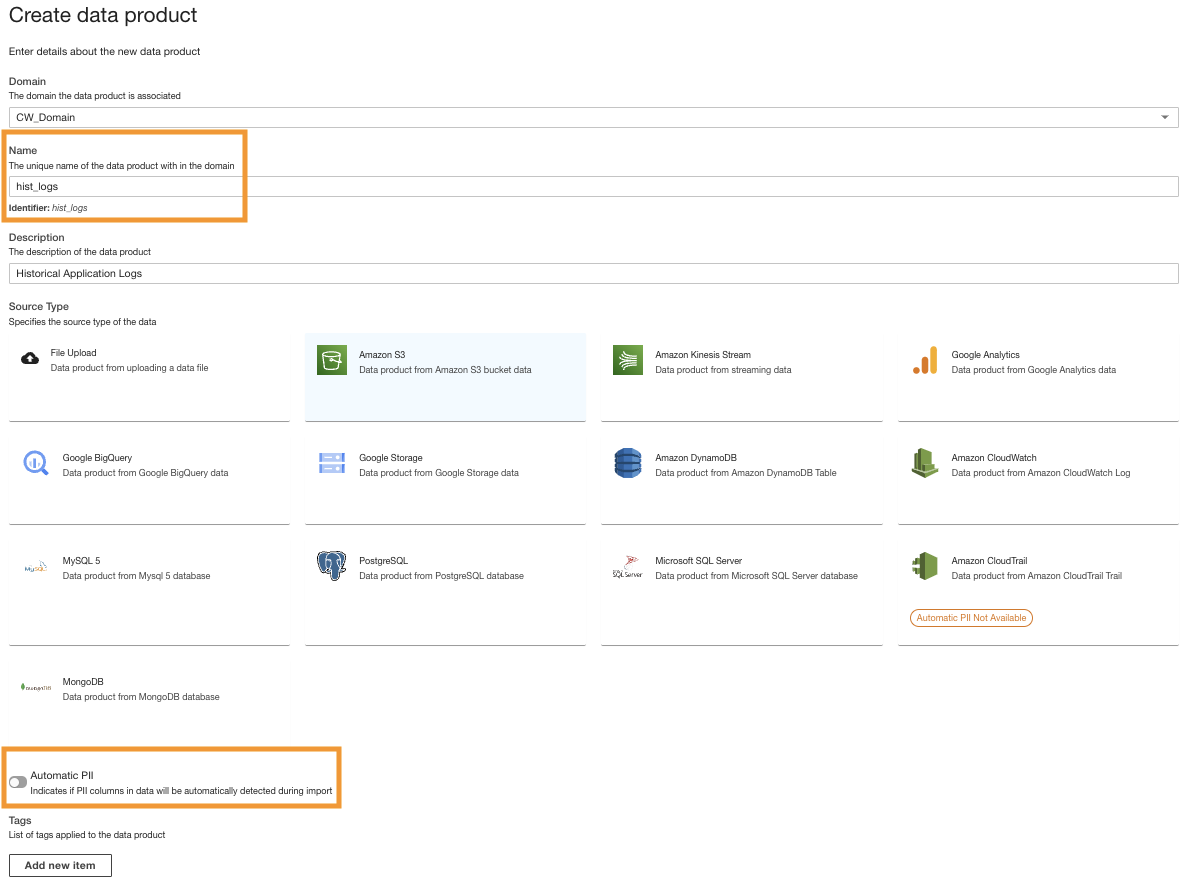
- Kopiera Amazon S3 URI (texten efter
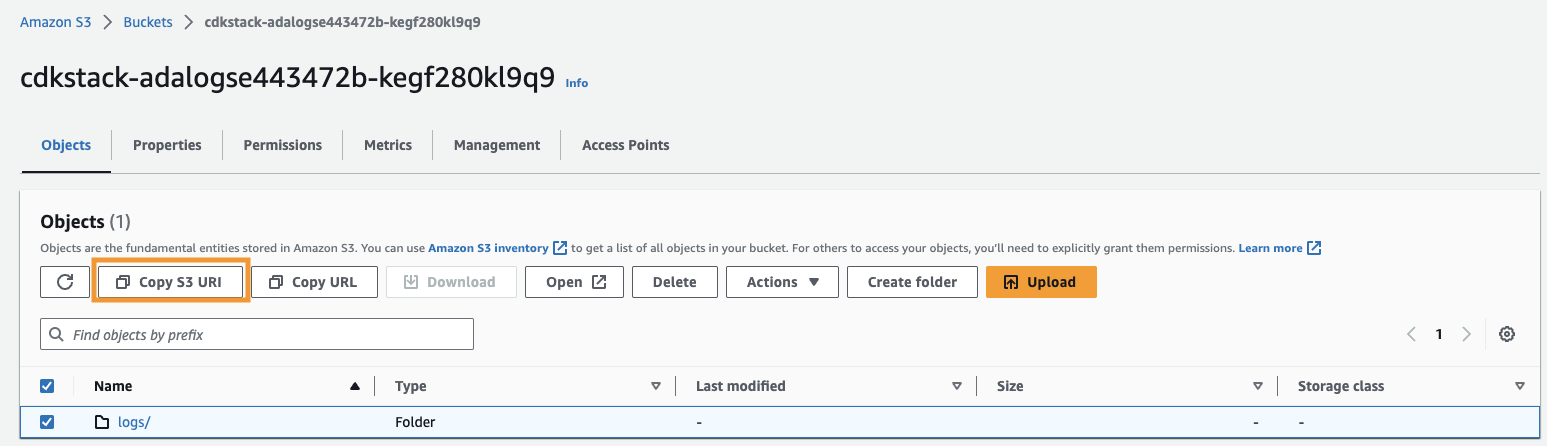
arn:aws:s3:::) frånCdkStack.S3utdatavariabel och navigera till Amazon S3-konsolen. - I sökrutan, skriv in den kopierade texten, öppna S3-hinken, välj
/logsmapp och välj Kopiera S3 URI.
De historiska loggarna lagras på denna väg.
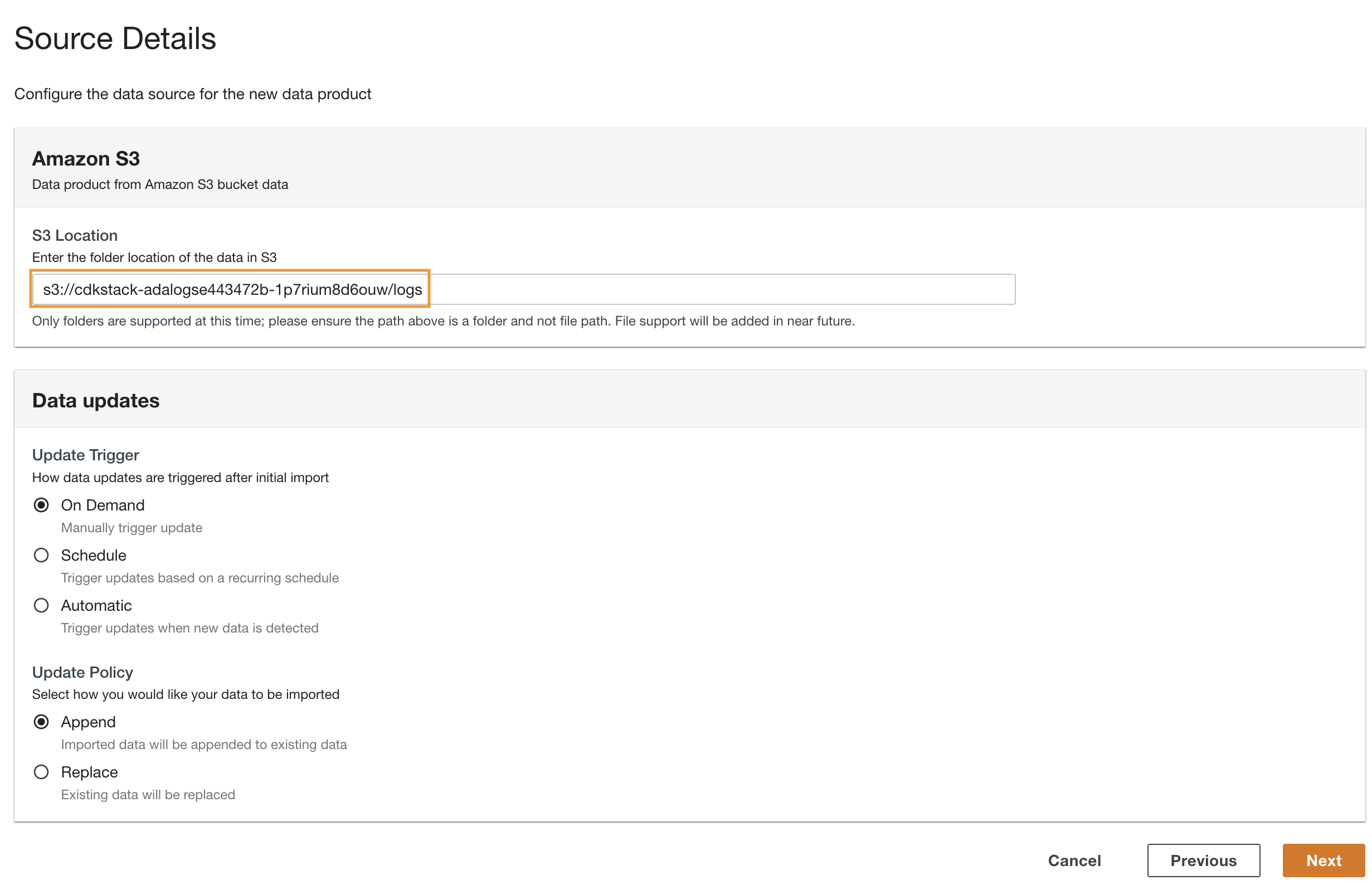
- Navigera tillbaka till ADA-konsolen och ange den kopierade S3-URI för S3-plats.
- För Uppdatera trigger, Välj På begäran eftersom de historiska loggarna uppdateras med en ospecificerad frekvens.
- För Uppdatera policy, Välj Bifoga för att lägga till nyimporterade data till befintliga data.
- Välja Nästa.
ADA bearbetar schemat för filerna i den valda mappsökvägen. Eftersom loggarna är i CSV-format kan ADA läsa kolumnnamnen utan att kräva ytterligare transformationer. Däremot kolumnerna status_code och request_size antas som lång typ av ADA. Vi vill hålla kolumndatatyperna konsekventa bland dataprodukterna så att vi kan sammanfoga datatabellerna och fråga efter data. Kolumnen status_code kommer att användas för att skapa kopplingar över datatabellerna.
- Välja Förvandla schema för att ändra datatyperna för de två kolumnerna till strängdatatyp.
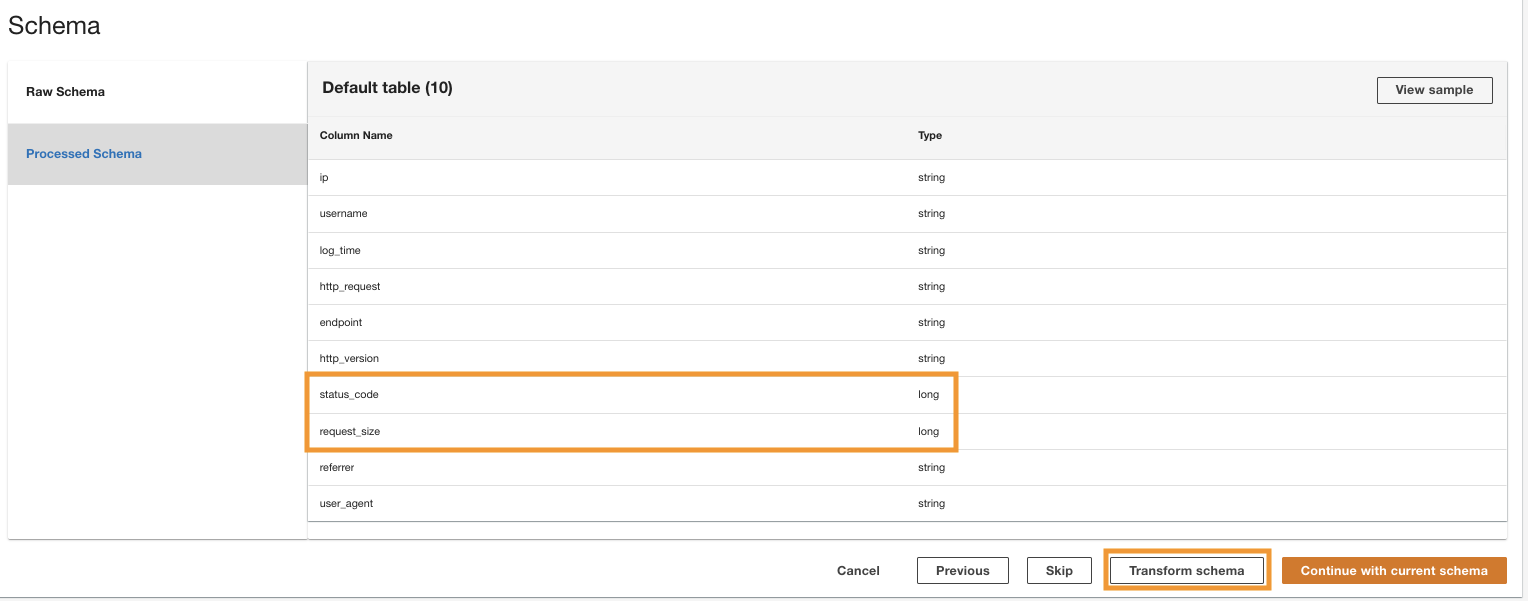
Notera de markerade kolumnnamnen i Schema förhandsgranskning innan du tillämpar datatypstransformationerna.
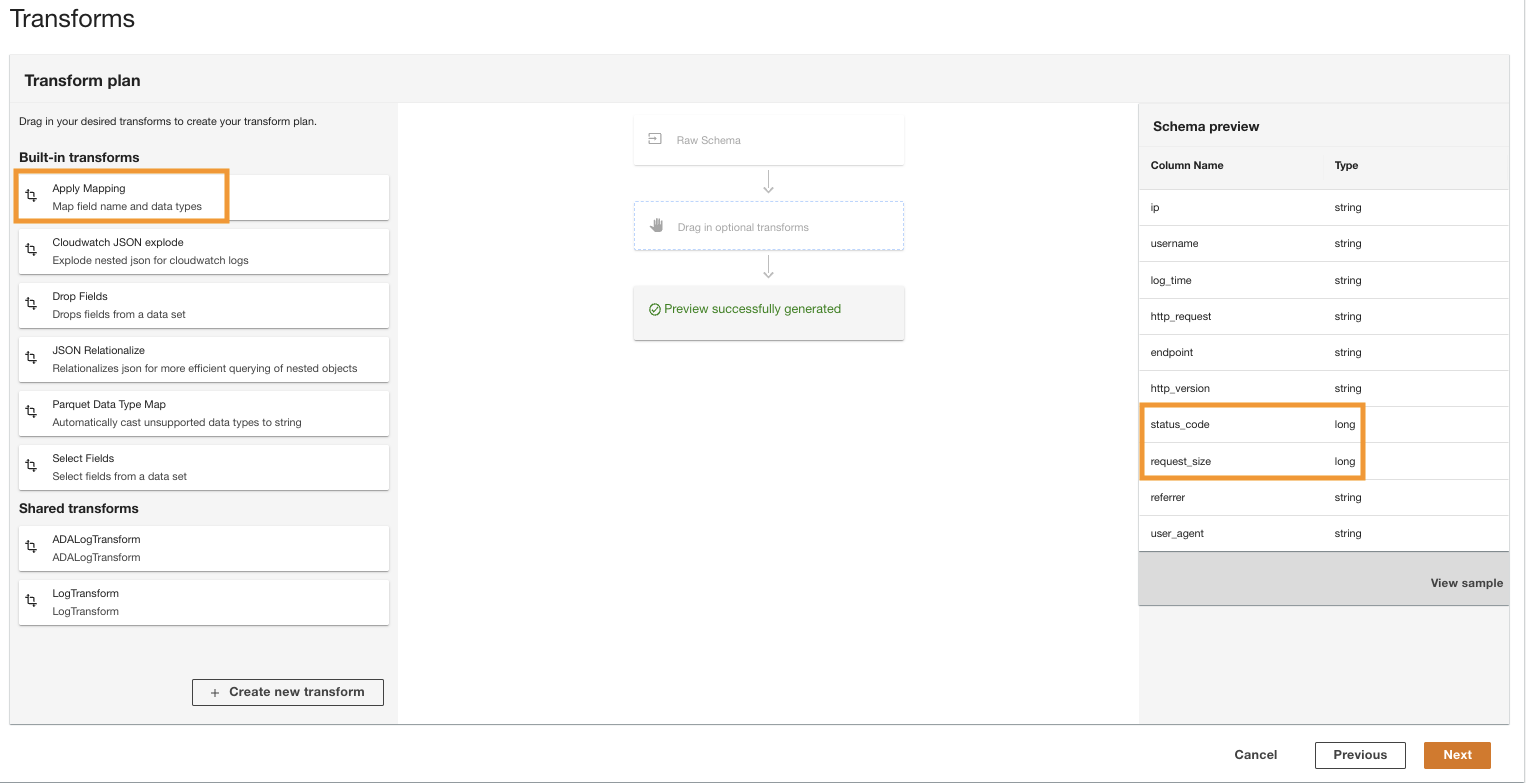
- I Förvandla plan ruta, under Inbyggda transformationerväljer Använd mappning.
Det här alternativet låter dig ändra datatypen från en typ till en annan.
- I Använd mappning avsnitt, avmarkera Släpp andra fält.
Om det här alternativet inte är inaktiverat kommer bara de transformerade kolumnerna att bevaras och alla andra kolumner kommer att tas bort. Eftersom vi vill behålla alla kolumner inaktiverar vi det här alternativet.
- Enligt Fältkartläggningarför Gammalt namn och Nytt namn, stiga på
status_codeoch för Ny typ, stiga påstring.
- Välja Lägg till artikel.
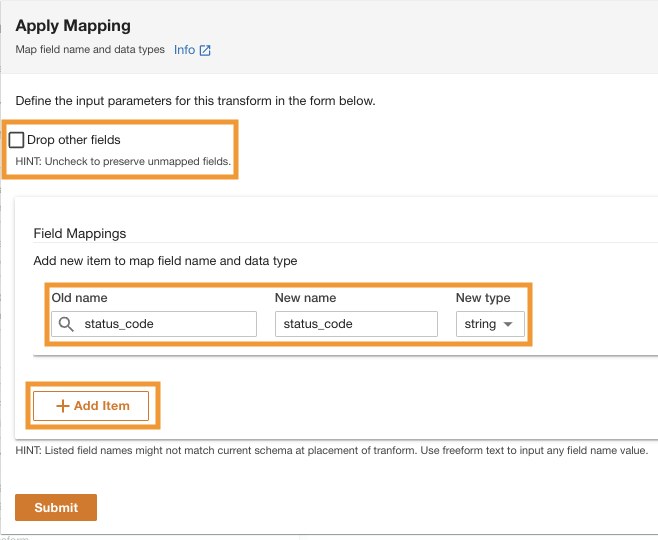
- För Gammalt namn och Nytt namn¸ ange request_size och för Ny datatyp, ange sträng.
- Välja Skicka.
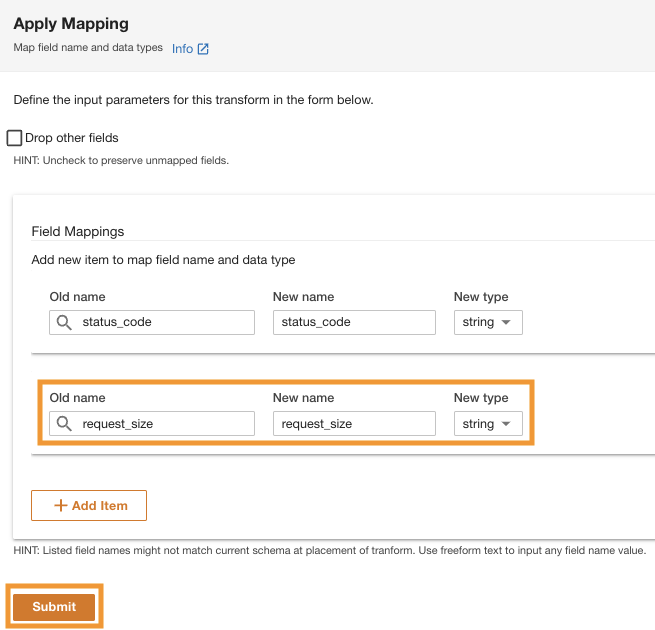
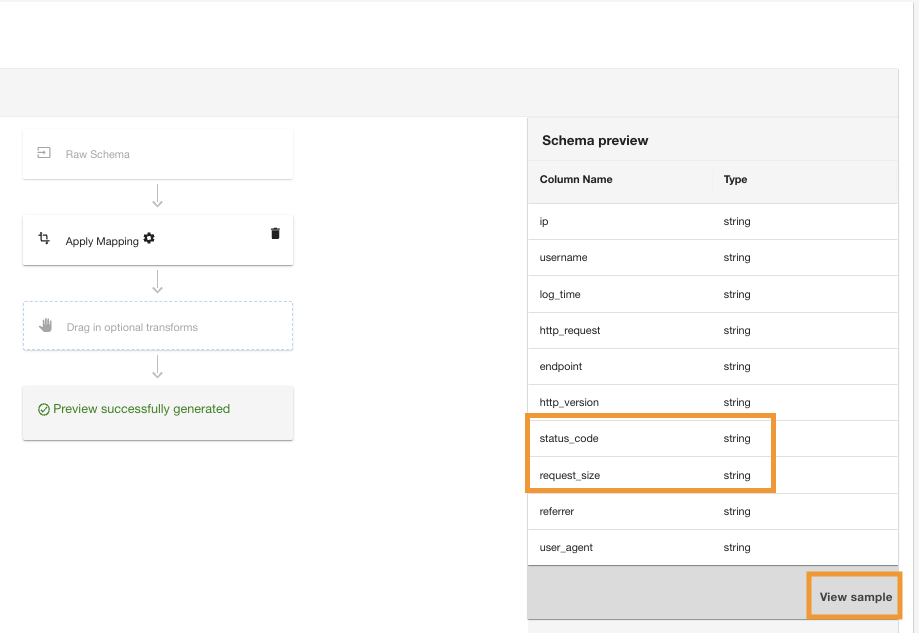
ADA kommer att tillämpa mappningstransformationen på Amazon S3-datakällan. Notera kolumntyperna i Schema förhandsgranskning rutan.
- Välja Visa prov för att förhandsgranska data med omvandlingen tillämpad.
ADA kommer att visa PII-databekräftelsen för att säkerställa att antingen endast auktoriserade användare kan se data eller att datasetet inte innehåller några PII-data.
- Välja Godkänn för att fortsätta att se exempeldata.
Observera att schemat är identiskt med CloudWatch-logggruppsschemat eftersom både den aktuella applikationen och historiska applikationsloggar är i Apache-loggformat.
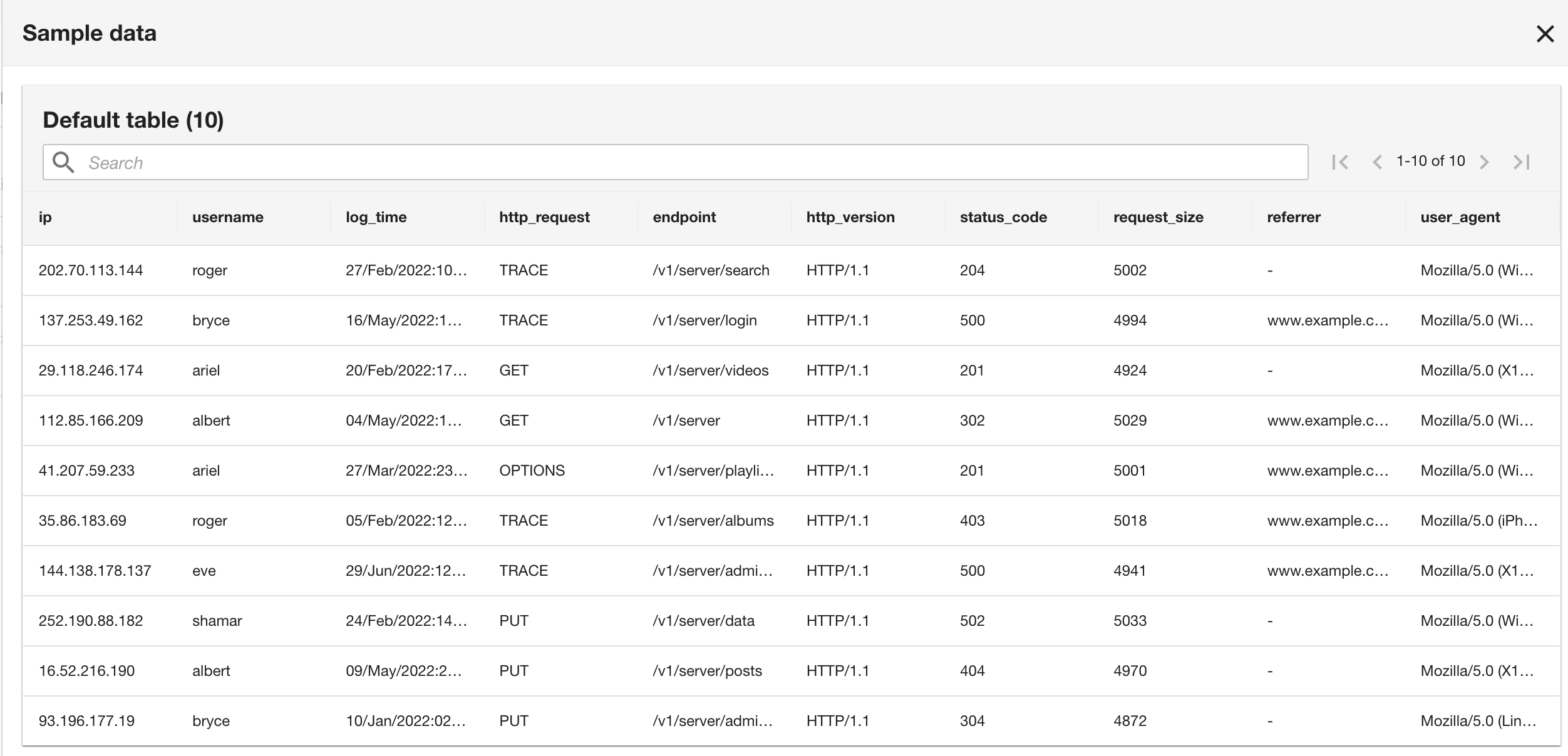
- I det sista steget, granska konfigurationen och välj Skicka.
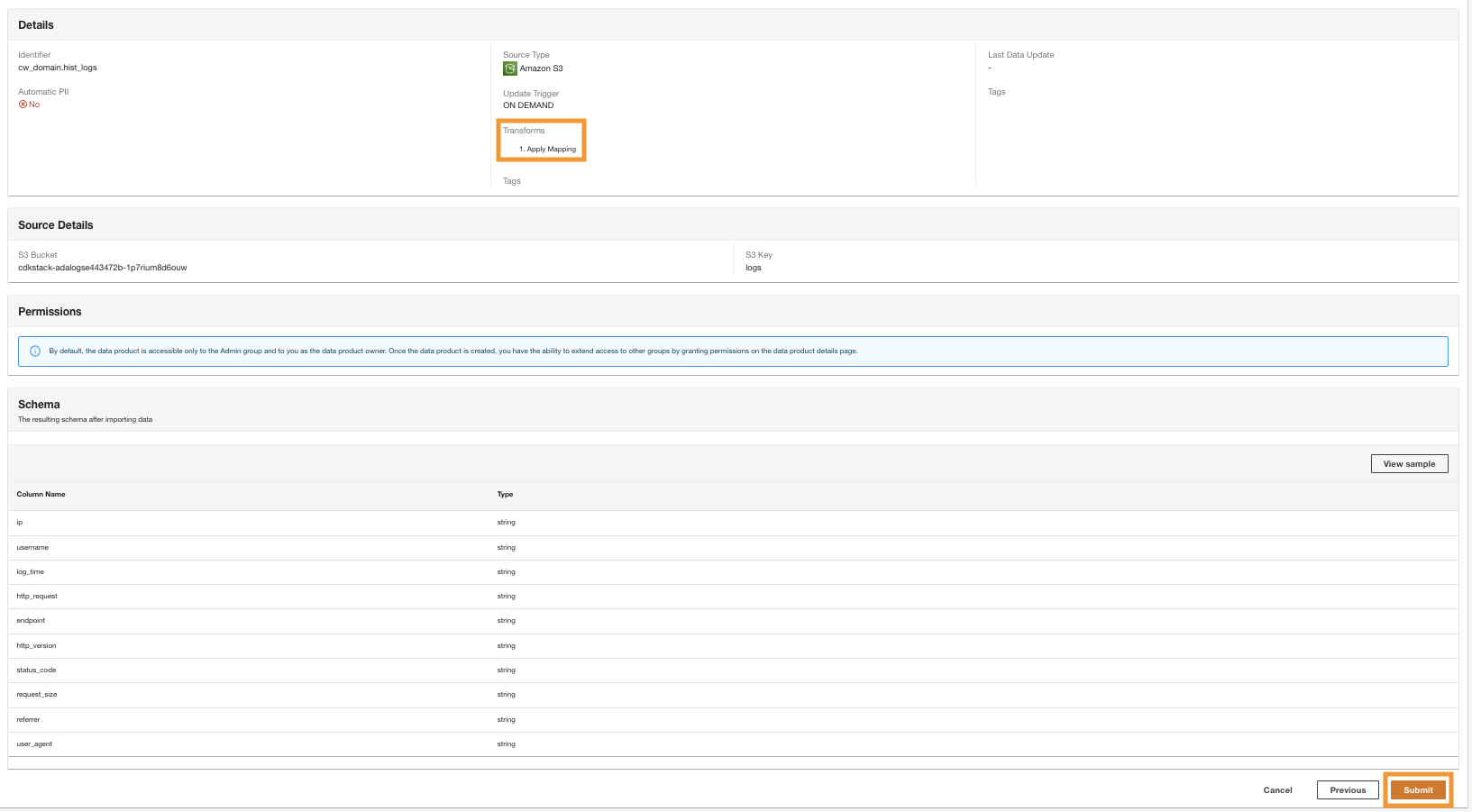
ADA börjar bearbeta data från Amazon S3-källan, skapar backend-infrastrukturen och förbereder dataprodukten. Denna process tar några minuter beroende på storleken på data.
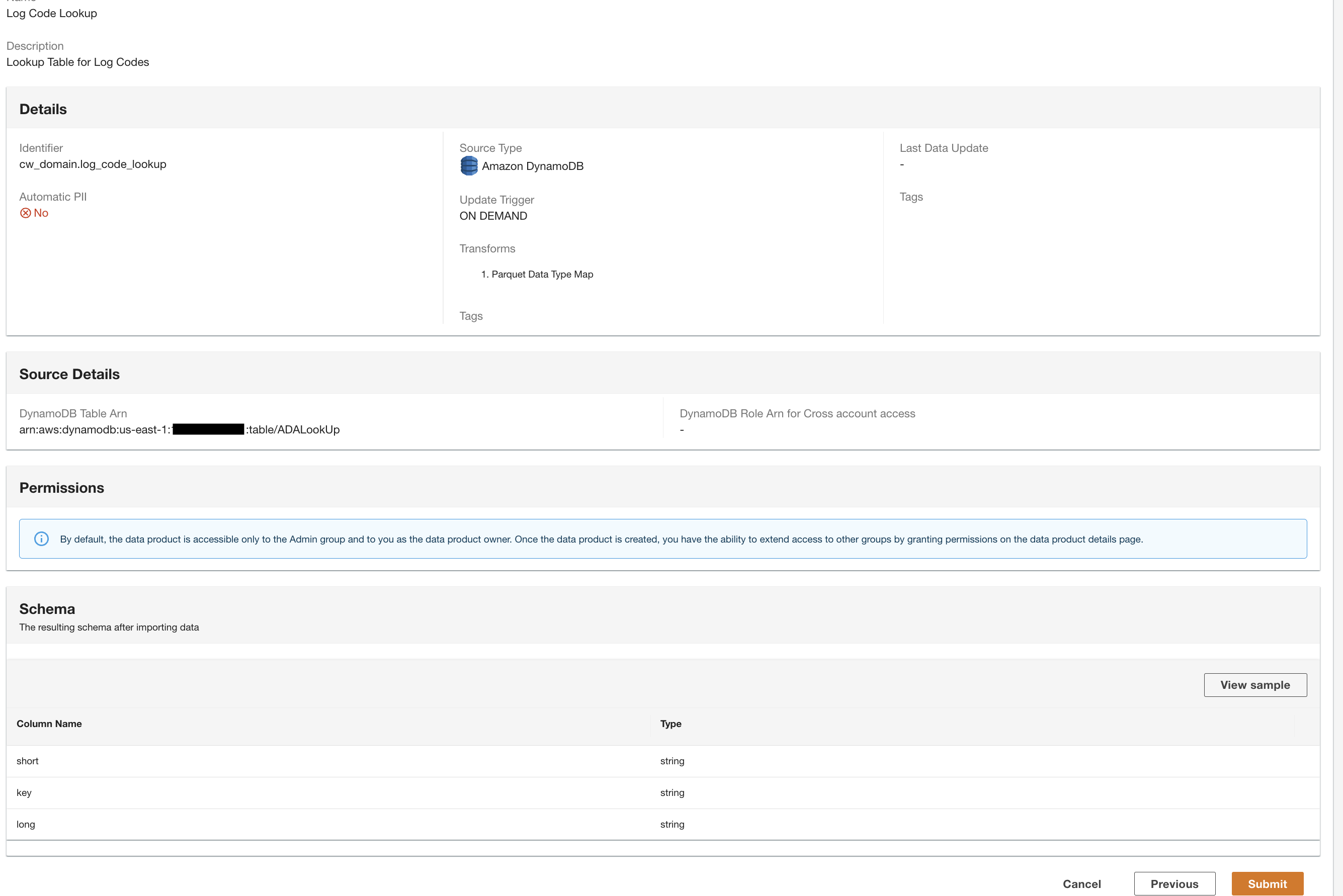
Skapa en DynamoDB-dataprodukt
Slutligen skapar vi en DynamoDB-dataprodukt. Slutför följande steg:
- Skapa en ny dataprodukt på ADA-konsolen.
- Ange ett namn (
lookup) och välj Amazon DynamoDB.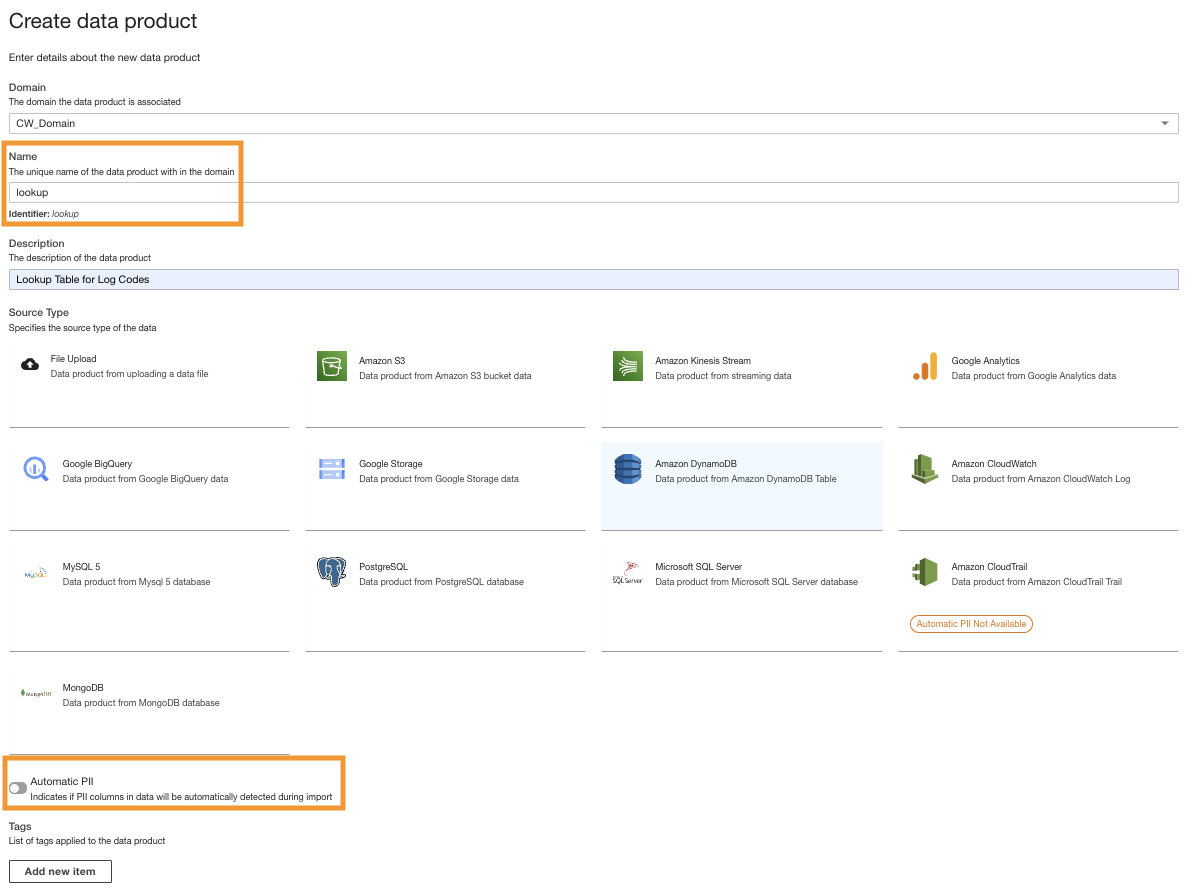
- Ange
Cdk.DynamoDBTableutgångsvariabel för DynamoDB Tabell ARN.
Den här tabellen innehåller nyckelattribut som kommer att användas som en uppslagstabell i denna demo. För uppslagsdata använder vi HTTP-koder och långa och korta beskrivningar av koderna. Du kan också använda PostgreSQL, MySQL eller en CSV-filkälla som ett alternativ.
- För Uppdatera trigger, Välj On-Demand.
Uppdateringarna kommer att ske på begäran eftersom uppslagningen mestadels är för referensändamål under förfrågningar och eventuella uppdateringar av uppslagsdata kan uppdateras i ADA med hjälp av utlösare på begäran.
- Välja Nästa.
ADA läser schemat från det underliggande DynamoDB-schemat och presenterar kolumnnamnet och typen för valfri transformation. Vi fortsätter med standardschemavalet eftersom kolumntyperna överensstämmer med typerna från CloudWatch-logggruppen och Amazon S3 CSV-datakällan. Genom att ha datatyper som är konsekventa över datakällorna kan vi skriva frågor för att hämta poster genom att sammanfoga tabellerna med kolumnfälten. Till exempel kolumnen key i DynamoDB-schemat motsvarar status_code i Amazon S3 och CloudWatch dataprodukter. Vi kan skriva frågor som kan sammanfoga de tre tabellerna med hjälp av kolumnnamnet key. Ett exempel visas i nästa avsnitt.
- Välja Fortsätt med nuvarande schema.
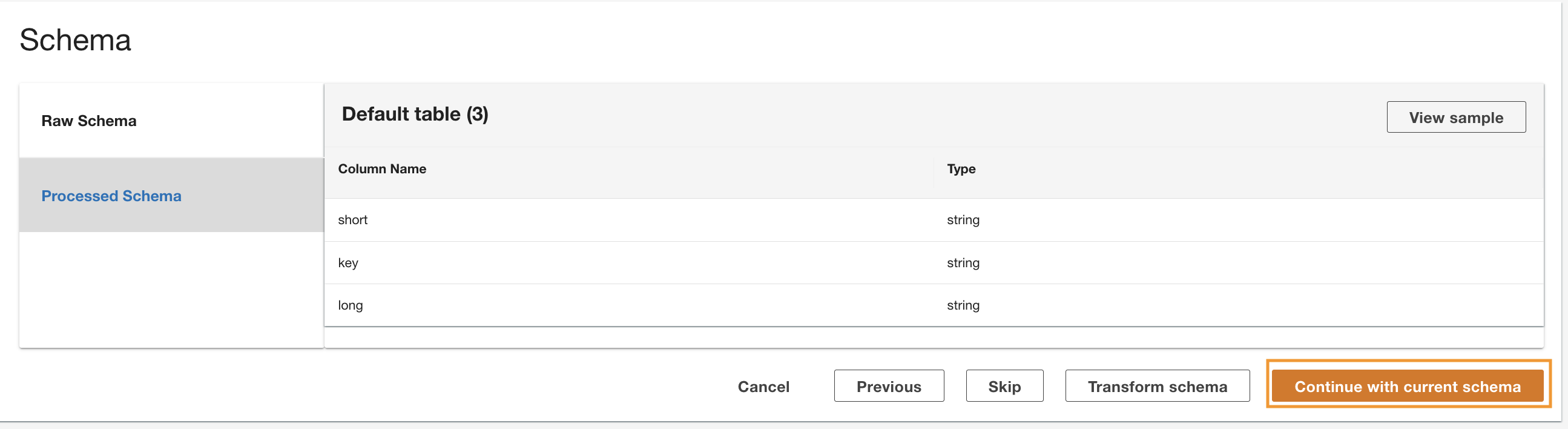
- Granska konfigurationen och välj Skicka.
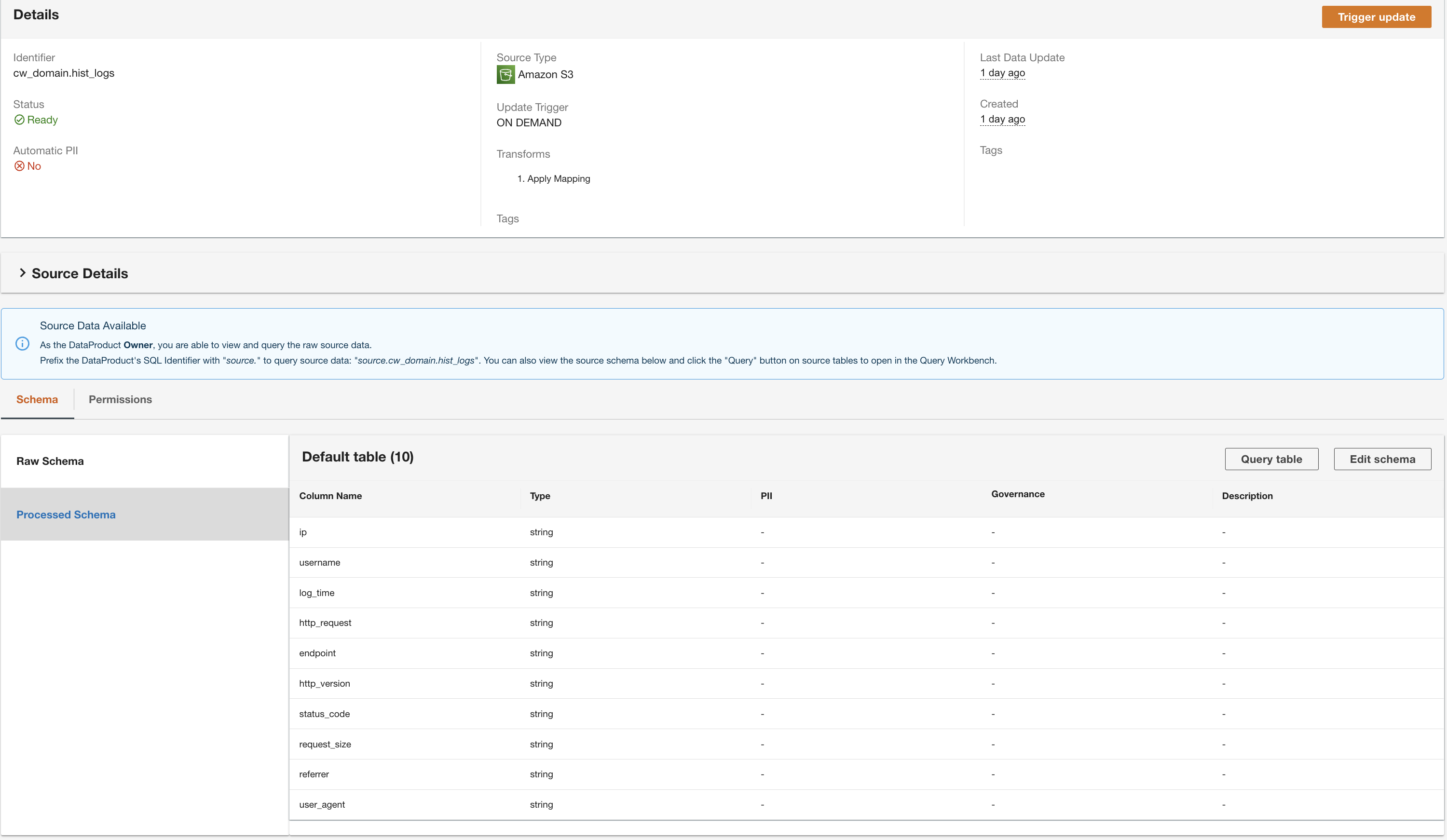
ADA kommer att bearbeta data från DynamoDB-tabelldatakällan och förbereda dataprodukten. Beroende på datastorleken tar denna process några minuter.
Nu har vi alla tre dataprodukter som bearbetats av ADA och tillgängliga för dig att köra frågor.

Använd Query Workbench för att fråga efter data
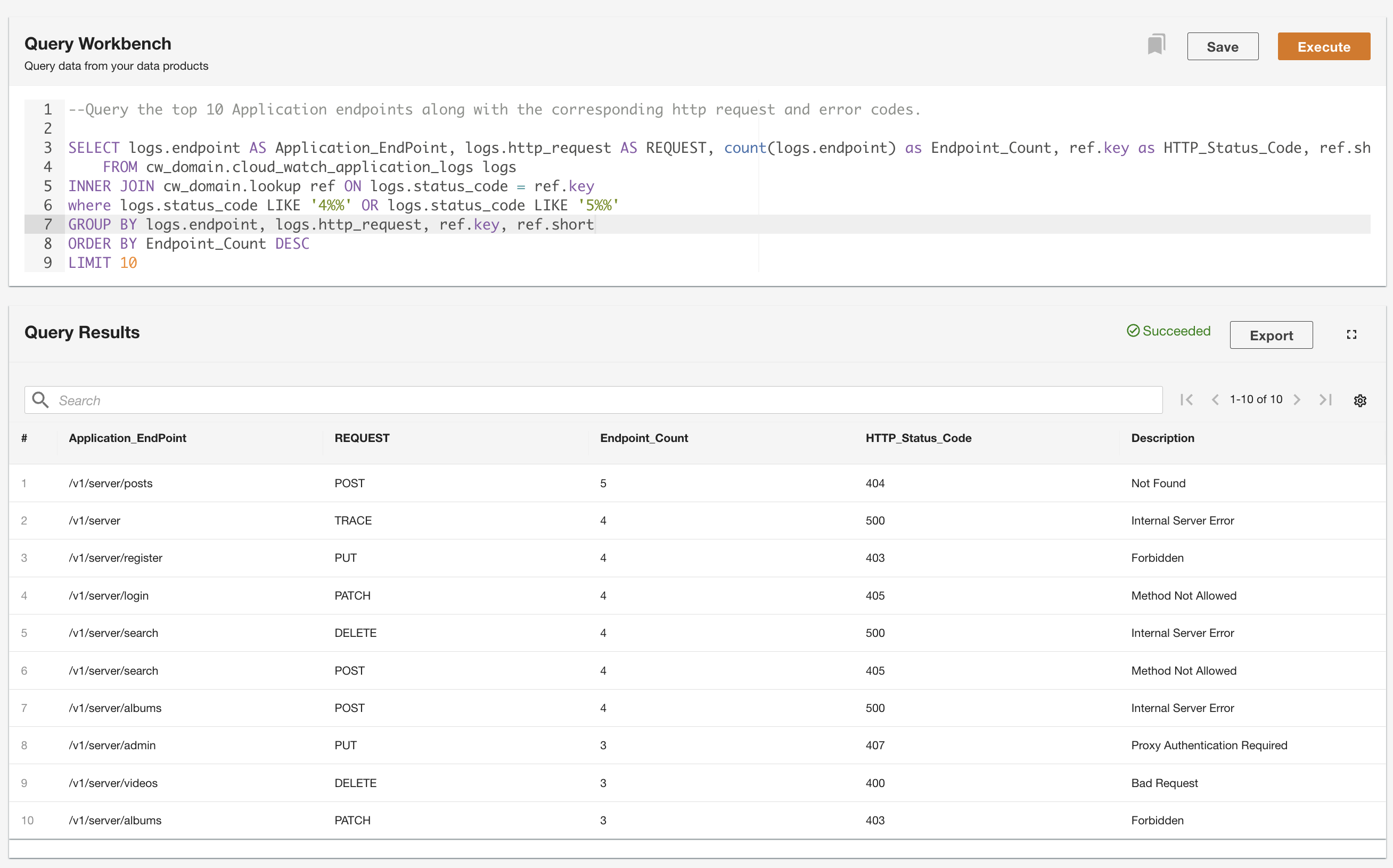
ADA låter dig köra frågor mot dataprodukterna samtidigt som du abstraherar datakällan och gör den tillgänglig med SQL (Structured Query Language). Du kan skriva frågor och sammanfoga tabellerna precis som du skulle fråga mot tabeller i en relationsdatabas. Vi visar ADA:s frågeförmåga via två användarscenarier. I båda scenarierna sammanfogar vi en applikationsloggdatauppsättning till uppslagstabellen för felkoder. I det första användningsfallet frågar vi de aktuella applikationsloggarna för att identifiera de 10 mest åtkomliga applikationsändpunkterna tillsammans med motsvarande HTTP-statuskoder:
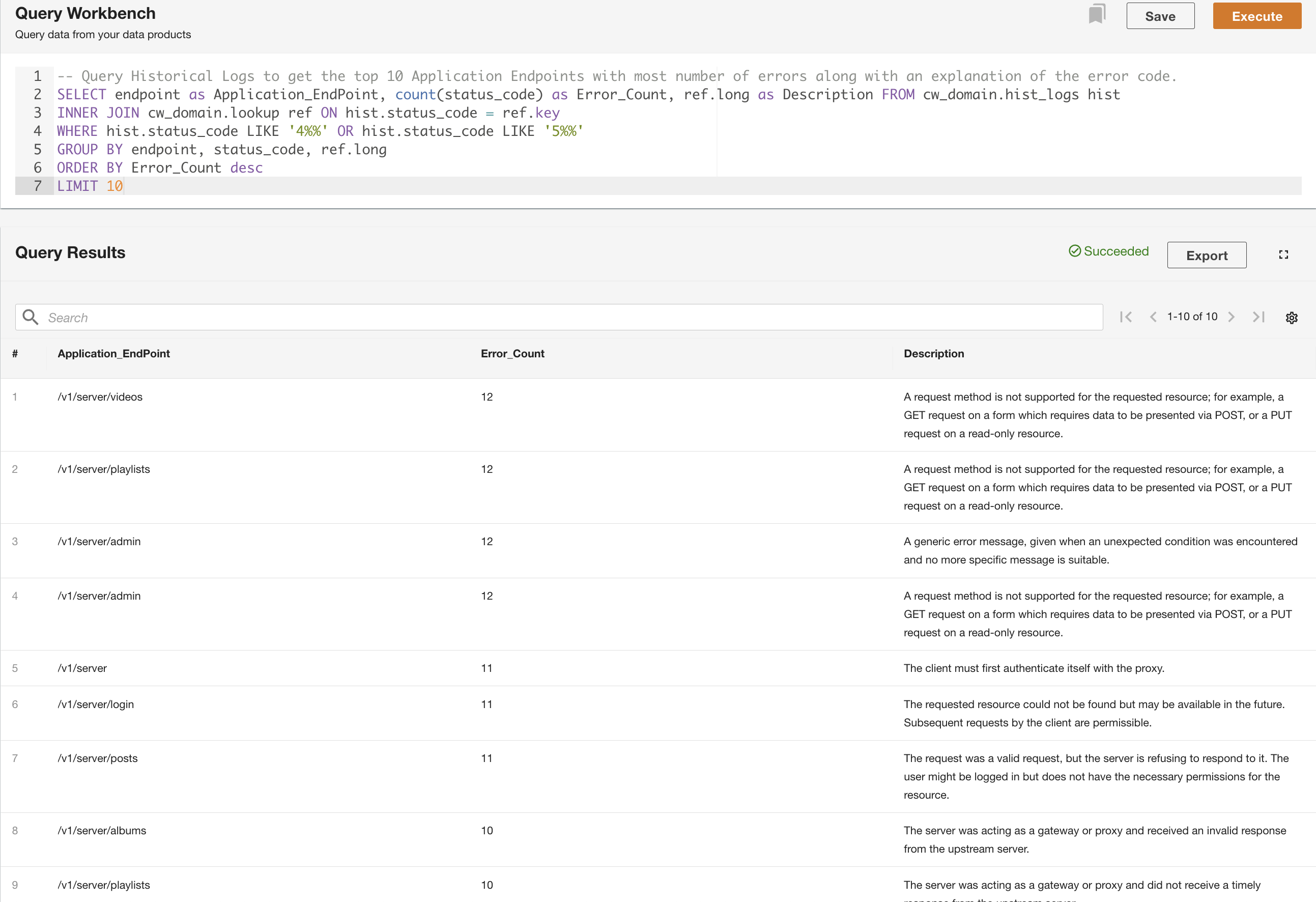
I det andra exemplet frågar vi tabellen med historiska loggar för att få de 10 bästa applikationsändpunkterna med flest fel för att förstå mönstret för slutpunktsanrop:
Förutom att fråga kan du valfritt spara frågan och dela den sparade frågan med andra användare på samma domän. De delade frågorna är tillgängliga direkt från Query Workbench. Frågeresultaten kan också exporteras till CSV-format.
Visualisera ADA-dataprodukter i Tableau
ADA erbjuder möjligheten att ansluta till tredjeparts BI-verktyg för att visualisera data och skapa rapporter från ADA-dataprodukterna. I den här demon använder vi ADA:s inbyggda integration med Tableau för att visualisera data från de tre dataprodukter som vi konfigurerade tidigare. Använda Tableaus Athena-kontakt och följa stegen i Tablåkonfiguration, kan du konfigurera ADA som en datakälla i Tableau. Efter att en framgångsrik anslutning har upprättats mellan Tableau och ADA, kommer Tableau att fylla i de tre dataprodukterna under Tableau-katalogen cw_domain.
Vi upprättar sedan en relation mellan de tre databaserna med hjälp av HTTP-statuskoden som kopplingskolumnen, som visas i följande skärmdump. Tableau låter oss arbeta i online- och offlineläge med datakällorna. I onlineläge kommer Tableau att ansluta till ADA och fråga dataprodukterna live. I offlineläge kan vi använda Utdrag alternativet att extrahera data från ADA och importera data till Tableau. I den här demon importerar vi data till Tableau för att göra sökningen mer responsiv. Vi sparar sedan Tableau-arbetsboken. Vi kan inspektera data från datakällorna genom att välja databasen och Uppdatera nu.
Med datakällans konfigurationer på plats i Tableau kan vi skapa anpassade rapporter, diagram och visualiseringar på ADA-dataprodukterna. Låt oss överväga två användningsfall för visualiseringar.
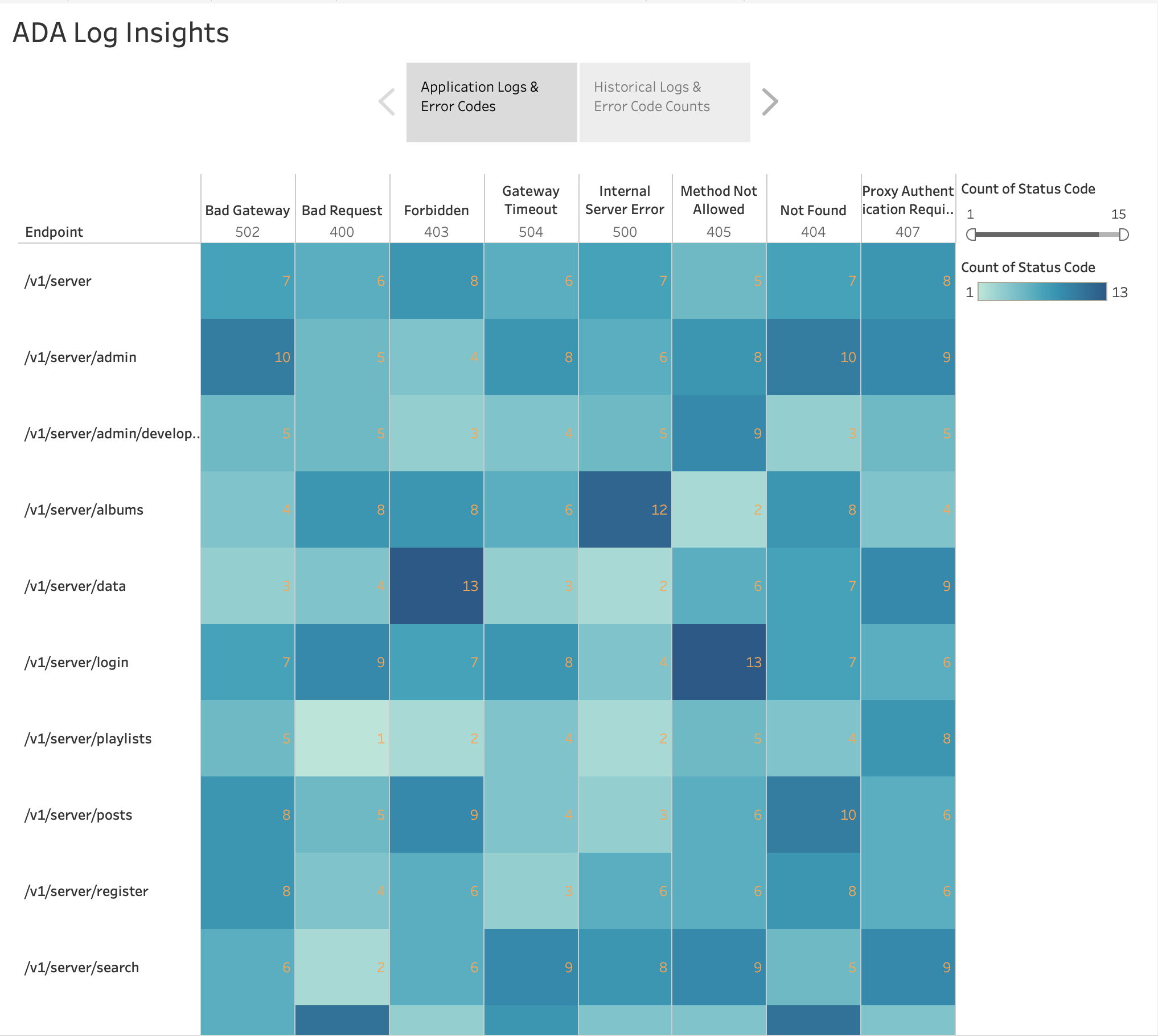
Som visas i följande figur, visualiserade vi frekvensen av HTTP-fel efter applikationsslutpunkter med hjälp av Tableaus inbyggda värmekarta Diagram. Vi filtrerade bort HTTP-statuskoderna så att de bara inkluderade felkoder i intervallet 4xx och 5xx.
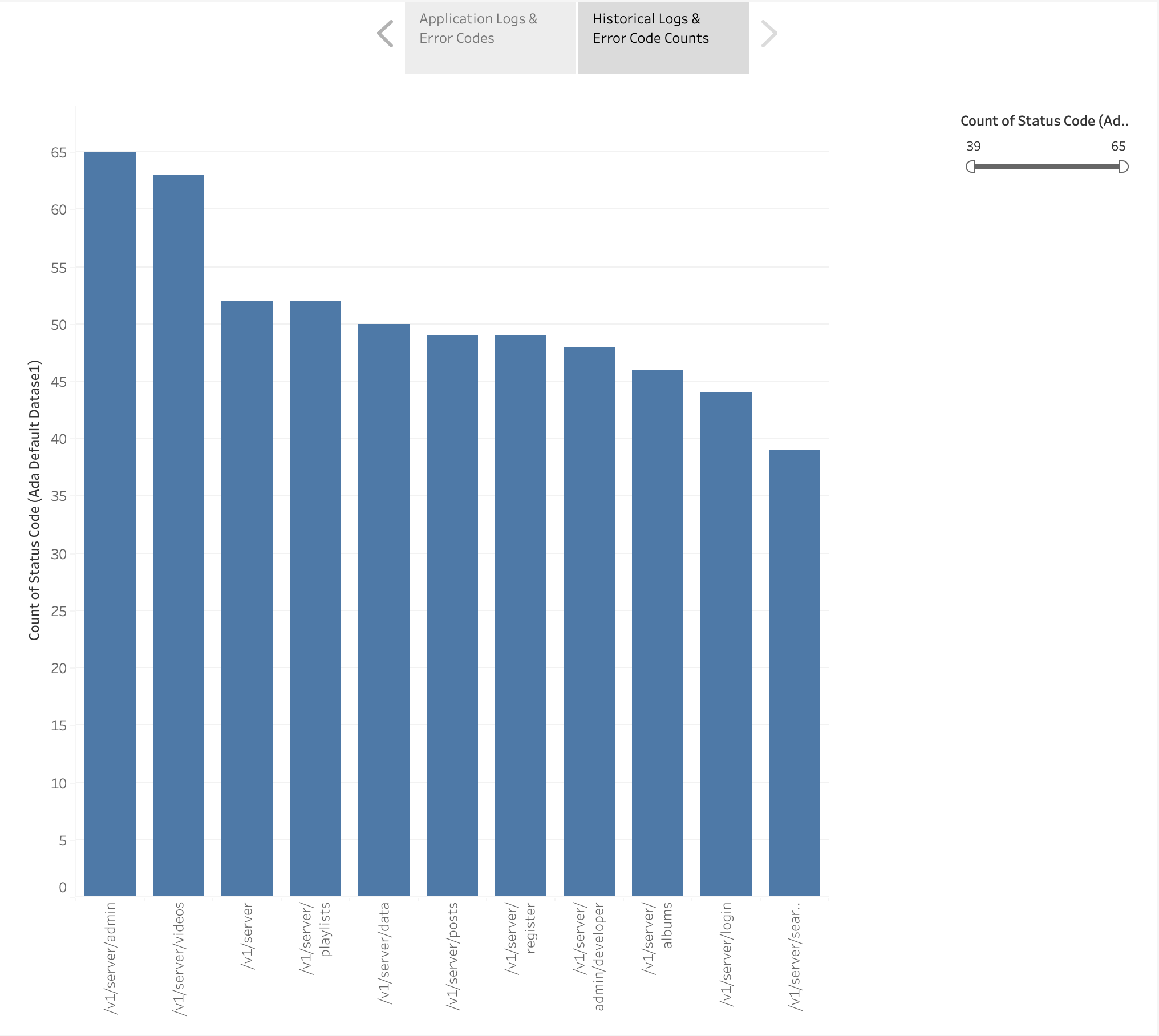
Vi skapade också ett stapeldiagram för att visa applikationens slutpunkter från de historiska loggarna sorterade efter antalet HTTP-felkoder. I det här diagrammet kan vi se att /v1/server/admin endpoint har genererat flest HTTP-felstatuskoder.
Städa upp
Att städa upp i exempelapplikationens infrastruktur är en process i två steg. Först, för att ta bort infrastrukturen som tillhandahålls för denna demo, kör följande kommando i terminalen:
För följande fråga, skriv y och AWS CDK kommer att ta bort resurserna som distribuerats för demon:
Alternativt kan du ta bort resurserna via AWS CloudFormation-konsolen genom att navigera till CdkStack-stacken och välja Radera.
Det andra steget är att avinstallera ADA. För instruktioner, se Avinstallera lösningen.
Slutsats
I det här inlägget demonstrerade vi hur man använder ADA-lösningen för att hämta insikter från applikationsloggar lagrade över två olika datakällor. Vi visade hur man installerar ADA på ett AWS-konto och distribuerar demokomponenterna med AWS CDK. Vi skapade dataprodukter i ADA och konfigurerade dataprodukterna med respektive datakällor med hjälp av ADA:s inbyggda dataanslutningar. Vi visade hur man frågar dataprodukterna med standard SQL-frågor och genererar insikter om loggdata. Vi kopplade också Tableau Desktop-klienten, en tredjeparts BI-produkt, till ADA och visade hur man bygger visualiseringar mot dataprodukterna.
ADA automatiserar processen att ta in, omvandla, styra och söka olika datauppsättningar och förenkla livscykelhanteringen av data. ADA:s förbyggda kontakter gör att du kan mata in data från olika datakällor. Programvaruteam med grundläggande kunskaper om AWS-produkter och tjänster kommer att kunna sätta upp en operativ dataanalysplattform på några timmar och ge säker åtkomst till data. Uppgifterna kan sedan enkelt och snabbt efterfrågas med hjälp av ett intuitivt och fristående webbanvändargränssnitt.
Prova ADA idag för att enkelt hantera och få insikter från data.
Om författarna
 Aparajithan Vaidyanathan är en Principal Enterprise Solutions Architect på AWS. Han hjälper företagskunder att migrera och modernisera sina arbetsbelastningar på AWS-molnet. Han är en molnarkitekt med 23+ års erfarenhet av att designa och utveckla företag, storskaliga och distribuerade mjukvarusystem. Han är specialiserad på maskininlärning och dataanalys med fokus på domänen Data och Feature Engineering. Han är en blivande maratonlöpare och hans hobbyer inkluderar vandring, cykling och att umgås med sin fru och två pojkar.
Aparajithan Vaidyanathan är en Principal Enterprise Solutions Architect på AWS. Han hjälper företagskunder att migrera och modernisera sina arbetsbelastningar på AWS-molnet. Han är en molnarkitekt med 23+ års erfarenhet av att designa och utveckla företag, storskaliga och distribuerade mjukvarusystem. Han är specialiserad på maskininlärning och dataanalys med fokus på domänen Data och Feature Engineering. Han är en blivande maratonlöpare och hans hobbyer inkluderar vandring, cykling och att umgås med sin fru och två pojkar.
 Rashim Rahman är en mjukvaruutvecklare baserad i Sydney, Australien med 10+ års erfarenhet av mjukvaruutveckling och arkitektur. Han arbetar främst med att bygga storskaliga AWS-lösningar med öppen källkod för vanliga kundanvändningsfall och affärsproblem. På fritiden gillar han sport och umgås med vänner och familj.
Rashim Rahman är en mjukvaruutvecklare baserad i Sydney, Australien med 10+ års erfarenhet av mjukvaruutveckling och arkitektur. Han arbetar främst med att bygga storskaliga AWS-lösningar med öppen källkod för vanliga kundanvändningsfall och affärsproblem. På fritiden gillar han sport och umgås med vänner och familj.
 Hafiz Saadullah är en huvudsaklig teknisk produktchef på Amazon Web Services. Hafiz fokuserar på AWS-lösningar, designade för att hjälpa kunder genom att ta itu med vanliga affärsproblem och användningsfall.
Hafiz Saadullah är en huvudsaklig teknisk produktchef på Amazon Web Services. Hafiz fokuserar på AWS-lösningar, designade för att hjälpa kunder genom att ta itu med vanliga affärsproblem och användningsfall.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Fordon / elbilar, Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- ChartPrime. Höj ditt handelsspel med ChartPrime. Tillgång här.
- BlockOffsets. Modernisera miljökompensation ägande. Tillgång här.
- Källa: https://aws.amazon.com/blogs/big-data/derive-operational-insights-from-application-logs-using-automated-data-analytics-on-aws/
- : har
- :är
- :inte
- :var
- $UPP
- 10
- 11
- 12
- 14
- 15%
- 16
- 160
- 17
- 2021
- 3000
- 500
- 7
- 8
- 9
- a
- förmåga
- Able
- Om Oss
- tillgång
- Accessed
- tillgänglig
- Konto
- tvärs
- åtgärder
- ADA
- lägga till
- Dessutom
- Annat
- adresse
- administration
- Efter
- mot
- Alla
- tillåter
- tillåter
- längs
- också
- alternativ
- amason
- Amazon Web Services
- bland
- an
- analys
- analytiker
- analytics
- analysera
- och
- Annan
- vilken som helst
- Apache
- api
- API: er
- Ansökan
- tillämpningar
- tillämpas
- Ansök
- Tillämpa
- arkitektur
- ÄR
- AS
- blivande
- At
- attribut
- Australien
- Autentisering
- tillstånd
- Automatiserad
- automatiserar
- automatiskt
- tillgänglig
- AWS
- AWS molnformation
- tillbaka
- backend
- bar
- baserat
- grundläggande
- BE
- därför att
- varit
- innan
- beställda
- mellan
- båda
- Box
- SLUTRESULTAT
- Byggnad
- inbyggd
- företag
- business intelligence
- men
- by
- Ring
- KAN
- kapacitet
- Vid
- fall
- katalog
- CD
- byta
- Diagram
- Diagram
- Välja
- välja
- klient
- cloud
- koda
- koder
- samling
- Kolumn
- Kolonner
- Gemensam
- fullborda
- komponenter
- konfiguration
- konfigurerad
- Kontakta
- anslutna
- anslutning
- ansluter
- Tänk
- konsekvent
- Konsol
- innehåller
- fortsätta
- korrelerade
- Korrelation
- Motsvarande
- motsvarar
- Pris
- skapa
- skapas
- skapar
- Skapa
- referenser
- Aktuella
- beställnings
- kund
- Kunder
- instrumentbräda
- datum
- Data Analytics
- databehandling
- Databas
- databaser
- datauppsättningar
- Standard
- Efterfrågan
- demo
- demonstrera
- demonstreras
- beroende
- distribuera
- utplacerade
- utplacering
- vecklas ut
- beskrivning
- utformade
- design
- desktop
- detaljerad
- detaljer
- Utvecklare
- utveckla
- Utveckling
- diagnos
- olika
- direkt
- inaktiverad
- Upptäckten
- Visa
- distribueras
- flera
- inte
- domän
- domäner
- inte
- tappade
- under
- varje
- Tidigare
- lätt
- redigering
- antingen
- aktiverad
- möjliggör
- Slutpunkt
- endpoints
- Teknik
- säkerställa
- ange
- Företag
- företagskunder
- Enterprise Solutions
- fel
- fel
- etablera
- etablerade
- Eter (ETH)
- exempel
- befintliga
- erfarenhet
- Förklara
- förklaring
- extrahera
- extrahera data
- bekant
- familj
- Leverans
- få
- fält
- Fält
- Figur
- Fil
- Filer
- slutlig
- finansiering
- Förnamn
- flexibel
- Fokus
- fokuserar
- efter
- För
- format
- fyra
- Frekvens
- vänner
- från
- fungera
- Få
- generera
- genereras
- skaffa sig
- få
- styrande
- Grupp
- Gruppens
- Har
- har
- he
- hjälpa
- Markerad
- vandring
- hans
- historisk
- hobbies
- värd
- ÖPPETTIDER
- Hur ser din drömresa ut
- How To
- Men
- html
- http
- HTTPS
- IAM
- identiska
- identifiera
- Identitet
- if
- importera
- in
- innefattar
- innefattar
- Inklusive
- informationen
- Infrastruktur
- inledande
- insikter
- installera
- Installationen
- instruktioner
- integrerade
- integrering
- Intelligens
- interaktiva
- intresserad
- Gränssnitt
- in
- intuitiv
- anropar
- involverade
- fråga
- IT
- delta
- sammanfogning
- Fogar
- jpg
- json
- bara
- Ha kvar
- Nyckel
- kunskap
- språk
- Large
- storskalig
- Efternamn
- senare
- lansera
- inlärning
- Bibliotek
- Licensierade
- livscykel
- tycka om
- BEGRÄNSA
- linje
- Lista
- lever
- log
- skogsavverkning
- Lång
- se
- slå upp
- Maskinen
- maskininlärning
- göra
- Framställning
- hantera
- ledning
- chef
- många
- karta
- kartläggning
- Marathon
- Marknadsföring
- Materia
- meningsfull
- meddelande
- UD
- kanske
- migrera
- minuter
- Mode
- modernisera
- mer
- mest
- för det mesta
- Mozilla
- multifaktorautentisering
- MySQL
- namn
- Som heter
- namn
- nativ
- Navigera
- navigerande
- Navigering
- Behöver
- behövs
- behov
- Nya
- nytt
- Nästa
- antal
- of
- Erbjudanden
- offline
- Gamla
- on
- On-Demand
- ONE
- nätet
- endast
- öppet
- öppen källkod
- operativa
- Alternativet
- or
- beställa
- Övriga
- Övrigt
- ut
- produktion
- Översikt
- sida
- panelen
- Lösenord
- bana
- Mönster
- utföra
- behörigheter
- Personligen
- telefon
- pii
- rörledning
- Plats
- Enkel
- Planen
- plattform
- plato
- Platon Data Intelligence
- PlatonData
- Strategier
- Portal
- Inlägg
- PostgreSQL
- drivs
- Förbered
- förbereder
- förutsättningar
- presentera
- presenterar
- Förhandsvisning
- föregående
- primärt
- Principal
- Innan
- problem
- Fortsätt
- process
- bearbetade
- processer
- bearbetning
- producerad
- Produkt
- produktchef
- Produkter
- Produkter och tjänster
- Program
- projektet
- ge
- förutsatt
- leverantör
- ger
- Syftet
- syfte
- Python
- sökfrågor
- fråga
- snabbt
- område
- Läsa
- redo
- motta
- register
- avses
- region
- relation
- relevanta
- ta bort
- upprepa
- Rapport
- begära
- Obligatorisk
- Resurser
- att
- mottaglig
- Resultat
- behålla
- översyn
- rider
- roller
- rot
- Regel
- Körning
- runner
- rinnande
- försäljning
- Samma
- Save
- Skala
- scenarier
- planerad
- omfattning
- Sök
- Andra
- §
- säkra
- säkerhet
- se
- vald
- Val
- sända
- skickas
- separat
- tjänar
- Server
- service
- Tjänster
- in
- inställning
- Dela
- delas
- Kort
- visas
- Visar
- Enkelt
- förenklade
- förenkla
- Storlek
- färdigheter
- So
- Mjukvara
- mjukvaruutveckling
- lösning
- Lösningar
- Källa
- Källor
- specialist
- specialiserat
- specifik
- specificerade
- Spendera
- Sporter
- SQL
- stapel
- fristående
- standard
- starta
- startar
- status
- Steg
- Steg
- förvaring
- lagras
- Sträng
- strukturerade
- framgångsrik
- Framgångsrikt
- sådana
- Stöder
- säker
- sydney
- System
- bord
- Tableau
- Ta
- tar
- grupp
- lag
- Teknisk
- tekniska förmågor
- terminal
- den där
- Smakämnen
- källan
- deras
- sedan
- Där.
- Dessa
- tredje part
- detta
- tre
- Genom
- tid
- till
- i dag
- verktyg
- topp
- Top 10
- Totalt
- Förvandla
- Transformation
- transformationer
- transformerad
- omvandla
- transformer
- triggas
- två
- Typ
- typer
- under
- underliggande
- förstå
- uppdaterad
- Uppdateringar
- på
- URI
- us
- användning
- användningsfall
- Begagnade
- Användare
- Användargränssnitt
- användare
- med hjälp av
- Värden
- variabel
- mängd
- version
- via
- utsikt
- vill
- Sätt..
- we
- webb
- webbservice
- VÄL
- när
- som
- medan
- bred
- Brett utbud
- fru
- kommer
- med
- inom
- utan
- Arbete
- arbetsflöde
- fungerar
- skulle
- skriva
- år
- dig
- Din
- zephyrnet