Bild av redaktör
Den 14 mars 2023 lanserade OpenAI GPT-4, den senaste och mest kraftfulla versionen av deras språkmodell.
Inom bara timmar efter lanseringen häpnade GPT-4 människor genom att vrida på en handritad skiss till en funktionell webbplats, klara advokatexamenoch generera korrekta sammanfattningar av Wikipedia-artiklar.
Den överträffar också sin föregångare, GPT-3.5, när det gäller att lösa matematiska problem och svara på frågor baserade på logik och resonemang.
ChatGPT, chatboten som byggdes ovanpå GPT-3.5 och släpptes för allmänheten, var ökänd för att "hallucinera". Det skulle generera svar som till synes var korrekta och skulle försvara sina svar med "fakta", även om de var laddade med fel.
En användare tog till Twitter efter att modellen insisterade på att elefantägg var det största av alla landdjur:
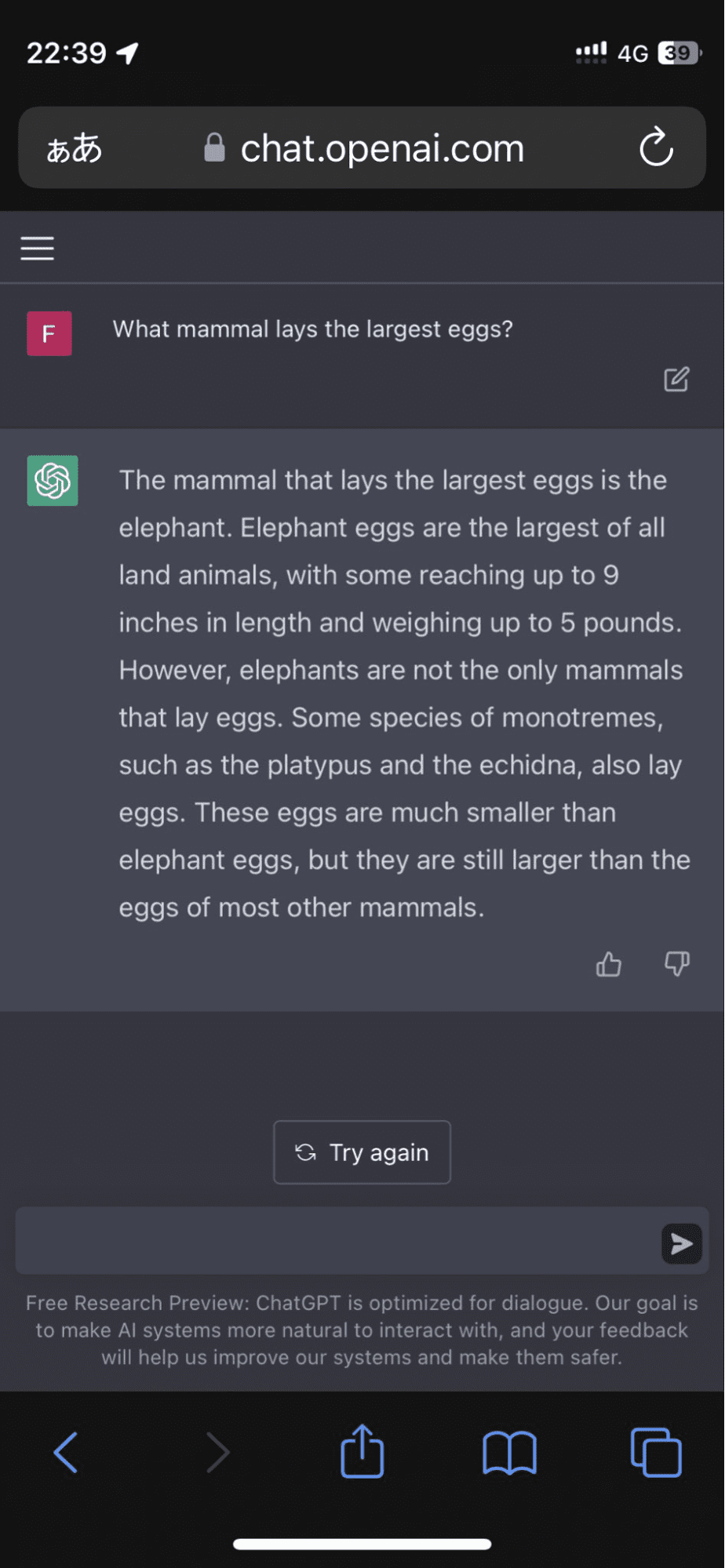
Bild från FioraAeterna
Och det stannade inte där. Algoritmen fortsatte med att bekräfta sitt svar med påhittade fakta som nästan övertygade mig för ett ögonblick.
GPT-4, å andra sidan, tränades att "hallucinera" mer sällan. OpenAI:s senaste modell är svårare att lura och genererar inte lika ofta falskheter.
Som datavetare kräver mitt jobb att jag hittar relevanta datakällor, förbearbetar stora datamängder och bygger mycket exakta maskininlärningsmodeller som driver affärsnytta.
Jag tillbringar en stor del av min dag med att extrahera data från olika filformat och konsolidera dem på ett ställe.
Efter att ChatGPT först lanserades i november 2022, tittade jag på chatboten för att få lite vägledning om mina dagliga arbetsflöden. Jag använde verktyget för att spara den tid som ägnades åt snålt arbete - så att jag kunde fokusera på att komma på nya idéer och skapa bättre modeller istället.
När GPT-4 väl släpptes var jag nyfiken på om det skulle göra någon skillnad i arbetet jag gjorde. Fanns det några betydande fördelar med att använda GPT-4 jämfört med sina föregångare? Skulle det hjälpa mig att spara mer tid än vad jag redan gjorde med GPT-3.5?
I den här artikeln kommer jag att visa dig hur jag använder ChatGPT för att automatisera datavetenskapliga arbetsflöden.
Jag kommer att skapa samma uppmaningar och mata in dem i både GPT-4 och GPT-3.5, för att se om de förra verkligen presterar bättre och resulterar i mer tidsbesparingar.
Om du vill följa med i allt jag gör i den här artikeln måste du ha tillgång till GPT-4 och GPT-3.5.
GPT-3.5
GPT-3.5 är allmänt tillgänglig på OpenAI:s hemsida. Navigera helt enkelt till https://chat.openai.com/auth/login, fyll i de nödvändiga uppgifterna så får du tillgång till språkmodellen:
Bild från ChatGPT
GPT-4
GPT-4, å andra sidan, är för närvarande gömd bakom en betalvägg. För att komma åt modellen måste du uppgradera till ChatGPTPlus genom att klicka på "Uppgradera till Plus."
Det finns en månatlig prenumerationsavgift på $20/månad som kan avbrytas när som helst:
Bild från ChatGPT
Om du inte vill betala den månatliga prenumerationsavgiften kan du också gå med i API väntelista för GPT-4. När du får tillgång till API:t kan du följa detta guide för att använda den i Python.
Det är okej om du för närvarande inte har tillgång till GPT-4.
Du kan fortfarande följa den här handledningen med gratisversionen av ChatGPT som använder GPT-3.5 i backend.
1. Datavisualisering
När jag utför utforskande dataanalys hjälper generering av en snabb visualisering i Python mig ofta att bättre förstå datasetet.
Tyvärr kan denna uppgift bli otroligt tidskrävande – speciellt när du inte kan rätt syntax att använda för att få önskat resultat.
Jag kommer ofta på mig själv med att söka igenom Seaborns omfattande dokumentation och använda StackOverflow för att generera en enda Python-plot.
Låt oss se om ChatGPT kan hjälpa till att lösa det här problemet.
Vi kommer att använda Pima Indians Diabetes datauppsättning i det här avsnittet. Du kan ladda ner datasetet om du vill följa resultaten som genereras av ChatGPT.
Efter att ha laddat ner datasetet, låt oss ladda det i Python med Pandas-biblioteket och skriva ut huvudet på dataramen:
import pandas as pd df = pd.read_csv('diabetes.csv')
df.head()
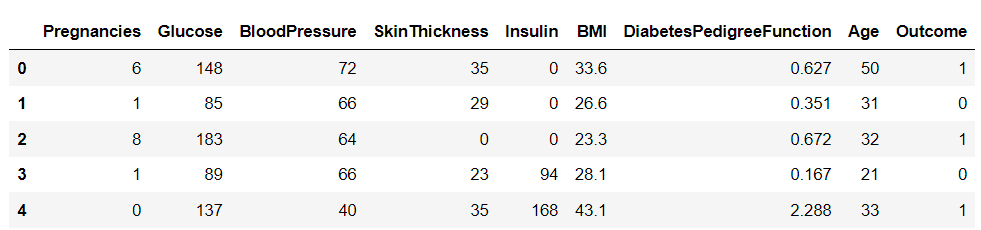
Det finns nio variabler i denna datauppsättning. En av dem, "Utfall", är målvariabeln som talar om för oss om en person kommer att utveckla diabetes. De återstående är oberoende variabler som används för att förutsäga utfallet.
Okej! Så jag vill se vilka av dessa variabler som har en inverkan på om en person kommer att utveckla diabetes.
För att uppnå detta kan vi skapa ett klustrat stapeldiagram för att visualisera variabeln "Diabetes" över alla beroende variabler i datamängden.
Detta är faktiskt ganska lätt att koda ut, men låt oss börja enkelt. Vi kommer att gå vidare till mer komplicerade uppmaningar när vi går igenom artikeln.
Datavisualisering med GPT-3.5
Eftersom jag har en betalprenumeration på ChatGPT låter verktyget mig välja den underliggande modellen jag vill använda varje gång jag använder den.
Jag kommer att välja GPT-3.5:
Bild från ChatGPT Plus
Om du inte har ett abonnemang kan du använda gratisversionen av ChatGPT eftersom chatboten använder GPT-3.5 som standard.
Låt oss nu skriva följande prompt för att generera en visualisering med hjälp av diabetesdataset:
Jag har en datauppsättning med 8 oberoende variabler och 1 beroende variabel. Den beroende variabeln, "Utfall", talar om för oss om en person kommer att utveckla diabetes.
De oberoende variablerna "Graviditeter", "Glukos", "Blodtryck", "Hudtjocklek", "Insulin", "BMI", "DiabetesPedigreeFunction" och "Ålder" används för att förutsäga detta utfall.
Kan du generera Python-kod för att visualisera alla dessa oberoende variabler efter resultat? Utdata ska vara ett klustrade stapeldiagram som färgas av variabeln "Resultat". Det bör vara 16 staplar totalt, 2 för varje oberoende variabel.
Här är modellens svar på ovanstående uppmaning:
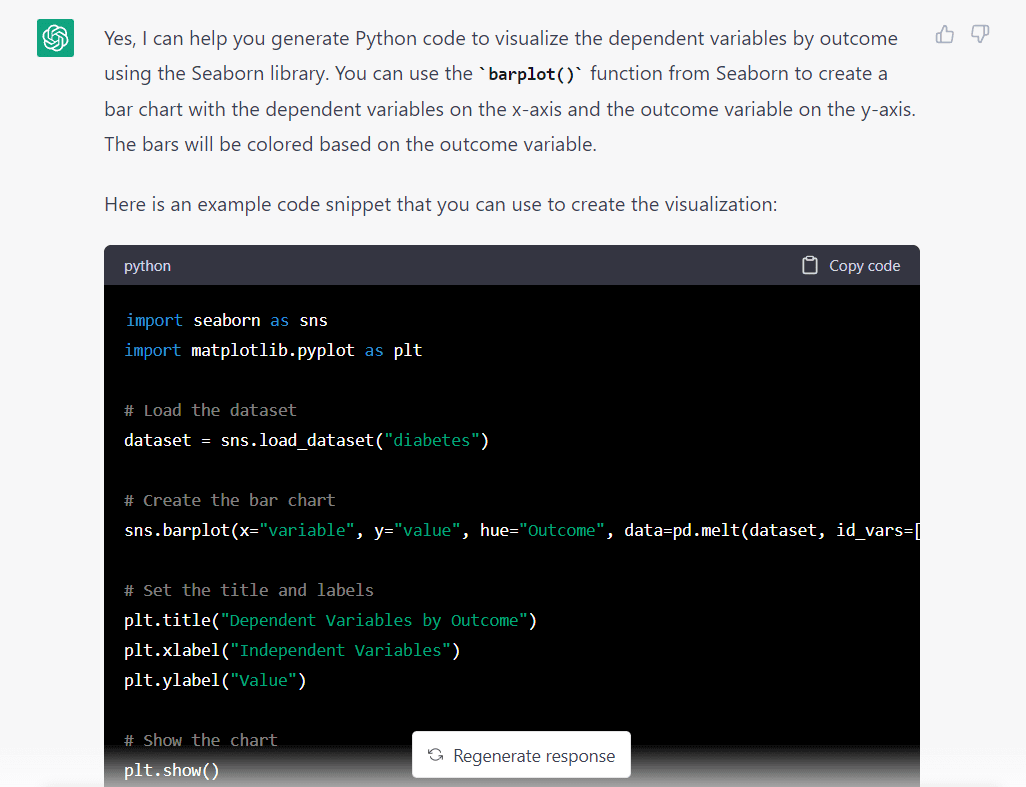
En sak som sticker ut direkt är att modellen antog att vi ville importera ett dataset från Seaborn. Det gjorde förmodligen detta antagande eftersom vi bad det att använda Seaborn-biblioteket.
Det här är inget stort problem, vi behöver bara ändra en rad innan vi kör koderna.
Här är hela kodavsnittet genererat av GPT-3.5:
import seaborn as sns
import matplotlib.pyplot as plt # Load the dataset
dataset = pd.read_csv("diabetes.csv") # Create the bar chart
sns.barplot( x="variable", y="value", hue="Outcome", data=pd.melt(dataset, id_vars=["Outcome"]), ci=None,
) # Set the title and labels
plt.title("Dependent Variables by Outcome")
plt.xlabel("Independent Variables")
plt.ylabel("Value") # Show the chart
plt.show()
Du kan kopiera och klistra in detta i din Python IDE.
Här är resultatet som genereras efter att ha kört ovanstående kod:
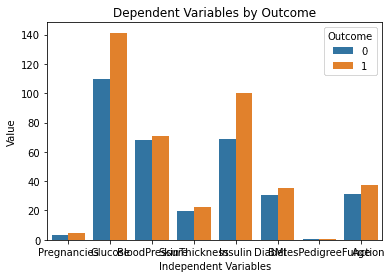
Det här diagrammet ser perfekt ut! Det är precis som jag föreställde mig det när jag skrev uppmaningen i ChatGPT.
En fråga som dock sticker ut är att texten i detta diagram överlappar varandra. Jag kommer att fråga modellen om den kan hjälpa oss att fixa detta genom att skriva följande prompt:
Algoritmen förklarade att vi kunde förhindra denna överlappning genom att antingen rotera diagrametiketterna eller justera figurstorleken. Den genererade också ny kod för att hjälpa oss uppnå detta.
Låt oss köra den här koden för att se om den ger oss önskat resultat:
import seaborn as sns
import matplotlib.pyplot as plt # Load the dataset
dataset = pd.read_csv("diabetes.csv") # Create the bar chart
sns.barplot( x="variable", y="value", hue="Outcome", data=pd.melt(dataset, id_vars=["Outcome"]), ci=None,
) # Set the title and labels
plt.title("Dependent Variables by Outcome")
plt.xlabel("Independent Variables")
plt.ylabel("Value") # Rotate the x-axis labels by 45 degrees and set horizontal alignment to right
plt.xticks(rotation=45, ha="right") # Show the chart
plt.show()
Ovanstående kodrader bör generera följande utdata:
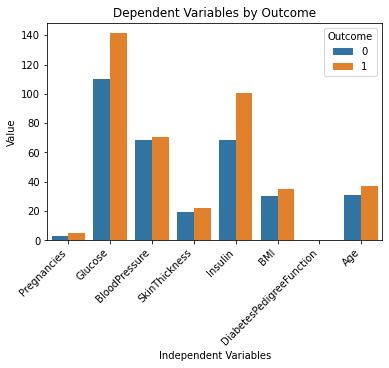
Det här ser bra ut!
Jag förstår datasetet mycket bättre nu genom att helt enkelt titta på det här diagrammet. Det verkar som om personer med högre glukos- och insulinnivåer är mer benägna att utveckla diabetes.
Observera också att variabeln "DiabetesPedigreeFunction" inte ger oss någon information i det här diagrammet. Detta beror på att funktionen är i mindre skala (mellan 0 och 2.4). Om du vill experimentera ytterligare med ChatGPT kan du uppmana den att generera flera subplots inom ett enda diagram för att lösa detta problem.
Datavisualisering med GPT-4
Låt oss nu mata in samma uppmaningar i GPT-4 för att se om vi får ett annat svar. Jag kommer att välja GPT-4-modellen inom ChatGPT och skriv in samma prompt som tidigare:
Lägg märke till hur GPT-4 inte antar att vi kommer att använda en dataram som är inbyggd i Seaborn.
Den berättar för oss att den kommer att använda en dataram som heter "df" för att bygga visualiseringen, vilket är en förbättring från svaret som genereras av GPT-3.5.
Här är den fullständiga koden som genereras av denna algoritm:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt # Assuming your DataFrame is called df
# First, you need to melt the DataFrame to make # it suitable for creating a clustered bar chart
melted_df = pd.melt( df, id_vars=["Outcome"], var_name="Independent Variable", value_name="Value",
) # Create the clustered bar chart
plt.figure(figsize=(12, 6))
sns.barplot( data=melted_df, x="Independent Variable", y="Value", hue="Outcome", ci=None,
) # Customize the plot
plt.title("Independent Variables by Outcome")
plt.ylabel("Average Value")
plt.xlabel("Independent Variables")
plt.legend(title="Outcome", loc="upper right") # Show the plot
plt.show()
Ovanstående kod bör generera följande plot:
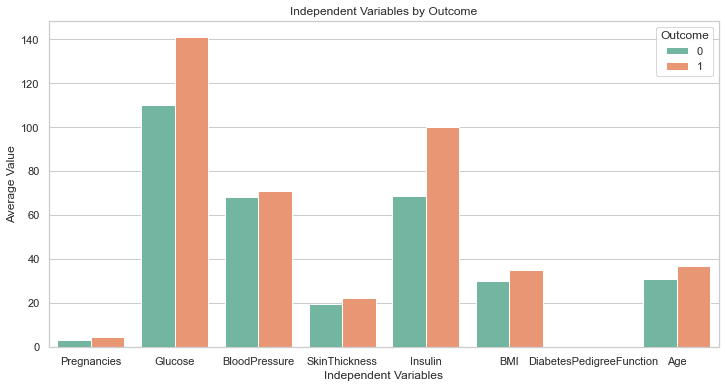
Detta är perfekt!
Även om vi inte bad om det, har GPT-4 inkluderat en kodrad för att öka tomtstorleken. Etiketterna på detta diagram är alla väl synliga, så vi behöver inte gå tillbaka och ändra koden som vi gjorde tidigare.
Detta är ett steg över svaret som genereras av GPT-3.5.
Sammantaget verkar det dock som om GPT-3.5 och GPT-4 båda är effektiva för att generera kod för att utföra uppgifter som datavisualisering och analys.
Det är viktigt att notera att eftersom du inte kan ladda upp data till ChatGPT:s gränssnitt bör du förse modellen med en korrekt beskrivning av din datauppsättning för optimala resultat.
2. Arbeta med PDF-dokument
Även om detta inte är ett vanligt användningsfall för datavetenskap, har jag varit tvungen att extrahera textdata från hundratals PDF-filer för att bygga en sentimentanalysmodell en gång. Datan var ostrukturerad och jag tillbringade mycket tid på att extrahera och förbearbeta den.
Jag arbetar också ofta med forskare som läser och skapar innehåll om aktuella händelser som äger rum i specifika branscher. De måste hålla koll på nyheterna, analysera företagsrapporter och läsa om potentiella trender i branschen.
Istället för att läsa 100 sidor av ett företags rapport, är det inte lättare att helt enkelt extrahera ord du är intresserad av och bara läsa igenom meningar som innehåller dessa nyckelord?
Eller om du är intresserad av trender kan du skapa ett automatiserat arbetsflöde som visar sökordstillväxt över tid istället för att gå igenom varje rapport manuellt.
I det här avsnittet kommer vi att använda ChatGPT för att analysera PDF-filer i Python. Vi kommer att be chatboten att extrahera innehållet i en PDF-fil och skriva det till en textfil.
Återigen kommer detta att göras med både GPT-3.5 och GPT-4 för att se om det finns en signifikant skillnad i den genererade koden.
Läsa PDF-filer med GPT-3.5
I det här avsnittet kommer vi att analysera ett allmänt tillgängligt PDF-dokument med titeln En kort introduktion till maskininlärning för ingenjörer. Se till att ladda ner den här filen om du vill koda med till det här avsnittet.
Låt oss först be algoritmen att generera Python-kod för att extrahera data från detta PDF-dokument och spara det i en textfil:
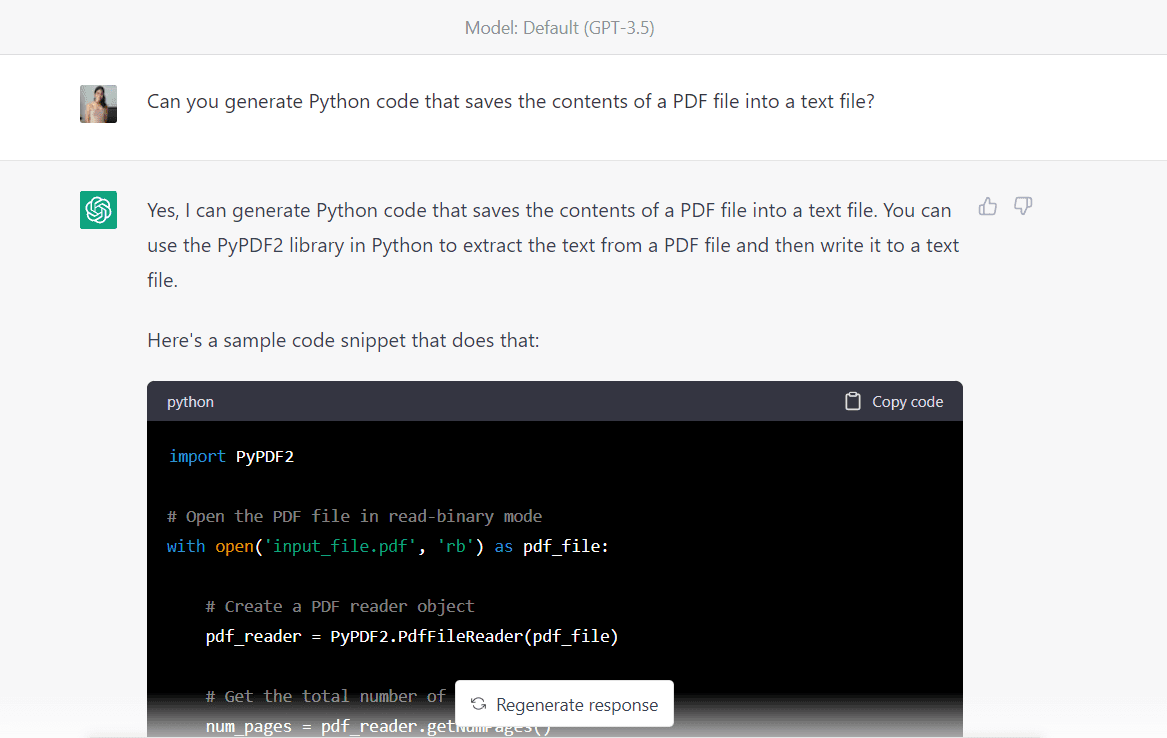
Här är den fullständiga koden som tillhandahålls av algoritmen:
import PyPDF2 # Open the PDF file in read-binary mode
with open("Intro_to_ML.pdf", "rb") as pdf_file: # Create a PDF reader object pdf_reader = PyPDF2.PdfFileReader(pdf_file) # Get the total number of pages in the PDF file num_pages = pdf_reader.getNumPages() # Create a new text file with open("output_file.txt", "w") as txt_file: # Loop through each page in the PDF file for page_num in range(num_pages): # Get the text from the current page page_text = pdf_reader.getPage(page_num).extractText() # Write the text to the text file txt_file.write(page_text)
(Obs: Se till att ändra PDF-filens namn till det du sparade innan du kör den här koden.)
Tyvärr, efter att ha kört koden som genererades av GPT-3.5, stötte jag på följande unicode-fel:

Låt oss gå tillbaka till GPT-3.5 och se om modellen kan fixa detta:
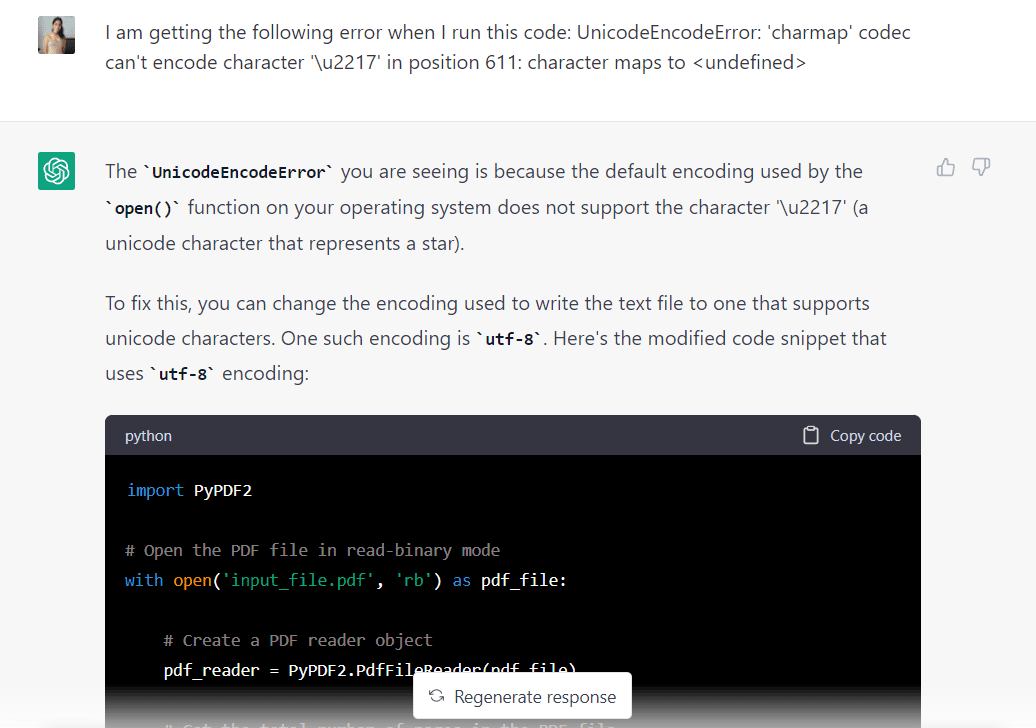
Jag klistrade in felet i ChatGPT, och modellen svarade att det kunde fixas genom att ändra kodningen som används till "utf-8." Det gav mig också lite modifierad kod som återspeglade denna förändring:
import PyPDF2 # Open the PDF file in read-binary mode
with open("Intro_to_ML.pdf", "rb") as pdf_file: # Create a PDF reader object pdf_reader = PyPDF2.PdfFileReader(pdf_file) # Get the total number of pages in the PDF file num_pages = pdf_reader.getNumPages() # Create a new text file with utf-8 encoding with open("output_file.txt", "w", encoding="utf-8") as txt_file: # Loop through each page in the PDF file for page_num in range(num_pages): # Get the text from the current page page_text = pdf_reader.getPage(page_num).extractText() # Write the text to the text file txt_file.write(page_text)
Denna kod kördes framgångsrikt och skapade en textfil som heter "output_file.txt." Allt innehåll i PDF-dokumentet har skrivits till filen:
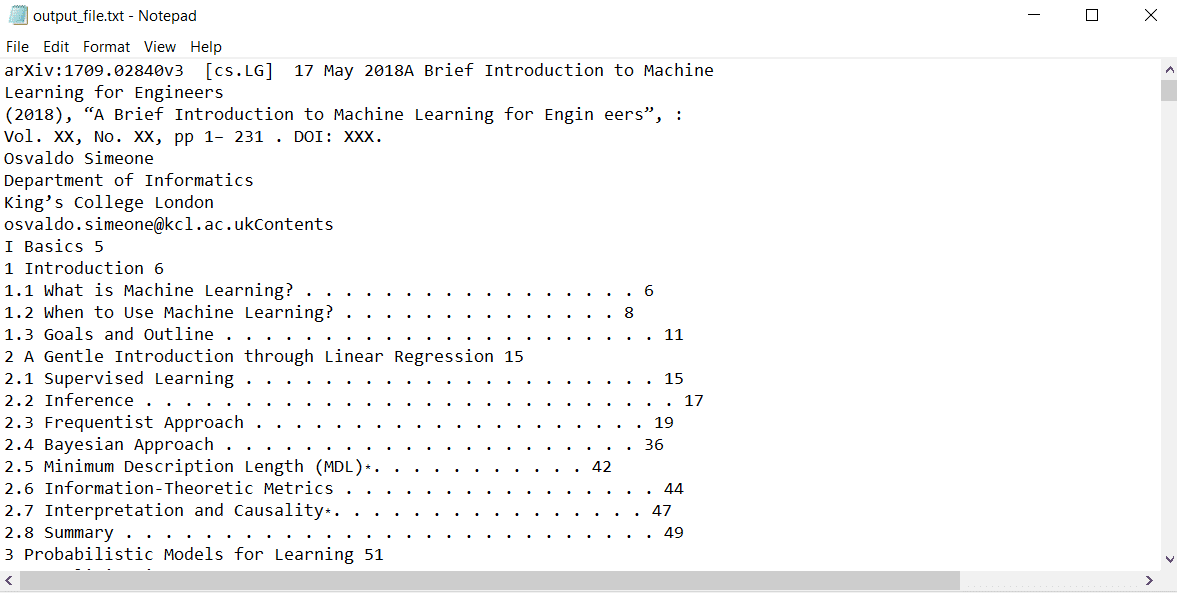
Läsa PDF-filer med GPT-4
Nu ska jag klistra in samma prompt i GPT-4 för att se vad modellen kommer med:
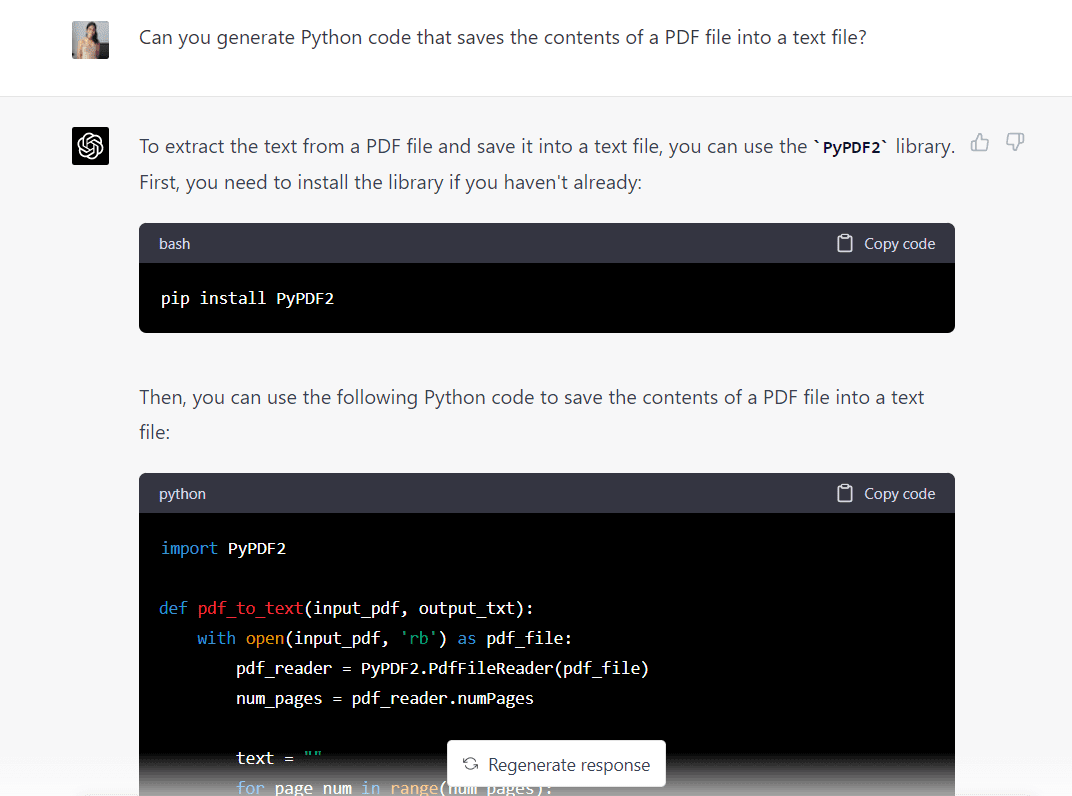
Här är hela koden genererad av GPT-4:
import PyPDF2 def pdf_to_text(input_pdf, output_txt): with open(input_pdf, "rb") as pdf_file: pdf_reader = PyPDF2.PdfFileReader(pdf_file) num_pages = pdf_reader.numPages text = "" for page_num in range(num_pages): page = pdf_reader.getPage(page_num) text += page.extractText() with open(output_txt, "w", encoding="utf-8") as text_file: text_file.write(text) input_pdf = "Intro_to_ML.pdf"
output_txt = "output_gpt4.txt"
pdf_to_text(input_pdf, output_txt)
Titta på det där!
Till skillnad från GPT-3.5 har GPT-4 redan specificerat att "utf-8"-kodning ska användas för att öppna textfilen. Vi behöver inte gå tillbaka och ändra koden som vi gjorde tidigare.
Koden som tillhandahålls av GPT-4 bör köras framgångsrikt, och du bör se innehållet i PDF-dokumentet i textfilen som skapades.
Det finns många andra tekniker du kan använda för att automatisera PDF-dokument med Python. Om du vill utforska detta ytterligare, här är några andra uppmaningar du kan skriva in i ChatGPT:
- Kan du skriva Python-kod för att slå samman två PDF-filer?
- Hur kan jag räkna förekomsten av ett specifikt ord eller en specifik fras i ett PDF-dokument med Python?
- Kan du skriva Python-kod för att extrahera tabeller från PDF-filer och skriva dem i Excel?
Jag föreslår att du provar några av dessa under din lediga tid - du skulle bli förvånad över hur snabbt GPT-4 kan hjälpa dig att utföra svåra uppgifter som vanligtvis tar timmar att utföra.
3. Skicka automatiska e-postmeddelanden
Jag tillbringar timmar av min arbetsvecka med att läsa och svara på mejl. Detta är inte bara tidskrävande, utan det kan också vara otroligt stressigt att hålla koll på e-postmeddelanden när du jagar snäva deadlines.
Och även om du inte kan få ChatGPT att skriva alla dina e-postmeddelanden åt dig (jag önskar), kan du fortfarande använda det för att skriva program som skickar schemalagda e-postmeddelanden vid en viss tidpunkt eller modifiera en enda e-postmall som kan skickas ut till flera personer .
I det här avsnittet kommer vi att få GPT-3.5 och GPT-4 för att hjälpa oss att skriva ett Python-skript för att skicka automatiska e-postmeddelanden.
Skicka automatiska e-postmeddelanden med GPT-3.5
Låt oss först skriva följande uppmaning för att generera koder för att skicka ett automatiskt e-postmeddelande:
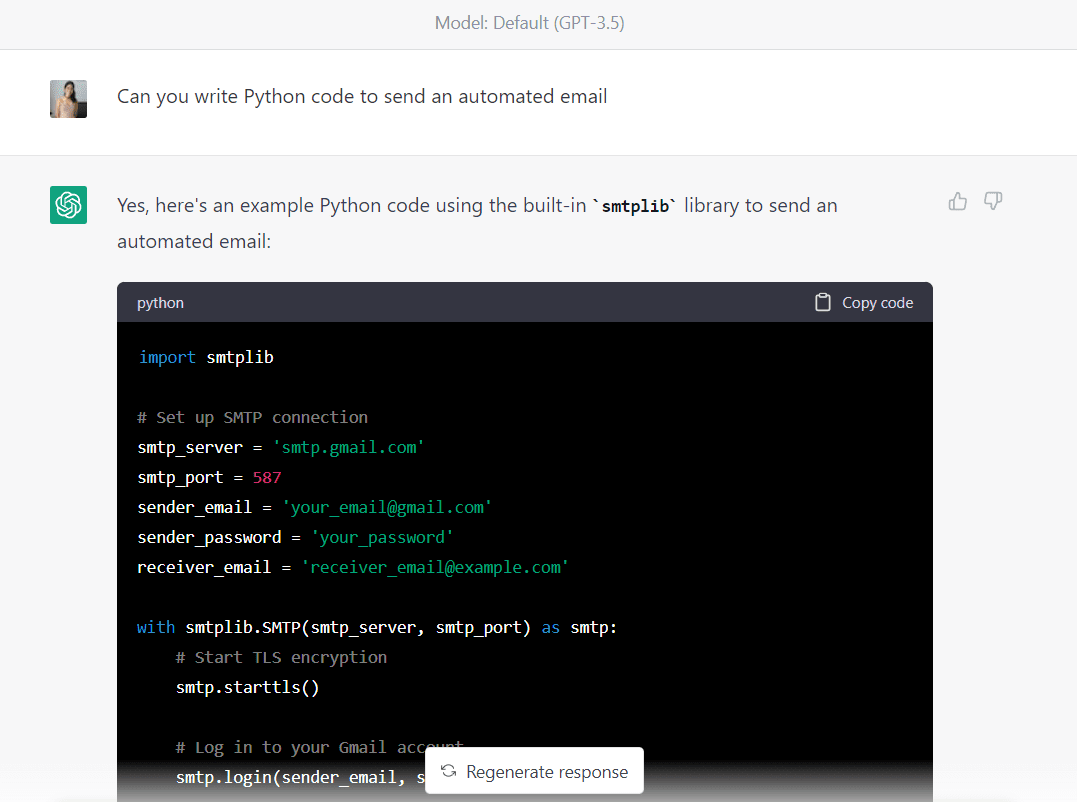
Här är den fullständiga koden som genereras av GPT-3.5 (Se till att ändra e-postadresser och lösenord innan du kör den här koden):
import smtplib # Set up SMTP connection
smtp_server = "smtp.gmail.com"
smtp_port = 587
sender_email = "your_email@gmail.com"
sender_password = "your_password"
receiver_email = "receiver_email@example.com" with smtplib.SMTP(smtp_server, smtp_port) as smtp: # Start TLS encryption smtp.starttls() # Log in to your Gmail account smtp.login(sender_email, sender_password) # Compose your email message subject = "Automated email" body = "Hello,nnThis is an automated email sent from Python." message = f"Subject: {subject}nn{body}" # Send the email smtp.sendmail(sender_email, receiver_email, message)
Tyvärr kördes inte den här koden framgångsrikt för mig. Det genererade följande fel:
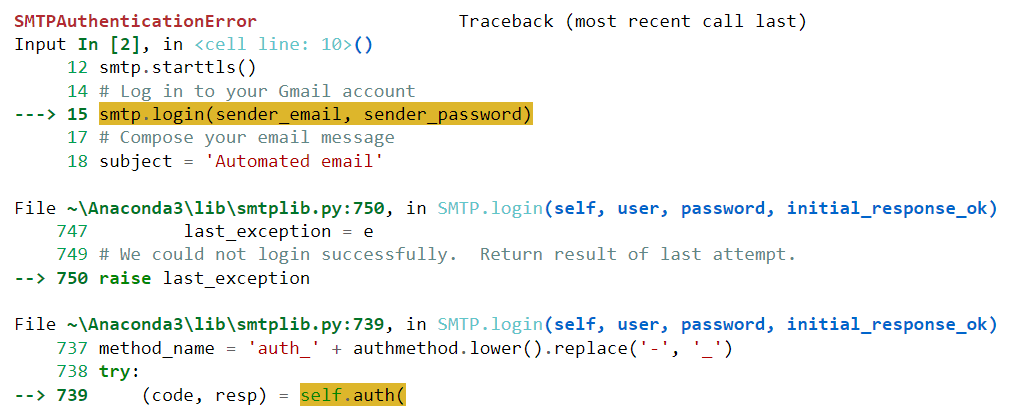
Låt oss klistra in det här felet i ChatGPT och se om modellen kan hjälpa oss att lösa det:

Okej, så algoritmen påpekade några anledningar till varför vi kan stöta på det här felet.
Jag vet med säkerhet att mina inloggningsuppgifter och e-postadresser var giltiga och att det inte fanns några stavfel i koden. Så dessa skäl kan uteslutas.
GPT-3.5 föreslår också att tillåtelse av mindre säkra appar kan lösa detta problem.
Om du provar detta kommer du dock inte att hitta något alternativ i ditt Google-konto för att tillåta åtkomst till mindre säkra appar.
Detta beror på att Google inte längre låter användare tillåta mindre säkra appar på grund av säkerhetsproblem.
Slutligen nämner GPT-3.5 också att ett applösenord ska genereras om tvåfaktorsautentisering var aktiverad.
Jag har inte tvåfaktorsautentisering aktiverad, så jag tänker (tillfälligt) ge upp den här modellen och se om GPT-4 har en lösning.
Skicka automatiska e-postmeddelanden med GPT-4
Okej, så om du skriver samma prompt i GPT-4 kommer du att upptäcka att algoritmen genererar kod som är väldigt lik vad GPT-3.5 gav oss. Detta kommer att orsaka samma fel som vi stötte på tidigare.
Låt oss se om GPT-4 kan hjälpa oss att fixa det här felet:

GPT-4:s förslag är mycket lika det vi såg tidigare.
Men den här gången ger det oss en steg-för-steg-uppdelning av hur vi ska utföra varje steg.
GPT-4 föreslår också att du skapar ett applösenord, så låt oss prova det.
Besök först ditt Google-konto, navigera till "Säkerhet" och aktivera tvåfaktorsautentisering. Sedan, i samma avsnitt, bör du se ett alternativ som säger "Applösenord."
Klicka på den och följande skärm visas:
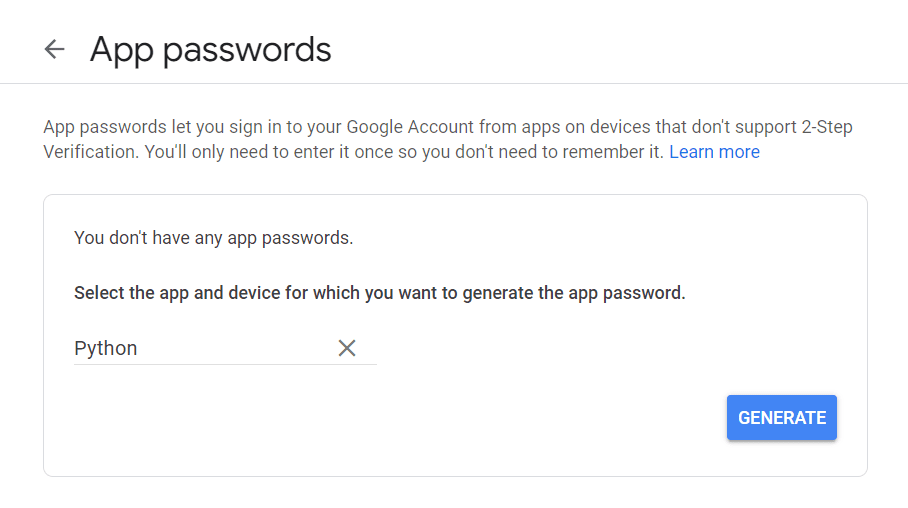
Du kan ange vilket namn du vill och klicka på "Generera".
Ett nytt applösenord visas.
Byt ut ditt befintliga lösenord i Python-koden med det här applösenordet och kör koden igen:
import smtplib # Set up SMTP connection
smtp_server = "smtp.gmail.com"
smtp_port = 587
sender_email = "your_email@gmail.com"
sender_password = "YOUR_APP_PASSWORD"
receiver_email = "receiver_email@example.com" with smtplib.SMTP(smtp_server, smtp_port) as smtp: # Start TLS encryption smtp.starttls() # Log in to your Gmail account smtp.login(sender_email, sender_password) # Compose your email message subject = "Automated email" body = "Hello,nnThis is an automated email sent from Python." message = f"Subject: {subject}nn{body}" # Send the email smtp.sendmail(sender_email, receiver_email, message)
Det bör köras framgångsrikt den här gången, och din mottagare kommer att få ett e-postmeddelande som ser ut så här:
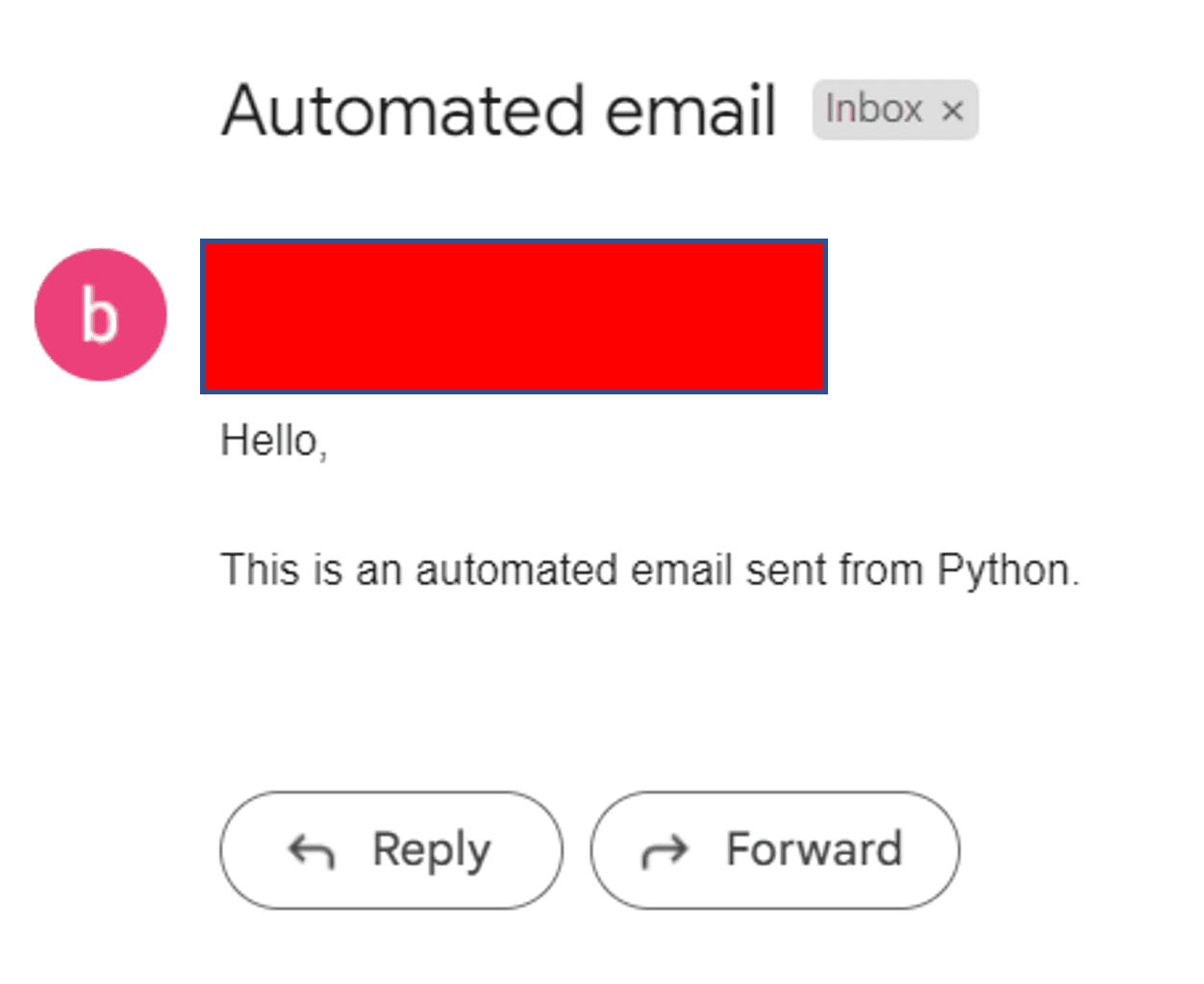
Perfekt!
Tack vare ChatGPT har vi framgångsrikt skickat ut ett automatiskt e-postmeddelande med Python.
Om du vill ta det här ett steg längre föreslår jag att du genererar uppmaningar som låter dig:
- Skicka massmeddelanden till flera mottagare samtidigt
- Skicka schemalagda e-postmeddelanden till en fördefinierad lista med e-postadresser
- Skicka ett anpassat e-postmeddelande till mottagare som är anpassat efter deras ålder, kön och plats.
Natassha Selvaraj är en självlärd dataforskare med en passion för att skriva. Du kan få kontakt med henne LinkedIn.
- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- Platoblockchain. Web3 Metaverse Intelligence. Kunskap förstärkt. Tillgång här.
- Källa: https://www.kdnuggets.com/2023/03/automate-boring-stuff-chatgpt-python.html?utm_source=rss&utm_medium=rss&utm_campaign=automate-the-boring-stuff-with-chatgpt-and-python
- :är
- $UPP
- 1
- 100
- 2022
- 2023
- 7
- 8
- a
- Om oss
- ovan
- tillgång
- åstadkomma
- Konto
- exakt
- Uppnå
- tvärs
- faktiskt
- adresser
- Efter
- algoritm
- Alla
- tillåta
- tillåter
- redan
- Även
- mängd
- analys
- analysera
- analys
- och
- djur
- svar
- api
- app
- visas
- appar
- ÄR
- Artikeln
- AS
- antas
- Antagandet
- At
- Autentisering
- automatisera
- Automatiserad
- tillgänglig
- genomsnitt
- tillbaka
- backend
- bar
- barer
- baserat
- BE
- därför att
- blir
- innan
- bakom
- Fördelarna
- Bättre
- mellan
- bmi
- kropp
- Boring
- Fördelning
- SLUTRESULTAT
- byggt
- företag
- by
- kallas
- KAN
- avbokad
- kan inte
- Orsak
- byta
- byte
- Diagram
- chatbot
- ChatGPT
- klart
- klick
- koda
- COM
- kommande
- Gemensam
- företag
- Företagets
- fullborda
- komplicerad
- oro
- självsäkert
- Kontakta
- anslutning
- konsolidera
- innehåll
- innehåll
- bekräfta
- kunde
- skapa
- skapas
- Skapa
- referenser
- nyfiken
- Aktuella
- För närvarande
- skräddarsy
- kundanpassad
- dagligen
- datum
- dataanalys
- datavetenskap
- datavetare
- datavisualisering
- datauppsättningar
- dag
- Standard
- beroende
- beskrivning
- detaljer
- utveckla
- Diabetes
- DID
- Skillnaden
- olika
- dokumentera
- dokumentation
- dokument
- inte
- gör
- inte
- ladda ner
- driv
- under
- varje
- Tidigare
- lättare
- Effektiv
- Ägg
- antingen
- elefant
- e
- möjliggöra
- aktiverad
- kryptering
- ange
- fel
- fel
- speciellt
- Eter (ETH)
- händelser
- Varje
- allt
- exakt
- excel
- exekvera
- befintliga
- experimentera
- förklarade
- Utforskande dataanalys
- utforska
- omfattande
- extrahera
- Leverans
- avgift
- få
- Figur
- Fil
- Filer
- fylla
- hitta
- Förnamn
- Fast
- fixerad
- Fokus
- följer
- efter
- För
- Tidigare
- Fri
- ofta
- från
- funktionella
- ytterligare
- Kön
- generera
- genereras
- genererar
- generera
- skaffa sig
- Ge
- ger
- gmail
- Go
- kommer
- Tillväxt
- vägleda
- styra
- sidan
- Har
- huvud
- hjälpa
- hjälper
- här.
- dold
- högre
- höggradigt
- Horisontell
- ÖPPETTIDER
- Hur ser din drömresa ut
- How To
- Men
- HTTPS
- stor
- Hundratals
- i
- idéer
- blir omedelbart
- Inverkan
- importera
- med Esport
- förbättring
- in
- ingår
- Öka
- oerhört
- oberoende
- industrier
- industrin
- informationen
- istället
- intresserad
- Gränssnitt
- Beskrivning
- fråga
- IT
- DESS
- Jobb
- delta
- KDnuggets
- Vet
- Etiketter
- land
- språk
- Large
- största
- senaste
- lansera
- lanserades
- inlärning
- Lets
- nivåer
- Bibliotek
- tycka om
- sannolikt
- linje
- rader
- Lista
- läsa in
- läge
- såg
- du letar
- UTSEENDE
- Lot
- Maskinen
- maskininlärning
- gjord
- göra
- manuellt
- många
- Mars
- matte
- matplotlib
- nämner
- Sammanfoga
- meddelande
- kanske
- Mode
- modell
- modeller
- modifierad
- modifiera
- ögonblick
- månad
- månadsabonnemang
- mer
- mest
- flytta
- multipel
- namn
- Navigera
- Behöver
- Nya
- ny app
- Senaste
- nyheter
- ökänd
- November
- antal
- objektet
- of
- Okej
- on
- ONE
- öppet
- OpenAI
- optimal
- Alternativet
- Övriga
- Resultat
- utklassar
- produktion
- sida
- betalas
- pandor
- brinner
- Lösenord
- lösenord
- Betala
- Personer
- utföra
- utför
- personen
- Plats
- plato
- Platon Data Intelligence
- PlatonData
- plus
- potentiell
- den mäktigaste
- företrädare
- förutse
- pretty
- förhindra
- tidigare
- Skriva ut
- förmodligen
- Problem
- problem
- Program
- Framsteg
- ge
- förutsatt
- allmän
- publicly
- Python
- frågor
- Snabbt
- snabbt
- Läsa
- Läsare
- Läsning
- skäl
- motta
- mottagare
- reflekterad
- frigörs
- relevanta
- Återstående
- rapport
- Rapport
- Obligatorisk
- Kräver
- forskare
- reagera
- respons
- resultera
- Resultat
- Körning
- rinnande
- Samma
- Save
- Besparingar
- säger
- Skala
- planerad
- Vetenskap
- Forskare
- screen
- havsfödda
- söka
- §
- säkra
- säkerhet
- skicka
- känsla
- in
- skall
- show
- signifikant
- liknande
- Enkelt
- helt enkelt
- eftersom
- enda
- Storlek
- mindre
- So
- lösning
- LÖSA
- Lösa
- några
- Källor
- specifik
- specificerade
- spendera
- spent
- står
- starta
- bo
- Steg
- Fortfarande
- Sluta
- ämne
- prenumeration
- Framgångsrikt
- Föreslår
- lämplig
- överraskad
- syntax
- skräddarsydd
- Ta
- tar
- Målet
- uppgift
- uppgifter
- tekniker
- berättar
- mall
- den där
- Smakämnen
- deras
- Dem
- Där.
- Dessa
- sak
- Genom
- tid
- tidskrävande
- Titel
- betitlad
- TLS
- till
- verktyg
- topp
- Totalt
- tränad
- Trender
- Vrida
- handledning
- underliggande
- förstå
- unicode
- uppgradera
- us
- användning
- Användare
- användare
- vanligen
- värde
- version
- synlig
- Besök
- visualisering
- W
- ville
- Webbplats
- Vad
- om
- som
- VEM
- wikipedia
- kommer
- med
- inom
- ord
- ord
- Arbete
- arbetsflöde
- arbetsflöden
- arbetssätt
- skulle
- skriva
- skrivning
- skriven
- Din
- zephyrnet