- SEO-drivet innehåll och PR-distribution. Bli förstärkt idag.
- PlatoData.Network Vertical Generative Ai. Styrka dig själv. Tillgång här.
- PlatoAiStream. Web3 Intelligence. Kunskap förstärkt. Tillgång här.
- Platoesg. Kol, CleanTech, Energi, Miljö, Sol, Avfallshantering. Tillgång här.
- PlatoHealth. Biotech och kliniska prövningar Intelligence. Tillgång här.
- Källa: https://www.nanowerk.com/news2/robotics/newsid=63842.php
- :är
- 10
- 100
- 15%
- 2023
- 7
- a
- Able
- tvärs
- Anta
- AI
- lika
- Alla
- Även
- bland
- an
- och
- svar
- tillämpas
- ÄR
- AS
- be
- aspekter
- assistenter
- associerad
- At
- attackera
- Attacker
- tillgänglig
- bort
- BE
- Där vi får lov att vara utan att konstant prestera,
- mellan
- miljarder
- SLUTRESULTAT
- företag
- men
- by
- KAN
- försiktigt
- VD
- chatbots
- ChatGPT
- klar
- stängt
- Gemensam
- Företag
- dator
- Oro
- om
- Konferens
- kunde
- skapa
- Skapa
- kritisk
- För närvarande
- cyber
- Datum
- demonstrera
- demonstreras
- utplacera
- detaljerad
- Detektering
- utveckla
- olika
- digital
- upptäckt
- dr
- företag
- Hela
- Även
- bevis
- existerar
- befintliga
- Exploit
- extraktion
- extremt
- fascinerande
- finansiella
- finansiella tjänster
- Förnamn
- fokuserade
- För
- från
- ytterligare
- vunnits
- ges
- Ge
- Marken
- Har
- dold
- höjdpunkter
- värd
- Hur ser din drömresa ut
- How To
- Men
- HTTPS
- Kramar ansikte
- med Esport
- in
- ökat
- alltmer
- industrin
- underrätta
- informationen
- informationssäkerhet
- insiktsfull
- Internet
- Invest
- investera
- IT
- jpg
- Nyckel
- kunskap
- känd
- språk
- Large
- Stora företag
- lansera
- ledande
- LÄRA SIG
- inlärning
- mindre
- liten
- Maskinen
- maskininlärning
- större
- Maj..
- mätning
- miljoner
- modell
- modeller
- mycket
- Nya
- of
- on
- öppet
- öppen källkod
- or
- ut
- egen
- Papper
- parti
- Peter
- platser
- planering
- plato
- Platon Data Intelligence
- PlatonData
- möjlig
- potentiellt
- den mäktigaste
- förbereda
- presenteras
- Principal
- privat
- ge
- publicly
- område
- Betygsätta
- replikeras
- förfrågningar
- forskning
- forskare
- avslöjar
- risker
- Nämnda
- säga
- vetenskapsmän
- säkerhet
- Tjänster
- in
- skall
- show
- mindre
- smarta
- So
- några
- Källa
- Etapp
- Uppstart
- Storm
- Läsa på
- framgång
- Framgångsrikt
- sådana
- tagen
- tala
- riktade
- targeting
- uppgifter
- grupp
- Tekniken
- Teknologi
- Testning
- än
- den där
- Smakämnen
- den information
- Storbritannien
- världen
- deras
- sedan
- Där.
- Dessa
- de
- tror
- Tredje
- detta
- i år
- gånger
- till
- verktyg
- överförd
- transformativ
- Uk
- förståelse
- åtar
- universitet
- användning
- Begagnade
- användningar
- värderas
- mycket
- sårbarheter
- var
- Sätt..
- we
- vecka
- były
- som
- bred
- Brett utbud
- kommer
- med
- inom
- utan
- Arbete
- träna
- fungerar
- världen
- oroande
- år
- zephyrnet
Mer från Nanoverk
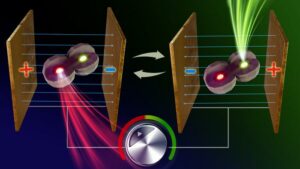
Släpp lös en ny era av färgavstämbara nanoenheter – den minsta ljuskällan någonsin med växlande färger bildade
Källnod: 2801585
Tidsstämpel: Augusti 3, 2023

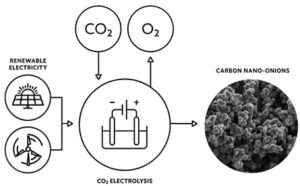
Kolnanorör kan spela en betydande roll för att binda atmosfärisk koldioxid
Källnod: 2836729
Tidsstämpel: Augusti 21, 2023

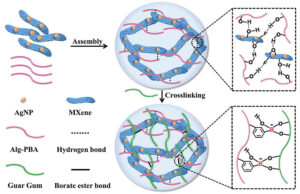
MXene hydrogelbaserade antibakteriella epidermiska sensorer
Källnod: 2661017
Tidsstämpel: Maj 18, 2023
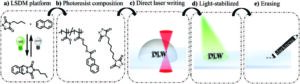
3D-utskrifter förenar den mörka sidan och försvinner
Källnod: 2903619
Tidsstämpel: September 27, 2023
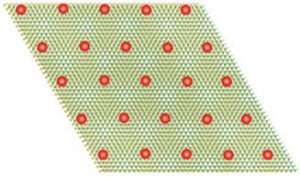
När materialet blir kvant, saktar elektronerna ner och bildar en kristall
Källnod: 1975767
Tidsstämpel: Februari 23, 2023

Ingenjörer utvecklar en effektiv process för att göra bränsle från koldioxid
Källnod: 2963812
Tidsstämpel: Oktober 30, 2023