Monitor Apache Spark applications on Amazon EMR with Amazon Cloudwatch | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2854566Time Stamp: Aug 30, 2023
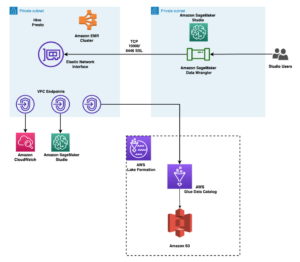
Apply fine-grained data access controls with AWS Lake Formation in Amazon SageMaker Data Wrangler | Amazon Web Services Source Cluster: AWS Machine Learning Source Node: 2839184Time Stamp: Aug 21, 2023
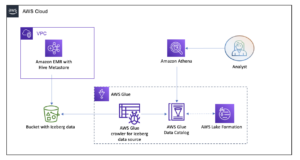
Introducing AWS Glue crawler and create table support for Apache Iceberg format | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2826837Time Stamp: Aug 16, 2023
How Ontraport reduced data processing cost by 80% with AWS Glue | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2817212Time Stamp: Aug 11, 2023
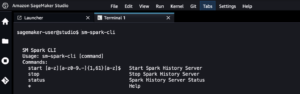
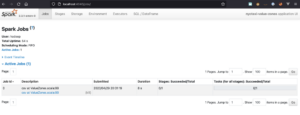
Host the Spark UI on Amazon SageMaker Studio | Amazon Web Services Source Cluster: AWS Machine Learning Source Node: 2810873Time Stamp: Aug 8, 2023
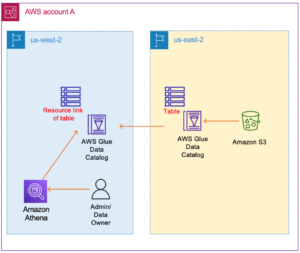
Configure cross-Region table access with the AWS Glue Catalog and AWS Lake Formation | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2801202Time Stamp: Aug 3, 2023
Extend your data mesh with Amazon Athena and federated views | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2790721Time Stamp: Jul 28, 2023
Improved scalability and resiliency for Amazon EMR on EC2 clusters | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2788875Time Stamp: Jul 27, 2023
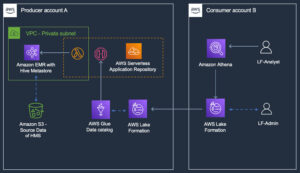
Query your Apache Hive metastore with AWS Lake Formation permissions | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2775959Time Stamp: Jul 20, 2023
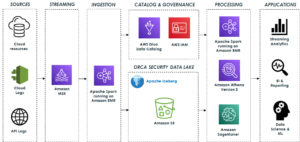
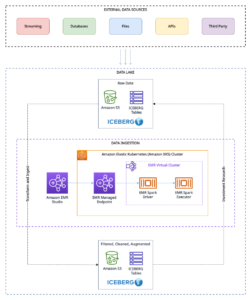
Orca Security’s journey to a petabyte-scale data lake with Apache Iceberg and AWS Analytics | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2775961Time Stamp: Jul 20, 2023
How Amazon Finance Automation built a data mesh to support distributed data ownership and centralize governance | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2763589Time Stamp: Jul 14, 2023
Backtesting index rebalancing arbitrage with Amazon EMR and Apache Iceberg | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2746965Time Stamp: Jul 3, 2023
Get started managing partitions for Amazon S3 tables backed by the AWS Glue Data Catalog | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2753148Time Stamp: Jun 22, 2023
Efficiently crawl your data lake and improve data access with an AWS Glue crawler using partition indexes | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2726353Time Stamp: Jun 15, 2023
Enable remote reads from Azure ADLS with SAS tokens using Spark in Amazon EMR | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2728461Time Stamp: Jun 15, 2023
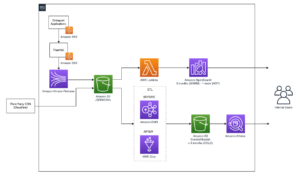
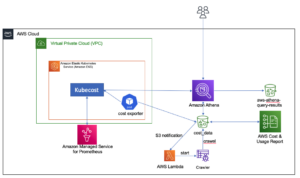
Cost monitoring for Amazon EMR on Amazon EKS | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2713245Time Stamp: Jun 9, 2023
Choosing an open table format for your transactional data lake on AWS | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2713251Time Stamp: Jun 9, 2023
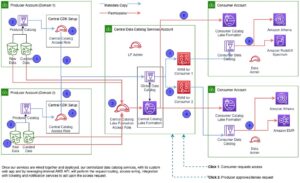
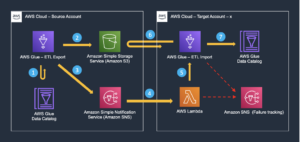
How Cargotec uses metadata replication to enable cross-account data sharing | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2707058Time Stamp: Jun 7, 2023
Introducing Amazon EMR on EKS job submission with Spark Operator and spark-submit | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2704613Time Stamp: Jun 6, 2023
Improve operational efficiencies of Apache Iceberg tables built on Amazon S3 data lakes | Amazon Web Services Source Cluster: AWS Big Data Source Node: 2675074Time Stamp: May 24, 2023