Številne organizacije, majhne in velike, si prizadevajo preseliti in posodobiti svoje analitične delovne obremenitve na spletne storitve Amazon (AWS). Obstaja veliko razlogov, zakaj stranke migrirajo na AWS, vendar je eden od glavnih razlogov možnost uporabe popolnoma upravljanih storitev, namesto da bi porabili čas za vzdrževanje infrastrukture, popravke, spremljanje, varnostne kopije in drugo. Vodstvene in razvojne ekipe lahko porabijo več časa za optimizacijo trenutnih rešitev in celo eksperimentiranje z novimi primeri uporabe, namesto da vzdržujejo trenutno infrastrukturo.
Z možnostjo hitrega premikanja na AWS morate biti odgovorni tudi do podatkov, ki jih prejemate in obdelujete, ko nadaljujete s prilagajanjem. Te odgovornosti vključujejo skladnost z zakoni in predpisi o zasebnosti podatkov ter neshranjevanje ali razkrivanje občutljivih podatkov, kot so podatki, ki omogočajo osebno identifikacijo (PII) ali zaščitene zdravstvene informacije (PHI), iz virov navzgor.
V tem prispevku se sprehodimo skozi visokonivojsko arhitekturo in poseben primer uporabe, ki prikazuje, kako lahko še naprej širite podatkovno platformo vaše organizacije, ne da bi morali porabiti veliko časa za razvoj, da bi rešili vprašanja glede zasebnosti podatkov. Uporabljamo AWS lepilo za odkrivanje, maskiranje in redigiranje podatkov PII, preden jih naložite v Storitev Amazon OpenSearch.
Pregled rešitev
Naslednji diagram ponazarja arhitekturo rešitve na visoki ravni. Vse plasti in komponente našega dizajna smo definirali v skladu z Objektiv za analizo podatkov dobro zasnovanega ogrodja AWS.
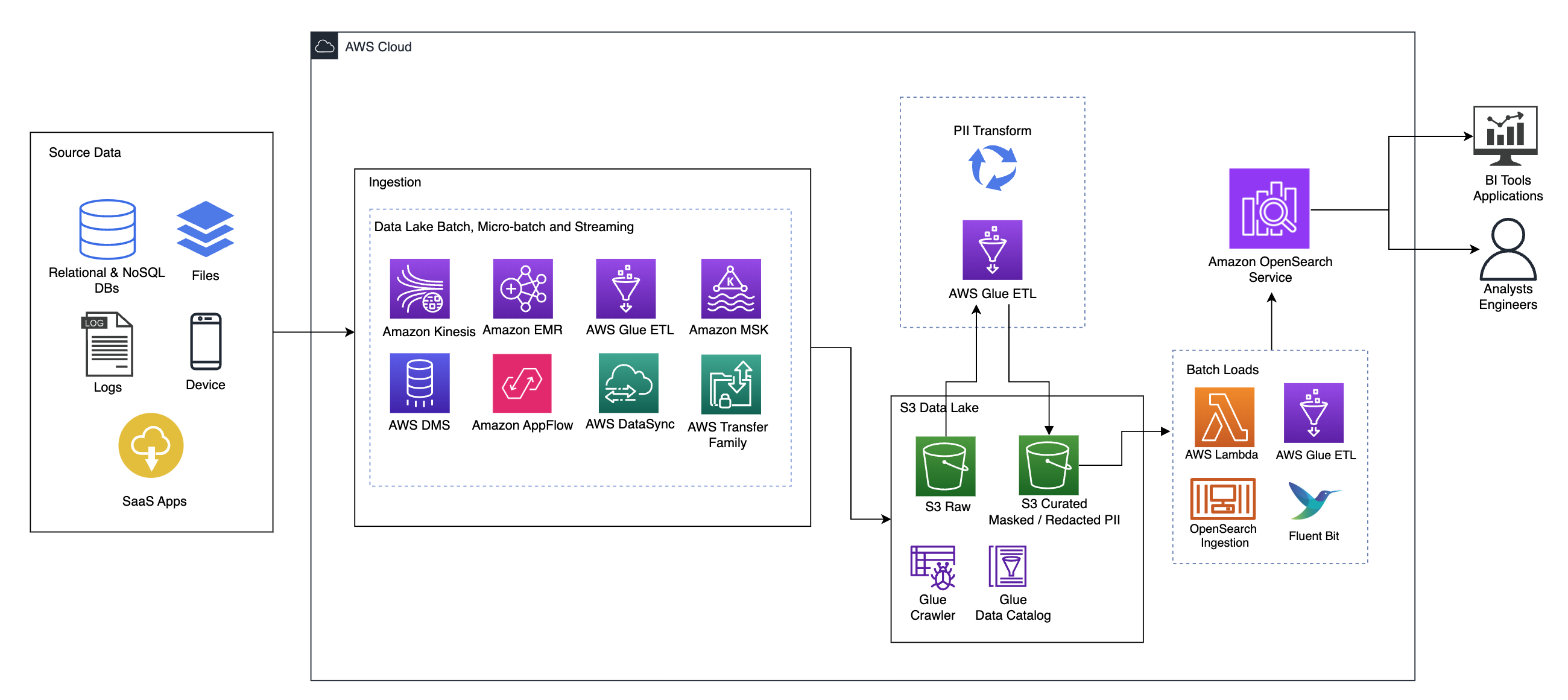
Arhitektura je sestavljena iz več komponent:
Izvorni podatki
Podatki lahko prihajajo iz več deset do stotin virov, vključno z zbirkami podatkov, prenosi datotek, dnevniki, programi kot storitev (SaaS) in drugimi. Organizacije morda nimajo vedno nadzora nad tem, kateri podatki pridejo prek teh kanalov v njihovo nadaljnjo shrambo in aplikacije.
Zaužitje: Paket podatkovnega jezera, mikropaket in pretakanje
Številne organizacije prenesejo svoje izvorne podatke v svoje podatkovno jezero na različne načine, vključno s paketnimi, mikropaketnimi in pretočnimi opravili. na primer Amazonski EMR, AWS lepiloin Storitev za selitev baze podatkov AWS (AWS DMS) je mogoče uporabiti za izvajanje paketnih in/ali pretočnih operacij, ki se prenesejo v podatkovno jezero na Preprosta storitev shranjevanja Amazon (Amazon S3). Amazon App Flow se lahko uporablja za prenos podatkov iz različnih aplikacij SaaS v podatkovno jezero. AWS DataSync in Družina za prenos AWS lahko pomaga pri premikanju datotek v podatkovno jezero in iz njega preko številnih različnih protokolov. Amazon Kinesis in Amazon MSK imata tudi zmogljivosti za pretakanje podatkov neposredno v podatkovno jezero na Amazon S3.
Podatkovno jezero S3
Uporaba Amazon S3 za vaše podatkovno jezero je v skladu s sodobno podatkovno strategijo. Zagotavlja poceni shranjevanje brez žrtvovanja zmogljivosti, zanesljivosti ali razpoložljivosti. S tem pristopom lahko po potrebi prenesete računalništvo v svoje podatke in plačate le za zmogljivost, ki jo potrebuje za delovanje.
V tej arhitekturi lahko neobdelani podatki prihajajo iz različnih virov (notranjih in zunanjih), ki lahko vsebujejo občutljive podatke.
Z uporabo pajkov AWS Glue lahko odkrijemo in katalogiziramo podatke, ki nam bodo zgradili sheme tabel, in na koncu poenostavimo uporabo AWS Glue ETL s transformacijo PII za odkrivanje in maskiranje ali redigiranje občutljivih podatkov, ki so morda pristali. v podatkovnem jezeru.
Poslovni kontekst in nabori podatkov
Da pokažemo vrednost našega pristopa, si predstavljajmo, da ste del skupine za podatkovno inženirstvo za organizacijo za finančne storitve. Vaše zahteve so, da zaznate in prikrijete občutljive podatke, ko so zaužiti v oblaku vaše organizacije. Podatke bodo porabili nadaljnji analitični procesi. V prihodnosti bodo vaši uporabniki lahko varno iskali zgodovinske plačilne transakcije na podlagi podatkovnih tokov, zbranih iz notranjih bančnih sistemov. Rezultati iskanja operativnih skupin, strank in vmesniških aplikacij morajo biti prikriti v občutljivih poljih.
Naslednja tabela prikazuje podatkovno strukturo, uporabljeno za rešitev. Zaradi jasnosti smo surovo preslikali v kurirana imena stolpcev. Opazili boste, da več polj znotraj te sheme velja za občutljive podatke, kot so ime, priimek, številka socialnega zavarovanja (SSN), naslov, številka kreditne kartice, telefonska številka, e-pošta in naslov IPv4.
| Neobdelano ime stolpca | Izbrano ime stolpca | tip |
| c0 | ime | niz |
| c1 | priimek | niz |
| c2 | ssn | niz |
| c3 | Naslov | niz |
| c4 | poštno številko | niz |
| c5 | država | niz |
| c6 | buy_site | niz |
| c7 | Številka kreditne kartice | niz |
| c8 | ponudnik_kreditne_kartice | niz |
| c9 | valuta | niz |
| c10 | nabavna_vrednost | celo |
| c11 | datum_transakcije | Datum |
| c12 | telefonska številka | niz |
| c13 | E-naslov | niz |
| c14 | ipv4 | niz |
Primer uporabe: Paketno zaznavanje PII pred nalaganjem v storitev OpenSearch
Stranke, ki izvajajo naslednjo arhitekturo, so zgradile svoje podatkovno jezero na Amazon S3 za izvajanje različnih vrst analitike v velikem obsegu. Ta rešitev je primerna za stranke, ki ne potrebujejo vnosa v storitev OpenSearch v realnem času in nameravajo uporabljati orodja za integracijo podatkov, ki se izvajajo po urniku ali se sprožijo prek dogodkov.
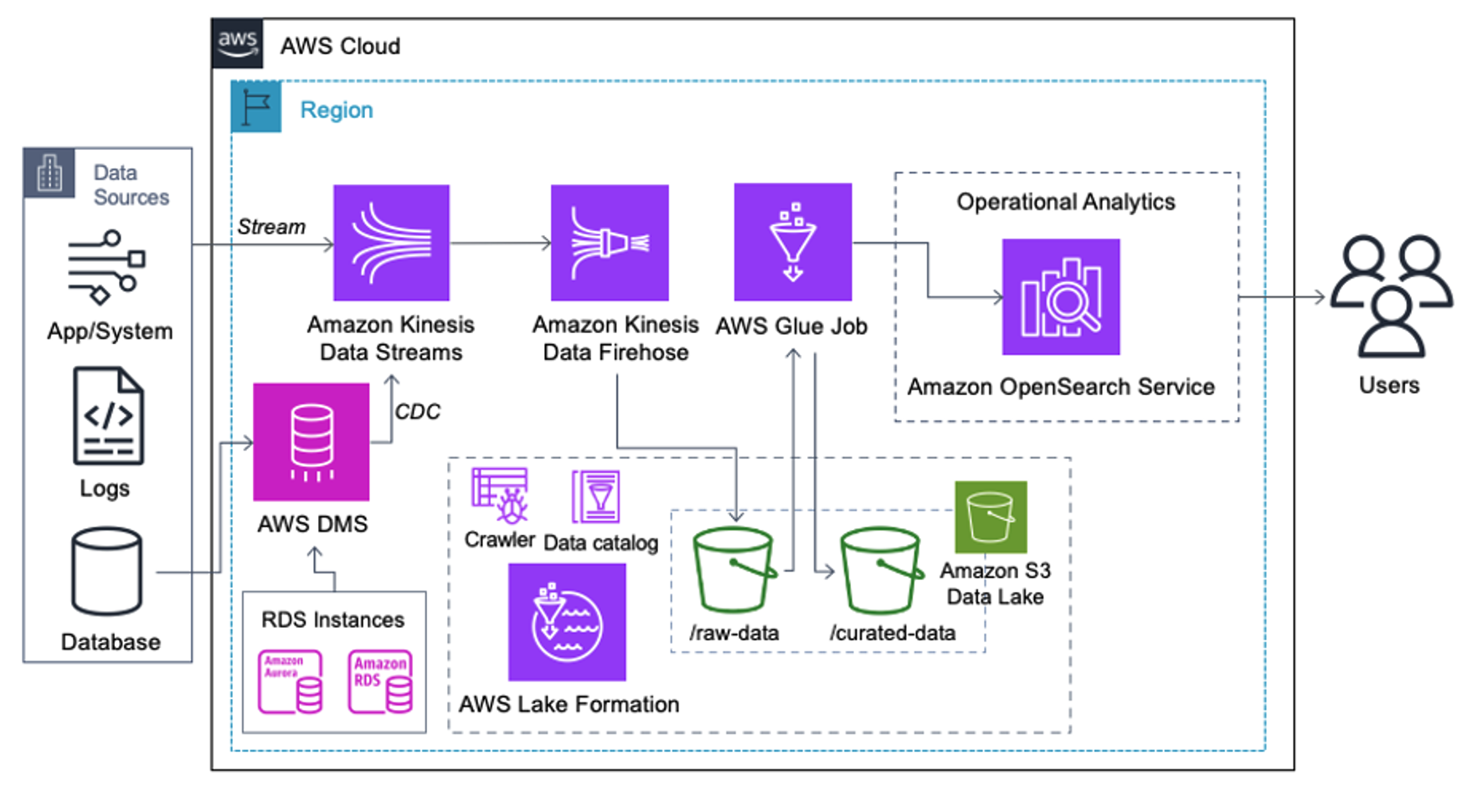
Preden podatkovni zapisi pristanejo na Amazon S3, implementiramo plast za sprejem, da vse tokove podatkov zanesljivo in varno prenesemo v podatkovno jezero. Podatkovni tokovi Kinesis so razporejeni kot vnosni sloj za pospešen vnos strukturiranih in polstrukturiranih podatkovnih tokov. Primeri tega so spremembe relacijske baze podatkov, aplikacije, sistemski dnevniki ali tokovi klikov. Za primere uporabe spreminjanja zajemanja podatkov (CDC) lahko uporabite Kinesis Data Streams kot cilj za AWS DMS. Aplikacije ali sistemi, ki generirajo tokove, ki vsebujejo občutljive podatke, se pošljejo v podatkovni tok Kinesis prek ene od treh podprtih metod: Amazon Kinesis Agent, AWS SDK za Javo ali Kinesis Producer Library. Kot zadnji korak, Amazon Kinesis Data Firehose nam pomaga zanesljivo naložiti pakete podatkov v skoraj realnem času v naš cilj podatkovnega jezera S3.
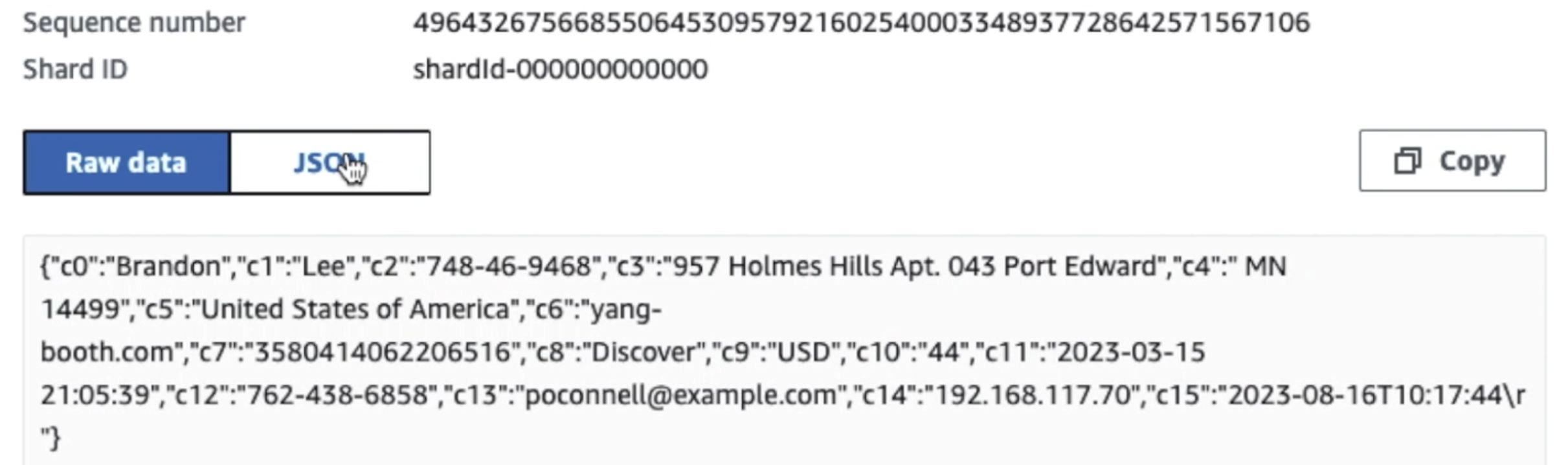
Naslednji posnetek zaslona prikazuje, kako podatki tečejo prek Kinesis Data Streams prek Pregledovalnik podatkov in pridobi vzorčne podatke, ki pristanejo na neobdelani predponi S3. Za to arhitekturo smo sledili življenjskemu ciklu podatkov za predpone S3, kot je priporočeno v Temelj podatkovnega jezera.
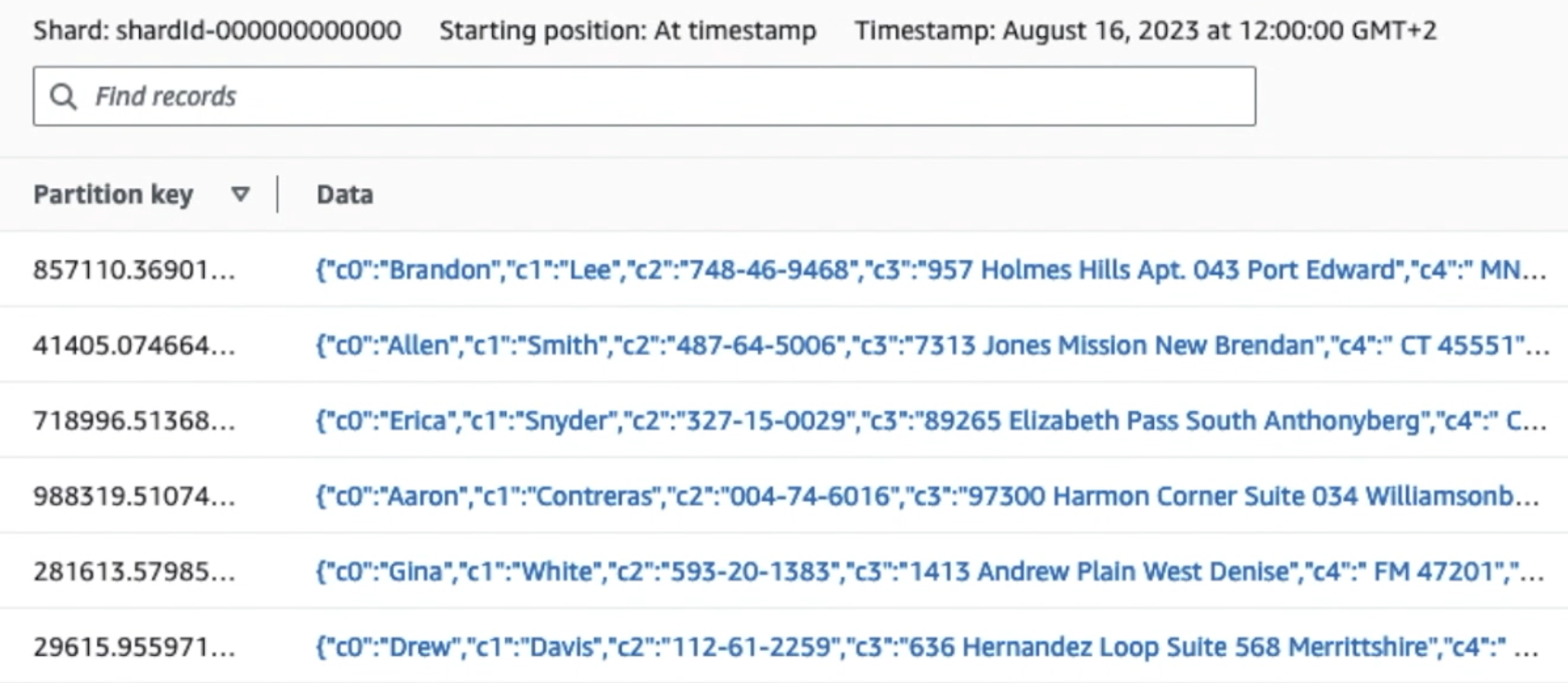
Kot lahko vidite iz podrobnosti prvega zapisa na naslednjem posnetku zaslona, koristni tovor JSON sledi isti shemi kot v prejšnjem razdelku. Vidite lahko neredigirane podatke, ki tečejo v podatkovni tok Kinesis, ki bodo pozneje v naslednjih fazah zakriti.
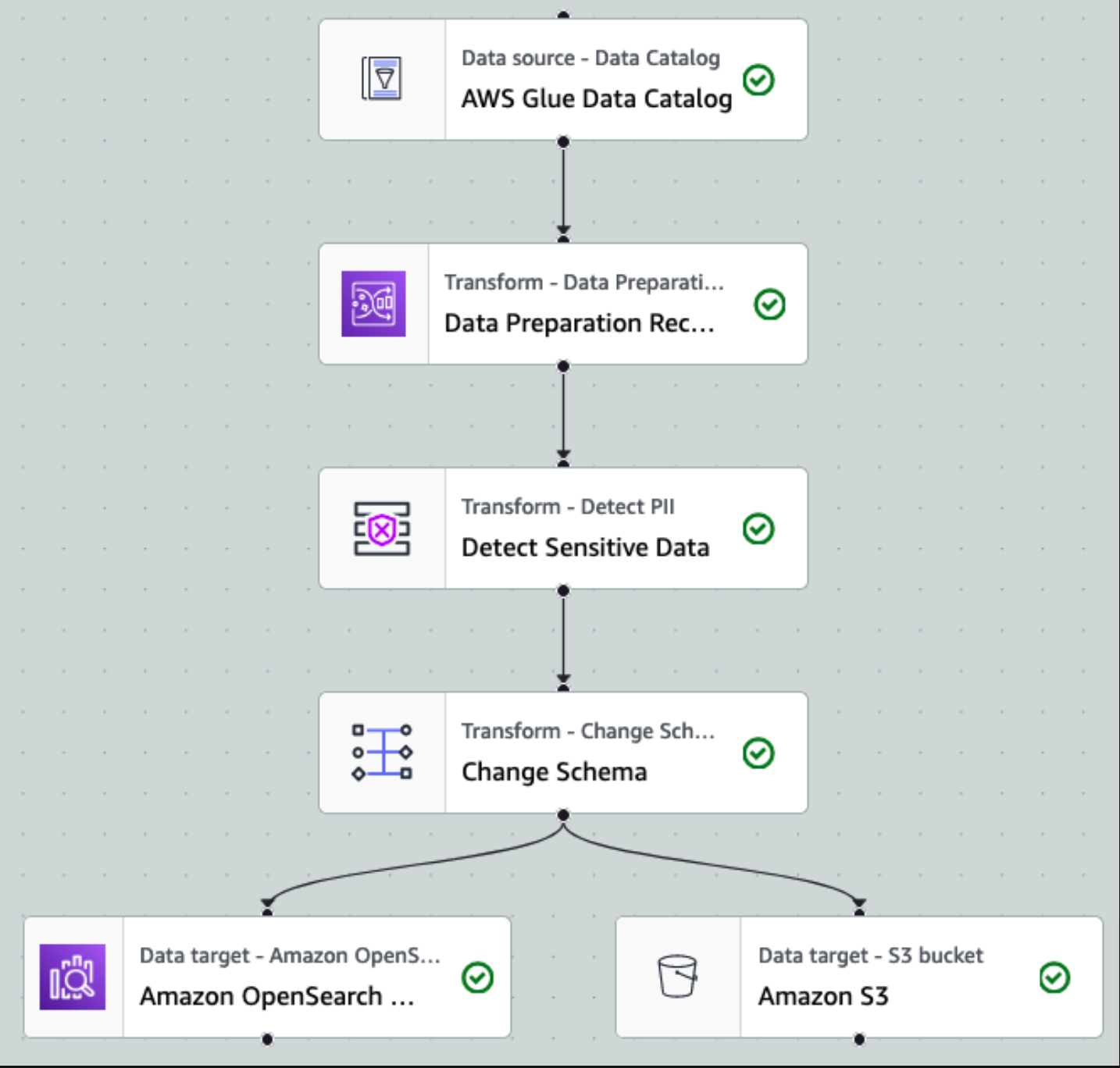
Ko so podatki zbrani in vnešeni v Kinesis Data Streams ter dostavljeni v vedro S3 z uporabo Kinesis Data Firehose, prevzame procesno plast arhitekture. Pretvorbo AWS Glue PII uporabljamo za avtomatsko odkrivanje in maskiranje občutljivih podatkov v našem cevovodu. Kot je prikazano v naslednjem diagramu delovnega toka, smo uporabili pristop brez kode, vizualni ETL za izvedbo našega transformacijskega opravila v AWS Glue Studio.
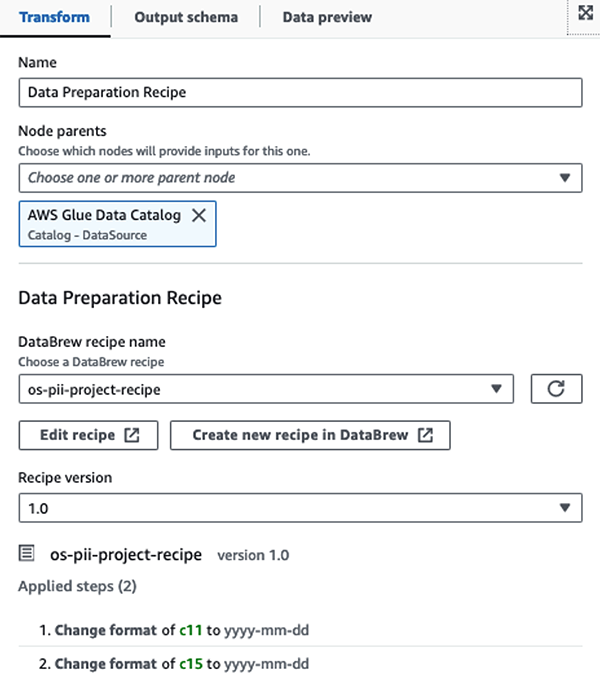
Najprej dostopamo do neobdelane tabele izvornega podatkovnega kataloga iz pii_data_db zbirka podatkov. Tabela ima strukturo sheme, predstavljeno v prejšnjem razdelku. Za spremljanje neobdelanih obdelanih podatkov smo uporabili delovni zaznamki.

Mi uporabljamo Recepti AWS Glue DataBrew v opravilu vizualnega ETL AWS Glue Studio za pretvorbo dveh atributov datuma, da bosta združljiva s pričakovanim OpenSearch Oblike. To nam omogoča popolno izkušnjo brez kodiranja.
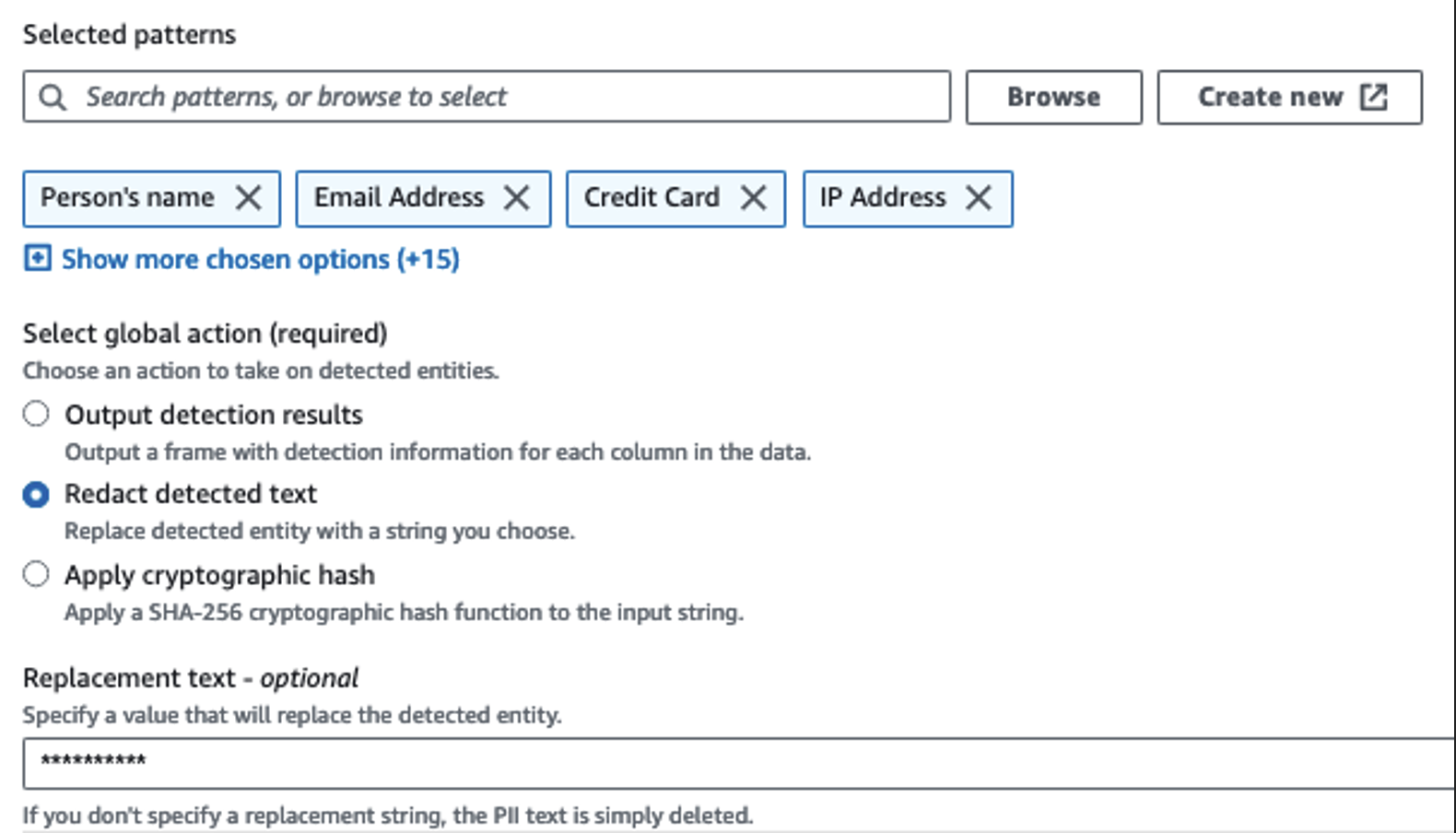
Za prepoznavanje občutljivih stolpcev uporabljamo dejanje Zaznaj osebno prepoznavne podatke. AWS Glue pustimo, da to določi na podlagi izbranih vzorcev, praga zaznavanja in vzorčnega dela vrstic iz nabora podatkov. V našem primeru smo uporabili vzorce, ki veljajo posebej za Združene države (kot so SSN) in morda ne bodo zaznali občutljivih podatkov iz drugih držav. Lahko poiščete razpoložljive kategorije in lokacije, ki veljajo za vaš primer uporabe, ali uporabite regularne izraze (regex) v AWS Glue, da ustvarite entitete zaznavanja za občutljive podatke iz drugih držav.
Pomembno je izbrati pravilno metodo vzorčenja, ki jo ponuja AWS Glue. V tem primeru je znano, da imajo podatki, ki prihajajo iz toka, občutljive podatke v vsaki vrstici, zato ni treba vzorčiti 100 % vrstic v naboru podatkov. Če imate zahtevo, po kateri nobeni občutljivi podatki niso dovoljeni za nadaljnje vire, razmislite o vzorčenju 100 % podatkov za vzorce, ki ste jih izbrali, ali skenirajte celoten nabor podatkov in ukrepajte na vsaki posamezni celici, da zagotovite, da so zaznani vsi občutljivi podatki. Prednost vzorčenja so nižji stroški, ker vam ni treba skenirati toliko podatkov.

Dejanje Zaznaj PII vam omogoča, da izberete privzeti niz pri maskiranju občutljivih podatkov. V našem primeru uporabljamo niz **********.
Uporabljamo operacijo uveljavitve preslikave za preimenovanje in odstranjevanje nepotrebnih stolpcev, kot je npr ingestion_year, ingestion_monthin ingestion_day. Ta korak nam omogoča tudi, da spremenimo vrsto podatkov enega od stolpcev (purchase_value) iz niza v celo število.

Od te točke naprej se opravilo razdeli na dva izhodna cilja: OpenSearch Service in Amazon S3.
Naša predvidena gruča OpenSearch Service je povezana prek Vgrajen konektor OpenSearch za Glue. Določimo indeks OpenSearch, v katerega želimo pisati, in konektor obravnava poverilnice, domeno in vrata. Na spodnjem posnetku zaslona pišemo v navedeni indeks index_os_pii.
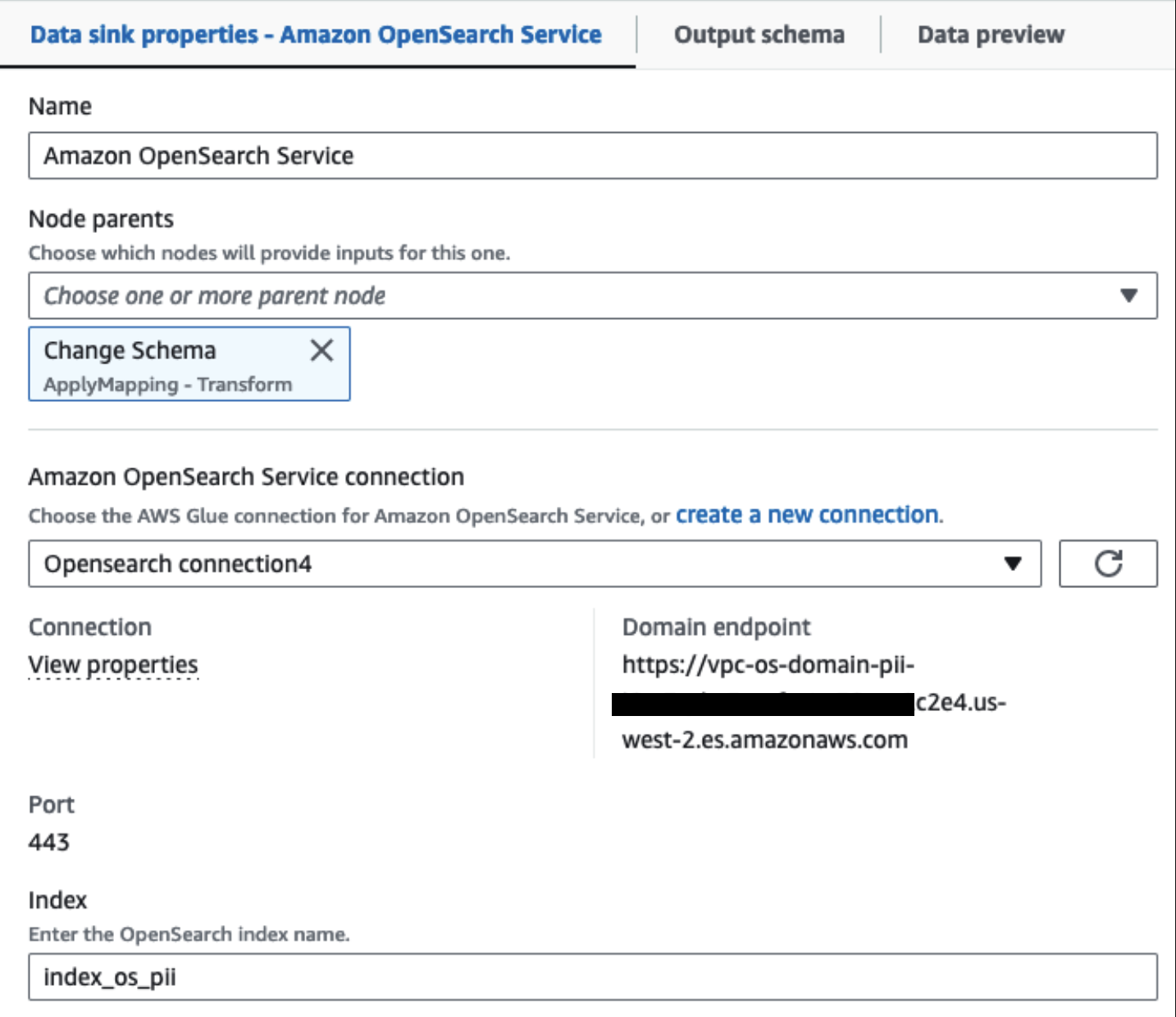
Maskiran nabor podatkov shranimo v kurirano predpono S3. Tam imamo podatke, normalizirane za določen primer uporabe in varno uporabo podatkovnih znanstvenikov ali za ad hoc potrebe poročanja.
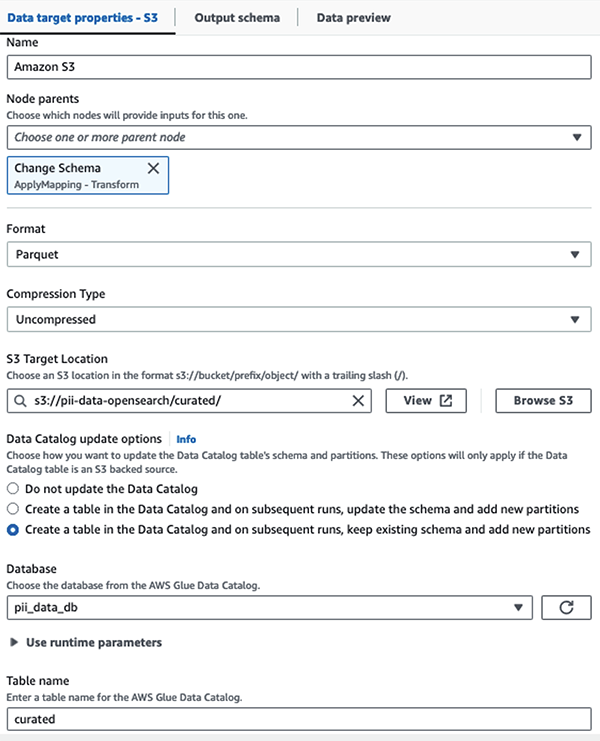
Za poenoteno upravljanje, nadzor dostopa in revizijske sledi vseh naborov podatkov in tabel kataloga podatkov lahko uporabite Oblikovanje jezera AWS. To vam pomaga omejiti dostop do tabel AWS Glue Data Catalog in osnovnih podatkov samo na tiste uporabnike in vloge, ki so jim za to bila podeljena potrebna dovoljenja.
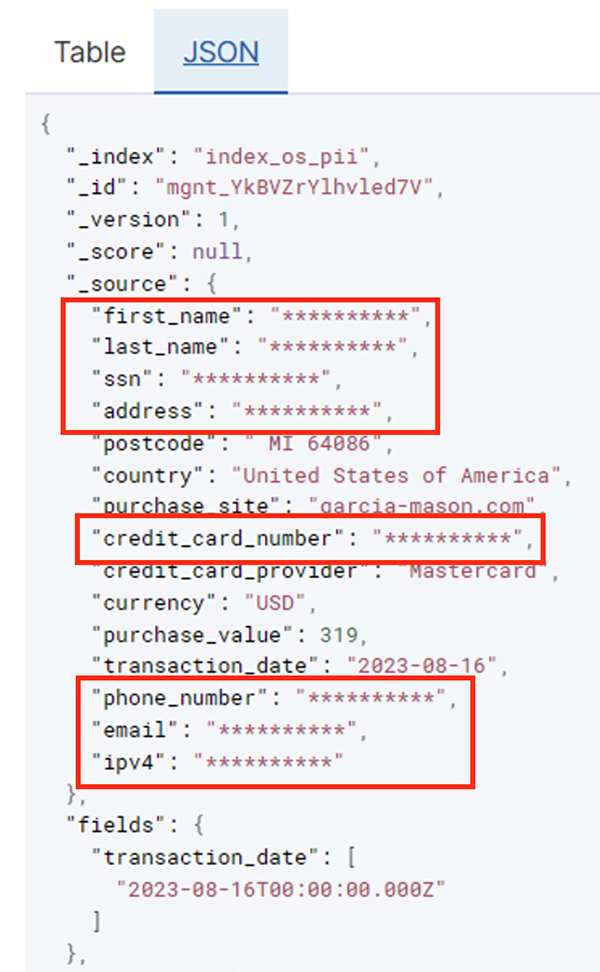
Ko se paketno opravilo uspešno izvede, lahko uporabite storitev OpenSearch za izvajanje iskalnih poizvedb ali poročil. Kot je prikazano na naslednjem posnetku zaslona, je cevovod samodejno prikril občutljiva polja brez truda pri razvoju kode.

Trende lahko prepoznate iz operativnih podatkov, kot je količina transakcij na dan, ki jih filtrira ponudnik kreditne kartice, kot je prikazano na prejšnjem posnetku zaslona. Določite lahko tudi lokacije in domene, kjer uporabniki kupujejo. The transaction_date nam pomaga videti te trende skozi čas. Naslednji posnetek zaslona prikazuje zapis z vsemi podatki o transakciji, ki so ustrezno redigirani.
Za alternativne metode nalaganja podatkov v Amazon OpenSearch glejte Nalaganje pretočnih podatkov v Amazon OpenSearch Service.
Poleg tega je občutljive podatke mogoče odkriti in prikriti tudi z drugimi rešitvami AWS. Na primer, lahko uporabite Amazon Macie za odkrivanje občutljivih podatkov v vedru S3 in nato uporabite Amazonsko razumevanje da popravi občutljive podatke, ki so bili zaznani. Za več informacij glejte Pogoste tehnike za odkrivanje podatkov PHI in PII z uporabo storitev AWS.
zaključek
Ta objava je razpravljala o pomembnosti ravnanja z občutljivimi podatki v vašem okolju ter o različnih metodah in arhitekturah, da ostanete skladni, hkrati pa vaši organizaciji omogočite hitro širitev. Zdaj bi morali dobro razumeti, kako zaznati, maskirati ali redigirati in naložiti svoje podatke v Amazon OpenSearch Service.
O avtorjih
 Michael Hamilton je Sr Analytics Solutions Architect, ki se osredotoča na pomoč poslovnim strankam pri posodobitvi in poenostavitvi njihovih analitičnih delovnih obremenitev na AWS. Uživa v gorskem kolesarjenju in preživlja čas z ženo in tremi otroki, ko ni v službi.
Michael Hamilton je Sr Analytics Solutions Architect, ki se osredotoča na pomoč poslovnim strankam pri posodobitvi in poenostavitvi njihovih analitičnih delovnih obremenitev na AWS. Uživa v gorskem kolesarjenju in preživlja čas z ženo in tremi otroki, ko ni v službi.
 Daniel Rozo je višji arhitekt rešitev pri AWS, ki podpira stranke na Nizozemskem. Njegova strast je inženiring preprostih podatkovnih in analitičnih rešitev ter pomoč strankam pri prehodu na sodobne podatkovne arhitekture. Izven službe rad igra tenis in kolesari.
Daniel Rozo je višji arhitekt rešitev pri AWS, ki podpira stranke na Nizozemskem. Njegova strast je inženiring preprostih podatkovnih in analitičnih rešitev ter pomoč strankam pri prehodu na sodobne podatkovne arhitekture. Izven službe rad igra tenis in kolesari.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/detect-mask-and-redact-pii-data-using-aws-glue-before-loading-into-amazon-opensearch-service/
- :ima
- : je
- :ne
- :kje
- 07
- 100
- 28
- 300
- 31
- 32
- 39
- 40
- 46
- 50
- 51
- 600
- 90
- 970
- a
- sposobnost
- Sposobna
- pospešeno
- dostop
- Zakon
- Ukrep
- Ad
- Naslov
- Agent
- vsi
- dovoljene
- Dovoli
- omogoča
- Prav tako
- vedno
- Amazon
- Amazon Kinesis
- Amazon Web Services
- Amazonske spletne storitve (AWS)
- znesek
- zneski
- an
- Analitično
- analitika
- in
- kaj
- primerno
- aplikacije
- Uporabi
- pristop
- ustrezno
- Arhitektura
- SE
- AS
- At
- lastnosti
- Revizija
- avtomatizirati
- samodejno
- razpoložljivost
- Na voljo
- AWS
- AWS lepilo
- varnostne kopije
- Bančništvo
- Bančni sistemi
- temeljijo
- BE
- ker
- bilo
- pred
- počutje
- spodaj
- koristi
- prinašajo
- izgradnjo
- zgrajena
- vgrajeno
- vendar
- by
- CAN
- Zmogljivosti
- kapaciteta
- zajemanje
- kartice
- primeru
- primeri
- Katalog
- kategorije
- CDC
- celica
- spremenite
- Spremembe
- kanali
- Otroci
- izbral
- jasnost
- Cloud
- Grozd
- Koda
- Stolpec
- Stolpci
- kako
- prihaja
- prihajajo
- združljiv
- skladno
- deli
- Sestavljeno
- Izračunajte
- Skrbi
- povezane
- Razmislite
- šteje
- porabi
- poraba
- vsebujejo
- ozadje
- naprej
- nadzor
- popravi
- stroški
- bi
- države
- ustvarjajo
- Mandatno
- kredit
- kreditne kartice
- kurirano
- Trenutna
- Stranke, ki so
- datum
- Podatkovna analiza
- integracija podatkov
- Data jezero
- Podatkovna platforma
- zasebnost podatkov
- podatkovna strategija
- Baze podatkov
- baze podatkov
- nabor podatkov
- Datum
- dan
- privzeto
- opredeljen
- dostavi
- izkazati
- dokazuje,
- razporejeni
- Oblikovanje
- destinacija
- destinacije
- Podrobnosti
- odkrivanje
- Zaznali
- Odkrivanje
- Ugotovite,
- Razvoj
- razvojne ekipe
- drugačen
- neposredno
- odkriti
- odkril
- razpravljali
- do
- domena
- domen
- dont
- vsak
- prizadevanja
- E-naslov
- Inženiring
- zagotovitev
- Podjetje
- podjetniške stranke
- Celotna
- subjekti
- okolje
- Eter (ETH)
- Tudi
- dogodki
- Tudi vsak
- Primer
- Primeri
- Pričakuje
- izkušnje
- izrazi
- zunanja
- FAST
- Področja
- file
- datoteke
- finančna
- finančne storitve
- prva
- Teče
- Tokovi
- osredotoča
- sledili
- po
- sledi
- za
- Okvirni
- iz
- polno
- v celoti
- Prihodnost
- ustvarjajo
- dobili
- dobro
- upravljanje
- odobreno
- Ročaji
- Ravnanje
- Imajo
- he
- Zdravje
- zdravstvene informacije
- pomoč
- pomoč
- Pomaga
- na visoki ravni
- njegov
- zgodovinski
- Kako
- Kako
- HTML
- http
- HTTPS
- Stotine
- identificirati
- if
- ponazarja
- slika
- izvajati
- Pomembnost
- Pomembno
- in
- vključujejo
- Vključno
- Indeks
- individualna
- Podatki
- Infrastruktura
- v notranjosti
- integracija
- notranji
- v
- IT
- Java
- Job
- Delovna mesta
- jpg
- json
- Imejte
- Kinesis Data FireHose
- Podatkovni tokovi Kinesis
- znano
- Jezero
- Država
- Zemljišč
- velika
- Zadnja
- pozneje
- Zakoni
- Zakoni in predpisi
- plast
- plasti
- Vodstvo
- Naj
- Knjižnica
- življenski krog
- kot
- vrstica
- obremenitev
- nalaganje
- Lokacije
- Poglej
- nizkimi stroški
- Glavne
- vzdrževanje
- Znamka
- upravlja
- več
- kartiranje
- Maska
- Maj ..
- Metoda
- Metode
- selitev
- migracije
- sodobna
- posodobiti
- spremljanje
- več
- Mountain
- premikanje
- premikanje
- veliko
- več
- morajo
- Ime
- Imena
- potrebno
- Nimate
- potrebna
- potrebujejo
- potrebe
- Nizozemska
- Novo
- št
- vozlišča
- Opaziti..
- zdaj
- Številka
- of
- Ponudbe
- on
- ONE
- samo
- Delovanje
- operativno
- operacije
- optimizacijo
- možnosti
- or
- Organizacija
- organizacije
- Ostalo
- naši
- izhod
- zunaj
- več
- del
- strast
- Zaplata
- vzorci
- Plačajte
- Plačilo
- za
- opravlja
- performance
- Dovoljenja
- Osebno
- telefon
- pii
- plinovod
- Načrt
- platforma
- platon
- Platonova podatkovna inteligenca
- PlatoData
- igranje
- Točka
- del
- Prispevek
- pred
- predstavljeni
- prejšnja
- zasebnost
- zakoni o zasebnosti
- obdelani
- Procesi
- obravnavati
- Proizvajalec
- zaščiteni
- protokoli
- Ponudnik
- zagotavlja
- nakupi
- poizvedbe
- hitro
- precej
- Surovi
- surovi podatki
- v realnem času
- Razlogi
- prejema
- Recepti
- priporočeno
- zapis
- evidence
- Zmanjšana
- glejte
- redni
- predpisi
- zanesljivost
- ostajajo
- odstrani
- Poročanje
- Poročila
- zahteva
- zahteva
- Zahteve
- odgovornosti
- odgovorna
- omejiti
- Rezultati
- vloge
- ROW
- Run
- deluje
- SaaS
- žrtvovanje
- varna
- varno
- Enako
- Lestvica
- skeniranje
- urnik
- Znanstveniki
- Zaslon
- SDK
- Iskalnik
- Oddelek
- Varno
- varnost
- glej
- izberite
- izbran
- višji
- občutljiva
- poslan
- Storitev
- Storitve
- shot
- shouldnt
- pokazale
- Razstave
- Enostavno
- poenostavitev
- majhna
- So
- socialna
- Software
- programske opreme kot storitve
- Rešitev
- rešitve
- vir
- Viri
- specifična
- posebej
- določeno
- preživeti
- Poraba
- Razcepi
- postopka
- Države
- Korak
- shranjevanje
- trgovina
- naravnost
- Strategija
- tok
- pretakanje
- tokovi
- String
- Struktura
- strukturirano
- studio
- kasneje
- Uspešno
- taka
- primerna
- Podprti
- Podpora
- sistem
- sistemi
- miza
- meni
- ciljna
- skupina
- Skupine
- tehnike
- tenis
- deset
- kot
- da
- O
- Prihodnost
- Nizozemska
- Vir
- njihove
- POTEM
- Tukaj.
- te
- ta
- tisti,
- 3
- Prag
- skozi
- čas
- do
- vzel
- orodja
- sledenje
- Transakcije
- prenos
- transferji
- Transform
- Preoblikovanje
- Trends
- sprožilo
- dva
- tip
- Vrste
- Konec koncev
- osnovni
- razumevanje
- poenoteno
- Velika
- Združene države Amerike
- us
- uporaba
- primeru uporabe
- Rabljeni
- Uporabniki
- uporabo
- vrednost
- raznolikost
- različnih
- preko
- vizualna
- sprehod
- je
- načini
- we
- web
- spletne storitve
- Kaj
- kdaj
- ki
- medtem
- WHO
- žena
- bo
- z
- v
- brez
- delo
- potek dela
- deluje
- pisati
- jo
- Vaša rutina za
- zefirnet