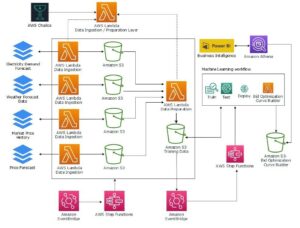
Vdelave igrajo ključno vlogo pri obdelavi naravnega jezika (NLP) in strojnem učenju (ML). Vdelava besedila se nanaša na proces preoblikovanja besedila v numerične predstavitve, ki se nahajajo v visokodimenzionalnem vektorskem prostoru. Ta tehnika je dosežena z uporabo algoritmov ML, ki omogočajo razumevanje pomena in konteksta podatkov (semantični odnosi) ter učenje kompleksnih odnosov in vzorcev znotraj podatkov (sintaktični odnosi). Dobljene vektorske predstavitve lahko uporabite za široko paleto aplikacij, kot je iskanje informacij, klasifikacija besedil, obdelava naravnega jezika in številne druge.
Besedilne vdelave Amazon Titan je model vdelave besedila, ki pretvori besedilo v naravnem jeziku – sestavljeno iz posameznih besed, besednih zvez ali celo velikih dokumentov – v numerične predstavitve, ki jih je mogoče uporabiti za primere uporabe, kot so iskanje, personalizacija in združevanje v gruče na podlagi semantične podobnosti.
V tej objavi razpravljamo o modelu Amazon Titan Text Embeddings, njegovih funkcijah in primerih uporabe.
Nekateri ključni koncepti vključujejo:
- Numerična predstavitev besedila (vektorji) zajame semantiko in razmerja med besedami
- Za primerjavo podobnosti besedila je mogoče uporabiti bogate vdelave
- Večjezične vdelave besedila lahko prepoznajo pomen v različnih jezikih
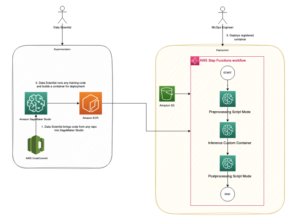
Kako se del besedila pretvori v vektor?
Obstaja več tehnik za pretvorbo stavka v vektor. Ena priljubljena metoda je uporaba algoritmov za vdelavo besed, kot je Word2Vec, GloVe ali FastText, in nato združevanje vdelav besed v vektorsko predstavitev na ravni stavka.
Drug pogost pristop je uporaba velikih jezikovnih modelov (LLM), kot sta BERT ali GPT, ki lahko zagotovijo kontekstualizirane vdelave za celotne stavke. Ti modeli temeljijo na arhitekturah globokega učenja, kot je Transformers, ki lahko učinkoviteje zajamejo kontekstualne informacije in razmerja med besedami v stavku.
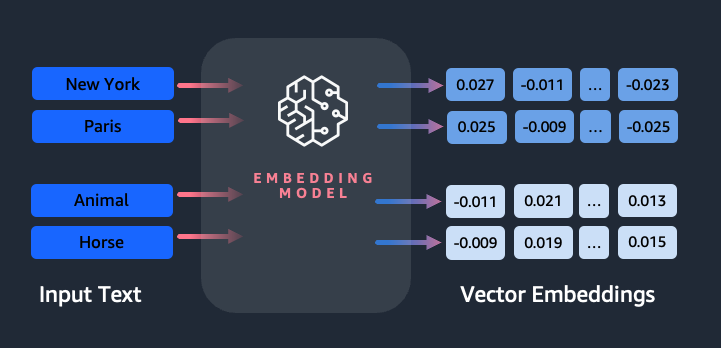
Zakaj potrebujemo model vdelave?
Vektorske vdelave so bistvenega pomena za LLM-je pri razumevanju semantičnih stopenj jezika, prav tako pa LLM-jem omogočajo, da dobro opravljajo naloge NLP-ja na nižji stopnji, kot so analiza čustev, prepoznavanje imenovanih entitet in klasifikacija besedila.
Poleg semantičnega iskanja lahko uporabite vdelave, da povečate svoje pozive za natančnejše rezultate prek Retrieval Augmented Generation (RAG) – toda če jih želite uporabiti, jih boste morali shraniti v bazo podatkov z vektorskimi zmogljivostmi.
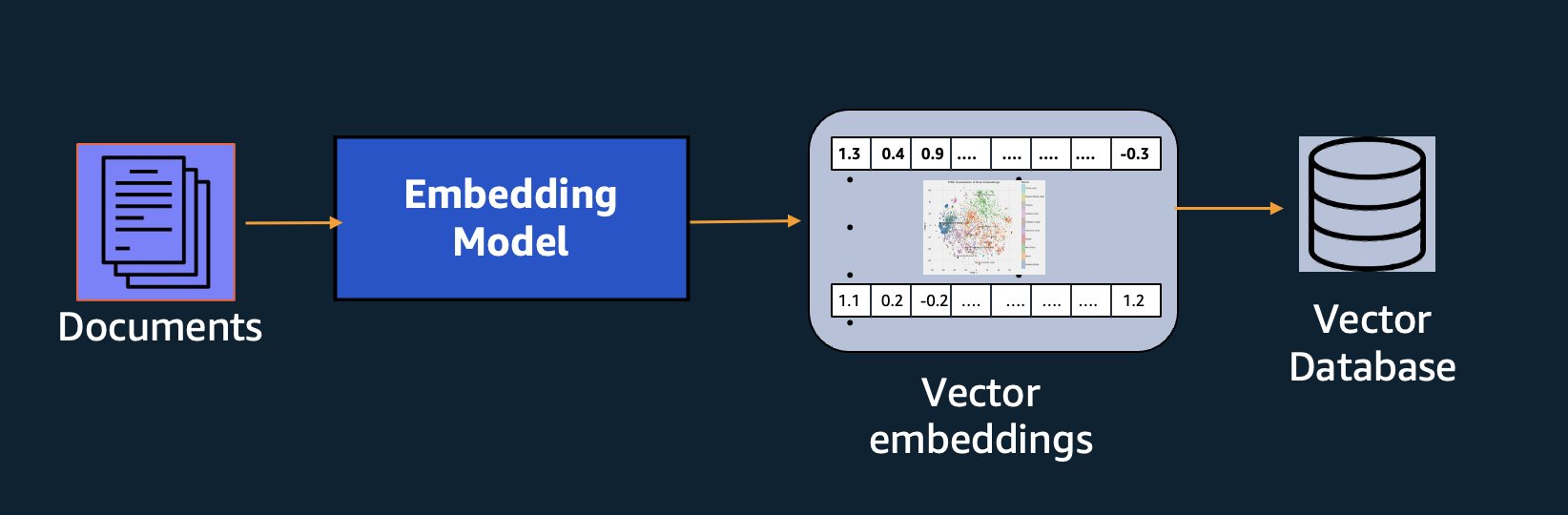
Model Amazon Titan Text Embeddings je optimiziran za iskanje besedila, da omogoči primere uporabe RAG. Omogoča vam, da svoje besedilne podatke najprej pretvorite v numerične predstavitve ali vektorje, nato pa te vektorje uporabite za natančno iskanje ustreznih odlomkov iz vektorske baze podatkov, kar vam omogoča, da kar najbolje izkoristite svoje lastniške podatke v kombinaciji z drugimi modeli temeljev.
Ker je Amazon Titan Text Embeddings upravljani model Amazon Bedrock, je na voljo kot popolnoma brezstrežniška izkušnja. Uporabljate ga lahko prek storitve Amazon Bedrock REST API ali AWS SDK. Zahtevani parametri so besedilo, katerega vdelave želite ustvariti, in modelID parameter, ki predstavlja ime modela Amazon Titan Text Embeddings. Naslednja koda je primer uporabe AWS SDK za Python (Boto3):
Izhod bo videti nekako takole:
Nanašati se na Nastavitev Amazon Bedrock boto3 za več podrobnosti o tem, kako namestiti zahtevane pakete, se povežite z Amazon Bedrock in prikličite modele.
Funkcije Amazon Titan Text Embeddings
Z Amazon Titan Text Embeddings lahko vnesete do 8,000 žetonov, zaradi česar je zelo primeren za delo s posameznimi besedami, frazami ali celotnimi dokumenti glede na vaš primer uporabe. Amazon Titan vrne izhodne vektorje dimenzije 1536, kar mu daje visoko stopnjo natančnosti, hkrati pa optimizira za nizke zakasnitve in stroškovno učinkovite rezultate.
Amazon Titan Text Embeddings podpira ustvarjanje in poizvedovanje po vdelavah za besedilo v več kot 25 različnih jezikih. To pomeni, da lahko uporabite model za svoje primere uporabe, ne da bi morali ustvariti in vzdrževati ločene modele za vsak jezik, ki ga želite podpirati.
Imeti en sam model vdelav, usposobljen za številne jezike, zagotavlja naslednje ključne prednosti:
- Širši doseg – S podporo za več kot 25 jezikov takoj po namestitvi lahko razširite doseg svojih aplikacij na uporabnike in vsebino na številnih mednarodnih trgih.
- Dosledno delovanje – Z enotnim modelom, ki pokriva več jezikov, dobite dosledne rezultate v različnih jezikih, namesto da optimizirate ločeno za vsak jezik. Model je celostno usposobljen, tako da imate prednost v različnih jezikih.
- Podpora za večjezične poizvedbe – Amazon Titan Text Embeddings omogoča poizvedovanje po vdelavah besedila v katerem koli od podprtih jezikov. To zagotavlja prilagodljivost za pridobivanje pomensko podobne vsebine v različnih jezikih, ne da bi bili omejeni na en sam jezik. Izdelate lahko aplikacije, ki poizvedujejo in analizirajo večjezične podatke z uporabo istega poenotenega prostora za vdelave.
Od tega pisanja so podprti naslednji jeziki:
- arabsko
- Chinese (Simplified)
- Kitajščina (tradicionalna)
- Češki
- Nizozemski
- Angleščina
- francosko
- nemški
- hebrejščina
- hindi
- Italijanski
- Japonski
- kannada
- Korejski
- malajalamščina
- maratščina
- poljski
- portugalski
- Ruski
- španski
- Švedski
- filipinsko tagaloščino
- tamil
- telugu
- turški
Uporaba Amazon Titan Text Embeddings z LangChain
LangChain je priljubljeno odprtokodno ogrodje za delo z generativnimi modeli AI in podpornimi tehnologijami. Vključuje a Odjemalec BedrockEmbeddings ki priročno ovije Boto3 SDK s plastjo abstrakcije. The BedrockEmbeddings odjemalec vam omogoča neposredno delo z besedilom in vdelavami, ne da bi poznali podrobnosti strukture zahtev ali odgovorov JSON. Sledi preprost primer:
Uporabite lahko tudi LangChain BedrockEmbeddings odjemalec skupaj z odjemalcem Amazon Bedrock LLM za poenostavitev izvajanja RAG, semantičnega iskanja in drugih vzorcev, povezanih z vdelavami.
Primeri uporabe za vdelave
Čeprav je RAG trenutno najbolj priljubljen primer uporabe za delo z vdelavami, obstaja veliko drugih primerov uporabe, kjer je mogoče uporabiti vdelave. Sledi nekaj dodatnih scenarijev, v katerih lahko uporabite vdelave za reševanje določenih težav, bodisi samostojno bodisi v sodelovanju z LLM:
- Vprašanje in odgovor – Vdelave lahko pomagajo pri podpori vmesnikov vprašanj in odgovorov prek vzorca RAG. Generiranje vdelav v kombinaciji z vektorsko zbirko podatkov vam omogoča iskanje tesnih ujemanj med vprašanji in vsebino v repozitoriju znanja.
- Prilagojena priporočila – Podobno kot vprašanja in odgovori lahko uporabite vdelave za iskanje počitniških destinacij, fakultet, vozil ali drugih izdelkov na podlagi kriterijev, ki jih zagotovi uporabnik. To bi lahko bilo v obliki preprostega seznama ujemanj ali pa bi nato uporabili LLM za obdelavo vsakega priporočila in razlago, kako izpolnjuje merila uporabnika. Ta pristop lahko uporabite tudi za ustvarjanje »10 najboljših« člankov po meri za uporabnika na podlagi njegovih posebnih potreb.
- Upravljanje podatkov – Ko imate vire podatkov, ki se med seboj ne preslikajo čisto, vendar imate vsebino besedila, ki opisuje zapis podatkov, lahko uporabite vdelave za prepoznavanje morebitnih podvojenih zapisov. Na primer, lahko uporabite vdelave za identifikacijo podvojenih kandidatov, ki lahko uporabljajo drugačno oblikovanje, okrajšave ali imajo celo prevedena imena.
- Racionalizacija portfelja aplikacij – Ko želite uskladiti portfelje aplikacij v matičnem podjetju in prevzemu, ni vedno jasno, kje začeti iskati morebitno prekrivanje. Kakovost podatkov o upravljanju konfiguracije je lahko omejevalni dejavnik in lahko je težko usklajevati med ekipami, da bi razumeli pokrajino aplikacij. Z uporabo semantičnega ujemanja z vdelavami lahko izvedemo hitro analizo portfeljev aplikacij, da prepoznamo aplikacije kandidatov z visokim potencialom za racionalizacijo.
- Združevanje vsebine – Z vdelavami lahko pomagate pri združevanju podobne vsebine v kategorije, ki jih morda ne poznate vnaprej. Recimo, da ste imeli zbirko e-poštnih sporočil strank ali spletnih ocen izdelkov. Ustvarite lahko vdelave za vsak element, nato pa te vdelave preženete k-pomeni združevanje v gruče za prepoznavanje logičnih skupin pomislekov strank, pohval ali pritožb izdelkov ali drugih tem. Nato lahko z LLM ustvarite usmerjene povzetke iz vsebine teh skupin.
Primer semantičnega iskanja
V našem primer na GitHubu, prikazujemo preprosto aplikacijo za iskanje vdelav z Amazon Titan Text Embeddings, LangChain in Streamlit.
Primer ujema uporabnikovo poizvedbo z najbližjimi vnosi v vektorski bazi podatkov v pomnilniku. Ta ujemanja nato prikažemo neposredno v uporabniškem vmesniku. To je lahko koristno, če želite odpraviti težave z aplikacijo RAG ali neposredno oceniti model vdelave.
Zaradi enostavnosti uporabljamo in-memory FAISS baza podatkov za shranjevanje in iskanje vdelanih vektorjev. V velikem scenariju resničnega sveta boste verjetno želeli uporabiti trajno shrambo podatkov, kot je vektorski mehanizem za Amazon OpenSearch Serverless ali pgvector razširitev za PostgreSQL.
Poskusite nekaj pozivov iz spletne aplikacije v različnih jezikih, na primer naslednje:
- Kako lahko spremljam svojo porabo?
- Kako lahko prilagodim modele?
- Katere programske jezike lahko uporabljam?
- Comment mes données sont-elles sécurisées ?
- 私のデータはどのように保護されていますか?
- Quais fornecedores de modelos estão disponíveis por meio do Bedrock?
- In welchen Regionen ist Amazon Bedrock verfügbar?
- 有哪些级别的支持?
Upoštevajte, da čeprav je bil izvorni material v angleščini, so bile poizvedbe v drugih jezikih usklajene z ustreznimi vnosi.
zaključek
Zmožnosti generiranja besedil temeljnih modelov so zelo vznemirljive, vendar je pomembno vedeti, da so razumevanje besedila, iskanje ustrezne vsebine iz zbirke znanja in vzpostavljanje povezav med odlomki ključnega pomena za doseganje polne vrednosti generativne umetne inteligence. Še naprej bomo videli nove in zanimive primere uporabe vdelav, ki se bodo pojavljali v naslednjih letih, saj se ti modeli še naprej izboljšujejo.
Naslednji koraki
Dodatne primere vdelav kot zvezke ali demo aplikacije lahko najdete na naslednjih delavnicah:
O avtorjih
 Jason Stehle je višji arhitekt za rešitve pri AWS s sedežem na območju Nove Anglije. S strankami sodeluje pri usklajevanju zmogljivosti AWS z njihovimi največjimi poslovnimi izzivi. Zunaj dela svoj čas preživlja z gradnjo stvari in gledanjem stripov z družino.
Jason Stehle je višji arhitekt za rešitve pri AWS s sedežem na območju Nove Anglije. S strankami sodeluje pri usklajevanju zmogljivosti AWS z njihovimi največjimi poslovnimi izzivi. Zunaj dela svoj čas preživlja z gradnjo stvari in gledanjem stripov z družino.
 Nitin Evzebij je višji arhitekt za podjetniške rešitve pri AWS, ima izkušnje s programskim inženiringom, podjetniško arhitekturo in AI/ML. Zelo je navdušen nad raziskovanjem možnosti generativne umetne inteligence. Sodeluje s strankami, da bi jim pomagal zgraditi dobro zasnovane aplikacije na platformi AWS, in je predan reševanju tehnoloških izzivov in pomoči pri njihovi poti v oblak.
Nitin Evzebij je višji arhitekt za podjetniške rešitve pri AWS, ima izkušnje s programskim inženiringom, podjetniško arhitekturo in AI/ML. Zelo je navdušen nad raziskovanjem možnosti generativne umetne inteligence. Sodeluje s strankami, da bi jim pomagal zgraditi dobro zasnovane aplikacije na platformi AWS, in je predan reševanju tehnoloških izzivov in pomoči pri njihovi poti v oblak.
 Raj Pathak je glavni arhitekt rešitev in tehnični svetovalec velikih podjetij s seznama Fortune 50 in srednje velikih ustanov za finančne storitve (FSI) v Kanadi in Združenih državah. Specializiran je za aplikacije strojnega učenja, kot so generativni AI, obdelava naravnega jezika, inteligentna obdelava dokumentov in MLOps.
Raj Pathak je glavni arhitekt rešitev in tehnični svetovalec velikih podjetij s seznama Fortune 50 in srednje velikih ustanov za finančne storitve (FSI) v Kanadi in Združenih državah. Specializiran je za aplikacije strojnega učenja, kot so generativni AI, obdelava naravnega jezika, inteligentna obdelava dokumentov in MLOps.
 Mani Khanuja je tehnični vodja – Generative AI Specialists, avtorica knjige – Applied Machine Learning and High Performance Computing on AWS in članica upravnega odbora Fundacije za ženske v proizvodnem izobraževanju. Vodi projekte strojnega učenja (ML) na različnih področjih, kot so računalniški vid, obdelava naravnega jezika in generativna umetna inteligenca. Strankam pomaga zgraditi, usposobiti in uvesti velike modele strojnega učenja v velikem obsegu. Govori na internih in zunanjih konferencah, kot so re:Invent, Women in Manufacturing West, YouTube spletni seminarji in GHC 23. V prostem času se rada odpravi na dolge teke ob plaži.
Mani Khanuja je tehnični vodja – Generative AI Specialists, avtorica knjige – Applied Machine Learning and High Performance Computing on AWS in članica upravnega odbora Fundacije za ženske v proizvodnem izobraževanju. Vodi projekte strojnega učenja (ML) na različnih področjih, kot so računalniški vid, obdelava naravnega jezika in generativna umetna inteligenca. Strankam pomaga zgraditi, usposobiti in uvesti velike modele strojnega učenja v velikem obsegu. Govori na internih in zunanjih konferencah, kot so re:Invent, Women in Manufacturing West, YouTube spletni seminarji in GHC 23. V prostem času se rada odpravi na dolge teke ob plaži.
 Mark Roy je glavni arhitekt strojnega učenja za AWS, ki strankam pomaga oblikovati in zgraditi rešitve AI/ML. Markovo delo pokriva širok spekter primerov uporabe ML, pri čemer ga zanima predvsem računalniški vid, globoko učenje in razširjanje ML v podjetju. Pomagal je podjetjem v številnih panogah, vključno z zavarovalništvom, finančnimi storitvami, mediji in zabavo, zdravstvom, komunalnimi storitvami in proizvodnjo. Mark ima šest certifikatov AWS, vključno s certifikatom ML Specialty. Preden se je Mark pridružil podjetju AWS, je bil več kot 25 let arhitekt, razvijalec in tehnološki vodja, vključno z 19 leti v finančnih storitvah.
Mark Roy je glavni arhitekt strojnega učenja za AWS, ki strankam pomaga oblikovati in zgraditi rešitve AI/ML. Markovo delo pokriva širok spekter primerov uporabe ML, pri čemer ga zanima predvsem računalniški vid, globoko učenje in razširjanje ML v podjetju. Pomagal je podjetjem v številnih panogah, vključno z zavarovalništvom, finančnimi storitvami, mediji in zabavo, zdravstvom, komunalnimi storitvami in proizvodnjo. Mark ima šest certifikatov AWS, vključno s certifikatom ML Specialty. Preden se je Mark pridružil podjetju AWS, je bil več kot 25 let arhitekt, razvijalec in tehnološki vodja, vključno z 19 leti v finančnih storitvah.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/machine-learning/getting-started-with-amazon-titan-text-embeddings/
- :ima
- : je
- :ne
- :kje
- $GOR
- 000
- 10
- 100
- 12
- 121
- 125
- 19
- 23
- 25
- 50
- 8
- a
- O meni
- abstrakcija
- Sprejmi
- natančnost
- natančna
- natančno
- doseže
- doseganju
- pridobitev
- čez
- Poleg tega
- Dodatne
- Prednost
- svetovalec
- naprej
- AI
- AI modeli
- AI / ML
- algoritmi
- uskladiti
- vsi
- omogočajo
- Dovoli
- omogoča
- skupaj
- skupaj
- Prav tako
- vedno
- Amazon
- Amazon Web Services
- an
- Analiza
- analizirati
- in
- odgovor
- kaj
- uporaba
- aplikacije
- uporabna
- Uporabi
- pristop
- Arhitektura
- arhitekture
- SE
- OBMOČJE
- članki
- AS
- pomoč
- At
- povečanje
- Povečana
- Avtor
- Na voljo
- AWS
- temeljijo
- BE
- Beach
- počutje
- Prednosti
- med
- svet
- uprava
- telo
- Knjiga
- Pasovi
- izgradnjo
- Building
- poslovni
- vendar
- by
- CAN
- Kanada
- Kandidat
- kandidati
- Zmogljivosti
- zajemanje
- ujame
- primeru
- primeri
- kategorije
- certificiranje
- certifikati
- izzivi
- Razvrstitev
- stranke
- Zapri
- Cloud
- grozdenje
- Koda
- zbirka
- Visoke šole
- kombinacija
- Skupno
- Podjetja
- podjetje
- primerjate
- Pritožbe
- kompleksna
- računalnik
- Računalniška vizija
- računalništvo
- koncepti
- Skrbi
- konference
- konfiguracija
- Connect
- povezava
- povezave
- dosledno
- vsebina
- ozadje
- kontekstualno
- naprej
- priročno
- pretvorbo
- pretvori
- sodelovanje
- usklajevanje
- stroškovno učinkovito
- bi
- kritje
- prevleke
- ustvarjajo
- Ustvarjanje
- Merila
- ključnega pomena
- Trenutno
- po meri
- stranka
- Stranke, ki so
- prilagodite
- datum
- Baze podatkov
- de
- namenjen
- globoko
- globoko učenje
- globoko
- opredeliti
- Stopnja
- Predstavitev
- izkazati
- razporedi
- opisuje
- Oblikovanje
- destinacije
- Podrobnosti
- Razvojni
- drugačen
- težko
- Dimenzije
- neposredno
- Direktorji
- razpravlja
- zaslon
- do
- dokument
- Dokumenti
- domen
- dont
- vsak
- Izobraževanje
- učinkovito
- bodisi
- e-pošta
- vdelava
- pojavljajo
- omogočajo
- omogoča
- Motor
- Inženiring
- Anglija
- Angleščina
- Podjetje
- Rešitve za podjetja
- Zabava
- Celotna
- popolnoma
- entiteta
- Eter (ETH)
- oceniti
- Tudi
- Primer
- Primeri
- zanimivo
- Razširi
- izkušnje
- izkušen
- Pojasnite
- Raziskovati
- razširitev
- zunanja
- olajšati
- Faktor
- družina
- Lastnosti
- Nekaj
- finančna
- finančne storitve
- Najdi
- iskanje
- prva
- prilagodljivost
- osredotočena
- po
- za
- obrazec
- Fortune
- Fundacija
- Okvirni
- brezplačno
- iz
- polno
- temeljna
- ustvarjajo
- generacija
- generativno
- Generativna AI
- dobili
- pridobivanje
- Giving
- rokavice
- Go
- Največji
- imel
- Imajo
- he
- zdravstveno varstvo
- pomoč
- pomagal
- pomoč
- Pomaga
- jo
- visoka
- High Performance Computing
- njegov
- drži
- Kako
- Kako
- HTML
- HTTPS
- i
- identificirati
- if
- izvajanja
- uvoz
- Pomembno
- izboljšanje
- in
- V drugi
- vključujejo
- vključuje
- Vključno
- industrij
- Podatki
- vhod
- namestitev
- Namesto
- Institucije
- zavarovanje
- Inteligentna
- Inteligentna obdelava dokumentov
- obresti
- Zanimivo
- vmesnik
- vmesniki
- notranji
- Facebook Global
- v
- IT
- ITS
- pridružil
- Potovanje
- jpg
- json
- Ključne
- Vedite
- Vedeti
- znanje
- Pokrajina
- jezik
- jeziki
- velika
- plast
- vodi
- Vodja
- Interesenti
- učenje
- Naj
- kot
- Verjeten
- všeč mi je
- omejujoč
- Seznam
- llm
- logično
- Long
- Poglej
- si
- stroj
- strojno učenje
- vzdrževati
- Znamka
- Izdelava
- upravlja
- upravljanje
- proizvodnja
- več
- map
- znamka
- Markove
- Prisotnost
- ujema
- tekme
- ujemanje
- Material
- me
- kar pomeni,
- pomeni
- mediji
- član
- Metoda
- morda
- ML
- ML algoritmi
- MLOps
- Model
- modeli
- monitor
- več
- Najbolj
- Najbolj popularni
- filmi
- več
- my
- Ime
- Imenovan
- Imena
- naravna
- Naravni jezik
- Obdelava Natural Language
- Nimate
- potrebujejo
- potrebe
- Novo
- Naslednja
- nlp
- zvezki
- Očitna
- of
- ponujen
- on
- ONE
- na spletu
- odprite
- open source
- optimizirana
- optimizacijo
- or
- Da
- Ostalo
- drugi
- naši
- ven
- izhod
- zunaj
- več
- lastne
- pakete
- seznanjeni
- parameter
- parametri
- matično podjetje
- odlomki
- strastno
- Vzorec
- vzorci
- za
- opravlja
- performance
- personalizacija
- stavki
- kos
- platforma
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Predvajaj
- prosim
- Popular
- S
- Portfelj
- portfelji
- možnosti
- Prispevek
- postgresql
- potencial
- moč
- primarni
- , ravnateljica
- Tiskanje
- Predhodna
- Težave
- Postopek
- obravnavati
- Izdelek
- Artiklov
- Izdelki
- Programiranje
- programskih jezikov
- projekti
- pozove
- lastniško
- zagotavljajo
- če
- zagotavlja
- Python
- kakovost
- poizvedbe
- poizvedba
- vprašanje
- vprašanja
- Hitri
- krpa
- območje
- RE
- dosežejo
- resnični svet
- Priznanje
- Priporočilo
- Priporočila
- zapis
- evidence
- nanaša
- Razmerja
- pomembno
- ne pozabite
- Skladišče
- zastopanje
- predstavlja
- zahteva
- obvezna
- Odgovor
- REST
- omejeno
- rezultat
- Rezultati
- iskanje
- vrne
- Mnenja
- vloga
- Run
- deluje
- s
- Enako
- pravijo,
- Lestvica
- skaliranje
- Scenarij
- scenariji
- SDK
- Iskalnik
- glej
- pomensko
- semantika
- višji
- stavek
- sentiment
- ločena
- Brez strežnika
- Storitve
- je
- Podoben
- Enostavno
- preprostost
- poenostavljeno
- poenostavitev
- sam
- SIX
- So
- Software
- inženiring programske opreme
- rešitve
- SOLVE
- Reševanje
- nekaj
- Nekaj
- vir
- Viri
- Vesolje
- Govori
- strokovnjaki
- specializirano
- Posebnost
- specifična
- Začetek
- začel
- Države
- trgovina
- strukture
- taka
- podpora
- Podprti
- Podpora
- Podpira
- Bodite
- Naloge
- Skupine
- tech
- tehnični
- tehnika
- tehnike
- Tehnologije
- Tehnologija
- povej
- besedilo
- Razvrstitev besedil
- tvorjenje besedila
- da
- O
- Vir
- njihove
- Njih
- teme
- POTEM
- Tukaj.
- te
- stvari
- ta
- tisti,
- čeprav?
- skozi
- čas
- titan
- do
- Boni
- tradicionalna
- Vlak
- usposobljeni
- transformatorji
- preoblikovanje
- razumeli
- razumevanje
- poenoteno
- Velika
- Združene države Amerike
- Uporaba
- uporaba
- primeru uporabe
- Rabljeni
- koristno
- uporabnik
- Uporabniški vmesnik
- Uporabniki
- uporabo
- javne gospodarske službe
- počitnice
- vrednost
- različnih
- Vozila
- zelo
- preko
- Vizija
- želeli
- je
- gledanju
- we
- web
- Spletna aplikacija
- spletne storitve
- Webinars
- Dobro
- so bili
- West
- kdaj
- ki
- medtem
- široka
- Širok spekter
- bo
- z
- v
- brez
- Ženske
- beseda
- besede
- delo
- deluje
- deluje
- Delavnice
- bi
- pisati
- pisanje
- let
- jo
- Vaša rutina za
- youtube
- zefirnet