AWS Glue Studio je zdaj integriran z AWS lepilo DataBrew. AWS Glue Studio je grafični vmesnik, ki olajša ustvarjanje, zagon in spremljanje opravil ekstrahiranja, preoblikovanja in nalaganja (ETL) v AWS lepilo. DataBrew je vizualno orodje za pripravo podatkov, ki vam omogoča čiščenje in normalizacijo podatkov brez pisanja kode. Več kot 200 transformacij, ki jih ponuja, je zdaj na voljo za uporabo v vizualnem opravilu AWS Glue Studio.
V programu DataBrew a Recept je nabor korakov za pretvorbo podatkov, ki jih lahko ustvarite interaktivno v njegovem intuitivnem vizualnem vmesniku. V tej objavi boste videli, kako uporabiti sestavite recept v DataBrew in ga nato uporabite kot del vizualnega ETL opravila AWS Glue Studio.
Obstoječi uporabniki DataBrew bodo prav tako imeli koristi od te integracije – zdaj lahko izvajate svoje recepte kot del večjega vizualnega poteka dela z vsemi drugimi komponentami, ki jih ponuja AWS Glue Studio, poleg tega, da lahko uporabljate napredno konfiguracijo opravil in najnovejšo različico mehanizma AWS Glue .
Ta integracija prinaša posebne prednosti obstoječim uporabnikom obeh orodij:
- V AWS Glue Studio imate centraliziran pogled celotnega diagrama ETL od konca do konca
- Interaktivno lahko definirate recept, si ogledate vrednosti, statistiko in distribucijo na konzoli DataBrew, nato pa ponovno uporabite to preizkušeno logiko obdelave z različicami v vizualnih opravilih AWS Glue Studio
- Orkestrirate lahko več receptov DataBrew v opravilu AWS Glue ETL ali celo več opravil z uporabo delovnih tokov AWS Glue
- Recepti DataBrew lahko zdaj uporabljajo funkcije AWS Glue job, kot so zaznamki za inkrementalno obdelavo podatkov, samodejni ponovni poskusi, samodejno merjenje ali združevanje majhnih datotek za večjo učinkovitost
Pregled rešitev
V našem fiktivnem primeru uporabe je zahteva čiščenje podatkovnega niza sintetičnih medicinskih trditev, ustvarjenega za to objavo, ki ima nekaj težav s kakovostjo podatkov, uvedenih namenoma za prikaz zmogljivosti DataBrew za pripravo podatkov. Nato se podatki o zahtevkih vnesejo v katalog (tako da so vidni analitikom), potem ko se obogatijo z nekaterimi ustreznimi podrobnostmi o ustreznih ponudnikih zdravstvenih storitev, ki prihajajo iz ločenega vira.
Rešitev je sestavljena iz vizualnega opravila AWS Glue Studio, ki bere dve datoteki CSV z zahtevki oziroma ponudniki. Opravilo uporabi recept prvega za obravnavo težav s kakovostjo, izbere stolpce iz drugega, združi oba niza podatkov in končno shrani rezultat na Preprosta storitev shranjevanja Amazon (Amazon S3), ustvarjanje tabele v katalogu, tako da lahko izhodne podatke uporabljajo druga orodja, kot je Amazonska Atena.
Ustvarite recept za DataBrew
Začnite z registracijo shrambe podatkov za datoteko zahtevkov. To vam bo omogočilo, da sestavite recept v njegovem interaktivnem urejevalniku z uporabo dejanskih podatkov, tako da lahko ocenite rezultat transformacij, ko jih definirate.
- Prenesite datoteko zahtevkov CSV s to povezavo: alabama_claims_data_Jun2023.csv.
- Na konzoli DataBrew izberite Podatkovni nizi v podoknu za krmarjenje in nato izberite Povežite nov nabor podatkov.
- Izberite možnost Nalaganje datoteke.
- za Ime nabora podatkov, vnesite
Alabama claims. - za Izberite datoteko za nalaganje, izberite datoteko, ki ste jo pravkar prenesli v svoj računalnik.
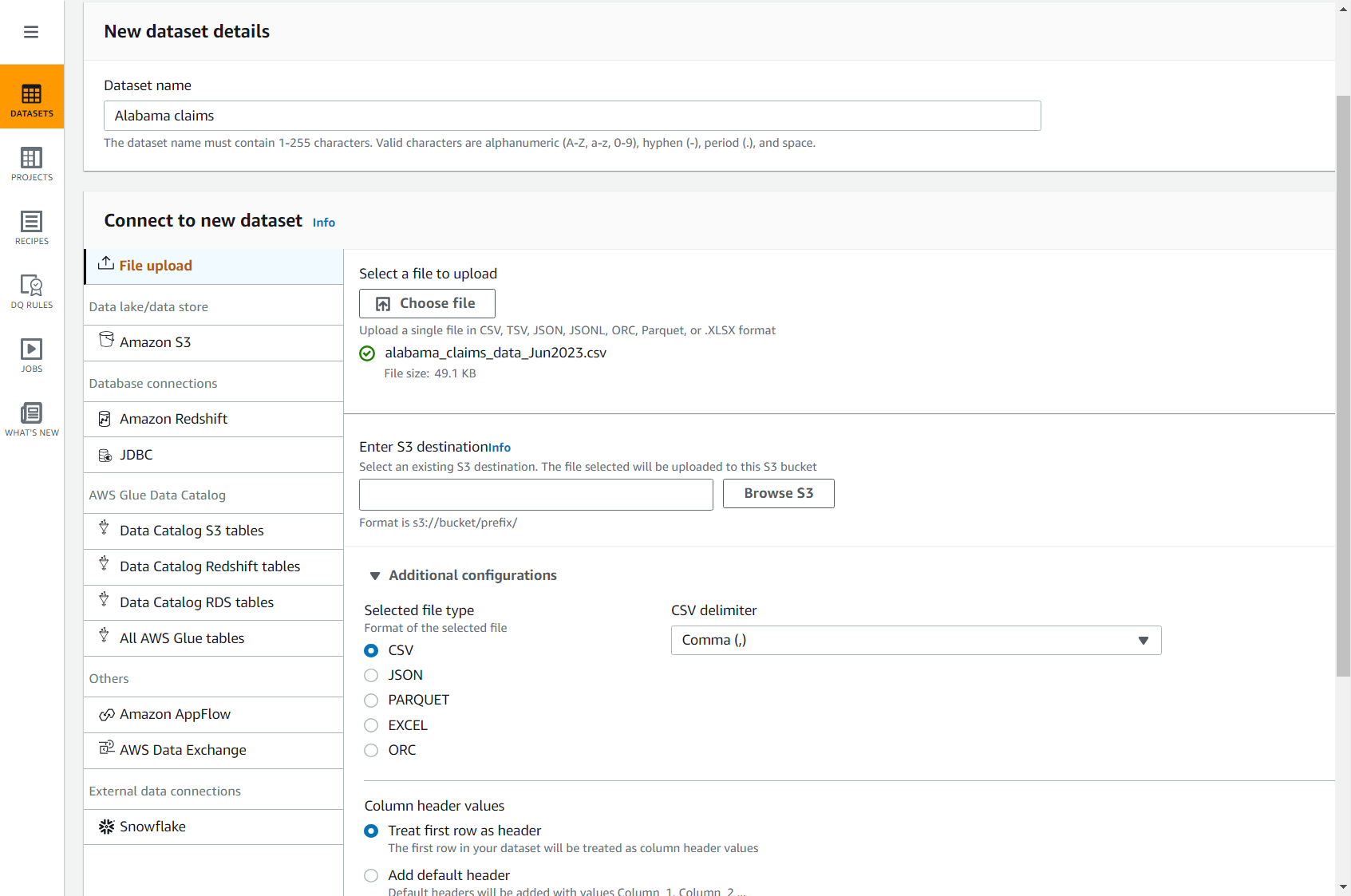
- za Vnesite cilj S3, vnesite ali poiščite vedro v svojem računu in regiji.
- Ostale možnosti pustite privzete (CSV ločen z vejico in z glavo) in dokončajte ustvarjanje nabora podatkov.
- Izberite Projekt v podoknu za krmarjenje in nato izberite Ustvarite projekt.
- za Ime Projekta, ime
ClaimsCleanup. - Pod Podrobnosti receptaZa Priložen recept, izberite Ustvari nov recept, ime
ClaimsCleanup-recipein izberiteAlabama claimsnabor podatkov, ki ste ga pravkar ustvarili.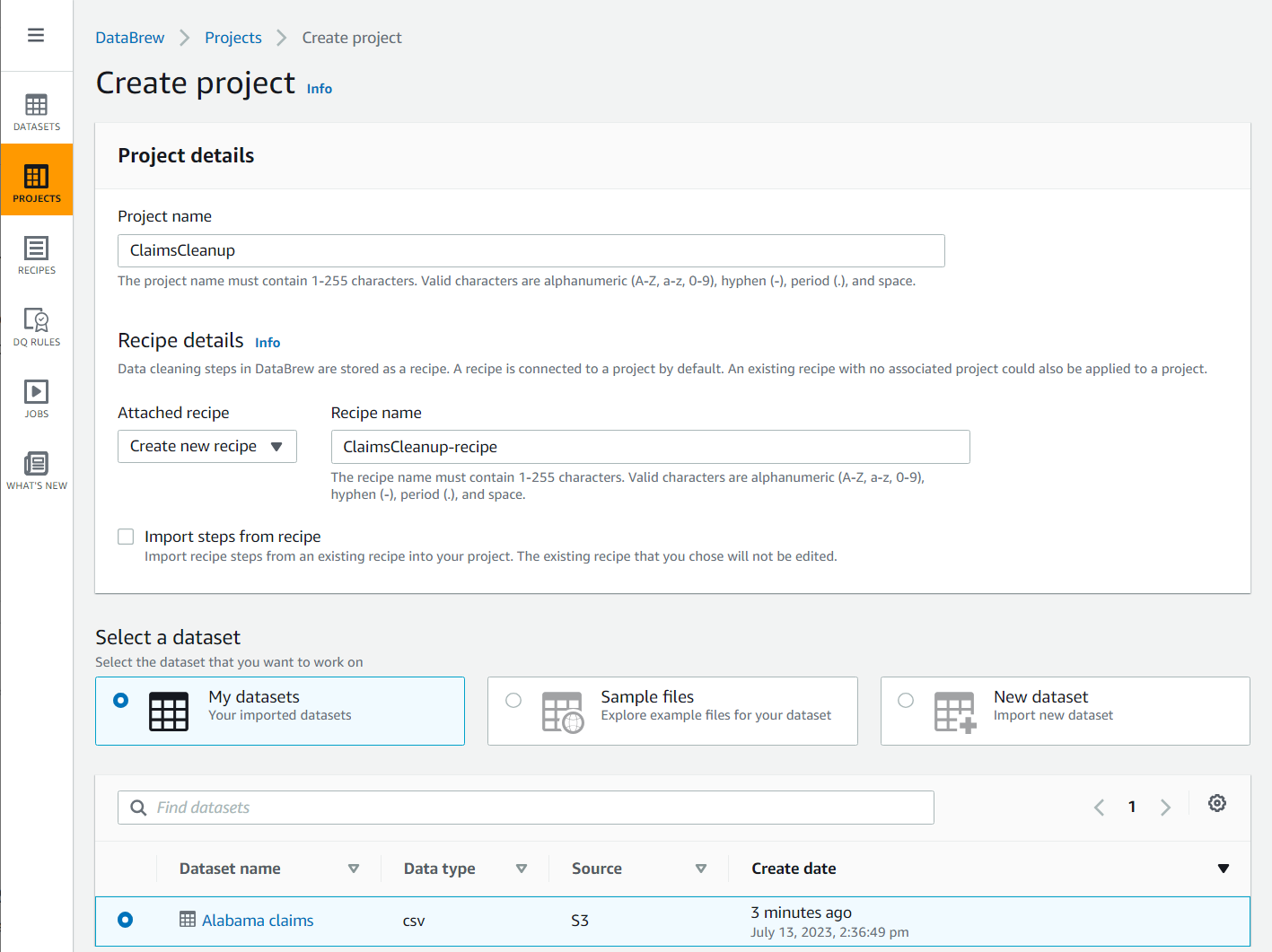
- Izberi vloga primerna za DataBrew ali ustvarite novega in dokončajte ustvarjanje projekta.
To bo ustvarilo sejo z uporabo nastavljive podnabora podatkov. Ko je inicializiral sejo, lahko opazite, da imajo nekatere celice neveljavne ali manjkajoče vrednosti.
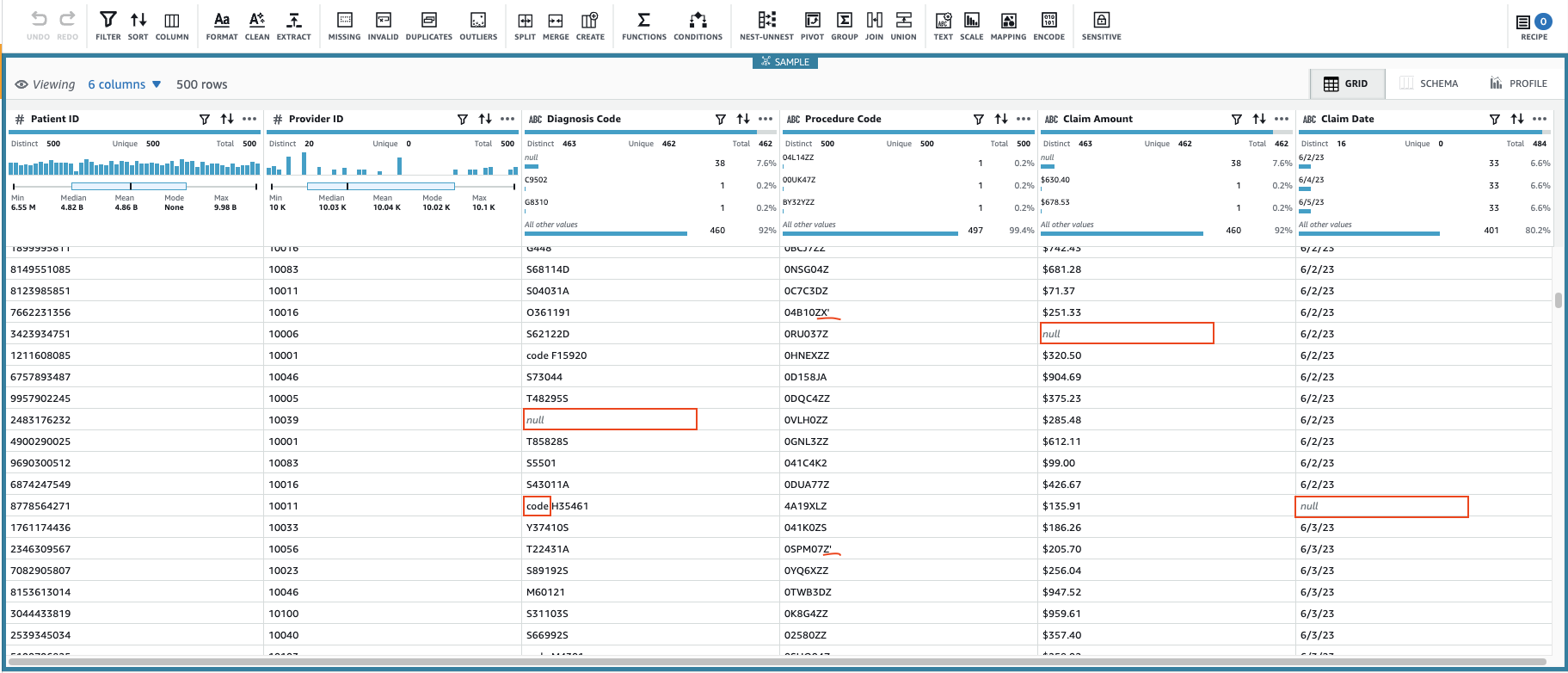
Poleg manjkajočih vrednosti v stolpcih Diagnostična koda, Znesek zahtevkain Datum zahtevkaimajo nekatere vrednosti v podatkih nekaj dodatnih znakov: Diagnostična koda vrednosti imajo včasih predpono "koda" (vključen presledek) in Postopkovni zakonik vrednostim včasih sledijo enojni narekovaji.
Znesek zahtevka vrednosti bodo verjetno uporabljene za nekatere izračune, zato pretvorite v število in Podatki o zahtevku je treba pretvoriti v vrsto datuma.
Zdaj, ko smo identificirali težave s kakovostjo podatkov, ki jih je treba obravnavati, se moramo odločiti, kako ravnati v vsakem primeru.
Korake recepta lahko dodate na več načinov, vključno z uporabo kontekstnega menija stolpca, orodne vrstice na vrhu ali iz povzetka recepta. Z zadnjo metodo lahko poiščete navedeno vrsto koraka za ponovitev recepta, ustvarjenega v tej objavi.
Znesek zahtevka je bistvenega pomena za ta primer uporabe in odločitev je, da se takšne vrstice odstranijo.
- Dodajte korak Odstranite manjkajoče vrednosti.
- za Izvorni stolpec, izberite Znesek zahtevka.
- Pustite privzeto dejanje Izbrišite vrstice z manjkajočimi vrednostmi In izberite Uporabi da ga shranite.
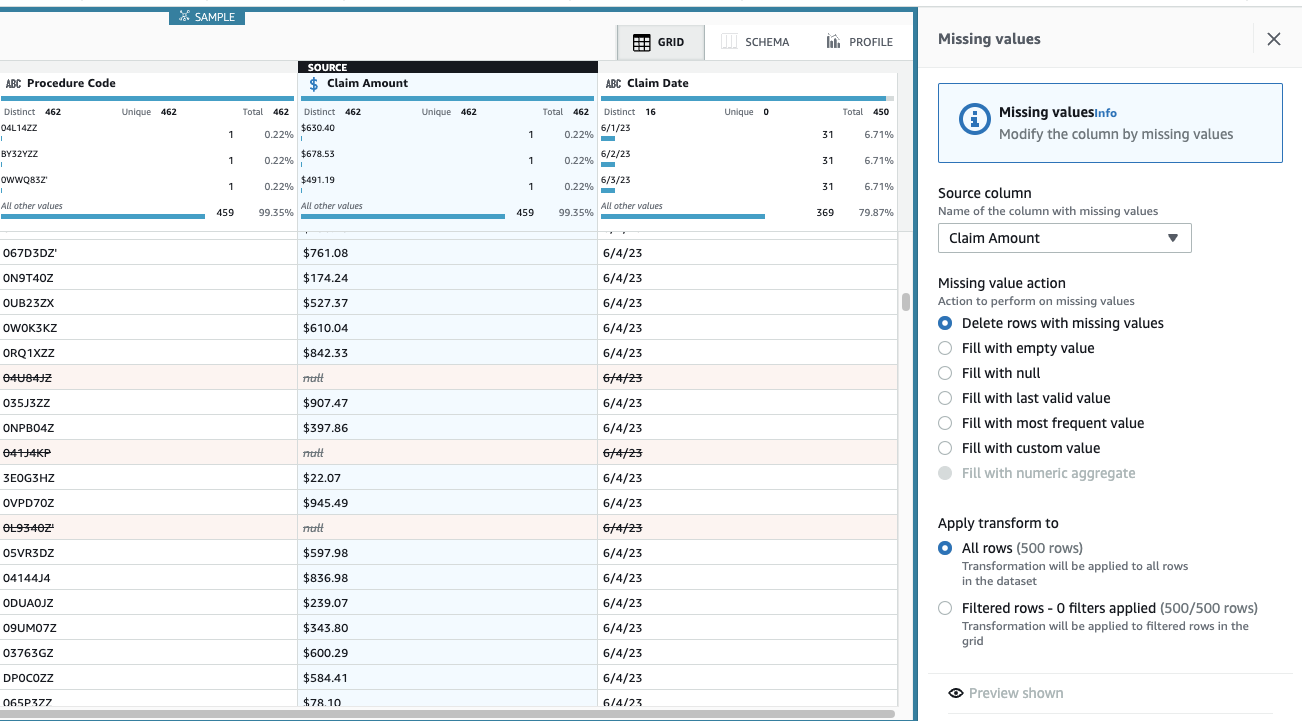
Pogled je zdaj posodobljen, da odraža aplikacijo korakov, vrstic z manjkajočimi zneski pa ni več.
Diagnostična koda je lahko prazno, zato je to sprejemljivo, vendar v primeru Datum zahtevka, želimo imeti razumno oceno. Vrstice v podatkih so razvrščene v kronološkem vrstnem redu, tako da lahko pripišete manjkajoče datume z uporabo veljavne vrednosti predogleda iz prejšnjih vrstic. Ob predpostavki, da ima vsak dan zahtevke, bi bila največja napaka pri dodelitvi dnevu predogleda, če bi prvemu zahtevku tega dne manjkal datum; za ponazoritev upoštevajmo to morebitno napako kot sprejemljivo.
Najprej pretvorite stolpec iz niza v vrsto datuma.
- Dodajte korak Spremeni vrsto.
- Izberite Datum zahtevka kot stolpec in Datum kot vrsto, nato izberite Uporabi.
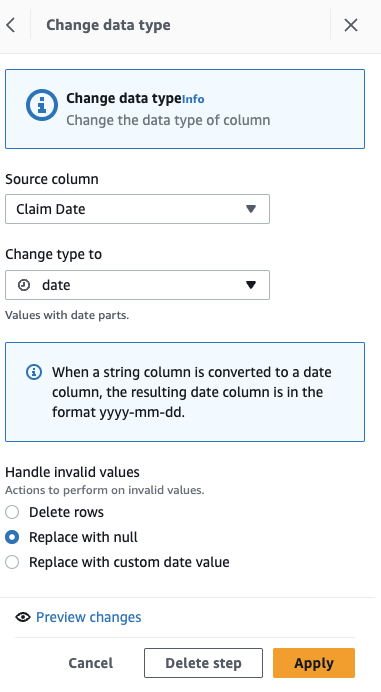
- Zdaj, da izvedete imputacijo manjkajočih datumov, dodajte korak Izpolnite ali pripišite manjkajoče vrednosti.
- Za dejanje izberite Izpolni z zadnjo veljavno vrednostjo in izberite Datum zahtevka kot vir.
- Izberite Predogled sprememb da ga potrdite, nato izberite Uporabi da shranite korak.
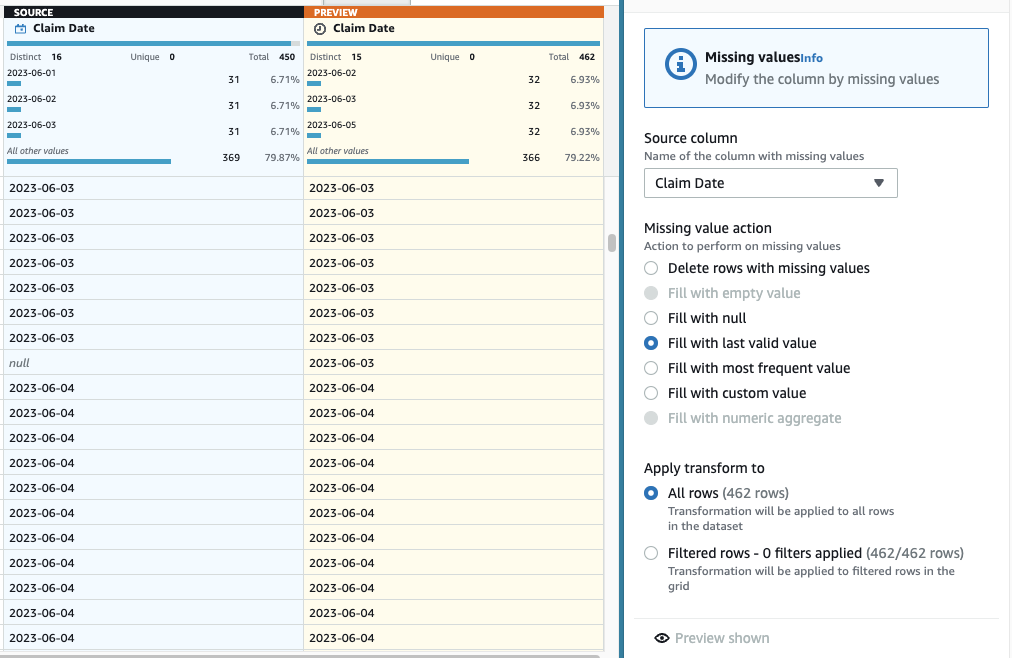
Zaenkrat bi moral vaš recept imeti tri korake, kot je prikazano na naslednjem posnetku zaslona.
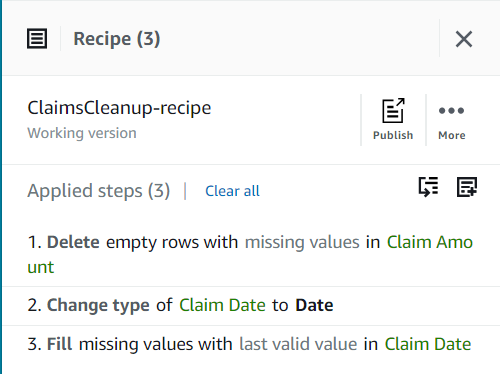
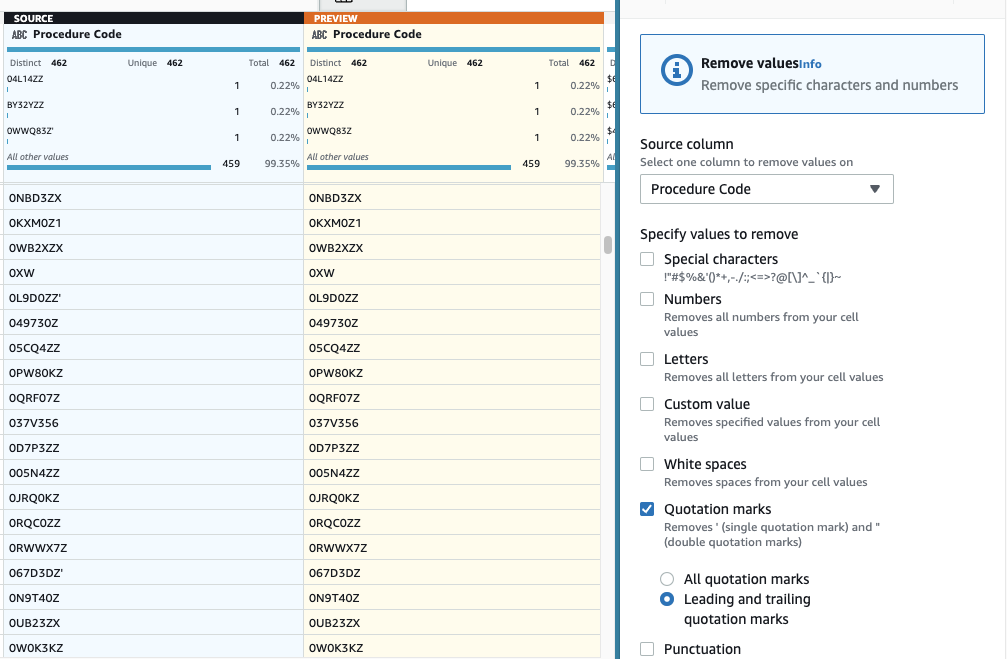
- Nato dodajte korak Odstranite narekovaje.
- Izberite Postopkovni zakonik stolpec in izberite Začetni in končni narekovaji.
- Predogled, da preverite, ali ima želeni učinek, in uporabite nov korak.
- Dodajte korak Odstranite posebne znake.
- Izberite Znesek zahtevka in če smo natančnejši, izberite Posebni znaki po meri in vnesite
$za Vnesite posebne znake po meri.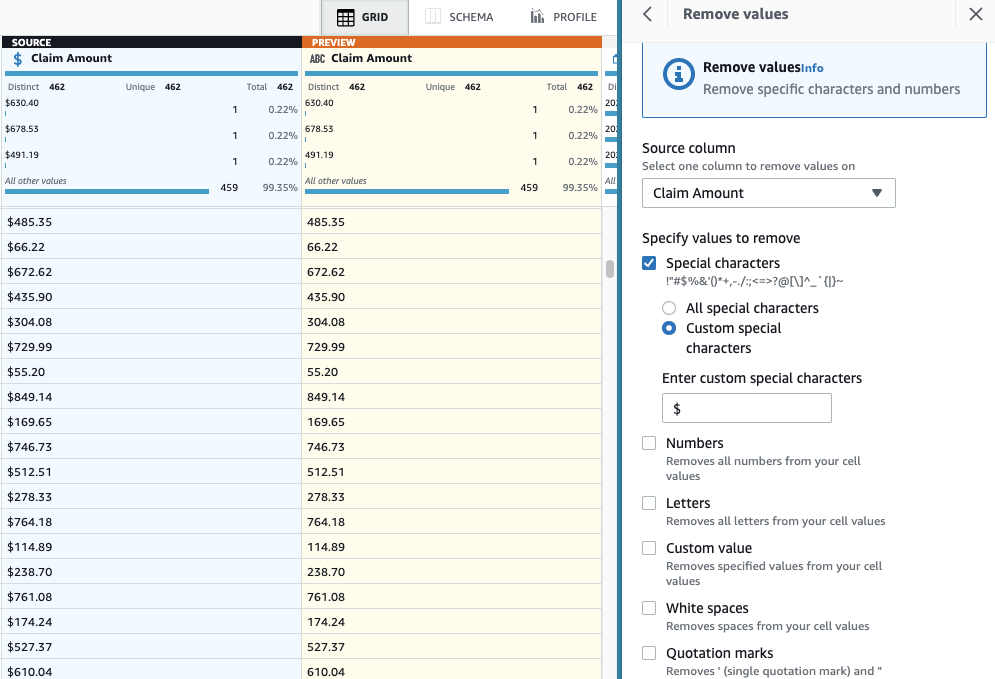
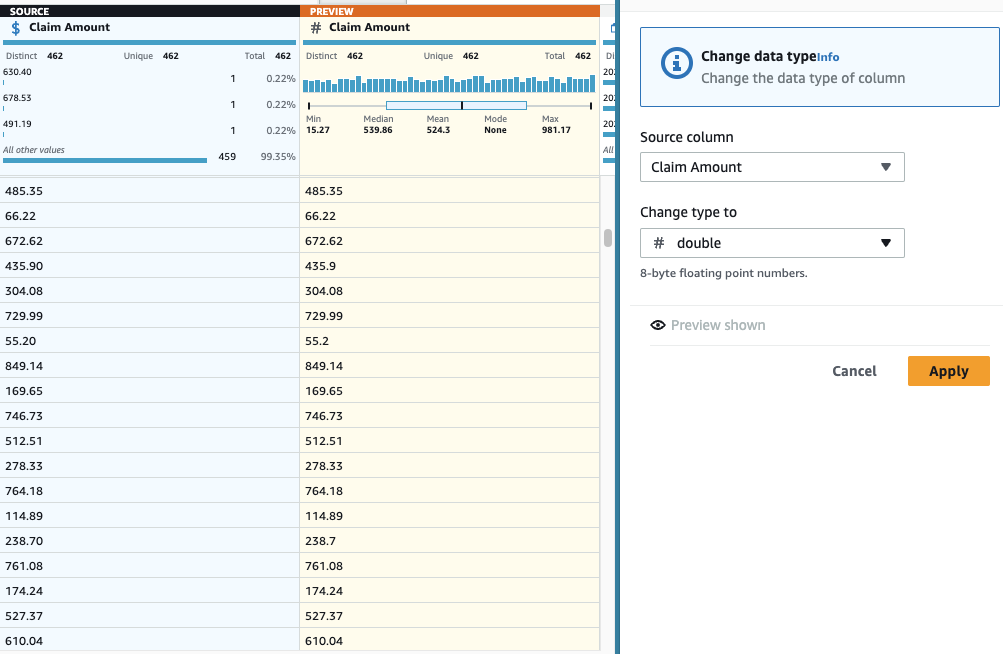
- Dodaj Spremeni vrsto stopiti na stolpec Znesek zahtevka In izberite podvojila kot tip.
- Kot zadnji korak, da odstranite odvečno predpono »code«, dodajte a Zamenjajte vrednost ali vzorec korak.
- Izberite stolpec Diagnostična kodaIn za Vnesite vrednost po meri, vnesite
code(s presledkom na koncu).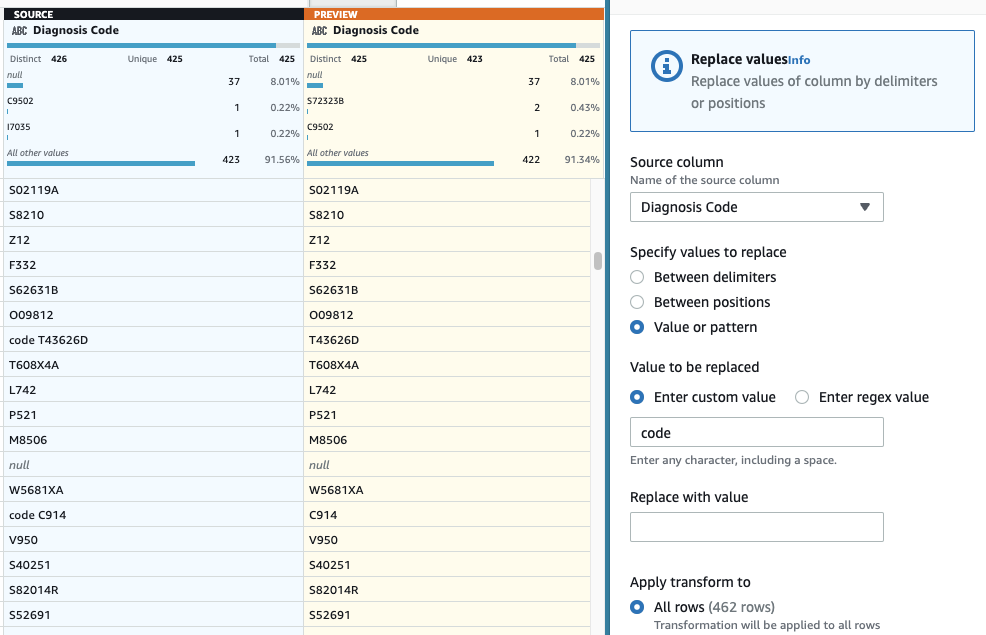
Zdaj, ko ste obravnavali vse težave s kakovostjo podatkov, ugotovljene v vzorcu, objavite projekt kot recept.
- Izberite objavi v Recept podokno, vnesite izbirni opis in dokončajte objavo.
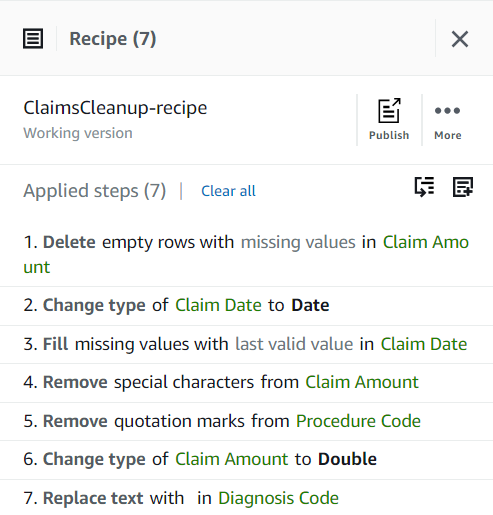
Vsakič, ko objavite, bo ustvarila drugačno različico recepta. Kasneje boste lahko izbrali, katero različico recepta boste uporabili.
Ustvarite vizualno opravilo ETL v AWS Glue Studio
Nato ustvarite opravilo, ki uporablja recept. Izvedite naslednje korake:
- Na konzoli AWS Glue Studio izberite Vizualni ETL v podoknu za krmarjenje.
- Izberite Vizualno s praznim platnom in ustvarite vizualno delo.
- Na vrhu opravila zamenjajte »Delo brez naslova« z imenom po vaši izbiri.
- o podrobnosti zaposlitve podajte vlogo, ki jo bo opravilo uporabljalo.
To mora biti AWS upravljanje identitete in dostopa (JAZ SEM) vloga primerna za lepilo AWS z dovoljenji za Amazon S3 in AWS Glue Data Catalog. Upoštevajte, da vloga, ki je bila prej uporabljena za DataBrew, ni uporabna za zagonska opravila, zato ne bo navedena na Vloga IAM spustni meni tukaj.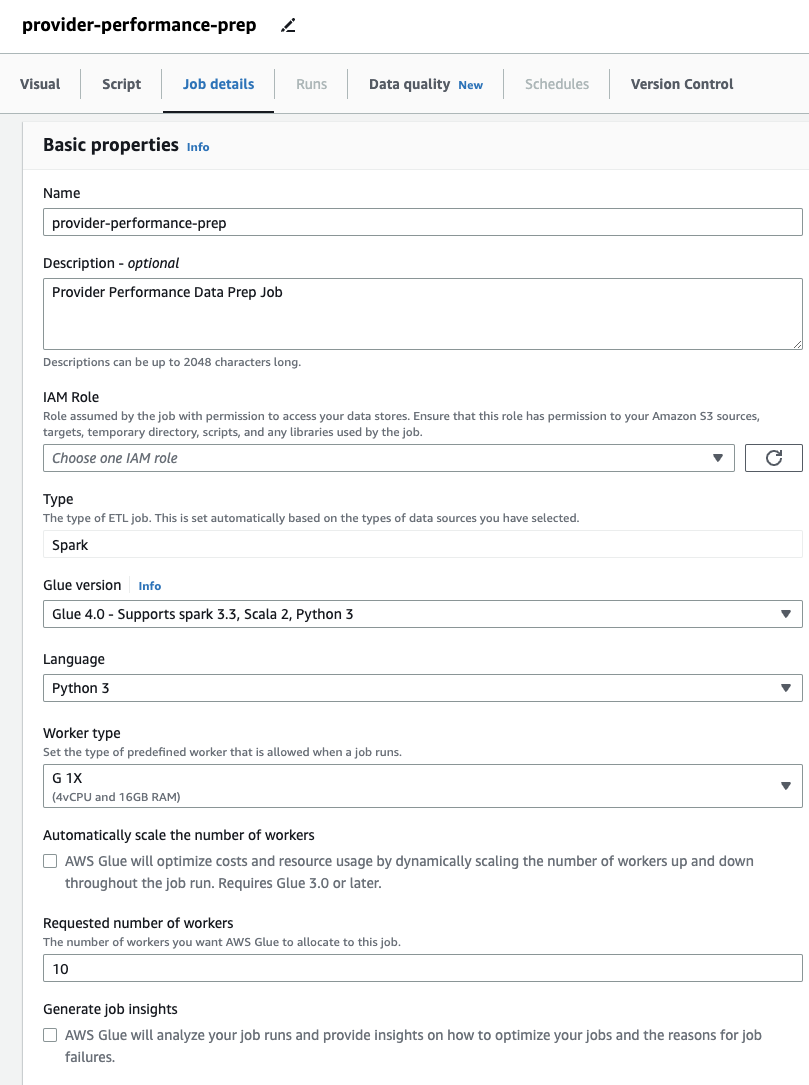
Če ste prej uporabljali samo opravila DataBrew, opazite, da lahko v AWS Glue Studio izberete nastavitve zmogljivosti in stroškov, vključno z velikostjo delavca, samodejnim skaliranjem in Prilagodljiva izvedba, kot tudi uporabo najnovejšega izvajalnega okolja AWS Glue 4.0 in izkoristite znatne izboljšave zmogljivosti, ki jih prinaša. Za to opravilo lahko uporabite privzete nastavitve, vendar zmanjšate zahtevano število delavcev zaradi varčnosti. Za ta primer bosta zadostovala dva delavca. - o Vizualni dodajte vir S3 in ga poimenujte
Providers. - za S3 URL, vnesite
s3://awsglue-datasets/examples/medicare/Medicare_Hospital_Provider.csv.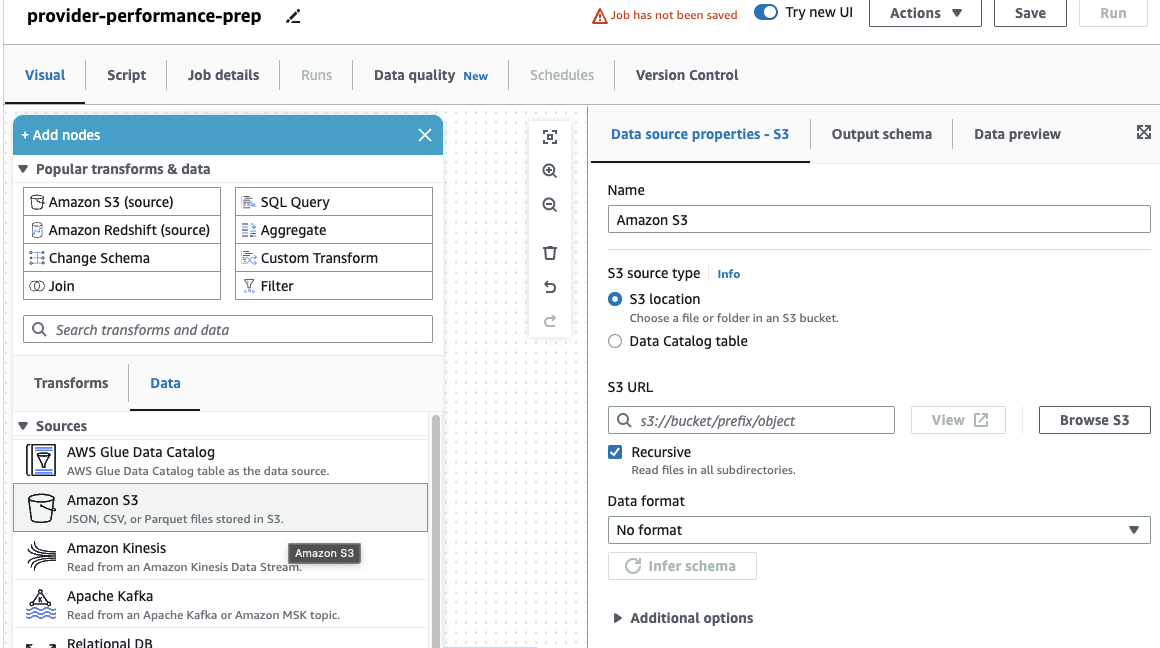
- Izberite obliko kot CSV In izberite Sklepaj shemo.
Zdaj je shema navedena na Izhodna shema z uporabo glave datoteke.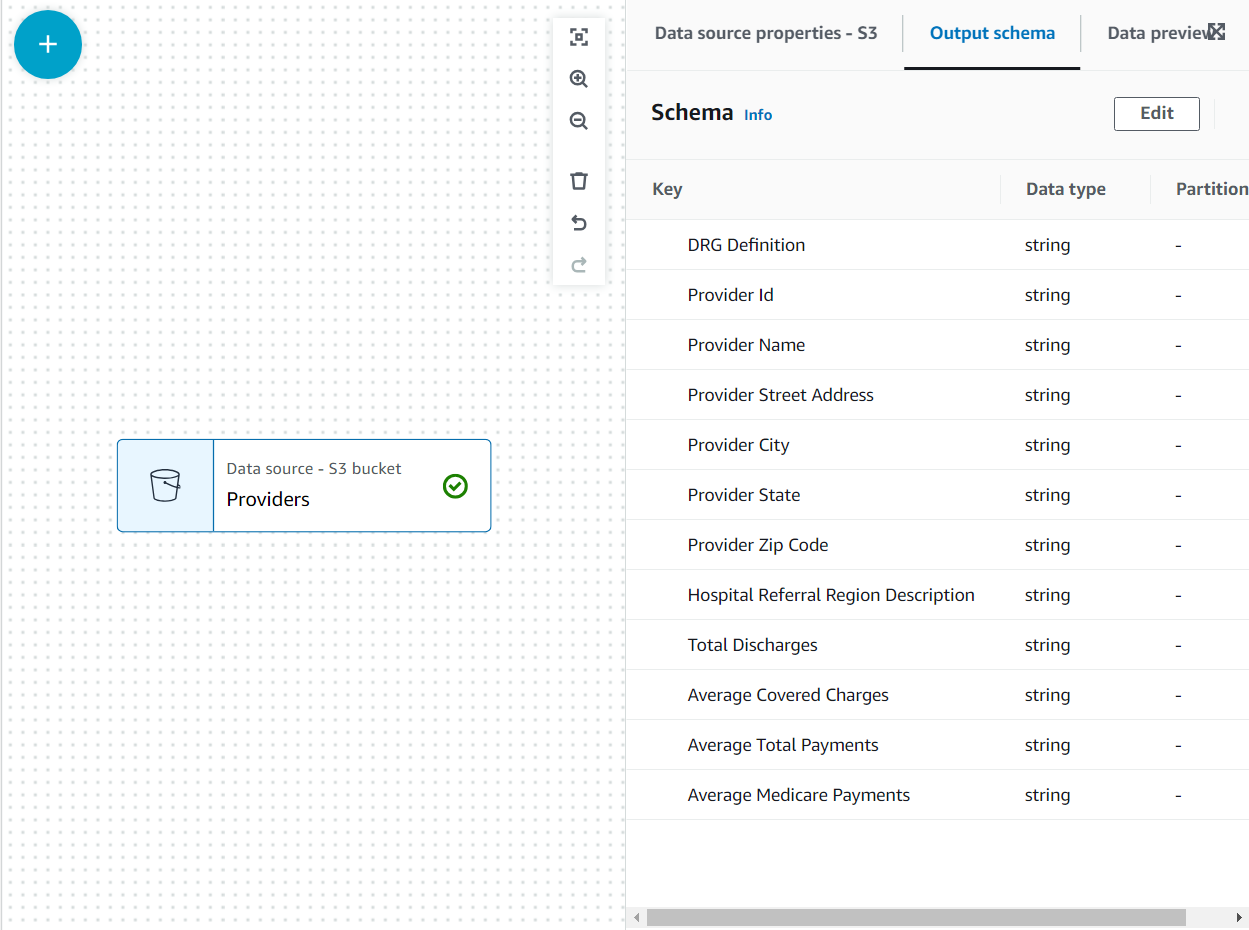
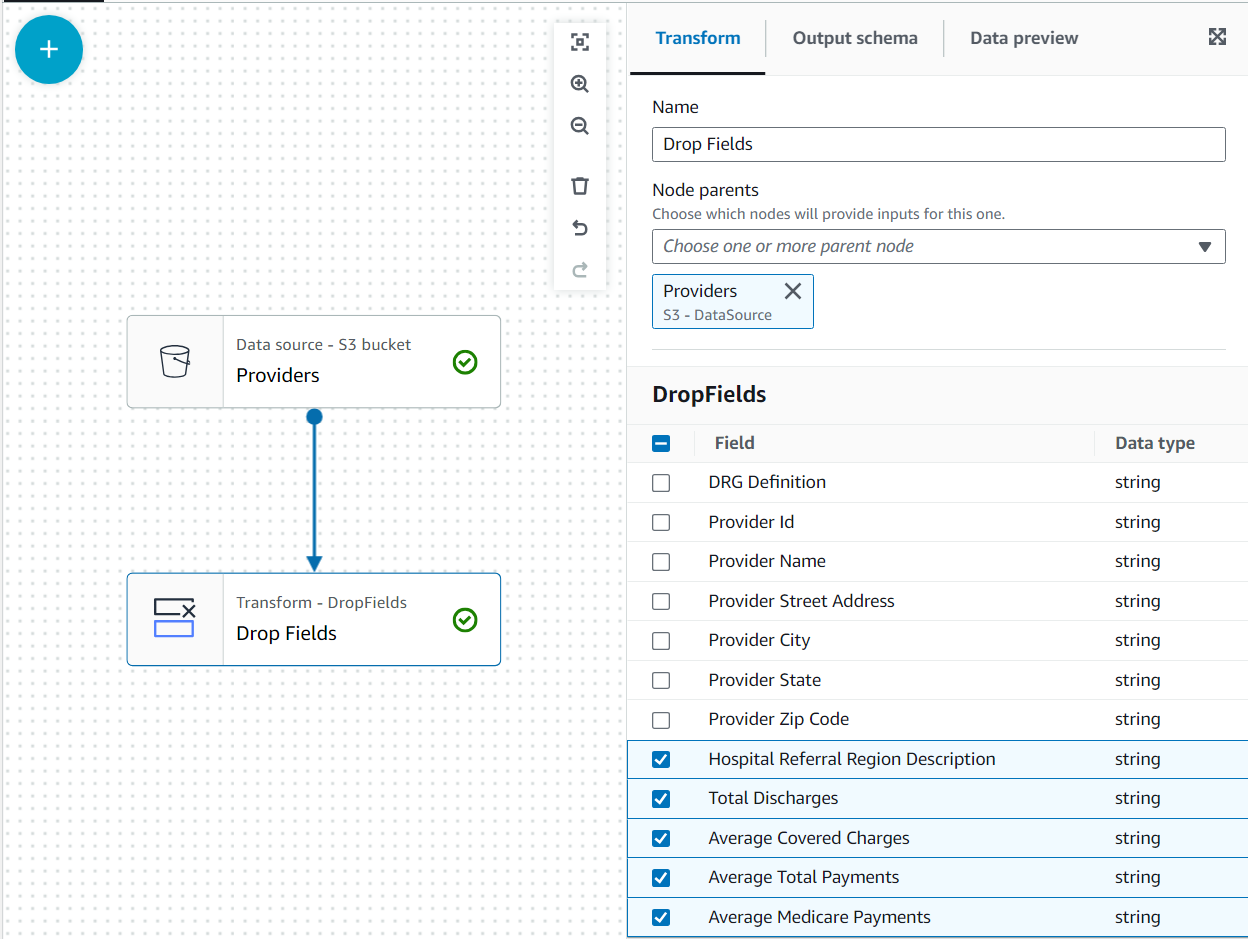
V tem primeru uporabe je odločitev takšna, da niso potrebni vsi stolpci v naboru podatkov ponudnikov, tako da lahko ostale zavržemo.
- Z Ponudniki izbrano vozlišče, dodajte a Spustite polja transform (če niste izbrali nadrejenega vozlišča, ga ne bo imelo; v tem primeru nadrejenega vozlišča dodelite ročno).
- Nato izberite vsa polja Poštna številka ponudnika.
Kasneje se bodo tem podatkom pridružili zahtevki za državo Alabama, ki uporabljajo ponudnika; vendar ta drugi nabor podatkov nima navedenega stanja. Znanje o podatkih lahko uporabimo za optimizacijo pridružitve s filtriranjem podatkov, ki jih resnično potrebujemo.
- Dodaj filter spremeniti kot otroka Spustite polja.
- Ime ga
Alabama providersin dodamo pogoj, ki mu mora ustrezati državaAL.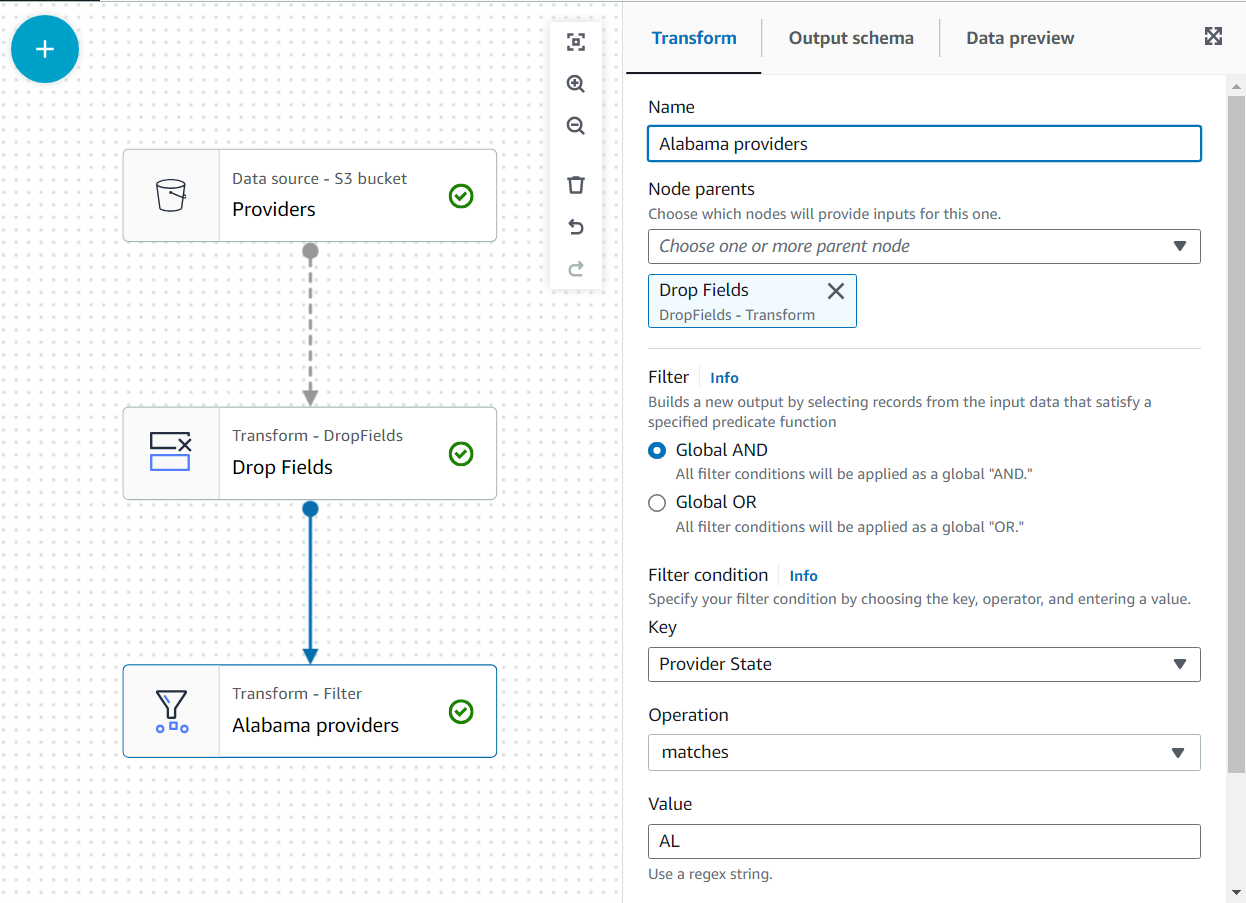
- Dodajte drugi vir (nov vir S3) in ga poimenujte
Alabama claims. - Za vstop v S3 URL, odprite DataBrew na ločenem zavihku brskalnika, v navigacijskem podoknu izberite Nabori podatkov in v tabeli kopirajte lokacijo, prikazano v tabeli za Alabama trdi (kopirajte besedilo, ki se začne s s3://, ne povezane povezave http). Nato nazaj na vizualno opravilo, ga prilepite kot S3 URL; če je pravilna, boste videli v Izhodna shema zavihkom navedena podatkovna polja.
- Izberite obliko CSV in ugotovite shemo, kot ste storili z drugim virom.
- Kot otrok tega vira iščite v Dodajte vozlišča meni za
recipeIn izberite Recept za pripravo podatkov.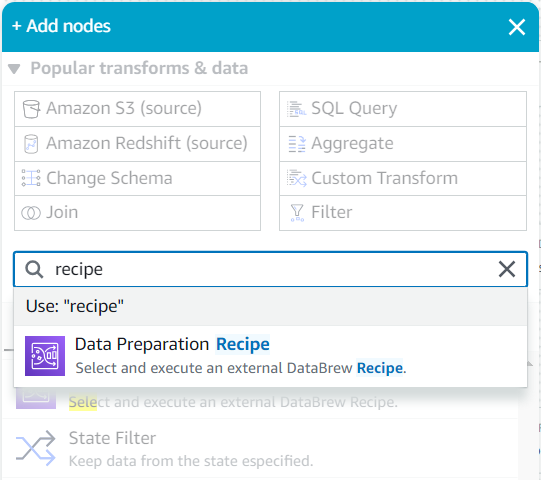
- V lastnostih tega novega vozlišča mu dajte ime
Claim cleanup recipein izberite recept in različico, ki ste jo objavili prej. - Tukaj lahko pregledate korake recepta in uporabite povezavo do DataBrew, da po potrebi spremenite.
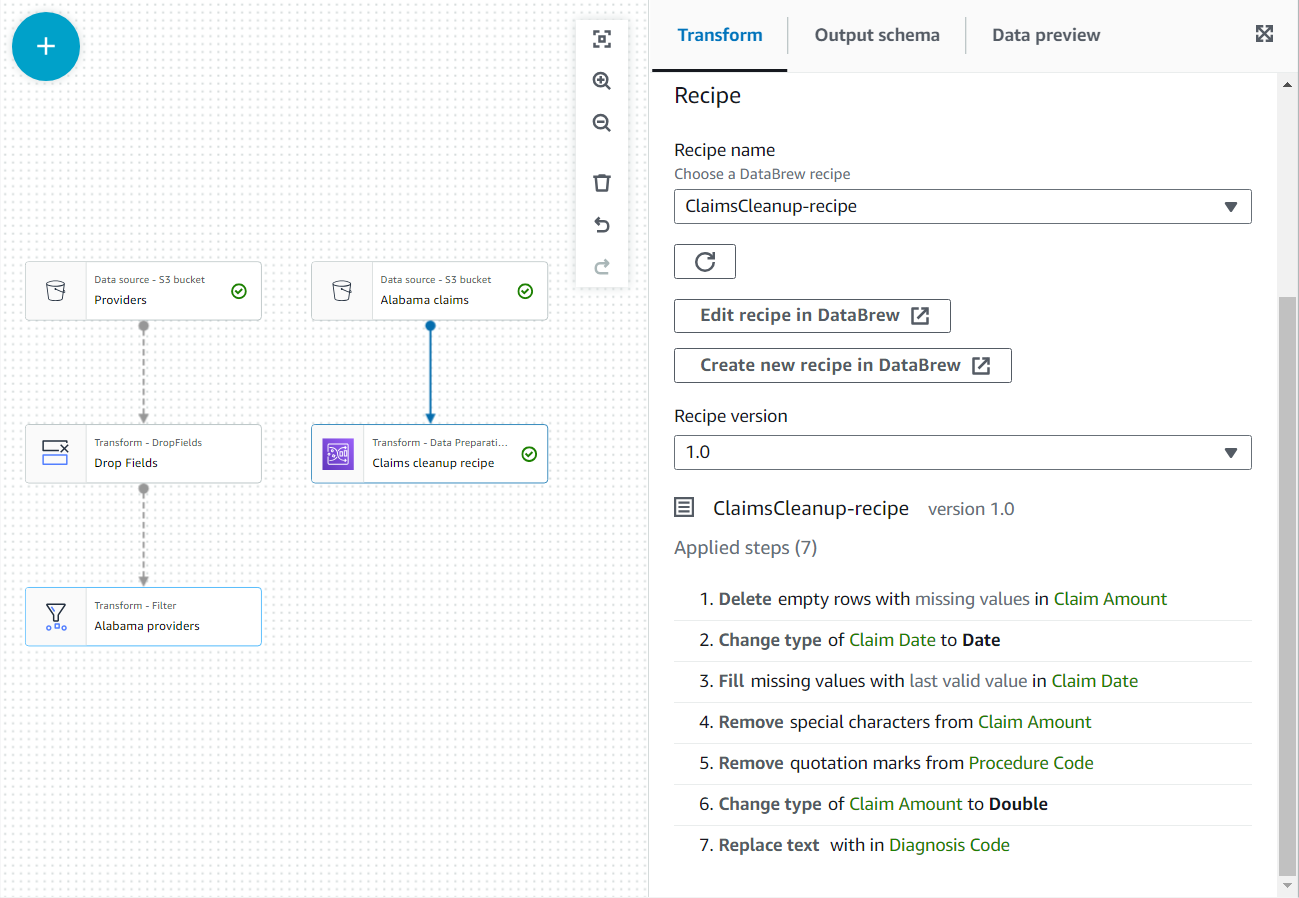
- Dodaj pridruži se vozlišče in izberite oboje Alabama ponudniki in Zahtevajte recepte za čiščenje kot starš.
- Dodajte pogoj pridružitve, ki je enak ID-ju ponudnika iz obeh virov.
- Kot zadnji korak dodajte vozlišče S3 kot cilj (upoštevajte, da je prvi naveden pri iskanju vir; poskrbite, da izberete različico, ki je navedena kot cilj).
- V konfiguraciji vozlišča pustite privzeto obliko JSON in vnesite URL S3, na katerega ima vloga službe dovoljenje za pisanje.
Poleg tega omogočite izpis podatkov kot tabelo v katalogu.
- v Možnosti posodobitve podatkovnega kataloga izberite drugo možnost Ustvarite tabelo v podatkovnem katalogu in pri naslednjih zagonih posodobite shemo in dodajte nove particije, nato izberite bazo podatkov, v kateri imate dovoljenje za ustvarjanje tabel.
- Dodeli
alabama_claimskot ime in izberite Datum zahtevka kot particijski ključ (to je za ponazoritev; majhna tabela, kot je ta, v resnici ne potrebuje particij, če nadaljnji podatki ne bodo dodani pozneje).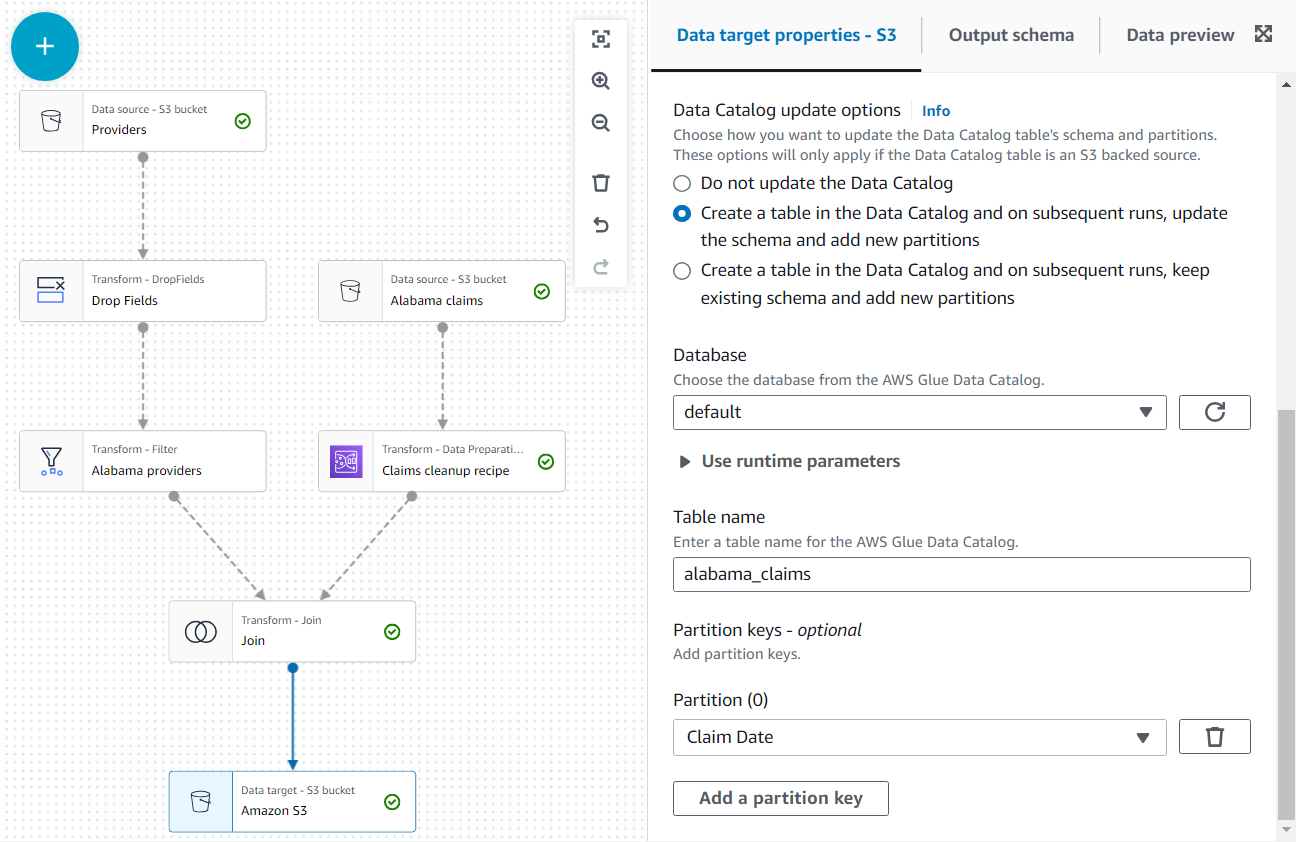
- Zdaj lahko shranite in zaženete opravilo.
- o Teče lahko spremljate postopek in si ogledate podrobne meritve opravil s povezavo ID opravila.
Opravilo naj traja nekaj minut.
- Ko je opravilo končano, se pomaknite do konzole Athena.
- Poiščite mizo
alabama_claimsv zbirki podatkov, ki ste jo izbrali, in v kontekstnem meniju izberite Predogled tabele, ki bo na tabeli zagnal preprost stavek SELECT * SQL.
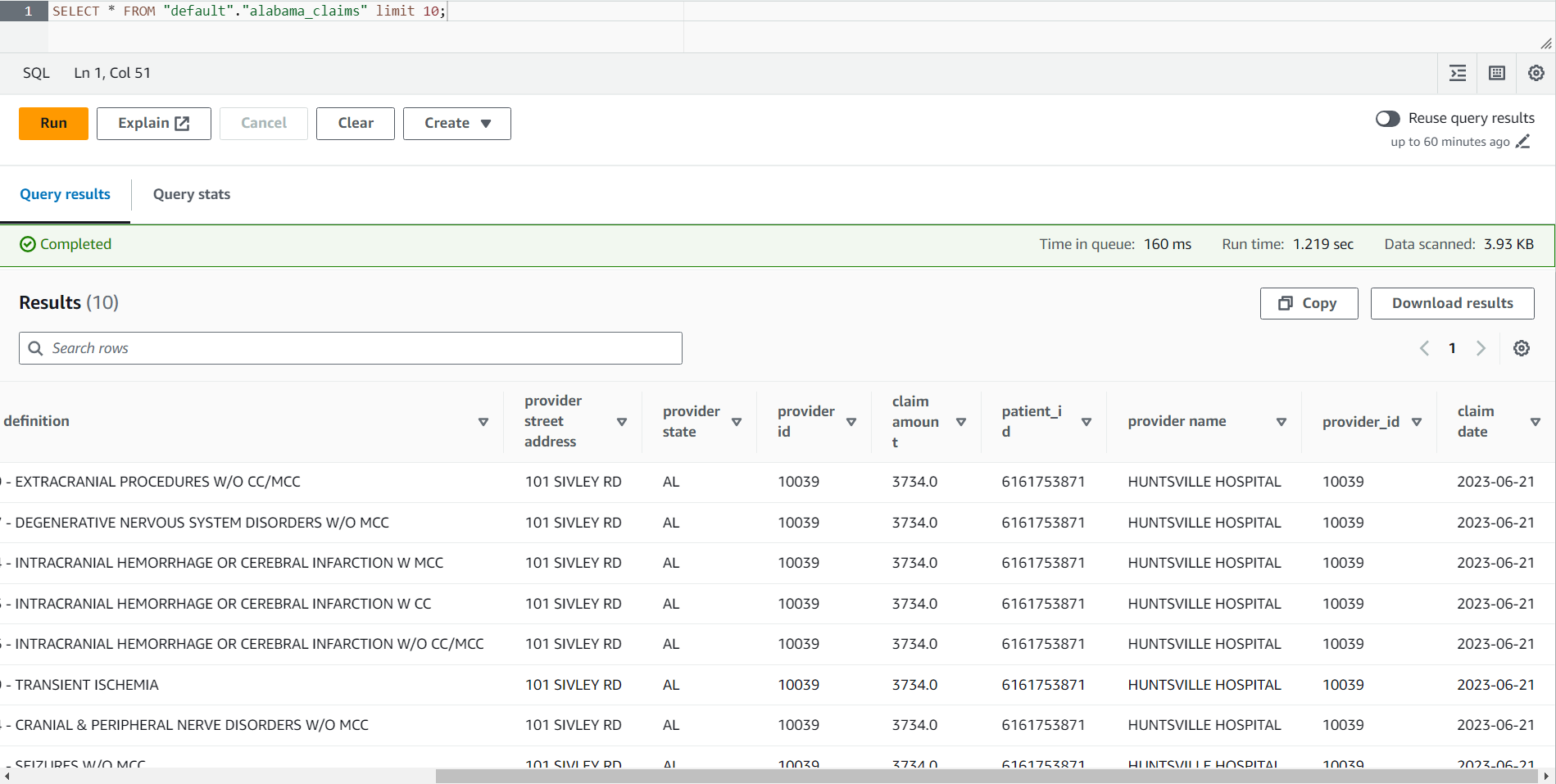
V rezultatu opravila lahko vidite, da so bili podatki očiščeni z receptom DataBrew in obogateni z združitvijo AWS Glue Studio.
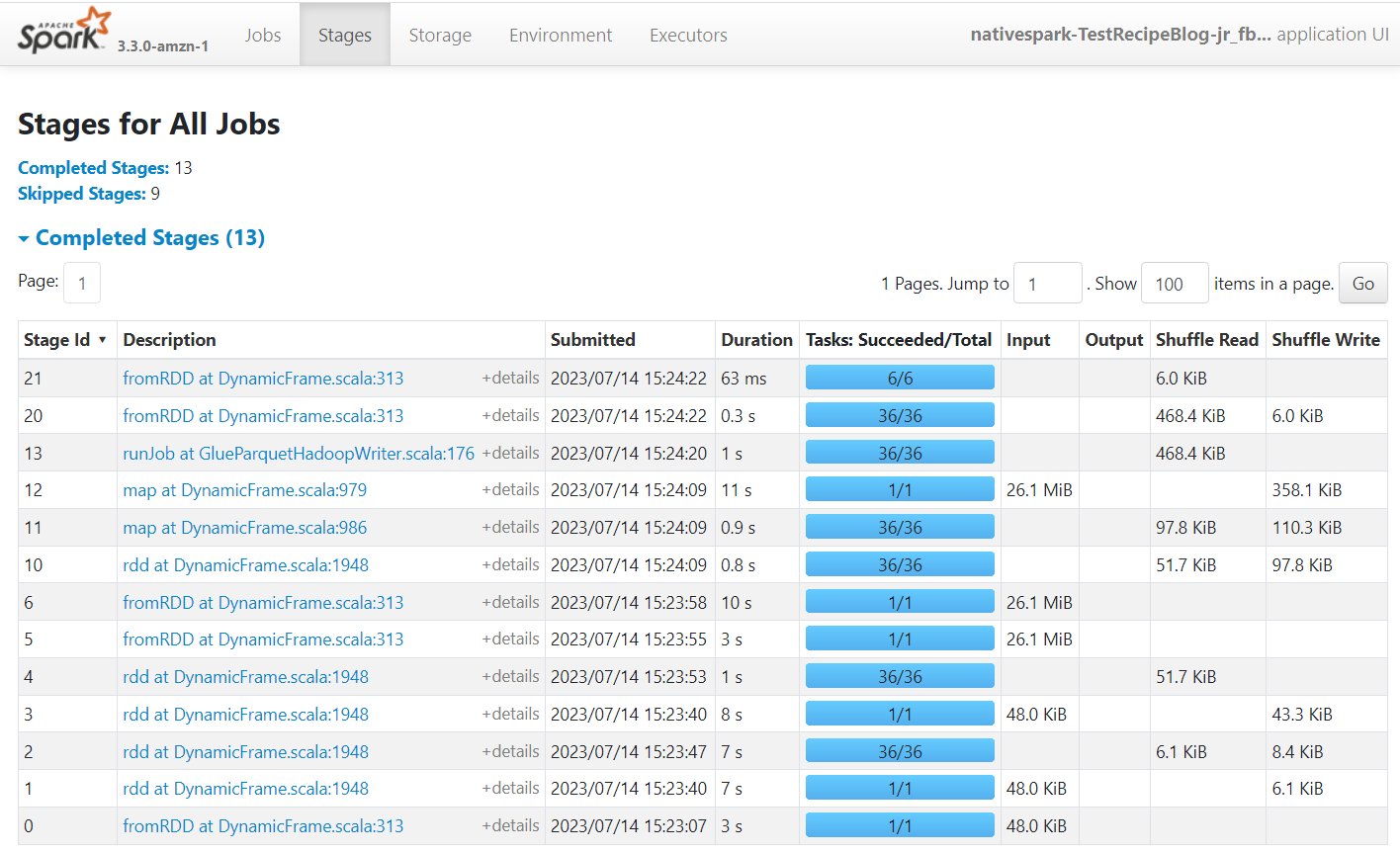
Apache Spark je motor, ki poganja delovna mesta, ustvarjena v AWS Glue Studio. Z uporabniškim vmesnikom Spark v dnevnikih dogodkov, ki jih ustvari, si lahko ogledate vpoglede v načrt opravila in zagon, kar vam lahko pomaga razumeti, kako deluje vaše delo, in morebitna ozka grla pri delovanju. Na primer, za to opravilo na velikem naboru podatkov bi ga lahko uporabili za primerjavo vpliva eksplicitnega filtriranja stanja ponudnika pred izvedbo združevanja ali ugotovili, ali vam lahko koristi dodajanje pretvorbe samodejnega ravnovesja za izboljšanje vzporednosti.
Privzeto bo opravilo shranilo dnevnike dogodkov Apache Spark pod pot s3://aws-glue-assets-<your account id>-<your region name>/sparkHistoryLogs/. Če si želite ogledati opravila, morate namestiti strežnik zgodovine z uporabo ena od razpoložljivih metod.
Čiščenje
Če te rešitve ne potrebujete več, lahko izbrišete datoteke, ustvarjene na Amazon S3, tabelo, ki jo je ustvarilo opravilo, recept DataBrew in opravilo AWS Glue.
zaključek
V tej objavi smo pokazali, kako lahko uporabite AWS DataBrew za ustvarjanje recepta s priloženim interaktivnim urejevalnikom in nato uporabite objavljeni recept kot del vizualnega ETL opravila AWS Glue Studio. Vključili smo nekaj primerov običajnih opravil, ki so potrebna pri pripravi podatkov in vnašanju podatkov v tabele AWS Glue Catalog.
Ta primer je uporabil en sam recept v vizualnem opravilu, vendar je mogoče uporabiti več receptov v različnih delih procesa ETL, pa tudi ponovno uporabiti isti recept pri več opravilih.
Te rešitve AWS Glue vam omogočajo učinkovito ustvarjanje naprednih cevovodov ETL, ki jih je enostavno zgraditi in vzdrževati, vse brez pisanja kode. Že danes lahko začnete ustvarjati rešitve, ki združujejo obe orodji.
O avtorjih
 Mihail Smirnov je starejši razvijalec programske opreme v skupini AWS Glue in del razvojne ekipe AWS Glue DataBrew. Zunaj službe ga zanima učenje igranja kitare in potovanja z družino.
Mihail Smirnov je starejši razvijalec programske opreme v skupini AWS Glue in del razvojne ekipe AWS Glue DataBrew. Zunaj službe ga zanima učenje igranja kitare in potovanja z družino.
 Gonzalo Herreros je starejši arhitekt velikih podatkov v skupini AWS Glue. S sedežem v Dublinu na Irskem pomaga strankam uspeti z rešitvami za velike količine podatkov, ki temeljijo na AWS Glue. V prostem času se ukvarja z družabnimi igrami in kolesari.
Gonzalo Herreros je starejši arhitekt velikih podatkov v skupini AWS Glue. S sedežem v Dublinu na Irskem pomaga strankam uspeti z rešitvami za velike količine podatkov, ki temeljijo na AWS Glue. V prostem času se ukvarja z družabnimi igrami in kolesari.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Avtomobili/EV, Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- BlockOffsets. Posodobitev okoljskega offset lastništva. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/use-aws-glue-databrew-recipes-in-your-aws-glue-studio-visual-etl-jobs/
- :ima
- : je
- :ne
- $GOR
- 10
- 100
- 12
- 15%
- 20
- 200
- 22
- 26
- 28
- 500
- 7
- 8
- a
- Sposobna
- O meni
- sprejemljiv
- sprejeta
- dostop
- Račun
- Ukrep
- dejanska
- dodajte
- dodano
- dodajanje
- Poleg tega
- Naslov
- napredno
- po
- Alabama
- vsi
- omogočajo
- Prav tako
- Amazon
- Amazon Web Services
- zneski
- an
- Analitiki
- in
- kaj
- Apache
- Apache Spark
- uporaba
- Uporabi
- SE
- AS
- povezan
- At
- Avtor
- avto
- Samodejno
- Na voljo
- AWS
- AWS lepilo
- nazaj
- temeljijo
- BE
- pred
- počutje
- koristi
- Prednosti
- Big
- Big Podatki
- prazno
- svet
- Namizne igre
- zaznamki
- tako
- Prinaša
- brskalnik
- izgradnjo
- vendar
- by
- CAN
- Zmogljivosti
- primeru
- Katalog
- Celice
- centralizirano
- spremenite
- Spremembe
- znaki
- otrok
- izbira
- Izberite
- trdijo
- terjatve
- Koda
- Stolpec
- Stolpci
- združujejo
- prihajajo
- Skupno
- primerjate
- dokončanje
- deli
- računalnik
- stanje
- konfiguracija
- Razmislite
- vsebuje
- Konzole
- ozadje
- pretvorbo
- pretvori
- popravi
- Ustrezno
- strošek
- bi
- ustvarjajo
- ustvaril
- Ustvarjanje
- Oblikovanje
- po meri
- Stranke, ki so
- datum
- Priprava podatkov
- obdelava podatkov
- kakovosti podatkov
- Baze podatkov
- nabor podatkov
- Datum
- Termini
- dan
- ponudba
- odloča
- Odločitev
- privzeto
- izkazati
- opis
- želeno
- podrobno
- Podrobnosti
- dev
- Razvoj
- razvojna ekipa
- DID
- drugačen
- izrazit
- distribucija
- do
- Ne
- tem
- Dollar
- podvojila
- Drop
- dublin
- vsak
- lahka
- urednik
- učinek
- učinkovito
- omogoča
- konec
- Motor
- inženir
- obogatena
- bogatenje
- Vnesite
- Napaka
- bistvena
- Eter (ETH)
- oceniti
- Tudi
- Event
- Tudi vsak
- vsak dan
- Primer
- Primeri
- obstoječih
- dodatna
- ekstrakt
- družina
- daleč
- Lastnosti
- Nekaj
- Področja
- file
- datoteke
- izpolnite
- filter
- filtriranje
- končno
- prva
- sledili
- po
- za
- format
- iz
- nadalje
- Games
- ustvarila
- Daj
- več
- Imajo
- he
- pomoč
- Pomaga
- tukaj
- njegov
- zgodovina
- Kako
- Kako
- Vendar
- HTML
- http
- HTTPS
- IAM
- ID
- identificirati
- identificirati
- identiteta
- if
- vpliv
- izboljšanje
- Izboljšave
- in
- vključujejo
- vključeno
- Vključno
- naveden
- vhod
- vpogledi
- namestitev
- primer
- integrirana
- integracija
- interaktivno
- obresti
- interesi
- vmesnik
- v
- Uvedeno
- intuitivno
- Irska
- Vprašanja
- IT
- ITS
- Job
- Delovna mesta
- pridružite
- pridružil
- jpg
- json
- samo
- Imejte
- Ključne
- znanje
- velika
- večja
- Največji
- Zadnja
- pozneje
- Zadnji
- učenje
- pustite
- kot
- Verjeten
- LINK
- Navedeno
- obremenitev
- kraj aktivnosti
- Logika
- več
- vzdrževati
- Znamka
- IZDELA
- ročno
- Stave
- medicinski
- Meni
- Metoda
- Metode
- Meritve
- min
- manjka
- monitor
- več
- več
- morajo
- Ime
- Krmarjenje
- ostalo
- Nimate
- potrebna
- potrebe
- Novo
- št
- Vozel
- Opaziti..
- zdaj
- Številka
- of
- on
- ONE
- samo
- odprite
- Optimizirajte
- Možnost
- možnosti
- or
- Da
- Ostalo
- naši
- izhod
- zunaj
- več
- Splošni
- podokno
- del
- deli
- pot
- performance
- izvajati
- Dovoljenje
- Dovoljenja
- Načrt
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Predvajaj
- mogoče
- Prispevek
- potencial
- Priprava
- predogled
- Predogledi
- Postopek
- obravnavati
- proizvaja
- Projekt
- Lastnosti
- če
- Ponudnik
- ponudniki
- zagotavlja
- Objava
- objavijo
- objavljeno
- Namen
- namene
- kakovost
- kotacije
- res
- razumno
- Recept
- Recepti
- zmanjša
- odražajo
- okolica
- registracijo
- pomembno
- odstrani
- zamenjajte
- zahtevano
- obvezna
- zahteva
- oziroma
- REST
- povzroči
- Rezultati
- ponovna
- pregleda
- vloga
- Run
- deluje
- Enako
- Shrani
- Lestvica
- skaliranje
- Iskalnik
- drugi
- Oddelek
- glej
- videnje
- izbran
- ločena
- Storitve
- Zasedanje
- nastavite
- nastavitve
- shouldnt
- je pokazala,
- pokazale
- podpisati
- pomemben
- Enostavno
- sam
- Velikosti
- majhna
- So
- doslej
- Software
- Rešitev
- rešitve
- nekaj
- vir
- Viri
- Vesolje
- Spark
- posebna
- specifična
- določeno
- SQL
- Začetek
- Začetek
- Država
- Izjava
- Statistika
- Korak
- Koraki
- shranjevanje
- trgovina
- naravnost
- String
- studio
- kasneje
- uspeh
- taka
- primerna
- POVZETEK
- Preverite
- sintetična
- miza
- Bodite
- ciljna
- Naloge
- skupina
- Testiran
- da
- O
- Vir
- Država
- Njih
- POTEM
- Tukaj.
- ta
- 3
- čas
- do
- danes
- orodje
- orodja
- vrh
- sledenje
- Transform
- Preoblikovanje
- transformacije
- Potovanje
- dva
- tip
- ui
- pod
- razumeli
- Nadgradnja
- posodobljeno
- URL
- uporabno
- uporaba
- primeru uporabe
- Rabljeni
- Uporabniki
- uporablja
- uporabo
- POTRDI
- vrednost
- Vrednote
- preverjanje
- različica
- Poglej
- vidna
- želeli
- je
- načini
- we
- web
- spletne storitve
- Dobro
- so bili
- kdaj
- ki
- bo
- z
- brez
- delo
- delavec
- delavci
- potek dela
- bi
- pisati
- pisanje
- jo
- Vaša rutina za
- zefirnet
- Zip