V tej objavi prikazujemo, kako uporabiti strukturno obrezovanje na podlagi iskanja po nevronski arhitekturi (NAS) za stiskanje natančno nastavljenega modela BERT za izboljšanje zmogljivosti modela in skrajšanje časa sklepanja. Vnaprej pripravljeni jezikovni modeli (PLM) se hitro uveljavljajo v komerciali in podjetjih na področjih orodij za produktivnost, storitev za stranke, iskanja in priporočil, avtomatizacije poslovnih procesov in ustvarjanja vsebin. Uvajanje končnih točk sklepanja PLM je običajno povezano z večjo zakasnitvijo in višjimi stroški infrastrukture zaradi računalniških zahtev in zmanjšane računalniške učinkovitosti zaradi velikega števila parametrov. Obrezovanje PLM zmanjša velikost in kompleksnost modela, hkrati pa ohrani njegove napovedne zmožnosti. Obrezani PLM-ji dosegajo manjši pomnilniški odtis in manjšo zakasnitev. To dokazujemo z obrezovanjem PLM in trgovanjem s številom parametrov in napako pri preverjanju za določeno ciljno nalogo ter lahko dosežemo hitrejše odzivne čase v primerjavi z osnovnim modelom PLM.
Optimizacija z več cilji je področje odločanja, ki optimizira več kot eno ciljno funkcijo, kot so poraba pomnilnika, čas usposabljanja in računalniški viri, ki jih je treba optimizirati hkrati. Strukturno obrezovanje je tehnika za zmanjšanje velikosti in računalniških zahtev PLM z obrezovanjem plasti ali nevronov/vozlišč, hkrati pa poskuša ohraniti natančnost modela. Z odstranjevanjem plasti strukturno obrezovanje doseže višje stopnje stiskanja, kar vodi do strojne opreme prijazne strukturirane redkosti, ki skrajša čas izvajanja in odzivne čase. Uporaba tehnike strukturnega obrezovanja za model PLM ima za posledico lažji model z manjšim pomnilniškim odtisom, ki, ko ga gosti kot končna točka sklepanja v SageMakerju, nudi izboljšano učinkovitost virov in nižje stroške v primerjavi z izvirnim natančno nastavljenim PLM.
Koncepte, prikazane v tej objavi, je mogoče uporabiti za aplikacije, ki uporabljajo funkcije PLM, kot so sistemi priporočil, analiza razpoloženja in iskalniki. Natančneje, ta pristop lahko uporabite, če imate namenske skupine za strojno učenje (ML) in podatkovne znanosti, ki natančno prilagajajo svoje lastne modele PLM z uporabo naborov podatkov, specifičnih za domeno, in uvajajo veliko število končnih točk sklepanja z uporabo Amazon SageMaker. En primer je spletni trgovec na drobno, ki uporablja veliko število končnih točk sklepanja za povzemanje besedila, klasifikacijo kataloga izdelkov in klasifikacijo povratnih informacij o izdelkih. Drug primer je lahko ponudnik zdravstvenega varstva, ki uporablja končne točke sklepanja PLM za klasifikacijo kliničnih dokumentov, prepoznavanje imenovanih entitet iz zdravstvenih poročil, zdravstvenih klepetalnih robotov in stratifikacijo tveganja za paciente.
Pregled rešitev
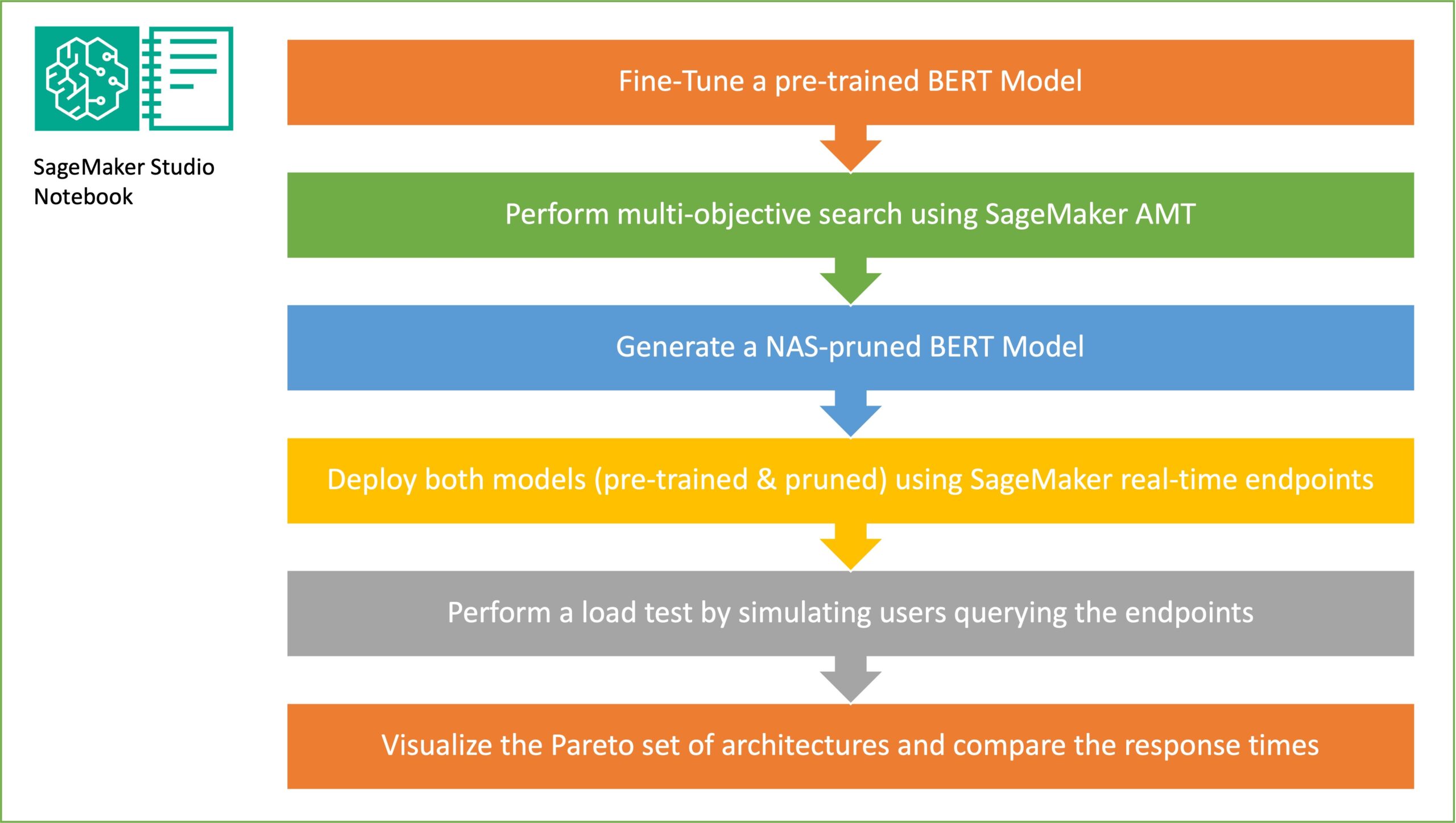
V tem razdelku predstavljamo celoten potek dela in razlagamo pristop. Najprej uporabimo an Amazon SageMaker Studio prenosnik za natančno nastavitev vnaprej usposobljenega modela BERT na ciljni nalogi z uporabo nabora podatkov, specifičnega za domeno. BERTI (Bidirectional Encoder Representations from Transformers) je vnaprej pripravljen jezikovni model, ki temelji na transformatorska arhitektura uporablja se za naloge obdelave naravnega jezika (NLP). Iskanje po nevronski arhitekturi (NAS) je pristop za avtomatizacijo načrtovanja umetnih nevronskih mrež in je tesno povezan z optimizacijo hiperparametrov, ki je široko uporabljen pristop na področju strojnega učenja. Cilj NAS je najti optimalno arhitekturo za dano težavo z iskanjem po velikem naboru kandidatnih arhitektur z uporabo tehnik, kot je optimizacija brez gradientov ali z optimizacijo želenih metrik. Učinkovitost arhitekture se običajno meri z metrikami, kot je izguba validacije. Samodejno prilagajanje modela SageMaker (AMT) avtomatizira dolgočasen in zapleten proces iskanja optimalnih kombinacij hiperparametrov modela ML, ki dajejo najboljšo zmogljivost modela. AMT uporablja inteligentne iskalne algoritme in iterativne ocene z uporabo niza hiperparametrov, ki jih določite. Izbere vrednosti hiperparametrov, ki ustvarijo model, ki deluje najbolje, kot se meri z metrikami uspešnosti, kot sta natančnost in rezultat F-1.
Pristop natančnega prilagajanja, opisan v tej objavi, je splošen in ga je mogoče uporabiti za kateri koli nabor podatkov, ki temelji na besedilu. Naloga, dodeljena BERT PLM, je lahko besedilna naloga, kot je analiza razpoloženja, klasifikacija besedila ali vprašanja in odgovori. V tej predstavitvi je ciljna naloga problem binarne klasifikacije, kjer se BERT uporablja za identifikacijo iz nabora podatkov, ki je sestavljen iz zbirke parov besedilnih fragmentov, ali je pomen enega besedilnega fragmenta mogoče sklepati iz drugega fragmenta. Uporabljamo Prepoznavanje nabora podatkov Textual Entailment iz zbirke primerjalnih analiz GLUE. Izvajamo iskanje z več cilji z uporabo SageMaker AMT, da identificiramo podomrežja, ki ponujajo optimalne kompromise med številom parametrov in natančnostjo napovedi za ciljno nalogo. Ko izvajamo iskanje z več cilji, začnemo z opredelitvijo natančnosti in števila parametrov kot ciljev, ki jih želimo optimizirati.
Znotraj omrežja BERT PLM so lahko modularna, samostojna podomrežja, ki modelu omogočajo specializirane zmogljivosti, kot sta razumevanje jezika in predstavitev znanja. BERT PLM uporablja večglavno podomrežje samopozornosti in podomrežje za naprej. Večglavna plast samopozornosti omogoča BERT-u, da poveže različne položaje enega samega zaporedja, da izračuna predstavitev zaporedja, tako da omogoči več glavam, da spremljajo več kontekstnih signalov. Vnos je razdeljen na več podprostorov in samopozornost se uporabi za vsakega od podprostorov posebej. Več glav v transformatorskem PLM omogoča modelu, da skupaj spremlja informacije iz različnih podprostorov predstavitve. Naprejšnje podomrežje je preprosta nevronska mreža, ki vzame izhod iz večglavnega podomrežja samopozornosti, obdela podatke in vrne končne predstavitve kodirnika.
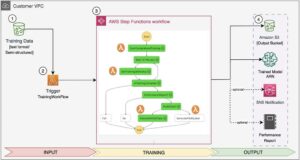
Cilj naključnega vzorčenja podomrežja je usposobiti manjše modele BERT, ki se lahko dovolj dobro obnesejo pri ciljnih nalogah. Vzorčimo 100 naključnih podomrežij iz natančno nastavljenega osnovnega modela BERT in hkrati ocenjujemo 10 omrežij. Usposobljena podomrežja se ovrednotijo glede na objektivne metrike in končni model se izbere na podlagi kompromisov, ugotovljenih med objektivnimi metrikami. Vizualiziramo, Pareto spredaj za vzorčena podomrežja, ki vsebuje skrajšani model, ki ponuja optimalen kompromis med natančnostjo modela in velikostjo modela. Izberemo kandidatno podomrežje (model BERT s skrajšanim NAS) na podlagi velikosti modela in natančnosti modela, s katerima smo pripravljeni trgovati. Nato gostimo končne točke, vnaprej pripravljen osnovni model BERT in model BERT, zmanjšan za NAS, z uporabo SageMakerja. Za izvajanje obremenitvenega testiranja uporabljamo Locust, odprtokodno orodje za testiranje obremenitve, ki ga lahko implementirate s Pythonom. Izvajamo obremenitveno testiranje na obeh končnih točkah z uporabo Locusta in vizualiziramo rezultate z uporabo Pareto fronte, da ponazorimo kompromis med odzivnimi časi in natančnostjo za oba modela. Naslednji diagram ponuja pregled poteka dela, razloženega v tej objavi.
Predpogoji
Za to delovno mesto so potrebni naslednji predpogoji:
Prav tako morate povečati servisna kvota za dostop do vsaj treh primerkov ml.g4dn.xlarge v SageMakerju. Vrsta primerka ml.g4dn.xlarge je stroškovno učinkovit primerek GPU, ki vam omogoča izvorno izvajanje PyTorcha. Če želite povečati kvoto storitev, izvedite naslednje korake:
- Na konzoli se pomaknite do storitvenih kvot.
- za Upravljajte kvote, izberite Amazon SageMaker, nato izberite Ogled kvot.

- Poiščite »ml-g4dn.xlarge for training job usage« in izberite element kvote.
- Izberite Zahtevajte povečanje na ravni računa.
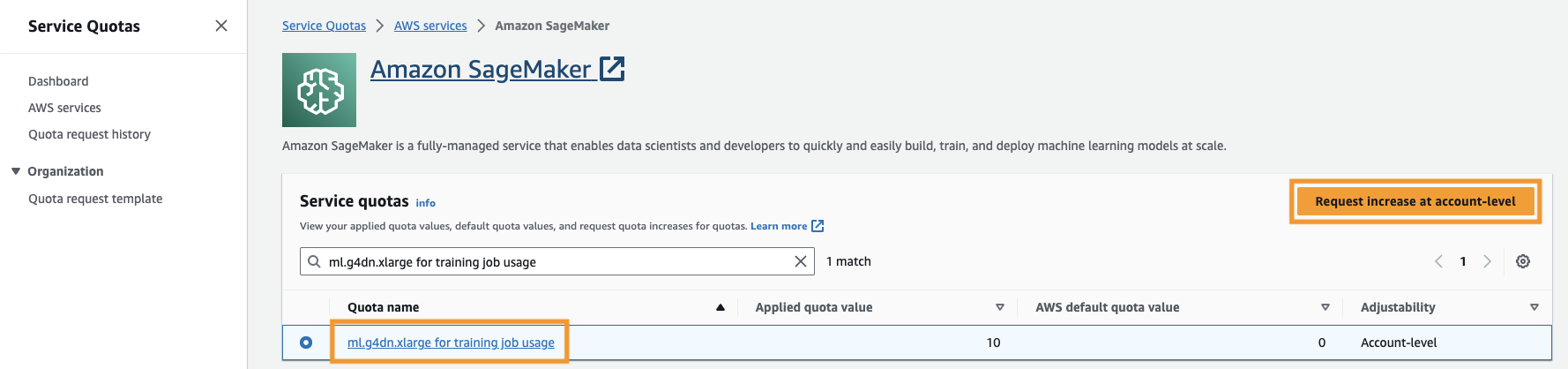
- za Povečajte vrednost kvote, vnesite vrednost 5 ali več.
- Izberite Zahteva.
Odobritev zahtevane kvote lahko traja nekaj časa, odvisno od dovoljenj računa.

- Odprite SageMaker Studio na konzoli SageMaker.

- Izberite Sistemski terminal pod Pripomočki in datoteke.

- Zaženite naslednji ukaz, da klonirate GitHub repo na instanco SageMaker Studio:
- Pomaknite se na
amazon-sagemaker-examples/hyperparameter_tuning/neural_architecture_search_llm. - Odprite datoteko
nas_for_llm_with_amt.ipynb. - Nastavite okolje z an
ml.g4dn.xlargeprimerek in izberite Izberite.

Nastavite predhodno usposobljen model BERT
V tem razdelku uvozimo nabor podatkov Recognizing Textual Entailment iz knjižnice nabora podatkov in nabor podatkov razdelimo na nabore za usposabljanje in preverjanje. Ta niz podatkov je sestavljen iz parov stavkov. Naloga BERT PLM je, da glede na dva fragmenta besedila prepozna, ali je pomen enega fragmenta besedila mogoče razbrati iz drugega fragmenta. V naslednjem primeru lahko sklepamo na pomen prve fraze iz druge fraze:
Naložimo nabor podatkov o vsebini za prepoznavanje besedila iz LEPILO nabor za primerjalno analizo prek knjižnica nabora podatkov iz Hugging Face v našem skriptu za usposabljanje (./training.py). Prvotni nabor podatkov za usposabljanje iz GLUE smo razdelili na nabor za usposabljanje in validacijo. V našem pristopu natančno prilagodimo osnovni model BERT z uporabo nabora podatkov o usposabljanju, nato izvedemo iskanje z več cilji, da prepoznamo nabor podomrežij, ki optimalno uravnotežijo objektivne metrike. Nabor podatkov o usposabljanju uporabljamo izključno za natančno nastavitev modela BERT. Vendar pa podatke o validaciji uporabljamo za iskanje z več cilji z merjenjem natančnosti na naboru podatkov za preverjanje zadržanosti.
Natančno prilagodite BERT PLM z uporabo nabora podatkov, specifičnega za domeno
Tipični primeri uporabe neobdelanega modela BERT vključujejo predvidevanje naslednjega stavka ali modeliranje maskiranega jezika. Za uporabo osnovnega modela BERT za naloge na nižji stopnji, kot je vključitev prepoznavanja besedila, moramo model še natančneje prilagoditi z naborom podatkov, specifičnim za domeno. Natančno nastavljen model BERT lahko uporabite za naloge, kot je klasifikacija zaporedja, odgovarjanje na vprašanja in klasifikacija žetonov. Vendar pa za namene te predstavitve uporabljamo natančno nastavljen model za binarno klasifikacijo. Vnaprej usposobljeni model BERT natančno prilagodimo z naborom podatkov za usposabljanje, ki smo ga predhodno pripravili, z uporabo naslednjih hiperparametrov:
Kontrolno točko usposabljanja modela shranimo v an Preprosta storitev shranjevanja Amazon (Amazon S3), tako da je mogoče model naložiti med iskanjem z več cilji na osnovi NAS. Preden usposobimo model, definiramo metrike, kot so epoha, izguba pri urjenju, število parametrov in napaka pri validaciji:
Ko se začne postopek natančnega prilagajanja, traja približno 15 minut usposabljanja.
Izvedite iskanje z več cilji, da izberete podomrežja in vizualizirate rezultate
V naslednjem koraku izvedemo iskanje z več cilji na natančno nastavljenem osnovnem modelu BERT z vzorčenjem naključnih podomrežij z uporabo SageMaker AMT. Za dostop do podomrežja znotraj super-omrežja (natančno nastavljen model BERT) maskiramo vse komponente PLM, ki niso del podomrežja. Maskiranje super-omrežja za iskanje podomrežij v PLM je tehnika, ki se uporablja za izolacijo in prepoznavanje vzorcev obnašanja modela. Upoštevajte, da transformatorji Hugging Face potrebujejo skrito velikost, ki je večkratnik števila glav. Skrita velikost v transformatorskem PLM nadzoruje velikost vektorskega prostora skritega stanja, kar vpliva na sposobnost modela, da se nauči kompleksnih predstavitev in vzorcev v podatkih. V BERT PLM je skriti vektor stanja fiksne velikosti (768). Skrite velikosti ne moremo spremeniti, zato mora biti število glav v [1, 3, 6, 12].
V nasprotju z optimizacijo z enim ciljem pri nastavitvi z več cilji običajno nimamo ene rešitve, ki bi hkrati optimizirala vse cilje. Namesto tega želimo zbrati nabor rešitev, ki prevladujejo nad vsemi drugimi rešitvami v vsaj enem cilju (kot je napaka pri preverjanju). Zdaj lahko začnemo iskanje z več cilji prek AMT z nastavitvijo metrik, ki jih želimo zmanjšati (napaka pri preverjanju in število parametrov). Naključna podomrežja so definirana s parametrom max_jobs in število hkratnih opravil je določeno s parametrom max_parallel_jobs. Koda za nalaganje kontrolne točke modela in ovrednotenje podomrežja je na voljo v evaluate_subnetwork.py skripta.
Posel nastavitve AMT traja približno 2 uri in 20 minut. Ko se opravilo nastavitve AMT uspešno izvede, razčlenimo zgodovino opravila in zberemo konfiguracije podomrežja, kot so število glav, število plasti, število enot in ustrezne metrike, kot sta napaka pri preverjanju in število parametrov. Naslednji posnetek zaslona prikazuje povzetek uspešnega opravila sprejemnika AMT.
Nato vizualiziramo rezultate z uporabo Paretovega nabora (znanega tudi kot Paretova meja ali Paretov optimalni nabor), ki nam pomaga prepoznati optimalne nabore podomrežij, ki prevladujejo nad vsemi drugimi podomrežji v objektivni metriki (napaka pri preverjanju):
Najprej zberemo podatke iz opravila nastavitve AMT. Nato narišemo Paretovo množico z uporabo matplotlob.pyplot s številom parametrov na osi x in napako pri validaciji na osi y. To pomeni, da moramo, ko se premaknemo iz enega podomrežja Paretovega nabora v drugo, bodisi žrtvovati zmogljivost ali velikost modela, drugo pa izboljšati. Navsezadnje nam Paretov nabor omogoča prilagodljivost pri izbiri podomrežja, ki najbolj ustreza našim željam. Lahko se odločimo, koliko želimo zmanjšati velikost našega omrežja in koliko zmogljivosti smo pripravljeni žrtvovati.

Namestite natančno nastavljen model BERT in model podomrežja, optimiziran za NAS, s pomočjo SageMakerja
Nato uvedemo največji model v našem Paretovem naboru, ki vodi do najmanjše stopnje degeneracije zmogljivosti Končna točka SageMaker. Najboljši model je tisti, ki zagotavlja optimalen kompromis med napako pri preverjanju in številom parametrov za naš primer uporabe.
Primerjava modelov
Vzeli smo predhodno usposobljen osnovni model BERT, ga natančno prilagodili z naborom podatkov, specifičnim za domeno, zagnali iskanje NAS, da bi identificirali prevladujoča podomrežja na podlagi objektivnih meritev, in razmestili zmanjšani model na končni točki SageMaker. Poleg tega smo vzeli vnaprej pripravljen osnovni model BERT in osnovni model namestili na drugi končni točki SageMaker. Nato smo tekli testiranje obremenitve z uporabo Locusta na obeh končnih točkah sklepanja in ovrednotil uspešnost v smislu odzivnega časa.
Najprej uvozimo potrebne knjižnice Locust in Boto3. Nato sestavimo metapodatke zahteve in zabeležimo začetni čas, ki se uporabi za testiranje obremenitve. Nato se koristni tovor posreduje API-ju za priklic končne točke SageMaker prek BotoClient za simulacijo dejanskih uporabniških zahtev. Locust uporabljamo za ustvarjanje več virtualnih uporabnikov za vzporedno pošiljanje zahtev in merjenje zmogljivosti končne točke pod obremenitvijo. Testi se izvajajo s povečanjem števila uporabnikov za vsako od obeh končnih točk. Ko so testi končani, Locust izda datoteko CSV s statistiko zahtev za vsakega od nameščenih modelov.
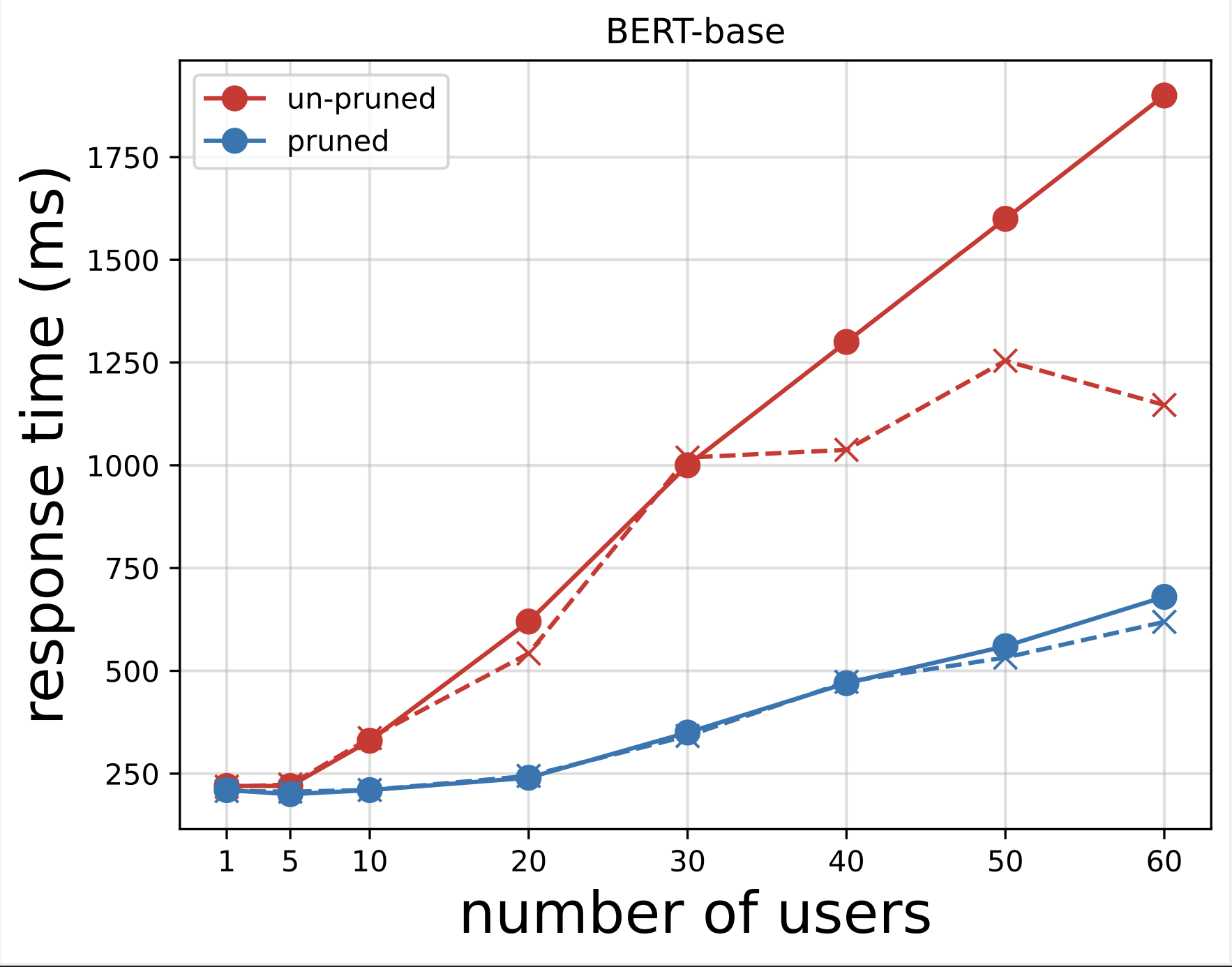
Nato ustvarimo diagrame odzivnega časa iz datotek CSV, ki smo jih prenesli po izvajanju testov z Locust. Namen risanja odzivnega časa v primerjavi s številom uporabnikov je analizirati rezultate testiranja obremenitve z vizualizacijo vpliva odzivnega časa končnih točk modela. V naslednjem grafikonu lahko vidimo, da končna točka modela, skrajšana z NAS, dosega nižji odzivni čas v primerjavi z osnovno končno točko modela BERT.
V drugem grafikonu, ki je razširitev prvega grafikona, opazimo, da SageMaker po približno 70 uporabnikih začne dušiti osnovno končno točko modela BERT in vrže izjemo. Vendar pa se za končno točko modela, zmanjšanega za NAS, dušenje zgodi med 90–100 uporabniki in z nižjim odzivnim časom.

Iz obeh grafikonov opazimo, da ima skrajšani model hitrejši odzivni čas in se bolje meri v primerjavi z neobrezanim modelom. Ko povečamo število končnih točk sklepanja, kot je to v primeru uporabnikov, ki uporabljajo veliko število končnih točk sklepanja za svoje aplikacije PLM, postanejo stroškovne koristi in izboljšanje zmogljivosti precejšnji.
Čiščenje
Če želite izbrisati končne točke SageMaker za natančno nastavljen osnovni model BERT in obrezani model NAS, dokončajte naslednje korake:
- Na konzoli SageMaker izberite Sklepanje in Končne točke v podoknu za krmarjenje.
- Izberite končno točko in jo izbrišite.
Druga možnost je, da iz zvezka SageMaker Studio zaženete naslednje ukaze, tako da podate imena končnih točk:
zaključek
V tej objavi smo razpravljali o tem, kako uporabiti NAS za obrezovanje natančno nastavljenega modela BERT. Najprej smo usposobili osnovni model BERT z uporabo podatkov, specifičnih za domeno, in ga uvedli v končno točko SageMaker. Izvedli smo iskanje z več cilji na natančno nastavljenem osnovnem modelu BERT z uporabo SageMaker AMT za ciljno nalogo. Vizualizirali smo sprednjo stran Pareto in izbrali Pareto optimalen NAS-prirezan model BERT ter model namestili na drugo končno točko SageMaker. Izvedli smo obremenitveno testiranje s programom Locust za simulacijo uporabnikov, ki poizvedujejo po obeh končnih točkah, ter izmerili in zabeležili odzivne čase v datoteko CSV. Narisali smo odzivni čas v primerjavi s številom uporabnikov za oba modela.
Opazili smo, da je zmanjšan model BERT deloval bistveno bolje tako pri odzivnem času kot pri pragu dušenja primerka. Ugotovili smo, da je bil model, okrnjen z NAS, bolj odporen na povečano obremenitev končne točke, pri čemer je ohranil nižji odzivni čas, čeprav je več uporabnikov obremenjevalo sistem v primerjavi z osnovnim modelom BERT. Tehniko NAS, opisano v tej objavi, lahko uporabite za kateri koli velik jezikovni model, da poiščete skrajšani model, ki lahko izvede ciljno nalogo z znatno krajšim odzivnim časom. Pristop lahko dodatno optimizirate z uporabo zakasnitve kot parametra poleg izgube pri validaciji.
Čeprav v tej objavi uporabljamo NAS, je kvantizacija še en pogost pristop, ki se uporablja za optimizacijo in stiskanje modelov PLM. Kvantizacija zmanjša natančnost uteži in aktivacij v usposobljenem omrežju z 32-bitne plavajoče vejice na nižje bitne širine, kot so 8-bitna ali 16-bitna cela števila, kar ima za posledico stisnjen model, ki generira hitrejše sklepanje. Kvantizacija ne zmanjša števila parametrov; namesto tega zmanjša natančnost obstoječih parametrov, da dobi stisnjen model. Obrezovanje NAS odstrani odvečna omrežja v PLM, kar ustvari redek model z manj parametri. Običajno se obrezovanje NAS in kvantizacija uporabljata skupaj za stiskanje velikih PLM-jev, da se ohrani natančnost modela, zmanjšajo izgube pri validaciji ob hkratnem izboljšanju zmogljivosti in zmanjša velikost modela. Druge pogosto uporabljene tehnike za zmanjšanje velikosti PLM vključujejo destilacija znanja, matrična faktorizacijain destilacijske kaskade.
Pristop, predlagan v objavi v spletnem dnevniku, je primeren za ekipe, ki uporabljajo SageMaker za usposabljanje in natančno nastavitev modelov z uporabo podatkov, specifičnih za domeno, in uvajanje končnih točk za ustvarjanje sklepanja. Če iščete popolnoma upravljano storitev, ki ponuja izbiro visoko zmogljivih temeljnih modelov, potrebnih za izdelavo generativnih aplikacij AI, razmislite o uporabi Amazon Bedrock. Če iščete vnaprej pripravljene odprtokodne modele za širok nabor primerov poslovne uporabe in želite dostopati do predlog rešitev in primerov zvezkov, razmislite o uporabi Amazon SageMaker JumpStart. Vnaprej usposobljena različica modela z osnovnim ohišjem Hugging Face BERT, ki smo ga uporabili v tej objavi, je na voljo tudi pri SageMaker JumpStart.
O avtorjih
 Aparajithan Vaidyanathan je glavni arhitekt za podjetniške rešitve pri AWS. Je arhitekt oblaka s 24+ leti izkušenj z načrtovanjem in razvojem poslovnih, obsežnih in porazdeljenih programskih sistemov. Specializiran je za generativno umetno inteligenco in podatkovno inženirstvo strojnega učenja. Je ambiciozen maratonec in njegovi hobiji vključujejo pohodništvo, kolesarjenje in preživljanje časa z ženo in dvema fantoma.
Aparajithan Vaidyanathan je glavni arhitekt za podjetniške rešitve pri AWS. Je arhitekt oblaka s 24+ leti izkušenj z načrtovanjem in razvojem poslovnih, obsežnih in porazdeljenih programskih sistemov. Specializiran je za generativno umetno inteligenco in podatkovno inženirstvo strojnega učenja. Je ambiciozen maratonec in njegovi hobiji vključujejo pohodništvo, kolesarjenje in preživljanje časa z ženo in dvema fantoma.
 Aaron Klein je višja uporabna znanstvenica pri AWS, ki se ukvarja z metodami avtomatiziranega strojnega učenja za globoke nevronske mreže.
Aaron Klein je višja uporabna znanstvenica pri AWS, ki se ukvarja z metodami avtomatiziranega strojnega učenja za globoke nevronske mreže.
 Jacek Golebiowski je višja uporabna znanstvenica pri AWS.
Jacek Golebiowski je višja uporabna znanstvenica pri AWS.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/machine-learning/reduce-inference-time-for-bert-models-using-neural-architecture-search-and-sagemaker-automated-model-tuning/
- :ima
- : je
- :ne
- :kje
- ][str
- $GOR
- 1
- 10
- 100
- 11
- 12
- 13
- 15%
- 17
- 19
- 20
- 26
- 30
- 31
- 320
- 7
- 70
- 72
- 8
- 9
- a
- sposobnost
- Sposobna
- dostop
- Račun
- natančnost
- Doseči
- Dosega
- aktivacije
- Poleg tega
- Sprejetje
- po
- AI
- Cilj
- Usmerjanje
- algoritmi
- vsi
- omogočajo
- Dovoli
- omogoča
- Prav tako
- Amazon
- Amazon Web Services
- znesek
- an
- Analiza
- analitika
- analizirati
- in
- Še ena
- odgovor
- kaj
- API
- aplikacije
- uporabna
- Uporabi
- Uporaba
- pristop
- odobritev
- približno
- Arhitektura
- SE
- OBMOČJE
- območja
- Argumenti
- okoli
- umetni
- umetne nevronske mreže
- AS
- ambiciozni
- dodeljena
- povezan
- At
- poskus
- pričakuje
- Avtomatizirano
- avtomatizirano strojno učenje
- avtomatizira
- Samodejno
- avtomatizacija
- Avtomatizacija
- Na voljo
- AWS
- Os
- Ravnovesje
- baza
- temeljijo
- BE
- postanejo
- pred
- vedenje
- primerjalna analiza
- Prednosti
- BEST
- Boljše
- med
- Bit
- telo
- tako
- izgradnjo
- poslovni
- Poslovni proces
- Avtomatizacija poslovnih procesov
- vendar
- by
- CAN
- Kandidat
- Zmogljivosti
- primeru
- primeri
- Katalog
- spremenite
- Graf
- Charts
- klepetalnice
- izbira
- Izberite
- izbran
- razred
- Razvrstitev
- klinični
- tesno
- Cloud
- Koda
- zbiranje
- zbirka
- kombinacije
- komercialna
- Skupno
- pogosto
- v primerjavi z letom
- dokončanje
- Končana
- kompleksna
- kompleksnost
- deli
- računalniški
- Izračunajte
- koncepti
- sklenjene
- Razmislite
- vsebuje
- Konzole
- omejitve
- gradnjo
- poraba
- Vsebuje
- vsebina
- ustvarjanje vsebine
- ozadje
- naprej
- kontrast
- Nadzor
- Ustrezno
- strošek
- stroški
- štetje
- ustvarjajo
- ustvari
- Oblikovanje
- stranka
- Za stranke
- datum
- znanost o podatkih
- nabor podatkov
- Datum čas
- odloča
- Odločanje
- namenjen
- globoko
- globoke nevronske mreže
- opredeliti
- opredeljen
- definiranje
- Predstavitev
- izkazati
- Odvisno
- razporedi
- razporejeni
- uvajanja
- razpolaga
- opisano
- Oblikovanje
- oblikovanje
- želeno
- razvoju
- drugačen
- razpravljali
- porazdeljena
- dokument
- Ne
- prevladujoč
- prevladujejo
- dont
- 2
- med
- e
- vsak
- učinkovitosti
- učinkovite
- bodisi
- Končna točka
- Končne točke
- Inženiring
- Motorji
- dovolj
- Vnesite
- Podjetje
- posvojitev podjetja
- Rešitve za podjetja
- entiteta
- Vpis
- okolje
- epoha
- Napaka
- Eter (ETH)
- oceniti
- ocenili
- vrednotenja
- Tudi
- dogodki
- Primer
- Razen
- izjema
- ekskluzivno
- obstoječih
- izkušnje
- Pojasnite
- razložiti
- razširitev
- Obraz
- false
- hitreje
- Lastnosti
- povratne informacije
- manj
- Polje
- file
- datoteke
- končna
- Najdi
- iskanje
- prva
- Všita
- prilagodljivost
- plavajoči
- po
- Odtis
- za
- je pokazala,
- Fundacija
- iz
- spredaj
- Frontier
- v celoti
- funkcija
- nadalje
- ustvarjajo
- ustvarja
- generativno
- Generativna AI
- dobili
- dana
- Cilj
- GPU
- siva
- se zgodi
- Imajo
- he
- Glava
- glave
- zdravstveno varstvo
- Pomaga
- skrita
- visoko zmogljiv
- več
- pohodništvo
- njegov
- zgodovina
- Prosti čas
- gostitelj
- gostila
- URE
- Kako
- Kako
- Vendar
- HTML
- http
- HTTPS
- HuggingFace
- Optimizacija hiperparametra
- Uglaševanje hiperparametrov
- i
- identificirati
- idx
- if
- ilustrirajte
- vpliv
- Vplivi
- izvajati
- uvoz
- izboljšanje
- izboljšalo
- Izboljšanje
- izboljšanju
- in
- vključujejo
- Povečajte
- povečal
- narašča
- Podatki
- Infrastruktura
- vhod
- primer
- primerov
- Namesto
- Inteligentna
- v
- IT
- ITS
- Job
- Delovna mesta
- jpg
- json
- znanje
- znano
- jezik
- velika
- obsežne
- Največji
- Latenca
- plast
- plasti
- Interesenti
- UČITE
- učenje
- vsaj
- Naj
- knjižnice
- Knjižnica
- vrstica
- obremenitev
- prijavi
- sečnja
- si
- off
- izgube
- nižje
- stroj
- strojno učenje
- vzdrževati
- vzdrževanje
- moški
- upravlja
- Maraton
- Maska
- matplotlib
- največja
- Maj ..
- kar pomeni,
- merjenje
- izmerjena
- merjenje
- medicinski
- Srečati
- Spomin
- metapodatki
- Metode
- meritev
- Meritve
- morda
- zmanjšajo
- min
- ML
- Model
- modeliranje
- modeli
- Modularna
- več
- premikanje
- veliko
- več
- morajo
- Ime
- Imenovan
- Imena
- na
- naravna
- Naravni jezik
- Obdelava Natural Language
- Krmarjenje
- ostalo
- potrebno
- Nimate
- potrebna
- potrebe
- mreža
- omrežij
- Nevronski
- nevronska mreža
- nevronske mreže
- Naslednja
- nlp
- Noben
- Upoštevajte
- prenosnik
- zvezki
- zdaj
- Številka
- predmet
- Cilj
- Cilji
- opazujejo
- opazovana
- of
- off
- ponudba
- Ponudbe
- on
- ONE
- na spletu
- spletni prodajalec
- samo
- odprite
- open source
- optimalna
- optimizacija
- Optimizirajte
- optimizirana
- Optimizira
- optimizacijo
- or
- Da
- izvirno
- Ostalo
- naši
- ven
- izhod
- izhodi
- več
- Splošni
- pregled
- lastne
- parov
- podokno
- vzporedno
- parameter
- parametri
- Pareto
- del
- opravil
- pot
- Bolnik
- vzorci
- opravlja
- performance
- opravljeno
- izvajati
- opravlja
- Dovoljenja
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Točka
- točke
- pozicije
- Prispevek
- Precision
- napoved
- napovedno
- Predictor
- nastavitve
- pripravljeni
- predpogoji
- predstaviti
- prej
- , ravnateljica
- problem
- Postopek
- Avtomatizacija procesov
- Procesi
- obravnavati
- Izdelek
- produktivnost
- Orodja za produktivnost
- predlagano
- Ponudnik
- zagotavlja
- zagotavljanje
- vlečenje
- Potegne
- Namen
- namene
- Python
- pitorha
- Vprašanja in odgovori
- vprašanje
- precej
- naključno
- območje
- hitro
- Cene
- Surovi
- pravo
- Priznanje
- priznajo
- prepoznavanje
- Priporočilo
- Priporočila
- zapis
- Zabeležena
- Rdeča
- zmanjša
- Zmanjšana
- zmanjšuje
- regresija
- povezane
- odstrani
- odstranjevanje
- Poročila
- zastopanje
- zahteva
- zahtevano
- zahteva
- obvezna
- Zahteve
- odporno
- vir
- viri
- oziroma
- Odgovor
- Rezultati
- trgovec na drobno
- ohranitev
- vrne
- jahanje
- Tveganje
- ROW
- Run
- runner
- tek
- deluje
- s
- žrtvovati
- sagemaker
- Sklep SageMaker
- Shrani
- Lestvica
- luske
- Znanost
- Znanstvenik
- rezultat
- script
- Iskalnik
- Iskalniki
- iskanje
- drugi
- Oddelek
- glej
- izberite
- izbran
- SAMO
- pošljite
- stavek
- sentiment
- Zaporedje
- Storitev
- Storitve
- Zasedanje
- nastavite
- Kompleti
- nastavitev
- Razstave
- signali
- bistveno
- Enostavno
- hkrati
- hkrati
- sam
- Velikosti
- manj
- So
- Software
- Rešitev
- rešitve
- nekaj
- vir
- Vesolje
- Spawn
- specializirani
- specializirano
- specifična
- posebej
- Poraba
- po delih
- Začetek
- začne
- Država
- Statistika
- Korak
- Koraki
- shranjevanje
- strukturno
- strukturirano
- studio
- precejšen
- uspešno
- Uspešno
- taka
- primerna
- apartma
- POVZETEK
- sistem
- sistemi
- T
- Bodite
- meni
- ciljna
- Naloga
- Naloge
- Skupine
- tehnika
- tehnike
- predloge
- Pogoji
- Testiranje
- testi
- besedilo
- Razvrstitev besedil
- besedilno
- kot
- da
- O
- njihove
- POTEM
- Tukaj.
- zato
- te
- ta
- 3
- Prag
- skozi
- čas
- krat
- do
- skupaj
- žeton
- vzel
- orodje
- orodja
- trgovini
- Trgovanje
- Vlak
- usposobljeni
- usposabljanje
- transformator
- transformatorji
- Res
- poskusite
- dva
- tip
- Vrste
- tipičen
- tipično
- Konec koncev
- pod
- v postopku
- razumevanje
- enote
- us
- uporaba
- primeru uporabe
- Rabljeni
- uporabnik
- Uporabniki
- uporablja
- uporabo
- potrjevanje
- vrednost
- Vrednote
- različica
- preko
- Virtual
- vizualizirati
- vs
- želeli
- je
- we
- web
- spletne storitve
- Dobro
- kdaj
- ali
- ki
- medtem
- WHO
- široka
- Širok spekter
- pogosto
- žena
- Wikipedia
- bo
- pripravljeni
- z
- v
- delo
- potek dela
- deluje
- X
- let
- donos
- jo
- Vaša rutina za
- zefirnet