

vir: rawpixel.com
Pogovorni AI je aplikacija LLM, ki je sprožila veliko hrupa in pozornosti zaradi svoje razširljivosti v številnih panogah in primerih uporabe. Medtem ko konverzacijski sistemi obstajajo že desetletja, so LLM-ji prinesli kakovost, ki je bila potrebna za njihovo obsežno sprejetje. V tem članku bomo uporabili miselni model, prikazan na sliki 1, za razčlenitev pogovornih aplikacij umetne inteligence (prim. Gradnja izdelkov AI s celostnim mentalnim modelom za uvod v mentalni model). Po preučitvi tržnih priložnosti in poslovne vrednosti pogovornih sistemov umetne inteligence bomo razložili dodatne »stroje« v smislu podatkov, natančnega prilagajanja LLM in pogovornega dizajna, ki jih je treba nastaviti, da bodo pogovori ne samo mogoči, temveč tudi uporabni. in prijetno.
1. Priložnost, vrednost in omejitve
Tradicionalna zasnova UX je zgrajena okoli množice umetnih elementov UX, potegov, dotikov in klikov, ki zahtevajo krivuljo učenja za vsako novo aplikacijo. Z uporabo pogovorne umetne inteligence lahko odpravimo to zasedenost in jo nadomestimo z elegantno izkušnjo naravno tekočega pogovora, v katerem lahko pozabimo na prehode med različnimi aplikacijami, okni in napravami. Uporabljamo jezik, naš univerzalni in znani protokol za komunikacijo, za interakcijo z različnimi virtualnimi pomočniki (VA) in izpolnjevanje naših nalog.
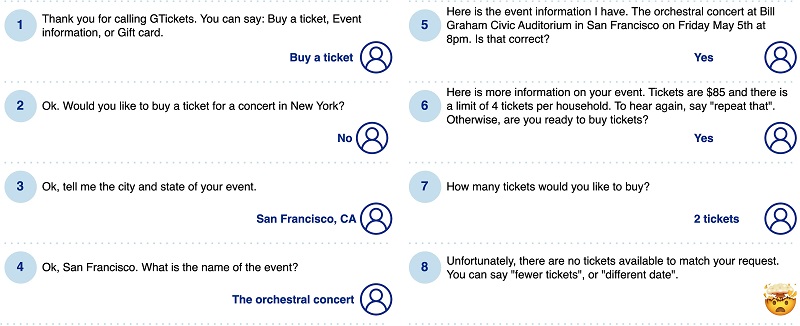
Pogovorni uporabniški vmesniki niso ravno nova vroča stvar. Interaktivni glasovni odzivni sistemi (IVR) in klepetalni roboti obstajajo že od devetdesetih let prejšnjega stoletja, velikemu napredku v NLP pa so pozorno sledili valovi upanja in razvoja glasovnih in klepetalnih vmesnikov. Vendar pa je bila pred časom LLM večina sistemov implementirana v simbolni paradigmi, ki je temeljila na pravilih, ključnih besedah in pogovornih vzorcih. Prav tako so bili omejeni na določeno, vnaprej določeno področje »kompetentnosti« in uporabniki, ki bi se podali izven tega, bi kmalu zašli v slepo ulico. Skratka, ti sistemi so bili rudarjeni s potencialnimi točkami odpovedi in po nekaj frustrirajočih poskusih se mnogi uporabniki nikoli niso vrnili k njim. Naslednja slika prikazuje primer dialoga. Uporabnik, ki želi naročiti vstopnico za določen koncert, gre potrpežljivo skozi podrobno spraševanje, na koncu pa ugotovi, da je koncert razprodan.
Kot omogočena tehnologija lahko LLM popelje pogovorne vmesnike na nove ravni kakovosti in zadovoljstva uporabnikov. Pogovorni sistemi lahko zdaj prikažejo veliko širše znanje sveta, jezikovno kompetenco in pogovorne sposobnosti. Z uporabo vnaprej usposobljenih modelov jih je mogoče razviti tudi v veliko krajših časovnih obdobjih, saj je dolgočasno delo sestavljanja pravil, ključnih besed in tokov dialoga zdaj nadomeščeno s statističnim znanjem LLM. Oglejmo si dve vidni aplikaciji, kjer lahko pogovorna umetna inteligenca zagotovi vrednost v velikem obsegu:
- Podpora strankam in na splošno aplikacije, ki jih uporablja veliko število uporabnikov, ki pogosto postavljajo podobne zahteve. Tukaj ima podjetje, ki nudi podporo strankam, jasno informacijsko prednost pred uporabnikom in lahko to izkoristi za ustvarjanje bolj intuitivne in prijetne uporabniške izkušnje. Razmislite o primeru ponovne rezervacije leta. Meni, ki precej pogosto letim, se to zgodi 1-2 krat na leto. Vmes ponavadi pozabim na podrobnosti postopka, da ne govorim o uporabniškem vmesniku določene letalske družbe. Nasprotno pa ima podpora strankam letalske družbe zahteve za ponovno rezervacijo na čelu in v središču svojih operacij. Namesto da bi postopek ponovne rezervacije razkrili prek zapletenega grafičnega vmesnika, je njegovo logiko mogoče »skrijeti« pred strankami, ki stopijo v stik s podporo, in lahko uporabijo jezik kot naraven kanal za ponovno rezervacijo. Seveda bo še vedno ostal »dolg rep« manj poznanih zahtev. Na primer, predstavljajte si spontano nihanje razpoloženja, ki poslovno stranko spodbudi, da doda svojega ljubljenega psa kot odvečno prtljago na rezerviran let. Te bolj individualne zahteve je mogoče posredovati človeškim agentom ali pokriti prek notranjega sistema za upravljanje znanja, povezanega z virtualnim pomočnikom.
- Upravljanje znanja ki temelji na veliki količini podatkov. Za mnoga sodobna podjetja je notranje znanje, ki ga naberejo v letih delovanja, ponavljanja in učenja, ključno sredstvo in razlika – če je shranjeno, upravljano in dostopno do njega na učinkovit način. Če sedijo na množici podatkov, ki so skriti v orodjih za sodelovanje, notranjih wikijih, bazah znanja itd., jih pogosto ne uspejo spremeniti v uporabno znanje. Ko zaposleni odhajajo, se vkrcajo novi zaposleni in nikoli ne dokončate tiste strani z dokumentacijo, ki ste jo začeli pred tremi meseci, dragoceno znanje postane žrtev entropije. Vse težje postaja najti pot skozi notranji podatkovni labirint in se dokopati do delčkov informacij, ki so potrebne v določeni poslovni situaciji. To vodi do velikih izgub učinkovitosti delavcev znanja. Da bi rešili to težavo, lahko razširimo LLM s semantičnim iskanjem po notranjih virih podatkov. LLM-ji omogočajo uporabo vprašanj v naravnem jeziku namesto zapletenih formalnih poizvedb za postavljanje vprašanj glede te baze podatkov. Uporabniki se tako lahko osredotočijo na svoje informacijske potrebe in ne na strukturo baze znanja ali sintakso poizvedovalnega jezika, kot je SQL. Ker ti sistemi temeljijo na besedilu, delujejo s podatki v bogatem semantičnem prostoru in ustvarjajo smiselne povezave »pod pokrovom«.
Poleg teh glavnih področij uporabe obstajajo številne druge aplikacije, kot so telezdravje, pomočniki za duševno zdravje in izobraževalni klepetalni roboti, ki lahko poenostavijo UX in svojim uporabnikom prinesejo vrednost na hitrejši in učinkovitejši način.
Če je ta poglobljena izobraževalna vsebina za vas koristna, lahko se naročite na naš seznam raziskav AI za raziskave na katerega bomo opozorili, ko bomo izdali novo gradivo.
2. Podatki
LLM prvotno niso usposobljeni za tekoče pogovore ali obsežnejše pogovore. Namesto tega se naučijo ustvariti naslednji žeton na vsakem koraku sklepanja, kar na koncu povzroči koherentno besedilo. Ta cilj na nizki ravni se razlikuje od izziva človeškega pogovora. Pogovor je za ljudi neverjetno intuitiven, vendar postane neverjetno zapleten in niansiran, ko želite naučiti stroj, da to počne. Na primer, poglejmo temeljni pojem namenov. Ko uporabljamo jezik, to počnemo za določen namen, kar je naš komunikacijski namen - lahko je posredovanje informacij, druženje ali prošnja nekoga, naj nekaj naredi. Medtem ko sta prva dva precej enostavna za LLM (dokler je videl zahtevane informacije v podatkih), je slednje že bolj zahtevno. Ne samo, da mora LLM združiti in strukturirati povezane informacije na koherenten način, ampak mora tudi nastaviti pravi čustveni ton v smislu mehkih meril, kot so formalnost, ustvarjalnost, humor itd. To je izziv za konverzacijsko oblikovanje (prim. razdelek 5), ki je tesno prepleten z nalogo ustvarjanja podatkov za fino nastavitev.
Prehod od generiranja klasičnega jezika k prepoznavanju in odzivanju na specifične komunikacijske namene je pomemben korak k boljši uporabnosti in sprejemanju pogovornih sistemov. Kot pri vseh prizadevanjih za fino uravnavanje se tudi to začne z zbiranjem ustreznega nabora podatkov.
Podatki natančnega prilagajanja bi se morali čim bolj približati (prihodnji) distribuciji podatkov v resničnem svetu. Najprej bi morali biti pogovorni (dialoški) podatki. Drugič, če bo vaš virtualni pomočnik specializiran za določeno področje, poskusite zbrati podatke o natančnem uravnavanju, ki odražajo potrebno znanje o področju. Tretjič, če obstajajo značilni tokovi in zahteve, ki se bodo v vaši aplikaciji pogosto ponavljale, kot v primeru podpore strankam, poskusite v svoje podatke o usposabljanju vključiti različne primere teh. Naslednja tabela prikazuje vzorec podatkov za natančno nastavitev pogovorov iz Nabor podatkov 3K pogovorov za ChatBot, ki je prosto dostopen na Kaggle:
Ročno ustvarjanje pogovornih podatkov lahko postane drag podvig - množično iskanje in uporaba LLM-jev za pomoč pri ustvarjanju podatkov sta dva načina za povečanje. Ko so podatki o dialogih zbrani, je treba pogovore oceniti in dodati opombe. To vam omogoča, da svojemu modelu pokažete tako pozitivne kot negativne primere in ga spodbudite k prevzemanju značilnosti »pravih« pogovorov. Ocenjevanje se lahko izvede z absolutnimi točkami ali razvrstitvijo različnih možnosti med seboj. Slednji pristop vodi do natančnejšega natančnega prilagajanja podatkov, ker so ljudje običajno boljši pri razvrščanju več možnosti kot pri ocenjevanju le-teh ločeno.
S svojimi podatki ste pripravljeni, da natančno prilagodite svoj model in ga obogatite z dodatnimi zmogljivostmi. V naslednjem razdelku si bomo ogledali natančno uravnavanje, integracijo dodatnih informacij iz pomnilnika in semantičnega iskanja ter povezovanje agentov z vašim konverzacijskim sistemom, da mu omogočimo izvajanje določenih nalog.
3. Sestavljanje pogovornega sistema
Tipičen pogovorni sistem je zgrajen s pogovornim agentom, ki orkestrira in usklajuje komponente in zmogljivosti sistema, kot so LLM, pomnilnik in zunanji viri podatkov. Razvoj konverzacijskih sistemov umetne inteligence je zelo eksperimentalna in empirična naloga, vaši razvijalci pa se bodo nenehno vrteli med optimizacijo vaših podatkov, izboljšanjem strategije natančnega prilagajanja, igranjem z dodatnimi komponentami in izboljšavami ter preizkušanjem rezultatov. . Netehnični člani skupine, vključno z vodji izdelkov in oblikovalci uporabniške izkušnje, bodo prav tako nenehno testirali izdelek. Na podlagi svojih dejavnosti odkrivanja strank so v odličnem položaju, da predvidijo slog in vsebino pogovorov prihodnjih uporabnikov in bi morali aktivno prispevati to znanje.
3.1 Poučevanje konverzacijskih veščin vašega LLM
Za natančno uravnavanje potrebujete podatke o natančnem uravnavanju (glej razdelek 2) in predhodno usposobljen LLM. LLM že veliko vedo o jeziku in svetu, naš izziv pa je, da jih naučimo konverzacijskih principov. Pri natančnem uravnavanju so ciljni izhodi besedila, model pa bo optimiziran za ustvarjanje besedil, ki so čim bolj podobna ciljem. Za nadzorovano fino uravnavanje morate najprej jasno definirati pogovorno nalogo umetne inteligence, za katero želite, da jo izvede model, zbrati podatke ter zagnati in ponoviti postopek natančnega uravnavanja.
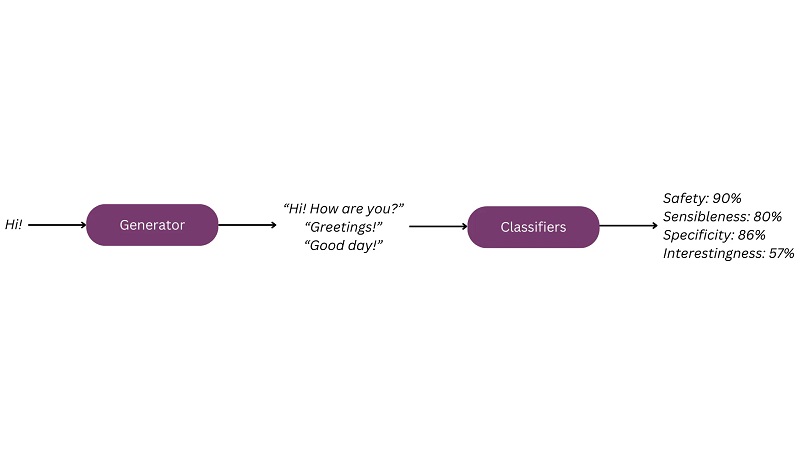
Zaradi navdušenja okoli LLM-jev so se pojavile različne metode natančnega prilagajanja. Za precej tradicionalen primer natančne nastavitve za pogovor si lahko ogledate opis modela LaMDA.[1] LaMDA je bila natančno nastavljena v dveh korakih. Prvič, podatki o dialogu se uporabljajo za učenje modelnih pogovornih veščin ("generativno" fino uravnavanje). Nato se oznake, ki jih ustvarijo opombevalci med ocenjevanjem podatkov, uporabijo za usposabljanje klasifikatorjev, ki lahko ocenijo rezultate modela glede na želene atribute, ki vključujejo občutljivost, specifičnost, zanimivost in varnost (»diskriminativno« fino uravnavanje). Ti klasifikatorji se nato uporabijo za usmerjanje vedenja modela glede na te atribute.
Poleg tega je utemeljenost dejstev – zmožnost, da svoje rezultate utemeljijo z verodostojnimi zunanjimi informacijami – pomemben atribut LLM. Da bi zagotovili utemeljenost dejstev in zmanjšali halucinacije, je bil LaMDA natančno prilagojen z naborom podatkov, ki vključuje klice v zunanji sistem za iskanje informacij, kadar koli je potrebno zunanje znanje. Tako se je model naučil najprej pridobiti dejanske informacije, kadar koli je uporabnik izvedel poizvedbo, ki je zahtevala novo znanje.
Druga priljubljena tehnika natančnega uravnavanja je okrepitveno učenje iz človeških povratnih informacij (RLHF) [2]. RLHF »preusmeri« učni proces LLM od enostavne, a umetne naloge napovedovanja naslednjega žetona k učenju človeških preferenc v dani komunikacijski situaciji. Te človeške preference so neposredno kodirane v podatkih o usposabljanju. Med postopkom označevanja se ljudem prikažejo pozivi in napišejo želeni odgovor ali razvrstijo niz obstoječih odgovorov. Vedenje LLM je nato optimizirano, da odraža človeške želje.
3.2 Dodajanje zunanjih podatkov in semantično iskanje
Poleg sestavljanja pogovorov za natančno nastavitev modela boste morda želeli izboljšati svoj sistem s posebnimi podatki, ki jih je mogoče uporabiti med pogovorom. Vaš sistem bo na primer morda potreboval dostop do zunanjih podatkov, kot so patenti ali znanstveni članki, ali notranjih podatkov, kot so profili strank ali vaša tehnična dokumentacija. To se običajno izvaja s semantičnim iskanjem (znanim tudi kot generiranje z razširjenim iskanjem ali RAG)[3]. Dodatni podatki so shranjeni v bazi podatkov v obliki semantičnih vdelav (prim. ta članek za razlago vdelav in nadaljnjih referenc). Ko pride uporabniška zahteva, se predhodno obdela in pretvori v semantično vdelavo. Semantično iskanje nato identificira dokumente, ki so najbolj pomembni za zahtevo, in jih uporabi kot kontekst za poziv. Z integracijo dodatnih podatkov s semantičnim iskanjem lahko zmanjšate halucinacije in zagotovite bolj uporabne, na dejstvih utemeljene odgovore. Z nenehnim posodabljanjem baze podatkov za vdelavo lahko tudi ohranjate posodobljenost znanja in odzivov vašega sistema, ne da bi nenehno izvajali postopek natančnega prilagajanja.
3.3 Zavedanje spomina in konteksta
Predstavljajte si, da greste na zabavo in srečate Petra, odvetnika. Navdušite se in začnete predstavljati zakonitega klepetalnika, ki ga trenutno nameravate zgraditi. Peter je videti zainteresiran, se nagne k tebi, uhm in prikima. Na neki točki želite njegovo mnenje o tem, ali bi želel uporabljati vašo aplikacijo. Namesto informativne izjave, ki bi nadomestila vašo zgovornost, slišite: "Uhm ... kaj je spet počela ta aplikacija?"
Nenapisana pogodba medčloveške komunikacije predpostavlja, da poslušamo sogovornika in gradimo lastna govorna dejanja na kontekstu, ki ga soustvarjamo med interakcijo. V družbenem okolju je pojav tega skupnega razumevanja značilen za ploden, bogat pogovor. V bolj vsakdanjih okoljih, kot je rezervacija mize v restavraciji ali nakup vozovnice za vlak, je to nujno potrebno za izpolnitev naloge in zagotavljanje pričakovane vrednosti za uporabnika. To zahteva, da vaš pomočnik pozna zgodovino trenutnega pogovora, pa tudi preteklih pogovorov - na primer, ne bi smel vedno znova zahtevati imena in drugih osebnih podatkov uporabnika, kadar koli začne pogovor.
Eden od izzivov pri ohranjanju zavedanja konteksta je koreferenčna ločljivost, tj. razumevanje, na katere predmete se nanašajo zaimki. Ljudje intuitivno uporabljajo veliko kontekstualnih namigov, ko razlagajo jezik - na primer, lahko otroka vprašate: "Prosim, vzemi zeleno žogo iz rdeče škatle in mi jo prinesi," in otrok bo vedel, da misliš žogo , ne škatla. Za virtualne pomočnike je ta naloga lahko precej zahtevna, kot je prikazano v naslednjem dialogu:
Pomočnik: Hvala, zdaj bom rezerviral vaš let. Bi radi tudi vi naročili obrok za svoj let?
Uporabnik: Uhm ... ali se lahko pozneje odločim, ali ga želim?
Pomočnik: Žal tega leta pozneje ni mogoče spremeniti ali odpovedati.
Tukaj pomočnik ne prepozna, da je zaimek it od uporabnika se ne nanaša na let, temveč na obrok, zato je za odpravo tega nesporazuma potrebna še ena ponovitev.
3.4 Dodatne zaščitne ograje
Vsake toliko časa se bo tudi najboljši magister prava slabo obnašal in haluciniral. V mnogih primerih so halucinacije preproste težave z natančnostjo - in dobro, sprejeti morate, da nobena umetna inteligenca ni 100-odstotno natančna. V primerjavi z drugimi sistemi umetne inteligence je »razdalja« med uporabnikom in umetno inteligenco med uporabnikom in umetno inteligenco precej majhna. Navadna težava z natančnostjo se lahko hitro spremeni v nekaj, kar se dojema kot strupeno, diskriminatorno ali na splošno škodljivo. Poleg tega lahko LLM razkrijejo občutljive podatke, kot so podatki, ki omogočajo osebno identifikacijo (PII), ker nimajo lastnega razumevanja zasebnosti. Temu vedenju se lahko borite z dodatnimi zaščitnimi ograjami. Orodja, kot so Guardrails AI, Rebuff, NeMo Guardrails in Microsoft Guidance, vam omogočajo, da zmanjšate tveganje svojega sistema tako, da oblikujete dodatne zahteve za rezultate LLM in blokirate neželene rezultate.
V pogovorni AI je možnih več arhitektur. Naslednja shema prikazuje preprost primer, kako lahko konverzacijski agent integrira natančno nastavljen LLM, zunanje podatke in pomnilnik, ki je odgovoren tudi za hitro konstrukcijo in zaščitne ograje.

4. Uporabniška izkušnja in pogovorno oblikovanje
Čar pogovornih vmesnikov je v njihovi preprostosti in enotnosti v različnih aplikacijah. Če je prihodnost uporabniških vmesnikov takšna, da so vse aplikacije bolj ali manj enake, ali je delo oblikovalca UX obsojeno na propad? Vsekakor ne – pogovor je umetnost, ki se je morate naučiti svojega LLM, da lahko vodi pogovore, ki so koristni, naravni in udobni za vaše uporabnike. Dober pogovorni dizajn nastane, ko združimo svoje znanje človeške psihologije, jezikoslovja in UX oblikovanja. V nadaljevanju bomo najprej razmislili o dveh osnovnih odločitvah pri gradnji pogovornega sistema, in sicer ali boste uporabljali glas in/ali klepet, kot tudi širši kontekst vašega sistema. Nato si bomo ogledali same pogovore in videli, kako lahko oblikujete osebnost svojega pomočnika, hkrati pa ga naučite sodelovati v koristnih in sodelovalnih pogovorih.
4.1 Glas v primerjavi s klepetom
Pogovorne vmesnike je mogoče implementirati s klepetom ali glasom. Na kratko, glas je hitrejši, medtem ko klepet uporabnikom omogoča, da ostanejo zasebni in izkoristijo obogateno funkcionalnost uporabniškega vmesnika. Potopimo se nekoliko globlje v obe možnosti, saj je to ena prvih in najpomembnejših odločitev, s katerimi se boste soočili pri izdelavi pogovorne aplikacije.
Če želite izbirati med dvema možnostma, najprej razmislite o fizičnem okolju, v katerem se bo uporabljala vaša aplikacija. Na primer, zakaj skoraj vsi pogovorni sistemi v avtomobilih, kot so tisti, ki jih ponuja Nuance Communications, temeljijo na glasu? Ker so roke voznika že tako zasedene in ne more nenehno preklapljati med volanom in tipkovnico. To velja tudi za druge dejavnosti, kot je kuhanje, kjer želijo uporabniki med uporabo vaše aplikacije ostati v toku svoje dejavnosti. Avtomobili in kuhinje so večinoma zasebne nastavitve, tako da lahko uporabniki izkusijo veselje glasovne interakcije, ne da bi jih skrbelo zasebnost ali motenje drugih. Nasprotno pa, če bo vaša aplikacija uporabljena v javnem okolju, kot je pisarna, knjižnica ali železniška postaja, glas morda ni vaša prva izbira.
Ko razumete fizično okolje, razmislite o čustveni plati. Glas se lahko namerno uporablja za prenos tona, razpoloženja in osebnosti – ali to dodaja vrednost v vašem kontekstu? Če gradite svojo aplikacijo za prosti čas, bi lahko glas povečal dejavnik zabave, medtem ko bi pomočnik za duševno zdravje lahko poskrbel za več empatije in potencialno težavnemu uporabniku omogočil širši obseg izražanja. Nasprotno, če bo vaša aplikacija pomagala uporabnikom v profesionalnem okolju, kot je trgovanje ali storitve za stranke, bi lahko bolj anonimna interakcija, ki temelji na besedilu, prispevala k bolj objektivnim odločitvam in vam prihranila težave pri načrtovanju preveč čustvene izkušnje.
Kot naslednji korak razmislite o funkcionalnosti. Besedilni vmesnik vam omogoča obogatitev pogovorov z drugimi mediji, kot so slike in grafični elementi uporabniškega vmesnika, kot so gumbi. Na primer, v pomočniku za e-trgovino bo aplikacija, ki predlaga izdelke z objavo njihovih slik in strukturiranih opisov, veliko bolj uporabniku prijazna kot tista, ki opisuje izdelke z glasom in potencialno zagotavlja njihove identifikatorje.
Nazadnje se pogovorimo o dodatnih načrtovalskih in razvojnih izzivih gradnje glasovnega uporabniškega vmesnika:
- Obstaja dodaten korak prepoznavanja govora, ki se zgodi, preden se uporabniški vnosi lahko obdelajo z LLM in obdelavo naravnega jezika (NLP).
- Glas je bolj oseben in čustven medij komunikacije - zato so zahteve za oblikovanje dosledne, ustrezne in prijetne osebnosti za vašim virtualnim pomočnikom večje, zato boste morali upoštevati dodatne dejavnike "glasovnega oblikovanja", kot je tember , stres, ton in hitrost govora.
- Uporabniki pričakujejo, da bo vaš glasovni pogovor potekal z enako hitrostjo kot človeški pogovor. Če želite ponuditi naravno interakcijo prek glasu, potrebujete veliko krajšo zakasnitev kot za klepet. V človeških pogovorih je tipičen presledek med obrati 200 milisekund – ta hiter odziv je mogoč, ker začnemo sestavljati svoje obrate med poslušanjem partnerjevega govora. Vaš glasovni pomočnik se bo moral ujemati s to stopnjo tekočnosti v interakciji. Nasprotno pa pri klepetalnih robotih tekmujete s časovnimi razponi sekund, nekateri razvijalci pa celo uvedejo dodatno zakasnitev, da se pogovor počuti kot natipkan klepet med ljudmi.
- Komunikacija prek glasu je linearna, enkratna dejavnost – če vaš uporabnik ni razumel, kar ste rekli, vas čaka dolgočasno pojasnjevalno zanko, nagnjeno k napakam. Zato morajo biti vaši obrati čim bolj jedrnati, jasni in informativni.
Če se odločite za glasovno rešitev, se prepričajte, da ne le jasno razumete prednosti v primerjavi s klepetom, ampak imate tudi spretnosti in vire za reševanje teh dodatnih izzivov.
4.2 Kje bo živel vaš pogovorni AI?
Zdaj pa razmislimo o širšem kontekstu, v katerega lahko integrirate pogovorni AI. Vsi poznamo chatbote na spletnih mestih podjetij – tiste pripomočke na desni strani zaslona, ki se prikažejo, ko odpremo spletno mesto podjetja. Osebno je moja intuitivna reakcija bolj pogosto poiskati gumb Zapri. Zakaj? Skozi začetne poskuse »pogovarjanja« s temi boti sem ugotovil, da ne morejo zadovoljiti bolj specifičnih informacijskih zahtev, in na koncu moram še vedno prečesati spletno stran. Morala zgodbe? Ne zgradite klepetalnega robota, ker je kul in trendi - raje ga zgradite, ker ste prepričani, da lahko ustvari dodatno vrednost za vaše uporabnike.
Poleg kontroverznega gradnika na spletni strani podjetja obstaja več vznemirljivih kontekstov za integracijo tistih bolj splošnih klepetalnih robotov, ki so postali možni z LLM-ji:
- Kopiloti: Ti pomočniki vas vodijo in svetujejo skozi posebne procese in naloge, kot je GitHub CoPilot za programiranje. Običajno so kopiloti "vezani" na določeno aplikacijo (ali majhen nabor sorodnih aplikacij).
- Sintetični ljudje (tudi digitalni ljudje): Ta bitja »posnemajo« prave ljudi v digitalnem svetu. Izgledajo, se obnašajo in govorijo kot ljudje, zato potrebujejo tudi bogate pogovorne sposobnosti. Sintetični ljudje se pogosto uporabljajo v poglobljenih aplikacijah, kot so igre na srečo ter razširjena in navidezna resničnost.
- Digitalni dvojčki: Digitalni dvojčki so digitalne »kopije« procesov in predmetov iz resničnega sveta, kot so tovarne, avtomobili ali motorji. Uporabljajo se za simulacijo, analizo in optimizacijo zasnove in obnašanja realnega objekta. Interakcije naravnega jezika z digitalnimi dvojčki omogočajo bolj gladek in vsestranski dostop do podatkov in modelov.
- Baze podatkov: Dandanes so na voljo podatki o kateri koli temi, pa naj gre za naložbena priporočila, izrezke kode ali izobraževalna gradiva. Pogosto je težko najti zelo specifične podatke, ki jih uporabniki potrebujejo v določeni situaciji. Grafični vmesniki do podatkovnih baz so preveč grobi ali prekriti z neskončnimi pripomočki za iskanje in filtriranje. Vsestranski poizvedovalni jeziki, kot sta SQL in GraphQL, so dostopni samo uporabnikom z ustreznimi veščinami. Pogovorne rešitve omogočajo uporabnikom, da poizvedujejo po podatkih v naravnem jeziku, medtem ko jih LLM, ki obdela zahteve, samodejno pretvori v ustrezen poizvedovalni jezik (prim. ta članek za razlago Text2SQL).
4.3 Vtisnite osebnost svojemu pomočniku
Kot ljudje smo naravnani na antropomorfizacijo, tj. na vnašanje dodatnih človeških lastnosti, ko vidimo nekaj, kar nejasno spominja na človeka. Jezik je ena izmed najbolj edinstvenih in fascinantnih sposobnosti človeštva in pogovorni izdelki bodo samodejno povezani z ljudmi. Ljudje si bodo za svojim zaslonom ali napravo predstavljali osebo – in dobra praksa je, da te določene osebe ne prepustite domišljiji vaših uporabnikov, temveč ji raje posodite dosledno osebnost, ki je usklajena z vašim izdelkom in blagovno znamko. Ta proces se imenuje "oblikovanje osebnosti".
Prvi korak oblikovanja osebnosti je razumevanje značajskih lastnosti, ki bi jih radi prikazali. V idealnem primeru je to storjeno že na ravni podatkov o usposabljanju - na primer, ko uporabljate RLHF, lahko prosite svoje opombe, da razvrstijo podatke glede na lastnosti, kot so ustrežljivost, vljudnost, zabava itd., da se model preusmeri k želene lastnosti. Te značilnosti je mogoče uskladiti z atributi vaše blagovne znamke, da ustvarite dosledno podobo, ki nenehno promovira vašo blagovno znamko prek izkušnje z izdelkom.
Poleg splošnih značilnosti bi morali razmišljati tudi o tem, kako se bo vaš virtualni pomočnik spopadel s specifičnimi situacijami zunaj »srečne poti«. Na primer, kako se bo odzval na zahteve uporabnikov, ki presegajo njegov obseg, odgovarjal na vprašanja o sebi in obravnaval žaljiv ali vulgaren jezik?
Pomembno je razviti eksplicitne notranje smernice o vaši osebnosti, ki jih lahko uporabljajo označevalci podatkov in oblikovalci pogovorov. To vam bo omogočilo, da načrtujete svojo osebnost na namenski način in jo ohranite dosledno v vaši ekipi in skozi čas, saj je vaša aplikacija podvržena številnim ponovitvam in izboljšavam.
4.4 Kako pomagati pogovorom z »načelom sodelovanja«
Ali ste kdaj imeli vtis, da se pogovarjate z opečnim zidom, medtem ko ste dejansko govorili s človekom? Včasih ugotovimo, da naši sogovorniki preprosto niso zainteresirani za uspeh pogovora. Na srečo v večini primerov stvari potekajo bolj gladko in ljudje bodo intuitivno sledili »načelu sodelovanja«, ki ga je predstavil jezikovni filozof Paul Grice. V skladu s tem načelom ljudje, ki med seboj uspešno komuniciramo, sledimo štirim maksimom, in sicer količini, kakovosti, ustreznosti in načinu.
Maksimalna količina
Maksima kvantitete od govorca zahteva, da je informativen in da svoj prispevek naredi tako informativen, kot je potrebno. Na strani virtualnega pomočnika to pomeni tudi aktivno premikanje pogovora naprej. Na primer, razmislite o tem izrezku iz modne aplikacije za e-trgovino:
Pomočnik: Kakšna oblačila iščete?
Uporabnik: Iščem obleko v oranžni barvi.
Pomočnik: Ne: Oprostite, trenutno nimamo oranžnih oblek.
Do: Oprostite, nimamo oblek v oranžni barvi, imamo pa to odlično in zelo udobno obleko v rumeni barvi: …
Uporabnik upa, da bo vašo aplikacijo zapustil z ustreznim predmetom. Prekinitev pogovora, ker nimate elementov, ki bi ustrezali natančnemu opisu, uniči možnost uspeha. Če pa vaša aplikacija daje predloge o alternativnih elementih, bo videti bolj uporabna in pustila odprto možnost uspešne interakcije.
Zlasti pri glasovnih interakcijah je pomembno najti pravo ravnovesje med zagotavljanjem vseh informacij, ki jih uporabnik morda potrebuje za uspeh, hkrati pa jih ne zasipamo z nepotrebnimi informacijami, ki bi lahko zameglile interakcijo.
Maksimalna kakovost
Maksima kakovosti od govorcev zahteva, da so resnicoljubni in ne govorijo stvari, za katere menijo, da so lažne ali za katere nimajo ustreznih dokazov. Tukaj je vključenih veliko subjektivnosti in osebnega prepričanja - zato te maksime ni mogoče neposredno projicirati na LLM. Kot smo videli, so magistri nagnjeni k halucinacijam in to tveganje je še posebej veliko, ko pogovor zaide na manj poznana področja. Uporabite lahko dodatne zaščitne ograje, da se izognete zavajajočim izjavam in vrnete pogovor na pravo pot.
Maksima ustreznosti
Maksima ustreznosti od nas zahteva, da smo — no, ustrezni. Kot predpogoj mora virtualni pomočnik razumeti resnične namene uporabnika. Tukaj je primer letalskega pomočnika, ki krši to pravilo:
Uporabnik: Jutri zjutraj potrebujem let iz Berlina v Zürich.
Pomočnik: OK, našel sem naslednje lete iz Berlina v Zürich za jutri zjutraj. Let BZ36294 odpelje iz Berlina ob 6.30 zjutraj in prispe v Zürich ob 8. uri zjutraj. Let BZ96294 odpelje iz Berlina ob 8 in prispe ob 9.30. Let BZ96294 odpelje iz Berlina ob 8 in prispe v Zürich ob 9.30. Let BZ95614 odpelje iz Berlina ob 11 in prispe v Zürich ob 12.30. Obstaja tudi možnost povezovalnega leta, v tem primeru bi iz Berlina odšli ob 11.45 in prispeli v Zürich ob 3.
Uporabnik: Oprostite ... ali lahko to ponovite?
Pomočnik uporabnika zasipa s podrobnimi informacijami, ki morda niso pomembne. Če to razdelimo in uporabnika usmerimo k omejitvi prostora iskanja, postane dialog veliko lažje prebavljiv:
Uporabnik: Jutri zjutraj potrebujem let iz Berlina v Zürich.
Pomočnik: V redu, našel sem lete ob 6.30, 8. in 11. uri. Kdaj želite oditi?
Uporabnik: V Zürichu moram biti pred 9. uro zjutraj.
Pomočnik: V redu, lahko greste na let BZ36294. Odhod je ob 6.30 in prihod ob 8. Naj ti kupim karto?
Uporabnik: Ja, hvala.
Maksima manire
Nazadnje, načelo vedenja pravi, da morajo biti naša govorna dejanja jasna, jedrnata in urejena ter se izogibati dvoumnosti in nejasnosti izražanja. Vaš virtualni pomočnik se mora izogibati tehničnemu ali notranjemu žargonu in dati prednost preprostim, univerzalno razumljivim formulacijam.
Medtem ko Griceova načela veljajo za vse pogovore neodvisno od določene domene, jih LLM-ji, ki niso usposobljeni posebej za pogovor, pogosto ne izpolnjujejo. Zato je pri sestavljanju vaših podatkov o usposabljanju pomembno, da imate dovolj vzorcev dialogov, ki vašemu modelu omogočajo, da se nauči teh načel.
Področje konverzacijskega oblikovanja se precej hitro razvija. Ne glede na to, ali že gradite izdelke umetne inteligence ali razmišljate o svoji karierni poti v umetni inteligenci, vas spodbujam, da se poglobite v to temo (prim. odlične uvode v [5] in [6]). Ker se umetna inteligenca spreminja v blago, bosta dobra zasnova skupaj z ubranljivo podatkovno strategijo postala dva pomembna razlikovalna dejavnika za izdelke umetne inteligence.
Povzetek
Povzemimo ključne povzetke iz članka. Poleg tega slika 5 ponuja »goljufanje« z glavnimi točkami, ki jih lahko prenesete kot referenco.
- LLM-ji izboljšujejo pogovorno umetno inteligenco: veliki jezikovni modeli (LLM) so znatno izboljšali kakovost in razširljivost pogovornih aplikacij umetne inteligence v različnih panogah in primerih uporabe.
- Pogovorna umetna inteligenca lahko doda veliko vrednosti aplikacijam z veliko podobnimi uporabniškimi zahtevami (npr. storitve za stranke) ali ki potrebujejo dostop do velike količine nestrukturiranih podatkov (npr. upravljanje znanja).
- Podatki: Natančna nastavitev LLM-jev za pogovorne naloge zahteva visokokakovostne pogovorne podatke, ki natančno odražajo interakcije v resničnem svetu. Crowdsourcing in podatki, ustvarjeni z LLM, so lahko dragoceni viri za povečevanje zbiranja podatkov.
- Sestavljanje sistema: Razvoj pogovornih sistemov umetne inteligence je ponavljajoč se in eksperimentalen proces, ki vključuje stalno optimizacijo podatkov, strategije natančnega prilagajanja in integracijo komponent.
- Poučevanje konverzacijskih veščin za LLM: Natančna prilagoditev LLM vključuje njihovo usposabljanje za prepoznavanje in odzivanje na posebne komunikacijske namere in situacije.
- Dodajanje zunanjih podatkov s semantičnim iskanjem: Integracija zunanjih in notranjih virov podatkov z uporabo semantičnega iskanja izboljša odzive umetne inteligence z zagotavljanjem kontekstualno relevantnejših informacij.
- Zavedanje spomina in konteksta: Učinkoviti pogovorni sistemi morajo vzdrževati zavedanje konteksta, vključno s sledenjem zgodovini trenutnega pogovora in preteklih interakcij, da zagotovijo smiselne in skladne odzive.
- Postavitev zaščitnih ograj: Da bi zagotovili odgovorno vedenje, bi morali pogovorni sistemi AI uporabiti zaščitne ograje za preprečevanje netočnosti, halucinacij in kršitev zasebnosti.
- Oblikovanje osebnosti: Oblikovanje dosledne osebnosti vašega pogovornega pomočnika je bistvenega pomena za ustvarjanje kohezivne uporabniške izkušnje z blagovno znamko. Lastnosti osebnosti se morajo ujemati z lastnostmi vašega izdelka in blagovne znamke.
- Glas v primerjavi s klepetom: Izbira med vmesnikoma za glas in klepet je odvisna od dejavnikov, kot so fizična nastavitev, čustveni kontekst, funkcionalnost in izzivi oblikovanja. Upoštevajte te dejavnike, ko se odločate o vmesniku za svoj pogovorni AI.
- Integracija v različnih kontekstih: Pogovorno umetno inteligenco je mogoče integrirati v različne kontekste, vključno s kopiloti, sintetičnimi ljudmi, digitalnimi dvojčki in bazami podatkov, od katerih ima vsaka posebne primere uporabe in zahteve.
- Upoštevanje načela sodelovanja: upoštevanje načel količine, kakovosti, ustreznosti in načina v pogovorih lahko naredi interakcije s pogovorno umetno inteligenco bolj koristne in uporabniku prijaznejše.

Reference
[1] Heng-Tze Chen et al. 2022. LaMDA: Proti varnim, prizemljenim in visokokakovostnim modelom pogovorov za vse.
[2] OpenAI. 2022. ChatGPT: Optimizacija jezikovnih modelov za dialog. Pridobljeno dne 13. januar 2022.
[3] Patrick Lewis et al. 2020. Generacija z razširjenim iskanjem za NLP naloge, ki zahtevajo veliko znanja.
[4] Paul Grice. 1989. Študije na poti slov.
[5] Cathy Pearl. 2016. Oblikovanje glasovnih uporabniških vmesnikov.
[6] Michael Cohen et al. 2004. Oblikovanje glasovnega uporabniškega vmesnika.
Opomba: Vse slike so avtorske, razen če ni drugače navedeno.
Ta članek je bil prvotno objavljen na Proti znanosti o podatkih in z dovoljenjem avtorja ponovno objavljen v TOPBOTS.
Uživate v tem članku? Prijavite se za več posodobitev raziskav AI.
Obvestili vas bomo, ko bomo objavili več povzetkov, kot je ta.
Podobni
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://www.topbots.com/redefining-conversational-ai-with-large-language-models/
- :ima
- : je
- :ne
- :kje
- $GOR
- 1
- 10
- 11
- 110
- 12
- 125
- 13
- 14
- 17
- 200
- 2016
- 2020
- 2022
- 30
- 32
- 35%
- 41
- 65
- 7
- 70
- 8
- 9
- a
- sposobnosti
- sposobnost
- O meni
- absolutna
- Sprejmi
- sprejem
- dostop
- dostopna
- dostopen
- prilagoditi
- doseganje
- Po
- Račun
- Akumulirajte
- natančnost
- natančna
- čez
- Zakon
- aktivno
- dejavnosti
- dejavnost
- aktov
- dejansko
- dodajte
- dodajanje
- Dodatne
- Dodatne informacije
- Poleg tega
- Naslov
- Sprejetje
- napredek
- Prednost
- Prednosti
- svetuje
- po
- spet
- proti
- Agent
- agenti
- Avgust
- AI
- ai raziskave
- AI sistemi
- letalski prevoznik
- AL
- uskladiti
- poravnano
- vsi
- omogočajo
- omogoča
- skoraj
- skupaj
- že
- Prav tako
- alternativa
- alternative
- am
- Dvoumnost
- med
- an
- analizirati
- in
- anonimni
- Še ena
- pričakujte
- kaj
- aplikacija
- zdi
- uporaba
- aplikacije
- velja
- pristop
- primerno
- aplikacije
- SE
- območja
- okoli
- Prihaja
- Umetnost
- članek
- članki
- umetni
- AS
- vprašati
- sprašuje
- oceniti
- ocenili
- ocenjevanje
- sredstvo
- pomoč
- Pomočnik
- pomočniki
- povezan
- At
- Poskusi
- pozornosti
- lastnosti
- povečanje
- Povečana
- Avtor
- samodejno
- Na voljo
- izogniti
- izogibanje
- zavest
- stran
- nazaj
- nazaj na pravo pot
- Ravnovesje
- žoga
- baza
- temeljijo
- Osnovni
- BE
- ker
- postanejo
- postane
- bilo
- pred
- zadaj
- počutje
- prepričanje
- Verjemite
- ljubljeni
- koristi
- berlin
- BEST
- najboljše prakse
- Boljše
- med
- Poleg
- pristranskosti
- Bit
- blokiranje
- Knjiga
- tako
- bote
- Pasovi
- blagovne znamke
- blagovno znamko
- blagovne znamke
- kršitve
- Breaking
- prinašajo
- širši
- prinesel
- izgradnjo
- Zgradite chatbot
- Building
- zgrajena
- poslovni
- zaseden
- vendar
- Gumb
- gumbi
- nakup
- Nakup
- by
- se imenuje
- poziva
- prišel
- CAN
- prekinjeno
- ne more
- Zmogljivosti
- Kariera
- avtomobili
- primeru
- primeri
- Cathy
- center
- izziv
- izzivi
- izziv
- priložnost
- spremenilo
- Channel
- značaja
- lastnosti
- označuje
- chatbot
- klepetalnice
- ChatGPT
- chen
- otrok
- izbira
- možnosti
- izbiri
- jasno
- jasno
- Zapri
- tesno
- Oblačila
- Cloud
- Koda
- cohen
- KOHERENTNO
- kohezivni
- sodelovanje
- zbirka
- združujejo
- kako
- prihaja
- udobna
- blago
- komunicirajo
- Komunikacija
- Communications
- Podjetja
- podjetje
- v primerjavi z letom
- tekmujejo
- kompleksna
- komponenta
- deli
- Koncert
- zgoščeno
- Ravnanje
- povezane
- Povezovanje
- povezave
- Razmislite
- upoštevamo
- dosledno
- stalna
- nenehno
- gradnjo
- Gradbeništvo
- kontakt
- vsebina
- ozadje
- kontekstih
- kontekstualno
- stalno
- Naročilo
- kontrast
- prispevajo
- prispeva
- Prispevek
- sporen
- Pogovor
- pogovorni
- pogovorni AI
- Pogovorni vmesniki
- pogovorov
- kuhanje
- Cool
- sodelovanje
- zadruga
- Core
- Ustrezno
- bi
- par
- Tečaj
- zajeti
- ustvarjajo
- Ustvarjanje
- ustvarjalnost
- bitja
- verodostojno
- Merila
- crowdsourcing
- Trenutna
- Trenutno
- krivulja
- stranka
- Za stranke
- Pomoč strankam
- Stranke, ki so
- datum
- podatkovna strategija
- Baze podatkov
- baze podatkov
- mrtva
- ponudba
- desetletja
- odloča
- Odločanje
- odločitve
- globlje
- opredeliti
- vsekakor
- Stopnja
- zamuda
- odvisno
- opis
- Oblikovanje
- oblikovalec
- oblikovalci
- oblikovanje
- želeno
- podrobno
- Podrobnosti
- Razvoj
- razvili
- Razvijalci
- razvoju
- Razvoj
- naprava
- naprave
- Dialog
- Dialog
- drugačen
- diferenciator
- težko
- DIG
- prebaviti
- digitalni
- Digitalni dvojčki
- digitalni svet
- neposredno
- Odkritje
- zaslon
- distribucija
- potop
- do
- Dokumentacija
- Dokumenti
- ne
- Pes
- tem
- domena
- opravljeno
- dont
- Obsojen
- prenesi
- voznik
- 2
- med
- e
- e-trgovina
- E&T
- vsak
- lažje
- izobraževalne
- Učinkovito
- učinkovitosti
- učinkovite
- bodisi
- elementi
- vdelava
- pojavile
- pojav
- nastane
- Empatija
- Zaposleni
- opolnomočiti
- omogočanje
- spodbujanje
- konec
- prizadevanja
- Endless
- sodelovati
- Motorji
- okrepi
- izboljšave
- Izboljša
- prijetna
- dovolj
- obogatiti
- obogatena
- bogatenje
- zagotovitev
- Podjetje
- zlasti
- bistvena
- itd
- ocenjevanje
- Tudi
- sčasoma
- VEDNO
- dokazi
- točno
- Primer
- Primeri
- odlično
- Razen
- presežek
- razburjen
- zanimivo
- izvršiti
- obstoječih
- pričakovati
- Pričakuje
- drago
- izkušnje
- eksperimentalni
- Pojasnite
- Razlaga
- izraz
- zunanja
- Obraz
- Faktor
- tovarn
- dejavniki
- Dejansko
- FAIL
- ne uspe
- Napaka
- Falls
- false
- seznanjeni
- zanimivo
- Moda
- hitreje
- povratne informacije
- občutek
- Slika
- filter
- dokončati
- Najdi
- prva
- fit
- fiksna
- let
- Letalo
- Pretok
- Teče
- Tokovi
- Osredotočite
- sledi
- sledili
- po
- za
- obrazec
- formalno
- oblikovanje
- Na srečo
- Naprej
- je pokazala,
- štiri
- pogosto
- pogosto
- iz
- spredaj
- frustrirajoče
- Izpolnite
- zabava
- funkcionalnost
- temeljna
- nadalje
- Prihodnost
- igre na srečo
- vrzel
- zbiranje
- splošno
- splošno
- ustvarjajo
- generacija
- dobili
- GitHub
- dana
- Go
- goes
- dogaja
- dobro
- graphql
- veliko
- Zelen
- Igrišče
- Navodila
- vodi
- Smernice
- imel
- roke
- se zgodi
- se zgodi
- Trdi
- škodljiva
- Imajo
- he
- Zdravje
- slišati
- pomoč
- pomoč
- jo
- tukaj
- skrita
- visoka
- visoka kvaliteta
- več
- zelo
- njegov
- zgodovina
- hit
- celosten
- upam,
- upa
- HOT
- Kako
- Vendar
- HTML
- http
- HTTPS
- velika
- človeškega
- Ljudje
- Humor
- hype
- i
- idealno
- identifikatorji
- identificira
- if
- ponazarja
- slika
- slike
- Domišljija
- slika
- poglobljeno
- izvajali
- Pomembno
- izboljšalo
- izboljšanju
- in
- Poglobljena
- vključujejo
- Vključno
- vključi
- Povečajte
- neverjetno
- neodvisno
- individualna
- industrij
- povzročiti
- Podatki
- informativni
- inherentno
- začetna
- sproži
- vhodi
- Namesto
- integrirati
- integrirana
- Povezovanje
- integracija
- namen
- namerno
- interakcijo
- interakcije
- interakcije
- interaktivno
- Interaktivni glasovni sistemi
- zainteresirani
- vmesnik
- vmesniki
- notranji
- prepletena
- v
- uvesti
- Uvedeno
- Predstavitev
- Predstavitev
- intuitivno
- naložbe
- investicijska priporočila
- vključeni
- vključuje
- vključujejo
- izolacija
- vprašanje
- Vprašanja
- IT
- Izdelkov
- ponovitev
- ponovitve
- ITS
- sam
- IVR-ji
- januar
- žargon
- Job
- skupno
- jpg
- samo
- Imejte
- Ključne
- ključne besede
- Ubija
- Otrok
- Vedite
- znanje
- Upravljanje znanja
- znano
- Oznake
- labirint
- Pomanjkanje
- jezik
- jeziki
- velika
- obsežne
- večja
- Latenca
- pozneje
- odvetnik
- vodi
- Interesenti
- UČITE
- naučili
- učenje
- pustite
- odhodu
- Legacy
- Pravne informacije
- LEND
- manj
- Naj
- Stopnja
- ravni
- Vzvod
- finančni vzvod
- vzvod
- Lewis
- Knjižnica
- Leži
- kot
- LIMIT
- Limited
- jezikoslovje
- Poslušanje
- v živo
- Logika
- Long
- Poglej
- si
- POGLEDI
- izgube
- Sklop
- veliko
- stroj
- je
- Poštni
- Glavne
- vzdrževati
- vzdrževanje
- velika
- Znamka
- IZDELA
- Izdelava
- upravlja
- upravljanje
- upravljalni sistem
- Vodje
- Način
- več
- Tržna
- tržne priložnosti
- Stave
- ujema
- Material
- materiali
- max širine
- Maxim
- me
- pomeni
- smiselna
- pomeni
- mediji
- srednje
- srečanja
- člani
- Spomin
- duševne
- Duševno zdravje
- Metode
- Michael
- Microsoft
- morda
- milisekund
- minirano
- zavajajoče
- nesporazum
- Model
- modeli
- sodobna
- Trenutek
- mesecev
- razpoloženje
- moralna
- več
- učinkovitejše
- jutro
- Najbolj
- večinoma
- premikanje
- veliko
- več
- Množica
- morajo
- my
- jaz
- Ime
- in sicer
- naravna
- Naravni jezik
- Obdelava Natural Language
- potrebno
- nujnost
- Nimate
- potrebna
- potrebe
- negativna
- nikoli
- Novo
- nova aplikacija
- Naslednja
- nlp
- št
- netehnično
- Noben
- Običajno
- opozoriti
- Pojem
- zdaj
- Nuance
- Številka
- številne
- Nutshell
- predmet
- Cilj
- predmeti
- of
- off
- ponudba
- ponujen
- Ponudbe
- Office
- pogosto
- on
- enkrat
- ONE
- samo
- odprite
- OpenAI
- deluje
- operacije
- Mnenje
- Priložnosti
- Priložnost
- optimizacija
- Optimizirajte
- optimizirana
- optimizacijo
- Možnost
- možnosti
- or
- Oranžna
- Da
- originalno
- Ostalo
- drugi
- drugače
- naši
- ven
- izhodi
- zunaj
- več
- pretirano
- velika
- lastne
- Stran
- članki
- paradigma
- partnerji
- zabava
- opravil
- preteklosti
- Patenti
- pot
- potrpežljivo
- Patrick
- vzorci
- paul
- ljudje
- za
- zaznati
- opravlja
- Dovoljenje
- oseba
- Osebni
- Osebnost
- Osebno
- Peter
- fizično
- kramp
- slike
- pii
- pitching
- Kraj
- Plain
- načrtovanje
- platon
- Platonova podatkovna inteligenca
- PlatoData
- igranje
- Točka
- točke
- slaba
- pop
- Popular
- Stališče
- pozitiven
- možnost
- mogoče
- potencial
- potencialno
- praksa
- vaje
- napoved
- nastavitve
- predstavljeni
- preprečiti
- Načelo
- Načela
- zasebnost
- zasebna
- nadaljujte
- Postopek
- obdelani
- Procesi
- obravnavati
- Proizvedeno
- Izdelek
- Izdelki
- strokovni
- Profili
- Programiranje
- napovedane
- ugledni
- spodbuja
- protokol
- zagotavljajo
- zagotavlja
- zagotavljanje
- Psihologija
- javnega
- objavljeno
- Namen
- Push
- potiska
- kakovost
- Količina
- poizvedbe
- vprašanja
- hitro
- uvrstitev
- Lestvica
- precej
- reakcija
- pripravljen
- pravo
- resnični svet
- Reality
- Priznanje
- priznajo
- prepoznavanje
- Priporočila
- ponavljajoče se
- Rdeča
- Ponovna opredelitev
- zmanjša
- glejte
- reference
- reference
- besedilu
- nanaša
- odražajo
- odseva
- okrepljeno učenje
- povezane
- sprostitev
- ustreznost
- pomembno
- zanašanje
- ostajajo
- ponovite
- nadomesti
- odgovori
- zahteva
- zahteva
- obvezna
- Zahteve
- zahteva
- Raziskave
- spominja
- Resolucija
- viri
- Odzove
- odziva
- Odgovor
- odgovorov
- odgovorna
- restavracija
- rezultat
- Rezultati
- razkrivajo
- Rich
- Pravica
- Tveganje
- Pravilo
- pravila
- Run
- varna
- Varnost
- Je dejal
- Enako
- Zadovoljstvo
- shranjena
- pravijo,
- Prilagodljivost
- Lestvica
- skaliranje
- znanstveno
- Obseg
- rezultati
- Zaslon
- Iskalnik
- drugi
- sekund
- Oddelek
- glej
- videl
- občutljiva
- Serija
- Storitev
- nastavite
- nastavitev
- nastavitve
- več
- shouldnt
- Prikaži
- pokazale
- Razstave
- strani
- podpisati
- bistveno
- Podoben
- Enostavno
- preprostost
- saj
- Sedenje
- Razmere
- situacije
- spretnosti
- majhna
- bolj gladko
- delček
- So
- socialna
- družite se
- Soft
- prodaja
- Rešitev
- rešitve
- nekaj
- nekdo
- Nekaj
- Včasih
- Kmalu
- Viri
- Vesolje
- razponi
- govorijo
- Zvočniki
- zvočniki
- gledano
- specializirani
- specifična
- posebej
- specifičnosti
- govor
- Prepoznavanje govora
- hitrost
- SQL
- Začetek
- začel
- začne
- Izjava
- Izjave
- Države
- postaja
- Statistično
- bivanje
- usmerjanje
- krmiljenje
- volan
- Korak
- Koraki
- Še vedno
- ustavljanje
- shranjeni
- Zgodba
- naravnost
- strategije
- Strategija
- racionalizirati
- stres
- Struktura
- strukturirano
- Študije
- slog
- precejšen
- uspeh
- uspešno
- Uspešno
- taka
- Predlaga
- primerna
- apartma
- Povzamemo
- POVZETEK
- podpora
- Preverite
- swing
- Preklop
- simbolična
- sintaksa
- sintetična
- sistem
- sistemi
- miza
- Bodite
- Takeaways
- Pogovor
- pogovor
- Pipe
- ciljna
- Cilji
- Naloga
- Naloge
- učil
- poučevanje
- skupina
- Člani ekipe
- tehnični
- tehnika
- Tehnologija
- telezdravja
- Pogoji
- ozemelj
- Testiranje
- besedilo
- kot
- hvala
- da
- O
- Prihodnost
- informacije
- svet
- njihove
- Njih
- sami
- POTEM
- Tukaj.
- te
- jih
- stvari
- mislim
- Razmišljanje
- tretja
- ta
- tisti,
- 3
- skozi
- Tako
- Vstopnica
- vstopnice
- čas
- krat
- do
- skupaj
- žeton
- jutri
- TONE
- tudi
- orodja
- TOPBOTI
- temo
- proti
- proti
- sledenje
- Sledenje
- Trgovanje
- tradicionalna
- Vlak
- usposobljeni
- usposabljanje
- Transform
- preoblikovati
- Prehod
- prehodi
- posredujejo
- sprožilo
- Res
- poskusite
- OBRAT
- Obračalni
- zavoji
- Twins
- dva
- tipičen
- ui
- podvrže
- razumeli
- razumljivo
- razumevanje
- edinstven
- Universal
- splošno
- up-to-date
- posodobitve
- posodabljanje
- us
- uporabnost
- uporaba
- Rabljeni
- uporabnik
- Uporabniška izkušnja
- Uporabniški vmesnik
- oblikovanje uporabniškega vmesnika
- Uporabniku prijazen
- Uporabniki
- uporablja
- uporabo
- ux
- UX design
- oblikovalec ux
- ux oblikovalci
- veljavno
- dragocene
- vrednost
- raznolikost
- različnih
- vsestranski
- Proti
- zelo
- preko
- Žrtva
- Virtual
- virtualni asistent
- Navidezna resničnost
- Voice
- Glasovni asistent
- vs
- vulgarno
- W3
- Wall
- želeli
- želi
- je
- valovi
- način..
- načini
- we
- Wealth
- Spletna stran
- spletne strani
- Dobro
- so bili
- Kaj
- Kaj je
- Kolo
- kdaj
- kadar koli
- ali
- ki
- medtem
- WHO
- zakaj
- bo
- okna
- z
- brez
- besede
- delo
- delavci
- svet
- zaskrbljujoče
- bi
- pisati
- leto
- let
- rumene
- jo
- mladi
- Vaša rutina za
- zefirnet
- Zurich



