29. januar je državni dan ugank in ob praznovanju smo ustvarili zabaven blog, ki podrobno opisuje, kako rešiti sudoku z uporabo umetne inteligence (AI).
Predstavitev
pred wordleje Sudoku uganka je bil v modi in je še vedno zelo priljubljen. V zadnjih letih je uporaba optimizacija metode za reševanje uganke so bile prevladujoča tema. glej »Reševanje sudokuja z optimizacijo v Arkievi".
V sedanjih časih je uporaba umetne inteligence osredotočena na strojno učenje, ki zajema široko paleto metod od laso regresije do učenja z okrepitvijo. Uporaba AI ima ponovno spominjal lotiti se kompleksa razporejanje izzivi. Ena metoda, iskanje s sledenjem nazaj, se pogosto uporablja in je popolna za Sudoku.
Ta blog bo podroben opis uporabe te metode za reševanje Sudokuja. Izkazalo se je, da je »sledenje nazaj« mogoče najti v motorjih za optimizacijo in strojno učenje ter je temelj napredne hevristike, ki jo Arkieva uporablja za razporejanje. Algoritem je implementiran v »Array Programming Language«, funkcijsko usmerjenem programskem jeziku, ki obravnava bogat nabor matričnih struktur.
Osnove sudokuja
Iz Wikipedije: Sudoku je uganka, ki temelji na logiki, kombinatorični postavitvi številk. Cilj je zapolniti mrežo 9 × 9 s številkami, tako da vsak stolpec, vsaka vrstica in vsaka od devetih podmrež 3 × 3, ki sestavljajo mrežo (imenovane tudi »škatle«, »bloki«, »regije«, ali »podkvadrati«) vsebuje vse števke od 1 do 9. Sestavljalec uganke nudi delno izpolnjeno mrežo, ki ima običajno edinstveno rešitev. Dokončane uganke so vedno tip latinskega kvadrata z dodatno omejitvijo vsebine posameznih regij. Na primer, isto eno celo število se ne sme pojaviti dvakrat v isti vrstici ali stolpcu igralne plošče 9×9 ali v kateri koli od devetih podregij 3×3 igralne plošče 9×9.
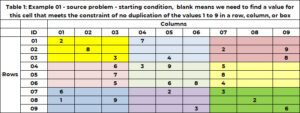
Tabela 1 ima primer težave. Obstaja 9 vrstic in 9 stolpcev za skupno 81 celic. Vsakemu je dovoljeno, da ima eno in samo eno od devetih celih števil med 1 in 9. V začetni rešitvi ima celica eno samo vrednost – ki vrednost v tej celici popravi na to vrednost, ali pa je celica prazna, kar pomeni, da potrebujemo da poiščete vrednost za to celico. Celica (1,1) ima vrednost 2, celica (6,5) pa vrednost 6. Celica (1,2) in celica (2,3) sta prazni in algoritem bo našel vrednost za ti celici.
Zaplet
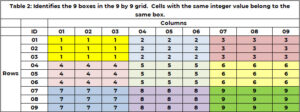
Poleg tega, da celica pripada eni in samo eni vrstici in stolpcu, celica pripada enemu in samo 1 polju. Obstaja 9 polj, ki so označena z barvo v tabeli 1. Tabela 2 uporablja edinstveno celo število med 1 in 9 za identifikacijo vsakega polja ali mreže. Celice z vrednostjo vrstice (1, 2 ali 3) in vrednostjo stolpca (1, 2 ali 3) pripadajo polju 1. Polje 6 so vrednosti vrstic (4, 5, 6) in vrednosti stolpcev (7, 8 , 9). ID polja je določen s formulo BOX_ID = {3x(floor((ROW_ID-1) /3)} + strop (COL_ID/3). Za celico (5,7) je 6 = 3x(floor(5-1 ))/3) + strop (8/3)= 3×1 + 3 = 3+3.
Srce uganke
Za iskanje ene cele vrednosti med 1 in 9 za vsako neznano celico, tako da so cela števila od 1 do 9 uporabljena enkrat in samo enkrat za vsak stolpec, vsako vrstico in vsako polje.
Poglejmo celico (1,3), ki je prazna. Vrstica 1 že ima vrednosti 2 in 7. Ti v tej celici niso dovoljeni. Stolpec 3 že ima vrednosti 3, 5,6, 7,9. Te niso dovoljene. Polje 1 (rumeno) ima vrednosti 2, 3 in 8. Te niso dovoljene. Naslednje vrednosti niso dovoljene (2,7); (3, 5, 6, 7, 9); (2, 3, 8). Enolične vrednosti, ki niso dovoljene, so (2, 3, 5, 6, 7, 8, 9). Edine možne vrednosti so (1,4).
Pristop k rešitvi bi bil, da celici (1) začasno dodelite 1,3 in nato poskusite najti možne vrednosti za drugo celico.
Rešitev za vračanje nazaj: zagon komponent
Struktura polja
Začetno mesto je odločitev o matrični strukturi za shranjevanje izvorne težave in podporo iskanju. Tabela 3 ima to matrično strukturo. Stolpec 1 je edinstven celoštevilski ID za vsako celico. Vrednosti segajo od 1 do 81. Stolpec 2 je ID vrstice celice. Stolpec 3 je ID stolpca celice. Stolpec 4 je ID polja. Stolpec 5 je vrednost v celici. Upoštevajte, da ima celica brez vrednosti vrednost nič namesto prazne ali ničelne vrednosti. To ohranja to "matriko samo celih števil" - veliko boljša za zmogljivost.

V APL bi bilo to polje shranjeno v 2-dimenzionalnem polju, katerega oblika je 81 krat 5. Predpostavimo, da so elementi tabele 3 shranjeni v spremenljivki MAT. Primeri funkcij so:
Ukaz MAT[1 2 3;]zgrabi prve 3 vrstice MAT
1 1 1 1 2
2 1 2 1 0
3 1 3 1 0
MAT[1 2 3; 4 5] zavaruje vrstice 1, 2, 3 in samo stolpca 4 in 5
1
1
1
(MAT[;5]=0)/MAT[;1] najde vse celice, ki potrebujejo vrednost.
VSTAVITE TABELO 3
Preverjanje razumnosti: Dvojniki
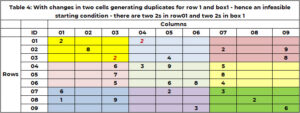
Pred začetkom iskanja je ključnega pomena, da preverite razum! To je izhodiščna izvedljiva rešitev. Izvedljivo za sudoku, če so zdaj dvojniki v kateri koli vrstici, stolpcu ali polju. Trenutna izhodiščna rešitev, na primer 1, je izvedljiva. V tabeli 4 je primer, kjer ima začetna rešitev dvojnike. Vrstica 1 ima dve vrednosti 2. Območje 1 ima dve vrednosti 2. Funkcija »SANITY_DUPE« obravnava to logiko.
Preverjanje pravilnosti: možnosti za celice brez vrednosti
Zelo koristen podatek bi bile vse možne vrednosti za celico brez vrednosti. Če ni kandidatov, potem ta uganka ni rešljiva. Celica ne more prevzeti vrednosti, ki jo že zahteva njena soseda. Če uporabimo tabelo 1 za celico (1,3,'1' – ta zadnja 1 je boxid), so njeni sosedje vrstica 1, stolpec 3 in polje 1. Vrstica 1 ima vrednosti (2,7); stolpec 3 ima vrednosti (3,5,6,7,9); polje 1 ima vrednosti (2,3,8). Celica (1,3.1) ne more sprejeti naslednjih vrednosti (2,3,5,6,7,8,9). Edine možnosti za celico (1,3,1) so (1,4). Za celico (4,1,2) so vrednosti 1, 2, 3, 5, 6, 7, 9 že uporabljene v vrstici 4, stolpcu 1 in/ali polju 4. Edine možne vrednosti so (4,8) . Funkcija “SANITY_CAND” obravnava to logiko.
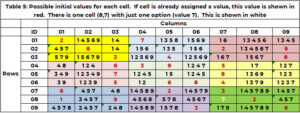
Tabela 5 prikazuje kandidate, na primer 1 na začetku iskanja. Če je bila celici že dodeljena vrednost v začetnih pogojih (tabela 1), se ta vrednost ponovi in prikaže rdeče. Če ima celica, ki potrebuje vrednost, samo eno možnost, je ta prikazana belo. Celica (8,7,9) ima eno samo vrednost 7 v beli barvi. (2,5,8,4,3) zahteva sosednji stolpec 7. (1, 2, 9) vrstica 8. (3,2,6) polje 9. Samo vrednost 7 ni zahtevana.
Preverjanje zdravega razuma: iskanje konfliktov
Informacije, ki identificirajo vse možnosti za celice, ki potrebujejo vrednost (objavljene v tabeli 4), nam omogočajo, da prepoznamo konflikt, preden začnemo postopek iskanja. Do spora pride, ko imata dve celici, ki potrebujeta vrednost, samo enega kandidata, vrednost kandidata je enaka in sta celici sosednji. Iz tabele 4 vemo, da je edina celica, ki potrebuje vrednost in ima samo enega kandidata, celica (8,7,9). Na primer 1, ni konflikta.
Kaj bi bil konflikt? Če je bila edina možna vrednost za celico (3,7,3) 7 (namesto 1, 6, 7), potem obstaja spor. Celica (8,7) in celica (3,7) sta sosedi – isti stolpec. Vendar, če bi bila edina možna vrednost za celico (4,9,2) 7 (namesto 1, 2, 7), to ne bi bilo spor. Te celice niso sosede.
Povzetek preverjanja razumnosti
- Če obstajajo dvojniki, izhodiščna rešitev ni izvedljiva.
- Če celica, ki potrebuje vrednost, nima nobenega kandidata, potem ni možne rešitve te uganke. Seznam kandidatnih vrednosti za vsako celico je mogoče uporabiti za zmanjšanje iskalnega prostora – tako za sledenje nazaj kot za optimizacijo.
- Sposobnost iskanja konfliktov ugotavlja, da uganka ni izvedljiva – nima rešitve – brez postopka iskanja. Poleg tega identificira "problematične celice".
Rešitev za sledenje nazaj: proces iskanja
Z vzpostavljenimi osnovnimi podatkovnimi strukturami in preverjanjem zdravega razuma pozornost usmerjamo na postopek iskanja. Ponavljajoča se tema je ponovno vzpostavitev podatkovnih struktur za podporo iskanju.
Sledenje iskanju
Niz Tracker spremlja opravljene naloge
- Stolpec 1 je števec
- Stolpec 2 je število možnosti, ki so na voljo za dodelitev tej celici
- 1 pomeni, da je na voljo 1 možnost, 2 pomeni dve možnosti itd.
- 0 pomeni – možnost ni na voljo ali ponastavitev na 0 (ni dodeljene vrednosti) in sledenje nazaj
- Stolpec 3 je celica, ki ji je dodeljena številka indeksa vrednosti (1 do 81)
- Stolpec 4 je vrednost, dodeljena celici v zgodovini poti
- Vrednost 9999 pomeni, da je bila ta celica takrat, ko je bila najdena slepa ulica
- Vrednost celega števila med 1 in vključno 9 je dodeljena vrednost tej celici na tej točki v procesu iskanja.
- Vrednost 0 pomeni, da ta celica potrebuje dodelitev
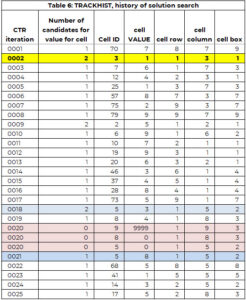
Niz sledilnikov se uporablja za podporo procesu iskanja. Niz TRACKHIST ima enako strukturo kot sledilnik, vendar hrani zgodovino celotnega postopka iskanja. Tabela 6 ima del TRACKHIST za primer 1. Podrobneje je razložen v kasnejšem razdelku.
Poleg tega niz PAV (vektor vektorja), spremlja predhodno dodeljene vrednosti tej celici. To zagotavlja, da ne bomo ponovno pregledali neuspešne rešitve – podobno, kot je storjeno v TABU.
Obstaja izbirni postopek dnevnika, kjer iskalni postopek zapiše vsak korak.
Zagon iskanja
Ko smo opravili knjigovodstvo in preverjanje razumnosti, lahko začnemo postopek iskanja. Koraki so:
- Ali so ostale celice, ki potrebujejo vrednost? – če ne, potem smo končali.
- Za vsako celico, ki potrebuje vrednost, poiščite vse možne možnosti za vsako celico. Tabela 4 vsebuje te vrednosti na začetku postopka reševanja. Pri vsaki ponovitvi se to posodobi, da se prilagodi vrednostim, dodeljenim celicam.
- Ocenite možnosti v tem vrstnem redu.
- Če ima celica NIČ možnosti, potem vvedite sledenje nazaj
- Poiščite vse celice z eno možnostjo, izberite eno od teh celic, naredite to dodelitev,
- in posodobite tabelo za sledenje, trenutno rešitev in PAV.
- Če imajo vse celice več kot eno možnost, izberite eno celico in eno vrednost ter posodobite
- in posodobite tabelo za sledenje, trenutno rešitev in PAV
Za ponazoritev vsakega koraka bomo uporabili tabelo 6, ki je del zgodovine procesa rešitve (imenovan TRACKHIST).
V prvi ponovitvi (CTR=1) je izbrana celica 70 (vrstica 8, stolpec 7, polje 9), ki ji je dodeljena vrednost. Obstaja le kandidat (7) in ta vrednost je dodeljena celici 70. Poleg tega je vrednost 7 dodana vektorju predhodno dodeljenih vrednosti (PAV) za celico 70.
V drugi ponovitvi je celici 30 dodeljena vrednost 1. Ta celica je imela dve kandidatni vrednosti. Najmanjša vrednost kandidata je dodeljena celici (samo poljubno pravilo, da je logiki enostavno slediti).
Postopek identifikacije celice, ki potrebuje vrednost, in dodeljevanja vrednosti deluje dobro do ponovitve (CTR) 20. Celica 9 potrebuje vrednost, vendar je število kandidatov NIČ. Obstajata dve možnosti:
- Za to uganko ni rešitve.
- Razveljavimo (vrnemo nazaj) nekatere naloge in uberemo drugo pot.
Poiskali smo dodelitev celice, ki je najbližja tej, kjer je bilo več kot ena možnost. V tem primeru se je to zgodilo pri iteraciji 18, kjer je celici 5 dodeljena vrednost 3, vendar sta bili za celico 5 dve možni vrednosti – vrednosti 3 in 8.
Med celico 5 (CTR = 18) in celico 9 (CTR = 20) je celici 8 dodeljena vrednost 4 (CTR = 19). Celici 8 in 5 vrnemo na seznam »potrebujemo vrednost«. To je zajeto v drugem in tretjem vnosu CTR=20, kjer je vrednost nastavljena na 0. Vrednost 3 se ohrani v vektorju PAV za celico 5. To pomeni, da iskalnik ne more dodeliti vrednosti 3 celici 5.
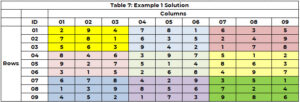
Iskalnik se znova zažene, da identificira vrednost za celico 5 (pri čemer 3 ni več možnost) in dodeli vrednost 8 celici 5 (CTR=21). Nadaljuje se, dokler vse celice nimajo vrednosti ali je celica brez možnosti in ni poti za vračanje nazaj. Rešitev je objavljena v tabeli 7.
Opazujte, če je več kot en kandidat za celico, je to možnost za vzporedno obdelavo.
Primerjava z MILP Optimization Solution
Na površinski ravni je predstavitev sudokuja dramatično drugačna. Pristop umetne inteligence uporablja cela števila in je po vseh merilih strožja in bolj intuitivna predstavitev. Poleg tega preverjevalci razumnosti nudijo koristne informacije za izdelavo močnejše formulacije. Predstavitev MILP je neskončna binarne datoteke (0/1). Vendar pa so binarne datoteke močne predstavitve glede na moč sodobnih reševalcev MILP.
Vendar interno reševalec MILP ne hrani binarnih datotek, ampak uporablja metodo redke matrike, da odpravi shranjevanje vseh ničel. Poleg tega se algoritmi za reševanje binarnih datotek pojavijo šele v osemdesetih in devetdesetih letih prejšnjega stoletja. Dokument iz leta 1980 Crowder, Johnson in Padberg poroča o eni prvih praktičnih rešitev optimizacije z binarnimi datotekami. Opozarjajo na pomen pametne predobdelave ter razvejanih in vezanih metod kot ključnega pomena za uspešno rešitev.
Nedavna eksplozija uporabe omejitvenega programiranja in programske opreme, kot je npr lokalni reševalec je jasno pokazal pomen uporabe metod umetne inteligence z izvirnimi optimizacijskimi metodami, kot sta linearno programiranje in najmanjši kvadrati.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://blog.arkieva.com/an-artificial-intelligence-based-solution-to-sudoku/?utm_source=rss&utm_medium=rss&utm_campaign=an-artificial-intelligence-based-solution-to-sudoku
- :ima
- : je
- :ne
- :kje
- $GOR
- 1
- 20
- 29
- 30
- 31
- 600
- 7
- 70
- 8
- 9
- a
- sposobnost
- prilagoditi
- dodano
- Poleg tega
- Dodatne
- Poleg tega
- napredno
- spet
- AI
- algoritem
- algoritmi
- vsi
- dovoljene
- že
- Prav tako
- vedno
- Amazon
- an
- in
- Še ena
- kaj
- zdi
- pristop
- samovoljna
- SE
- OBMOČJE
- Array
- umetni
- Umetna inteligenca
- Umetna inteligenca (AI)
- AS
- dodeljena
- domnevati
- At
- pozornosti
- Na voljo
- nazaj
- BE
- bilo
- pred
- pripadnosti
- pripada
- med
- prazno
- Blog
- svet
- tako
- zavezuje
- Pasovi
- škatle
- Branch
- vendar
- by
- se imenuje
- CAN
- Kandidat
- kandidati
- ne more
- Zajeto
- strop
- Praznovanje
- celica
- Celice
- izzivi
- priložnost
- preveriti
- preverjanje
- trdil,
- jasno
- barva
- Stolpec
- Stolpci
- pogosto
- Končana
- kompleksna
- Pogoji
- konflikt
- Konflikti
- Vsebuje
- Vsebina
- se nadaljuje
- Core
- kamen
- ustvaril
- kritično
- Trenutna
- datum
- dan
- mrtva
- odloča
- opis
- Podatki
- podrobno
- Podrobnosti
- določi
- drugačen
- števk
- do
- ne
- prevladujoč
- opravljeno
- dont
- dramatično
- dvojnikov
- vsak
- lahka
- bodisi
- elementi
- odpravo
- pojavljajo
- omogoča
- zajema
- konec
- Endless
- Motor
- Motorji
- zagotavlja
- Celotna
- itd
- Primer
- razložiti
- eksplozija
- ni uspelo
- daleč
- izvedljivo
- izpolnite
- Najdi
- najdbe
- konec
- prva
- popravke
- osredotočena
- sledi
- po
- za
- Formula
- formulacija
- je pokazala,
- iz
- zabava
- funkcija
- funkcije
- pridobivanje
- dana
- Mreža
- imel
- Ročaji
- Imajo
- Srce
- pomoč
- zgodovina
- Kako
- Kako
- Vendar
- HTML
- HTTPS
- ID
- identificira
- identificirati
- identifikacijo
- if
- ilustrirajte
- izvajali
- Pomembnost
- in
- Vključno
- Indeks
- naveden
- označuje
- individualna
- Podatki
- obvešča
- v notranjosti
- Namesto
- Inštitut
- Intelligence
- interno
- intuitivno
- IT
- ponovitev
- ITS
- Johnson
- jpg
- samo
- Imejte
- hranijo
- Vedite
- jezik
- Zadnja
- pozneje
- Latinski
- učenje
- vsaj
- levo
- Stopnja
- linearna
- Seznam
- prijavi
- Logika
- več
- Poglej
- Pogledal
- si
- stroj
- strojno učenje
- je
- Znamka
- max širine
- Maj ..
- pomeni
- merjenje
- Metoda
- Metode
- sodobna
- več
- nacionalni
- Nimate
- potrebe
- sosedi
- devet
- št
- Upoštevajte
- zdaj
- Številka
- Cilj
- opazujejo
- zgodilo
- of
- on
- enkrat
- ONE
- samo
- optimizacija
- Možnost
- možnosti
- or
- Da
- izvirno
- naši
- ven
- Papir
- vzporedno
- del
- pot
- popolna
- performance
- kos
- Kraj
- platon
- Platonova podatkovna inteligenca
- PlatoData
- igranje
- Točka
- Popular
- mogoče
- objavljene
- močan
- Praktično
- prej
- problem
- Postopek
- obravnavati
- Programiranje
- zagotavljajo
- zagotavlja
- dal
- puzzle
- Uganke
- Rage
- območje
- nedavno
- ponavljajoče se
- Rdeča
- zmanjša
- regije
- regresija
- okrepljeno učenje
- ponovi
- Poročila
- zastopanje
- ROW
- Pravilo
- Enako
- razporejanje
- Iskalnik
- iskalnik
- drugi
- Oddelek
- Varno
- glej
- izberite
- izbran
- nastavite
- Oblikujte
- pokazale
- Razstave
- Podoben
- sam
- So
- Software
- Rešitev
- rešitve
- SOLVE
- nekaj
- vir
- Vesolje
- kvadrat
- kvadratov
- Začetek
- Začetek
- začne
- Korak
- Koraki
- Še vedno
- trgovina
- shranjeni
- moč
- močnejši
- Struktura
- strukture
- uspešno
- taka
- superior
- podpora
- Površina
- miza
- reševanje
- Bodite
- kot
- da
- O
- Vir
- tema
- POTEM
- Tukaj.
- te
- jih
- tretja
- ta
- tesnejši
- krat
- do
- Skupaj za plačilo
- sledenje
- Sledenje
- poskusite
- OBRAT
- zavoji
- Dvakrat
- dva
- tip
- tipično
- edinstven
- neznan
- dokler
- Nadgradnja
- posodobljeno
- us
- uporaba
- Rabljeni
- uporablja
- uporabo
- vrednost
- Vrednote
- spremenljivka
- zelo
- je
- we
- so bili
- Kaj
- Kaj je
- kdaj
- ki
- bele
- široka
- Širok spekter
- Wikipedia
- bo
- z
- brez
- deluje
- bi
- let
- rumene
- zefirnet
- nič