Slike, ki jih frimufilmi on Freepik
To je obdobje, v katerem preboji umetne inteligence prihajajo vsak dan. Pred nekaj leti v javnosti nismo imeli veliko umetne inteligence, zdaj pa je tehnologija dostopna vsem. Odličen je za številne posamezne ustvarjalce ali podjetja, ki želijo znatno izkoristiti tehnologijo za razvoj nečesa zapletenega, kar lahko traja dolgo časa.
Eden najbolj neverjetnih prebojev, ki spremenijo naše delo, je izdaja GPT-3.5 model OpenAI. Kaj je model GPT-3.5? Če pustim, da model govori sam zase. V tem primeru je odgovor "zelo napreden model umetne inteligence na področju obdelave naravnega jezika z velikimi izboljšavami pri ustvarjanju kontekstualno natančnega in ustreznega besedilat ".
OpenAI ponuja API za model GPT-3.5, ki ga lahko uporabimo za razvoj preproste aplikacije, kot je povzemalnik besedila. Da bi to naredili, lahko uporabimo Python za brezhibno integracijo API-ja modela v predvideno aplikacijo. Kako izgleda postopek? Pojdimo vanj.
Preden sledite tej vadnici, morate izpolniti nekaj predpogojev, vključno z:
– Poznavanje Pythona, vključno z znanjem uporabe zunanjih knjižnic in IDE
– Razumevanje API-jev in ravnanje s končno točko s Pythonom
– Dostop do API-jev OpenAI
Za pridobitev dostopa do API-jev OpenAI se moramo registrirati na Platforma za razvijalce OpenAI in obiščite Ogled ključev API v svojem profilu. V spletu kliknite gumb »Ustvari nov skrivni ključ«, da pridobite dostop do API-ja (glejte sliko spodaj). Ne pozabite shraniti ključev, saj jim po tem ključi ne bodo več prikazani.

Slika avtorja
Z vsemi pripravljenimi pripravami poskusimo razumeti osnove modela API-jev OpenAI.
O Družinski model GPT-3.5 je bil določen za številne jezikovne naloge in vsak model v družini je odličen pri nekaterih nalogah. Za ta primer vadnice bi uporabili gpt-3.5-turbo saj je bil priporočljiv trenutni model, ko je bil ta članek napisan zaradi njegove zmogljivosti in stroškovne učinkovitosti.
Pogosto uporabljamo text-davinci-003 v vadnici OpenAI, vendar bi za to vadnico uporabili trenutni model. Zanesli bi se na ChatCompletion končna točka namesto zaključka, ker je trenutni priporočeni model model klepeta. Tudi če je bilo ime model klepeta, deluje za katero koli jezikovno nalogo.
Poskusimo razumeti, kako deluje API. Najprej moramo namestiti trenutne pakete OpenAI.
pip install openai
Ko končamo z namestitvijo paketa, bomo poskusili uporabiti API s povezavo prek končne točke ChatCompletion. Vendar pa moramo nastaviti okolje, preden nadaljujemo.
V vašem najljubšem IDE (zame je to VS Code) ustvarite dve datoteki, imenovani .env in summarizer_app.py, podobno kot na spodnji sliki.
Slika avtorja
O summarizer_app.py kjer bi zgradili našo preprosto aplikacijo za povzemanje in .env datoteka, kamor bi shranili naš ključ API. Iz varnostnih razlogov je vedno priporočljivo, da ključ API-ja ločite v drugi datoteki, namesto da bi ga trdo kodirali v datoteki Python.
v .env vnesite naslednjo sintakso in shranite datoteko. Zamenjajte your_api_key_here s svojim dejanskim ključem API. Ne spreminjajte ključa API v objekt niza; naj bodo tako kot je.
OPENAI_API_KEY=your_api_key_here
Za boljše razumevanje GPT-3.5 API; za ustvarjanje besede summarizer bi uporabili naslednjo kodo.
openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, top_p=0.5, frequency_penalty=0.5, messages=[ { "role": "system", "content": "You are a helpful assistant for text summarization.", }, { "role": "user", "content": f"Summarize this for a {person_type}: {prompt}", }, ],
)
Zgornja koda prikazuje našo interakcijo z modelom API-jev OpenAI GPT-3.5. Z API-jem ChatCompletion ustvarimo pogovor in po preteku poziva dobimo želeni rezultat.
Razčlenimo vsak del, da jih bomo bolje razumeli. V prvi vrstici uporabljamo openai.ChatCompletion.create kodo za ustvarjanje odgovora iz poziva, ki bi ga posredovali v API.
V naslednji vrstici imamo hiperparametre, ki jih uporabljamo za izboljšanje besedilnih nalog. Tukaj je povzetek vsake funkcije hiperparametra:
model: Modelna družina, ki jo želimo uporabiti. V tej vadnici uporabljamo trenutno priporočeni model (gpt-3.5-turbo).max_tokens: Zgornja meja besed, ki jih ustvari model. Pomaga omejiti dolžino ustvarjenega besedila.temperature: Naključnost izhoda modela z višjo temperaturo pomeni bolj raznolik in ustvarjalen rezultat. Razpon vrednosti je med 0 in neskončnostjo, čeprav vrednosti, večje od 2, niso običajne.top_p: Top P ali top-k vzorčenje ali vzorčenje jedra je parameter za nadzor skupine vzorčenja iz izhodne porazdelitve. Na primer, vrednost 0.1 pomeni, da model vzorči samo rezultat iz zgornjih 10 % distribucije. Razpon vrednosti je bil med 0 in 1; višje vrednosti pomenijo bolj raznolik rezultat.frequency_penalty: Kazen za žeton ponavljanja iz izhoda. Razpon vrednosti med -2 in 2, pri čemer bi pozitivne vrednosti modelu onemogočile ponavljanje žetona, medtem ko bi negativne vrednosti spodbudile model k uporabi več ponavljajočih se besed. 0 pomeni brez kazni.messages: Parameter, kamor posredujemo naš besedilni poziv, ki ga je treba obdelati z modelom. Posredujemo seznam slovarjev, kjer je ključ objekt vloge (bodisi »sistem«, »uporabnik« ali »pomočnik«), ki pomaga modelu razumeti kontekst in strukturo, medtem ko so vrednosti kontekst.- »Sistem« vlog je nastavljena smernica za model vedenja »pomočnika«,
- Vloga »uporabnik« predstavlja poziv osebe, ki komunicira z modelom,
- Vloga "pomočnik" je odgovor na poziv "uporabnik".
Ko smo razložili zgornji parameter, lahko vidimo, da je messages zgornji parameter ima dva slovarska predmeta. Prvi slovar je, kako smo model postavili kot povzemalnik besedila. Drugi je kraj, kjer bi posredovali naše besedilo in dobili izhod povzetka.
V drugem slovarju boste videli tudi spremenljivko person_type in prompt. person_type je spremenljivka, ki sem jo uporabil za nadzor sloga povzetka, ki ga bom pokazal v vadnici. Medtem ko je prompt kjer bi posredovali svoje besedilo, da ga povzamemo.
Nadaljujte z vadnico, postavite spodnjo kodo v summarizer_app.py in poskusili bomo pregledati, kako deluje spodnja funkcija.
import openai
import os
from dotenv import load_dotenv load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY") def generate_summarizer( max_tokens, temperature, top_p, frequency_penalty, prompt, person_type,
): res = openai.ChatCompletion.create( model="gpt-3.5-turbo", max_tokens=100, temperature=0.7, top_p=0.5, frequency_penalty=0.5, messages= [ { "role": "system", "content": "You are a helpful assistant for text summarization.", }, { "role": "user", "content": f"Summarize this for a {person_type}: {prompt}", }, ], ) return res["choices"][0]["message"]["content"]
V zgornji kodi ustvarimo funkcijo Python, ki bi sprejela različne parametre, o katerih smo že razpravljali, in vrnila izhod povzetka besedila.
Preizkusite zgornjo funkcijo s svojim parametrom in si oglejte rezultat. Nato nadaljujmo z vadnico za ustvarjanje preproste aplikacije s paketom streamlit.
Poenostavljeno je odprtokodni paket Python, zasnovan za ustvarjanje spletnih aplikacij za strojno učenje in podatkovno znanost. Je enostaven za uporabo in intuitiven, zato ga priporočajo številnim začetnikom.
Preden nadaljujemo z vadnico, namestimo paket streamlit.
pip install streamlit
Ko je namestitev končana, vstavite naslednjo kodo v summarizer_app.py.
import streamlit as st #Set the application title
st.title("GPT-3.5 Text Summarizer") #Provide the input area for text to be summarized
input_text = st.text_area("Enter the text you want to summarize:", height=200) #Initiate three columns for section to be side-by-side
col1, col2, col3 = st.columns(3) #Slider to control the model hyperparameter
with col1: token = st.slider("Token", min_value=0.0, max_value=200.0, value=50.0, step=1.0) temp = st.slider("Temperature", min_value=0.0, max_value=1.0, value=0.0, step=0.01) top_p = st.slider("Nucleus Sampling", min_value=0.0, max_value=1.0, value=0.5, step=0.01) f_pen = st.slider("Frequency Penalty", min_value=-1.0, max_value=1.0, value=0.0, step=0.01) #Selection box to select the summarization style
with col2: option = st.selectbox( "How do you like to be explained?", ( "Second-Grader", "Professional Data Scientist", "Housewives", "Retired", "University Student", ), ) #Showing the current parameter used for the model with col3: with st.expander("Current Parameter"): st.write("Current Token :", token) st.write("Current Temperature :", temp) st.write("Current Nucleus Sampling :", top_p) st.write("Current Frequency Penalty :", f_pen) #Creating button for execute the text summarization
if st.button("Summarize"): st.write(generate_summarizer(token, temp, top_p, f_pen, input_text, option))
Poskusite zagnati naslednjo kodo v ukaznem pozivu, da zaženete aplikacijo.
streamlit run summarizer_app.py
Če vse deluje dobro, boste v privzetem brskalniku videli naslednjo aplikacijo.
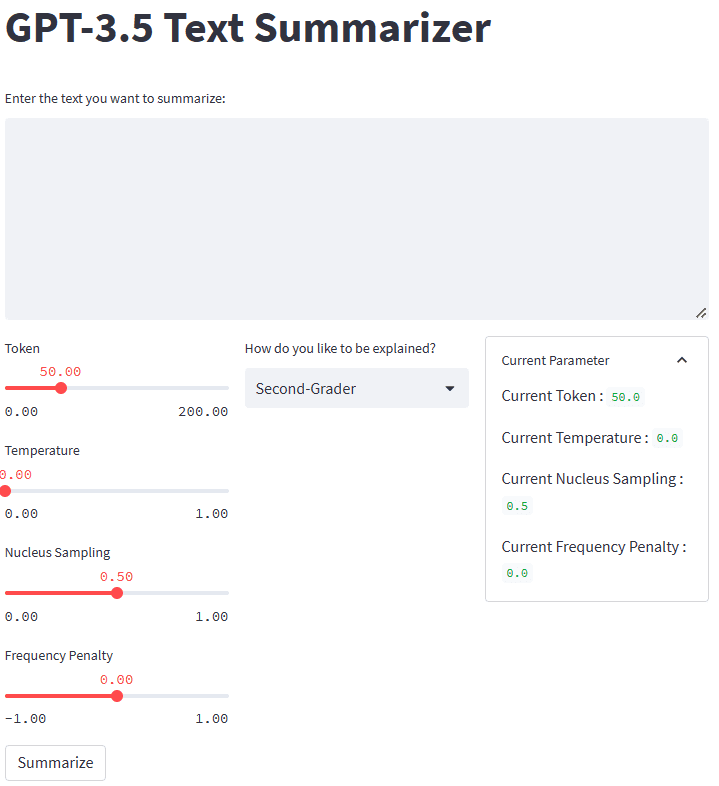
Slika avtorja
Torej, kaj se je zgodilo v zgornji kodi? Naj na kratko razložim vsako funkcijo, ki smo jo uporabili:
.st.title: Vnesite besedilo naslova spletne aplikacije..st.write: zapiše argument v aplikacijo; lahko je karkoli, razen v glavnem nizovno besedilo..st.text_area: Zagotovite območje za vnos besedila, ki ga je mogoče shraniti v spremenljivko in uporabiti za poziv za naš povzemalnik besedila.st.columns: Vsebniki predmetov za zagotavljanje interakcije drug ob drugem..st.slider: Zagotovite gradnik drsnika z nastavljenimi vrednostmi, s katerimi lahko uporabnik komunicira. Vrednost je shranjena v spremenljivki, ki se uporablja kot parameter modela..st.selectbox: Zagotovite izbirni pripomoček za uporabnike, da izberejo slog povzemanja, ki ga želijo. V zgornjem primeru uporabljamo pet različnih stilov..st.expander: Zagotovite vsebnik, ki ga lahko uporabniki razširijo in zadržijo več predmetov..st.button: Zagotovite gumb, ki zažene predvideno funkcijo, ko ga uporabnik pritisne.
Ker bi streamlit samodejno oblikoval uporabniški vmesnik, ki sledi dani kodi od zgoraj navzdol, bi se lahko bolj osredotočili na interakcijo.
Z vsemi deli na mestu poskusimo našo aplikacijo za povzemanje s primerom besedila. Za naš primer bi uporabil Stran Wikipedije o teoriji relativnosti besedilo, ki ga je treba povzeti. S privzetim parametrom in slogom drugorazrednika dobimo naslednji rezultat.
Albert Einstein was a very smart scientist who came up with two important ideas about how the world works. The first one, called special relativity, talks about how things move when there is no gravity. The second one, called general relativity, explains how gravity works and how it affects things in space like stars and planets. These ideas helped us understand many things in science, like how particles interact with each other and even helped us discover black holes!
Morda boste dobili drugačen rezultat od zgornjega. Poskusimo v slogu gospodinj in nekoliko prilagodimo parameter (žeton 100, temperatura 0.5, vzorčenje jedra 0.5, kazen frekvence 0.3).
The theory of relativity is a set of physics theories proposed by Albert Einstein in 1905 and 1915. It includes special relativity, which applies to physical phenomena without gravity, and general relativity, which explains the law of gravitation and its relation to the forces of nature. The theory transformed theoretical physics and astronomy in the 20th century, introducing concepts like 4-dimensional spacetime and predicting astronomical phenomena like black holes and gravitational waves.
Kot lahko vidimo, obstaja razlika v slogu za isto besedilo, ki ga ponujamo. S pozivom za spremembo in parametrom je lahko naša aplikacija bolj funkcionalna.
Celoten videz naše aplikacije za povzemanje besedila lahko vidite na spodnji sliki.
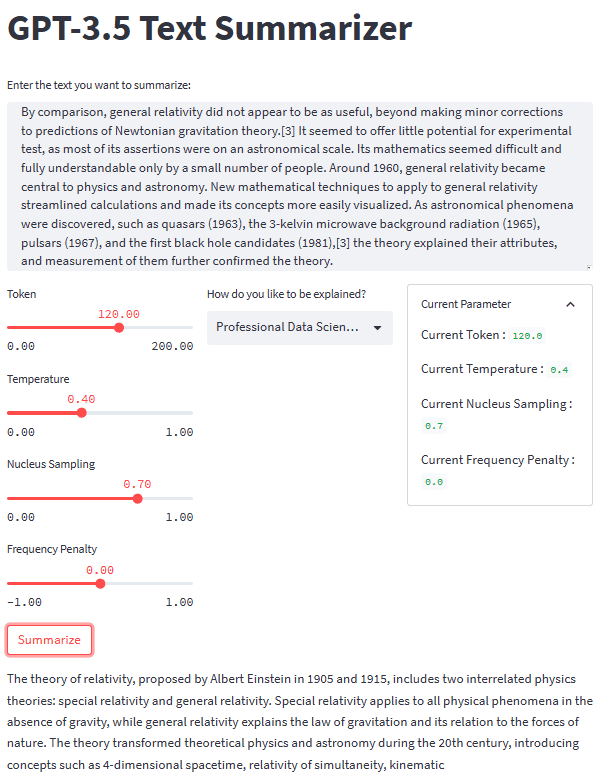
Slika avtorja
To je vadnica o ustvarjanju razvoja aplikacije za povzemanje besedila z GPT-3.5. Aplikacijo bi lahko še bolj prilagodili in jo uvedli.
Generativni AI je v porastu in morali bi izkoristiti priložnost z ustvarjanjem fantastične aplikacije. V tej vadnici se bomo naučili, kako delujejo API-ji GPT-3.5 OpenAI in kako jih uporabiti za ustvarjanje aplikacije za povzemanje besedila s pomočjo Pythona in paketa streamlit.
Cornellius Yudha Wijaya je vodja podatkovne znanosti in pisec podatkov. Medtem ko dela s polnim delovnim časom pri Allianz Indonesia, rad deli nasvete o Pythonu in podatkih prek družbenih medijev in pisnih medijev.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. Dostopite tukaj.
- vir: https://www.kdnuggets.com/2023/04/text-summarization-development-python-tutorial-gpt35.html?utm_source=rss&utm_medium=rss&utm_campaign=text-summarization-development-a-python-tutorial-with-gpt-3-5
- : je
- ][str
- $GOR
- 1
- 100
- 28
- 7
- a
- O meni
- nad
- Sprejmi
- dostop
- dostopen
- natančna
- pridobiti
- napredno
- Prednost
- po
- AI
- vsi
- Allianz
- Čeprav
- vedno
- in
- Še ena
- odgovor
- API
- Dostop do API-ja
- API-ji
- aplikacija
- uporaba
- Razvoj aplikacij
- aplikacije
- SE
- OBMOČJE
- Argument
- članek
- AS
- Pomočnik
- astronomija
- At
- samodejno
- Osnovni
- BE
- ker
- pred
- Začetniki
- spodaj
- Boljše
- med
- Bit
- črna
- črne luknje
- Bottom
- Pasovi
- Break
- preboj
- preboji
- Na kratko
- brskalnik
- izgradnjo
- Gumb
- by
- se imenuje
- CAN
- primeru
- Stoletje
- spremenite
- možnosti
- klik
- Koda
- Stolpci
- prihajajo
- Skupno
- Podjetja
- dokončanje
- kompleksna
- koncepti
- Povezovanje
- Posoda
- Zabojniki
- vsebina
- ozadje
- naprej
- nadzor
- Pogovor
- bi
- ustvarjajo
- Ustvarjanje
- Creative
- Ustvarjalci
- Trenutna
- vsak dan
- datum
- znanost o podatkih
- podatkovni znanstvenik
- privzeto
- razporedi
- Oblikovanje
- zasnovan
- Razvoj
- Razvojni
- Razvoj
- Razlika
- drugačen
- odkriti
- razpravljali
- distribucija
- razne
- dont
- navzdol
- vsak
- bodisi
- spodbujanje
- Končna točka
- Vnesite
- okolje
- Era
- Eter (ETH)
- Tudi
- vsi
- vse
- Primer
- odlično
- izvršiti
- Razširi
- Pojasnite
- razložiti
- Pojasni
- zunanja
- družina
- fantastičen
- Priljubljeni
- Nekaj
- Polje
- file
- datoteke
- prva
- Osredotočite
- po
- za
- sile
- frekvenca
- iz
- funkcija
- funkcionalno
- nadalje
- splošno
- ustvarjajo
- ustvarila
- ustvarjajo
- dobili
- dana
- gravitacijsko
- Gravitacijski valovi
- teža
- Smernice
- Ravnanje
- se je zgodilo
- Imajo
- ob
- pomoč
- pomagal
- pomoč
- Pomaga
- tukaj
- več
- zelo
- držite
- Luknje
- Kako
- Kako
- Kako delamo
- Vendar
- HTTPS
- i
- Ideje
- slika
- uvoz
- Pomembno
- izboljšanje
- Izboljšave
- in
- vključuje
- Vključno
- Neverjetno
- individualna
- Indonezija
- neskončnost
- sproži
- vhod
- namestitev
- Namestitev
- Namesto
- integrirati
- interakcijo
- medsebojno delovanje
- interakcije
- Predstavljamo
- intuitivno
- IT
- ITS
- jpg
- KDnuggets
- Ključne
- tipke
- znanje
- jezik
- zakon
- UČITE
- učenje
- dolžina
- knjižnice
- kot
- LIMIT
- vrstica
- Seznam
- Long
- dolgo časa
- Poglej
- izgleda kot
- stroj
- strojno učenje
- upravitelj
- več
- pomeni
- mediji
- Sporočilo
- morda
- Model
- več
- Najbolj
- premikanje
- več
- Ime
- naravna
- Naravni jezik
- Obdelava Natural Language
- Narava
- Nimate
- negativna
- Novo
- Naslednja
- predmet
- predmeti
- pridobi
- of
- on
- ONE
- open source
- OpenAI
- Priložnost
- Možnost
- OS
- Ostalo
- izhod
- Splošni
- paket
- pakete
- parameter
- parametri
- del
- Podaje
- oseba
- fizično
- Fizika
- kosov
- Kraj
- Planeti
- platon
- Platonova podatkovna inteligenca
- PlatoData
- bazen
- pozitiven
- napovedovanje
- predpogoji
- prej
- Postopek
- obravnavati
- strokovni
- profil
- predlagano
- zagotavljajo
- zagotavlja
- javnega
- dal
- Python
- naključnost
- območje
- precej
- pripravljen
- Razlogi
- priporočeno
- Registracija
- Razmerje
- sprostitev
- pomembno
- ne pozabite
- ponavljajoč
- zamenjajte
- predstavlja
- Odgovor
- povzroči
- vrnitev
- narašča
- vloga
- Run
- Enako
- Shrani
- Znanost
- Znanstvenik
- brez težav
- drugi
- skrivnost
- Oddelek
- varnost
- izbor
- ločena
- nastavite
- Delite s prijatelji, znanci, družino in partnerji :-)
- shouldnt
- Prikaži
- pokazale
- bistveno
- Podoben
- Enostavno
- Drsnik
- pametna
- So
- socialna
- družbeni mediji
- nekaj
- Nekaj
- Vesolje
- posebna
- določeno
- Stars
- trgovina
- shranjeni
- String
- Struktura
- študent
- slog
- stili
- taka
- Povzamemo
- POVZETEK
- sintaksa
- sistem
- Bodite
- Pogovor
- pogovori
- Naloga
- Naloge
- Tehnologija
- da
- O
- zakon
- svet
- Njih
- sami
- Teoretični
- te
- stvari
- 3
- skozi
- čas
- nasveti
- Naslov
- do
- žeton
- vrh
- preoblikovati
- Navodila
- ui
- razumeli
- razumevanje
- univerza
- us
- uporaba
- uporabnik
- Uporabniki
- uporabiti
- vrednost
- Vrednote
- različnih
- Popravljeno
- preko
- Poglej
- obisk
- vs
- proti kodi
- valovi
- web
- Spletna aplikacija
- Dobro
- Kaj
- Kaj je
- ki
- medtem
- WHO
- Wikipedia
- bo
- z
- v
- brez
- beseda
- besede
- delo
- deluje
- deluje
- svet
- bi
- Pisatelj
- pisanje
- pisni
- let
- Vaša rutina za
- zefirnet