Veliki jezikovni modeli (LLM) postajajo vse bolj priljubljeni, pri čemer se nenehno raziskujejo novi primeri uporabe. Na splošno lahko izdelate aplikacije, ki jih poganjajo LLM, tako da v svojo kodo vključite hitro inženirstvo. Vendar pa obstajajo primeri, ko poziv obstoječemu LLM ne uspe. Tu lahko pomaga fina nastavitev modela. Pri hitrem inženiringu gre za usmerjanje izhodnih podatkov modela z oblikovanjem vhodnih pozivov, medtem ko pri natančnem uravnavanju gre za usposabljanje modela na naborih podatkov po meri, da postane bolj primeren za posebne naloge ali domene.
Preden lahko natančno prilagodite model, morate najti nabor podatkov, specifičen za nalogo. En nabor podatkov, ki se pogosto uporablja, je Nabor podatkov skupnega pajkanja. Korpus Common Crawl vsebuje petabajte podatkov, ki se redno zbirajo od leta 2008, in vsebuje neobdelane podatke spletnih strani, izvlečke metapodatkov in izvlečke besedila. Poleg določanja, kateri niz podatkov je treba uporabiti, je potrebno čiščenje in obdelava podatkov glede na posebne potrebe natančnega prilagajanja.
Nedavno smo sodelovali s stranko, ki je želela predhodno obdelati podmnožico najnovejšega nabora podatkov Common Crawl in nato natančno prilagoditi svoj LLM s prečiščenimi podatki. Stranka je iskala, kako bi lahko to dosegla na najbolj stroškovno učinkovit način na AWS. Po razpravi o zahtevah smo priporočili uporabo Amazon EMR brez strežnika kot njihovo platformo za predhodno obdelavo podatkov. EMR Serverless je zelo primeren za obsežno obdelavo podatkov in odpravlja potrebo po vzdrževanju infrastrukture. Kar zadeva stroške, se zaračunava samo glede na vire in trajanje, uporabljeno za vsako opravilo. Stranka je lahko z EMR Serverless vnaprej obdelala na stotine TB podatkov v enem tednu. Ko so podatke predhodno obdelali, so jih uporabili Amazon SageMaker za natančno nastavitev LLM.
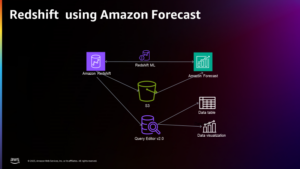
V tej objavi vas popeljemo skozi strankin primer uporabe in uporabljeno arhitekturo.
V naslednjih razdelkih najprej predstavimo nabor podatkov Common Crawl ter kako raziskati in filtrirati podatke, ki jih potrebujemo. Amazonska Atena zaračuna samo velikost podatkov, ki jih skenira, in se uporablja za hitro raziskovanje in filtriranje podatkov, hkrati pa je stroškovno učinkovit. EMR Serverless ponuja stroškovno učinkovito možnost brez vzdrževanja za obdelavo podatkov Spark in se uporablja za obdelavo filtriranih podatkov. Nato uporabimo Amazon SageMaker JumpStart za natančno nastavitev Model Llama 2 s predhodno obdelanim naborom podatkov. SageMaker JumpStart ponuja nabor rešitev za najpogostejše primere uporabe, ki jih je mogoče namestiti z le nekaj kliki. Za natančno nastavitev LLM-ja, kot je Llama 2, vam ni treba napisati kode. Na koncu uvedemo natančno nastavljen model z Amazon SageMaker in primerjajte razlike v izpisu besedila za isto vprašanje med originalnim in natančno nastavljenim modelom Llama 2.
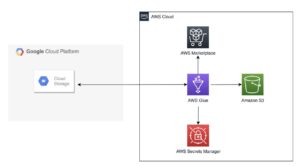
Naslednji diagram prikazuje arhitekturo te rešitve.
Preden se poglobite v podrobnosti rešitve, dokončajte naslednje predpogojne korake:
Common Crawl je nabor odprtih korpusnih podatkov, pridobljen s pajkanjem več kot 50 milijard spletnih strani. Vključuje ogromne količine nestrukturiranih podatkov v več jezikih, začenši od leta 2008 do petabajtne ravni. Nenehno se posodablja.
Pri usposabljanju GPT-3 nabor podatkov Common Crawl predstavlja 60 % podatkov o usposabljanju, kot je prikazano v naslednjem diagramu (vir: Jezikovni modeli se učijo le malo posnetkov).
Drug pomemben nabor podatkov, ki ga je vredno omeniti, je nabor podatkov C4. C4, okrajšava za Colossal Clean Crawled Corpus, je nabor podatkov, ki izhaja iz naknadne obdelave nabora podatkov Common Crawl. V dokumentu LLaMA družbe Meta so orisali uporabljene nize podatkov, pri čemer Common Crawl predstavlja 67 % (uporablja 3.3 TB podatkov) in C4 15 % (uporablja 783 GB podatkov). Članek poudarja pomen vključevanja različno vnaprej obdelanih podatkov za izboljšanje učinkovitosti modela. Kljub temu, da so izvirni podatki C4 del Common Crawl, se je Meta odločila za ponovno obdelano različico teh podatkov.
V tem razdelku pokrivamo običajne načine za interakcijo, filtriranje in obdelavo nabora podatkov Common Crawl.
Nabor neobdelanih podatkov Common Crawl vključuje tri vrste podatkovnih datotek: neobdelane podatke spletnih strani (WARC), metapodatke (WAT) in ekstrakcijo besedila (WET).
Podatki, zbrani po letu 2013, so shranjeni v formatu WARC in vključujejo ustrezne metapodatke (WAT) in podatke o ekstrakciji besedila (WET). Nabor podatkov se nahaja v Amazon S3, posodablja se mesečno in je do njega mogoče neposredno dostopati AWS Marketplace.
$ aws s3 ls s3://commoncrawl/crawl-data/CC-MAIN-2023-23/
PRE segments/
2023-06-21 00:34:08 2164 cc-index-table.paths.gz
2023-06-21 00:34:08 637 cc-index.paths.gz
2023-06-21 05:52:05 2724 index.html
2023-06-21 00:34:09 161064 non200responses.paths.gz
2023-06-21 00:34:10 160888 robotstxt.paths.gz
2023-06-21 00:34:10 480 segment.paths.gz
2023-06-21 00:34:11 161082 warc.paths.gz
2023-06-21 00:34:12 160895 wat.paths.gz
2023-06-21 00:34:12 160898 wet.paths.gzNabor podatkov Common Crawl ponuja tudi indeksno tabelo za filtriranje podatkov, ki se imenuje cc-index-table.
cc-index-table je indeks obstoječih podatkov, ki zagotavlja indeks datotek WARC na osnovi tabele. Omogoča preprosto iskanje informacij, na primer katera datoteka WARC ustreza določenemu URL-ju.
Ustvarite lahko na primer tabelo Athena za preslikavo podatkov cc-index z naslednjo kodo:
Prejšnji stavki SQL prikazujejo, kako ustvariti tabelo Athena, dodati particije in zagnati poizvedbo.
Filtrirajte podatke iz nabora podatkov Common Crawl
Kot lahko vidite iz stavka SQL za ustvarjanje tabele, obstaja več polj, ki lahko pomagajo filtrirati podatke. Na primer, če želite pridobiti število kitajskih dokumentov v določenem obdobju, je lahko stavek SQL naslednji:
Če želite izvesti nadaljnjo obdelavo, lahko rezultate shranite v drugo vedro S3.
Analizirajte filtrirane podatke
O Repozitorij Common Crawl GitHub ponuja več primerov PySpark za obdelavo neobdelanih podatkov.
Poglejmo primer teka server_count.py (primer skripta, ki ga zagotavlja repo Common Crawl GitHub) o podatkih, ki se nahajajo v s3://commoncrawl/crawl-data/CC-MAIN-2023-23/segments/1685224643388.45/warc/.
Najprej potrebujete okolje Spark, kot je EMR Spark. Na primer, lahko zaženete Amazon EMR v gruči EC2 us-east-1 (ker je nabor podatkov v us-east-1). Uporaba EMR v gruči EC2 vam lahko pomaga pri izvedbi preizkusov, preden pošljete opravila v produkcijsko okolje.
Po zagonu EMR v gruči EC2 se morate prijaviti s SSH v primarno vozlišče gruče. Nato zapakirajte okolje Python in pošljite skript (glejte Conda dokumentacija za namestitev Miniconde):
Obdelava vseh sklicev v warc.path lahko traja nekaj časa. Za predstavitvene namene lahko izboljšate čas obdelave z naslednjimi strategijami:
- Prenesite datoteko
s3://commoncrawl/crawl-data/CC-MAIN-2023-23/warc.paths.gzna vaš lokalni računalnik, ga razpakirajte in nato naložite v HDFS ali Amazon S3. To je zato, ker datoteke .gzip ni mogoče razdeliti. Za vzporedno obdelavo te datoteke jo morate razpakirati. - Spremeni
warc.pathdatoteko, izbrišite večino njenih vrstic in obdržite samo dve vrstici, da bo delo potekalo veliko hitreje.
Ko je delo končano, lahko vidite rezultat v s3://xxxx-common-crawl/output/, v formatu Parket.
Izvedite prilagojeno logiko posedovanja
Repo Common Crawl GitHub zagotavlja skupen pristop za obdelavo datotek WARC. Na splošno lahko razširite CCSparkJob za preglasitev posamezne metode (process_record), kar zadostuje za številne primere.
Oglejmo si primer, da dobimo ocene najnovejših filmov na IMDB. Najprej morate filtrirati datoteke na spletnem mestu IMDB:
Nato lahko dobite sezname datotek WARC, ki vsebujejo podatke o ocenah IMDB, in shranite imena datotek WARC kot seznam v besedilni datoteki.
Lahko pa uporabite EMR Spark, da pridobite seznam datotek WARC in ga shranite v Amazon S3. Na primer:
Izhodna datoteka bi morala biti podobna s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txt.
Naslednji korak je ekstrahiranje mnenj uporabnikov iz teh datotek WARC. Lahko podaljšate CCSparkJob preglasiti process_record() metoda:
Prejšnji skript lahko shranite kot imdb_extractor.py, ki ga boste uporabili v naslednjih korakih. Ko pripravite podatke in skripte, lahko uporabite EMR Serverless za obdelavo filtriranih podatkov.
EMR brez strežnika
EMR Serverless je možnost uvedbe brez strežnika za izvajanje aplikacij za analitiko velikih podatkov z uporabo odprtokodnih okvirov, kot sta Apache Spark in Hive, brez konfiguriranja, upravljanja in skaliranja gruč ali strežnikov.
Z EMR Serverless lahko izvajate analitične delovne obremenitve v katerem koli obsegu s samodejnim skaliranjem, ki spremeni velikost virov v nekaj sekundah, da ustreza spreminjajočim se količinam podatkov in zahtevam obdelave. EMR Serverless samodejno poveča in zmanjša vire, da zagotovi pravo količino zmogljivosti za vašo aplikacijo, vi pa plačate samo tisto, kar porabite.
Obdelava nabora podatkov Common Crawl je na splošno enkratna obdelava, zaradi česar je primerna za delovne obremenitve brez strežnika EMR.
Ustvarite aplikacijo EMR Serverless
Aplikacijo EMR Serverless lahko ustvarite na konzoli EMR Studio. Izvedite naslednje korake:
- Na konzoli EMR Studio izberite Aplikacije pod Brez strežnika v podoknu za krmarjenje.
- Izberite Ustvari aplikacijo.

- Vnesite ime za aplikacijo in izberite različico Amazon EMR.

- Če je potreben dostop do virov VPC, dodajte prilagojeno omrežno nastavitev.

- Izberite Ustvari aplikacijo.
Vaše brezstrežniško okolje Spark bo nato pripravljeno.
Preden lahko pošljete opravilo EMR Spark Serverless, morate še vedno ustvariti izvršilno vlogo. Nanašati se na Kako začeti z Amazon EMR Serverless Za več podrobnosti.
Obdelajte podatke skupnega pajkanja z EMR Serverless
Ko je vaša aplikacija EMR Spark Serverless pripravljena, dokončajte naslednje korake za obdelavo podatkov:
- Pripravite okolje Conda in ga naložite v Amazon S3, ki bo uporabljeno kot okolje v EMR Spark Serverless.
- Naložite skripte za izvajanje v vedro S3. V naslednjem primeru sta dva skripta:
- imbd_extractor.py – Prilagojena logika za pridobivanje vsebine iz nabora podatkov. Vsebino lahko najdete prej v tej objavi.
- cc-pyspark/sparkcc.py – Primer ogrodja PySpark iz Common Crawl GitHub repo, ki jih je treba vključiti.
- Pošljite opravilo PySpark v EMR Serverless Spark. Definirajte naslednje parametre za izvajanje tega primera v vašem okolju:
- id-aplikacije – ID aplikacije vaše aplikacije EMR Serverless.
- izvršitvena-vloga-arn – Vaša vloga izvajanja EMR Serverless. Če ga želite ustvariti, glejte Ustvarite vlogo izvajalnega časa opravila.
- Lokacija datoteke WARC – Lokacija vaših datotek WARC.
s3://xxxx-common-crawl/warclist/imdb_warclist/part-00000-6af12797-0cdc-4ef2-a438-cf2b935f2ffd-c000.txtvsebuje seznam filtriranih datotek WARC, ki ste ga pridobili prej v tej objavi. - spark.sql.skladišče.dir – Privzeta lokacija skladišča (uporabite imenik S3).
- iskra.arhiv – Lokacija S3 pripravljenega okolja Conda.
- spark.submit.pyFiles – Pripravljen skript PySpark sparkcc.py.
Glej naslednjo kodo:
Ko je opravilo končano, se izvlečene ocene shranijo v Amazon S3. Če želite preveriti vsebino, lahko uporabite Amazon S3 Select, kot je prikazano na naslednjem posnetku zaslona.
Premisleki
Pri delu z ogromnimi količinami podatkov s kodo po meri je treba upoštevati naslednje:
- Nekatere knjižnice Python drugih proizvajalcev morda niso na voljo v Condi. V takih primerih lahko preklopite na virtualno okolje Python, da zgradite izvajalno okolje PySpark.
- Če je treba obdelati ogromno podatkov, poskusite ustvariti in uporabiti več aplikacij EMR Serverless Spark, da jih vzporedite. Vsaka aplikacija obravnava podmnožico seznamov datotek.
- Pri filtriranju ali obdelavi podatkov Common Crawl lahko naletite na težavo z upočasnitvijo Amazon S3. To je zato, ker je vedro S3, v katerem so shranjeni podatki, javno dostopno in drugi uporabniki lahko istočasno dostopajo do podatkov. Če želite ublažiti to težavo, lahko dodate mehanizem za ponovni poskus ali sinhronizirate določene podatke iz vedra Common Crawl S3 v svoje vedro.
Natančno nastavite Llamo 2 s SageMakerjem
Ko so podatki pripravljeni, lahko z njimi natančno prilagodite model Llama 2. To lahko storite z uporabo SageMaker JumpStart, ne da bi pisali kodo. Za več informacij glejte Natančno nastavite Llama 2 za ustvarjanje besedila na Amazon SageMaker JumpStart.
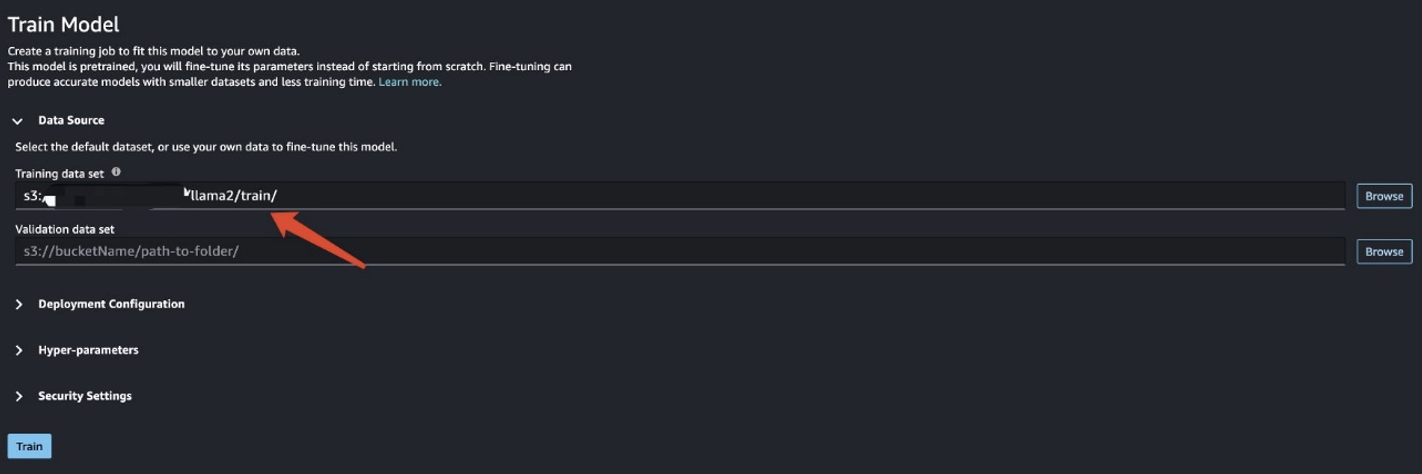
V tem scenariju izvedete natančno prilagoditev domene. Pri tem naboru podatkov je vnos datoteka CSV, JSON ali TXT. Vse podatke pregleda morate spraviti v datoteko TXT. Če želite to narediti, lahko oddate preprosto Spark opravilo EMR Spark Serverless. Oglejte si naslednji vzorčni delček kode:
Ko pripravite podatke o vadbi, vnesite lokacijo podatkov za Nabor podatkov o usposabljanju, nato izberite Vlak.
Lahko spremljate status delovnega mesta za usposabljanje.
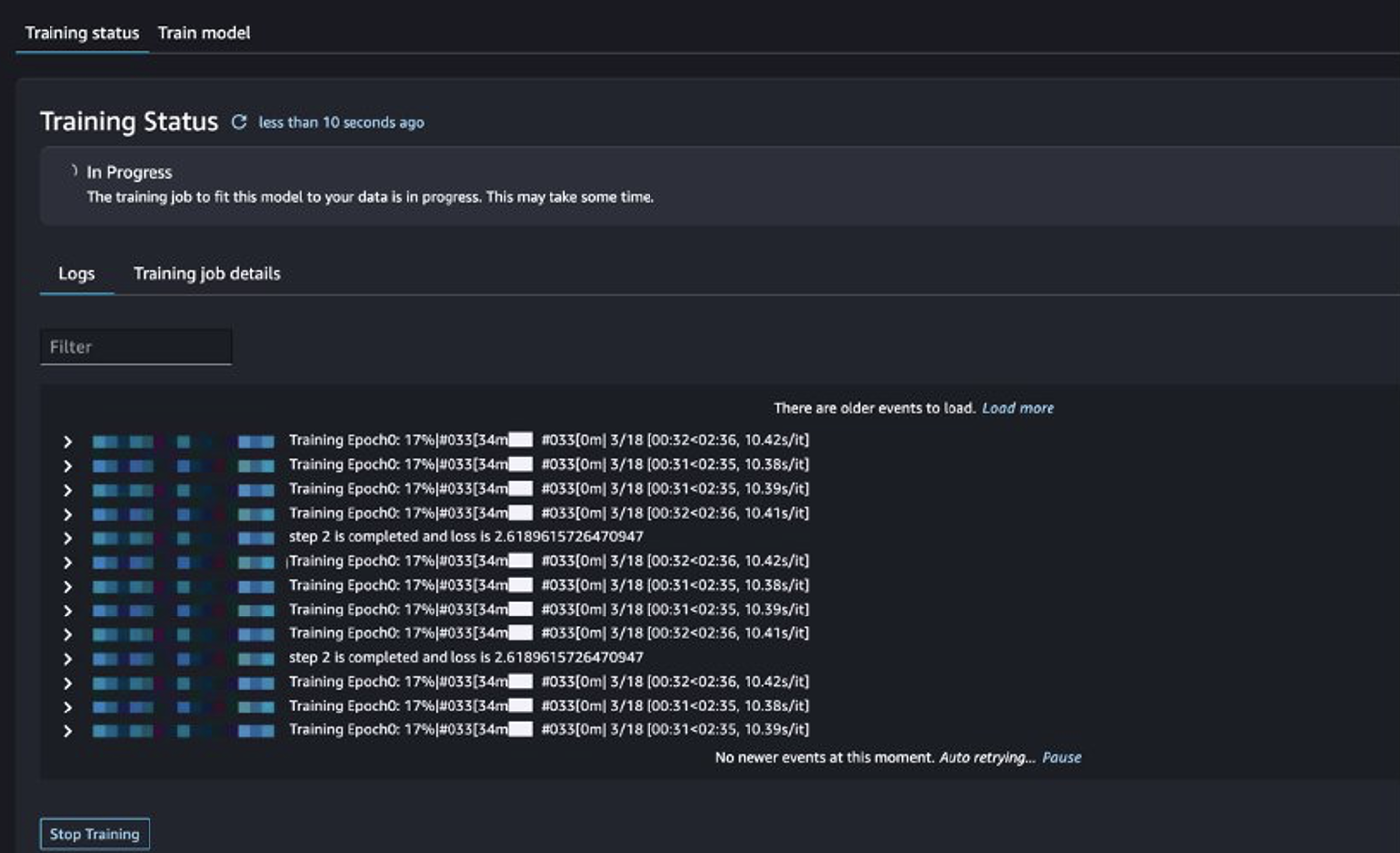
Ocenite natančno nastavljen model
Po končanem usposabljanju izberite uvajanje v SageMaker JumpStart za uvedbo vašega natančno nastavljenega modela.

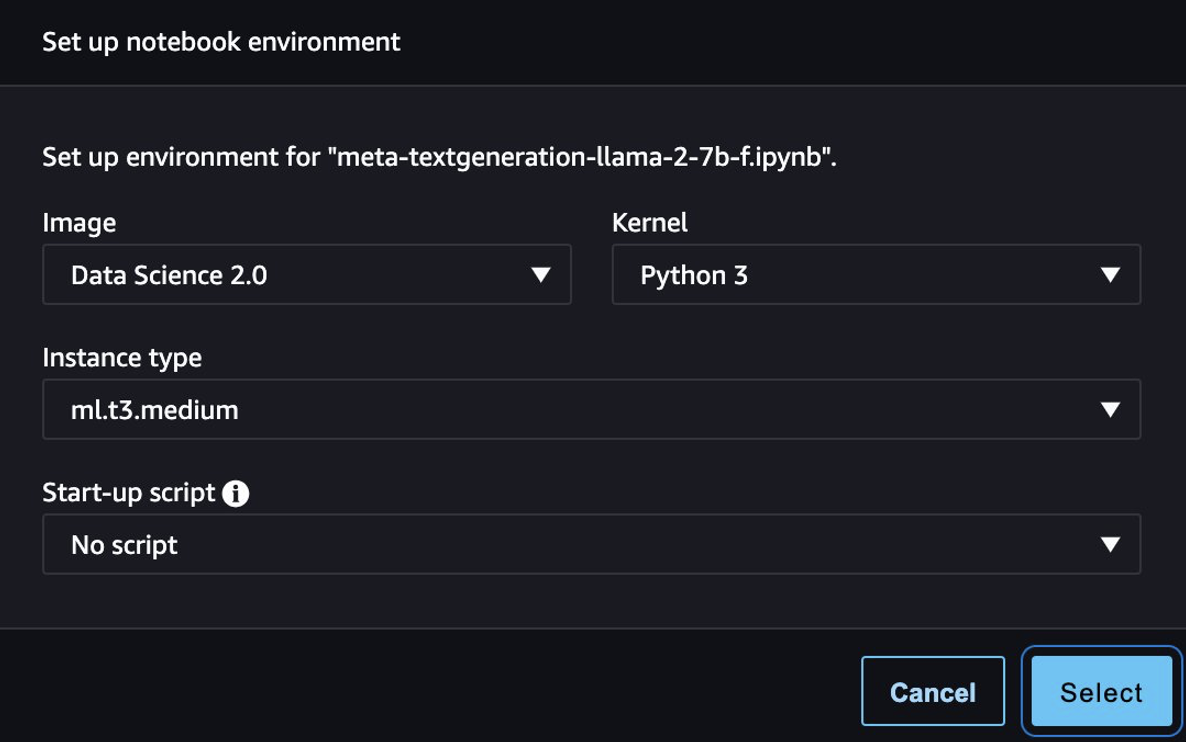
Ko je model uspešno uveden, izberite Odprite Beležnico, ki vas preusmeri na pripravljen Jupyterjev zvezek, kjer lahko zaženete svojo kodo Python.

Za prenosni računalnik lahko uporabite sliko Data Science 2.0 in jedro Python 3.
Nato lahko v tem zvezku ocenite natančno nastavljen model in izvirni model.
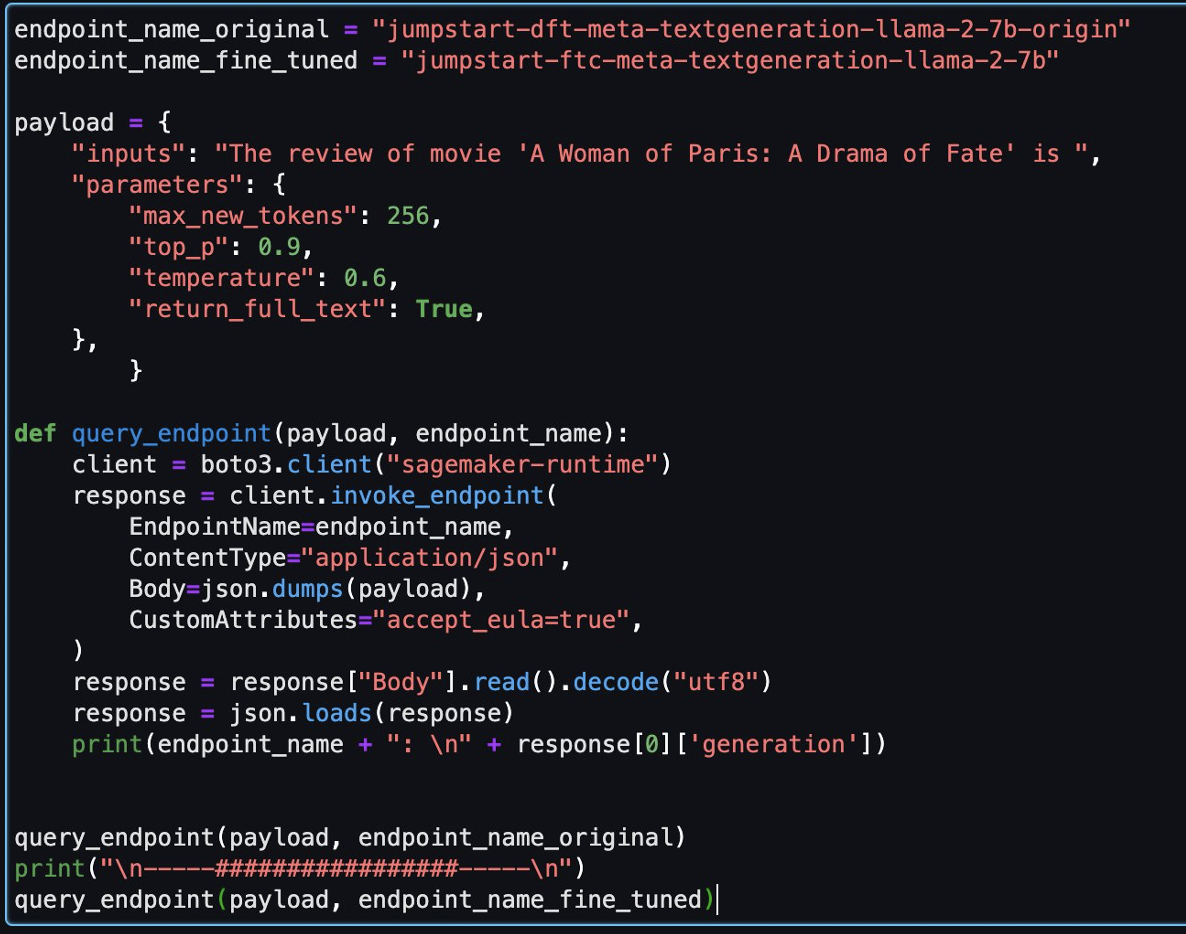
Sledita dva odgovora, ki sta ju za isto vprašanje vrnila izvirni in natančno prilagojeni model.

Oba modela smo opremili z enakim stavkom: »Recenzija filma 'Parižanka: Drama usode' je« in ju pustili, da dokončata stavek.
Izvirni model izpiše nesmiselne stavke:
"The review of movie 'A woman of Paris: A Drama of Fate' is 3.0/5.
A Woman of Paris: A Drama of Fate(1923)
A Woman of Paris: A Drama of Fate movie released on 17 October, 1992. The movie is directed by. A Woman of Paris: A Drama of Fate featured Jeanne Eagles, William Haines, Burr McIntosh and Jack Rollens in lead rols.
..."
Nasprotno pa so rezultati natančno nastavljenega modela bolj podobni filmski recenziji:
" The review of movie 'A Woman of Paris: A Drama of Fate' is 6.3/10. I liked the story, the plot, the character, the background. The performances are amazing. Rory (Judy Davis) is an Australian photographer who travels to Africa to photograph the people, wildlife, and scenery. She meets Peter (Donald Sutherland), a zoologist, and they begin a relationship..."
Očitno je, da natančno nastavljen model deluje bolje v tem posebnem scenariju.
Čiščenje
Ko končate to vajo, izvedite naslednje korake za čiščenje virov:
- Izbrišite vedro S3 ki hrani očiščen nabor podatkov.
- Zaustavite okolje EMR Serverless.
- Izbrišite končno točko SageMaker ki gosti model LLM.
- Izbrišite domeno SageMaker ki poganja vaše zvezke.
Aplikacija, ki ste jo ustvarili, se mora privzeto samodejno ustaviti po 15 minutah nedejavnosti.
Na splošno vam ni treba čistiti okolja Athena, ker ni stroškov, ko ga ne uporabljate.
zaključek
V tej objavi smo predstavili nabor podatkov Common Crawl in kako uporabljati EMR Serverless za obdelavo podatkov za natančno nastavitev LLM. Nato smo pokazali, kako uporabiti SageMaker JumpStart za natančno nastavitev LLM in njegovo uvajanje brez kode. Za več primerov uporabe EMR Serverless glejte Amazon EMR brez strežnika. Za več informacij o modelih gostovanja in natančnega prilagajanja na Amazon SageMaker JumpStart glejte Dokumentacija Sagemaker JumpStart.
O avtorjih
 Shijian Tang je strokovnjak za analitiko, arhitekt rešitev pri Amazon Web Services.
Shijian Tang je strokovnjak za analitiko, arhitekt rešitev pri Amazon Web Services.
 Matthew Liem je višji vodja arhitekture rešitev pri Amazon Web Services.
Matthew Liem je višji vodja arhitekture rešitev pri Amazon Web Services.
 Dalei Xu je strokovnjak za analitiko, arhitekt rešitev pri Amazon Web Services.
Dalei Xu je strokovnjak za analitiko, arhitekt rešitev pri Amazon Web Services.
 Yuanjun Xiao je višji arhitekt rešitev pri Amazon Web Services.
Yuanjun Xiao je višji arhitekt rešitev pri Amazon Web Services.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/preprocess-and-fine-tune-llms-quickly-and-cost-effectively-using-amazon-emr-serverless-and-amazon-sagemaker/
- : je
- :ne
- :kje
- $GOR
- 08
- 09
- 1
- 10
- 100
- 11
- 12
- 14
- 15%
- 17
- 2008
- 2013
- 23
- 258
- 40
- 50
- 52
- 7
- 9
- a
- Sposobna
- O meni
- dostop
- dostopna
- dostopen
- računovodstvo
- računi
- Doseči
- aktivira
- dodajte
- Poleg tega
- Afrika
- po
- vsi
- omogoča
- Prav tako
- Neverjetno
- Amazon
- Amazonski EMR
- Amazon SageMaker
- Amazon SageMaker JumpStart
- Amazon Web Services
- znesek
- zneski
- an
- analitika
- in
- Še ena
- kaj
- Apache
- Apache Spark
- uporaba
- aplikacije
- pristop
- Arhitektura
- SE
- AS
- At
- avstralski
- Samodejno
- samodejno
- Na voljo
- AWS
- ozadje
- temeljijo
- Osnova
- BE
- lepa
- ker
- postajajo
- pred
- začetek
- počutje
- Boljše
- med
- Big
- Big Podatki
- Billion
- telo
- tako
- izgradnjo
- by
- se imenuje
- CAN
- Lahko dobiš
- kapaciteta
- opravlja
- primeru
- primeri
- spreminjanje
- značaja
- Stroški
- preveriti
- kitajski
- Izberite
- razred
- čiščenje
- stranke
- Grozd
- Koda
- COM
- Skupno
- pogosto
- primerjate
- dokončanje
- konfiguriranje
- Razmislite
- vsebuje
- Konzole
- nenehno
- vsebujejo
- Vsebuje
- Vsebina
- stalno
- kontrast
- Ustrezno
- ustreza
- strošek
- stroškovno učinkovito
- bi
- štetje
- pokrov
- ustvarjajo
- ustvaril
- po meri
- stranka
- meri
- datum
- Podatkovna analiza
- obdelava podatkov
- znanost o podatkih
- nabor podatkov
- Davis
- deliti
- Ponudba
- globoko
- privzeto
- opredeliti
- Predstavitev
- izkazati
- Dokazano
- razporedi
- razporejeni
- uvajanje
- Izpeljano
- Kljub
- Podrobnosti
- določanje
- diagram
- razlike
- drugače
- usmerjen
- neposredno
- razpravljali
- potop
- do
- Dokumenti
- domena
- domen
- Donald
- dont
- navzdol
- Drama
- voznik
- trajanje
- med
- vsak
- prej
- lahka
- odpravlja
- poudarja
- srečanje
- Inženiring
- izboljšanje
- Vnesite
- okolje
- Eter (ETH)
- oceniti
- Primer
- Primeri
- izvedba
- Vaja
- obstoječih
- obstaja
- raziskuje
- Raziskano
- razširiti
- zunanja
- ekstrakt
- pridobivanje
- Izvlečki
- Falls
- false
- hitreje
- Usoda
- izrazit
- Nekaj
- Področja
- file
- datoteke
- filter
- filtriranje
- končno
- Najdi
- konča
- prva
- po
- sledi
- za
- format
- je pokazala,
- Okvirni
- okviri
- iz
- nadalje
- splošno
- splošno
- ustvarjajo
- generacija
- dobili
- git
- GitHub
- vodenje
- Imajo
- pomoč
- Panj
- gostovanje
- Gostitelji
- Kako
- Kako
- Vendar
- HTML
- HTTPS
- Stotine
- i
- IAM
- ID
- if
- ponazarja
- slika
- uvoz
- Pomembno
- izboljšanje
- in
- vključeno
- vključuje
- vključujoč
- narašča
- Indeks
- Podatki
- Infrastruktura
- vhod
- vhodi
- namestitev
- interakcijo
- v
- uvesti
- Uvedeno
- vprašanje
- IT
- ITS
- jack
- Job
- Delovna mesta
- json
- Jupyter Notebook
- samo
- Imejte
- Ključne
- jezik
- jeziki
- obsežne
- Zadnji
- kosilo
- začetek
- vodi
- Naj
- Stopnja
- knjižnice
- kot
- LIMIT
- linije
- Seznam
- seznami
- Llama
- llm
- lokalna
- nahaja
- kraj aktivnosti
- Logika
- prijava
- Poglej
- si
- iskanje
- stroj
- vzdrževanje
- Znamka
- Izdelava
- upravitelj
- upravljanje
- več
- map
- ogromen
- Maj ..
- Mehanizem
- Srečati
- ustreza
- omemba
- Meta
- metapodatki
- Metoda
- min
- Omiliti
- Model
- modeli
- mesečno
- več
- Najbolj
- Film
- filmi
- veliko
- več
- Ime
- Imena
- ostalo
- potrebno
- Nimate
- mreža
- Novo
- Naslednja
- št
- Vozel
- prenosnik
- zvezki
- pridobljeni
- oktober
- of
- on
- ONE
- samo
- odprite
- open source
- Možnost
- or
- izvirno
- Ostalo
- ven
- opisano
- izhod
- izhodi
- več
- preglasijo
- lastne
- Pack
- paket
- podokno
- Papir
- vzporedno
- parametri
- paris
- del
- pot
- poti
- Plačajte
- ljudje
- performance
- predstave
- opravlja
- Obdobje
- petabajt
- Peter
- fotograf
- platforma
- platon
- Platonova podatkovna inteligenca
- PlatoData
- parcela
- točke
- Popular
- Prispevek
- poganja
- pred
- pred
- Pripravimo
- pripravljeni
- primarni
- Postopek
- obdelani
- obravnavati
- proizvodnja
- pozove
- zagotavljajo
- če
- zagotavlja
- zagotavljanje
- javno
- namene
- dal
- Python
- poizvedba
- vprašanje
- hitro
- Surovi
- surovi podatki
- dosegli
- Preberi
- pripravljen
- nedavno
- Pred kratkim
- priporočeno
- zapis
- glejte
- reference
- redno
- Razmerje
- sprosti
- popravilo
- zamenjajte
- zahteva
- obvezna
- Zahteve
- viri
- Odgovor
- odgovorov
- povzroči
- Rezultati
- pregleda
- Mnenja
- Pravica
- vloga
- Rory
- Run
- tek
- deluje
- sagemaker
- Enako
- Shrani
- Lestvica
- luske
- skaliranje
- skenira
- Scenarij
- Znanost
- script
- skripte
- sekund
- Oddelek
- oddelki
- glej
- Segment
- izberite
- SAMO
- višji
- stavek
- Brez strežnika
- strežniki
- Storitve
- nastavite
- nastavitev
- več
- je
- Kratke Hlače
- shouldnt
- pokazale
- Pomen
- Podoben
- saj
- sam
- spletna stran
- Velikosti
- Upočasni
- delček
- So
- Rešitev
- rešitve
- juha
- vir
- Spark
- specialist
- specifična
- SQL
- ssh
- začel
- Začetek
- Izjava
- Izjave
- Status
- Korak
- Koraki
- Še vedno
- stop
- trgovina
- shranjeni
- trgovine
- Zgodba
- naravnost
- strategije
- String
- studio
- predloži
- oddaja
- Uspešno
- taka
- dovolj
- primerna
- Preklop
- sinhronizacijo.
- miza
- Bodite
- ciljna
- Naloga
- Naloge
- tensorflo
- Pogoji
- testi
- besedilo
- tvorjenje besedila
- da
- O
- njihove
- Njih
- POTEM
- Tukaj.
- te
- jih
- tretjih oseb
- ta
- 3
- skozi
- čas
- Časovni žig
- do
- sledenje
- usposabljanje
- potovanja
- Res
- poskusite
- dva
- Vrste
- pod
- nestrukturirano
- posodobljeno
- URL
- uporaba
- primeru uporabe
- Rabljeni
- uporabnik
- mnenja uporabnikov
- Uporabniki
- uporabo
- Uporaben
- različica
- Virtual
- prostornine
- sprehod
- želeli
- hotel
- Skladišče
- je
- način..
- načini
- we
- web
- spletne storitve
- teden
- Dobro
- Kaj
- kdaj
- medtem ko
- ki
- medtem
- WHO
- Wildlife
- bo
- william
- z
- v
- brez
- ženska
- delal
- vredno
- pisati
- pisanje
- donos
- jo
- Vaša rutina za
- zefirnet