Amazon RedShift je hitro, popolnoma upravljano skladišče podatkov v oblaku velikosti petabajtov, ki omogoča preprosto in stroškovno učinkovito analizo vseh vaših podatkov z uporabo standardnega SQL in vaših obstoječih orodij poslovne inteligence (BI). Več deset tisoč strank danes uporablja Amazon Redshift za analizo eksabajtov podatkov in izvajanje analitičnih poizvedb, zaradi česar je najbolj razširjeno skladišče podatkov v oblaku. Amazon Redshift je na voljo tako v konfiguracijah brez strežnika kot v konfiguracijah, ki so na voljo.
Amazon Redshift vam omogoča neposreden dostop do podatkov, shranjenih v Preprosta storitev shranjevanja Amazon (Amazon S3) z uporabo poizvedb SQL in združevanje podatkov v vašem podatkovnem skladišču in podatkovnem jezeru. Z Amazon Redshift lahko poizvedujete po podatkih v svojem podatkovnem jezeru S3 z uporabo centrale AWS lepilo metastore iz vašega podatkovnega skladišča Redshift.
Amazon Redshift podpira poizvedovanje po številnih formatih podatkov, kot so CSV, JSON, Parquet in ORC, ter formatih tabel, kot sta Apache Hudi in Delta. Amazon Redshift podpira tudi poizvedovanje po ugnezdenih podatkih s kompleksnimi tipi podatkov, kot so struct, array in map.
S to zmožnostjo Amazon Redshift razširi vaše petabajtno podatkovno skladišče na eksabajtno podatkovno jezero na Amazon S3 na stroškovno učinkovit način.
Apache Iceberg je najnovejši format tabele, ki ga zdaj v predogledu podpira Amazon Redshift. V tej objavi vam pokažemo, kako poizvedovati po tabelah Iceberg z uporabo Amazon Redshift ter raziščemo podporo in možnosti za Iceberg.
Pregled rešitev
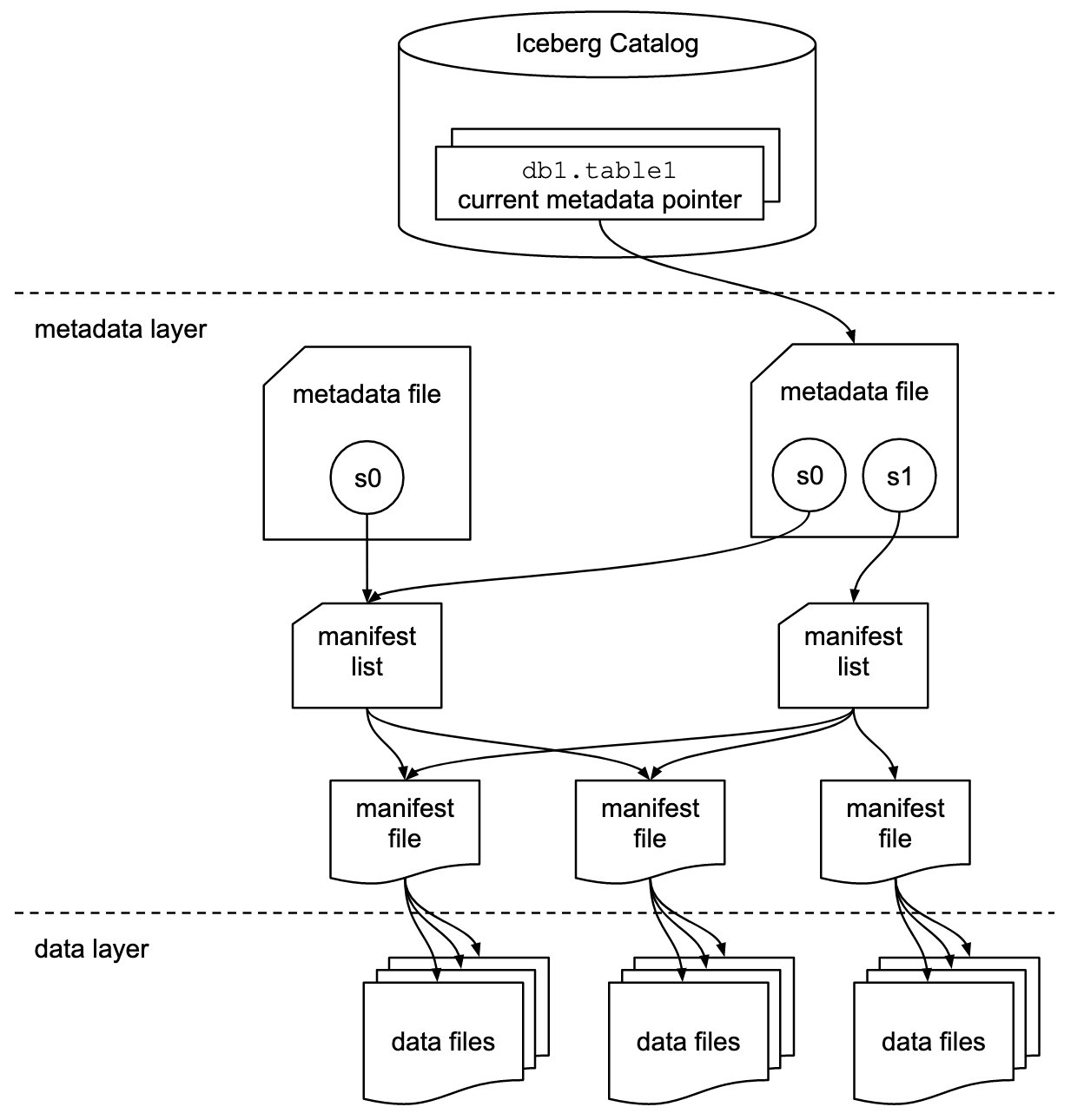
Apaška ledena gora je oblika odprte tabele za zelo velike analitične nize podatkov v petabajtnem merilu. Iceberg upravlja velike zbirke datotek kot tabel in podpira sodobne operacije analitičnega podatkovnega jezera, kot so poizvedbe za vstavljanje, posodabljanje, brisanje in potovanje na ravni zapisa. Specifikacija Iceberg omogoča nemoten razvoj tabel, kot je razvoj sheme in particije, njena zasnova pa je optimizirana za uporabo na Amazon S3.
Iceberg shrani metapodatkovni kazalec za vse metapodatkovne datoteke. Ko poizvedba SELECT bere tabelo Iceberg, gre mehanizem poizvedb najprej v katalog Iceberg, nato pa pridobi vnos lokacije najnovejše datoteke z metapodatki, kot je prikazano v naslednjem diagramu.
Amazon Redshift zdaj zagotavlja podporo za tabele Apache Iceberg, ki strankam podatkovnega jezera omogoča izvajanje analitičnih poizvedb samo za branje na transakcijsko dosleden način. To vam omogoča preprosto upravljanje in vzdrževanje vaših tabel na transakcijskih podatkovnih jezerih.
Amazon Redshift podpira izvorno shemo Apache Iceberg in zmožnosti razvoja particij z uporabo Katalog podatkov o lepilu AWS, odpravlja potrebo po spreminjanju definicij tabel za dodajanje novih particij ali premikanje in obdelavo velikih količin podatkov za spreminjanje sheme obstoječe tabele podatkovnega jezera. Amazon Redshift uporablja statistične podatke stolpcev, shranjene v metapodatkih tabele Apache Iceberg, da optimizira svoje načrte poizvedb in zmanjša preglede datotek, potrebne za izvajanje poizvedb.
V tej objavi uporabljamo Javni nabor podatkov o rumenem taksiju Komisije za taksije in limuzine v New Yorku kot naš izvorni podatek. Nabor podatkov vsebuje podatkovne datoteke v Parket Apache format na Amazon S3. Uporabljamo Amazonska Atena za pretvorbo tega nabora podatkov Parquet in nato uporabo Amazonov rdeči premik spektra za poizvedovanje in združevanje z lokalno tabelo Redshift, izvajanje izbrisov in posodobitev na ravni vrstic ter razvoj particij, vse to je usklajeno prek kataloga podatkov AWS Glue v podatkovnem jezeru S3.
Predpogoji
Morali bi imeti naslednje predpogoje:
Pretvorite podatke Parquet v tabelo Iceberg
Za to objavo potrebujete Javni nabor podatkov o rumenem taksiju Komisije za taksije in limuzine v New Yorku na voljo v formatu Iceberg. Datoteke lahko prenesete in nato uporabite Atheno za pretvorbo nabora podatkov Parquet v tabelo Iceberg ali si ogledate Zgradite podatkovno jezero Apache Iceberg z uporabo Amazon Athena, Amazon EMR in AWS Glue objava v spletnem dnevniku za ustvarjanje mize Iceberg.
V tej objavi uporabljamo Atheno za pretvorbo podatkov. Izvedite naslednje korake:
- Prenesite datoteke s prejšnjo povezavo ali uporabite Vmesnik ukazne vrstice AWS (AWS CLI), da kopirate datoteke iz javnega vedra S3 za leti 2020 in 2021 v svoje vedro S3 z naslednjim ukazom:
Za več informacij glejte Nastavitev Amazon Redshift CLI.
- Ustvari bazo podatkov
Icebergdbin ustvarite tabelo z Atheno, ki kaže na datoteke formata Parquet z naslednjim stavkom: - Preverite podatke v tabeli Parquet z naslednjim SQL:

- Ustvarite tabelo Iceberg v Atheni z naslednjo kodo. V nadaljevanju si lahko ogledate lastnosti vrste tabele kot tabele Iceberg s formatom Parquet in hitrim stiskanjem
create tableizjava. Preden zaženete SQL, morate posodobiti lokacijo S3. Upoštevajte tudi, da je miza Iceberg pregrajena zYearključ. - Ko ustvarite tabelo, naložite podatke v tabelo Iceberg z uporabo predhodno naložene tabele Parquet
nyc_taxi_yellow_parquetz naslednjim SQL: - Ko je stavek SQL dokončan, potrdite podatke v tabeli Iceberg
nyc_taxi_yellow_iceberg. Ta korak je obvezen pred prehodom na naslednji korak. - Z naslednjim ukazom lahko potrdite, da je tabela nyc_taxi_yellow_iceberg v tabeli formata Iceberg in razdeljena na stolpec Leto:



Ustvarite zunanjo shemo v Amazon Redshift
V tem razdelku prikazujemo, kako ustvariti zunanjo shemo v Amazon Redshift, ki kaže na bazo podatkov AWS Glue icebergdb za poizvedbo po tabeli Iceberg nyc_taxi_yellow_iceberg ki smo jih videli v prejšnjem razdelku z uporabo Athene.
Prijavite se v Redshift preko Urejevalnik poizvedb v2 ali odjemalca SQL in zaženite naslednji ukaz (upoštevajte, da zbirka podatkov AWS Glue icebergdb in podatki o regiji se uporabljajo):

Če želite izvedeti več o ustvarjanju zunanjih shem v Amazon Redshift, glejte ustvarite zunanjo shemo
Ko ustvarite zunanjo shemo spectrum_iceberg_schema, lahko poizvedujete po tabeli Iceberg v Amazon Redshift.
Poizvedite po tabeli Iceberg v Amazon Redshift
Zaženite naslednjo poizvedbo v urejevalniku poizvedb v2. Upoštevajte to spectrum_iceberg_schema je ime zunanje sheme, ustvarjene v Amazon Redshift in nyc_taxi_yellow_iceberg je tabela v bazi podatkov AWS Glue, uporabljena v poizvedbi:
Podatki poizvedbe na naslednjem posnetku zaslona kažejo, da je po tabeli AWS Glue s formatom Iceberg mogoče poizvedovati z uporabo Redshift Spectrum.

Preverite načrt razlage poizvedovanja po tabeli Iceberg
Z naslednjo poizvedbo lahko dobite izhod razlage načrta, ki prikazuje obliko ICEBERG:

Potrdite posodobitve za skladnost podatkov
Ko je posodobitev tabele Iceberg končana, lahko poizvedujete po Amazon Redshift, da si ogledate transakcijsko dosleden pogled podatkov. Zaženimo poizvedbo tako, da izberemo a vendorid in za določen prevzem in oddajo:

Nato posodobite vrednost passenger_count do 4 in trip_distance do 9.4 za a vendorid in določeni datumi prevzema in odhoda v Atheni:

Na koncu zaženite naslednjo poizvedbo v urejevalniku poizvedb v2, da vidite posodobljeno vrednost passenger_count in trip_distance:
Kot je prikazano na naslednjem posnetku zaslona, so operacije posodabljanja tabele Iceberg na voljo v Amazon Redshift.

Ustvarite enoten pogled lokalne tabele in zgodovinskih podatkov v Amazon Redshift
Kot sodobna strategija podatkovne arhitekture lahko organizirate zgodovinske podatke ali manj pogosto dostopne podatke v podatkovnem jezeru in podatke, do katerih pogosto dostopate, hranite v podatkovnem skladišču Redshift. To zagotavlja prilagodljivost za upravljanje analitike v velikem obsegu in iskanje stroškovno najučinkovitejše arhitekturne rešitve.
V tem primeru naložimo podatke za 2 leti v tabelo Redshift; preostali podatki ostanejo v podatkovnem jezeru S3, ker se po tem nizu podatkov manj pogosto poizveduje.
- Uporabite naslednjo kodo za nalaganje 2 let podatkov v
nyc_taxi_yellow_recenttabela v Amazon Redshift, izvira iz tabele Iceberg:
- Nato lahko z naslednjim ukazom v Atheni odstranite podatke za zadnji 2 leti iz tabele Iceberg, ker ste podatke naložili v tabelo Redshift v prejšnjem koraku:

Ko dokončate te korake, ima tabela Redshift podatke za 2 leti, preostali podatki pa so v tabeli Iceberg v Amazonu S3.
- Ustvarite pogled z uporabo
nyc_taxi_yellow_icebergMiza Iceberg innyc_taxi_yellow_recenttabela v Amazon Redshift: - Zdaj poizvedite pogled, odvisno od pogojev filtra bo Redshift Spectrum pregledal bodisi podatke Iceberga, tabelo Redshift ali oboje. Naslednji primer poizvedbe vrne število zapisov iz vsake od izvornih tabel s skeniranjem obeh tabel:

Evolucija particije
Iceberg uporablja skrite particije, kar pomeni, da vam ni treba ročno dodajati particij za tabele Apache Iceberg. Nove vrednosti particije ali nove specifikacije particije (dodajanje ali odstranjevanje stolpcev particije) v tabelah Apache Iceberg samodejno zazna Amazon Redshift in za posodobitev particij v definiciji tabele ni potrebno ročno delovanje. Naslednji primer to dokazuje.
V našem primeru, če tabela Iceberg nyc_taxi_yellow_iceberg je bil prvotno razdeljen po letnicah in kasneje stolpcu vendorid je bil dodan kot dodaten particijski stolpec, potem lahko Amazon Redshift nemoteno poizveduje po tabeli Iceberg nyc_taxi_yellow_iceberg z dvema različnima razdelitvenima shemama v določenem časovnem obdobju.

Premisleki pri poizvedovanju po tabelah Iceberg z uporabo Amazon Redshift
Med obdobjem predogleda upoštevajte naslednje, ko uporabljate Amazon Redshift s tabelami Iceberg:
- Podprte so samo tabele Iceberg, definirane v katalogu podatkov AWS Glue Data Catalog.
- Ukazi zunanje tabele CREATE ali ALTER niso podprti, kar pomeni, da bi morala tabela Iceberg že obstajati v bazi podatkov AWS Glue.
- Poizvedbe o potovanju skozi čas niso podprte.
- Podprti sta različici Iceberg 1 in 2. Za več podrobnosti o različicah formata Iceberg glejte Oblikovanje različic.
- Za seznam podprtih tipov podatkov s tabelami Iceberg glejte Podprti tipi podatkov s tabelami Apache Iceberg (predogled).
- Cene za poizvedovanje po tabeli Iceberg so enake kot za dostop do drugih formatov podatkov z uporabo Amazon Redshift.
Za dodatne podrobnosti o predogledu tabel formata Iceberg glejte Uporaba tabel Apache Iceberg z Amazon Redshift (predogled).
Povratne informacije strank
»Tinuiti, največje neodvisno podjetje za uspešno trženje, dnevno obdeluje velike količine podatkov in mora imeti zanesljivo strategijo podatkovnega jezera in skladišča podatkov, da lahko naše ekipe za tržno obveščanje shranijo in analizirajo vse naše podatke o strankah na enostaven, cenovno dostopen in varen način. , in robusten način,« pravi Justin Manus, glavni tehnološki direktor pri Tinuiti. »Podpora Amazon Redshift za tabele Apache Iceberg v našem podatkovnem jezeru, ki je edini vir resnice, obravnava kritičen izziv pri optimizaciji zmogljivosti in dostopnosti ter dodatno poenostavlja naše cevovode za integracijo podatkov za dostop do vseh podatkov, zaužitih iz različnih virov, in za napajanje našega potencial blagovne znamke strank.”
zaključek
V tej objavi smo vam pokazali primer poizvedovanja po tabeli Iceberg v Redshiftu z uporabo datotek, shranjenih v Amazon S3, katalogiziranih kot tabela v katalogu podatkov AWS Glue Data Catalog, in prikazali nekatere ključne funkcije, kot so učinkovito posodabljanje in brisanje na ravni vrstic, in izkušnjo razvoja sheme za uporabnike, da odklenejo moč velikih podatkov s pomočjo Athene.
Amazon Redshift lahko uporabite za izvajanje poizvedb v tabelah podatkovnega jezera v različnih datotekah in formatih tabel, kot je npr. Apače Hudi in Delta jezero, in zdaj z Apache Iceberg (predogled), ki ponuja dodatne možnosti za potrebe vaših sodobnih podatkovnih arhitektur.
Upamo, da vam bo to odlično izhodišče za poizvedovanje po tabelah Iceberg v Amazon Redshift.
O avtorjih
 Rohit Bansal je strokovnjak za analitične rešitve pri AWS. Specializiran je za Amazon Redshift in sodeluje s strankami pri izgradnji analitičnih rešitev naslednje generacije z uporabo drugih storitev AWS Analytics.
Rohit Bansal je strokovnjak za analitične rešitve pri AWS. Specializiran je za Amazon Redshift in sodeluje s strankami pri izgradnji analitičnih rešitev naslednje generacije z uporabo drugih storitev AWS Analytics.
 Satish Sathiya je višji produktni inženir pri Amazon Redshift. Je navdušen navdušenec nad velikimi podatki, ki sodeluje s strankami po vsem svetu, da bi dosegel uspeh in zadovoljil njihove potrebe po skladiščenju podatkov in arhitekturi podatkovnega jezera.
Satish Sathiya je višji produktni inženir pri Amazon Redshift. Je navdušen navdušenec nad velikimi podatki, ki sodeluje s strankami po vsem svetu, da bi dosegel uspeh in zadovoljil njihove potrebe po skladiščenju podatkov in arhitekturi podatkovnega jezera.
 Ranjan Burman je strokovnjak za analitične rešitve pri AWS. Specializiran je za Amazon Redshift in strankam pomaga zgraditi razširljive analitične rešitve. Ima več kot 16 let izkušenj na področju različnih tehnologij podatkovnih zbirk in skladiščenja podatkov. Navdušen je nad avtomatizacijo in reševanjem težav strank z rešitvami v oblaku.
Ranjan Burman je strokovnjak za analitične rešitve pri AWS. Specializiran je za Amazon Redshift in strankam pomaga zgraditi razširljive analitične rešitve. Ima več kot 16 let izkušenj na področju različnih tehnologij podatkovnih zbirk in skladiščenja podatkov. Navdušen je nad avtomatizacijo in reševanjem težav strank z rešitvami v oblaku.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Avtomobili/EV, Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- ChartPrime. Izboljšajte svojo igro trgovanja s ChartPrime. Dostopite tukaj.
- BlockOffsets. Posodobitev okoljskega offset lastništva. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/query-your-iceberg-tables-in-data-lake-using-amazon-redshift-preview/
- :ima
- : je
- :ne
- :kje
- $GOR
- 1
- 10
- 100
- 16
- 17
- 2020
- 2021
- 22
- 26
- 28
- 30
- 385
- 46
- 500
- 53
- 7
- 8
- 9
- a
- O meni
- dostop
- dostopna
- dostopnost
- Dostop
- Doseči
- čez
- dodajte
- dodano
- Dodatne
- naslovi
- cenovno
- vsi
- omogoča
- že
- Prav tako
- Amazon
- Amazonska Atena
- Amazonski EMR
- Amazon Web Services
- zneski
- an
- Analitični
- Analitično
- analitika
- analizirati
- in
- kaj
- Apache
- Arhitektura
- SE
- okoli
- Array
- AS
- At
- samodejno
- avtomatizacija
- Na voljo
- AWS
- AWS lepilo
- Osnova
- ker
- pred
- počutje
- Big
- Big Podatki
- zavezujoče
- Blog
- tako
- blagovne znamke
- izgradnjo
- poslovni
- Poslovna inteligenca
- by
- CAN
- Zmogljivosti
- zmožnost
- Katalog
- Osrednji
- nekatere
- izziv
- spremenite
- šef
- Vodja tehnološke
- stranke
- Cloud
- Koda
- Zbirke
- Stolpec
- Stolpci
- dokončanje
- kompleksna
- Pogoji
- Razmislite
- premislekov
- dosledno
- Vsebuje
- pretvorbo
- usklajeno
- stroškovno učinkovito
- ustvarjajo
- ustvaril
- Ustvarjanje
- kritično
- stranka
- podatki o strankah
- Stranke, ki so
- vsak dan
- datum
- integracija podatkov
- Data jezero
- podatkovno skladišče
- Baze podatkov
- nabor podatkov
- Termini
- privzeto
- opredeljen
- opredelitev
- definicije
- Delta
- izkazati
- Dokazano
- dokazuje,
- Odvisno
- Oblikovanje
- Podrobnosti
- Zaznali
- dev
- drugačen
- neposredno
- dont
- podvojila
- prenesi
- vsak
- enostavno
- lahka
- urednik
- učinkovite
- bodisi
- odstranjevanje
- omogoča
- Motor
- inženir
- navdušenec
- Vpis
- Eter (ETH)
- evolucija
- Primer
- obstajajo
- obstoječih
- izkušnje
- Pojasnite
- raziskuje
- Se razširi
- zunanja
- dodatna
- FAST
- Lastnosti
- file
- datoteke
- filter
- Najdi
- Firm
- prva
- prilagodljivost
- po
- za
- format
- pogosto
- iz
- v celoti
- nadalje
- dobili
- daje
- globus
- goes
- veliko
- skupina
- Ročaji
- Imajo
- he
- Pomaga
- zgodovinski
- upam,
- Kako
- Kako
- HTML
- http
- HTTPS
- if
- in
- Neodvisni
- Podatki
- integracija
- Intelligence
- v
- IT
- ITS
- pridružite
- jpg
- json
- Justin
- Imejte
- Ključne
- Jezero
- velika
- Največji
- Zadnja
- pozneje
- Zadnji
- UČITE
- manj
- kot
- LIMIT
- vrstica
- LINK
- Seznam
- obremenitev
- lokalna
- kraj aktivnosti
- vzdrževati
- IZDELA
- Izdelava
- upravljanje
- upravlja
- upravlja
- Način
- Navodilo
- ročno
- map
- Tržna
- Trženje
- pomeni
- Srečati
- metapodatki
- sodobna
- več
- Najbolj
- premikanje
- premikanje
- morajo
- Ime
- materni
- Nimate
- potrebna
- potrebe
- Novo
- Naslednja
- Naslednja generacija
- št
- Upoštevajte
- zdaj
- Številka
- NYC
- of
- Častnik
- on
- odprite
- Delovanje
- operacije
- Optimizirajte
- optimizirana
- optimizacijo
- možnosti
- or
- originalno
- Ostalo
- naši
- izhod
- več
- Stran
- strastno
- opravlja
- performance
- Obdobje
- Načrt
- načrti
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Točka
- Prispevek
- potencial
- moč
- predpogoji
- predogled
- prejšnja
- prej
- Težave
- Postopek
- Izdelek
- Lastnosti
- zagotavlja
- javnega
- poizvedbe
- reading
- evidence
- zmanjša
- okolica
- odstrani
- zamenjajte
- obvezna
- REST
- vrne
- robusten
- Run
- tek
- Enako
- Videl
- pravi
- razširljive
- Lestvica
- skeniranje
- skeniranje
- skenira
- sheme
- brezšivne
- brez težav
- Oddelek
- zavarovanje
- glej
- višji
- Brez strežnika
- Storitve
- nastavite
- shouldnt
- Prikaži
- je pokazala,
- pokazale
- Razstave
- Enostavno
- sam
- Rešitev
- rešitve
- Reševanje
- nekaj
- vir
- Viri
- Sourcing
- specialist
- specializirano
- specifikacija
- La tienda de Love Monkey entregado a Enfermería Fitzroy, de convalecencia y casas de reposo
- Spectrum
- SQL
- standardna
- Začetek
- Izjava
- Statistika
- Korak
- Koraki
- shranjevanje
- trgovina
- shranjeni
- trgovine
- Strategija
- String
- uspeh
- taka
- podpora
- Podprti
- Podpira
- miza
- Skupine
- Tehnologije
- Tehnologija
- deset
- kot
- da
- O
- Vir
- njihove
- POTEM
- te
- ta
- tisoče
- skozi
- čas
- Čas potovanja
- Časovni žig
- do
- danes
- orodja
- transakcijski
- potovanja
- Resnica
- dva
- tip
- Vrste
- poenoteno
- unija
- odklepanje
- Nadgradnja
- posodobljeno
- posodobitve
- Uporaba
- uporaba
- Rabljeni
- Uporabniki
- uporablja
- uporabo
- POTRDI
- vrednost
- Vrednote
- raznolikost
- različnih
- zelo
- preko
- Poglej
- prostornine
- Skladišče
- skladiščenje
- je
- način..
- we
- web
- spletne storitve
- kdaj
- ki
- WHO
- široka
- pogosto
- bo
- z
- deluje
- leto
- let
- jo
- Vaša rutina za
- zefirnet