Pomen podatkovnih skladišč in analitike, ki se izvajajo na platformah podatkovnih skladišč, je z leti vztrajno naraščal, pri čemer so se mnoga podjetja začela zanašati na te sisteme kot kritičnega pomena za kratkoročno operativno odločanje in dolgoročno strateško načrtovanje. Običajno se podatkovna skladišča osvežujejo v paketnih ciklih, na primer mesečno, tedensko ali dnevno, tako da lahko podjetja iz njih pridobijo različne vpoglede.
Mnoge organizacije se zavedajo, da vnos podatkov v skoraj realnem času skupaj z napredno analitiko odpira nove priložnosti. Finančna ustanova lahko na primer predvidi, ali je transakcija s kreditno kartico goljufiva, tako da zažene program za zaznavanje nepravilnosti v skoraj realnem času namesto v paketnem načinu.
V tem prispevku pokažemo, kako Amazon RedShift lahko zagotovi napovedi pretakanja in strojnega učenja (ML) na eni platformi.
Amazon Redshift je hitro, razširljivo, varno in v celoti upravljano skladišče podatkov v oblaku, ki omogoča preprosto in stroškovno učinkovito analizo vseh vaših podatkov s standardnim SQL.
Amazon Redshift ML analitikom podatkov in razvijalcem baz podatkov olajša ustvarjanje, usposabljanje in uporabo modelov ML z uporabo znanih ukazov SQL v podatkovnih skladiščih Amazon Redshift.
Veseli smo lansiranja Zaužitje Amazon Redshift Streaming za Amazonski kinezi podatkovni tokovi in Amazonovo pretakanje za Apache Kafka (Amazon MSK), ki vam omogoča vnos podatkov neposredno iz podatkovnega toka Kinesis ali teme Kafka, ne da bi morali podatke uprizoriti v Preprosta storitev shranjevanja Amazon (Amazon S3). Zaužitje pretakanja Amazon Redshift vam omogoča, da dosežete nizko zakasnitev v vrstnem redu sekund, medtem ko zaužijete stotine megabajtov podatkov v vaše podatkovno skladišče.
Ta objava prikazuje, kako vam Amazon Redshift, skladišče podatkov v oblaku, omogoča ustvarjanje napovedi ML v skoraj realnem času z uporabo pretakanja Amazon Redshift in funkcij Redshift ML z znanim jezikom SQL.
Pregled rešitev
Z upoštevanjem korakov, opisanih v tej objavi, boste lahko nastavili aplikacijo producenta za pretakanje na Amazonski elastični računalniški oblak (Amazon EC2), ki simulira transakcije s kreditnimi karticami in v realnem času potiska podatke v Kinesis Data Streams. V storitvi Amazon Redshift nastavite materializiran pogled Amazon Redshift Streaming Ingestion, kjer se sprejemajo pretočni podatki. Usposobite in zgradite model Redshift ML za ustvarjanje sklepov v realnem času glede na pretočne podatke.
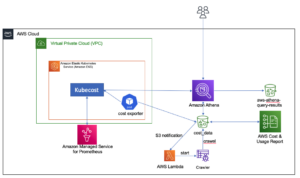
Naslednji diagram prikazuje arhitekturo in potek procesa.
Postopek po korakih je naslednji:
- Primerek EC2 simulira aplikacijo za transakcije s kreditnimi karticami, ki vstavi transakcije s kreditnimi karticami v tok podatkov Kinesis.
- Podatkovni tok shranjuje dohodne podatke o transakcijah s kreditno kartico.
- Materializirani pogled Amazon Redshift Streaming Ingestion se ustvari na vrhu podatkovnega toka, ki samodejno zaužije pretočne podatke v Amazon Redshift.
- Z Redshift ML zgradite, učite in uvedete model ML. Model Redshift ML se usposablja z uporabo preteklih transakcijskih podatkov.
- Podatke o pretakanju pretvorite in ustvarite napovedi ML.
- Stranke lahko opozorite ali posodobite aplikacijo, da zmanjšate tveganje.
To navodilo uporablja podatke o pretoku transakcij s kreditno kartico. Podatki o transakcijah s kreditno kartico so izmišljeni in temeljijo na a Simulator. Nabor podatkov o strankah je prav tako izmišljen in se ustvari z nekaterimi naključnimi podatkovnimi funkcijami.
Predpogoji
- Ustvarite gručo Amazon Redshift.
- Konfigurirajte gručo za uporabo Redshift ML.
- ustvarjanje an AWS upravljanje identitete in dostopa Uporabnik (IAM).
- Posodobite vlogo IAM, priloženo gruči Redshift, da vključite dovoljenja za dostop do toka podatkov Kinesis. Za več informacij o zahtevanem pravilniku glejte Kako začeti s pretakanjem.
- Ustvarite primerek m5.4xlarge EC2. Aplikacijo Producer smo preizkusili z instanco m5.4xlarge, vendar lahko prosto uporabljate drugo vrsto instance. Pri ustvarjanju primerka uporabite amzn2-ami-kernel-5.10-hvm-2.0.20220426.0-x86_64-gp2 AMI.
- Če želite zagotoviti, da je Python3 nameščen v primerku EC2, zaženite naslednji ukaz, da preverite svojo različico Python (upoštevajte, da skript za ekstrakcijo podatkov deluje samo na Python 3):
- Namestite naslednje odvisne pakete za zagon programa simulatorja:
- Konfigurirajte Amazon EC2 z uporabo spremenljivk, kot so poverilnice AWS, ustvarjene za uporabnika IAM, ustvarjenega v 3. koraku zgoraj. Naslednji posnetek zaslona prikazuje primer uporabe Aws konfigurirati.

Nastavite podatkovne tokove Kinesis
Amazon Kinesis Data Streams je izjemno razširljiva in vzdržljiva storitev pretakanja podatkov v realnem času. Nenehno lahko zajema gigabajte podatkov na sekundo iz več sto tisoč virov, kot so tokovi klikov spletnega mesta, tokovi dogodkov v bazi podatkov, finančne transakcije, viri družbenih medijev, dnevniki IT in dogodki sledenja lokaciji. Zbrani podatki so na voljo v milisekundah, da se omogočijo primeri uporabe analitike v realnem času, kot so nadzorne plošče v realnem času, zaznavanje nepravilnosti v realnem času, dinamično določanje cen in drugo. Kinesis Data Streams uporabljamo, ker je rešitev brez strežnika, ki se lahko spreminja glede na uporabo.
Ustvarite podatkovni tok Kinesis
Najprej morate ustvariti podatkovni tok Kinesis, če želite prejeti pretočne podatke:
- Na konzoli Amazon Kinesis izberite Podatkovni tokovi v podoknu za krmarjenje.
- Izberite Ustvari tok podatkov.
- za Ime toka podatkov, vnesite
cust-payment-txn-stream. - za Način zmogljivostitako, da izberete Na zahtevo.

- Za ostale možnosti izberite privzete možnosti in sledite pozivom za dokončanje nastavitve.
- Zajemite ARN za ustvarjeni tok podatkov, ki ga boste uporabili v naslednjem razdelku pri definiranju pravilnika IAM.

Nastavite dovoljenja
Da lahko aplikacija za pretakanje piše v Kinesis Data Streams, mora imeti aplikacija dostop do Kinesis. Z naslednjo izjavo o pravilniku lahko procesu simulatorja, ki ste ga nastavili v naslednjem razdelku, dodelite dostop do toka podatkov. Uporabite ARN podatkovnega toka, ki ste ga shranili v prejšnjem koraku.
Konfigurirajte proizvajalca toka
Preden lahko porabimo pretočne podatke v Amazon Redshift, potrebujemo vir pretočnih podatkov, ki zapisuje podatke v tok podatkov Kinesis. Ta objava uporablja generator podatkov po meri in AWS SDK za Python (Boto3) za objavo podatkov v podatkovnem toku. Za navodila za nastavitev glejte Simulator proizvajalca. Ta proces simulatorja objavi pretočne podatke v tok podatkov, ustvarjen v prejšnjem koraku (cust-payment-txn-stream).
Konfigurirajte porabnika toka
Ta razdelek govori o konfiguraciji porabnika toka (pogled vnosa pretakanja Amazon Redshift).
Amazon Redshift Streaming Ingestion zagotavlja nizko zakasnitev in visoko hitrost pretakanja podatkov iz podatkovnih tokov Kinesis v materializiran pogled Amazon Redshift. Svojo gručo Amazon Redshift lahko konfigurirate tako, da omogočite pretakanje in ustvarite materializiran pogled s samodejnim osveževanjem z uporabo stavkov SQL, kot je opisano v Ustvarjanje materializiranih pogledov v Amazon Redshift. Samodejni postopek osveževanja materializiranega pogleda bo vnesel pretočne podatke s hitrostjo več sto megabajtov podatkov na sekundo iz Kinesis Data Streams v Amazon Redshift. Posledica tega je hiter dostop do zunanjih podatkov, ki se hitro osvežijo.
Ko ustvarite materializirani pogled, lahko dostopate do svojih podatkov iz podatkovnega toka s pomočjo SQL in poenostavite svoje podatkovne cevovode z ustvarjanjem materializiranih pogledov neposredno na vrhu toka.
Izvedite naslednje korake za konfiguracijo materializiranega pogleda pretakanja Amazon Redshift:
- Na konzoli IAM izberite pravilnike v podoknu za krmarjenje.
- Izberite Ustvari pravilnik.
- Ustvarite novo politiko IAM, imenovano
KinesisStreamPolicy. Za definicijo politike pretakanja glejte Kako začeti s pretakanjem. - V podoknu za krmarjenje izberite vloge.
- Izberite Ustvari vlogo.
- Izberite Storitev AWS In izberite Redshift in Redshift prilagodljiv.
- Ustvarite novo vlogo, imenovano
redshift-streaming-rolein priložite pravilnikKinesisStreamPolicy. - Ustvarite zunanjo shemo za preslikavo podatkovnih tokov Kinesis:
Zdaj lahko ustvarite materializiran pogled za uporabo podatkov toka. Podatkovni tip SUPER lahko uporabite za shranjevanje tovora takšnega, kot je, v formatu JSON, ali pa uporabite funkcije Amazon Redshift JSON za razčlenitev podatkov JSON v posamezne stolpce. Za to objavo uporabljamo drugo metodo, ker je shema dobro definirana.
- Ustvarite materializirani pogled pretakanja
cust_payment_tx_stream. Če v naslednji kodi določite AUTO REFRESH YES, lahko omogočite samodejno osveževanje pogleda vnosa pretakanja, kar prihrani čas, saj se izognete gradnji podatkovnih cevovodov:
Upoštevajte, da json_extract_path_text ima omejitev dolžine 64 KB. Tudi from_varbye filtrira zapise, večje od 65 KB.
- Osvežite podatke.
Materializirani pogled pretakanja Amazon Redshift samodejno osveži Amazon Redshift za vas. Tako vam ni treba skrbeti zaradi zastarelosti podatkov. S samodejnim osveževanjem materializiranega pogleda se podatki samodejno naložijo v Amazon Redshift, ko postanejo na voljo v toku. Če se odločite za ročno izvedbo te operacije, uporabite naslednji ukaz:
- Zdaj pa poizvedimo v pretočnem materializiranem pogledu, da si ogledamo vzorčne podatke:

- Preverimo, koliko zapisov je zdaj v pogledu pretakanja:

Zdaj ste končali z nastavitvijo pogleda vnosa pretakanja Amazon Redshift, ki se nenehno posodablja z dohodnimi podatki o transakcijah s kreditno kartico. V moji nastavitvi vidim, da je bilo okoli 67,000 zapisov potegnjenih v pogled pretakanja v času, ko sem zagnal svojo poizvedbo za štetje izbire. Ta številka je lahko drugačna za vas.
Rdeči premik ML
Z Redshift ML lahko prinesete vnaprej pripravljen model ML ali ga ustvarite doma. Za več informacij glejte Uporaba strojnega učenja v Amazon Redshift.
V tej objavi usposabljamo in gradimo model ML z uporabo zgodovinskega nabora podatkov. Podatki vsebujejo a tx_fraud polje, ki zgodovinsko transakcijo označi kot goljufivo ali ne. Gradimo nadzorovani model ML z uporabo Redshift Auto ML, ki se uči iz tega nabora podatkov in predvideva dohodne transakcije, ko se izvajajo prek funkcij predvidevanja.
V naslednjih razdelkih prikazujemo, kako nastaviti nabor zgodovinskih podatkov in podatke o strankah.
Naložite nabor zgodovinskih podatkov
Zgodovinska tabela ima več polj kot vir pretočnih podatkov. Ta polja vsebujejo strankino zadnjo porabo in oceno terminalskega tveganja, kot je število goljufivih transakcij, izračunanih s pretvorbo pretočnih podatkov. Obstajajo tudi kategorične spremenljivke, kot so transakcije ob koncu tedna ali nočne transakcije.
Za nalaganje zgodovinskih podatkov zaženite ukaze z uporabo Amazon Redshift urejevalnik poizvedb.
Ustvarite tabelo zgodovine transakcij z naslednjo kodo. DDL lahko najdete tudi na GitHub.
Preverimo, koliko transakcij je naloženih:
Preverite mesečni trend goljufij in transakcij, ki niso goljufije:
Ustvarite in naložite podatke o strankah
Zdaj ustvarimo tabelo strank in naložimo podatke, ki vsebujejo e-pošto in telefonsko številko stranke. Naslednja koda ustvari tabelo, naloži podatke in vzorči tabelo. Tabela DDL je na voljo na GitHub.
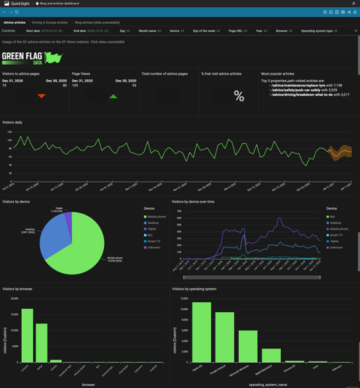
Naši testni podatki obsegajo približno 5,000 strank. Naslednji posnetek zaslona prikazuje vzorčne podatke o strankah.

Zgradite model ML
Naša tabela preteklih kartičnih transakcij vsebuje podatke za 6 mesecev, ki jih zdaj uporabljamo za usposabljanje in testiranje modela ML.
Model kot vhod sprejme naslednja polja:
Dobimo tx_fraud kot izhod.
Te podatke razdelimo na nabore podatkov za usposabljanje in teste. Transakcije od 2022. aprila 04 do 01. julija 2022 so za nabor za usposabljanje. Transakcije od 07. avgusta 31 do 2022. septembra 08 se uporabljajo za testni niz.
Ustvarimo model ML z uporabo znanega SQL Stavek CREATE MODEL. Uporabljamo osnovno obliko ukaza Redshift ML. Uporablja se naslednja metoda Amazonski SageMaker avtopilot, ki za vas samodejno izvaja pripravo podatkov, inženiring funkcij, izbiro modela in usposabljanje. Navedite ime vašega vedra S3, ki vsebuje kodo.
Model ML imenujem kot Cust_cc_txn_fd, in funkcija napovedi kot fn_customer_cc_fd. Klavzula FROM prikazuje vhodne stolpce iz zgodovinske tabele public.cust_payment_tx_history. Ciljni parameter je nastavljen na tx_fraud, ki je ciljna spremenljivka, ki jo poskušamo predvideti. IAM_Role je nastavljeno na privzeto, ker je gruča konfigurirana s to vlogo; če ne, morate zagotoviti svojo vlogo IAM v gruči Amazon Redshift ARN. Nastavil sem max_runtime na 3,600 sekund, kar je čas, ki ga damo SageMakerju, da dokonča postopek. Redshift ML uporablja najboljši model, ki je prepoznan v tem časovnem okviru.
Odvisno od kompleksnosti modela in količine podatkov lahko traja nekaj časa, da je model na voljo. Če ugotovite, da izbira modela ni popolna, povečajte vrednost za max_runtime. Nastavite lahko največjo vrednost 9999.
Ukaz CREATE MODEL se izvaja asinhrono, kar pomeni, da deluje v ozadju. Lahko uporabite PRIKAŽI MODEL ukaz za ogled statusa modela. Ko je status pripravljen, to pomeni, da je model usposobljen in uveden.
Naslednji posnetki zaslona prikazujejo naš rezultat.



Iz rezultatov vidim, da je bil model pravilno prepoznan kot BinaryClassification, F1 pa je bil izbran kot cilj. The Ocena F1 je metrika, ki upošteva oboje natančnost in odpoklic. Vrne vrednost med 1 (popolna natančnost in priklic) in 0 (najnižja možna ocena). V mojem primeru je 0.91. Višja kot je vrednost, boljša je zmogljivost modela.
Preizkusimo ta model s testnim naborom podatkov. Zaženite naslednji ukaz, ki pridobi vzorčne napovedi:

Vidimo, da se nekatere vrednosti ujemajo, nekatere pa ne. Primerjajmo napovedi s temeljno resnico:

Potrdili smo, da model deluje in je ocena F1 dobra. Preidimo na ustvarjanje napovedi o pretočnih podatkih.
Predvidi goljufive transakcije
Ker je model Redshift ML pripravljen za uporabo, ga lahko uporabimo za izvajanje napovedi proti zaužitju pretočnih podatkov. Zgodovinski nabor podatkov ima več polj kot tisto, kar imamo v viru pretočnih podatkov, vendar so to samo meritve nedavnosti in pogostosti glede tveganja stranke in terminala za goljufivo transakcijo.
Transformacije lahko zelo enostavno uporabimo na vrhu pretočnih podatkov, tako da SQL vdelamo v poglede. Ustvarite prvi pogled, ki združuje pretočne podatke na ravni stranke. Nato ustvarite drugi pogled, ki združuje pretočne podatke na ravni terminala, in tretji pogled, ki združuje dohodne transakcijske podatke z agregiranimi podatki o strankah in terminalih ter kliče funkcijo napovedi vse na enem mestu. Koda za tretji pogled je naslednja:
Zaženite stavek SELECT na pogledu:
Ko večkrat zaženete izjavo SELECT, gredo najnovejše transakcije s kreditnimi karticami skozi transformacije in napovedi ML v skoraj realnem času.
To dokazuje moč Amazon Redshift – z ukazi SQL, ki so enostavni za uporabo, lahko pretvorite pretočne podatke z uporabo zapletenih okenskih funkcij in uporabite model ML za napovedovanje goljufivih transakcij v enem koraku, brez gradnje zapletenih podatkovnih cevovodov ali gradnje in upravljanja dodatno infrastrukturo.
Razširite rešitev
Ker so podatkovni tokovi in napovedi ML izdelani v skoraj realnem času, lahko zgradite poslovne procese za opozarjanje vaše stranke z Amazon Simple notification Service (Amazon SNS), lahko pa zaklenete račun kreditne kartice stranke v operacijskem sistemu.
Ta objava se ne spušča v podrobnosti teh operacij, če pa želite izvedeti več o izdelavi rešitev, ki temeljijo na dogodkih, z uporabo Amazon Redshift, glejte naslednje GitHub repozitorij.
Čiščenje
Da se izognete prihodnjim stroškom, izbrišite vire, ki so bili ustvarjeni kot del te objave.
zaključek
V tej objavi smo pokazali, kako nastaviti podatkovni tok Kinesis, konfigurirati proizvajalca in objaviti podatke v tokovih ter nato ustvariti pogled Amazon Redshift Streaming Ingestion in poizvedovati po podatkih v Amazon Redshift. Ko so bili podatki v gruči Amazon Redshift, smo pokazali, kako usposobiti model ML in zgraditi funkcijo napovedi ter jo uporabiti proti pretočnim podatkom za ustvarjanje napovedi v skoraj realnem času.
Če imate kakršne koli povratne informacije ali vprašanja, jih pustite v komentarjih.
O avtorjih
 Bhanu Pittampally je strokovnjak za analitične rešitve arhitekt s sedežem v Dallasu. Specializiran je za gradnjo analitičnih rešitev. Njegovo ozadje je na področju podatkovnih skladišč – arhitektura, razvoj in administracija. Na področju podatkov in analitike je že več kot 15 let.
Bhanu Pittampally je strokovnjak za analitične rešitve arhitekt s sedežem v Dallasu. Specializiran je za gradnjo analitičnih rešitev. Njegovo ozadje je na področju podatkovnih skladišč – arhitektura, razvoj in administracija. Na področju podatkov in analitike je že več kot 15 let.
 Praveen Kadipikonda je višji arhitekt specialist za analitiko pri AWS iz Dallasa. Strankam pomaga zgraditi učinkovite, zmogljive in razširljive analitične rešitve. Že več kot 15 let se ukvarja z izgradnjo podatkovnih baz in rešitev za skladišča podatkov.
Praveen Kadipikonda je višji arhitekt specialist za analitiko pri AWS iz Dallasa. Strankam pomaga zgraditi učinkovite, zmogljive in razširljive analitične rešitve. Že več kot 15 let se ukvarja z izgradnjo podatkovnih baz in rešitev za skladišča podatkov.
 Ritesh Kumar Sinha je specialist za analitične rešitve arhitekt s sedežem v San Franciscu. Strankam že več kot 16 let pomaga zgraditi razširljivo skladiščenje podatkov in rešitve za velike količine podatkov. Rad oblikuje in gradi učinkovite rešitve od konca do konca na AWS. V prostem času rad bere, se sprehaja in se ukvarja z jogo.
Ritesh Kumar Sinha je specialist za analitične rešitve arhitekt s sedežem v San Franciscu. Strankam že več kot 16 let pomaga zgraditi razširljivo skladiščenje podatkov in rešitve za velike količine podatkov. Rad oblikuje in gradi učinkovite rešitve od konca do konca na AWS. V prostem času rad bere, se sprehaja in se ukvarja z jogo.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/near-real-time-fraud-detection-using-amazon-redshift-streaming-ingestion-with-amazon-kinesis-data-streams-and-amazon-redshift-ml/
- 000
- 000 kupcev
- 1
- 10
- 100
- 11
- 15 let
- 67
- 7
- 9
- a
- Sposobna
- O meni
- nad
- dostop
- Račun
- Doseči
- Ukrep
- Dodatne
- uprava
- napredno
- po
- proti
- Opozorite
- vsi
- omogoča
- Amazon
- Amazon EC2
- Amazon Kinesis
- znesek
- Analitiki
- Analitični
- analitika
- analizirati
- in
- odkrivanje anomalije
- Apache
- uporaba
- Uporabi
- Uporaba
- Arhitektura
- okoli
- pripisujejo
- avto
- Samodejno
- samodejno
- Na voljo
- izogibanje
- AWS
- ozadje
- temeljijo
- Osnovni
- ker
- postane
- BEST
- Boljše
- med
- Big
- Big Podatki
- prinašajo
- izgradnjo
- Building
- poslovni
- poslovnih procesov
- podjetja
- klic
- se imenuje
- poziva
- zajemanje
- kartice
- primeru
- primeri
- značaja
- Stroški
- preveriti
- Izberite
- mesto
- Cloud
- Grozd
- Koda
- Stolpci
- združuje
- prihajajo
- komentarji
- primerjate
- dokončanje
- dokončanje
- kompleksna
- kompleksnost
- Izračunajte
- meni
- Konzole
- porabijo
- Potrošnik
- Vsebuje
- stroškovno učinkovito
- bi
- ustvarjajo
- ustvaril
- ustvari
- Ustvarjanje
- Mandatno
- kredit
- kreditne kartice
- stranka
- podatki o strankah
- Stranke, ki so
- ciklov
- vsak dan
- Dallas
- datum
- Priprava podatkov
- podatkovno skladišče
- skladišča podatkov
- Baze podatkov
- baze podatkov
- nabor podatkov
- Datum
- Odločanje
- privzeto
- definiranje
- poda
- Dokazano
- odvisno
- razporedi
- razporejeni
- razpolaga
- opisano
- Oblikovanje
- Podrobnosti
- Odkrivanje
- Razvijalci
- Razvoj
- drugačen
- neposredno
- Ne
- tem
- dont
- dow
- dinamično
- enostavno
- enostaven za uporabo
- učinek
- učinkovite
- E-naslov
- omogočajo
- omogoča
- konec koncev
- Inženiring
- Vnesite
- Eter (ETH)
- Event
- dogodki
- Primer
- razburjen
- zunanja
- pridobivanje
- f1
- seznanjeni
- FAST
- Feature
- Lastnosti
- povratne informacije
- Polje
- Področja
- Filtri
- finančna
- Najdi
- zastave
- Pretok
- sledi
- po
- sledi
- obrazec
- format
- je pokazala,
- FRAME
- Francisco
- goljufija
- odkrivanje goljufij
- brezplačno
- frekvenca
- iz
- v celoti
- funkcija
- funkcije
- Prihodnost
- ustvarjajo
- ustvarila
- ustvarjajo
- generator
- dobili
- Daj
- Go
- dobro
- odobri
- Igrišče
- skupina
- ob
- pomagal
- Pomaga
- več
- Označite
- zgodovinski
- zgodovina
- Kako
- Kako
- HTML
- HTTPS
- Stotine
- IAM
- identificirati
- identiteta
- Pomembnost
- in
- vključujejo
- Dohodni
- Povečajte
- narašča
- individualna
- Podatki
- Infrastruktura
- vhod
- Vložki
- vpogledi
- namestitev
- primer
- Inštitut
- Navodila
- zainteresirani
- IT
- pridružite
- json
- kafka
- Podatkovni tokovi Kinesis
- jezik
- večja
- Latenca
- Zadnji
- kosilo
- učenje
- pustite
- dolžina
- Stopnja
- LIMIT
- Omejitev
- obremenitev
- obremenitve
- dolgoročna
- nizka
- stroj
- strojno učenje
- je
- Znamka
- IZDELA
- upravlja
- upravljanje
- ročno
- več
- map
- množično
- ujemanje
- matplotlib
- max
- pomeni
- mediji
- Metoda
- meritev
- Meritve
- Omiliti
- ML
- način
- Model
- modeli
- mesečno
- mesecev
- več
- Najbolj
- premikanje
- Ime
- ostalo
- Nimate
- potrebe
- Novo
- Naslednja
- Obvestilo
- Številka
- otopeli
- Cilj
- ONE
- Odpre
- Delovanje
- operativno
- operacije
- Priložnosti
- možnosti
- Da
- organizacije
- Ostalo
- opisano
- pakete
- pand
- podokno
- parameter
- del
- popolna
- opravlja
- performance
- opravlja
- Dovoljenja
- telefon
- Kraj
- načrtovanje
- platforma
- Platforme
- platon
- Platonova podatkovna inteligenca
- PlatoData
- prosim
- politike
- politika
- mogoče
- Prispevek
- moč
- Precision
- napovedati
- napoved
- Napovedi
- Napovedi
- prejšnja
- cenitev
- Postopek
- Procesi
- Proizvajalec
- Program
- zagotavljajo
- zagotavlja
- javnega
- objavijo
- Python
- vprašanja
- hitro
- naključno
- reading
- pripravljen
- pravo
- v realnem času
- podatki v realnem času
- uresničevanje
- prejeti
- prejetih
- nedavno
- priznana
- evidence
- PONOVNO
- zamenjajte
- obvezna
- vir
- viri
- REST
- Rezultati
- vrne
- Tveganje
- vloga
- Run
- tek
- sagemaker
- San
- San Francisco
- razširljive
- Lestvica
- galerija
- SDK
- morski rojen
- drugi
- sekund
- Oddelek
- oddelki
- zavarovanje
- izbran
- izbor
- Brez strežnika
- Storitev
- nastavite
- nastavitev
- nastavitve
- nastavitev
- kratkoročno
- Prikaži
- Razstave
- Enostavno
- poenostavitev
- Simulator
- So
- socialna
- družbeni mediji
- Rešitev
- rešitve
- nekaj
- vir
- Viri
- specialist
- specializirano
- preživeti
- po delih
- SQL
- Stage
- standardna
- začel
- Država
- Izjava
- Izjave
- Status
- Korak
- Koraki
- shranjevanje
- trgovina
- trgovine
- Strateško
- tok
- pretakanje
- storitev pretakanja
- tokovi
- taka
- Super
- sistem
- sistemi
- miza
- Bodite
- meni
- pogovori
- ciljna
- terminal
- Test
- O
- tretja
- tisoče
- skozi
- čas
- Časovni žig
- do
- vrh
- temo
- tradicionalno
- Vlak
- usposobljeni
- usposabljanje
- transakcija
- transakcijski
- Transakcije
- Transform
- transformacije
- preoblikovanje
- Trend
- Nadgradnja
- posodobljeno
- Uporaba
- uporaba
- uporabnik
- potrjeno
- vrednost
- Vrednote
- različnih
- Verity
- različica
- Poglej
- ogledov
- hoja
- walkthrough
- Skladišče
- skladiščenje
- Spletna stran
- vikend
- Tedenski
- Kaj
- ki
- medtem
- Wikipedia
- bo
- brez
- delal
- deluje
- deluje
- pisati
- let
- Joga
- Vaša rutina za
- zefirnet