Agenti za povzemanje, ki jih predstavlja orodje za ustvarjanje slik z umetno inteligenco Dall-E.
Ste del populacije, ki pušča ocene na Google zemljevidih vsakič, ko obiščete novo restavracijo?
Ali pa ste morda tisti tip, ki deli svoje mnenje o nakupih na Amazonu, še posebej, ko vas sproži izdelek nizke kakovosti?
Ne skrbite, ne bom vam zameril – vsi imamo svoje trenutke!
V današnjem svetu podatkov vsi na več načinov prispevamo k poplavi podatkov. Ena vrsta podatkov, ki se mi zdi posebej zanimiva zaradi svoje raznolikosti in težavnosti interpretacije, so besedilni podatki, kot so neštete ocene, ki so vsak dan objavljene na internetu. Ali ste kdaj razmišljali o pomembnosti standardizacije in zgoščevanja besedilnih podatkov? Dobrodošli v svetu agentov za povzemanje!
Agenti za povzemanje so se neopazno integrirali v naše vsakdanje življenje, z zgoščevanjem informacij in zagotavljanjem hitrega dostopa do ustrezne vsebine v številnih aplikacijah in platformah.
V tem članku bomo raziskali uporabo ChatGPT kot zmogljivega agenta za povzemanje za naše aplikacije po meri. Zahvaljujoč zmožnosti velikih jezikovnih modelov (LLM) za obdelavo in razumevanje besedil, lahko pomagajo pri branju besedil in ustvarjanju natančnih povzetkov ali standardizaciji informacij. Vendar je pomembno znati izluščiti njihov potencial pri opravljanju takšne naloge, pa tudi priznati njihove omejitve.
Največja omejitev za povzemanje? LLM pogosto ne uspejo, ko gre za upoštevanje določenih znakov ali besednih omejitev v svojih povzetkih.
Raziščimo najboljše prakse za ustvarjanje povzetkov s ChatGPT za našo aplikacijo po meri, pa tudi razloge za njene omejitve in kako jih premagati!
Agenti za povzemanje se uporabljajo po vsem internetu. Spletna mesta na primer uporabljajo agente za povzemanje, da ponudijo jedrnate povzetke člankov, kar uporabnikom omogoča hiter pregled novic, ne da bi se poglobili v celotno vsebino. To počnejo tudi platforme družbenih medijev in iskalniki.
Od agregatorjev novic in platform družbenih medijev do spletnih mest za e-trgovino so agenti za povzemanje postali sestavni del našega digitalnega okolja.. In z dvigom LLM nekateri od teh agentov zdaj uporabljajo AI za učinkovitejše povzemanje rezultatov.
ChatGPT je lahko dober zaveznik pri gradnji aplikacije z uporabo agentov za povzemanje za pospešitev bralnih nalog in razvrščanje besedil. Na primer, predstavljajte si, da imamo podjetje za e-trgovino in nas zanima obdelava vseh mnenj naših strank. ChatGPT bi nam lahko pomagal pri povzemanju katerega koli pregleda v nekaj stavkih, standardizaciji v generično obliko, določanju razpoloženje pregleda in razvrščanje temu primerno.
Čeprav je res, da bi lahko pregled preprosto posredovali ChatGPT, obstaja seznam najboljših praks — in stvari, ki se jim je treba izogibati — da izkoristite moč ChatGPT pri tej konkretni nalogi.
Raziščimo možnosti tako, da ta primer oživimo!
Primer: Ocene e-trgovine
Gif, narejen sam.
Razmislite o zgornjem primeru, v katerem nas zanima obdelava vseh mnenj za določen izdelek na naši spletni strani za e-trgovino. Zanimalo bi nas za obdelavo mnenj, kot je naslednja o našem zvezdniškem izdelku: prvi računalnik za otroke!
prod_review = """
I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlier
than expected, so I got to play with it myself before I gave it to him. """
V tem primeru želimo, da ChatGPT:
Oceno razvrstite na pozitivno ali negativno.
Navedite povzetek pregleda v 20 besedah.
Izpišite odgovor s konkretno strukturo, da standardizirate vse ocene v en sam format.
Opombe o izvedbi
Tukaj je osnovna struktura kode, ki bi jo lahko uporabili za poziv ChatGPT iz naše aplikacije po meri. Ponujam tudi povezavo do a Jupyter Notebook z vsemi primeri, uporabljenimi v tem članku.
import openai
import os openai.api_key_path = "/path/to/key" def get_completion(prompt, model="gpt-3.5-turbo"): """
This function calls ChatGPT API with a given prompt
and returns the response back. """ messages = [{"role": "user", "content": prompt}] response = openai.ChatCompletion.create( model=model, messages=messages, temperature=0 ) return response.choices[0].message["content"] user_text = f"""
<Any given text> """ prompt = f"""
<Any prompt with additional text> """{user_text}""" """ # A simple call to ChatGPT
response = get_completion(prompt)
funkcija get_completion() pokliče API ChatGPT z danim poziv. Če poziv vsebuje dodatne besedilo uporabnika, kot je v našem primeru sama recenzija, je od preostale kode ločena s trojnimi narekovaji.
Uporabimo get_completion() funkcijo za poziv ChatGPT!
Tukaj je poziv, ki izpolnjuje zgoraj opisane zahteve:
prompt = f"""
Your task is to generate a short summary of a product review from an e-commerce site. Summarize the review below, delimited by triple backticks, in exactly 20 words. Output a json with the sentiment of the review, the summary and original review as keys. Review: ```{prod_review}``` """
response = get_completion(prompt)
print(response)
{ "sentiment": "positive", "summary": "Durable and engaging children's computer with intuitive interface and educational games. Volume could be louder.", "review": "I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlierthan expected, so I got to play with it myself before I gave it to him."
}
Kot lahko opazimo iz rezultatov, je pregled točen in dobro strukturiran, čeprav manjka nekaj informacij, ki bi nas lahko zanimale kot lastnike e-trgovine, kot so informacije o dostavi izdelka.
Povzemite s poudarkom na
Iterativno lahko izboljšamo naš poziv, ki ChatGPT zahteva, naj se osredotoči na določene stvari v povzetku. V tem primeru nas zanimajo vse podrobnosti glede pošiljanja in dostave:
prompt = f"""
Your task is to generate a short summary of a product review from an ecommerce site. Summarize the review below, delimited by triple backticks, in exactly 20 words and focusing on any aspects that mention shipping and delivery of the product. Output a json with the sentiment of the review, the summary and original review as keys. Review: ```{prod_review}``` """ response = get_completion(prompt)
print(response)
Tokratni odgovor ChatGPT je naslednji:
{ "sentiment": "positive", "summary": "Durable and engaging children's computer with intuitive interface. Arrived a day earlier than expected.", "review": "I purchased this children's computer for my son, and he absolutely adores it. He spends hours exploring its various features and engaging with the educational games. The colorful design and intuitive interface make it easy for him to navigate. The computer is durable and built to withstand rough handling, which is perfect for active kids. My only minor gripe is that the volume could be a bit louder. Overall, it's an excellent educational toy that provides hours of fun and learning for my son. It arrived a day earlierthan expected, so I got to play with it myself before I gave it to him."
}
Zdaj je pregled veliko bolj popoln. Navedba podrobnosti o pomembnem fokusu prvotnega pregleda je ključnega pomena, da se izognete temu, da ChatGPT preskoči nekatere informacije, ki bi lahko bile dragocene za naš primer uporabe.
Ali ste opazili, da čeprav ta drugi poskus vključuje informacije o dostavi, je preskočil edini negativni vidik prvotnega pregleda?
Popravimo to!
»Izvleči« namesto »Povzemi«
Z raziskovanjem nalog za povzemanje sem ugotovil, da povzemanje je lahko težavna naloga za LLM, če uporabniški poziv ni dovolj natančen.
Ko ChatGPT zahteva povzetek danega besedila, lahko preskoči informacije, ki bi lahko bile pomembne za nas — kot smo pred kratkim doživeli — ali pa bo dal enak pomen vsem temam v besedilu, le dal bo pregled glavnih točk.
Strokovnjaki v LLM uporabljajo izraz ekstrakt in dodatne informacije o njihovih fokusih namesto Povzamemo pri opravljanju takih nalog s pomočjo tovrstnih modelov.
Medtem ko je cilj povzemanja zagotoviti jedrnat pregled glavnih točk besedila, vključno s temami, ki niso povezane s temo, ki je v središču pozornosti, se pridobivanje informacij osredotoča na pridobivanje specifičnih podrobnosti in nam lahko da točno tisto, kar iščemo. Poskusimo torej z ekstrakcijo!
prompt = f"""
Your task is to extract relevant information from a product review from an ecommerce site to give feedback to the Shipping department. From the review below, delimited by triple quotes extract the information relevant to shipping and delivery. Use 100 characters. Review: ```{prod_review}``` """ response = get_completion(prompt)
print(response)
V tem primeru z ekstrakcijo dobimo le informacije o temi, ki smo jo osredotočili: Shipping: Arrived a day earlier than expected.
Avtomatizacija
Ta sistem deluje za en sam pregled. Kljub temu pri oblikovanju poziva za konkretno aplikacijo, pomembno je, da ga preizkusimo v nizu primerov, da lahko ujamemo morebitne odstopanja ali napačno vedenje v modelu.
V primeru obdelave več pregledov je tukaj vzorčna struktura kode Python, ki vam lahko pomaga.
reviews = [ "The children's computer I bought for my daughter is absolutely fantastic! She loves it and can't get enough of the educational games. The delivery was fast and arrived right on time. Highly recommend!", "I was really disappointed with the children's computer I received. It didn't live up to my expectations, and the educational games were not engaging at all. The delivery was delayed, which added to my frustration.", "The children's computer is a great educational toy. My son enjoys playing with it and learning new things. However, the delivery took longer than expected, which was a bit disappointing.", "I am extremely happy with the children's computer I purchased. It's highly interactive and keeps my kids entertained for hours. The delivery was swift and hassle-free.", "The children's computer I ordered arrived damaged, and some of the features didn't work properly. It was a huge letdown, and the delivery was also delayed. Not a good experience overall."
] prompt = f""" Your task is to generate a short summary of each product review from an e-commerce site. Extract positive and negative information from each of the given reviews below, delimited by triple backticks in at most 20 words each. Extract information about the delivery, if included. Review: ```{reviews}``` """
Tukaj so povzetki naše serije pregledov:
1. Positive: Fantastic children's computer, fast delivery. Highly recommend.
2. Negative: Disappointing children's computer, unengaging games, delayed delivery.
3. Positive: Great educational toy, son enjoys it. Delivery took longer than expected.
4. Positive: Highly interactive children's computer, swift and hassle-free delivery.
5. Negative: Damaged children's computer, some features didn't work, delayed delivery.
⚠️ Upoštevajte, da čeprav je bila besedna omejitev naših povzetkov dovolj jasna v naših pozivih, zlahka vidimo, da ta besedna omejitev ni dosežena v nobeni ponovitvi.
Do tega neskladja pri štetju besed pride, ker LLM nimajo natančnega razumevanja števila besed ali znakov. Razlog za to se opira na eno glavnih pomembnih komponent njihove arhitekture: tokenizer.
Tokenizer
LLM-ji, kot je ChatGPT, so zasnovani za ustvarjanje besedila na podlagi statističnih vzorcev, pridobljenih iz ogromnih količin jezikovnih podatkov. Čeprav so zelo učinkoviti pri ustvarjanju tekočega in koherentnega besedila, nimajo natančnega nadzora nad številom besed.
V zgornjih primerih, ko smo dali navodila o zelo natančnem štetju besed, ChatGPT se je trudil izpolniti te zahteve. Namesto tega je ustvaril besedilo, ki je dejansko krajše od določenega števila besed.
V drugih primerih lahko ustvari daljša besedila ali preprosto besedilo, ki je preveč besedno ali brez podrobnosti. Poleg tega ChatGPT lahko da prednost drugim dejavnikom, kot sta skladnost in ustreznost, pred strogim upoštevanjem števila besed. Posledica tega je lahko besedilo, ki je visokokakovostno v smislu svoje vsebine in koherencije, vendar ne ustreza natančno zahtevi glede števila besed.
Tokenizer je ključni element v arhitekturi ChatGPT, ki jasno vpliva na število besed v ustvarjenem rezultatu.
Gif, narejen sam.
Arhitektura tokenizerja
Tokenizer je prvi korak v procesu ustvarjanja besedila. Odgovoren je za razčlenitev dela besedila, ki ga vnesemo v ChatGPT, na posamezne elemente — žetoni —, ki jih nato obdela jezikovni model za ustvarjanje novega besedila.
Ko tokenizer razdeli del besedila na žetone, to stori na podlagi niza pravil, ki so zasnovana za prepoznavanje smiselnih enot ciljnega jezika. Vendar ta pravila niso vedno popolna in lahko pride do primerov, ko tokenizer razdeli ali združi žetone na način, ki vpliva na skupno število besed v besedilu.
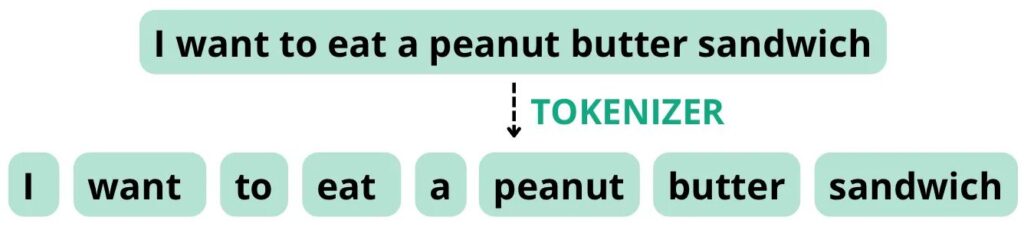
Na primer, upoštevajte naslednji stavek: "Želim jesti sendvič z arašidovim maslom". Če je tokenizer konfiguriran za razdelitev žetonov na podlagi presledkov in ločil, lahko ta stavek razdeli na naslednje žetone s skupnim številom besed 8, kar je enako številu žetonov.
Slika lastne izdelave.
Vendar, če je tokenizer konfiguriran za zdravljenje "arašidovo maslo" kot zloženka lahko stavek razdeli na naslednje žetone, s skupnim številom besed 8, vendar številom žetonov 7.
Tako lahko način konfiguracije tokenizerja vpliva na skupno število besed v besedilu, kar lahko vpliva na zmožnost LLM, da sledi navodilom o natančnem štetju besed. Medtem ko nekateri izdelovalci žetonov ponujajo možnosti za prilagoditev, kako je besedilo označeno z žetoni, to ni vedno dovolj za zagotovitev natančnega upoštevanja zahtev glede števila besed. Za ChatGPT v tem primeru ne moremo nadzorovati tega dela njegove arhitekture.
Zaradi tega ChatGPT ni tako dober pri doseganju omejitev znakov ali besed, vendar lahko namesto tega poskusite s stavki, saj tokenizer ne vpliva število stavkov, ampak njihova dolžina.
Zavedanje te omejitve vam lahko pomaga sestaviti najbolj primeren poziv za vašo aplikacijo. Ker imamo to znanje o tem, kako deluje štetje besed na ChatGPT, naredimo zadnjo ponovitev z našim pozivom za aplikacijo za e-trgovino!
Zaključek: Pregledi e-trgovine
Združimo svoja spoznanja iz tega članka v končni poziv! V tem primeru bomo zahtevali rezultate v HTML format za lepši izpis:
from IPython.display import display, HTML prompt = f"""
Your task is to extract relevant information from a product review from an ecommerce site to give feedback to the Shipping department and generic feedback from the product. From the review below, delimited by triple quotes construct an HTML table with the sentiment of the review, general feedback from
the product in two sentences and information relevant to shipping and delivery. Review: ```{prod_review}``` """ response = get_completion(prompt)
display(HTML(response))
In tukaj je končni rezultat ChatGPT:
Posnetek zaslona, ki ga je naredil sam iz Jupyter Notebook s primeri, uporabljenimi v tem članku.
Povzetek
V tem članku, razpravljali smo o najboljših praksah za uporabo ChatGPT kot agenta za povzemanje za našo aplikacijo po meri.
Videli smo, da je pri gradnji aplikacije izjemno težko priti do popolnega poziva, ki ustreza zahtevam vaše aplikacije v prvem poskusu. Mislim, da je lepo sporočilo za domov razmislite o spodbujanju kot o ponavljajočem se procesu kjer izpopolnjujete in modelirate svoj poziv, dokler ne dobite točno želenega rezultata.
Z iterativnim izpopolnjevanjem vašega poziva in njegovo uporabo v skupini primerov, preden ga uvedete v produkcijo, lahko zagotovite rezultat je dosleden v več primerih in pokriva izstopajoče odgovore. V našem primeru se lahko zgodi, da nekdo ponudi naključno besedilo namesto ocene. ChatGPT lahko naročimo, naj ima tudi standardiziran izhod, da izključi te izstopajoče odgovore.
Poleg tega je pri uporabi ChatGPT za določeno nalogo dobra praksa, da se poučite o prednostih in slabostih uporabe LLM-jev za našo ciljno nalogo. Tako smo naleteli na dejstvo, da so naloge ekstrakcije učinkovitejše od povzemanja, ko želimo običajen človeški povzetek vnesenega besedila. Naučili smo se tudi, da je lahko zagotavljanje fokusa povzetka a game-changer glede ustvarjene vsebine.
Nazadnje, medtem ko so LLM lahko zelo učinkoviti pri ustvarjanju besedila, niso idealni za sledenje natančnim navodilom o številu besed ali drugih posebnih zahtevah glede oblikovanja. Da bi dosegli te cilje, se bo morda treba držati štetja stavkov ali uporabiti druga orodja ali metode, kot je ročno urejanje ali bolj specializirana programska oprema.
Ta članek je bil prvotno objavljen na Proti znanosti o podatkih in z dovoljenjem avtorja ponovno objavljen v TOPBOTS.
Uživate v tem članku? Prijavite se za več posodobitev raziskav AI.
Obvestili vas bomo, ko bomo objavili več povzetkov, kot je ta.