Predstavitev
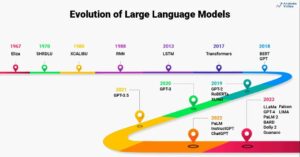
Predstavljajte si, da stojite v slabo osvetljeni knjižnici in se trudite dešifrirati zapleten dokument, medtem ko žonglirate z desetinami drugih besedil. To je bil svet Transformerjev, preden je časopis »Attention is All You Need« razkril svoj revolucionarni žaromet – mehanizem pozornosti.
Kazalo
Omejitve RNN
Tradicionalni sekvenčni modeli, npr Ponavljajoče se nevronske mreže (RNN), obdelan jezik besedo za besedo, kar vodi do več omejitev:
- Odvisnost kratkega dosega: RNN-ji so se trudili razumeti povezave med oddaljenimi besedami, pri čemer so pogosto napačno razlagali pomen stavkov, kot je "človek, ki je včeraj obiskal živalski vrt", kjer sta osebek in glagol daleč narazen.
- Omejen paralelizem: Zaporedna obdelava informacij je sama po sebi počasna, kar preprečuje učinkovito usposabljanje in uporabo računalniških virov, zlasti za dolga zaporedja.
- Osredotočite se na lokalni kontekst: RNN upoštevajo predvsem neposredne sosede, potencialno manjkajo ključne informacije iz drugih delov stavka.
Te omejitve so ovirale zmožnost Transformerjev za izvajanje kompleksnih nalog, kot sta strojno prevajanje in razumevanje naravnega jezika. Potem je prišel mehanizem pozornosti, revolucionarni žaromet, ki osvetljuje skrite povezave med besedami in spreminja naše razumevanje obdelave jezika. Toda kaj točno je pozornost rešila in kako je spremenila igro za Transformerje?
Osredotočimo se na tri ključna področja:
Odvisnost na dolge razdalje
- Težava: Tradicionalni modeli so pogosto naleteli na stavke, kot je "ženska, ki je živela na hribu, je sinoči videla padajočo zvezdo." Težko so povezovali »žensko« in »strelko« zaradi njune oddaljenosti, kar je vodilo v napačne interpretacije.
- Mehanizem pozornosti: Predstavljajte si, da model sveti s svetlim žarkom čez stavek, povezuje »ženska« neposredno z »zvezdo padalko« in razume stavek kot celoto. Ta sposobnost zajemanja odnosov ne glede na razdaljo je ključnega pomena za naloge, kot sta strojno prevajanje in povzemanje.
Preberite tudi: Pregled dolgotrajnega kratkoročnega spomina (LSTM)
Vzporedna procesna moč
- Težava: Tradicionalni modeli so informacije obdelovali zaporedno, kot bi brali knjigo stran za stranjo. To je bilo počasno in neučinkovito, zlasti pri dolgih besedilih.
- Mehanizem pozornosti: Predstavljajte si več reflektorjev, ki istočasno pregledujejo knjižnico in vzporedno analizirajo različne dele besedila. To dramatično pospeši delo modela in mu omogoči učinkovito obdelavo velikih količin podatkov. Ta vzporedna procesorska moč je bistvena za usposabljanje kompleksnih modelov in napovedovanje v realnem času.
Zavedanje globalnega konteksta
- Težava: Tradicionalni modeli so se pogosto osredotočali na posamezne besede in pogrešali širši kontekst stavka. To je povzročilo nesporazume v primerih, kot sta sarkazem ali dvojni pomen.
- Mehanizem pozornosti: Predstavljajte si, da žarometi preletijo celotno knjižnico, zajamejo vsako knjigo in razumejo, kako so med seboj povezane. To zavedanje globalnega konteksta omogoča modelu, da pri interpretaciji vsake besede upošteva celotno besedilo, kar vodi do bogatejšega in bolj niansiranega razumevanja.
Razločevanje večpomenskih besed
- Težava: Besede, kot sta »banka« ali »jabolko«, so lahko samostalniki, glagoli ali celo podjetja, kar ustvarja dvoumnost, ki so jo tradicionalni modeli težko razrešili.
- Mehanizem pozornosti: Predstavljajte si, da model osvetljuje vse pojavitve besede »banka« v stavku, nato pa analizira okoliški kontekst in razmerja z drugimi besedami. Z upoštevanjem slovnične strukture, bližnjih samostalnikov in celo preteklih stavkov lahko mehanizem pozornosti izpelje predvideni pomen. Ta sposobnost razločevanja večpomenskih besed je ključnega pomena za naloge, kot so strojno prevajanje, povzemanje besedila in sistemi dialoga.
Ti štirje vidiki – odvisnost na velike razdalje, vzporedna procesorska moč, zavedanje globalnega konteksta in razločevanje – prikazujejo transformativno moč mehanizmov pozornosti. Transformerje so pognali v ospredje obdelave naravnega jezika, kar jim omogoča, da se z izjemno natančnostjo in učinkovitostjo spopadejo s kompleksnimi nalogami.
Ker se NLP in posebej LLM še naprej razvijata, bodo mehanizmi pozornosti nedvomno igrali še bolj kritično vlogo. So most med linearnim zaporedjem besed in bogato tapiserijo človeškega jezika ter navsezadnje ključ do odklepanja pravega potenciala teh jezikovnih čudes. Ta članek obravnava različne vrste mehanizmov pozornosti in njihove funkcionalnosti.
1. Pozornost nase: Transformerjeva zvezda vodilnica
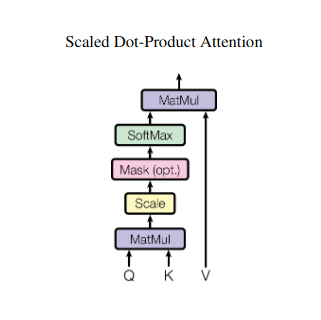
Predstavljajte si, da žonglirate z več knjigami in se morate med pisanjem povzetka sklicevati na določene odlomke v vsaki. Self-attention ali Scaled Dot-Product pozornost deluje kot inteligentni pomočnik in pomaga modelom narediti isto z zaporednimi podatki, kot so stavki ali časovne serije. Vsakemu elementu v zaporedju omogoča, da se posveti vsakemu drugemu elementu, s čimer učinkovito zajame dolgoročne odvisnosti in zapletene odnose.
Tukaj je podrobnejši pogled na njegove glavne tehnične vidike:
Vektorska predstavitev
Vsak element (beseda, podatkovna točka) se pretvori v visokodimenzionalni vektor, ki kodira njegovo informacijsko vsebino. Ta vektorski prostor služi kot temelj za interakcijo med elementi.
Transformacija QKV
Določene so tri ključne matrike:
- Poizvedba (V): Predstavlja "vprašanje", ki ga vsak element postavlja drugim. Q zajame informacijske potrebe trenutnega elementa in vodi njegovo iskanje ustreznih informacij v zaporedju.
- Ključ (K): Ima "ključ" do informacij o vsakem elementu. K kodira bistvo vsebine vsakega elementa in omogoča drugim elementom, da prepoznajo potencialno ustreznost na podlagi lastnih potreb.
- Vrednost (V): Shranjuje dejansko vsebino, ki jo želi deliti vsak element. V vsebuje podrobne informacije, do katerih lahko drugi elementi dostopajo in jih izkoristijo na podlagi svojih točk pozornosti.
Izračun ocene pozornosti
Združljivost med posameznimi pari elementov se meri s pikčastim zmnožkom med njihovimi vektorji Q in K. Višji rezultati kažejo na močnejšo potencialno relevantnost med elementi.
Skalirane uteži pozornosti
Da bi zagotovili relativno pomembnost, so te ocene združljivosti normalizirane s funkcijo softmax. Posledica tega so uteži pozornosti, ki segajo od 0 do 1, kar predstavlja uteženo pomembnost vsakega elementa za kontekst trenutnega elementa.
Uteženo združevanje konteksta
Uteži pozornosti se uporabijo za matriko V, ki v bistvu poudarja pomembne informacije iz vsakega elementa glede na njegovo pomembnost za trenutni element. Ta utežena vsota ustvari kontekstualizirano predstavitev trenutnega elementa, ki vključuje vpoglede, pridobljene iz vseh drugih elementov v zaporedju.
Izboljšana predstavitev elementov
S svojo obogateno predstavitvijo ima element zdaj globlje razumevanje lastne vsebine kot tudi odnosov z drugimi elementi v zaporedju. Ta transformirana predstavitev tvori osnovo za nadaljnjo obdelavo znotraj modela.
Ta večstopenjski postopek omogoča samopozornost na:
- Zajemite dolgoročne odvisnosti: Odnosi med oddaljenimi elementi postanejo takoj očitni, tudi če so ločeni z več vmesnimi elementi.
- Modelirajte kompleksne interakcije: Razkrite so subtilne odvisnosti in korelacije znotraj zaporedja, kar vodi do bogatejšega razumevanja podatkovne strukture in dinamike.
- Kontekstualizirajte vsak element: Model ne analizira vsakega elementa ločeno, ampak znotraj širšega okvira zaporedja, kar vodi do natančnejših in niansiranih napovedi ali predstavitev.
Pozornost nase je spremenila način, kako modeli obdelujejo zaporedne podatke, odklenila nove možnosti na različnih področjih, kot je strojno prevajanje, ustvarjanje naravnega jezika, napovedovanje časovnih vrst in drugod. Njegova zmožnost razkrivanja skritih odnosov znotraj zaporedij zagotavlja zmogljivo orodje za odkrivanje vpogledov in doseganje vrhunske zmogljivosti pri številnih nalogah.
2. Večglavna pozornost: gledanje skozi različne leče
Samopozornost zagotavlja celovit pogled, včasih pa je osredotočanje na posebne vidike podatkov ključnega pomena. Tu nastopi večglava pozornost. Predstavljajte si, da imate več pomočnikov, od katerih je vsak opremljen z drugačno lečo:
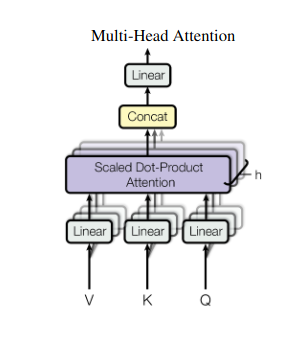
- Več "glav" so ustvarjeni, pri čemer vsak skrbi za vhodno zaporedje prek svojih matrik Q, K in V.
- Vsaka glava se nauči osredotočiti na različne vidike podatkov, kot so dolgoročne odvisnosti, sintaktični odnosi ali interakcije lokalnih besed.
- Izhodi iz vsake glave se nato združijo in projicirajo v končno predstavitev, ki zajame večplastno naravo vnosa.
To omogoča modelu, da hkrati upošteva različne perspektive, kar vodi do bogatejšega in bolj niansiranega razumevanja podatkov.
3. Navzkrižna pozornost: gradnja mostov med sekvencami
Sposobnost razumevanja povezav med različnimi informacijami je ključnega pomena za številne NLP naloge. Predstavljajte si, da napišete recenzijo knjige – besedila ne bi samo povzeli besedo za besedo, ampak raje črpali vpoglede in povezave med poglavji. Vnesite navzkrižna pozornost, zmogljiv mehanizem, ki gradi mostove med sekvencami in omogoča modelom, da izkoristijo informacije iz dveh različnih virov.
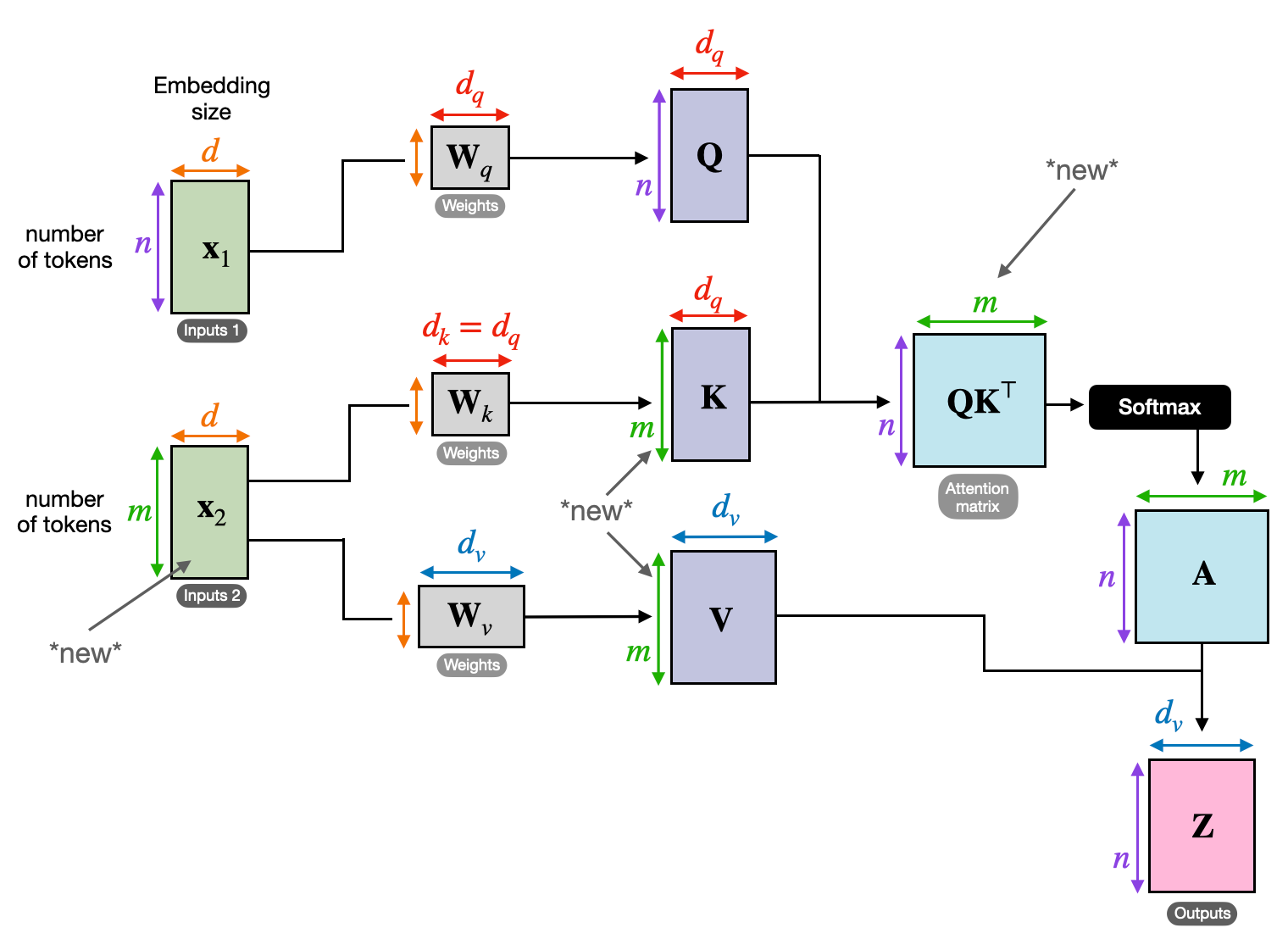
- V arhitekturah kodirnika-dekoderja, kot je Transformers, je dajalnika obdela vhodno zaporedje (knjigo) in ustvari skrito predstavitev.
- O dekoder uporablja navzkrižno pozornost, da se posveti skriti predstavitvi kodirnika pri vsakem koraku med ustvarjanjem izhodnega zaporedja (pregled).
- Matrika Q dekoderja sodeluje z matricama K in V kodirnika, kar mu omogoča, da se med pisanjem vsakega stavka recenzije osredotoči na ustrezne dele knjige.
Ta mehanizem je neprecenljiv za naloge, kot so strojno prevajanje, povzemanje in odgovarjanje na vprašanja, kjer je razumevanje odnosov med vhodnimi in izhodnimi zaporedji bistveno.
4. Vzročna pozornost: Ohranjanje toka časa
Predstavljajte si, da predvidevate naslednjo besedo v stavku, ne da bi kukali naprej. Tradicionalni mehanizmi pozornosti se spopadajo z nalogami, ki zahtevajo ohranjanje časovnega reda informacij, kot je ustvarjanje besedila in napovedovanje časovnih vrst. Z lahkoto »pokukajo naprej« v zaporedju, kar vodi do netočnih napovedi. Vzročna pozornost obravnava to omejitev tako, da zagotovi, da so napovedi odvisne izključno od predhodno obdelanih informacij.
Tukaj je, kako deluje
- Mehanizem maskiranja: Za uteži pozornosti se uporabi posebna maska, ki učinkovito blokira dostop modela do prihodnjih elementov v zaporedju. Na primer, ko napoveduje drugo besedo v "ženski, ki ...", lahko model upošteva samo "the" in ne "who" ali naslednjih besed.
- Avtoregresivna obdelava: Informacije tečejo linearno, pri čemer je predstavitev vsakega elementa zgrajena izključno iz elementov, ki se pojavljajo pred njim. Model obdeluje zaporedje besedo za besedo in ustvarja napovedi na podlagi konteksta, vzpostavljenega do te točke.
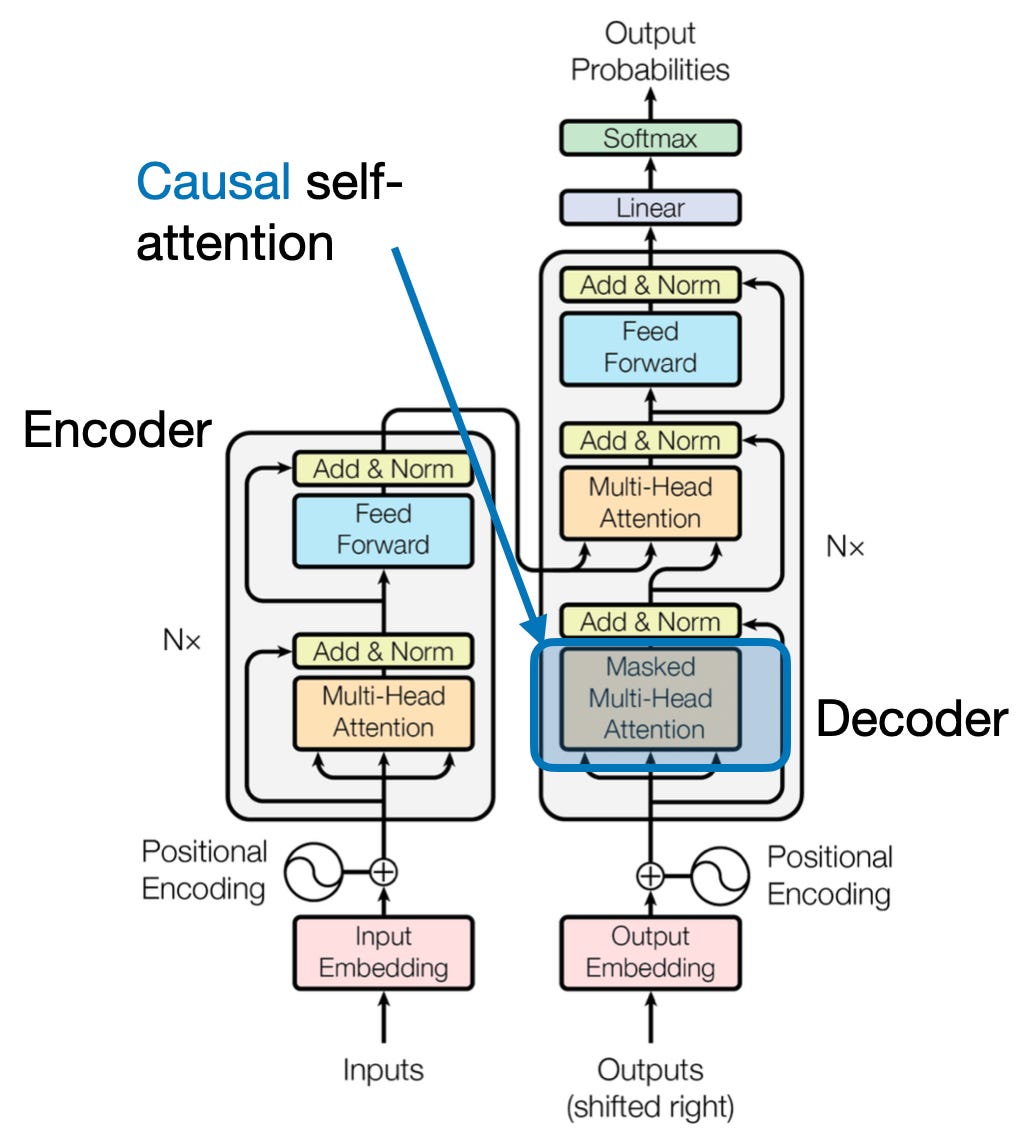
Vzročna pozornost je ključnega pomena za naloge, kot je ustvarjanje besedila in napovedovanje časovnih vrst, kjer je ohranjanje časovnega reda podatkov bistvenega pomena za natančne napovedi.
5. Globalna proti lokalni pozornosti: iskanje ravnotežja
Mehanizmi pozornosti se soočajo s ključnim kompromisom: zajemanje dolgoročnih odvisnosti v primerjavi z ohranjanjem učinkovitega računanja. To se kaže v dveh primarnih pristopih: svetovno pozornost in lokalna pozornost. Predstavljajte si, da preberete celotno knjigo, namesto da bi se osredotočili na določeno poglavje. Globalna pozornost obdela celotno zaporedje naenkrat, medtem ko se lokalna pozornost osredotoči na manjše okno:
- Globalna pozornost zajame dolgoročne odvisnosti in celoten kontekst, vendar je lahko računsko drago za dolga zaporedja.
- Lokalna pozornost je učinkovitejši, vendar bi lahko zamudil odnose na daljavo.
Izbira med globalno in lokalno pozornostjo je odvisna od več dejavnikov:
- Zahteve naloge: Naloge, kot je strojno prevajanje, zahtevajo zajemanje oddaljenih odnosov, kar daje prednost globalni pozornosti, medtem ko lahko analiza razpoloženja daje prednost lokalni pozornosti.
- Dolžina zaporedja: Zaradi daljših sekvenc je globalna pozornost računalniško draga, kar zahteva lokalne ali hibridne pristope.
- Zmogljivost modela: Omejitve virov lahko zahtevajo lokalno pozornost tudi za naloge, ki zahtevajo globalni kontekst.
Za doseganje optimalnega ravnovesja lahko modeli uporabljajo:
- Dinamično preklapljanje: uporabite globalno pozornost za ključne elemente in lokalno pozornost za druge, prilagajajte se glede na pomembnost in oddaljenost.
- Hibridni pristopi: združite oba mehanizma v isti plasti in izkoristite njune prednosti.
Preberite tudi: Analiza vrst nevronskih mrež pri poglobljenem učenju
zaključek
Navsezadnje je idealen pristop na spektru med globalno in lokalno pozornostjo. Razumevanje teh kompromisov in sprejemanje ustreznih strategij omogoča modelom učinkovito izkoriščanje ustreznih informacij na različnih lestvicah, kar vodi do bogatejšega in natančnejšega razumevanja zaporedja.
Reference
- Raschka, S. (2023). "Razumevanje in kodiranje pozornosti na samega sebe, pozornosti z več glavami, navzkrižne pozornosti in vzročne pozornosti pri LLM."
- Vaswani, A., et al. (2017). "Pozornost je vse, kar potrebujete."
- Radford, A., et al. (2019). "Jezikovni modeli so nenadzorovani večopravilni učenci."
Podobni
Sem ljubitelj podatkov in rad izluščim in razumem skrite vzorce v podatkih. Želim se učiti in rasti na področju strojnega učenja in podatkovne znanosti.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://www.analyticsvidhya.com/blog/2024/01/different-types-of-attention-mechanisms/
- :ima
- : je
- :ne
- :kje
- $GOR
- 1
- 2017
- 2019
- 2023
- 302
- 320
- 321
- 7
- a
- sposobnost
- dostop
- natančnost
- natančna
- Doseči
- doseganju
- čez
- aktov
- dejanska
- naslovi
- Sprejem
- naprej
- AL
- vsi
- Dovoli
- omogoča
- am
- Dvoumnost
- zneski
- an
- Analiza
- analize
- analiziranje
- in
- odgovor
- narazen
- očitno
- uporabna
- pristop
- pristopi
- SE
- območja
- članek
- AS
- vidiki
- Pomočnik
- pomočniki
- At
- pričakuje
- obiskujejo
- pozornosti
- zavest
- Ravnovesje
- temeljijo
- Osnova
- BE
- Širina
- postanejo
- pred
- med
- Poleg
- blokiranje
- Knjiga
- knjige
- tako
- MOST
- mostovi
- Bright
- širši
- prinesel
- Building
- Gradi
- zgrajena
- vendar
- by
- prišel
- CAN
- zajemanje
- ujame
- Zajemanje
- primeri
- spremenite
- Poglavje
- poglavij
- izbira
- bližje
- Kodiranje
- združujejo
- prihaja
- Podjetja
- združljivost
- kompleksna
- računanje
- računalniški
- Connect
- Povezovanje
- povezave
- Razmislite
- upoštevamo
- omejitve
- Vsebuje
- vsebina
- ozadje
- naprej
- Core
- korelacije
- ustvaril
- ustvari
- Ustvarjanje
- kritično
- ključnega pomena
- Trenutna
- datum
- znanost o podatkih
- Dešifriraj
- globoko
- globlje
- opredeljen
- poglablja
- odvisna
- odvisnost
- odvisnosti
- Odvisnost
- odvisno
- podrobno
- Dialog
- DID
- drugačen
- neposredno
- razdalja
- oddaljeni
- izrazit
- razne
- do
- dokument
- DOT
- podvojila
- desetine
- dramatično
- pripravi
- 2
- dinamika
- E&T
- vsak
- učinkovito
- učinkovitosti
- učinkovite
- učinkovito
- element
- elementi
- pooblastitvi
- omogoča
- omogočanje
- kodiranje
- obogatena
- zagotovitev
- zagotoviti
- Vnesite
- Celotna
- celota
- opremljena
- zlasti
- Bistvo
- bistvena
- v bistvu
- ustanovljena
- Tudi
- Tudi vsak
- razvijajo
- točno
- drago
- Izkoristite
- ekstrakt
- Obraz
- dejavniki
- daleč
- prednost
- Polje
- Področja
- končna
- Pretok
- Tokovi
- Osredotočite
- osredotočena
- Osredotoča
- osredotoča
- za
- ospredju
- Obrazci
- Fundacija
- štiri
- Okvirni
- iz
- funkcija
- funkcionalnosti
- Prihodnost
- igra
- ustvarja
- ustvarjajo
- generacija
- Globalno
- globalnem kontekstu
- prijem
- Grow
- Vodniki
- vodenje
- ročaj
- Imajo
- ob
- Glava
- pomoč
- skrita
- visoka
- več
- poudarjanje
- drži
- celosten
- Kako
- HTTPS
- človeškega
- Hybrid
- i
- idealen
- identificirati
- if
- slika
- Takojšen
- Pomembnost
- Pomembno
- in
- netočne
- vključujoč
- Navedite
- individualna
- neučinkovit
- Podatki
- inherentno
- vhod
- vpogledi
- primer
- Inteligentna
- namenjen
- interakcije
- interakcije
- interaktivni
- intervenirajo
- v
- neprecenljivo
- izolacija
- IT
- ITS
- jpg
- samo
- Ključne
- Ključna področja
- jezik
- Zadnja
- plast
- vodi
- UČITE
- Uči se in raste
- učencev
- učenje
- Led
- Lens
- leče
- Vzvod
- vzvod
- Knjižnica
- Leži
- light
- kot
- Omejitev
- omejitve
- lokalna
- Long
- več
- Poglej
- ljubezen
- stroj
- strojno učenje
- strojno prevajanje
- vzdrževanje
- Znamka
- Izdelava
- moški
- več
- Maska
- Matrix
- max širine
- kar pomeni,
- pomene
- izmerjena
- Mehanizem
- Mehanizmi
- Spomin
- morda
- pogrešam
- manjka
- Model
- modeli
- več
- učinkovitejše
- večplasten
- več
- naravna
- Naravni jezik
- Naravni jezik generacije
- Obdelava Natural Language
- Razumevanje naravnega jezika
- Narava
- Nimate
- potrebujejo
- potrebe
- sosedi
- omrežij
- Nevronski
- nevronske mreže
- Novo
- Naslednja
- noč
- nlp
- samostalniki
- zdaj
- niansirano
- of
- pogosto
- on
- enkrat
- samo
- optimalna
- or
- Da
- Ostalo
- drugi
- naši
- ven
- izhod
- izhodi
- Splošni
- pregled
- lastne
- Stran
- par
- Papir
- vzporedno
- deli
- odlomki
- preteklosti
- vzorci
- opravlja
- performance
- perspektive
- kosov
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Predvajaj
- Točka
- pozira
- poseduje
- možnosti
- močan
- potencial
- potencialno
- moč
- močan
- napovedovanje
- Napovedi
- ohranjanje
- preprečevanje
- prej
- v prvi vrsti
- primarni
- Postopek
- obdelani
- Procesi
- obravnavati
- Obdelava moči
- Izdelek
- napovedane
- poganja
- zagotavlja
- vprašanje
- območje
- obsegu
- precej
- Preberi
- zlahka
- reading
- v realnem času
- reference
- Ne glede na to
- Razmerja
- relativna
- ustreznost
- pomembno
- izjemno
- zastopanje
- predstavlja
- predstavlja
- zahteva
- reševanje
- vir
- viri
- tisti,
- Rezultati
- pregleda
- Revolucionarni
- revolucionirala
- Rich
- vloga
- s
- Enako
- Sarkazem
- Videl
- luske
- skeniranje
- Znanost
- rezultat
- rezultati
- Iskalnik
- drugi
- videnje
- stavek
- sentiment
- Zaporedje
- Serija
- služi
- več
- Delite s prijatelji, znanci, družino in partnerji :-)
- sijoč
- streljanje
- Kratke Hlače
- predstavitev
- hkrati
- počasi
- manj
- Izključno
- SOLVE
- Včasih
- Viri
- Vesolje
- specifična
- posebej
- Spectrum
- hitrosti
- Spotlight
- stoječa
- zvezda
- Korak
- trgovine
- strategije
- prednosti
- močnejši
- Struktura
- Boj
- Boriti se
- predmet
- kasneje
- taka
- primerna
- vsota
- Povzamemo
- POVZETEK
- superior
- Okolica
- sistemi
- reševanje
- ob
- tapiserijo
- Naloge
- tehnični
- Izraz
- besedilo
- tvorjenje besedila
- da
- O
- svet
- njihove
- Njih
- POTEM
- te
- jih
- ta
- 3
- skozi
- čas
- Časovne serije
- do
- orodje
- tradicionalna
- usposabljanje
- transformativno
- preoblikovati
- transformator
- transformatorji
- preoblikovanje
- prevod
- Res
- dva
- Vrste
- Konec koncev
- razumeli
- razumevanje
- nedvomno
- odklepanje
- razkrije
- predstavil
- uporaba
- uporablja
- uporabo
- različnih
- Popravljeno
- Proti
- Poglej
- obiskali
- ključnega pomena
- vs
- želeli
- želi
- je
- Dobro
- Kaj
- kdaj
- medtem
- WHO
- celoti
- široka
- Širok spekter
- bo
- okno
- z
- v
- brez
- ženska
- beseda
- besede
- delo
- svet
- pisanje
- včeraj
- jo
- zefirnet
- ZOO