Slika urednika
Ključni izdelki
- T-test je statistični test, s katerim lahko ugotovimo, ali obstaja pomembna razlika med sredinama dveh neodvisnih vzorcev podatkov.
- Ponazarjamo, kako je mogoče uporabiti t-test z uporabo nabora podatkov šarenice in Pythonove knjižnice Scipy.
T-test je statistični test, s katerim lahko ugotovimo, ali obstaja pomembna razlika med sredinama dveh neodvisnih vzorcev podatkov. V tej vadnici ponazarjamo najosnovnejšo različico t-testa, za katerega bomo predvidevali, da imata vzorca enake variance. Druge napredne različice t-testa vključujejo Welchov t-test, ki je prilagoditev t-testa in je bolj zanesljiv, če imata vzorca neenake variance in po možnosti neenake velikosti vzorcev.
T statistika ali t-vrednost se izračuna na naslednji način:
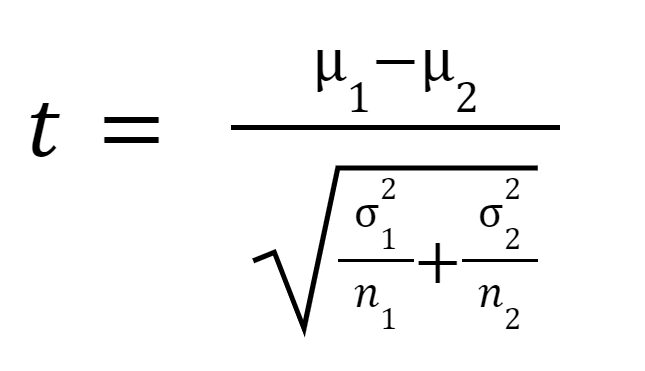
Kje
je povprečje vzorca 1,
je povprečje vzorca 2,
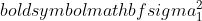 je varianca vzorca 1,
je varianca vzorca 1, 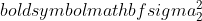 je varianca vzorca 2,
je varianca vzorca 2, 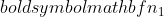 je velikost vzorca vzorca 1 in
je velikost vzorca vzorca 1 in 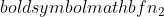 je velikost vzorca vzorca 2.
je velikost vzorca vzorca 2.
Za ponazoritev uporabe t-testa bomo prikazali preprost primer z uporabo nabora podatkov šarenice. Recimo, da opazujemo dva neodvisna vzorca, npr. dolžine cvetnih čašnih listov, in razmišljamo, ali sta bila vzorca vzeta iz iste populacije (npr. iste vrste cvetov ali dveh vrst s podobnimi lastnostmi čašnih listov) ali dveh različnih populacij.
T-test kvantificira razliko med aritmetičnimi sredinami obeh vzorcev. P-vrednost kvantificira verjetnost pridobitve opazovanih rezultatov ob predpostavki, da je ničelna hipoteza (da so vzorci vzeti iz populacij z enakimi povprečji populacije) resnična. P-vrednost, višja od izbranega praga (npr. 5 % ali 0.05), pomeni, da naše opazovanje ni tako malo verjetno, da bi se zgodilo po naključju. Zato sprejemamo ničelno hipotezo o enakih srednjih populacijah. Če je p-vrednost nižja od našega praga, potem imamo dokaze proti ničelni hipotezi o enakih srednjih populacijah.
Vnos T-testa
Vhodni podatki ali parametri, potrebni za izvedbo t-testa, so:
- Dva niza a in b ki vsebuje podatke za vzorec 1 in vzorec 2
Izhodi T-testa
T-test vrne naslednje:
- Izračunana t-statistika
- P-vrednost
Uvozite potrebne knjižnice
import numpy as np
from scipy import stats import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
Naloži nabor podatkov šarenice
from sklearn import datasets
iris = datasets.load_iris()
sep_length = iris.data[:,0]
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.4, random_state=1)
Izračunajte vzorčne srednje vrednosti in vzorčne variance
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Izvedite t-test
stats.ttest_ind(a_1, b_1, equal_var = False)
izhod
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(b_1, a_1, equal_var=False)
izhod
Ttest_indResult(statistic=-0.830066093774641, pvalue=0.4076270841218671)
stats.ttest_ind(a_1, b_1, equal_var=True)
izhod
Ttest_indResult(statistic=0.830066093774641, pvalue=0.4076132965045395)Opazovanja
Opažamo, da uporaba »true« ali »false« za parameter »equal-var« ne spremeni toliko rezultatov t-testa. Opazimo tudi, da zamenjava vrstnega reda vzorčnih nizov a_1 in b_1 daje negativno vrednost t-testa, vendar ne spremeni velikosti vrednosti t-testa, kot je bilo pričakovano. Ker je izračunana p-vrednost precej večja od mejne vrednosti 0.05, lahko zavrnemo ničelno hipotezo, da je razlika med sredinama vzorca 1 in vzorca 2 pomembna. To kaže, da sta bili dolžini čašnic za vzorec 1 in vzorec 2 vzeti iz istih populacijskih podatkov.
a_1, a_2 = train_test_split(sep_length, test_size=0.4, random_state=0)
b_1, b_2 = train_test_split(sep_length, test_size=0.5, random_state=1)
Izračunajte vzorčne srednje vrednosti in vzorčne variance
mu1 = np.mean(a_1) mu2 = np.mean(b_1) np.std(a_1) np.std(b_1)
Izvedite t-test
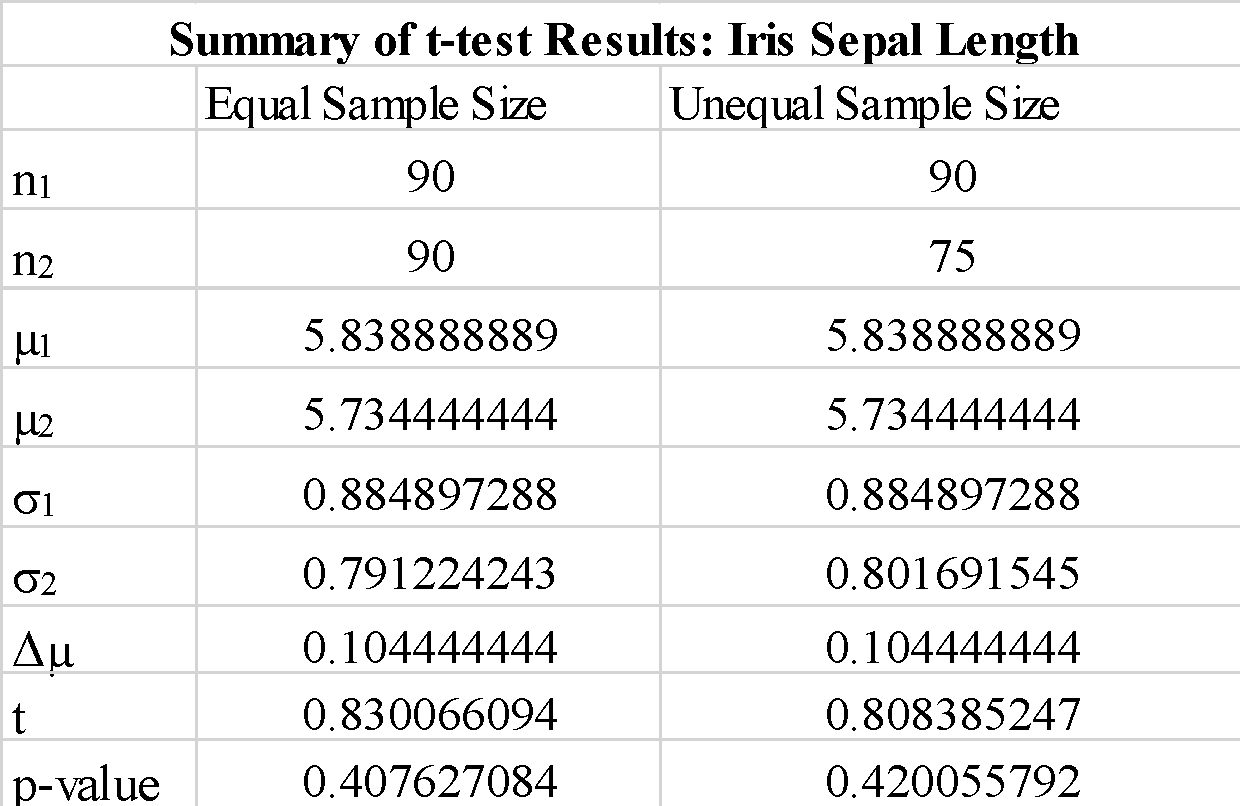
stats.ttest_ind(a_1, b_1, equal_var = False)
izhod
stats.ttest_ind(a_1, b_1, equal_var = False)Opazovanja
Opažamo, da uporaba vzorcev z neenako velikostjo ne spremeni bistveno t-statistike in p-vrednosti.
Če povzamemo, smo pokazali, kako bi lahko implementirali preprost t-test z uporabo knjižnice scipy v pythonu.
Benjamin O. Tayo je fizik, pedagog podatkovne znanosti in pisec ter lastnik DataScienceHuba. Prej je Benjamin poučeval tehniko in fiziko na Univerzi Central Oklahoma, Grand Canyon Univerzi in Pittsburgh State Univerzi.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- Platoblockchain. Web3 Metaverse Intelligence. Razširjeno znanje. Dostopite tukaj.
- vir: https://www.kdnuggets.com/2023/01/performing-ttest-python.html?utm_source=rss&utm_medium=rss&utm_campaign=performing-a-t-test-in-python
- 1
- 7
- 9
- a
- Sprejmi
- napredno
- proti
- in
- uporabna
- Osnovni
- Benjamin
- med
- izračuna
- Osrednji
- priložnost
- spremenite
- lastnosti
- izbran
- upoštevamo
- bi
- datum
- znanost o podatkih
- nabor podatkov
- Ugotovite,
- Razlika
- drugačen
- sestavljene
- Inženiring
- dokazi
- Primer
- Pričakuje
- cvet
- po
- sledi
- iz
- Kako
- HTTPS
- izvajali
- uvoz
- in
- vključujejo
- Neodvisni
- označuje
- KDnuggets
- večja
- Knjižnica
- matplotlib
- pomeni
- več
- Najbolj
- potrebno
- negativna
- otopeli
- opazujejo
- pridobitev
- zgodilo
- Oklahoma
- Da
- Ostalo
- Lastnik
- parameter
- parametri
- izvajati
- Fizika
- Pittsburgh
- platon
- Platonova podatkovna inteligenca
- PlatoData
- prebivalstvo
- prebivalstva
- prej
- verjetnost
- Python
- zanesljiv
- Rezultati
- vrne
- Enako
- Znanost
- Prikaži
- pokazale
- Razstave
- pomemben
- bistveno
- Podoben
- Enostavno
- saj
- Velikosti
- velikosti
- manj
- So
- Država
- Statistično
- statistika
- POVZETEK
- poučevanje
- Test
- O
- zato
- Prag
- do
- Res
- Navodila
- uporaba
- vrednost
- različica
- ali
- ki
- bo
- Pisatelj
- donosov
- zefirnet