OpenAI Whisper je napredni model samodejnega prepoznavanja govora (ASR) z licenco MIT. Tehnologija ASR najde uporabnost pri storitvah prepisovanja, glasovnih pomočnikih in izboljšanju dostopnosti za posameznike z okvaro sluha. Ta najsodobnejši model je usposobljen na obsežnem in raznolikem naboru večjezičnih in večopravilnih nadzorovanih podatkov, zbranih iz spleta. Zaradi visoke natančnosti in prilagodljivosti je dragocena prednost za širok nabor glasovnih nalog.
V nenehno razvijajočem se okolju strojnega učenja in umetne inteligence, Amazon SageMaker zagotavlja celovit ekosistem. SageMaker pooblašča podatkovne znanstvenike, razvijalce in organizacije za razvoj, usposabljanje, uvajanje in upravljanje modelov strojnega učenja v velikem obsegu. S široko paleto orodij in zmožnosti poenostavlja celoten potek dela strojnega učenja, od predhodne obdelave podatkov in razvoja modela do uvajanja in spremljanja brez truda. Zaradi uporabniku prijaznega vmesnika je SageMaker osrednja platforma za sprostitev celotnega potenciala umetne inteligence, ki ga uveljavlja kot rešitev, ki spreminja igre na področju umetne inteligence.
V tej objavi se lotimo raziskovanja zmogljivosti SageMakerja, pri čemer se posebej osredotočamo na gostovanje modelov Whisper. Poglobili se bomo v dve metodi za to: ena z uporabo modela Whisper PyTorch in druga z uporabo izvedbe Hugging Face modela Whisper. Poleg tega bomo izvedli poglobljeno preučitev možnosti sklepanja SageMaker in jih primerjali po parametrih, kot so hitrost, stroški, velikost tovora in razširljivost. Ta analiza omogoča uporabnikom, da sprejemajo informirane odločitve pri integraciji modelov Whisper v svoje specifične primere uporabe in sisteme.
Pregled rešitev
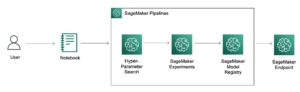
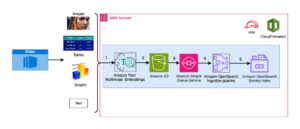
Naslednji diagram prikazuje glavne komponente te rešitve.
- Če želite model gostiti na Amazon SageMaker, je prvi korak shranjevanje artefaktov modela. Ti artefakti se nanašajo na bistvene komponente modela strojnega učenja, potrebnega za različne aplikacije, vključno z uvajanjem in ponovnim usposabljanjem. Vključujejo lahko parametre modela, konfiguracijske datoteke, komponente za predhodno obdelavo in metapodatke, kot so podrobnosti o različici, avtorstvo in morebitne opombe, povezane z njegovo zmogljivostjo. Pomembno je omeniti, da so modeli Whisper za izvedbe PyTorch in Hugging Face sestavljeni iz različnih artefaktov modela.
- Nato ustvarimo skripte sklepanja po meri. Znotraj teh skriptov definiramo, kako naj se model naloži, in določimo postopek sklepanja. Tu lahko po potrebi vključimo tudi parametre po meri. Poleg tega lahko zahtevane pakete Python navedete v a
requirements.txtmapa. Med uvajanjem modela se ti paketi Python samodejno namestijo v fazi inicializacije. - Nato izberemo vsebnike globokega učenja (DLC) PyTorch ali Hugging Face, ki jih zagotavlja in vzdržuje AWS. Ti vsebniki so vnaprej zgrajene slike Docker z ogrodji globokega učenja in drugimi potrebnimi paketi Python. Za več informacij lahko preverite to povezava.
- Z artefakti modela, skripti sklepanja po meri in izbranimi DLC-ji bomo ustvarili modele Amazon SageMaker za PyTorch oziroma Hugging Face.
- Končno je modele mogoče razmestiti v SageMaker in jih uporabiti z naslednjimi možnostmi: končne točke sklepanja v realnem času, opravila paketnega preoblikovanja in končne točke asinhronega sklepanja. Te možnosti se bomo podrobneje poglobili pozneje v tej objavi.
Primer zvezka in koda za to rešitev sta na voljo tukaj GitHub repozitorij.
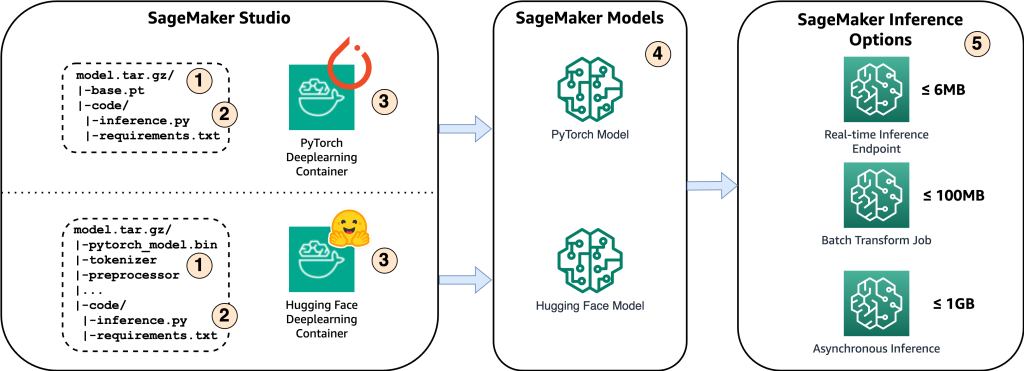
Slika 1. Pregled ključnih komponent rešitve
Walkthrough
Gostovanje modela Whisper na Amazon SageMaker
V tem razdelku bomo razložili korake za gostovanje modela Whisper na Amazon SageMaker z uporabo PyTorch oziroma Hugging Face Frameworks. Če želite preizkusiti to rešitev, potrebujete račun AWS in dostop do storitve Amazon SageMaker.
Ogrodje PyTorch
- Shranite artefakte modela
Prva možnost za gostovanje modela je uporaba Uradni paket Whisper Python, ki ga lahko namestite z uporabo pip install openai-whisper. Ta paket ponuja model PyTorch. Ko shranjujete artefakte modela v lokalnem repozitoriju, je prvi korak, da shranite učljive parametre modela, kot so uteži modela in pristranskosti vsake plasti v nevronski mreži, kot datoteko 'pt'. Izbirate lahko med različnimi velikostmi modelov, vključno z »majhnimi«, »osnovnimi«, »majhnimi«, »srednjimi« in »velikimi«. Večje velikosti modelov ponujajo višjo natančnost, vendar na račun daljše zakasnitve sklepanja. Poleg tega morate shraniti slovar stanja modela in slovar dimenzij, ki vsebujeta slovar Python, ki preslika vsako plast ali parameter modela PyTorch v njegove ustrezne učljive parametre, skupaj z drugimi metapodatki in konfiguracijami po meri. Spodnja koda prikazuje, kako shraniti artefakte Whisper PyTorch.
- Izberite DLC
Naslednji korak je, da iz tega izberete vnaprej zgrajeni DLC povezava. Pri izbiri pravilne slike bodite previdni in upoštevajte naslednje nastavitve: ogrodje (PyTorch), različica ogrodja, naloga (sklep), različica Python in strojna oprema (tj. GPU). Priporočljivo je, da uporabite najnovejše različice za okvir in Python, kadar koli je to mogoče, saj to povzroči boljšo zmogljivost in odpravi znane težave in napake iz prejšnjih izdaj.
- Ustvarite modele Amazon SageMaker
Nato uporabimo SDK SageMaker Python za ustvarjanje modelov PyTorch. Pomembno je, da ne pozabite dodati spremenljivk okolja, ko ustvarjate model PyTorch. Privzeto lahko TorchServe obdeluje samo velikosti datotek do 6 MB, ne glede na uporabljeno vrsto sklepanja.
Naslednja tabela prikazuje nastavitve za različne različice PyTorch:
| Okvirni | Spremenljivke okolja |
| PyTorch 1.8 (temelji na TorchServe) | "TS_MAX_REQUEST_SIZE': '100000000'" TS_MAX_RESPONSE_SIZE': '100000000'" TS_DEFAULT_RESPONSE_TIMEOUT': '1000' |
| PyTorch 1.4 (temelji na MMS) | "MMS_MAX_REQUEST_SIZE': '1000000000'" MMS_MAX_RESPONSE_SIZE': '1000000000'" MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- Definirajte metodo nalaganja modela v inference.py
V običaju inference.py skripta, najprej preverimo razpoložljivost GPE-ja, ki podpira CUDA. Če je tak GPE na voljo, potem dodelimo 'cuda' napravo na DEVICE spremenljivka; sicer dodelimo 'cpu' napravo. Ta korak zagotavlja, da je model nameščen na razpoložljivi strojni opremi za učinkovito računanje. Model PyTorch naložimo s paketom Whisper Python.
Okvir Hugging Face
- Shranite artefakte modela
Druga možnost je uporaba Hugging Face's Whisper izvajanje. Model lahko naložite s pomočjo AutoModelForSpeechSeq2Seq razred transformatorjev. Naučljivi parametri se shranijo v binarno datoteko (bin) z uporabo save_pretrained metoda. Ločeno je treba shraniti tudi tokenizer in predprocesor, da se zagotovi pravilno delovanje modela Hugging Face. Druga možnost je, da na Amazon SageMaker razmestite model neposredno iz središča Hugging Face Hub, tako da nastavite dve spremenljivki okolja: HF_MODEL_ID in HF_TASK. Za več informacij si oglejte to Spletna stran.
- Izberite DLC
Podobno kot pri ogrodju PyTorch lahko izberete vnaprej zgrajen DLC Hugging Face iz istega povezava. Prepričajte se, da ste izbrali DLC, ki podpira najnovejše transformatorje Hugging Face in vključuje podporo za GPU.
- Ustvarite modele Amazon SageMaker
Podobno uporabljamo SDK SageMaker Python za ustvarjanje modelov Hugging Face. Model Hugging Face Whisper ima privzeto omejitev, pri kateri lahko obdeluje samo zvočne segmente do 30 sekund. Če želite odpraviti to omejitev, lahko vključite chunk_length_s parameter v spremenljivki okolja, ko ustvarjate model Hugging Face, in pozneje posredujte ta parameter v skript sklepanja po meri, ko nalagate model. Nazadnje nastavite spremenljivke okolja, da povečate velikost tovora in časovno omejitev odziva za vsebnik Hugging Face.
| Okvirni | Spremenljivke okolja |
|
HuggingFace Inference Container (temelji na MMS) |
"MMS_MAX_REQUEST_SIZE': '2000000000'" MMS_MAX_RESPONSE_SIZE': '2000000000'" MMS_DEFAULT_RESPONSE_TIMEOUT': '900' |
- Definirajte metodo nalaganja modela v inference.py
Ko ustvarjamo skript sklepanja po meri za model Hugging Face, uporabljamo cevovod, ki nam omogoča, da prenesemo chunk_length_s kot parameter. Ta parameter omogoča modelu učinkovito obdelavo dolgih zvočnih datotek med sklepanjem.
Raziskovanje različnih možnosti sklepanja na Amazon SageMaker
Koraki za izbiro možnosti sklepanja so enaki za modela PyTorch in Hugging Face, zato spodaj ne bomo razlikovali med njima. Vendar je vredno omeniti, da je v času pisanja te objave sklepanje brez strežnika možnost iz SageMakerja ne podpira grafičnih procesorjev, zato to možnost izključujemo za ta primer uporabe.
Model lahko uvedemo kot končno točko v realnem času, ki zagotavlja odgovore v milisekundah. Vendar je pomembno upoštevati, da je ta možnost omejena na obdelavo vnosov pod 6 MB. Serializator definiramo kot zvočni serializator, ki je odgovoren za pretvorbo vhodnih podatkov v primerno obliko za nameščeni model. Za sklepanje uporabljamo instanco GPU, ki omogoča pospešeno obdelavo zvočnih datotek. Vnos sklepanja je zvočna datoteka iz lokalnega repozitorija.
Druga možnost sklepanja je opravilo paketnega preoblikovanja, ki lahko obdela vhodne obremenitve do 100 MB. Vendar lahko ta metoda traja nekaj minut zakasnitve. Vsaka instanca lahko obravnava samo eno paketno zahtevo naenkrat, zagon in zaustavitev instance pa prav tako zahtevata nekaj minut. Rezultati sklepanja so shranjeni v storitvi Amazon Simple Storage Service (Amazon S3) vedro po zaključku opravila paketnega preoblikovanja.
Pri konfiguraciji šaržnega transformatorja obvezno vključite max_payload = 100 za učinkovito obvladovanje večjih tovorov. Vnos sklepanja mora biti pot Amazon S3 do zvočne datoteke ali mape Amazon S3 Bucket, ki vsebuje seznam zvočnih datotek, od katerih je vsaka manjša od 100 MB.
Paketna transformacija razdeli predmete Amazon S3 v vhodu po ključu in preslika predmete Amazon S3 v primerke. Na primer, ko imate več zvočnih datotek, lahko ena instanca obdela input1.wav, druga instanca pa lahko obdela datoteko z imenom input2.wav za izboljšanje razširljivosti. Batch Transform vam omogoča konfiguracijo max_concurrent_transforms za povečanje števila zahtev HTTP za vsak posamezen vsebnik transformatorja. Vendar je pomembno upoštevati, da je vrednost (max_concurrent_transforms* max_payload) ne sme presegati 100 MB.
Nazadnje, Amazon SageMaker Asynchronous Inference je idealen za obdelavo več zahtev hkrati, ponuja zmerno zakasnitev in podpira vhodne obremenitve do 1 GB. Ta možnost zagotavlja odlično razširljivost, saj omogoča konfiguracijo skupine za samodejno skaliranje za končno točko. Ko pride do povečanja števila zahtev, se samodejno poveča za obravnavo prometa, in ko so vse zahteve obdelane, se končna točka zmanjša na 0, da prihrani stroške.
Z uporabo asinhronega sklepanja se rezultati samodejno shranijo v vedro Amazon S3. V AsyncInferenceConfig, lahko konfigurirate obvestila za uspešne ali neuspešne zaključke. Vhodna pot kaže na lokacijo zvočne datoteke Amazon S3. Za dodatne podrobnosti si oglejte kodo na GitHub.
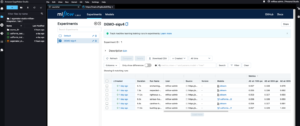
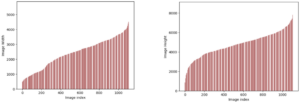
neobvezno: Kot smo že omenili, imamo možnost, da konfiguriramo skupino za samodejno skaliranje za končno točko asinhronega sklepanja, kar ji omogoča, da obvlada nenadno povečanje zahtev za sklepanje. Tukaj je naveden primer kode GitHub repozitorij. V naslednjem diagramu si lahko ogledate črtni grafikon, ki prikazuje dve meritvi iz amazoncloudwatch: ApproximateBacklogSize in ApproximateBacklogSizePerInstance. Na začetku, ko je bilo sproženih 1000 zahtev, je bil na voljo samo en primerek za obravnavo sklepanja. Tri minute je velikost zaostankov dosledno presegala tri (upoštevajte, da je te številke mogoče konfigurirati), skupina za samodejno skaliranje pa se je odzvala z vrtenjem dodatnih primerkov, da učinkovito odpravi zaostanke. To je povzročilo znatno zmanjšanje ApproximateBacklogSizePerInstance, kar omogoča veliko hitrejšo obdelavo zaostalih zahtev kot v začetni fazi.

Slika 2. Črtni grafikon, ki prikazuje časovne spremembe v meritvah Amazon CloudWatch
Primerjalna analiza za možnosti sklepanja
Primerjave za različne možnosti sklepanja temeljijo na običajnih primerih uporabe obdelave zvoka. Sklepanje v realnem času ponuja najhitrejšo hitrost sklepanja, vendar omejuje velikost tovora na 6 MB. Ta vrsta sklepanja je primerna za sisteme z zvočnimi ukazi, kjer uporabniki nadzorujejo ali komunicirajo z napravami ali programsko opremo z glasovnimi ukazi ali govorjenimi navodili. Glasovni ukazi so običajno majhni in nizka zakasnitev sklepanja je ključnega pomena za zagotovitev, da lahko prepisani ukazi takoj sprožijo naslednja dejanja. Paketno preoblikovanje je idealno za načrtovana opravila brez povezave, ko je velikost vsake zvočne datoteke manjša od 100 MB in ni posebnih zahtev za hitre odzivne čase sklepanja. Asinhrono sklepanje omogoča nalaganje do 1 GB in ponuja zmerno zakasnitev sklepanja. Ta vrsta sklepanja je zelo primerna za prepisovanje filmov, TV serij in posnetih konferenc, kjer je treba obdelati večje zvočne datoteke.
Možnosti sklepanja v realnem času in asinhronega sklepanja zagotavljajo zmožnosti samodejnega skaliranja, kar omogoča, da se instance končne točke samodejno povečajo ali zmanjšajo glede na količino zahtev. V primerih, ko ni zahtev, samodejno skaliranje odstrani nepotrebne instance, s čimer se lahko izognete stroškom, povezanim z omogočenimi instancami, ki niso aktivno v uporabi. Za sklepanje v realnem času pa je treba ohraniti vsaj en obstojen primerek, kar bi lahko povzročilo višje stroške, če končna točka deluje neprekinjeno. Nasprotno pa asinhroni sklep omogoča, da se glasnost primerka zmanjša na 0, ko ni v uporabi. Ko konfigurirate opravilo paketnega preoblikovanja, je mogoče uporabiti več primerkov za obdelavo opravila in prilagoditi max_concurrent_transforms, da omogočite enemu primerku obravnavanje več zahtev. Zato ponujajo vse tri možnosti sklepanja veliko razširljivost.
Čiščenje
Ko končate z uporabo rešitve, odstranite končne točke SageMaker, da preprečite dodatne stroške. Priloženo kodo lahko uporabite za brisanje končnih točk realnega časa oziroma asinhronega sklepanja.
zaključek
V tej objavi smo vam pokazali, kako je uvajanje modelov strojnega učenja za obdelavo zvoka postalo vse bolj pomembno v različnih panogah. Na primeru modela Whisper smo pokazali, kako gostiti odprtokodne modele ASR na Amazon SageMaker z uporabo pristopov PyTorch ali Hugging Face. Raziskovanje je zajelo različne možnosti sklepanja na Amazon SageMaker, ki ponuja vpogled v učinkovito ravnanje z zvočnimi podatki, napovedovanje in učinkovito upravljanje stroškov. Namen te objave je zagotoviti znanje raziskovalcem, razvijalcem in podatkovnim znanstvenikom, ki jih zanima izkoriščanje modela Whisper za naloge, povezane z zvokom, in sprejemanje premišljenih odločitev o strategijah sklepanja.
Za podrobnejše informacije o uvajanju modelov v SageMaker si oglejte to Vodnik za razvijalce. Poleg tega je model Whisper mogoče razmestiti s pomočjo SageMaker JumpStart. Za dodatne podrobnosti prosimo preverite Modeli Whisper za samodejno prepoznavanje govora so zdaj na voljo v Amazon SageMaker JumpStart post.
Vabimo vas, da si ogledate zvezek in kodo za ta projekt na GitHub in delite svoj komentar z nami.
O Author
 Ying Hou, dr, je arhitekt strojnega učenja prototipov pri AWS. Njena primarna področja zanimanja zajemajo globoko učenje s poudarkom na GenAI, računalniškem vidu, NLP-ju in napovedovanju podatkov časovnih vrst. V prostem času rada preživlja kakovostne trenutke s svojo družino, se potopi v romane in pohodi po nacionalnih parkih Združenega kraljestva.
Ying Hou, dr, je arhitekt strojnega učenja prototipov pri AWS. Njena primarna področja zanimanja zajemajo globoko učenje s poudarkom na GenAI, računalniškem vidu, NLP-ju in napovedovanju podatkov časovnih vrst. V prostem času rada preživlja kakovostne trenutke s svojo družino, se potopi v romane in pohodi po nacionalnih parkih Združenega kraljestva.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/machine-learning/host-the-whisper-model-on-amazon-sagemaker-exploring-inference-options/
- :ima
- : je
- :ne
- :kje
- $GOR
- 1
- 10
- 100
- 12
- 14
- 16
- 19
- 30
- 32
- 8
- a
- pospešeno
- dostop
- dostopnost
- Račun
- natančnost
- čez
- dejavnosti
- aktivno
- dodajte
- Dodatne
- Poleg tega
- Naslov
- prilagodite
- napredno
- AI
- Cilje
- vsi
- Dovoli
- omogoča
- skupaj
- Prav tako
- Amazon
- Amazon SageMaker
- Amazon Web Services
- an
- Analiza
- in
- Še ena
- kaj
- aplikacije
- pristopi
- SE
- območja
- Array
- umetni
- Umetna inteligenca
- AS
- sredstvo
- pomočniki
- povezan
- At
- audio
- Avtorstvo
- Samodejno
- samodejno
- razpoložljivost
- Na voljo
- izogniti
- AWS
- baza
- temeljijo
- BE
- postanejo
- spodaj
- Boljše
- med
- pristranskosti
- BIN
- tako
- hrošči
- vendar
- by
- CAN
- Zmogljivosti
- lahko
- previdni
- primeri
- Spremembe
- Graf
- preveriti
- Izberite
- izbiri
- razred
- jasno
- Koda
- kako
- komentar
- Skupno
- primerjavo
- primerjave
- Končana
- dokončanje
- deli
- celovito
- računanje
- računalnik
- Računalniška vizija
- Ravnanje
- konference
- konfiguracija
- konfigurirano
- konfiguriranje
- upoštevamo
- dosledno
- vsebujejo
- Posoda
- Zabojniki
- stalno
- kontrast
- nadzor
- pretvorbo
- popravi
- Ustrezno
- strošek
- stroški
- bi
- CPU
- ustvarjajo
- Ustvarjanje
- ključnega pomena
- po meri
- datum
- odločitve
- zmanjša
- globoko
- globoko učenje
- privzeto
- opredeliti
- Dokazano
- razporedi
- razporejeni
- uvajanja
- uvajanje
- Podatki
- podrobno
- Podrobnosti
- Razvoj
- Razvijalci
- Razvoj
- naprava
- naprave
- drugačen
- razlikovati
- Dimenzije
- neposredno
- prikazovanje
- potop
- razne
- Lučki delavec
- Ne
- tem
- navzdol
- med
- e
- vsak
- prej
- ekosistem
- učinkovito
- učinkovite
- učinkovito
- brez napora
- bodisi
- ostalo
- vkrcati
- pooblašča
- omogočajo
- omogoča
- omogočanje
- obsegajo
- Končna točka
- Končne točke
- okrepi
- izboljšanje
- zagotovitev
- zagotavlja
- Celotna
- okolje
- bistvena
- vzpostavitev
- Eter (ETH)
- Pregled
- Primer
- presega
- presežena
- odlično
- poskus
- Pojasnite
- raziskovanje
- Raziskovati
- Obraz
- ni uspelo
- false
- družina
- FAST
- hitreje
- Najhitreje
- Nekaj
- file
- datoteke
- najdbe
- prva
- Osredotočite
- osredotoča
- po
- za
- format
- Okvirni
- okviri
- brezplačno
- iz
- polno
- GPU
- Grafične kartice
- veliko
- skupina
- ročaj
- Ravnanje
- strojna oprema
- Imajo
- sluha
- pomoč
- jo
- visoka
- več
- pohodništvo
- gostitelj
- gostovanje
- Kako
- Kako
- Vendar
- HTML
- http
- HTTPS
- Hub
- HuggingFace
- i
- idealen
- if
- ponazarja
- slika
- slike
- Izvajanje
- izvedbe
- uvoz
- Pomembno
- in
- Poglobljena
- vključujejo
- vključuje
- Vključno
- vključi
- Povečajte
- vedno
- individualna
- posamezniki
- industrij
- Podatki
- obvestila
- začetna
- na začetku
- Začetek
- vhod
- vhodi
- vpogledi
- namestitev
- primer
- primerov
- Navodila
- Povezovanje
- Intelligence
- interakcijo
- obresti
- zainteresirani
- vmesnik
- v
- Vprašanja
- IT
- ITS
- Job
- Delovna mesta
- jpg
- Ključne
- znanje
- znano
- Pokrajina
- večja
- nazadnje
- Latenca
- pozneje
- Zadnji
- plast
- vodi
- učenje
- vsaj
- vzvod
- Licenca
- Omejitev
- Limited
- vrstica
- Seznam
- obremenitev
- nalaganje
- lokalna
- kraj aktivnosti
- Long
- več
- nizka
- stroj
- strojno učenje
- je
- Glavne
- Znamka
- IZDELA
- Izdelava
- upravljanje
- upravljanje
- Zemljevidi
- Maj ..
- omenjeno
- metapodatki
- Metoda
- Metode
- Meritve
- morda
- milisekund
- min
- MIT
- ML
- Model
- modeli
- zmerno
- Trenutki
- spremljanje
- več
- filmi
- veliko
- več
- morajo
- Imenovan
- nacionalni
- nacionalni parki
- potrebno
- Nimate
- potrebna
- mreža
- Nevronski
- nevronska mreža
- Naslednja
- nlp
- št
- Upoštevajte
- prenosnik
- Opombe
- Obvestilo
- Obvestila
- Opažam
- zdaj
- Številka
- številke
- predmet
- predmeti
- opazujejo
- of
- ponudba
- ponujanje
- Ponudbe
- Uradni
- offline
- on
- enkrat
- ONE
- samo
- open source
- deluje
- Možnost
- možnosti
- or
- Da
- organizacije
- OS
- Ostalo
- drugače
- ven
- pregled
- paket
- pakete
- parameter
- parametri
- parki
- mimo
- pot
- opravlja
- performance
- faza
- plinovod
- ključno
- postavi
- platforma
- platon
- Platonova podatkovna inteligenca
- PlatoData
- prosim
- točke
- mogoče
- Prispevek
- potencial
- napoved
- Napovedi
- preprečiti
- prejšnja
- primarni
- Postopek
- obdelani
- obravnavati
- Procesor
- Projekt
- pravilno
- prototipov
- zagotavljajo
- če
- zagotavlja
- zagotavljanje
- Python
- pitorha
- kakovost
- območje
- v realnem času
- kraljestvo
- Priznanje
- priporočeno
- Zabeležena
- Zmanjšana
- glejte
- Ne glede na to
- povezane
- Izpusti
- ne pozabite
- odstrani
- odstrani
- Skladišče
- zahteva
- zahteva
- zahteva
- obvezna
- zahteva
- raziskovalci
- oziroma
- Odgovor
- odgovorov
- odgovorna
- povzroči
- rezultat
- Rezultati
- ohraniti
- preusposabljanje
- vrnitev
- sagemaker
- Enako
- Shrani
- shranjena
- shranjevanje
- Prilagodljivost
- Lestvica
- luske
- načrtovano
- Znanstveniki
- script
- skripte
- drugi
- sekund
- Oddelek
- segmentih
- izberite
- izbran
- izbiranje
- Serija
- Storitev
- Storitve
- nastavite
- nastavitev
- nastavitve
- Delite s prijatelji, znanci, družino in partnerji :-)
- je
- shouldnt
- je pokazala,
- Razstave
- shutdown
- pomemben
- Enostavno
- poenostavlja
- Velikosti
- velikosti
- majhna
- manj
- So
- Software
- Rešitev
- specifična
- posebej
- določeno
- govor
- Prepoznavanje govora
- hitrost
- Poraba
- govorijo
- Začetek
- Država
- state-of-the-art
- Korak
- Koraki
- shranjevanje
- strategije
- kasneje
- uspešno
- taka
- nenadoma
- primerna
- podpora
- Podpora
- Podpira
- Preverite
- prenapetost
- sistemi
- miza
- Bodite
- ob
- Naloga
- Naloge
- Tehnologija
- kot
- da
- O
- UK
- njihove
- Njih
- POTEM
- Tukaj.
- zato
- te
- jih
- ta
- 3
- čas
- Časovne serije
- krat
- do
- orodja
- baklo
- Prometa
- Vlak
- usposobljeni
- Transform
- transformator
- transformatorji
- sprožijo
- sprožilo
- tv
- TV serije
- dva
- tip
- tipično
- Uk
- pod
- odklepanje
- naprej
- us
- uporaba
- Rabljeni
- Uporabniku prijazen
- Uporabniki
- uporabo
- pripomoček
- uporabiti
- Uporaben
- dragocene
- vrednost
- spremenljivka
- različnih
- Popravljeno
- različica
- Vizija
- Voice
- glasovne ukaze
- Obseg
- Počakaj
- želeli
- je
- we
- web
- spletne storitve
- Dobro
- so bili
- kdaj
- kadar koli
- ki
- Šepetanje
- široka
- Širok spekter
- z
- v
- potek dela
- deluje
- vredno
- pisanje
- jo
- Vaša rutina za
- zefirnet