Kako pogosto projekti strojnega učenja dosežejo uspešno uvedbo? Ne dovolj pogosto. obstaja veliko of Industrija Raziskave Prikaz da projekti ML običajno ne prinašajo donosov, vendar jih je redkokdo izmerilo razmerje med neuspehom in uspehom z vidika podatkovnih znanstvenikov – ljudi, ki razvijajo modele, ki naj bi jih ti projekti uvedli.
Spremljanjem raziskava podatkovnega znanstvenika ki sem ga lani izvajal s KDnuggets, letošnjo raziskavo Data Science Survey, vodilno v industriji Rexer Analytics, ki ga vodi svetovalno podjetje za ML, je obravnavalo to vprašanje – delno zato, ker je Karl Rexer, ustanovitelj in predsednik podjetja, dovolil, da vaše podjetje resnično sodeluje, kar je spodbudilo vključitev vprašanj o uspešnosti uvajanja (del mojega dela med enoletnim profesorjem analitike, ki sem ga imel na UVA Darden).
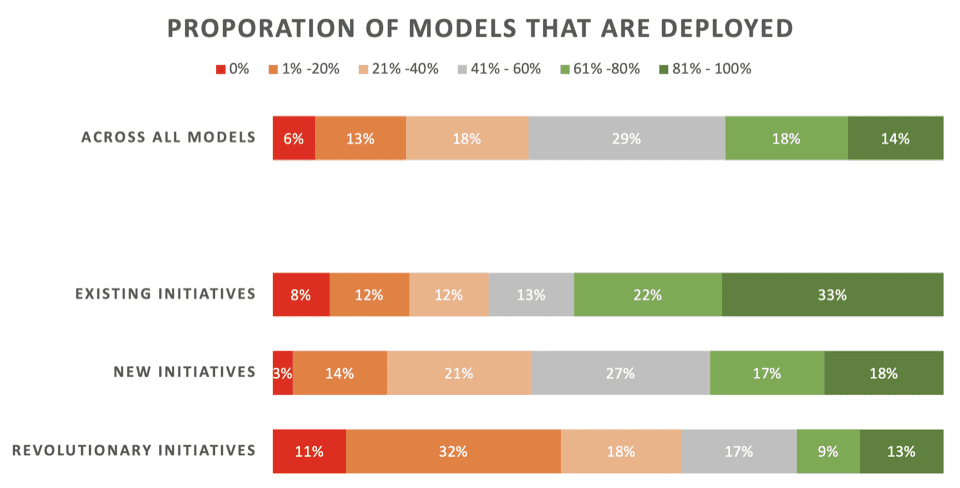
Novice niso dobre. Le 22 % podatkovnih znanstvenikov pravi, da se njihove "revolucionarne" pobude – modeli, razviti za omogočanje novega procesa ali zmogljivosti – običajno izvajajo. 43 % pravi, da se 80 % ali več ne uvede.
Prek vse vrste projektov ML – vključno z osvežitvijo modelov za obstoječe uvedbe – le 32 % pravi, da se njihovi modeli običajno uvedejo.
Tu so podrobni rezultati tega dela raziskave, kot jih je predstavil Rexer Analytics, ki razčlenjuje stopnje uvajanja na tri vrste pobud ML:
Legenda:
- Obstoječe pobude: Modeli, razviti za posodobitev/osvežitev obstoječega modela, ki je že bil uspešno uveden
- Nove pobude: Modeli, razviti za izboljšanje obstoječega procesa, za katerega še ni bil uporabljen noben model
- Revolucionarne pobude: Modeli, razviti za omogočanje novega procesa ali zmogljivosti
Po mojem mnenju ta boj za uvedbo izhaja iz dveh glavnih dejavnikov, ki prispevata: endemično premajhno načrtovanje in pomanjkanje konkretne prepoznavnosti poslovnih deležnikov. Številni strokovnjaki za obdelavo podatkov in vodilni v podjetjih niso spoznali, da je treba načrtovano operacionalizacijo ML načrtovati zelo podrobno in jo agresivno izvajati od začetka vsakega projekta ML.
Pravzaprav sem napisal novo knjigo prav o tem: The AI Playbook: Mastering the Rare Art of Machine Learning Deployment. V tej knjigi predstavljam prakso v šestih korakih, osredotočeno na uvajanje, za vodenje projektov strojnega učenja od zasnove do uvedbe, ki jih imenujem bizML (prednaročite trdo vezavo ali e-knjigo in prejmete brezplačno napredno kopijo različice zvočne knjige takoj).
Ključni deležnik projekta ML – oseba, ki je odgovorna za operativno učinkovitost, ki jo je treba izboljšati, kot je vodja poslovnega področja – potrebuje vpogled v to, kako natančno bo ML izboljšal njihovo delovanje in kakšno vrednost naj bi prinesla izboljšava. To potrebujejo, da na koncu dajo zeleno luč za uvedbo modela in pred tem pretehtajo izvedbo projekta v vseh fazah pred uvedbo.
Toda uspešnost ML se pogosto ne meri! Ko je anketa Rexer vprašala: "Kako pogosto vaše podjetje/organizacija meri uspešnost analitičnih projektov?" samo 48 % podatkovnih znanstvenikov je reklo "Vedno" ali "Večino časa." To je precej divje. Moralo bi biti približno 99 % ali 100 %.
In ko se meri uspešnost, je to v smislu tehničnih meritev, ki so skrivnostne in večinoma nepomembne za poslovne deležnike. Podatkovni znanstveniki vedo bolje, vendar se na splošno ne držijo – delno zato, ker orodja ML na splošno služijo samo tehničnim meritvam. V skladu z raziskavo podatkovni znanstveniki poslovne KPI-je, kot sta ROI in prihodek, razvrščajo med najpomembnejše meritve, vendar navajajo tehnične meritve, kot sta dvig in AUC, kot tiste, ki se najpogosteje merijo.
Meritve tehnične uspešnosti so "v bistvu neuporabne za poslovne deležnike in nepovezane z njimi", pravi Harvard Data Science Review. Evo zakaj: povedo vam samo relativna uspešnost modela, na primer, kako se primerja z ugibanjem ali drugo osnovno linijo. Poslovne meritve vam povedo absolutna poslovno vrednost, za katero se pričakuje, da bo model zagotavljal – ali, pri ocenjevanju po uvedbi, da se je izkazal. Takšne meritve so bistvene za projekte ML, osredotočene na uvajanje.
Poleg dostopa do poslovnih meritev se morajo povečati tudi poslovni deležniki. Ko je anketa Rexer vprašala: »Ali so menedžerji in odločevalci v vaši organizaciji, ki morajo odobriti uvedbo modela, dovolj dobro obveščeni, da sprejemajo takšne odločitve na dobro obveščen način?« samo 49 % vprašanih je odgovorilo "Večino časa" ali "Vedno."
Tukaj je tisto, kar verjamem, da se dogaja. »Stranka« podatkovnega znanstvenika, poslovni deležnik, se pogosto zmrazi, ko gre za odobritev uvedbe, saj bi to pomenilo pomembno operativno spremembo kruha in masla podjetja, njegovih največjih procesov. Nimajo kontekstualnega okvira. Na primer, sprašujejo se: "Kako naj razumem, koliko bo ta model, ki je daleč od popolnosti kristalne krogle, dejansko pomagal?" Tako projekt umre. Nato ustvarjalno dodajanje nekakšne pozitivne zasnove "pridobljenih spoznanj" služi za lepo pometanje neuspeha pod preprogo. Pomp umetne inteligence ostane nedotaknjen, čeprav se potencialna vrednost, namen projekta, izgubi.
Na to temo – krepitev zainteresiranih strani – bom dodal svojo novo knjigo, AI Playbook, samo še enkrat. Medtem ko obravnava prakso bizML, knjiga tudi izpopolnjuje poslovne strokovnjake z zagotavljanjem vitalnega, a prijaznega odmerka poltehničnega osnovnega znanja, ki ga potrebujejo vse zainteresirane strani, da lahko vodijo ali sodelujejo v projektih strojnega učenja od konca do konca. To postavlja poslovne in podatkovne strokovnjake na isto stran, tako da lahko poglobljeno sodelujejo in skupaj vzpostavljajo natančno kaj naj bi strojno učenje predvidevalo, kako dobro napoveduje in kako se njegove napovedi izvajajo za izboljšanje delovanja. Ti bistveni elementi naredijo ali uničijo vsako pobudo – njihova pravilna določitev utira pot za uvajanje strojnega učenja, ki temelji na vrednosti.
Varno lahko rečemo, da je zunaj težko, zlasti pri novih pobudah ML, ki se prvič preizkusijo. Ker sama sila navdušenja nad umetno inteligenco izgublja sposobnost nenehnega nadomestila
manj realizirane vrednosti od obljubljene, bo vedno več pritiska, da se dokaže operativna vrednost ML.? Zato pravim, pohitite s tem zdaj – začnite vcepljati učinkovitejšo kulturo sodelovanja med podjetji in vodenja projekta, usmerjenega v uvajanje!
Za podrobnejše rezultate iz 2023 Rexer Analytics Data Science Survey, Kliknite tukaj. To je največja raziskava strokovnjakov za podatkovno znanost in analitiko v industriji. Sestavljen je iz približno 35 izbirnih vprašanj in vprašanj odprtega tipa, ki pokrivajo veliko več kot le stopnje uspešnosti uvajanja – sedem splošnih področij znanosti in prakse podatkovnega rudarjenja: (1) Področje in cilji, (2) Algoritmi, (3) Modeli, ( 4) Orodja (uporabljeni programski paketi), (5) Tehnologija, (6) Izzivi in (7) Prihodnost. Izvaja se kot storitev (brez korporativnega sponzorstva) za skupnost znanosti o podatkih, rezultati pa so običajno objavljeni na konference Teden strojnega učenja in delite prek prosto dostopnih povzetkov poročil.
Ta članek je produkt avtorjevega dela, medtem ko je bil enoletni profesor analitike ob dvestoletnici telesa na poslovni šoli UVA Darden, kar je na koncu doseglo vrhunec z objavo The AI Playbook: Mastering the Rare Art of Machine Learning Deployment (brezplačna ponudba zvočnih knjig).
Eric Siegel, Ph.D., je vodilni svetovalec in nekdanji profesor na univerzi Columbia, ki naredi strojno učenje razumljivo in privlačno. Je ustanovitelj Svet napovedne analitike in Svet globokega učenja serije konferenc, ki so od leta 17,000 služile več kot 2009 udeležencem, inštruktor priznanega tečaja Vodenje in praksa strojnega učenja – obvladovanje od konca do konca, priljubljeni govornik, ki je bil naročen za 100+ osrednjih nagovorov, in izvršni urednik Časi strojnega učenja. Je avtor uspešnice Napovedna analitika: moč predvidevanja, kdo bo kliknil, kupil, lagal ali umrl, ki je bil uporabljen pri tečajih na več kot 35 univerzah in je prejel nagrade za poučevanje, ko je bil profesor na univerzi Columbia, kjer je pel poučne pesmi svojim študentom. Eric tudi objavlja op-eds o analitiki in socialni pravičnosti. Sledite mu na @predictanalytic.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://www.kdnuggets.com/survey-machine-learning-projects-still-routinely-fail-to-deploy?utm_source=rss&utm_medium=rss&utm_campaign=survey-machine-learning-projects-still-routinely-fail-to-deploy
- :ima
- : je
- :ne
- :kje
- $GOR
- 000
- 1
- 17
- 35%
- 7
- a
- sposobnost
- O meni
- dostop
- cenjen
- Po
- čez
- dejansko
- naslovljena
- napredno
- po
- agresivno
- naprej
- AI
- algoritmi
- vsi
- dovoljene
- že
- Prav tako
- vedno
- am
- an
- Analitični
- analitika
- in
- razglasitve
- Še ena
- odobri
- približno
- Skrivnosten
- SE
- območja
- Umetnost
- članek
- AS
- At
- udeležencev
- dražba
- avtor
- Na voljo
- Nagrade
- stran
- ozadje
- Izhodišče
- BE
- ker
- bilo
- pred
- Verjemite
- uspešnica
- Boljše
- Knjiga
- Kruh
- Break
- Breaking
- poslovni
- Poslovni voditelji
- vendar
- nakup
- by
- klic
- se imenuje
- CAN
- zmožnost
- navdušujoče
- izzivi
- spremenite
- naboj
- izbira
- klik
- stranke
- hladno
- sodelovati
- sodelovanje
- Columbia
- COM
- kako
- prihaja
- pogosto
- skupnost
- podjetje
- Podjetja
- Oblikovanje
- betonska
- poteka
- Konferenca
- vsebuje
- svetovanje
- svetovalec
- kontekstualno
- stalno
- prispeva
- Corporate
- Tečaj
- tečaji
- pokrov
- kritje
- Ustvarjalno
- cs
- Kultura
- datum
- rudarjenje podatkov
- znanost o podatkih
- podatkovni znanstvenik
- tisti, ki odločajo
- odločitve
- globoko
- poda
- dostavo
- razporedi
- razporejeni
- uvajanje
- razmestitve
- Podatki
- podrobno
- Razvoj
- razvili
- odklopljen
- do
- ne
- don
- dont
- Odmerek
- navzdol
- vožnjo
- med
- vsak
- urednik
- Učinkovito
- učinkovitost
- omogočajo
- konec
- konec koncev
- endemično
- okrepi
- dovolj
- eric
- zlasti
- bistvena
- Osnove
- vzpostavitev
- Eter (ETH)
- ocenjevanje
- Tudi
- Tudi vsak
- Primer
- izvedba
- izvršni
- obstoječih
- Pričakuje
- Dejstvo
- dejavniki
- FAIL
- Napaka
- daleč
- Feet
- Nekaj
- Polje
- sledi
- za
- moč
- Nekdanji
- Ustanovitelj
- Okvirni
- brezplačno
- prosto
- Prijazno
- iz
- Prihodnost
- pridobljeno
- splošno
- splošno
- dobili
- pridobivanje
- Cilji
- veliko
- Zgodi se
- Imajo
- he
- Hero
- pomoč
- ga
- njegov
- Kako
- HTML
- http
- HTTPS
- hype
- i
- IBM
- Pomembno
- izboljšanje
- Izboljšanje
- in
- začetek
- Vključno
- vključitev
- Industrija
- vodilne
- pobuda
- pobud
- vpogledi
- namenjen
- v
- uvesti
- isn
- IT
- ITS
- samo
- samo en
- karl
- KDnuggets
- Ključne
- Osrednji
- Otrok
- Vedite
- znanje
- primanjkuje
- Največji
- Zadnja
- Lansko leto
- vodi
- Voditelji
- Vodstvo
- vodi
- učenje
- laž
- kot
- Seznam
- ll
- Izgubi
- izgubil
- stroj
- strojno učenje
- Glavne
- Znamka
- IZDELA
- Izdelava
- upravitelj
- Vodje
- Način
- več
- Mastering
- pomeni
- pomenilo
- merjenje
- izmerjena
- Meritve
- Rudarstvo
- MIT
- ML
- Model
- modeli
- več
- Najbolj
- večinoma
- veliko
- več
- morajo
- my
- Nimate
- potrebe
- Novo
- novice
- št
- zdaj
- of
- pogosto
- on
- ONE
- tiste
- samo
- operativno
- operacije
- or
- Da
- Organizacija
- ven
- pakete
- Stran
- del
- sodelovanje
- tlakovci
- popolnost
- performance
- opravlja
- oseba
- perspektiva
- načrtovano
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Vtič
- Popular
- Stališče
- pozitiven
- potencial
- moč
- praksa
- prednaročilo
- Precious
- Ravno
- napovedati
- Napovedi
- Napovedi
- predstavljeni
- Predsednik
- tlak
- precej
- Postopek
- Procesi
- Izdelek
- strokovnjaki
- Učitelj
- Projekt
- projekti
- obljubil
- Dokaži
- dokazano
- Objava
- Objavlja
- Namen
- Postavlja
- Dajanje
- vprašanje
- vprašanja
- Ramp
- ramping
- uvrstitev
- REDKO
- Cene
- razmerje
- dosežejo
- realizirano
- priznajo
- ostanki
- Poročila
- anketirancev
- Rezultati
- vrne
- prihodki
- Revolucionarni
- Pravica
- rocky
- ROI
- rutinsko
- Run
- s
- varna
- Je dejal
- Enako
- pravijo,
- Lestvica
- <span style="color: #f7f7f7;">Šola</span>
- Znanost
- Znanstvenik
- Znanstveniki
- Serija
- služijo
- služil
- služi
- Storitev
- sedem
- deli
- pomemben
- saj
- So
- socialna
- Software
- nekaj
- Zvočniki
- Spin
- sponzorstvo
- postopka
- deležnik
- interesne skupine
- Začetek
- stebla
- Še vedno
- Boj
- Študenti
- uspeh
- uspešno
- Uspešno
- taka
- POVZETEK
- Anketa
- Sweep
- T
- ciljno
- poučevanje
- tehnični
- Tehnologija
- povej
- Pogoji
- kot
- da
- O
- njihove
- Njih
- POTEM
- Tukaj.
- te
- jih
- ta
- 3
- vsej
- Tako
- čas
- do
- orodja
- temo
- resnično
- dva
- Konec koncev
- pod
- razumeli
- razumljivo
- Univerze
- univerza
- naprej
- Rabljeni
- podučiti
- navadno
- vrednost
- Ve
- zelo
- preko
- Poglej
- vidljivost
- ključnega pomena
- je
- način..
- teden
- tehta
- Dobro
- Kaj
- kdaj
- ki
- medtem
- WHO
- zakaj
- Wild
- bo
- z
- brez
- Zmagali
- Sprašujem
- delo
- bi
- pisni
- leto
- še
- jo
- Vaša rutina za
- zefirnet








