Podatkovna jezera, ki jih poganja AWS, podprta z neprimerljivo razpoložljivostjo Preprosta storitev shranjevanja Amazon (Amazon S3), zmore obseg, agilnost in prilagodljivost, ki je potrebna za združevanje različnih podatkov in analitičnih pristopov. Ker so se podatkovna jezera povečala in uporaba dozorela, je mogoče vložiti veliko truda v ohranjanje skladnosti podatkov s poslovnimi dogodki. Da bi zagotovili posodabljanje datotek na transakcijsko dosleden način, vse več strank uporablja odprtokodne oblike transakcijskih tabel, kot je npr. Apaška ledena gora, Apače Hudiin Linux Foundation Delta Lake ki vam pomagajo pri shranjevanju podatkov z visokimi stopnjami stiskanja, izvornem vmesniku z vašimi aplikacijami in ogrodji ter poenostavijo inkrementalno obdelavo podatkov v podatkovnih jezerih, zgrajenih na Amazon S3. Ti formati omogočajo transakcije ACID (atomicity, consistency, isolation, durability), vstavitve in brisanja ter napredne funkcije, kot so potovanje skozi čas in posnetki, ki so bili prej na voljo samo v podatkovnih skladiščih. Vsak format shranjevanja izvaja to funkcijo na nekoliko drugačen način; za primerjavo glejte Izbira oblike odprte tabele za vaše transakcijsko podatkovno jezero na AWS.
V 2023, AWS je objavil splošno razpoložljivost za Apache Iceberg, Apache Hudi in Linux Foundation Delta Lake v Amazon Athena za Apache Spark, ki odpravlja potrebo po namestitvi ločenega konektorja ali povezanih odvisnosti in upravljanju različic ter poenostavlja konfiguracijske korake, potrebne za uporabo teh ogrodij.
V tej objavi vam pokažemo, kako uporabljati Spark SQL v Amazonska Atena zvezke in delo s formati tabel Iceberg, Hudi in Delta Lake. Demonstriramo običajne operacije, kot je ustvarjanje baz podatkov in tabel, vstavljanje podatkov v tabele, poizvedovanje po podatkih in pregledovanje posnetkov tabel v Amazonu S3 z uporabo Spark SQL v Atheni.
Predpogoji
Izpolnite naslednje predpogoje:
Prenesite in uvozite primere zvezkov iz Amazon S3
Če želite slediti, prenesite zvezke, obravnavane v tej objavi, z naslednjih lokacij:
Ko prenesete zvezke, jih uvozite v okolje Athena Spark tako, da sledite navodilom Za uvoz zvezka oddelek v Upravljanje datotek v zvezku.
Pomaknite se do določenega razdelka Open Table Format
Če vas zanima format tabele Iceberg, pojdite na Delo s tabelami Apache Iceberg oddelek.
Če vas zanima format tabele Hudi, pojdite na Delo s tabelami Apache Hudi oddelek.
Če vas zanima oblika tabele Delta Lake, pojdite na Delo s tabelami Delta Lake osnove Linuxa oddelek.
Delo s tabelami Apache Iceberg
Pri uporabi prenosnih računalnikov Spark v Atheni lahko izvajate poizvedbe SQL neposredno, ne da bi morali uporabljati PySpark. To naredimo z uporabo celičnih magij, ki so posebne glave v celici prenosnega računalnika, ki spremenijo vedenje celice. Za SQL lahko dodamo %%sql magic, ki bo interpretiral celotno vsebino celice kot stavek SQL, ki se izvaja na Atheni.
V tem razdelku pokažemo, kako lahko uporabite SQL v Apache Spark za Atheno za ustvarjanje, analizo in upravljanje tabel Apache Iceberg.
Nastavite sejo prenosnika
Če želite uporabljati Apache Iceberg v Atheni, med ustvarjanjem ali urejanjem seje izberite Apaška ledena gora možnost z razširitvijo Lastnosti Apache Spark razdelek. Vnaprej bo zapolnil lastnosti, kot je prikazano na naslednjem posnetku zaslona.
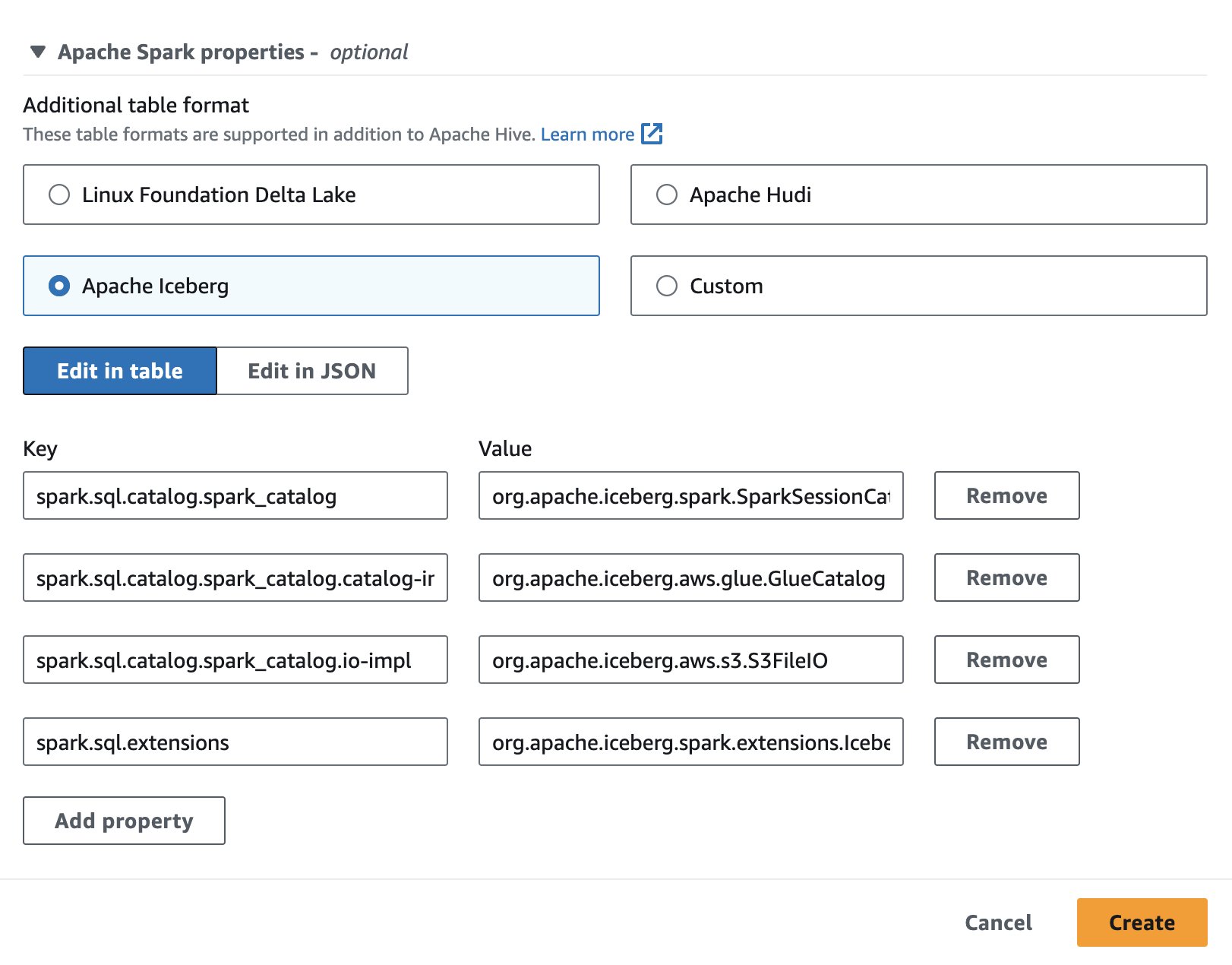
Za korake glejte Urejanje podrobnosti seje or Ustvarjanje lastnega zvezka.
Koda, uporabljena v tem razdelku, je na voljo v SparkSQL_iceberg.ipynb datoteko, ki ji sledite.
Ustvarite bazo podatkov in tabelo Iceberg
Najprej ustvarimo bazo podatkov v katalogu podatkov AWS Glue Data Catalog. Z naslednjim SQL lahko ustvarimo bazo podatkov, imenovano icebergdb:
Naprej v bazi podatkov icebergdb, ustvarimo tabelo Iceberg, imenovano noaa_iceberg ki kaže na lokacijo v Amazon S3, kamor bomo naložili podatke. Zaženite naslednji stavek in zamenjajte lokacijo s3://<your-S3-bucket>/<prefix>/ z vašim vedrom S3 in predpono:
V tabelo vnesite podatke
Za naselitev noaa_iceberg Tabela Iceberg, vnašamo podatke iz tabele Parket sparkblogdb.noaa_pq ki je bil ustvarjen kot del predpogojev. To lahko storite z uporabo VSTAVITE V IN izjava v Sparku:
Lahko pa uporabite tudi USTVARI TABELO KOT IZBIRO s klavzulo USING iceberg za ustvarjanje tabele Iceberg in vstavljanje podatkov iz izvorne tabele v enem koraku:
Poizvedi po tabeli Iceberg
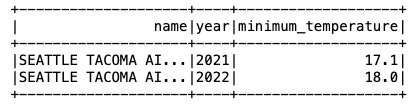
Zdaj, ko so podatki vstavljeni v tabelo Iceberg, jih lahko začnemo analizirati. Zaženimo Spark SQL, da poiščemo najnižjo zabeleženo temperaturo po letih za 'SEATTLE TACOMA AIRPORT, WA US' lokacija:
Dobimo naslednji izhod.
Posodobite podatke v tabeli Iceberg
Poglejmo, kako posodobiti podatke v naši tabeli. Želimo posodobiti ime postaje 'SEATTLE TACOMA AIRPORT, WA US' do 'Sea-Tac'. Z uporabo Spark SQL lahko zaženemo POSODOBI izjava proti mizi Iceberg:
Nato lahko zaženemo prejšnjo poizvedbo SELECT, da poiščemo najnižjo zabeleženo temperaturo za 'Sea-Tac' lokacija:
Dobili smo naslednji izhod.

Kompaktne podatkovne datoteke
Odprti formati tabel, kot je Iceberg, delujejo tako, da ustvarijo delta spremembe v shrambi datotek in sledijo različicam vrstic prek datotek manifesta. Več podatkovnih datotek povzroči več metapodatkov, shranjenih v manifestnih datotekah, majhne podatkovne datoteke pa pogosto povzročijo nepotrebno količino metapodatkov, kar povzroči manj učinkovite poizvedbe in višje stroške dostopa do Amazon S3. Tek Iceberg's rewrite_data_files postopek v Spark za Atheno bo strnil podatkovne datoteke in združil veliko majhnih datotek sprememb delta v manjši niz datotek Parquet, optimiziranih za branje. Stiskanje datotek pospeši operacijo branja ob poizvedbi. Če želite zagnati stiskanje na naši tabeli, zaženite naslednji Spark SQL:
rewrite_data_files ponuja možnosti da določite strategijo razvrščanja, ki lahko pomaga pri reorganizaciji in strnjenju podatkov.
Seznam posnetkov tabel
Vsaka operacija zapisovanja, posodabljanja, brisanja, postavitve in stiskanja v tabeli Iceberg ustvari nov posnetek tabele, medtem ko ohrani stare podatke in metapodatke za izolacijo posnetkov in potovanje skozi čas. Če želite prikazati posnetke tabele Iceberg, zaženite naslednji stavek SQL Spark:
Stari posnetki potečejo
Posnetke, ki redno potečejo, priporočamo za brisanje podatkovnih datotek, ki niso več potrebne, in za ohranjanje majhne velikosti metapodatkov tabele. Nikoli ne bo odstranil datotek, ki jih še vedno potrebuje posnetek, ki ni potekel. V Spark za Atheno zaženite naslednji SQL, da potečejo posnetki za tabelo icebergdb.noaa_iceberg ki so starejši od določenega časovnega žiga:
Upoštevajte, da je vrednost časovnega žiga podana kot niz v formatu yyyy-MM-dd HH:mm:ss.fff. Izhod bo dal število izbrisanih podatkovnih in metapodatkovnih datotek.
Spustite tabelo in bazo podatkov
S to vajo lahko zaženete naslednji Spark SQL, da počistite tabele Iceberg in povezane podatke v Amazonu S3:
Zaženite naslednji Spark SQL, da odstranite bazo podatkov icebergdb:
Če želite izvedeti več o vseh operacijah, ki jih lahko izvajate na mizah Iceberg z uporabo Spark for Athena, glejte Poizvedbe Spark in Postopki Spark v dokumentaciji Iceberg.
Delo s tabelami Apache Hudi
Nato pokažemo, kako lahko uporabite SQL na Spark for Athena za ustvarjanje, analizo in upravljanje tabel Apache Hudi.
Nastavite sejo prenosnika
Če želite uporabljati Apache Hudi v Atheni, med ustvarjanjem ali urejanjem seje izberite Apače Hudi možnost z razširitvijo Lastnosti Apache Spark oddelek.
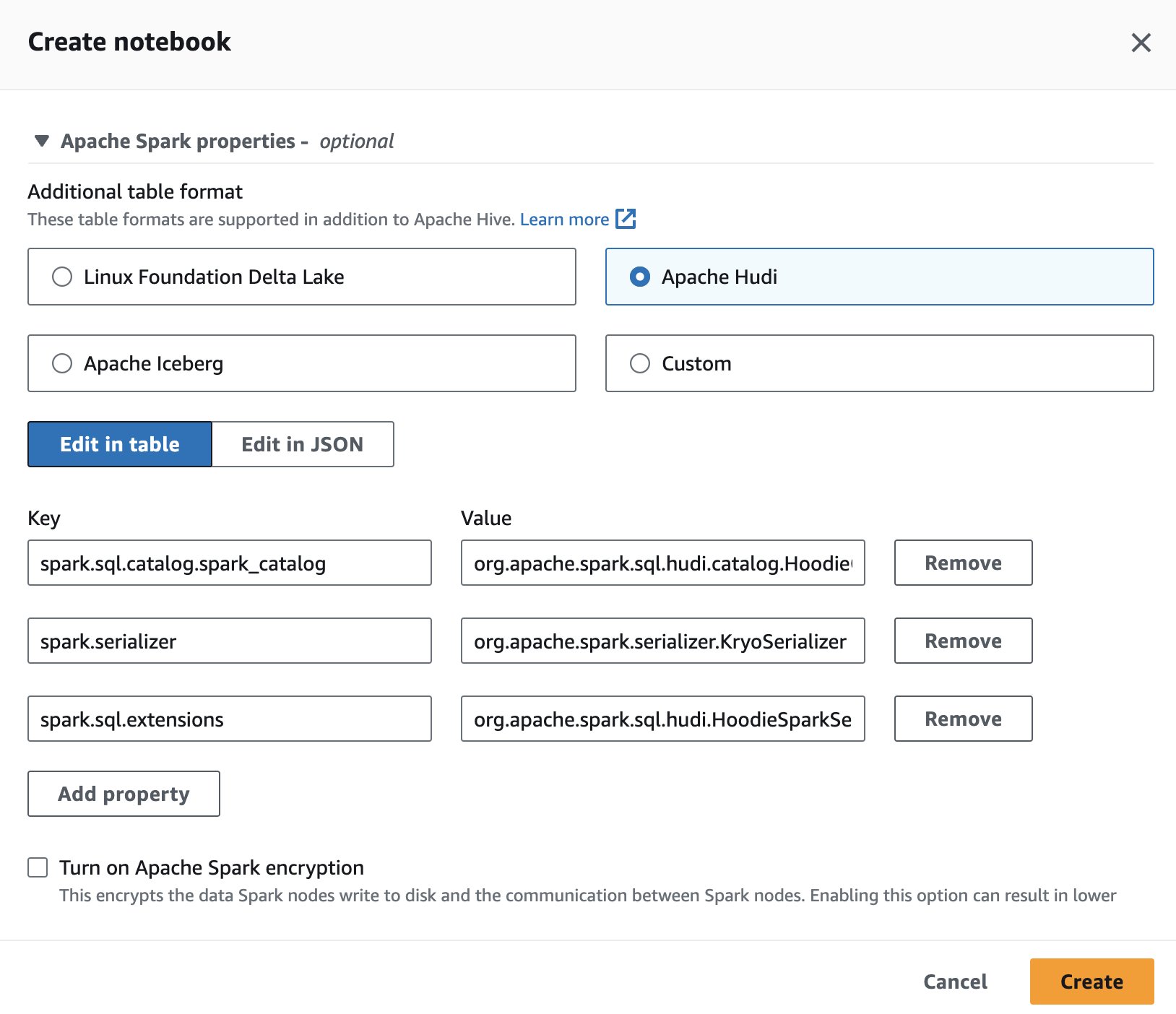
Za korake glejte Urejanje podrobnosti seje or Ustvarjanje lastnega zvezka.
Koda, uporabljena v tem razdelku, mora biti na voljo v SparkSQL_hudi.ipynb datoteko, ki ji sledite.
Ustvarite bazo podatkov in tabelo Hudi
Najprej ustvarimo bazo podatkov, imenovano hudidb ki bodo shranjeni v podatkovnem katalogu AWS Glue, čemur bo sledilo ustvarjanje tabele Hudi:
Ustvarimo tabelo Hudi, ki kaže na lokacijo v Amazon S3, kamor bomo naložili podatke. Upoštevajte, da je tabela od kopiraj-piši vrsta. Opredeljuje ga type= 'cow' v tabeli DDL. Definirali smo postajo in datum kot več primarnih ključev, preCombinedField pa kot leto. Poleg tega je tabela razdeljena na leto. Zaženite naslednji stavek in zamenjajte lokacijo s3://<your-S3-bucket>/<prefix>/ z vašim vedrom S3 in predpono:
V tabelo vnesite podatke
Tako kot pri Icebergu uporabljamo VSTAVITE V IN stavek za zapolnitev tabele z branjem podatkov iz sparkblogdb.noaa_pq tabela, ustvarjena v prejšnji objavi:
Poizvedite tabelo Hudi
Zdaj, ko je tabela ustvarjena, zaženimo poizvedbo, da poiščemo najvišjo zabeleženo temperaturo za 'SEATTLE TACOMA AIRPORT, WA US' lokacija:
Posodobite podatke v tabeli Hudi
Spremenimo ime postaje 'SEATTLE TACOMA AIRPORT, WA US' do 'Sea–Tac'. Zaženemo lahko stavek UPDATE na Spark za Atheno posodobitev zapisi o noaa_hudi miza:
Izvedemo prejšnjo poizvedbo SELECT, da poiščemo najvišjo zabeleženo temperaturo za 'Sea-Tac' lokacija:
Izvedite poizvedbe o potovanju skozi čas
Za analizo preteklih podatkovnih posnetkov lahko uporabimo poizvedbe o potovanju skozi čas v SQL na Atheni. Na primer:
Ta poizvedba preveri podatke o temperaturi na letališču Seattle za določen čas v preteklosti. Klavzula o časovnem žigu nam omogoča potovanje nazaj brez spreminjanja trenutnih podatkov. Upoštevajte, da je vrednost časovnega žiga podana kot niz v formatu yyyy-MM-dd HH:mm:ss.fff.
Optimizirajte hitrost poizvedb z združevanjem v gruče
Če želite izboljšati učinkovitost poizvedbe, lahko izvedete grozdenje na tabelah Hudi z uporabo SQL v Spark za Atheno:
Kompaktne mize
Kompakcija je storitev tabel, ki jo uporablja Hudi posebej v tabelah Merge On Read (MOR) za občasno združevanje posodobitev iz dnevniških datotek, ki temeljijo na vrsticah, v ustrezno osnovno datoteko, ki temelji na stolpcih, da se ustvari nova različica osnovne datoteke. Zgoščevanje ni uporabno za tabele Copy On Write (COW) in velja samo za tabele MOR. V programu Spark for Athena lahko zaženete naslednjo poizvedbo, da izvedete stiskanje tabel MOR:
Spustite tabelo in bazo podatkov
Zaženite naslednji Spark SQL, da odstranite tabelo Hudi, ki ste jo ustvarili, in povezane podatke z lokacije Amazon S3:
Zaženite naslednji Spark SQL, da odstranite bazo podatkov hudidb:
Če želite izvedeti več o vseh operacijah, ki jih lahko izvajate na Hudi tabelah z uporabo Spark for Athena, glejte SQL DDL in Postopki v dokumentaciji Hudi.
Delo s tabelami Delta Lake osnove Linuxa
Nato pokažemo, kako lahko uporabite SQL na Spark for Athena za ustvarjanje, analiziranje in upravljanje tabel Delta Lake.
Nastavite sejo prenosnika
Če želite med ustvarjanjem ali urejanjem seje uporabiti Delta Lake v Spark for Athena, izberite Linux Foundation Delta Lake s širitvijo Lastnosti Apache Spark oddelek.
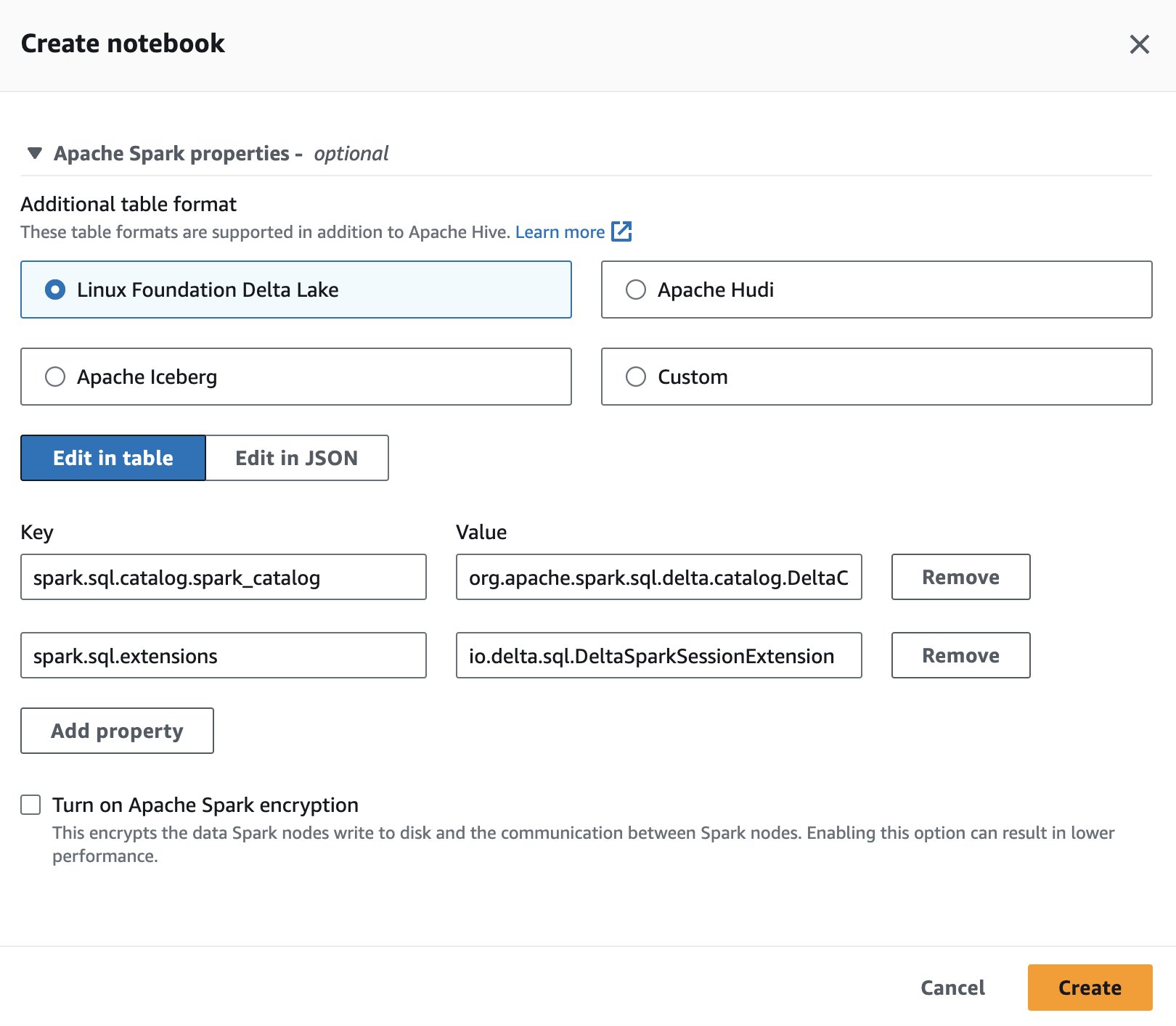
Za korake glejte Urejanje podrobnosti seje or Ustvarjanje lastnega zvezka.
Koda, uporabljena v tem razdelku, mora biti na voljo v SparkSQL_delta.ipynb datoteko, ki ji sledite.
Ustvarite bazo podatkov in tabelo Delta Lake
V tem razdelku ustvarimo bazo podatkov v katalogu podatkov AWS Glue Data Catalog. Z naslednjim SQL lahko ustvarimo bazo podatkov, imenovano deltalakedb:
Naprej v bazi podatkov deltalakedb, ustvarimo tabelo Delta Lake, imenovano noaa_delta ki kaže na lokacijo v Amazon S3, kamor bomo naložili podatke. Zaženite naslednji stavek in zamenjajte lokacijo s3://<your-S3-bucket>/<prefix>/ z vašim vedrom S3 in predpono:
V tabelo vnesite podatke
Uporabljamo VSTAVITE V IN stavek za zapolnitev tabele z branjem podatkov iz sparkblogdb.noaa_pq tabela, ustvarjena v prejšnji objavi:
Uporabite lahko tudi CREATE TABLE AS SELECT, da ustvarite tabelo Delta Lake in vstavite podatke iz izvorne tabele v eno poizvedbo.
Poizvedi po tabeli Delta Lake
Zdaj, ko so podatki vstavljeni v tabelo Delta Lake, jih lahko začnemo analizirati. Zaženimo Spark SQL, da poiščemo najmanjšo zabeleženo temperaturo za 'SEATTLE TACOMA AIRPORT, WA US' lokacija:
Posodobite podatke v tabeli Delta Lake
Spremenimo ime postaje 'SEATTLE TACOMA AIRPORT, WA US' do 'Sea–Tac'. Lahko vodimo POSODOBI izjava o Sparku za Atheno za posodobitev evidence noaa_delta miza:
Zaženemo lahko prejšnjo poizvedbo SELECT, da poiščemo najnižjo zabeleženo temperaturo za 'Sea-Tac' lokacijo in rezultat bi moral biti enak kot prej:
Kompaktne podatkovne datoteke
V Sparku za Atheno lahko zaženete OPTIMIZE na tabeli Delta Lake, ki bo strnila majhne datoteke v večje datoteke, tako da poizvedbe niso obremenjene s stroški majhnih datotek. Če želite izvesti operacijo stiskanja, zaženite naslednjo poizvedbo:
Nanašati se na Optimizacije v dokumentaciji Delta Lake za različne možnosti, ki so na voljo med izvajanjem OPTIMIZE.
Odstranite datoteke, na katere se tabela Delta Lake ne sklicuje več
Datoteke, shranjene v Amazon S3, na katere se tabela Delta Lake ne sklicuje več in so starejše od praga hrambe, lahko odstranite tako, da v tabeli zaženete ukaz VACCUM s Spark for Athena:
Nanašati se na Odstranite datoteke, na katere se tabela Delta ne sklicuje več v dokumentaciji Delta Lake za možnosti, ki so na voljo z VACUUM.
Spustite tabelo in bazo podatkov
Zaženite ta Spark SQL, da odstranite tabelo Delta Lake, ki ste jo ustvarili:
Zaženite naslednji Spark SQL, da odstranite bazo podatkov deltalakedb:
Zagon DROP TABLE DDL v tabeli in zbirki podatkov Delta Lake izbriše metapodatke za te objekte, vendar ne izbriše samodejno podatkovnih datotek v Amazon S3. V celici zvezka lahko zaženete naslednjo kodo Python, da izbrišete podatke z lokacije S3:
Če želite izvedeti več o stavkih SQL, ki jih lahko zaženete v tabeli Delta Lake z uporabo Spark for Athena, glejte hiter začetek v dokumentaciji Delta Lake.
zaključek
Ta objava je pokazala, kako uporabljati Spark SQL v prenosnikih Athena za ustvarjanje baz podatkov in tabel, vstavljanje podatkov in poizvedovanje po njih ter izvajanje pogostih operacij, kot so posodobitve, zgoščevanje in časovno potovanje v tabelah Hudi, Delta Lake in Iceberg. Formati odprtih tabel dodajajo transakcije ACID, vstavitve in brisanja v podatkovna jezera, s čimer presežejo omejitve shranjevanja neobdelanih predmetov. Z odstranitvijo potrebe po namestitvi ločenih konektorjev vgrajena integracija Spark on Athena zmanjša konfiguracijske korake in stroške upravljanja pri uporabi teh priljubljenih okvirov za gradnjo zanesljivih podatkovnih jezer na Amazon S3. Če želite izvedeti več o izbiri oblike odprte tabele za vaše delovne obremenitve podatkovnega jezera, glejte Izbira oblike odprte tabele za vaše transakcijsko podatkovno jezero na AWS.
O avtorjih
![]() Pathik Shah je starejši arhitekt za analitiko na Amazon Athena. AWS se je pridružil leta 2015 in se od takrat osredotoča na prostor analitike velikih podatkov ter strankam pomaga zgraditi razširljive in robustne rešitve z uporabo analitičnih storitev AWS.
Pathik Shah je starejši arhitekt za analitiko na Amazon Athena. AWS se je pridružil leta 2015 in se od takrat osredotoča na prostor analitike velikih podatkov ter strankam pomaga zgraditi razširljive in robustne rešitve z uporabo analitičnih storitev AWS.
![]() Raj Devnath je produktni vodja pri AWS na Amazon Athena. Navdušen je nad ustvarjanjem izdelkov, ki so všeč strankam, in pomaga strankam pridobiti vrednost iz njihovih podatkov. Njegovo ozadje je pri zagotavljanju rešitev za več končnih trgov, kot so finance, trgovina na drobno, pametne zgradbe, avtomatizacija doma in podatkovni komunikacijski sistemi.
Raj Devnath je produktni vodja pri AWS na Amazon Athena. Navdušen je nad ustvarjanjem izdelkov, ki so všeč strankam, in pomaga strankam pridobiti vrednost iz njihovih podatkov. Njegovo ozadje je pri zagotavljanju rešitev za več končnih trgov, kot so finance, trgovina na drobno, pametne zgradbe, avtomatizacija doma in podatkovni komunikacijski sistemi.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoData.Network Vertical Generative Ai. Opolnomočite se. Dostopite tukaj.
- PlatoAiStream. Web3 Intelligence. Razširjeno znanje. Dostopite tukaj.
- PlatoESG. Ogljik, CleanTech, Energija, Okolje, sončna energija, Ravnanje z odpadki. Dostopite tukaj.
- PlatoHealth. Obveščanje o biotehnologiji in kliničnih preskušanjih. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/use-amazon-athena-with-spark-sql-for-your-open-source-transactional-table-formats/
- :ima
- : je
- :ne
- :kje
- $GOR
- 000
- 1
- 10
- 100
- 107
- 11
- 12
- 13
- 16
- 2015
- 2023
- 23
- 300
- 41
- 43
- 53
- 58
- 7
- 8
- 9
- a
- O meni
- dostop
- dodajte
- napredno
- proti
- letališče
- vsi
- skupaj
- Prav tako
- Amazon
- Amazonska Atena
- Amazon Web Services
- znesek
- an
- analitika
- analizirati
- analiziranje
- in
- razglasitve
- Apache
- Apache Spark
- primerno
- aplikacije
- velja
- pristopi
- SE
- okoli
- AS
- povezan
- At
- samodejno
- Avtomatizacija
- razpoložljivost
- Na voljo
- AWS
- AWS lepilo
- nazaj
- ozadje
- baza
- BE
- bilo
- vedenje
- Big
- Big Podatki
- izgradnjo
- Building
- zgrajena
- vgrajeno
- poslovni
- vendar
- by
- klic
- se imenuje
- CAN
- Katalog
- Vzrok
- celica
- spremenite
- Spremembe
- Pregledi
- čiščenje
- Koda
- združujejo
- združevanje
- Skupno
- Komunikacija
- komunikacijski sistemi
- kompaktna
- Primerjava
- konfiguracija
- dosledno
- Vsebina
- Ustrezno
- stroški
- štetje
- ustvarjajo
- ustvaril
- ustvari
- Ustvarjanje
- Oblikovanje
- Trenutna
- Stranke, ki so
- datum
- Podatkovna analiza
- Data jezero
- obdelava podatkov
- skladišča podatkov
- Baze podatkov
- baze podatkov
- Datum
- opredeljen
- dostavo
- Delta
- izkazati
- Dokazano
- odvisnosti
- drugačen
- neposredno
- razpravljali
- do
- Dokumentacija
- Ne
- prenesi
- Drop
- trajnost
- vsak
- prej
- urejanje
- učinkovite
- prizadevanje
- zaposleni
- omogočajo
- konec
- zagotovitev
- Celotna
- okolje
- Eter (ETH)
- dogodki
- Primer
- Vaja
- širi
- ekstrakt
- Lastnosti
- file
- datoteke
- financiranje
- Najdi
- prva
- prilagodljivost
- osredotoča
- sledi
- sledili
- po
- za
- format
- Fundacija
- okviri
- iz
- funkcionalnost
- splošno
- dobili
- Daj
- skupina
- Pridelovanje
- goji
- ročaj
- Imajo
- ob
- he
- Glave
- pomoč
- pomoč
- hh
- visoka
- več
- njegov
- Domov
- Avtomatizacija doma
- Kako
- Kako
- HTML
- http
- HTTPS
- slika
- izvedbe
- uvoz
- izboljšanje
- in
- inkrementalno
- namestitev
- integracija
- zainteresirani
- vmesnik
- v
- izolacija
- IT
- pridružil
- jpg
- Imejte
- vzdrževanje
- tipke
- Jezero
- jezera
- večja
- zemljepisna širina
- Interesenti
- UČITE
- manj
- Lets
- kot
- omejitve
- linux
- temelj za linux
- Seznam
- obremenitev
- kraj aktivnosti
- Lokacije
- prijavi
- več
- Poglej
- si
- ljubezen
- magic
- upravljanje
- upravljanje
- upravitelj
- Način
- več
- Prisotnost
- max
- največja
- Spoji
- metapodatki
- minut
- minimalna
- več
- več
- Ime
- izvirno
- Krmarjenje
- Nimate
- potrebna
- nikoli
- Novo
- št
- Upoštevajte
- prenosnik
- zvezki
- Številka
- predmet
- Shranjevanje objektov
- predmeti
- of
- Ponudbe
- pogosto
- Staro
- starejši
- on
- ONE
- samo
- OP
- odprite
- open source
- Delovanje
- operacije
- Optimizirajte
- Možnost
- možnosti
- or
- Da
- naši
- izhod
- premagovanje
- lastne
- del
- strastno
- preteklosti
- opravlja
- performance
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Popular
- Prispevek
- predpogoji
- prejšnja
- prej
- primarni
- postopek
- obravnavati
- proizvodnjo
- Izdelek
- produktni vodja
- Izdelki
- Lastnosti
- Python
- poizvedbe
- Cene
- Surovi
- Preberi
- reading
- priporočeno
- Zabeležena
- evidence
- zmanjšuje
- glejte
- referenčno
- zanesljiv
- odstrani
- odstrani
- odstranjevanje
- zamenjajte
- obvezna
- povzroči
- rezultat
- Trgovina na drobno
- zadrževanje
- robusten
- Run
- tek
- Enako
- razširljive
- Lestvica
- Seattle
- drugi
- Oddelek
- glej
- izberite
- izbiranje
- ločena
- Storitev
- Storitve
- Zasedanje
- nastavite
- shouldnt
- Prikaži
- pokazale
- Razstave
- pomemben
- Enostavno
- poenostavlja
- poenostavitev
- saj
- Velikosti
- nekoliko drugačen
- SLP
- majhna
- manj
- pametna
- Posnetek
- So
- rešitve
- vir
- Vesolje
- Spark
- posebna
- specifična
- posebej
- določeno
- hitrost
- hitrosti
- porabljen
- SQL
- Začetek
- Izjava
- Izjave
- postaja
- Korak
- Koraki
- Še vedno
- shranjevanje
- trgovina
- shranjeni
- Strategija
- String
- taka
- Podprti
- sistem
- sistemi
- miza
- Tacoma
- kot
- da
- O
- njihove
- Njih
- POTEM
- te
- ta
- Prag
- skozi
- čas
- Čas potovanja
- Časovni žig
- do
- Sledenje
- transakcijski
- Transakcije
- potovanja
- tip
- neprimerljivo
- Nadgradnja
- posodobljeno
- posodobitve
- us
- Uporaba
- uporaba
- Rabljeni
- uporabo
- Vakuumska
- vrednost
- različica
- različice
- želeli
- je
- načini
- we
- web
- spletne storitve
- so bili
- kdaj
- ki
- medtem
- bo
- z
- brez
- delo
- pisati
- leto
- jo
- Vaša rutina za
- zefirnet