V današnjem podatkovno vodenem poslovnem okolju se organizacije soočajo z izzivom učinkovite priprave in preoblikovanja velikih količin podatkov za namene analitike in podatkovne znanosti. Podjetja morajo zgraditi podatkovna skladišča in podatkovna jezera na podlagi operativnih podatkov. To je posledica potrebe po centralizaciji in integraciji podatkov, ki prihajajo iz različnih virov.
Hkrati operativni podatki pogosto izvirajo iz aplikacij, ki jih podpirajo podedovane shrambe podatkov. Posodabljanje aplikacij zahteva arhitekturo mikrostoritev, ki posledično zahteva konsolidacijo podatkov iz več virov za izgradnjo operativne shrambe podatkov. Brez posodobitve lahko starejše aplikacije povzročijo večje stroške vzdrževanja. Posodobitev aplikacij vključuje spremembo osnovnega mehanizma baze podatkov v sodobno bazo podatkov, ki temelji na dokumentih, kot je MongoDB.
Ti dve nalogi (izgradnja podatkovnih jezer ali podatkovnih skladišč in posodobitev aplikacij) vključujeta premikanje podatkov, ki uporablja postopek ekstrahiranja, preoblikovanja in nalaganja (ETL). Delo ETL je ključna funkcija za dobro strukturiran proces za uspeh.
AWS lepilo je storitev integracije podatkov brez strežnika, ki omogoča preprosto odkrivanje, pripravo, premikanje in integracijo podatkov iz več virov za analitiko, strojno učenje (ML) in razvoj aplikacij. Atlas MongoDB je integrirana zbirka podatkovnih baz v oblaku in podatkovnih storitev, ki združuje obdelavo transakcij, iskanje na podlagi ustreznosti, analitiko v realnem času in sinhronizacijo podatkov med mobilnimi in oblaki v elegantni in integrirani arhitekturi.
Z uporabo AWS Glue z MongoDB Atlasom lahko organizacije poenostavijo svoje procese ETL. MongoDB Atlas s popolnoma upravljano, razširljivo in varno rešitvijo baze podatkov zagotavlja prilagodljivo in zanesljivo okolje za shranjevanje in upravljanje operativnih podatkov. AWS Glue ETL in MongoDB Atlas sta skupaj zmogljiva rešitev za organizacije, ki želijo optimizirati, kako gradijo podatkovna jezera in podatkovna skladišča, ter posodobiti svoje aplikacije, da bi izboljšali poslovno uspešnost, zmanjšali stroške ter spodbudili rast in uspeh.
V tej objavi prikazujemo, kako preseliti podatke iz Preprosta storitev shranjevanja Amazon (Amazon S3) vedra v MongoDB Atlas z uporabo AWS Glue ETL in kako ekstrahirati podatke iz MongoDB Atlasa v podatkovno jezero, ki temelji na Amazon S3.
Pregled rešitev
V tej objavi raziskujemo naslednje primere uporabe:
- Pridobivanje podatkov iz MongoDB – MongoDB je priljubljena zbirka podatkov, ki jo uporablja na tisoče strank za shranjevanje podatkov aplikacij v velikem obsegu. Podjetniške stranke lahko centralizirajo in integrirajo podatke, ki prihajajo iz več podatkovnih shramb, tako da zgradijo podatkovna jezera in podatkovna skladišča. Ta postopek vključuje pridobivanje podatkov iz shramb operativnih podatkov. Ko so podatki na enem mestu, jih lahko stranke hitro uporabijo za potrebe poslovnega obveščanja ali za ML.
- Vnos podatkov v MongoDB – MongoDB služi tudi kot baza podatkov brez SQL za shranjevanje aplikacijskih podatkov in gradnjo operativnih shramb podatkov. Posodabljanje aplikacij pogosto vključuje selitev operativne shrambe v MongoDB. Stranke bi morale ekstrahirati obstoječe podatke iz relacijskih baz podatkov ali iz ravnih datotek. Mobilne in spletne aplikacije pogosto zahtevajo, da podatkovni inženirji zgradijo podatkovne cevovode, da ustvarijo en sam pogled podatkov v Atlasu, medtem ko zaužijejo podatke iz več ločenih virov. Med to selitvijo bi se morali združiti z različnimi zbirkami podatkov, da bi ustvarili dokumente. Ta kompleksna operacija združevanja bi zahtevala znatno, enkratno računsko moč. Razvijalci bi to morali hitro zgraditi tudi za selitev podatkov.
AWS Glue je v teh primerih priročen s plačilnim modelom in njegovo zmožnostjo izvajanja kompleksnih transformacij v ogromnih nizih podatkov. Razvijalci lahko uporabljajo AWS Glue Studio za učinkovito ustvarjanje takšnih podatkovnih cevovodov.
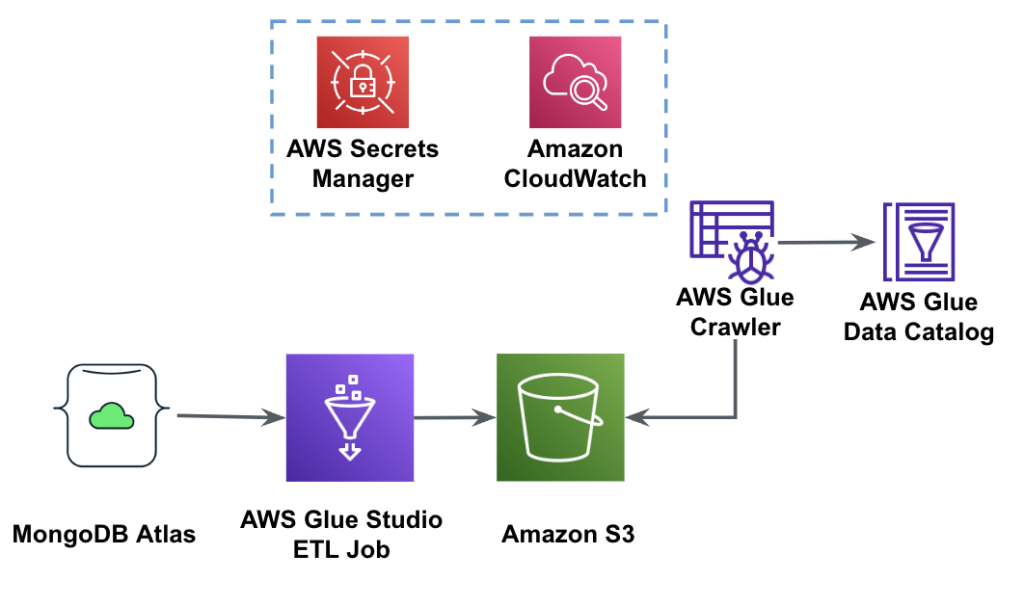
Naslednji diagram prikazuje delovni tok pridobivanja podatkov iz Atlasa MongoDB v vedro S3 z uporabo AWS Glue Studio.
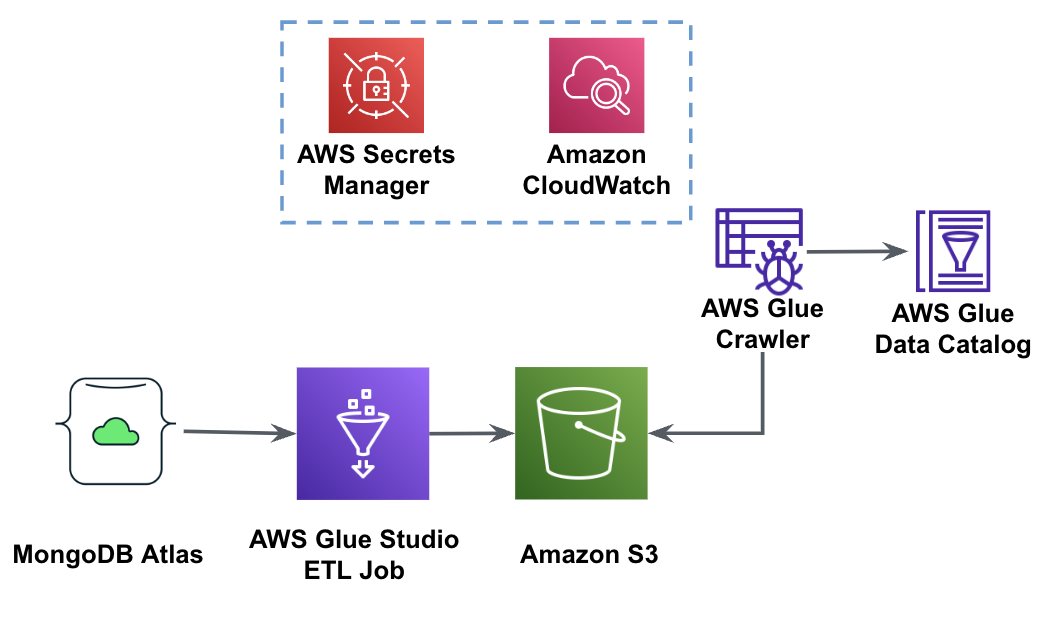
Za implementacijo te arhitekture boste potrebovali gručo MongoDB Atlas, vedro S3 in AWS upravljanje identitete in dostopa (IAM) za AWS Glue. Če želite konfigurirati te vire, si oglejte predpogojne korake v nadaljevanju GitHub repo.
Naslednja slika prikazuje delovni tok nalaganja podatkov iz vedra S3 v MongoDB Atlas z uporabo AWS Glue.
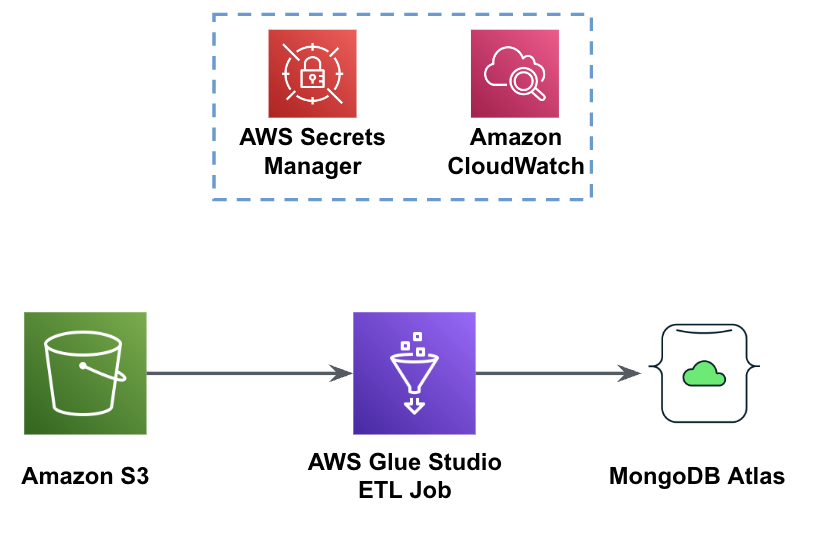
Tukaj so potrebni enaki predpogoji: vedro S3, vloga IAM in gruča MongoDB Atlas.
Naložite podatke iz Amazon S3 v MongoDB Atlas z uporabo AWS Glue
Naslednji koraki opisujejo, kako naložiti podatke iz vedra S3 v MongoDB Atlas z uporabo opravila AWS Glue. Postopek ekstrakcije iz MongoDB Atlas v Amazon S3 je zelo podoben, z izjemo uporabljenega skripta. Izpostavimo razlike med obema procesoma.
- Ustvarite brezplačno gručo v Atlasu MongoDB.
- Naložite vzorčna datoteka JSON v vaše vedro S3.
- Ustvarite novo opravilo AWS Glue Studio z Urejevalnik skriptov Spark možnost.

- Odvisno od tega, ali želite naložiti ali ekstrahirati podatke iz gruče MongoDB Atlas, vnesite naloži skript or ekstrahiraj skript v urejevalniku skriptov AWS Glue Studio.
Naslednji posnetek zaslona prikazuje delček kode za nalaganje podatkov v gručo MongoDB Atlas.

Koda uporablja Upravitelj skrivnosti AWS za pridobitev imena gruče MongoDB Atlas, uporabniškega imena in gesla. Nato ustvari a DynamicFrame za vedro S3 in ime datoteke, posredovano skriptu kot parametra. Koda pridobi bazo podatkov in imena zbirk iz konfiguracije parametrov opravila. Končno koda zapiše DynamicFrame v gručo MongoDB Atlas z uporabo pridobljenih parametrov.
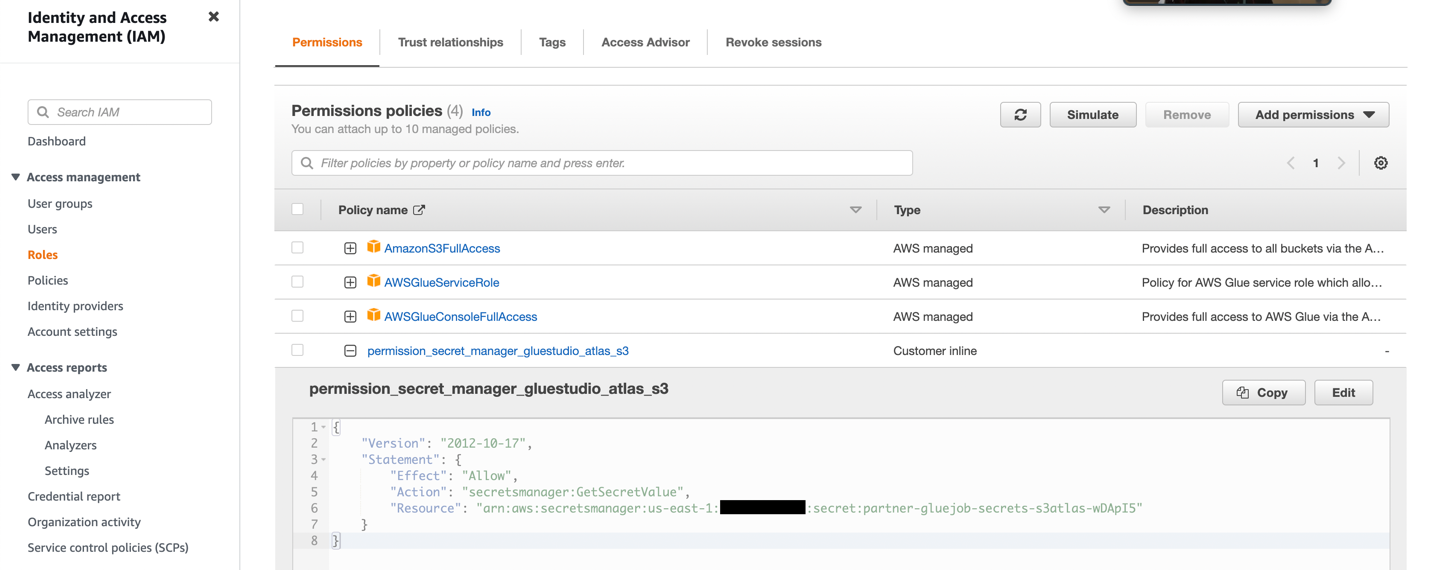
- Ustvarite vlogo IAM z dovoljenji, kot je prikazano na naslednjem posnetku zaslona.
Za več podrobnosti glejte Konfigurirajte vlogo IAM za svoje opravilo ETL.
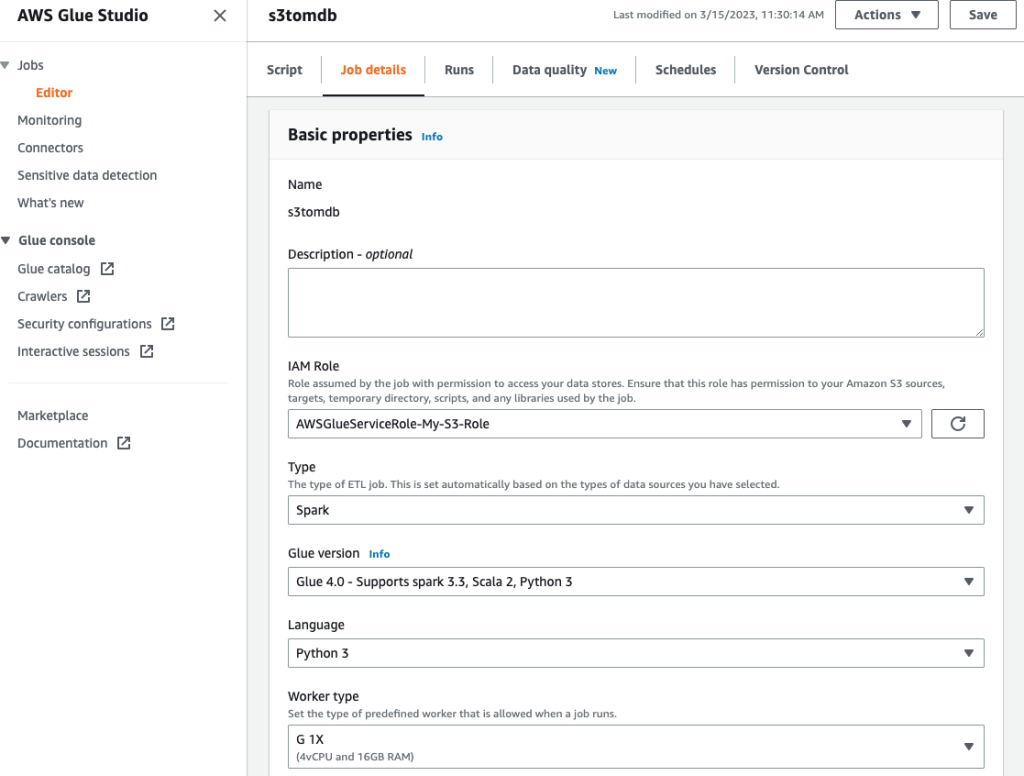
- Poimenujte opravilo in vnesite vlogo IAM, ustvarjeno v prejšnjem koraku na Podrobnosti o delovnem mestu tab.
- Ostale parametre lahko pustite privzete, kot je prikazano na naslednjih posnetkih zaslona.
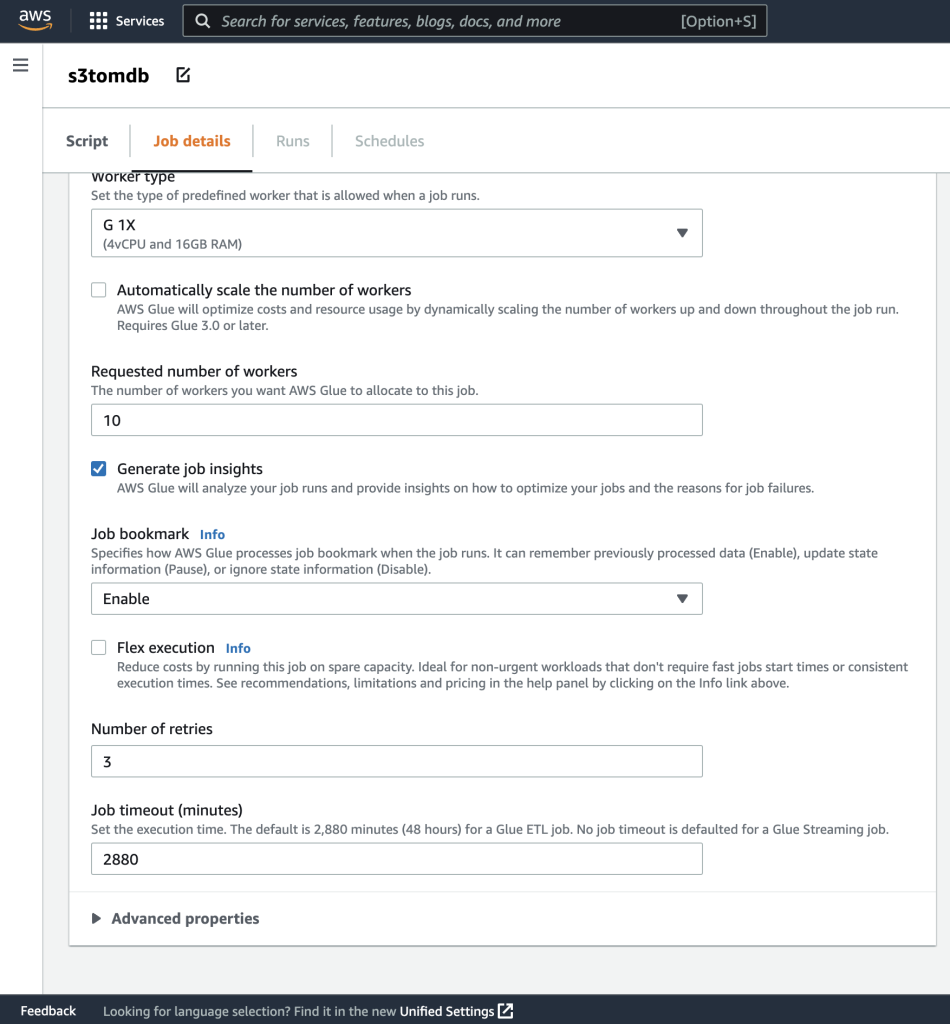
- Nato definirajte parametre opravila, ki jih uporablja skript, in navedite privzete vrednosti.
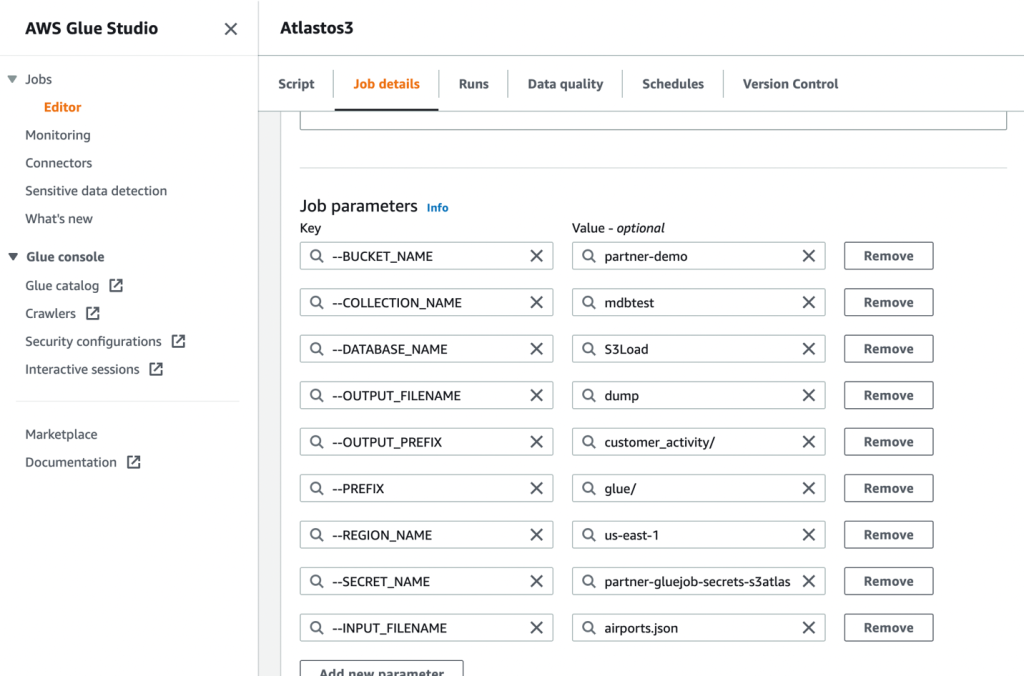
- Shranite opravilo in ga zaženite.
- Če želite potrditi uspešen zagon, opazujte vsebino zbirke podatkov MongoDB Atlas, če nalagate podatke, ali vedro S3, če izvajate ekstrakcijo.



Naslednji posnetek zaslona prikazuje rezultate uspešnega nalaganja podatkov iz vedra Amazon S3 v gručo MongoDB Atlas. Podatki so zdaj na voljo za poizvedbe v uporabniškem vmesniku MongoDB Atlas.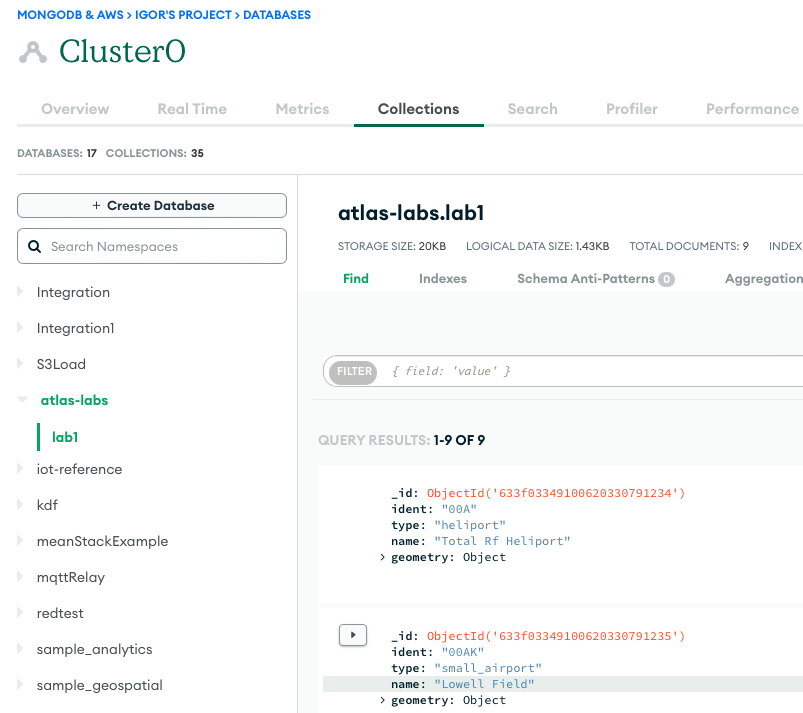
- Če želite odpraviti težave pri izvajanju, preglejte amazoncloudwatch dnevnike s povezavo na opravilih Run tab.
Naslednji posnetek zaslona prikazuje, da je opravilo uspešno potekalo, z dodatnimi podrobnostmi, kot so povezave do dnevnikov CloudWatch.

zaključek
V tej objavi smo opisali, kako ekstrahirati in vnesti podatke v MongoDB Atlas z uporabo AWS Glue.
Z opravili AWS Glue ETL lahko zdaj prenesemo podatke iz MongoDB Atlasa v vire, združljive z AWS Glue, in obratno. Rešitev lahko razširite tudi za izdelavo analitike z uporabo storitev AWS AI in ML.
Če želite izvedeti več, glejte GitHub repozitorij za navodila po korakih in vzorčno kodo. Lahko nabavite Atlas MongoDB na AWS Marketplace.
O avtorjih

Igor Aleksejev je višji arhitekt partnerskih rešitev pri AWS na področju podatkov in analitike. V svoji vlogi Igor sodeluje s strateškimi partnerji in jim pomaga zgraditi kompleksne arhitekture, optimizirane za AWS. Preden se je pridružil AWS, je kot Data/Solution Architect izvajal številne projekte na področju Big Data, vključno z več podatkovnimi jezeri v ekosistemu Hadoop. Kot podatkovni inženir je sodeloval pri uporabi AI/ML za odkrivanje goljufij in pisarniško avtomatizacijo.
 Babu Srinivasan je višji arhitekt partnerskih rešitev pri MongoDB. V svoji trenutni vlogi sodeluje z AWS pri izgradnji tehničnih integracij in referenčnih arhitektur za rešitve AWS in MongoDB. Ima več kot dve desetletji izkušenj na področju podatkovnih baz in tehnologij v oblaku. Strastno se ukvarja z zagotavljanjem tehničnih rešitev strankam, ki delajo z več globalnimi sistemskimi integratorji (GSI) na različnih območjih.
Babu Srinivasan je višji arhitekt partnerskih rešitev pri MongoDB. V svoji trenutni vlogi sodeluje z AWS pri izgradnji tehničnih integracij in referenčnih arhitektur za rešitve AWS in MongoDB. Ima več kot dve desetletji izkušenj na področju podatkovnih baz in tehnologij v oblaku. Strastno se ukvarja z zagotavljanjem tehničnih rešitev strankam, ki delajo z več globalnimi sistemskimi integratorji (GSI) na različnih območjih.
- Distribucija vsebine in PR s pomočjo SEO. Okrepite se še danes.
- PlatoAiStream. Podatkovna inteligenca Web3. Razširjeno znanje. Dostopite tukaj.
- Kovanje prihodnosti z Adryenn Ashley. Dostopite tukaj.
- Kupujte in prodajajte delnice podjetij pred IPO s PREIPO®. Dostopite tukaj.
- vir: https://aws.amazon.com/blogs/big-data/compose-your-etl-jobs-for-mongodb-atlas-with-aws-glue/
- :ima
- : je
- 100
- 11
- a
- sposobnost
- O meni
- dostop
- čez
- Dodatne
- AI
- AI / ML
- Prav tako
- Amazon
- zneski
- an
- analitika
- in
- uporaba
- Razvoj aplikacij
- aplikacije
- Uporaba
- aplikacije
- Arhitektura
- SE
- AS
- At
- atlas
- Avtomatizacija
- Na voljo
- AWS
- AWS lepilo
- AWS Marketplace
- Backed
- temeljijo
- počutje
- med
- Big
- Big Podatki
- izgradnjo
- Building
- poslovni
- Poslovna inteligenca
- poslovna uspešnost
- podjetja
- by
- klic
- CAN
- primeri
- izziv
- spreminjanje
- Cloud
- Grozd
- Koda
- zbirka
- združuje
- prihaja
- prihajajo
- kompleksna
- Izračunajte
- konfiguracija
- Potrdi
- konsolidacijo
- gradnjo
- Vsebina
- naprej
- stroški
- ustvarjajo
- ustvaril
- ustvari
- Oblikovanje
- Trenutna
- Stranke, ki so
- datum
- podatkovni inženir
- integracija podatkov
- Data jezero
- znanost o podatkih
- skladišča podatkov
- Podatkov usmerjenih
- Baze podatkov
- baze podatkov
- nabor podatkov
- desetletja
- privzeto
- izkazati
- opisati
- opisano
- Podrobnosti
- Odkrivanje
- Razvijalci
- Razvoj
- razlike
- drugačen
- odkriti
- različno
- Dokumenti
- domena
- pogon
- vozi
- med
- ekosistem
- urednik
- učinkovito
- Motor
- inženir
- Inženirji
- Vnesite
- Podjetje
- podjetniške stranke
- okolje
- Eter (ETH)
- izjema
- obstoječih
- izkušnje
- raziskuje
- razširiti
- ekstrakt
- pridobivanje
- Obraz
- Slika
- file
- datoteke
- končno
- stanovanje
- prilagodljiv
- po
- za
- goljufija
- odkrivanje goljufij
- brezplačno
- iz
- v celoti
- funkcionalnost
- geografije
- Globalno
- Rast
- Hadoop
- priročen
- ob
- he
- pomoč
- tukaj
- njegov
- Kako
- Kako
- HTML
- http
- HTTPS
- velika
- IAM
- identiteta
- if
- izvajati
- izvajali
- izboljšanje
- in
- Vključno
- narašča
- vhod
- Navodila
- integrirati
- integrirana
- integracija
- integracije
- Intelligence
- v
- vključujejo
- vključeni
- IT
- ITS
- Job
- Delovna mesta
- pridružite
- pridružil
- json
- Ključne
- Jezero
- velika
- UČITE
- učenje
- pustite
- Legacy
- kot
- LINK
- Povezave
- obremenitev
- nalaganje
- si
- stroj
- strojno učenje
- vzdrževanje
- IZDELA
- upravlja
- upravljanje
- več
- tržnica
- Maj ..
- selitev
- migracije
- ML
- Mobilni
- Model
- sodobna
- modernizacija
- posodobiti
- MongoDB
- več
- premikanje
- Gibanje
- več
- Ime
- Imena
- Nimate
- potrebna
- potrebe
- Novo
- zdaj
- opazujejo
- of
- Office
- pogosto
- on
- ONE
- Delovanje
- operativno
- Optimizirajte
- Možnost
- or
- Da
- organizacije
- ven
- parametri
- partner
- partnerji
- opravil
- strastno
- Geslo
- performance
- izvajati
- Dovoljenja
- Kraj
- platon
- Platonova podatkovna inteligenca
- PlatoData
- Popular
- Prispevek
- moč
- močan
- Pripravimo
- priprava
- predpogoji
- prejšnja
- Predhodna
- Postopek
- Procesi
- obravnavati
- projekti
- zagotavlja
- zagotavljanje
- namene
- poizvedbe
- hitro
- v realnem času
- zmanjša
- zanesljiv
- zahteva
- zahteva
- viri
- REST
- Rezultati
- pregleda
- vloga
- Run
- Enako
- razširljive
- Lestvica
- Znanost
- galerija
- Iskalnik
- zavarovanje
- višji
- Brez strežnika
- služi
- Storitev
- Storitve
- več
- pokazale
- Razstave
- pomemben
- Podoben
- Enostavno
- sam
- Rešitev
- rešitve
- Viri
- Korak
- Koraki
- shranjevanje
- trgovina
- trgovine
- naravnost
- Strateško
- strateški partnerji
- racionalizirati
- studio
- uspeh
- uspeh
- uspešno
- Uspešno
- taka
- apartma
- dobavi
- Sinhronizacija
- sistem
- Naloge
- tehnični
- Tehnologije
- kot
- da
- O
- njihove
- Njih
- POTEM
- te
- jih
- ta
- tisoče
- čas
- do
- današnje
- skupaj
- transakcijski
- prenos
- Transform
- transformacije
- preoblikovanje
- OBRAT
- dva
- ui
- osnovni
- uporaba
- Rabljeni
- uporabnik
- uporabo
- Vrednote
- zelo
- Poglej
- želeli
- je
- we
- web
- so bili
- kdaj
- ali
- ki
- medtem
- bo
- z
- brez
- potek dela
- deluje
- bi
- jo
- Vaša rutina za
- zefirnet