Нажмите, чтобы узнать больше об авторе Кендалл Кларк.
Обязанность ИТ обеспечивать ценность для бизнеса как никогда высока. Фактически, 76% руководителей считают, что ИТ должен быть активным партнером в разработке бизнес-стратегии. Здесь ловкость является ключом к успеху. Однако большинству предприятий мешают стратегии работы с данными, которые оставляют команды в затруднительном положении, когда рынок меняется или возникают новые проблемы.
Возьмем, к примеру, системы управления структурированными данными. Этот вариант хорошо работал, когда сам ландшафт корпоративных данных был преимущественно структурирован. Но мир теперь другой, и в ландшафте корпоративных данных преобладают гибридные, разнообразные и изменяющиеся данные. Появление Интернета вещей (IoT), рост объема неструктурированных данных, повышение актуальности внешних источников данных и тенденция к созданию гибридных многооблачных сред являются препятствиями для удовлетворения каждого нового запроса данных. старая стратегия данных, основанная на реляционных системах данных, в корне не работает. Так как же предприятия могут перейти от реактивной стратегии обработки данных к гибкой?
Enterprise Data Fabrics: путь вперед
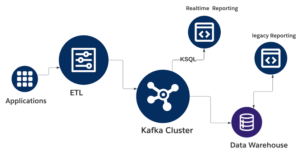
Сегодня организации стремятся построить фабрика данных для поддержки совместных, кросс-функциональных проектов и продуктов, а также для того, чтобы избежать реактивных рабочих процессов с помощью устойчивой цифровой основы — не требуется ломать и заменять. Фабрики данных объединяют данные из внутренних хранилищ данных и внешних источников и создают информационную сеть для приложений, ИИ и аналитики. Проще говоря, они поддерживают весь спектр проблем с данными в современном сложном, подключенном предприятии.
В отличие от старых статических методов интеграции данных, ключевые принципы фабрик данных заключаются в том, что они могут:
- Отвечайте на непредвиденные вопросы и адаптируйтесь к новым требованиям
- Придайте смысл данным, что приведет к лучшему пониманию
- Включите запросы к хранилищам данных и внешним источникам независимо от структуры данных.
- Модернизируйте существующие системы так, чтобы не требовалось замены
- Подключайте данные на уровне вычислений, а не на уровне хранения, чтобы хранилища данных можно было подключать без создания дополнительных хранилищ.
Фабрики данных также поддерживают кросс-функциональные подключения к данным, которые являются ключевыми для создания и защиты конкурентных преимуществ и обеспечения совместной работы в рамках предприятия и с внешними партнерами. Возьмем в качестве примера проблемы, связанные с инновациями в цепочке поставок. Обычные системы данных цепочки поставок представляют собой эстафету, работающую с линейной передачей обслуживания и разрозненными одноранговыми связями между системами. Мы видели предсказуемые результаты, когда разразился COVID-19 и глобальные цепочки поставок рухнули. Некоторое напряжение или даже частичный крах были неизбежны, но последствия усугублялись неадекватными стратегиями обработки данных, которые рассматривали цепочку поставок как жесткую систему. На самом деле цепочка поставок представляет собой сложную сеть участников, которые должны быть полностью синхронизированы, чтобы корректироваться по мере необходимости.
С цифровой сетью поставок, основанной на фабрике данных, предприятия могут отвечать на сложные вопросы, на которые они раньше не обращали внимания, например, «покажите мне все партии сырья и связанных с ними поставщиков, участвующих в производстве партии готовой продукции 123». Или «Как сравнить себестоимость продукта А в этих двух регионах?» Или «какие производители поставляли сырье, о котором идет речь в этой жалобе клиента?»
Создание успешной структуры данных начинается с понимания ее материалов
В отличие от других подходов, фабрики данных объединяют существующие системы и приложения управления данными. Поэтому неудивительно, что фабрики данных быстро рассматриваются как следующий шаг вперед в развитии пространства интеграции данных. Это происходит потому, что фабрики данных могут:
1. Раскройте скрытый смысл: Фабрики данных меняют статус-кво, предоставляя смысл, а не только данные, по всему предприятию. Это значение сплетено из многих источников: данных и метаданных, внутренних и внешних источников, а также облачных и локальных систем. Смысл фиксируется внутри и с помощью расширяемых моделей данных на основе графа знаний, при этом весь контекст каждого актива данных полностью присутствует и доступен в машиночитаемой форме. Благодаря фабрике данных люди и алгоритмы могут принимать более обоснованные решения, а также снижать вероятность и риск неправильного использования или неправильной интерпретации данных.
2. Ответьте на сложные вопросы: Структуры данных предоставляют ответы с помощью мощных возможностей запросов, поиска и обучения. Вместо статического объекта, основанного на перемещении или копировании данных, платформа фабрики данных предоставляет динамический «запрашиваемый» уровень данных, который собирает ответы со всего мира. разрозненные хранилища данных. Предыдущие стратегии интеграции данных основывались на создании новой модели данных для поддержки каждого нового варианта использования, а затем на перемещении или копировании данных для заполнения этой модели данных. Благодаря фабрике данных модели данных можно использовать повторно, поэтому, когда возникают непредвиденные вопросы, командам легко адаптироваться к потребностям бизнеса.
3. Поддержите кросс-функциональные проекты управления данными: Фабрики данных объединяют существующие системы управления данными, обогащая все подключенные приложения. Они заменяют старые системы, которые собирали или каталогизировали активы предприятия, но не могли сделать данные пригодными для использования. Предыдущие решения также потерпели неудачу отчасти из-за их неспособности обрабатывать гибридные, разнообразные и изменяющиеся данные, а также из-за организационного противодействия. Однако фабрики данных созданы для совместной работы, использования и соединения существующих активов, а также для запуска нового поколения кросс-функциональных проектов по управлению данными.
Модернизация существующих инвестиций
Большинство из нас помнят, как озера данных когда-то давали надежду на централизацию активов данных предприятия. Но многим озерам данных не удается реализовать свою рекламу именно потому, что они размещают данные на уровне хранения, а не соединяют их на уровне вычислений. Они используют данные на основе их местоположения, а не на основе их бизнес-значения. Вся предпосылка, лежащая в основе структуры данных, заключается в том, что физическое совместное размещение данных само по себе не обеспечивает соединение данных или обеспечивает смысл или контекст. Старые поколения интеграционных систем на основе хранения, таких как хранилища данных, на самом деле даже менее эффективны, чем озера данных, поскольку они с самого начала легко управляют только структурированными данными, оставляя полуструктурированные и неструктурированные хранилища данных полностью безадресными и разъединенными. Компании быстро обратились к каталогам данных, чтобы попытаться справиться с ошеломляющим разнообразием своих ландшафтов данных, только для того, чтобы узнать, что одна только каталогизация не ведет к подключенному предприятию.
Хотя эти технологии обещали покончить с хранилищами данных, правда в том, что они неизбежны и существуют по очень веским причинам. Они позволяют осуществлять локальный контроль и управление, когда это важно для определенной части бизнеса, поскольку некоторые данные должны храниться отдельно от других данных в соответствии с правовыми нормами или просто по унаследованным бизнес-причинам. Традиционная интеграция данных, ориентированная на устранение
разрозненных хранилищ посредством освоения, миграции, консолидации или управления. Но фабрики данных предлагают практическую альтернативу. Вместо того, чтобы работать с хранилищами данных, фабрика данных использует их, не требуя дополнительных копий данных. Вместо того, чтобы заменять устаревшие технологии, фабрика данных работает вместе с существующими инвестициями и повышает их полезность. Это связано с тем, что структура данных — это архитектурный проект, который работает на уровне вычислений и фокусируется на подключении данных, где бы они ни находились, и, таким образом, фактически улучшает существующие физически консолидированные ресурсы хранения данных, такие как озера данных, каталоги данных, хранилища, MDM и другие.
Графики знаний: недостающий элемент успешной структуры данных
Графы знаний способны отображать все разнообразие и сложность корпоративных данных, поскольку они служат универсальным форматом для значения, независимо от исходной структуры, местоположения или формата данных. Граф знаний заменяет текущий трудоемкий процесс интеграции корпоративных данных, который обычно включает в себя извлечение, преобразование, моделирование, сопоставление, а затем перемещение данных между различными приложениями. Пользовательский код, необходимый для моделирования и отображения, быстро становится громоздким в больших масштабах, что замедляет темпы инноваций и анализа.
Графы знаний являются неотъемлемой частью эффективной структуры данных, поскольку они создают многоразовую сеть знаний и легко представляют данные различной структуры и поддерживают несколько схем. Создавая доступное для запросов, повторно используемое семантическое понимание корпоративных и сторонних данных, графы знаний служат ядром структуры данных: обогащают и ускоряют существующие инвестиции и обеспечивают критический доступ к бизнес-аналитике.
Подобно обычной фабрике, которая соответствует всему, что в нее входит, фабрика корпоративных данных накладывается на существующие активы данных и подключается к ним через отдельные потоки, объединяя эти источники в единый слой. Таким образом, фабрики данных фактически увеличивают коммерческую ценность существующих инвестиций.
- доступ
- активный
- дополнительный
- плюс
- AI
- алгоритмы
- аналитика
- Приложения
- Программы
- около
- активы
- Активы
- строить
- бизнес
- изменение
- облако
- код
- сотрудничество
- Компании
- Соединение
- Вычисление
- Коммутация
- консолидация
- Covid-19.
- Создающий
- Текущий
- данным
- Интеграция данных
- управление данными
- хранение данных
- стратегия данных
- информационное хранилище
- доставки
- Проект
- Интернет
- Разнообразие
- вождение
- Эффективный
- Предприятие
- добыча
- ткань
- форма
- формат
- вперед
- полный
- Глобальный
- хорошо
- управление
- здесь
- Как
- HTTPS
- Гибридный
- информация
- Инновации
- рефлексологии
- интеграции.
- Интернет
- Интернет вещей
- Вложения
- вовлеченный
- КАТО
- IT
- Основные
- знания
- большой
- вести
- УЧИТЬСЯ
- изучение
- Юр. Информация
- Кредитное плечо
- локальным
- расположение
- управление
- рынок
- материалы
- модель
- моделирование
- сеть
- предлагают
- операционный
- Опция
- Другое
- Другое
- партнер
- Люди
- Платформа
- мощностью
- представить
- Продукт
- Производство
- Продукция
- проектов
- Гонки
- Сырье
- Реальность
- причины
- "Регулирование"
- Итоги
- Снижение
- Шкала
- Поиск
- сдвиг
- Замедление
- So
- Решения
- Space
- Статус:
- диск
- Стратегия
- успех
- успешный
- поставщики
- поставка
- цепочками поставок
- Каналы поставок
- поддержка
- система
- системы
- технологии
- Переводы
- открывай
- Universal
- us
- утилита
- ценностное
- объем
- Склады
- Ткать
- в
- работает
- Мир