
По мере того как искусственный интеллект мигрирует из облака в Edge, мы видим, что эта технология используется в постоянно расширяющемся разнообразии вариантов использования — от обнаружения аномалий до приложений, включая умные покупки, наблюдение, робототехнику и автоматизацию производства. Следовательно, не существует универсального решения, подходящего всем. Но с быстрым ростом количества устройств с камерой ИИ получил наиболее широкое распространение для анализа видеоданных в реальном времени с целью автоматизации видеомониторинга для повышения безопасности, повышения операционной эффективности и улучшения качества обслуживания клиентов, что в конечном итоге дает конкурентное преимущество в своих отраслях. . Чтобы лучше поддерживать анализ видео, вы должны понимать стратегии оптимизации производительности системы в периферийных развертываниях ИИ.
- Выбор вычислительных механизмов подходящего размера, отвечающих требуемым уровням производительности или превосходящих их. Для приложения искусственного интеллекта эти вычислительные механизмы должны выполнять функции всего конвейера машинного зрения (т. е. предварительную и постобработку видео, вывод нейронной сети).
Может потребоваться специальный ускоритель искусственного интеллекта, будь то дискретный или интегрированный в SoC (в отличие от выполнения вывода искусственного интеллекта на процессоре или графическом процессоре).
- Понимание разницы между пропускной способностью и задержкой; при этом пропускная способность — это скорость, с которой данные могут обрабатываться в системе, а задержка измеряет задержку обработки данных в системе и часто связана с оперативностью реагирования в реальном времени. Например, система может генерировать данные изображения со скоростью 100 кадров в секунду (пропускная способность), но для прохождения изображения через систему требуется 100 мс (задержка).
- Учитывая возможность легкого масштабирования производительности ИИ в будущем для удовлетворения растущих потребностей, меняющихся требований и развивающихся технологий (например, более совершенных моделей ИИ для повышения функциональности и точности). Масштабирование производительности можно выполнить с помощью ускорителей искусственного интеллекта в формате модуля или дополнительных микросхем ускорителей искусственного интеллекта.
Фактические требования к производительности зависят от приложения. Обычно можно ожидать, что для видеоаналитики система должна обрабатывать потоки данных, поступающие с камер, с частотой 30-60 кадров в секунду и разрешением 1080p или 4k. Камера с поддержкой искусственного интеллекта будет обрабатывать один поток; периферийное устройство будет обрабатывать несколько потоков параллельно. В любом случае периферийная система искусственного интеллекта должна поддерживать функции предварительной обработки для преобразования данных датчика камеры в формат, соответствующий входным требованиям раздела вывода искусственного интеллекта (рис. 1).
Функции предварительной обработки принимают необработанные данные и выполняют такие задачи, как изменение размера, нормализация и преобразование цветового пространства, прежде чем подавать входные данные в модель, работающую в ускорителе искусственного интеллекта. Предварительная обработка может использовать эффективные библиотеки обработки изображений, такие как OpenCV, чтобы сократить время предварительной обработки. Постобработка включает в себя анализ результатов вывода. Он использует такие задачи, как немаксимальное подавление (NMS интерпретирует выходные данные большинства моделей обнаружения объектов) и отображение изображений для создания действенной информации, такой как ограничивающие рамки, метки классов или оценки достоверности.

Рисунок 1. Для вывода модели ИИ функции предварительной и постобработки обычно выполняются на процессоре приложений.
При выводе модели ИИ может возникнуть дополнительная проблема, связанная с обработкой нескольких моделей нейронных сетей за кадр, в зависимости от возможностей приложения. Приложения компьютерного зрения обычно включают в себя несколько задач ИИ, требующих конвейера из нескольких моделей. Более того, выходные данные одной модели часто являются входными данными следующей модели. Другими словами, модели в приложении часто зависят друг от друга и должны выполняться последовательно. Точный набор моделей для выполнения может не быть статичным и может меняться динамически, даже от кадра к кадру.
Для динамического запуска нескольких моделей требуется внешний ускоритель искусственного интеллекта с выделенной и достаточно большой памятью для хранения моделей. Часто встроенный ускоритель искусственного интеллекта внутри SoC не может управлять многомодельной рабочей нагрузкой из-за ограничений, налагаемых подсистемой общей памяти и другими ресурсами в SoC.
Например, отслеживание объекта на основе прогнозирования движения основано на непрерывном обнаружении для определения вектора, который используется для идентификации отслеживаемого объекта в будущем положении. Эффективность этого подхода ограничена, поскольку ему не хватает истинной возможности повторной идентификации. При прогнозировании движения трек объекта может быть потерян из-за пропущенных обнаружений, окклюзий или выхода объекта из поля зрения, даже на мгновение. После потери невозможно повторно связать трек объекта. Добавление повторной идентификации решает это ограничение, но требует внедрения визуального внешнего вида (т. е. отпечатка изображения). Внедрения внешнего вида требуют, чтобы вторая сеть сгенерировала вектор признаков путем обработки изображения, содержащегося внутри ограничивающей рамки объекта, обнаруженного первой сетью. Это встраивание можно использовать для повторной идентификации объекта независимо от времени и пространства. Поскольку внедрения должны создаваться для каждого объекта, обнаруженного в поле зрения, требования к обработке возрастают по мере того, как сцена становится более загруженной. Отслеживание объектов с помощью повторной идентификации требует тщательного рассмотрения между выполнением обнаружения с высокой точностью, высоким разрешением и высокой частотой кадров и резервированием достаточных накладных расходов для масштабируемости внедрения. Одним из способов решения требований к обработке является использование специального ускорителя искусственного интеллекта. Как упоминалось ранее, механизм искусственного интеллекта SoC может страдать из-за нехватки ресурсов общей памяти. Оптимизацию модели также можно использовать для снижения требований к обработке, но это может повлиять на производительность и/или точность.
В интеллектуальной камере или периферийном устройстве встроенный SoC (т. е. хост-процессор) получает видеокадры и выполняет этапы предварительной обработки, которые мы описали ранее. Эти функции могут выполняться с помощью ядер ЦП или графического процессора SoC (если таковой имеется), но они также могут выполняться специальными аппаратными ускорителями в SoC (например, процессором сигналов изображения). После завершения этих этапов предварительной обработки ускоритель искусственного интеллекта, интегрированный в SoC, может получить прямой доступ к этому квантованному входному сигналу из системной памяти, или, в случае дискретного ускорителя искусственного интеллекта, входные данные затем доставляются для вывода, обычно через Интерфейс USB или PCIe.
Интегрированная SoC может содержать ряд вычислительных блоков, включая центральные процессоры, графические процессоры, ускоритель искусственного интеллекта, процессоры машинного зрения, видеокодеры/декодеры, процессор сигналов изображения (ISP) и многое другое. Все эти вычислительные блоки используют одну и ту же шину памяти и, следовательно, имеют доступ к одной и той же памяти. Кроме того, центральный и графический процессоры, возможно, также должны будут сыграть роль в выводе, и эти устройства будут заняты выполнением других задач в развернутой системе. Именно это мы подразумеваем под накладными расходами на уровне системы (рис. 2).
Многие разработчики ошибочно оценивают производительность встроенного в SoC ускорителя искусственного интеллекта, не учитывая влияние накладных расходов на системном уровне на общую производительность. В качестве примера рассмотрим запуск теста YOLO на ускорителе искусственного интеллекта производительностью 50 TOPS, интегрированном в SoC, который может получить результат теста 100 выводов в секунду (IPS). Но в развернутой системе со всеми остальными активными вычислительными блоками эти 50 TOPS можно уменьшить примерно до 12 TOPS, а общая производительность составит только 25 IPS, при условии щедрого коэффициента использования 25%. Накладные расходы системы всегда являются фактором, если платформа непрерывно обрабатывает видеопотоки. В качестве альтернативы, при использовании дискретного ускорителя искусственного интеллекта (например, Kinara Ara-1, Hailo-8, Intel Myriad X) загрузка на уровне системы может превысить 90 %, поскольку как только хост-система инициирует функцию вывода и передает входные данные модели искусственного интеллекта. данных, ускоритель работает автономно, используя выделенную память для доступа к весам и параметрам модели.
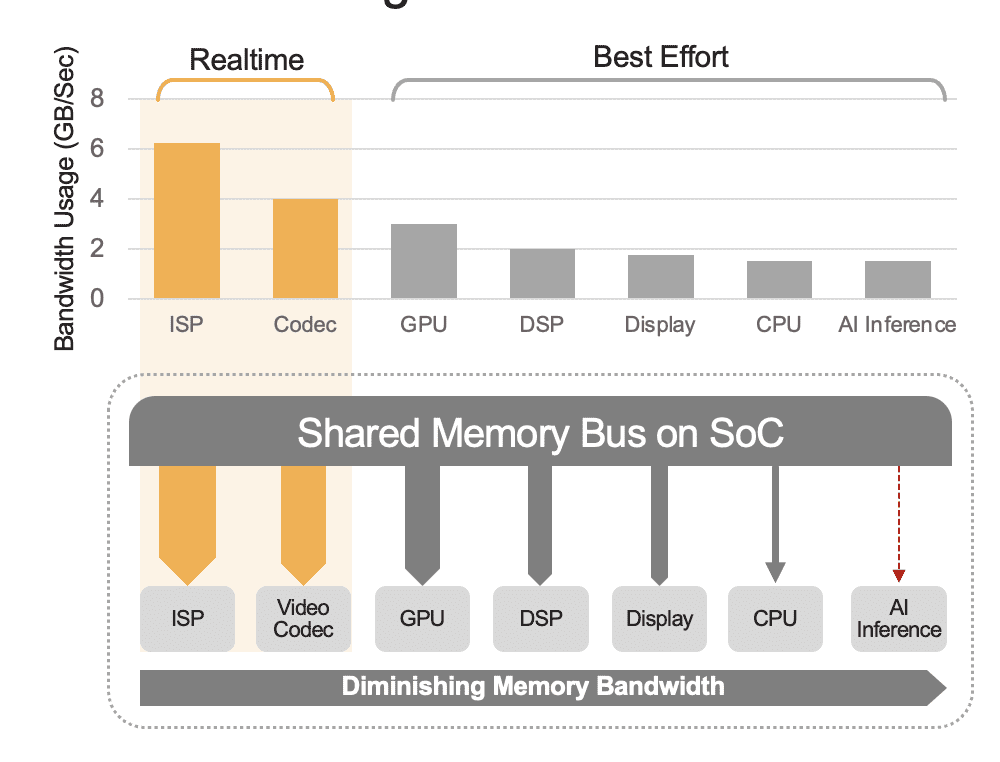
Рисунок 2. Шина общей памяти будет управлять производительностью на уровне системы, показанной здесь с приблизительными значениями. Реальные значения будут варьироваться в зависимости от модели использования вашего приложения и конфигурации вычислительного блока SoC.
До этого момента мы обсуждали производительность ИИ с точки зрения количества кадров в секунду и TOPS. Но низкая задержка — еще одно важное требование для обеспечения оперативности системы в реальном времени. Например, в играх низкая задержка имеет решающее значение для плавного и оперативного игрового процесса, особенно в играх с управлением движением и системах виртуальной реальности (VR). В системах автономного вождения низкая задержка жизненно важна для обнаружения объектов в реальном времени, распознавания пешеходов, определения полосы движения и распознавания дорожных знаков, чтобы избежать угрозы безопасности. Системы автономного вождения обычно требуют сквозной задержки менее 150 мс от обнаружения до фактического действия. Аналогичным образом, в производстве низкая задержка важна для обнаружения дефектов в реальном времени, распознавания аномалий, а роботизированное управление зависит от видеоаналитики с малой задержкой, чтобы обеспечить эффективную работу и минимизировать время простоя производства.
В общем, существует три компонента задержки в приложении видеоаналитики (рис. 3):
- Задержка захвата данных — это время от момента, когда датчик камеры захватывает видеокадр, до того, как кадр станет доступен системе аналитики для обработки. Вы можете оптимизировать эту задержку, выбрав камеру с быстрым сенсором и процессором с низкой задержкой, выбрав оптимальную частоту кадров и используя эффективные форматы сжатия видео.
- Задержка передачи данных — это время, в течение которого захваченные и сжатые видеоданные передаются от камеры к периферийным устройствам или локальным серверам. Сюда входят задержки сетевой обработки, возникающие в каждой конечной точке.
- Задержка обработки данных — это время, в течение которого периферийные устройства выполняют задачи обработки видео, такие как декомпрессия кадров и алгоритмы анализа (например, отслеживание объектов на основе прогнозирования движения, распознавание лиц). Как указывалось ранее, задержка обработки еще более важна для приложений, которые должны запускать несколько моделей искусственного интеллекта для каждого видеокадра.
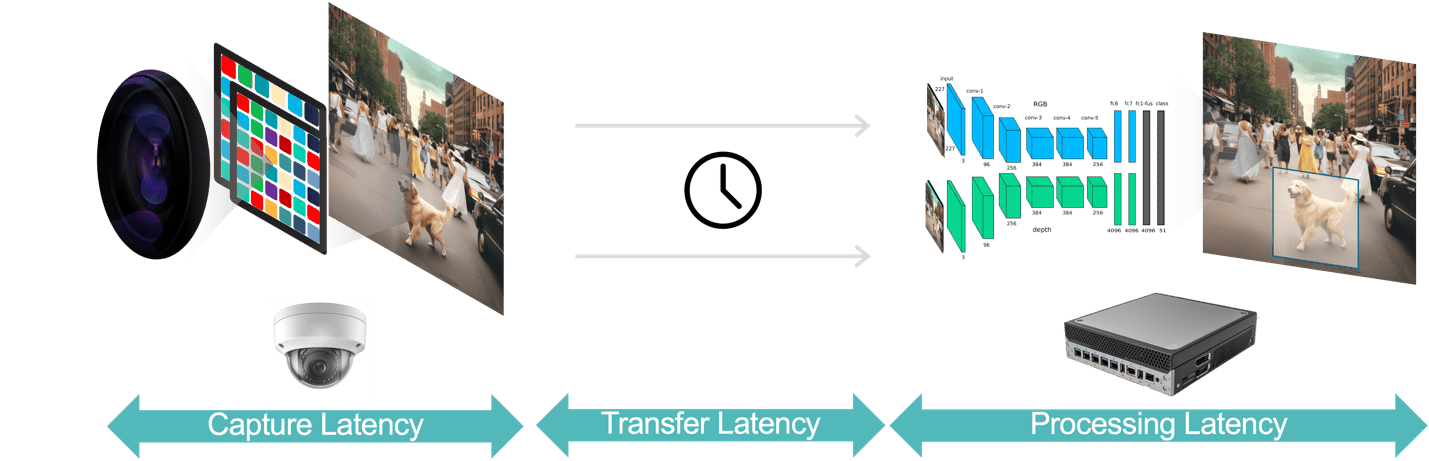
Рисунок 3. Конвейер видеоаналитики состоит из сбора, передачи и обработки данных.
Задержку обработки данных можно оптимизировать с помощью ускорителя искусственного интеллекта с архитектурой, предназначенной для минимизации перемещения данных внутри чипа, а также между вычислениями и различными уровнями иерархии памяти. Кроме того, чтобы улучшить задержку и эффективность на уровне системы, архитектура должна поддерживать нулевое (или близкое к нулю) время переключения между моделями, чтобы лучше поддерживать многомодельные приложения, которые мы обсуждали ранее. Еще один фактор повышения производительности и задержки связан с алгоритмической гибкостью. Другими словами, некоторые архитектуры предназначены для оптимального поведения только на определенных моделях ИИ, но в условиях быстро меняющейся среды ИИ новые модели с более высокой производительностью и большей точностью появляются, кажется, каждый день. Поэтому выбирайте периферийный процессор искусственного интеллекта без практических ограничений по топологии модели, операторам и размеру.
При максимизации производительности периферийного устройства искусственного интеллекта необходимо учитывать множество факторов, включая требования к производительности и задержке, а также накладные расходы системы. Успешная стратегия должна учитывать внешний ускоритель искусственного интеллекта для преодоления ограничений памяти и производительности в механизме искусственного интеллекта SoC.
Ч Чи Будучи опытным руководителем по маркетингу и управлению продуктами, Чи имеет обширный опыт продвижения продуктов и решений в полупроводниковой промышленности, уделяя особое внимание искусственному интеллекту, средствам связи и видеоинтерфейсам для различных рынков, включая корпоративный и потребительский. Будучи предпринимателем, Чи стал соучредителем двух стартапов в области полупроводниковой видеотехники, которые были приобретены публичной компанией по производству полупроводников. Чи возглавлял команды по маркетингу продуктов и любит работать с небольшой командой, которая сосредоточена на достижении отличных результатов.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://www.kdnuggets.com/maximize-performance-in-edge-ai-applications?utm_source=rss&utm_medium=rss&utm_campaign=maximize-performance-in-edge-ai-applications
- :имеет
- :является
- :нет
- 1
- 100
- 12
- 25
- 4k
- 50
- a
- способность
- ускоритель
- ускорители
- доступ
- доступа
- вмещать
- выполнять
- точность
- достижение
- приобретенный
- Приобретает
- через
- Действие
- активный
- фактического соединения
- добавить
- дополнительный
- принял
- продвинутый
- После
- снова
- AI
- AI движок
- AI модели
- алгоритмический
- алгоритмы
- Все
- причислены
- всегда
- an
- анализ
- аналитика
- анализ
- и
- обнаружение аномалии
- Другой
- Применение
- Приложения
- подхода
- архитектура
- МЫ
- AS
- связанный
- At
- автоматизировать
- автоматизация
- автономный
- автономно
- свободных мест
- доступен
- избежать
- основанный
- основа
- BE
- , так как:
- становится
- было
- до
- не являетесь
- эталонный тест
- Лучшая
- между
- изоферменты печени
- Коробка
- коробки
- встроенный
- автобус
- занятый
- но
- by
- камера
- камеры
- CAN
- возможности
- возможности
- захватить
- захваченный
- Захват
- тщательный
- случаев
- случаев
- вызов
- изменения
- чип
- чипсы
- Выбирая
- класс
- облако
- цвет
- приход
- Компания
- конкурентоспособный
- Заполненная
- компоненты
- компромат
- вычисление
- вычислительный
- Вычисление
- компьютер
- Компьютерное зрение
- Приложения компьютерного зрения
- доверие
- Конфигурация
- связь
- вследствие этого
- Рассматривать
- рассмотрение
- считается
- принимая во внимание
- состоит
- ограничения
- потребитель
- содержать
- содержащегося
- (CIJ)
- непрерывно
- Конверсия
- может
- ЦП
- критической
- клиент
- данным
- обработка данных
- день
- преданный
- задерживать
- задержки
- доставить
- поставляется
- зависимый
- в зависимости
- развернуть
- развертывания
- описано
- предназначенный
- обнаруженный
- обнаружение
- Определять
- застройщиков
- Устройства
- разница
- непосредственно
- обсуждается
- Дисплей
- время простоя
- вождение
- два
- динамично
- e
- каждый
- Ранее
- легко
- Edge
- эффект
- эффективность
- Эффективность
- затрат
- эффективный
- или
- вложения
- конец
- впритык
- Двигатель
- Двигатели
- повышать
- обеспечивать
- Предприятие
- Весь
- Предприниматель
- Окружающая среда
- существенный
- к XNUMX году
- оценивать
- Даже
- Каждая
- развивается
- пример
- превышать
- выполнять
- выполненный
- исполнительный
- ожидать
- опыт
- Впечатления
- обширный
- Богатый опыт
- и, что лучший способ
- Face
- распознавание лица
- фактор
- факторы
- завод
- БЫСТРО
- Особенность
- кормление
- поле
- фигура
- отпечаток пальца
- Во-первых,
- Трансформируемость
- фокусируется
- фокусировка
- Что касается
- формат
- КАДР
- от
- функция
- функциональность
- Функции
- Более того
- будущее
- получение
- Игры
- игровой
- игровой опыт
- Общие
- порождать
- генерируется
- щедрый
- Go
- GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР
- Графические процессоры
- большой
- большой
- Рост
- Рост
- руководство
- Аппаратные средства
- Есть
- следовательно
- здесь
- иерархия
- High
- высший
- кашель
- HTTPS
- i
- определения
- if
- изображение
- Влияние
- важную
- наложенный
- улучшать
- улучшенный
- in
- В других
- включает в себя
- В том числе
- Увеличение
- расширились
- промышленности
- промышленность
- Посвященные
- вход
- внутри
- размышления
- интегрированный
- Intel
- Интерфейс
- интерфейсы
- в
- включать в себя
- включает в себя
- независимо
- Поставщик интернет-услуг
- IT
- ЕГО
- КДнаггетс
- Этикетки
- Отсутствие
- Переулок
- большой
- Задержка
- уход
- привело
- Меньше
- уровни
- библиотеки
- такое как
- ограничение
- недостатки
- Ограниченный
- локальным
- потерянный
- Низкий
- ниже
- управлять
- управление
- производство
- многих
- Маркетинг
- Области применения:
- Максимизировать
- максимизации
- Май..
- значить
- меры
- Встречайте
- Память
- упомянутый
- может быть
- пропущенный
- модель
- Модели
- модуль
- Мониторинг
- БОЛЕЕ
- самых
- движение
- движение
- с разными
- должен
- мириады
- Возле
- потребности
- сеть
- нервный
- нейронной сети
- Новые
- следующий
- нет
- объект
- Обнаружение объекта
- происходить
- of
- .
- on
- консолидировать
- ONE
- только
- OpenCV
- операция
- оперативный
- Операторы
- против
- оптимальный
- оптимизация
- Оптимизировать
- оптимизированный
- оптимизирующий
- or
- Другое
- внешний
- выходной
- за
- общий
- Преодолеть
- Параллельные
- параметры
- особенно
- для
- выполнять
- производительность
- выполнены
- выполнения
- выполняет
- трубопровод
- Платформа
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- Играть
- Точка
- должность
- Постобработка
- практическое
- прогноз
- процесс
- обрабатываемых
- обработка
- процессор
- процессоры
- Продукт
- Производство
- Продукция
- Содействие
- обеспечивать
- что такое варган?
- ассортимент
- ранжирование
- быстро
- быстро
- Обменный курс
- Стоимость
- Сырье
- необработанные данные
- реальные
- реального времени
- Реальность
- признание
- уменьшить
- понимается
- требовать
- обязательный
- требование
- Требования
- требуется
- Постановления
- Полезные ресурсы
- отзывчивый
- Ограничения
- результат
- Итоги
- робототехника
- Роли
- Run
- Бег
- работает
- Сохранность
- то же
- Масштабируемость
- Шкала
- масштаб ай
- масштабирование
- сцена
- множество
- бесшовные
- Во-вторых
- Раздел
- посмотреть
- кажется
- выбор
- полупроводник
- набор
- Поделиться
- общие
- Шоппинг
- должен
- показанный
- подпись
- сигнал
- Аналогичным образом
- с
- одинарной
- Размер
- небольшой
- умный
- Решение
- Решения
- РЕШАТЬ
- Решает
- некоторые
- удалось
- Space
- конкретный
- стартапов
- Шаги
- магазин
- стратегий
- Стратегия
- поток
- потоки
- успешный
- такие
- достаточный
- поддержка
- подавление
- наблюдение
- система
- системы
- взять
- принимает
- задачи
- команда
- команды
- технологии
- Технологии
- terms
- чем
- который
- Ассоциация
- Будущее
- их
- тогда
- Там.
- следовательно
- Эти
- они
- этой
- те
- три
- Через
- пропускная способность
- время
- раз
- в
- Топы
- Всего
- трек
- Отслеживание
- трафик
- перевод
- переводы
- Transform
- путешествовать
- правда
- два
- типично
- В конечном счете
- не в состоянии
- понимать
- Ед. изм
- единиц
- Применение
- USB
- использование
- используемый
- использования
- через
- обычно
- Использующий
- Наши ценности
- разнообразие
- различный
- Видео
- Вид
- Виртуальный
- Виртуальная реальность
- видение
- жизненный
- vr
- Путь..
- we
- были
- Что
- будь то
- который
- широко
- будете
- без
- слова
- работает
- бы
- X
- Уступать
- Йоло
- являетесь
- ВАШЕ
- зефирнет
- нуль







