По мере того, как Roblox рос за последние 16 с лишним лет, росли и масштабы и сложность технической инфраструктуры, которая поддерживает миллионы иммерсивных совместных 3D-игр. Количество машин, которые мы поддерживаем, за последние два года увеличилось более чем в три раза: примерно с 36,000 30 по состоянию на 2021 июня 145,000 года до почти 1,000 XNUMX сегодня. Для поддержки непрерывного взаимодействия с людьми по всему миру требуется более XNUMX внутренних сервисов. Чтобы помочь нам контролировать затраты и задержки в сети, мы развертываем эти машины и управляем ими как часть специально созданной гибридной инфраструктуры частного облака, которая работает в основном локально.
Наша инфраструктура в настоящее время поддерживает более 70 миллионов ежедневных активных пользователей по всему миру, включая создателей, которые полагаются на Roblox. экономику для своего бизнеса. Все эти миллионы людей ожидают очень высокого уровня надежности. Учитывая захватывающий характер нашего опыта, мы крайне нетерпимы к задержкам или задержкам, не говоря уже о сбоях в работе. Roblox — это платформа для общения и общения, где люди собираются вместе в захватывающем 3D-опыте. Когда люди общаются через свои аватары в иммерсивном пространстве, даже незначительные задержки или сбои более заметны, чем при текстовой беседе или конференц-связи.
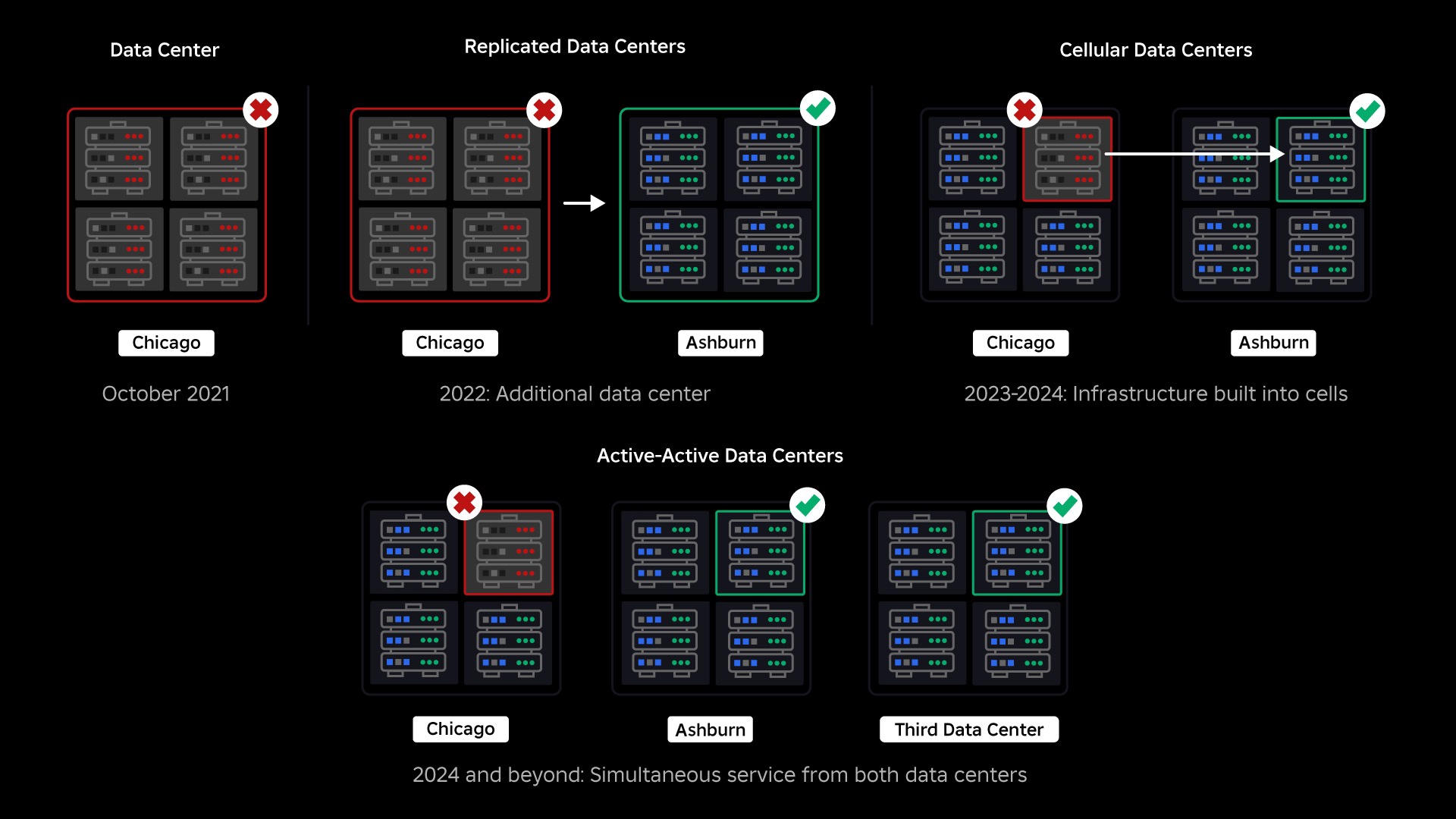
В октябре 2021 года у нас произошел общесистемный сбой. Все началось с малого, с проблемы в одном компоненте в одном центре обработки данных. Но пока мы проводили расследование, оно быстро распространилось и в конечном итоге привело к отключению электроэнергии на 73 часа. В то время мы делили оба подробности о том, что произошло и некоторые из наших первых выводов по этой проблеме. С тех пор мы изучаем эти знания и работаем над повышением устойчивости нашей инфраструктуры к типам сбоев, которые происходят во всех крупномасштабных системах из-за таких факторов, как резкие скачки трафика, погодные условия, сбои оборудования, ошибки программного обеспечения или просто люди совершают ошибки. Когда происходят такие сбои, как мы можем гарантировать, что проблема в одном компоненте или группе компонентов не распространится на всю систему? Этот вопрос находится в центре нашего внимания на протяжении последних двух лет, и хотя работа продолжается, то, что мы сделали до сих пор, уже приносит свои плоды. Например, в первой половине 2023 года мы сэкономили 125 миллионов часов взаимодействия в месяц по сравнению с первой половиной 2022 года. Сегодня мы делимся уже проделанной работой, а также нашим долгосрочным видением создания более устойчивая инфраструктурная система.
Создание защиты
В крупномасштабных инфраструктурных системах небольшие сбои случаются много раз в день. Если на одной машине возникла проблема и ее пришлось вывести из эксплуатации, это вполне осуществимо, поскольку большинство компаний поддерживают несколько экземпляров своих серверных служб. Поэтому, когда один экземпляр выходит из строя, другие берут на себя рабочую нагрузку. Чтобы устранить эти частые сбои, запросы обычно настраиваются на автоматический повтор в случае возникновения ошибки.
Это становится сложной задачей, когда система или человек повторяют попытки слишком агрессивно, что может привести к распространению мелких сбоев по всей инфраструктуре на другие службы и системы. Если сеть или пользователь повторяют попытки достаточно настойчиво, это в конечном итоге приведет к перегрузке каждого экземпляра этой службы и, возможно, других систем во всем мире. Наш сбой в 2021 году стал результатом того, что довольно часто встречается в крупномасштабных системах: сбой начинается с малого, затем распространяется по системе, становясь настолько большим, что его трудно устранить до того, как все выйдет из строя.
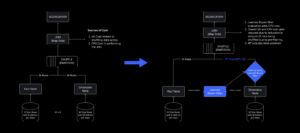
На момент сбоя у нас был один активный центр обработки данных (компоненты которого выступали в качестве резервных). Нам нужна была возможность вручную выполнить аварийное переключение в новый центр обработки данных, если из-за проблемы вышел из строя существующий. Нашей первоочередной задачей было обеспечить резервное развертывание Roblox, поэтому мы создали эту резервную копию в новом центре обработки данных, расположенном в другом географическом регионе. Это дополнительная защита для наихудшего сценария: сбой распространится на достаточное количество компонентов в центре обработки данных, и он станет полностью неработоспособным. Теперь у нас есть один центр обработки данных, обрабатывающий рабочие нагрузки (активный), и один резервный (пассивный). Наша долгосрочная цель — перейти от этой активно-пассивной конфигурации к конфигурации «активно-активный», в которой оба центра обработки данных обрабатывают рабочие нагрузки, а балансировщик нагрузки распределяет запросы между ними в зависимости от задержки, емкости и работоспособности. Как только это будет реализовано, мы ожидаем, что надежность всего Roblox будет еще выше, а аварийное переключение произойдет почти мгновенно, а не в течение нескольких часов. 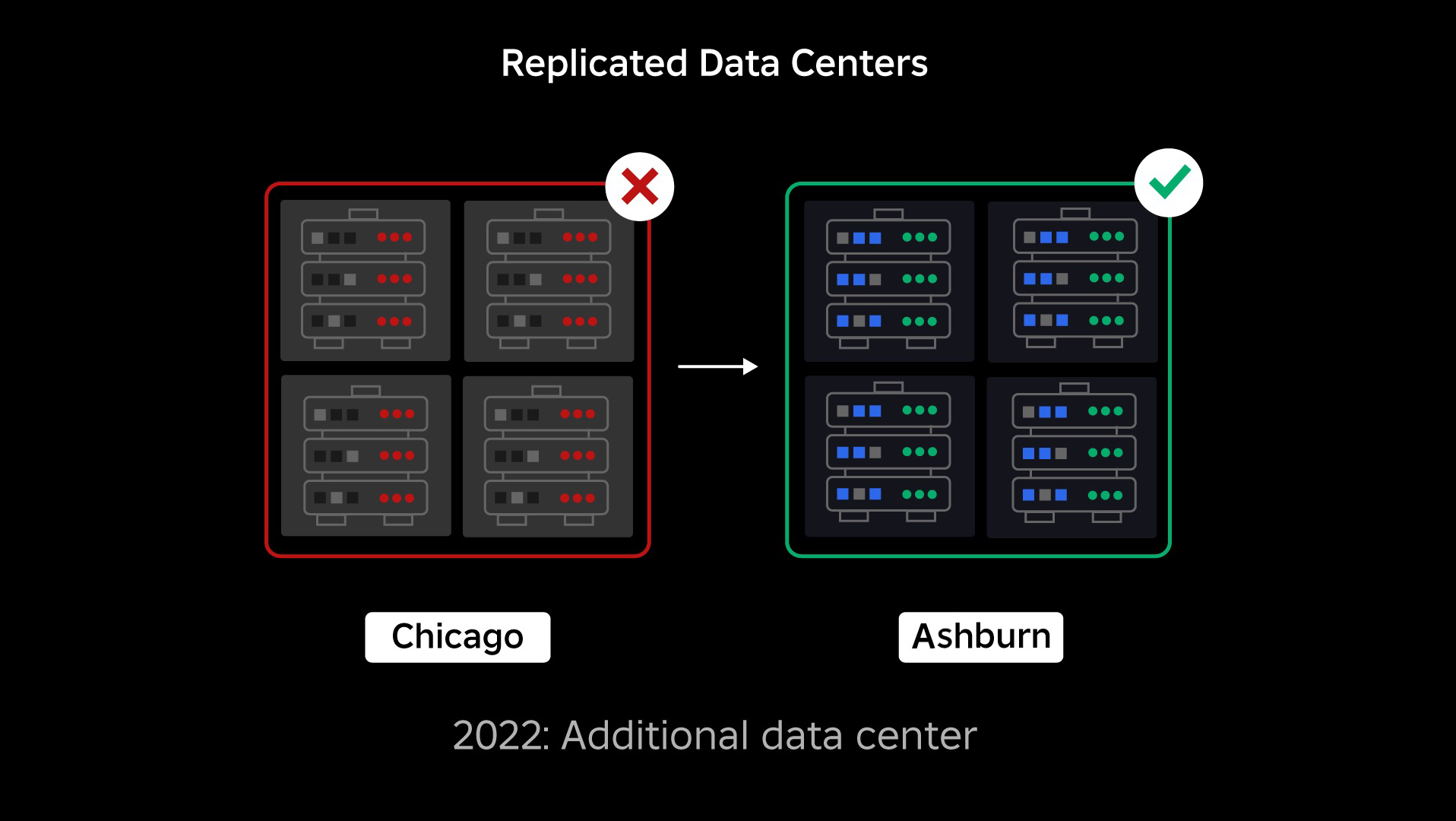
Переход на сотовую инфраструктуру
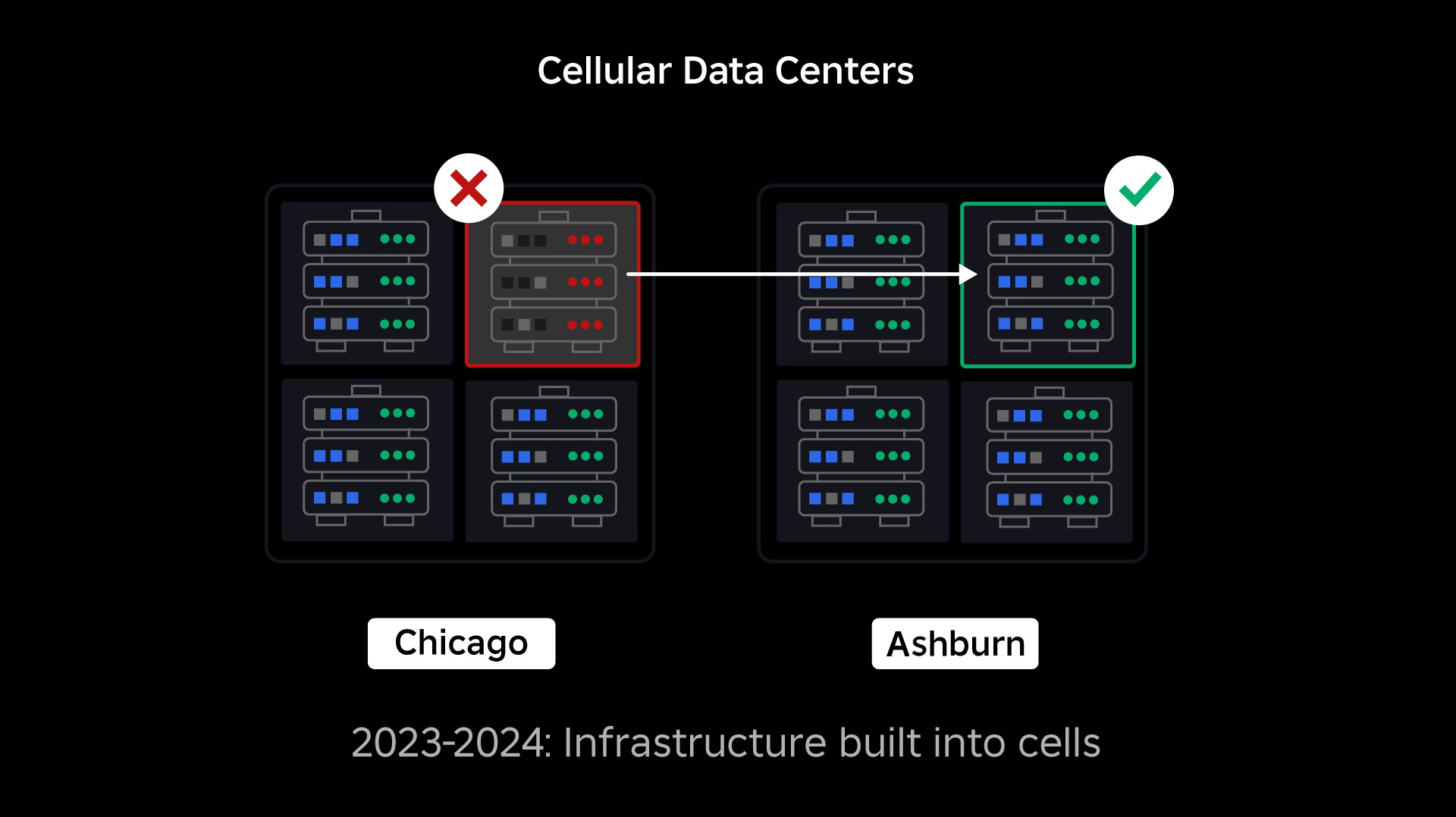
Нашим следующим приоритетом было создание прочных взрывозащитных стен внутри каждого центра обработки данных, чтобы снизить вероятность выхода из строя всего центра обработки данных. Ячейки (некоторые компании называют их кластерами) по сути представляют собой набор машин, с помощью которых мы создаем эти стены. Мы реплицируем услуги как внутри ячеек, так и между ними для дополнительной избыточности. В конечном счете, мы хотим, чтобы все сервисы Roblox работали в ячейках, чтобы они могли извлечь выгоду как из мощных взрывных стен, так и из-за резервирования. Если ячейка больше не функционирует, ее можно безопасно деактивировать. Репликация между ячейками позволяет службе продолжать работу во время восстановления ячейки. В некоторых случаях восстановление клеток может означать полное восстановление клетки. В отрасли очистка и повторная инициализация отдельной машины или небольшого набора машин является довольно распространенным явлением, но делать это для всей ячейки, содержащей около 1,400 машин, — нет.
Чтобы это работало, эти ячейки должны быть в значительной степени однородными, чтобы мы могли быстро и эффективно перемещать рабочие нагрузки из одной ячейки в другую. Мы установили определенные требования, которым должны соответствовать службы, прежде чем они начнут работать в ячейке. Например, сервисы должны быть контейнеризованы, что делает их гораздо более портативными и не позволяет никому вносить изменения в конфигурацию на уровне ОС. Мы приняли для ячеек философию «инфраструктура как код»: в наш репозиторий исходного кода мы включаем определения всего, что находится в ячейке, чтобы мы могли быстро перестроить его с нуля с помощью автоматизированных инструментов.
В настоящее время не все сервисы соответствуют этим требованиям, поэтому мы постарались помочь владельцам сервисов удовлетворить их, где это возможно, и создали новые инструменты, упрощающие миграцию сервисов в ячейки, когда они будут готовы. Например, наш новый инструмент развертывания автоматически распределяет развертывание службы по ячейкам, поэтому владельцам служб не нужно думать о стратегии репликации. Такой уровень строгости делает процесс миграции намного более сложным и трудоемким, но в долгосрочной перспективе результатом будет система, в которой:
- Гораздо проще сдержать сбой и предотвратить его распространение на другие ячейки;
- Наши инженеры по инфраструктуре могут работать более эффективно и действовать быстрее; и
- Инженерам, создающим сервисы уровня продукта, которые в конечном итоге развертываются в ячейках, не нужно знать или беспокоиться о том, в каких ячейках работают их сервисы.
Решение больших задач
Подобно тому, как противопожарные двери используются для сдерживания пламени, ячейки действуют как прочные противовзрывные стены в нашей инфраструктуре, помогая сдержать любую проблему, вызывающую сбой в одной ячейке. В конце концов, все сервисы, составляющие Roblox, будут дублированы внутри ячеек и между ними. После завершения этой работы проблемы могут распространиться достаточно широко, чтобы вывести из строя всю ячейку, но проблеме будет чрезвычайно трудно распространиться за пределы этой ячейки. И если нам удастся сделать клетки взаимозаменяемыми, восстановление будет значительно быстрее. потому что мы сможем выполнить аварийное переключение на другую ячейку и не допустить воздействия проблемы на конечных пользователей.
Сложность заключается в том, чтобы разделить эти ячейки настолько, чтобы уменьшить возможность распространения ошибок, сохраняя при этом производительность и функциональность. В сложной инфраструктурной системе сервисы должны взаимодействовать друг с другом для обмена запросами, информацией, рабочими нагрузками и т. д. Поскольку мы тиражируем эти сервисы в ячейки, нам необходимо подумать о том, как мы управляем перекрестной связью. В идеальном мире мы перенаправляем трафик от одной нездоровой ячейки к другой здоровой. Но как нам справиться с «запросом смерти»? Причинение клетка быть нездоровой? Если мы перенаправим этот запрос в другую ячейку, это может привести к тому, что эта ячейка станет неработоспособной, чего мы и пытаемся избежать. Нам необходимо найти механизмы для перемещения «хорошего» трафика от нездоровых ячеек, одновременно обнаруживая и подавляя трафик, который приводит к тому, что ячейки становятся неработоспособными.
В краткосрочной перспективе мы развернули копии вычислительных сервисов в каждой вычислительной ячейке, чтобы большинство запросов к центру обработки данных могло обслуживаться одной ячейкой. Мы также балансируем нагрузку трафика между ячейками. Заглядывая в будущее, мы начали создавать процесс обнаружения сервисов следующего поколения, который будет использоваться сервисной сеткой, и мы надеемся завершить его в 2024 году. Это позволит нам реализовать сложные политики, которые позволят осуществлять межсотовую связь только тогда, когда это не окажет негативного влияния на ячейки аварийного переключения. Также в 2024 году появится метод направления зависимых запросов к версии сервиса в одной и той же соте, что позволит минимизировать межсотовый трафик и тем самым снизить риск распространения сбоев между ячейками.
В пиковые периоды более 70 процентов трафика наших серверных сервисов обслуживается из ячеек, и мы много узнали о том, как создавать ячейки, но мы ожидаем дополнительных исследований и испытаний по мере того, как мы продолжим миграцию наших услуг до 2024 года и вне. По мере нашего продвижения эти взрывные стены будут становиться все сильнее.
Миграция постоянно доступной инфраструктуры
Roblox — это глобальная платформа, поддерживающая пользователей по всему миру, поэтому мы не можем перемещать сервисы в непиковое время или во время простоя, что еще больше усложняет процесс миграции всех наших машин в ячейки и запуска наших сервисов в этих ячейках. . У нас есть миллионы постоянно доступных приложений, которые необходимо продолжать поддерживать, даже когда мы перемещаем машины, на которых они работают, и службы, которые их поддерживают. Когда мы начали этот процесс, у нас не было десятков тысяч компьютеров, которые просто стояли без дела и были доступны для переноса этих рабочих нагрузок.
Однако у нас было небольшое количество дополнительных машин, которые были приобретены в ожидании будущего роста. Для начала мы построили новые ячейки, используя эти машины, а затем перенесли на них рабочие нагрузки. Мы ценим эффективность и надежность, поэтому вместо того, чтобы покупать больше машин, когда у нас заканчиваются «запасные» машины, мы построили больше ячеек, очистив и повторно подготовив машины, с которых мы мигрировали. Затем мы перенесли рабочие нагрузки на эти повторно подготовленные машины и начали процесс заново. Этот процесс сложен: по мере того, как машины заменяются и освобождаются для встраивания в клетки, они не освобождаются идеальным и упорядоченным образом. Они физически фрагментированы по залам данных, поэтому нам приходится предоставлять их по частям, что требует процесса дефрагментации на аппаратном уровне, чтобы обеспечить соответствие расположения оборудования крупномасштабным областям физических сбоев.
Часть нашей команды по проектированию инфраструктуры сосредоточена на переносе существующих рабочих нагрузок из нашей устаревшей или «досотовой» среды в ячейки. Эта работа будет продолжаться до тех пор, пока мы не перенесем тысячи различных инфраструктурных сервисов и тысячи серверных сервисов в новые ячейки. Мы ожидаем, что это займет весь следующий год и, возможно, вплоть до 2025 года из-за некоторых осложняющих факторов. Во-первых, эта работа требует создания надежных инструментов. Например, нам нужны инструменты для автоматической перебалансировки большого количества сервисов при развертывании новой ячейки, не влияя при этом на наших пользователей. Мы также видели сервисы, созданные с учетом предположений о нашей инфраструктуре. Нам необходимо пересмотреть эти услуги, чтобы они не зависели от вещей, которые могут измениться в будущем по мере нашего перехода в клетки. Мы также реализовали как способ поиска известных шаблонов проектирования, которые не будут хорошо работать с сотовой архитектурой, так и методический процесс тестирования для каждой мигрируемой службы. Эти процессы помогают нам предотвратить любые проблемы, с которыми сталкиваются пользователи, вызванные несовместимостью службы с ячейками.
Сегодня около 30,000 99.99 машин управляются ячейками. Это лишь малая часть нашего общего парка, но до сих пор переход прошел очень гладко и без каких-либо негативных последствий для игроков. Наша конечная цель — обеспечить бесперебойную работу наших систем на 0.01% каждый месяц, то есть мы будем нарушать не более XNUMX% часов взаимодействия. В масштабах всей отрасли время простоя невозможно полностью устранить, но наша цель — сократить время простоя Roblox до такой степени, чтобы оно стало почти незаметным.
Готовность к будущему по мере масштабирования
Хотя наши первые усилия оказались успешными, наша работа над клетками еще далека от завершения. Поскольку Roblox продолжает масштабироваться, мы продолжим работать над повышением эффективности и отказоустойчивости наших систем с помощью этой и других технологий. По мере продвижения платформа будет становиться все более устойчивой к проблемам, и любые возникающие проблемы должны становиться все менее заметными и разрушительными для людей на нашей платформе.
Подводя итоги, на сегодняшний день мы имеем:
- Построил второй дата-центр и успешно достиг активного/пассивного статуса.
- Создали ячейки в наших активных и пассивных центрах обработки данных и успешно перенесли в эти ячейки более 70 процентов трафика наших серверных услуг.
- Установите требования и передовые методы, которым нам нужно будет следовать, чтобы обеспечить единообразие всех ячеек по мере продолжения миграции остальной части нашей инфраструктуры.
- Начался непрерывный процесс строительства более прочных «взрывных стен» между камерами.
Поскольку эти ячейки станут более взаимозаменяемыми, между ячейками будет меньше перекрестных помех. Это открывает для нас некоторые очень интересные возможности с точки зрения повышения автоматизации мониторинга, устранения неполадок и даже автоматического переключения рабочих нагрузок.
В сентябре мы также начали проводить активные/активные эксперименты в наших центрах обработки данных. Это еще один механизм, который мы тестируем для повышения надежности и минимизации времени переключения при сбое. Эти эксперименты помогли выявить ряд шаблонов проектирования систем, в основном связанных с доступом к данным, которые нам необходимо переработать, поскольку мы стремимся стать полностью активными. В целом эксперимент оказался достаточно успешным, чтобы его можно было использовать для трафика ограниченного числа наших пользователей.
Мы рады продолжать эту работу, чтобы повысить эффективность и отказоустойчивость платформы. Эта работа над сотами и активно-активной инфраструктурой, наряду с другими нашими усилиями, позволит нам превратиться в надежную, высокопроизводительную утилиту для миллионов людей и продолжать масштабироваться, пока мы работаем над тем, чтобы соединить миллиарды людей в реальном времени. время.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://blog.roblox.com/2023/12/making-robloxs-infrastructure-efficient-resilient/
- :имеет
- :является
- :нет
- :куда
- $UP
- 000
- 01
- 1
- 125
- 2021
- 2022
- 2023
- 2024
- 2025
- 30
- 36
- 3d
- 400
- 70
- a
- способность
- в состоянии
- О нас
- доступ
- Достигать
- достигнутый
- через
- Действие (Act):
- действующий
- активный
- добавленный
- дополнительный
- адрес
- принял
- снова
- агрессивно
- выровненный
- Все
- позволять
- в одиночестве
- вдоль
- уже
- причислены
- an
- и
- Другой
- предвидеть
- ожидание
- любой
- кто угодно
- примерно
- архитектура
- МЫ
- около
- AS
- предположения
- At
- Автоматизированный
- автоматически
- автоматизация
- доступен
- Аватары
- избежать
- Back-конец
- Восстановление
- стабилизатор
- Балансировка
- основанный
- BE
- , так как:
- становиться
- становится
- становление
- было
- до
- начал
- не являетесь
- польза
- ЛУЧШЕЕ
- лучшие практики
- между
- Beyond
- большой
- больший
- миллиард
- Блог
- изоферменты печени
- приносить
- принес
- ошибки
- строить
- Строительство
- построенный
- бизнес
- но
- покупка
- by
- призывают
- CAN
- не могу
- Пропускная способность
- случаев
- Вызывать
- вызванный
- Причинение
- ячейка
- Клетки
- сотовый
- Центр
- Центры
- определенный
- сложные
- изменение
- изменения
- Закрыть
- облако
- облачная инфраструктура
- код
- как
- приход
- Общий
- общаться
- общение
- Связь
- Компании
- сравненный
- полный
- полностью
- комплекс
- сложность
- компонент
- компоненты
- Вычисление
- вычисление
- Конференция
- Конфигурация
- Свяжитесь
- связи
- содержать
- содержит
- продолжать
- продолжается
- (CIJ)
- контроль
- копии
- Расходы
- может
- Создайте
- Создающий
- Создатели
- В настоящее время
- Изготовленный на заказ
- ежедневно
- данным
- доступ к данным
- Центр обработки данных
- центров обработки данных
- Время
- день
- определение
- Степень
- задержки
- зависеть
- зависимый
- развертывание
- развернуть
- развертывание
- Проект
- шаблоны проектирования
- DID
- различный
- трудный
- руководство
- открытие
- срывать
- подрывной
- распределительный
- do
- приносит
- дело
- доменов
- сделанный
- Dont
- Двери
- вниз
- время простоя
- вождение
- два
- в течение
- каждый
- Рано
- легче
- легко
- затрат
- эффективный
- эффективно
- усилия
- устранен
- позволяет
- конец
- обязательство
- Проект и
- Инженеры
- достаточно
- обеспечивать
- Весь
- полностью
- Окружающая среда
- ошибка
- ошибки
- по существу
- и т.д
- Даже
- со временем
- Каждая
- многое
- пример
- возбужденный
- существующий
- ожидать
- опытные
- Впечатления
- эксперимент
- Эксперименты
- экстремальный
- чрезвычайно
- факторы
- FAIL
- отсутствии
- не удается
- Ошибка
- сбои
- достаточно
- далеко
- Фэшн
- быстрее
- Найдите
- Для пожарных
- Во-первых,
- ФЛОТ
- Фокус
- внимание
- следовать
- Что касается
- вперед
- доля
- фрагментированный
- Бесплатно
- частое
- от
- полный
- полностью
- функциональная
- далее
- будущее
- будущий рост
- в общем
- географический
- получить
- получающий
- данный
- Глобальный
- ГЛОБАЛЬНО
- Go
- цель
- идет
- будет
- большой
- группы
- Расти
- взрослый
- Рост
- было
- Половина
- обрабатывать
- Управляемость
- происходить
- Жесткий
- Аппаратные средства
- Есть
- Медицина
- здоровый
- помощь
- помог
- High
- высший
- надежды
- ЧАСЫ
- Как
- How To
- Однако
- HTTPS
- Людей
- Гибридный
- идеальный
- определения
- if
- погружение
- Влияние
- воздействуя
- осуществлять
- в XNUMX году
- улучшать
- in
- включают
- В том числе
- несовместимый
- Увеличение
- повышение
- все больше и больше
- individual
- промышленность
- информация
- Инфраструктура
- внутри
- пример
- случаев
- мгновенно
- интересный
- в нашей внутренней среде,
- в
- вопрос
- вопросы
- IT
- июнь
- всего
- Сохранить
- хранение
- Знать
- известный
- большой
- крупномасштабный
- в значительной степени
- Задержка
- узнали
- Оставлять
- уход
- Наследие
- Меньше
- позволять
- уровень
- заемные средства
- такое как
- Ограниченный
- загрузка
- расположенный
- места
- долгосрочный
- дольше
- искать
- серия
- Низкий
- машина
- Продукция
- поддерживать
- сделать
- ДЕЛАЕТ
- Создание
- управлять
- управляемого
- вручную
- многих
- макс-ширина
- значить
- смысл
- механизм
- механизмы
- Встречайте
- сетке
- метод
- методический
- может быть
- мигрировать
- мигрировали
- мигрирующий
- миграция
- миллиона
- миллионы
- минимизировать
- небольшая
- ошибки
- Мониторинг
- Месяц
- БОЛЕЕ
- более эффективным
- самых
- двигаться
- много
- с разными
- должен
- природа
- почти
- Необходимость
- необходимый
- отрицательный
- отрицательно
- сеть
- Новые
- вновь
- следующий
- следующее поколение
- нет
- сейчас
- номер
- номера
- происходить
- октябрь
- of
- от
- on
- консолидировать
- ONE
- постоянный
- только
- Возможности
- Возможность
- or
- OS
- Другое
- Другое
- наши
- внешний
- перебой в работе
- Отключения
- за
- общий
- Владельцы
- часть
- пассивный
- мимо
- паттеранами
- платить
- Вершина горы
- Люди
- для
- процент
- выполнения
- настойчиво
- человек
- философия
- физический
- Физически
- выбирать
- Часть
- Платформа
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- игрок
- сборах
- портативный
- часть
- возможность
- возможное
- возможно
- потенциально
- практиками
- предотвращать
- предотвращает
- в первую очередь
- приоритет
- частная
- процесс
- Процессы
- Прогресс
- постепенно
- распространение
- защиту
- доказывания
- обеспечение
- купленный
- Push
- Запросы
- вопрос
- быстро
- скорее
- готовый
- реальные
- реального времени
- восстановить равновесие
- выздоровление
- переориентировать
- уменьшить
- область
- надежность
- складская
- полагаться
- ремонт
- заменить
- копирование
- хранилище
- Запросы
- Требования
- требуется
- исследованиям
- упругость
- упругий
- решение
- ОТДЫХ
- результат
- привело
- пересматривать
- Снижение
- Roblox
- надежный
- Run
- Бег
- работает
- безопасно
- то же
- сохраняются
- Шкала
- сценарий
- поцарапать
- Поиск
- Во-вторых
- видел
- отделяющий
- сентябрь
- служил
- обслуживание
- Услуги
- выступающей
- набор
- несколько
- Поделиться
- общие
- разделение
- сдвиг
- СДВИГАЯ
- Короткое
- должен
- существенно
- с
- одинарной
- Сидящий
- небольшой
- сгладить
- So
- уже
- Software
- некоторые
- удалось
- сложный
- Источник
- исходный код
- Space
- шипы
- распространение
- Распространение
- Начало
- и политические лидеры
- начинается
- Статус:
- По-прежнему
- Стратегия
- сильный
- сильнее
- изучение
- быть успешными
- успешный
- Успешно
- РЕЗЮМЕ
- поддержка
- Поддержанный
- поддержки
- Поддержка
- система
- системы
- взять
- приняты
- команда
- Технический
- технологии
- десятки
- срок
- terms
- Тестирование
- текст
- чем
- который
- Ассоциация
- Будущее
- мир
- их
- Их
- тогда
- Там.
- тем самым
- Эти
- они
- вещи
- think
- этой
- те
- тысячи
- Через
- по всему
- время
- раз
- в
- сегодня
- вместе
- терпимость
- слишком
- инструментом
- инструменты
- Всего
- к
- трафик
- переход
- срабатывание
- пытается
- два
- Типы
- окончательный
- В конечном счете
- отпирает
- до
- неиспользованный
- на
- Провел на сайте
- us
- используемый
- Информация о пользователе
- пользователей
- через
- утилита
- ценностное
- версия
- очень
- видимый
- видение
- хотеть
- законопроект
- Путь..
- we
- Погода
- ЧТО Ж
- были
- Что
- любой
- когда
- который
- в то время как
- КТО
- широкий
- будете
- вытирание
- в
- Работа
- работавший
- работает
- Мир
- беспокоиться
- бы
- год
- лет
- зефирнет