Организации во всех отраслях предъявляют сложные требования к обработке данных для своих аналитических вариантов использования в различных аналитических системах, таких как озера данных на AWS, хранилища данных (Амазонка Redshift), поиск (Сервис Amazon OpenSearch), NoSQL (Amazon DynamoDB), машинное обучение (Создатель мудреца Амазонки), и более. Перед профессионалами в области аналитики стоит задача извлечь выгоду из данных, хранящихся в этих распределенных системах, для создания лучшего, безопасного и оптимизированного по стоимости опыта для своих клиентов. Например, компании, занимающиеся цифровыми медиа, стремятся объединять и обрабатывать наборы данных во внутренних и внешних базах данных, чтобы создавать унифицированные представления своих профилей клиентов, стимулировать идеи для инновационных функций и повышать вовлеченность платформы.
В этих сценариях клиенты, которым требуется бессерверное решение для интеграции данных, используют Клей AWS в качестве основного компонента для обработки и каталогизации данных. AWS Glue хорошо интегрирован с сервисами AWS и партнерскими продуктами и предоставляет возможности извлечения, преобразования и загрузки (ETL) с минимальным/отсутствием кода для включения аналитики, машинного обучения (ML) или рабочих процессов разработки приложений. Задания AWS Glue ETL могут быть одним из компонентов более сложного конвейера. Организация выполнения и управление зависимостями между этими компонентами является ключевой возможностью в стратегии данных. Управляемые рабочие процессы Amazon для Apache Airflows (Amazon MWAA) организует конвейеры данных с использованием распределенных технологий, включая локальные ресурсы, сервисы AWS и сторонние компоненты.
В этом посте мы покажем, как упростить мониторинг задания AWS Glue, организованного Airflow, с помощью новейших функций Amazon MWAA.
Обзор решения
В этом посте обсуждается следующее:
- Как обновить среду Amazon MWAA до версии 2.4.3.
- Как организовать задание AWS Glue из Airflow Направленный ациклический график (ДАГ).
- Улучшения наблюдаемости пакета провайдера Airflow Amazon в Amazon MWAA. Теперь вы можете консолидировать журналы выполнения заданий AWS Glue в консоли Airflow, чтобы упростить устранение неполадок с конвейерами данных. Консоль Amazon MWAA становится единой ссылкой для мониторинга и анализа выполнения заданий AWS Glue. Раньше группам поддержки требовался доступ к Консоль управления AWS и выполните ручные шаги для этой видимости. Эта функция по умолчанию доступна в Amazon MWAA версии 2.4.3.
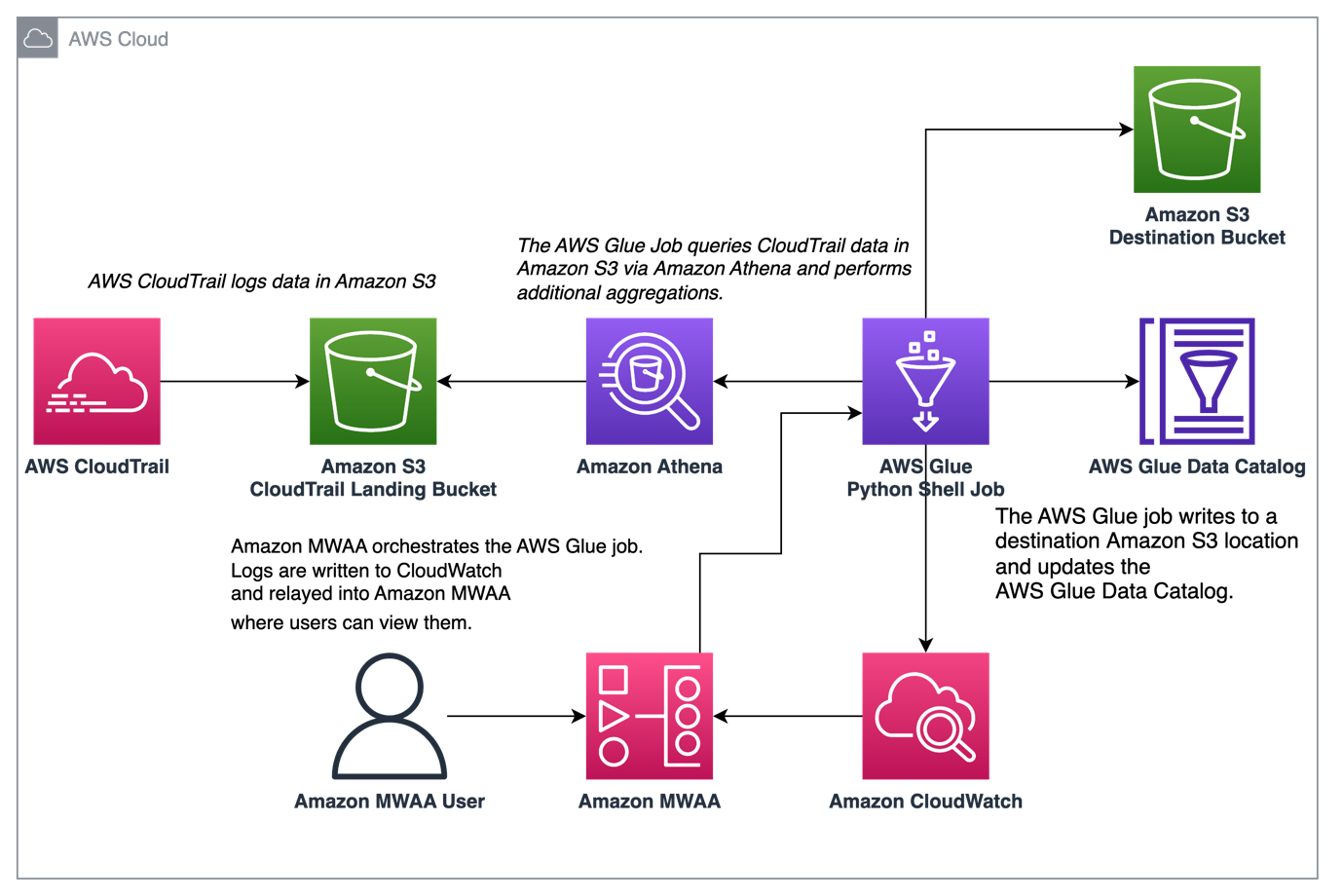
На следующей диаграмме показана архитектура нашего решения.
Предпосылки
Вам необходимы следующие предпосылки:
Настройка среды Amazon MWAA
Инструкции по созданию среды см. Создайте среду Amazon MWAA. Существующим пользователям мы рекомендуем обновиться до версии 2.4.3, чтобы воспользоваться улучшениями наблюдаемости, описанными в этом посте.
Действия по обновлению Amazon MWAA до версии 2.4.3 различаются в зависимости от текущей версии: 1.10.12 или 2.2.2. Оба варианта мы обсудим в этом посте.
Предварительные условия для настройки среды Amazon MWAA
Вы должны соответствовать следующим требованиям:
Обновление с версии 1.10.12 до 2.4.3
Если вы используете версию Amazon MWAA 1.10.12, Ссылаться на Миграция в новую среду Amazon MWAA для обновления до 2.4.3.
Обновление с версии 2.0.2 или 2.2.2 до 2.4.3
Если вы используете среду Amazon MWAA версии 2.2.2 или более ранней, выполните следующие действия:
- Создайте requirements.txt для любых пользовательских зависимостей с конкретными версиями, необходимыми для ваших DAG.
- Загрузите файл на Amazon S3 в соответствующем месте, где среда Amazon MWAA указывает на файл requirements.txt для установки зависимостей.
- Следуйте инструкциям в Миграция в новую среду Amazon MWAA и выберите версию 2.4.3.
Обновите свои DAG
Клиентам, которые обновили старую среду Amazon MWAA, может потребоваться обновить существующие группы обеспечения доступности баз данных. В Airflow версии 2.4.3 среда Airflow будет использовать пакет провайдера Amazon версии 6.0.0 по умолчанию. Этот пакет может включать в себя некоторые потенциально критические изменения, такие как изменения в именах операторов. Например, AWSGlueJobOperator устарела и заменена на Оператор GlueJob. Для обеспечения совместимости обновите свои группы обеспечения доступности баз данных Airflow, заменив все устаревшие или неподдерживаемые операторы из предыдущих версий новыми. Выполните следующие шаги:
- Перейдите в Операторы Amazon AWS.
- Выберите соответствующую версию, установленную в вашем экземпляре Amazon MWAA (по умолчанию 6.0.0), чтобы найти список поддерживаемых операторов Airflow.
- Внесите необходимые изменения в существующий код DAG и загрузите измененные файлы в папку DAG в Amazon S3.
Оркестрация задания AWS Glue из Airflow
В этом разделе описываются подробности организации задания AWS Glue в группах обеспечения доступности баз данных Airflow. Airflow упрощает разработку конвейеров данных с зависимостями между разнородными системами, такими как локальные процессы, внешние зависимости, другие сервисы AWS и т. д.
Агрегация журналов CloudTrail с помощью AWS Glue и Amazon MWAA
В этом примере мы рассмотрим вариант использования Amazon MWAA для организации задания AWS Glue Python Shell, которое сохраняет агрегированные показатели на основе журналов CloudTrail.
CloudTrail обеспечивает видимость вызовов API AWS, которые выполняются в вашей учетной записи AWS. Обычный вариант использования этих данных — сбор показателей использования принципалов, действующих на ресурсах вашей учетной записи, для целей аудита и нормативных требований.
Поскольку события CloudTrail регистрируются, они доставляются в виде файлов JSON в Amazon S3, что не идеально подходит для аналитических запросов. Мы хотим агрегировать эти данные и сохранить их в виде файлов Parquet, чтобы обеспечить оптимальную производительность запросов. В качестве начального шага мы можем использовать Athena для первоначального запроса данных перед выполнением дополнительных агрегаций в нашем задании AWS Glue. Дополнительные сведения о создании таблицы каталога данных AWS Glue см. Создание таблицы для журналов CloudTrail в Athena с использованием проекции разделов данные. После того, как мы изучили данные с помощью Athena и решили, какие показатели мы хотим сохранить в агрегированных таблицах, мы можем создать задание AWS Glue.
Создайте таблицу CloudTrail в Athena
Во-первых, нам нужно создать таблицу в нашем каталоге данных, которая позволит запрашивать данные CloudTrail через Athena. Следующий пример запроса создает таблицу с двумя разделами по региону и дате (называется snapshot_date). Обязательно замените заполнители для корзины CloudTrail, идентификатора учетной записи AWS и имени таблицы CloudTrail:
create external table if not exists `<<<CLOUDTRAIL_TABLE_NAME>>>`( `eventversion` string comment 'from deserializer', `useridentity` struct<type:string,principalid:string,arn:string,accountid:string,invokedby:string,accesskeyid:string,username:string,sessioncontext:struct<attributes:struct<mfaauthenticated:string,creationdate:string>,sessionissuer:struct<type:string,principalid:string,arn:string,accountid:string,username:string>>> comment 'from deserializer', `eventtime` string comment 'from deserializer', `eventsource` string comment 'from deserializer', `eventname` string comment 'from deserializer', `awsregion` string comment 'from deserializer', `sourceipaddress` string comment 'from deserializer', `useragent` string comment 'from deserializer', `errorcode` string comment 'from deserializer', `errormessage` string comment 'from deserializer', `requestparameters` string comment 'from deserializer', `responseelements` string comment 'from deserializer', `additionaleventdata` string comment 'from deserializer', `requestid` string comment 'from deserializer', `eventid` string comment 'from deserializer', `resources` array<struct<arn:string,accountid:string,type:string>> comment 'from deserializer', `eventtype` string comment 'from deserializer', `apiversion` string comment 'from deserializer', `readonly` string comment 'from deserializer', `recipientaccountid` string comment 'from deserializer', `serviceeventdetails` string comment 'from deserializer', `sharedeventid` string comment 'from deserializer', `vpcendpointid` string comment 'from deserializer')
PARTITIONED BY ( `region` string, `snapshot_date` string)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde' STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/'
TBLPROPERTIES ( 'projection.enabled'='true', 'projection.region.type'='enum', 'projection.region.values'='us-east-2,us-east-1,us-west-1,us-west-2,af-south-1,ap-east-1,ap-south-1,ap-northeast-3,ap-northeast-2,ap-southeast-1,ap-southeast-2,ap-northeast-1,ca-central-1,eu-central-1,eu-west-1,eu-west-2,eu-south-1,eu-west-3,eu-north-1,me-south-1,sa-east-1', 'projection.snapshot_date.format'='yyyy/mm/dd', 'projection.snapshot_date.interval'='1', 'projection.snapshot_date.interval.unit'='days', 'projection.snapshot_date.range'='2020/10/01,now', 'projection.snapshot_date.type'='date', 'storage.location.template'='s3://<<<CLOUDTRAIL_BUCKET>>>/AWSLogs/<<<ACCOUNT_ID>>>/CloudTrail/${region}/${snapshot_date}')Запустите предыдущий запрос в консоли Athena и запишите имя таблицы и базу данных каталога данных AWS Glue, в которой она была создана. Мы используем эти значения позже в коде Airflow DAG.
Пример кода задания AWS Glue
Следующий код является образцом Вакансия AWS Glue Python Shell что делает следующее:
- Принимает аргументы (которые мы передаем от нашей группы DAG Amazon MWAA) о том, какие данные дня обрабатывать.
- Использует SDK AWS для панд запустить запрос Athena для начальной фильтрации данных CloudTrail JSON вне AWS Glue
- Использует Pandas для простой агрегации отфильтрованных данных.
- Выводит агрегированные данные в каталог данных AWS Glue в виде таблицы.
- Использует ведение журнала во время обработки, которое будет видно в Amazon MWAA.
import awswrangler as wr
import pandas as pd
import sys
import logging
from awsglue.utils import getResolvedOptions
from datetime import datetime, timedelta # Logging setup, redirects all logs to stdout
LOGGER = logging.getLogger()
formatter = logging.Formatter('%(asctime)s.%(msecs)03d %(levelname)s %(module)s - %(funcName)s: %(message)s')
streamHandler = logging.StreamHandler(sys.stdout)
streamHandler.setFormatter(formatter)
LOGGER.addHandler(streamHandler)
LOGGER.setLevel(logging.INFO) LOGGER.info(f"Passed Args :: {sys.argv}") sql_query_template = """
select
region,
useridentity.arn,
eventsource,
eventname,
useragent from "{cloudtrail_glue_db}"."{cloudtrail_table}"
where snapshot_date='{process_date}'
and region in ('us-east-1','us-east-2') """ required_args = ['CLOUDTRAIL_GLUE_DB', 'CLOUDTRAIL_TABLE', 'TARGET_BUCKET', 'TARGET_DB', 'TARGET_TABLE', 'ACCOUNT_ID']
arg_keys = [*required_args, 'PROCESS_DATE'] if '--PROCESS_DATE' in sys.argv else required_args
JOB_ARGS = getResolvedOptions ( sys.argv, arg_keys) LOGGER.info(f"Parsed Args :: {JOB_ARGS}") # if process date was not passed as an argument, process yesterday's data
process_date = ( JOB_ARGS['PROCESS_DATE'] if JOB_ARGS.get('PROCESS_DATE','NONE') != "NONE" else (datetime.today() - timedelta(days=1)).strftime("%Y-%m-%d") ) LOGGER.info(f"Taking snapshot for :: {process_date}") RAW_CLOUDTRAIL_DB = JOB_ARGS['CLOUDTRAIL_GLUE_DB']
RAW_CLOUDTRAIL_TABLE = JOB_ARGS['CLOUDTRAIL_TABLE']
TARGET_BUCKET = JOB_ARGS['TARGET_BUCKET']
TARGET_DB = JOB_ARGS['TARGET_DB']
TARGET_TABLE = JOB_ARGS['TARGET_TABLE']
ACCOUNT_ID = JOB_ARGS['ACCOUNT_ID'] final_query = sql_query_template.format( process_date=process_date.replace("-","/"), cloudtrail_glue_db=RAW_CLOUDTRAIL_DB, cloudtrail_table=RAW_CLOUDTRAIL_TABLE
) LOGGER.info(f"Running Query :: {final_query}") raw_cloudtrail_df = wr.athena.read_sql_query( sql=final_query, database=RAW_CLOUDTRAIL_DB, ctas_approach=False, s3_output=f"s3://{TARGET_BUCKET}/athena-results",
) raw_cloudtrail_df['ct']=1 agg_df = raw_cloudtrail_df.groupby(['arn','region','eventsource','eventname','useragent'],as_index=False).agg({'ct':'sum'})
agg_df['snapshot_date']=process_date LOGGER.info(agg_df.info(verbose=True)) upload_path = f"s3://{TARGET_BUCKET}/{TARGET_DB}/{TARGET_TABLE}" if not agg_df.empty: LOGGER.info(f"Upload to {upload_path}") try: response = wr.s3.to_parquet( df=agg_df, path=upload_path, dataset=True, database=TARGET_DB, table=TARGET_TABLE, mode="overwrite_partitions", schema_evolution=True, partition_cols=["snapshot_date"], compression="snappy", index=False ) LOGGER.info(response) except Exception as exc: LOGGER.error("Uploading to S3 failed") LOGGER.exception(exc) raise exc
else: LOGGER.info(f"Dataframe was empty, nothing to upload to {upload_path}")
Ниже приведены некоторые ключевые преимущества этой работы AWS Glue:
- Мы используем запрос Athena, чтобы гарантировать, что первоначальная фильтрация выполняется вне нашего задания AWS Glue. Таким образом, задания Python Shell с минимальными вычислительными затратами по-прежнему достаточно для агрегирования большого набора данных CloudTrail.
- Мы гарантируем опция установки библиотеки аналитики включен при создании нашего задания AWS Glue для использования библиотеки AWS SDK для Pandas.
Создание задания AWS Glue
Выполните следующие шаги, чтобы создать задание AWS Glue:
- Скопируйте сценарий из предыдущего раздела и сохраните его в локальном файле. Для этого поста файл называется
script.py. - На консоли AWS Glue выберите ETL-задания в навигационной панели.
- Создайте новое задание и выберите Редактор скриптов Python Shell.
- Выберите Загрузите и отредактируйте существующий скрипт и загрузите файл, который вы сохранили локально.
- Выберите Создавай.

- На Детали работы введите имя для задания AWS Glue.
- Что касается Роль IAM, выберите существующую роль или создайте новую роль с необходимыми разрешениями для Amazon S3, AWS Glue и Athena. Роль должна запросить созданную ранее таблицу CloudTrail и записать ее в выходное расположение.
Вы можете использовать следующий образец кода политики. Замените заполнители своей корзиной журналов CloudTrail, именем выходной таблицы, выходной базой данных AWS Glue, выходной корзиной S3, именем таблицы CloudTrail, базой данных AWS Glue, содержащей таблицу CloudTrail, и идентификатором вашей учетной записи AWS.
{ "Version": "2012-10-17", "Statement": [ { "Action": [ "s3:List*", "s3:Get*" ], "Resource": [ "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>/*", "arn:aws:s3:::<<<CLOUDTRAIL_LOGS_BUCKET>>>*" ], "Effect": "Allow", "Sid": "GetS3CloudtrailData" }, { "Action": [ "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>/<<<CLOUDTRAIL_TABLE>>>*" ], "Effect": "Allow", "Sid": "GetGlueCatalogCloudtrailData" }, { "Action": [ "s3:PutObject*", "s3:Abort*", "s3:DeleteObject*", "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:Head*" ], "Resource": [ "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>", "arn:aws:s3:::<<<OUTPUT_S3_BUCKET>>>/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>/*" ], "Effect": "Allow", "Sid": "WriteOutputToS3" }, { "Action": [ "glue:CreateTable", "glue:CreatePartition", "glue:UpdatePartition", "glue:UpdateTable", "glue:DeleteTable", "glue:DeletePartition", "glue:BatchCreatePartition", "glue:BatchDeletePartition", "glue:Get*", "glue:BatchGet*" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:database/<<<OUTPUT_GLUE_DB>>>", "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:table/<<<OUTPUT_GLUE_DB>>>/<<<OUTPUT_TABLE_NAME>>>*" ], "Effect": "Allow", "Sid": "AllowOutputToGlue" }, { "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:/aws-glue/*", "Effect": "Allow", "Sid": "LogsAccess" }, { "Action": [ "s3:GetObject*", "s3:GetBucket*", "s3:List*", "s3:DeleteObject*", "s3:PutObject", "s3:PutObjectLegalHold", "s3:PutObjectRetention", "s3:PutObjectTagging", "s3:PutObjectVersionTagging", "s3:Abort*" ], "Resource": [ "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>", "arn:aws:s3:::<<<ATHENA_RESULTS_BUCKET>>>/*" ], "Effect": "Allow", "Sid": "AccessToAthenaResults" }, { "Action": [ "athena:StartQueryExecution", "athena:StopQueryExecution", "athena:GetDataCatalog", "athena:GetQueryResults", "athena:GetQueryExecution" ], "Resource": [ "arn:aws:glue:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:catalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:datacatalog/AwsDataCatalog", "arn:aws:athena:us-east-1:<<<YOUR_AWS_ACCT_ID>>>:workgroup/primary" ], "Effect": "Allow", "Sid": "AllowAthenaQuerying" } ]
}
Что касается Версия Python, выберите Python 3.9.
- Выберите Загрузить общие библиотеки аналитики.
- Что касается Блоки обработки данных, выберите 1 ДПУ.
- Остальные параметры оставьте по умолчанию или настройте по мере необходимости.

- Выберите Сохранить чтобы сохранить конфигурацию задания.
Настройте группу обеспечения доступности баз данных Amazon MWAA для управления заданием AWS Glue.
Следующий код предназначен для группы обеспечения доступности баз данных, которая может организовать созданное нами задание AWS Glue. Мы используем следующие ключевые особенности этой DAG:
"""Sample DAG"""
import airflow.utils
from airflow.providers.amazon.aws.operators.glue import GlueJobOperator
from airflow import DAG
from datetime import timedelta
import airflow.utils # allow backfills via DAG run parameters
process_date = '{{ dag_run.conf.get("process_date") if dag_run.conf.get("process_date") else "NONE" }}' dag = DAG( dag_id = "CLOUDTRAIL_LOGS_PROCESSING", default_args = { 'depends_on_past':False, 'start_date':airflow.utils.dates.days_ago(0), 'retries':1, 'retry_delay':timedelta(minutes=5), 'catchup': False }, schedule_interval = None, # None for unscheduled or a cron expression - E.G. "00 12 * * 2" - at 12noon Tuesday dagrun_timeout = timedelta(minutes=30), max_active_runs = 1, max_active_tasks = 1 # since there is only one task in our DAG
) ## Log ingest. Assumes Glue Job is already created
glue_ingestion_job = GlueJobOperator( task_id="<<<some-task-id>>>", job_name="<<<GLUE_JOB_NAME>>>", script_args={ "--ACCOUNT_ID":"<<<YOUR_AWS_ACCT_ID>>>", "--CLOUDTRAIL_GLUE_DB":"<<<GLUE_DB_WITH_CLOUDTRAIL_TABLE>>>", "--CLOUDTRAIL_TABLE":"<<<CLOUDTRAIL_TABLE>>>", "--TARGET_BUCKET": "<<<OUTPUT_S3_BUCKET>>>", "--TARGET_DB": "<<<OUTPUT_GLUE_DB>>>", # should already exist "--TARGET_TABLE": "<<<OUTPUT_TABLE_NAME>>>", "--PROCESS_DATE": process_date }, region_name="us-east-1", dag=dag, verbose=True
) glue_ingestion_job
Повышение наблюдаемости заданий AWS Glue в Amazon MWAA
Задания AWS Glue записывают журналы в Amazon CloudWatch. Благодаря недавним улучшениям в плане наблюдаемости в пакете Airflow Amazon provider эти журналы теперь интегрированы с журналами задач Airflow. Эта консолидация предоставляет пользователям Airflow сквозную видимость непосредственно в пользовательском интерфейсе Airflow, устраняя необходимость поиска в CloudWatch или консоли AWS Glue.
Чтобы использовать эту функцию, убедитесь, что роль IAM, прикрепленная к среде Amazon MWAA, имеет следующие разрешения на получение и запись необходимых журналов:
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents", "logs:GetLogEvents", "logs:GetLogRecord", "logs:DescribeLogStreams", "logs:FilterLogEvents", "logs:GetLogGroupFields", "logs:GetQueryResults", ], "Resource": [ "arn:aws:logs:*:*:log-group:airflow-243-<<<Your environment name>>>-*"--Your Amazon MWAA Log Stream Name ] } ]
}Если verbose=true, журналы выполнения заданий AWS Glue отображаются в журналах заданий Airflow. Значение по умолчанию — ложь. Для получения дополнительной информации см. параметры.
Если этот параметр включен, группы обеспечения доступности баз данных считывают поток журналов CloudWatch задания AWS Glue и передают их в журналы шагов задания Airflow DAG AWS Glue. Это дает подробные сведения о выполнении задания AWS Glue в режиме реального времени с помощью журналов DAG. Обратите внимание, что задания AWS Glue создают группу выходных данных и журналов ошибок CloudWatch на основе STDOUT и STDERR задания соответственно. Все журналы в группе выходных журналов, а также журналы исключений или ошибок из группы журналов ошибок передаются в Amazon MWAA.
Администраторы AWS теперь могут ограничить доступ группы поддержки только к Airflow, что делает Amazon MWAA единой панелью управления оркестровкой заданий и управлением их состоянием. Раньше пользователям нужно было проверять статус выполнения задания AWS Glue на шагах группы обеспечения доступности баз данных Airflow и получать идентификатор выполнения задания. Затем им нужно было получить доступ к консоли AWS Glue, чтобы найти историю выполнения заданий, найти интересующее задание с помощью идентификатора и, наконец, перейти к журналам CloudWatch задания для устранения неполадок.
Создайте группу обеспечения доступности баз данных
Чтобы создать DAG, выполните следующие шаги:
- Сохраните предыдущий код DAG в локальный файл .py, заменив указанные заполнители.
Значения идентификатора вашей учетной записи AWS, имени задания AWS Glue, базы данных AWS Glue с таблицей CloudTrail и имени таблицы CloudTrail уже должны быть известны. Вы можете настроить выходную корзину S3, выходную базу данных AWS Glue и имя выходной таблицы по мере необходимости, но убедитесь, что роль IAM задания AWS Glue, которую вы использовали ранее, настроена соответствующим образом.
- В консоли Amazon MWAA перейдите в свою среду, чтобы увидеть, где хранится код DAG.
Папка DAGs — это префикс в корзине S3, куда должен быть помещен ваш файл DAG.
- Загрузите туда отредактированный файл.

- Откройте консоль Amazon MWAA, чтобы убедиться, что DAG отображается в таблице.

Запустите группу обеспечения доступности баз данных
Чтобы запустить DAG, выполните следующие действия:
- Выберите один из следующих вариантов:
- Триггер DAG – Это приводит к тому, что вчерашние данные используются в качестве данных для обработки.
- Триггер DAG с конфигурацией – С помощью этой опции вы можете передать другую дату, возможно, для обратной засыпки, которая извлекается с помощью
dag_run.confв коде DAG, а затем передается в задание AWS Glue в качестве параметра

На следующем снимке экрана показаны дополнительные параметры конфигурации, если вы выберете Триггер DAG с конфигурацией.

- Отслеживайте работу DAG.
- Когда группа обеспечения доступности баз данных будет завершена, откройте сведения о запуске.
На правой панели вы можете просмотреть журналы или выбрать Сведения об экземпляре задачи для полного просмотра.

- Просматривайте журналы вывода заданий AWS Glue в Amazon MWAA без использования консоли AWS Glue благодаря
GlueJobOperatorподробный флаг.

Задание AWS Glue запишет результаты в указанную вами выходную таблицу.
- Запросите эту таблицу через Athena, чтобы убедиться, что запрос выполнен успешно.
Обзор
Amazon MWAA теперь предоставляет единое место для отслеживания состояния заданий AWS Glue и позволяет использовать консоль Airflow в качестве единой панели для координации заданий и управления их работоспособностью. В этом посте мы рассмотрели шаги по организации заданий AWS Glue через Airflow с использованием GlueJobOperator. Благодаря новым улучшениям наблюдаемости вы можете легко устранять неполадки с заданиями AWS Glue в унифицированном интерфейсе. Мы также продемонстрировали, как обновить среду Amazon MWAA до совместимой версии, обновить зависимости и соответствующим образом изменить политику роли IAM.
Дополнительные сведения об общих шагах по устранению неполадок см. Устранение неполадок: создание и обновление среды Amazon MWAA. Подробные сведения о миграции в среду Amazon MWAA см. Обновление с 1.10 до 2. Чтобы узнать об изменениях в открытом исходном коде для повышения наблюдаемости заданий AWS Glue в пакете поставщика Amazon Airflow, см. журналы ретрансляции из заданий AWS Glue.
Наконец, мы рекомендуем посетить Блог о больших данных AWS другие материалы по аналитике, машинному обучению и управлению данными в AWS.
Об авторах
 Рушаб Локханде — инженер по данным и машинному обучению, работающий с практикой аналитики AWS Professional Services. Он помогает клиентам внедрять решения для больших данных, машинного обучения и аналитики. Вне работы он любит проводить время с семьей, читать, бегать и играть в гольф.
Рушаб Локханде — инженер по данным и машинному обучению, работающий с практикой аналитики AWS Professional Services. Он помогает клиентам внедрять решения для больших данных, машинного обучения и аналитики. Вне работы он любит проводить время с семьей, читать, бегать и играть в гольф.
 Райан Гомес — инженер по данным и машинному обучению, работающий с практикой аналитики AWS Professional Services. Он увлечен тем, что помогает клиентам добиваться лучших результатов с помощью решений для аналитики и машинного обучения в облаке. Вне работы он любит заниматься спортом, готовить и проводить время с друзьями и семьей.
Райан Гомес — инженер по данным и машинному обучению, работающий с практикой аналитики AWS Professional Services. Он увлечен тем, что помогает клиентам добиваться лучших результатов с помощью решений для аналитики и машинного обучения в облаке. Вне работы он любит заниматься спортом, готовить и проводить время с друзьями и семьей.
 Вишва Гупта является старшим архитектором данных в AWS Professional Services Analytics Practice. Он помогает клиентам внедрять решения для больших данных и аналитики. Вне работы он любит проводить время с семьей, путешествовать и пробовать новую еду.
Вишва Гупта является старшим архитектором данных в AWS Professional Services Analytics Practice. Он помогает клиентам внедрять решения для больших данных и аналитики. Вне работы он любит проводить время с семьей, путешествовать и пробовать новую еду.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- ПлатонАйСтрим. Анализ данных Web3. Расширение знаний. Доступ здесь.
- Чеканка будущего с Эдриенн Эшли. Доступ здесь.
- Покупайте и продавайте акции компаний PREIPO® с помощью PREIPO®. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/simplify-aws-glue-job-orchestration-and-monitoring-with-amazon-mwaa/
- :имеет
- :является
- :нет
- :куда
- $UP
- 1
- 10
- 100
- 12
- 8
- a
- О нас
- доступ
- соответственно
- Учетная запись
- Достигать
- через
- Действие
- ациклический
- дополнительный
- плюс
- Преимущества
- После
- агрегирование
- Все
- позволять
- позволяет
- уже
- причислены
- Amazon
- Amazon Web Services
- an
- Аналитические фармацевтические услуги
- аналитика
- анализировать
- и
- любой
- апаш
- API
- Применение
- Разработка приложения
- соответствующий
- архитектура
- МЫ
- аргумент
- Аргументы
- AS
- At
- Атрибуты
- аудит
- доступен
- AWS
- Клей AWS
- Профессиональные услуги AWS
- основанный
- BE
- становится
- было
- до
- не являетесь
- Лучшая
- между
- большой
- Big Data
- изоферменты печени
- Разрыв
- строить
- но
- by
- под названием
- Объявления
- CAN
- случаев
- случаев
- каталог
- Причины
- изменение
- изменения
- проверка
- Выберите
- облако
- код
- COM
- объединять
- комментарий
- Общий
- Компании
- совместимость
- совместим
- полный
- комплекс
- компонент
- компоненты
- Вычисление
- Конфигурация
- подтвердить
- Консоли
- консолидировать
- консолидация
- приготовление
- Основные
- чехлы
- Создайте
- создали
- создает
- Создающий
- Текущий
- изготовленный на заказ
- клиент
- Клиенты
- DAG
- данным
- Интеграция данных
- обработка данных
- стратегия данных
- хранилища данных
- База данных
- базы данных
- Наборы данных
- Время
- Финики
- Дата и время
- Дней
- решенный
- По умолчанию
- поставляется
- убивают
- в зависимости
- устарела
- подробный
- подробнее
- Развитие
- отличаться
- различный
- Интернет
- Цифровые СМИ
- непосредственно
- обсуждать
- распределенный
- распределенные системы
- do
- приносит
- дело
- сделанный
- в течение
- e
- Ранее
- Облегчает
- эффект
- уничтожение
- еще
- включить
- включен
- позволяет
- впритык
- обязательство
- инженер
- улучшения
- обеспечивать
- Enter
- Окружающая среда
- ошибка
- Эфир (ETH)
- События
- пример
- Кроме
- исключение
- существовать
- существующий
- существует
- опыт
- Впечатления
- Разведанный
- выражение
- и, что лучший способ
- извлечение
- Oшибка
- ложный
- семья
- Особенность
- СПЕЦЦЕНА
- Особенности
- Файл
- Файлы
- фильтрация
- в заключение
- Найдите
- фитнес
- после
- питание
- Что касается
- формат
- друзья
- от
- полный
- собирать
- порождать
- стекло
- Go
- гольф
- управление
- группы
- Hadoop
- Есть
- he
- Медицина
- помощь
- помогает
- история
- Hive
- Как
- How To
- HTML
- HTTP
- HTTPS
- IAM
- ID
- идеальный
- идеи
- идентификатор
- if
- иллюстрирует
- осуществлять
- Импортировать
- in
- углубленный
- включают
- В том числе
- Увеличение
- расширились
- указанный
- промышленности
- info
- информация
- начальный
- инновационный
- размышления
- Установка
- пример
- инструкции
- интегрированный
- интеграции.
- интерес
- в нашей внутренней среде,
- в
- IT
- работа
- Джобс
- JPG
- JSON
- Основные
- известный
- большой
- новее
- последний
- УЧИТЬСЯ
- изучение
- Библиотека
- ОГРАНИЧЕНИЯ
- Список
- загрузка
- локальным
- в местном масштабе
- расположение
- журнал
- Войти
- каротаж
- искать
- машина
- обучение с помощью машины
- сделанный
- поддерживать
- сделать
- Создание
- управляемого
- управление
- управления
- руководство
- материала
- Май..
- Медиа
- Встречайте
- сообщение
- Метрика
- мигрирующий
- минимальный
- ML
- модифицировало
- модуль
- монитор
- Мониторинг
- БОЛЕЕ
- должен
- имя
- имена
- Откройте
- Навигация
- необходимо
- Необходимость
- необходимый
- потребности
- Новые
- ничего
- сейчас
- of
- предлагающий
- on
- ONE
- те,
- только
- открытый
- с открытым исходным кодом
- открытый исходный код
- оператор
- Операторы
- оптимальный
- Опция
- Опции
- or
- организовал
- оркестровка
- Другое
- наши
- Результаты
- выходной
- внешнюю
- пакет
- панд
- хлеб
- параметры
- партнер
- pass
- Прошло
- страстный
- производительность
- Разрешения
- сохраняется
- трубопровод
- Часть
- Платформа
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- пунктов
- политика
- После
- потенциально
- практика
- предпосылки
- предыдущий
- предварительно
- процесс
- Процессы
- обработка
- Продукция
- профессиональный
- профессионалы
- Профили
- Проекция
- Недвижимости
- поставщики
- приводит
- Питон
- Запросы
- повышение
- ассортимент
- Читать
- Reading
- реальные
- реального времени
- последний
- рекомендовать
- область
- регуляторы
- Реле
- замещать
- заменить
- обязательный
- Требования
- ресурс
- Полезные ресурсы
- соответственно
- ответ
- Итоги
- сохранять
- правую
- Роли
- РЯД
- Run
- Бег
- s
- Сохранить
- Сценарии
- SDK
- легко
- Поиск
- Раздел
- безопасный
- посмотреть
- Искать
- старший
- Serverless
- Услуги
- установка
- установка
- Оболочка
- должен
- показывать
- Шоу
- просто
- упростить
- с
- одинарной
- Снимок
- Решение
- Решения
- некоторые
- конкретный
- указанный
- Расходы
- заявление
- Статус:
- Шаг
- Шаги
- По-прежнему
- диск
- хранить
- Стратегия
- поток
- строка
- успешный
- такие
- достаточный
- поддержка
- Поддержанный
- системы
- ТАБЛИЦЫ
- взять
- с
- Сложность задачи
- команды
- технологии
- шаблон
- благодаря
- который
- Ассоциация
- их
- Их
- тогда
- Там.
- Эти
- они
- сторонние
- этой
- Через
- время
- в
- трек
- Transform
- Путешествие
- правда
- стараться
- вторник
- Оказалось
- два
- напишите
- ui
- унифицированный
- Ед. изм
- Обновление ПО
- Updates
- обновление
- модернизация
- повышен
- Загрузка
- Применение
- использование
- прецедент
- используемый
- пользователей
- через
- ценностное
- Наши ценности
- версия
- с помощью
- Вид
- Просмотры
- видимость
- видимый
- ходил
- хотеть
- законопроект
- we
- Web
- веб-сервисы
- ЧТО Ж
- Что
- когда
- будь то
- который
- КТО
- будете
- в
- без
- Работа
- Рабочие процессы
- бы
- записывать
- письменный
- являетесь
- ВАШЕ
- зефирнет