В современном мире, управляемом данными, возможность легко перемещать и анализировать данные на различных платформах имеет важное значение. Поток приложений Amazon, полностью управляемый сервис интеграции данных, был в авангарде оптимизации передачи данных между сервисами AWS, приложениями «программное обеспечение как услуга» (SaaS), а теперь и Google BigQuery. В этом сообщении блога вы познакомитесь с новыми Коннектор Google BigQuery в Amazon AppFlow и узнайте, как он упрощает процесс передачи данных из хранилища данных Google в Сервис Amazon Simple Storage (Amazon S3), предоставляя значительные преимущества профессионалам и организациям, работающим с данными, включая демократизацию доступа к мультиоблачным данным.
Обзор Amazon AppFlow
Поток приложений Amazon — это полностью управляемая служба интеграции, которую можно использовать для безопасной передачи данных между приложениями SaaS, такими как Google BigQuery, Salesforce, SAP, Hubspot и ServiceNow, а также сервисами AWS, такими как Amazon S3 и Амазонка Redshift, всего за несколько кликов. С помощью Amazon AppFlow вы можете запускать потоки данных практически в любом масштабе с выбранной вами частотой — по расписанию, в ответ на деловое событие или по требованию. Вы можете настроить возможности преобразования данных, такие как фильтрация и проверка, для создания полных, готовых к использованию данных как части самого потока без дополнительных действий. Amazon AppFlow автоматически шифрует передаваемые данные и позволяет ограничить передачу данных через общедоступный Интернет для приложений SaaS, интегрированных с Приватная ссылка AWS, снижая подверженность угрозам безопасности.
Представляем коннектор Google BigQuery
Новый Коннектор Google BigQuery в Amazon AppFlow открывает возможности для организаций, стремящихся использовать аналитические возможности хранилища данных Google, а также легко интегрировать, анализировать, хранить или дополнительно обрабатывать данные из BigQuery, превращая их в полезную информацию.
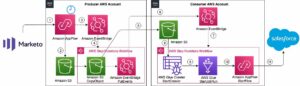
Архитектура
Давайте рассмотрим архитектуру передачи данных из Google BigQuery в Amazon S3 с помощью Amazon AppFlow.

- Выберите источник данных: В Поток приложений Amazon, выберите Google BigQuery в качестве источника данных. Укажите таблицы или наборы данных, из которых вы хотите извлечь данные.
- Сопоставление и преобразование полей: настройте передачу данных с помощью интуитивно понятного визуального интерфейса Amazon AppFlow. Вы можете сопоставить поля данных и применить необходимые преобразования, чтобы привести данные в соответствие с вашими требованиями.
- Частота передачи. Решите, как часто вы хотите передавать данные (например, ежедневно, еженедельно или ежемесячно), обеспечивая гибкость и автоматизацию.
- Назначение: укажите корзину S3 в качестве места назначения для ваших данных. Amazon AppFlow эффективно переместит данные, сделав их доступными в вашем хранилище Amazon S3.
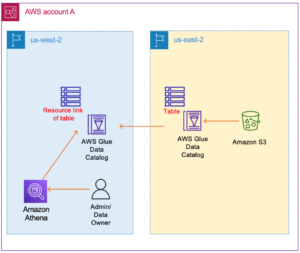
- Потребление: Использовать Амазонка Афина для анализа данных в Amazon S3.
Предпосылки
Набор данных, используемый в этом решении, создается Синтея, синтетический симулятор популяции пациентов и проект с открытым исходным кодом под Лицензия Apache 2.0. Загрузите эти данные в Google BigQuery или используйте существующий набор данных.
Подключите Amazon AppFlow к своей учетной записи Google BigQuery.
Для этого сообщения вы используете учетную запись Google, клиент OAuth с соответствующими разрешениями и данные Google BigQuery. Чтобы включить доступ Google BigQuery из Amazon AppFlow, необходимо заранее настроить новый клиент OAuth. Инструкции см. Коннектор Google BigQuery для Amazon AppFlow.
Настроить Амазон S3
Каждый объект в Amazon S3 хранится в корзине. Прежде чем вы сможете хранить данные в Amazon S3, вы должны создать ведро S3 для хранения результатов.
Создайте новую корзину S3 для результатов Amazon AppFlow.
Чтобы создать корзину S3, выполните следующие действия:
- В консоли управления AWS для Amazon S3, выберите Создать ведро.
- Введите глобально уникальный имя для твоего ведра; например,
appflow-bq-sample. - Выберите Создать ведро.
Создайте новую корзину S3 для результатов Amazon Athena.
Чтобы создать корзину S3, выполните следующие действия:
- В консоли управления AWS для Amazon S3, выберите Создать ведро.
- Введите глобально уникальный имя для твоего ведра; например,
athena-results. - Выберите Создать ведро.
Роль пользователя (роль IAM) для каталога данных AWS Glue
Чтобы каталогизировать данные, которые вы передаете с потоком, у вас должна быть соответствующая роль пользователя в Управление идентификацией и доступом AWS (IAM). Вы предоставляете эту роль Amazon AppFlow, чтобы предоставить ему разрешения, необходимые для создания Каталог данных AWS Glue, таблицы, базы данных и разделы.
Пример политики IAM, имеющей необходимые разрешения, см. Примеры политик на основе идентификации для Amazon AppFlow.
Прохождение конструкции
Теперь давайте рассмотрим практический пример использования, чтобы увидеть, как работает коннектор Amazon AppFlow Google BigQuery с Amazon S3. В данном случае вы будете использовать Amazon AppFlow для архивирования исторических данных из Google BigQuery в Amazon S3 для долгосрочного хранения и анализа.
Настройте Amazon AppFlow
Создайте новый поток Amazon AppFlow для передачи данных из Google Analytics в Amazon S3.
- На Консоль Amazon AppFlow, выберите Создать поток.
- Введите имя для вашего потока; например,
my-bq-flow. - Добавьте необходимое Теги; например, для Основные вводить
envи для Значение вводитьdev.

- Выберите Следующая.
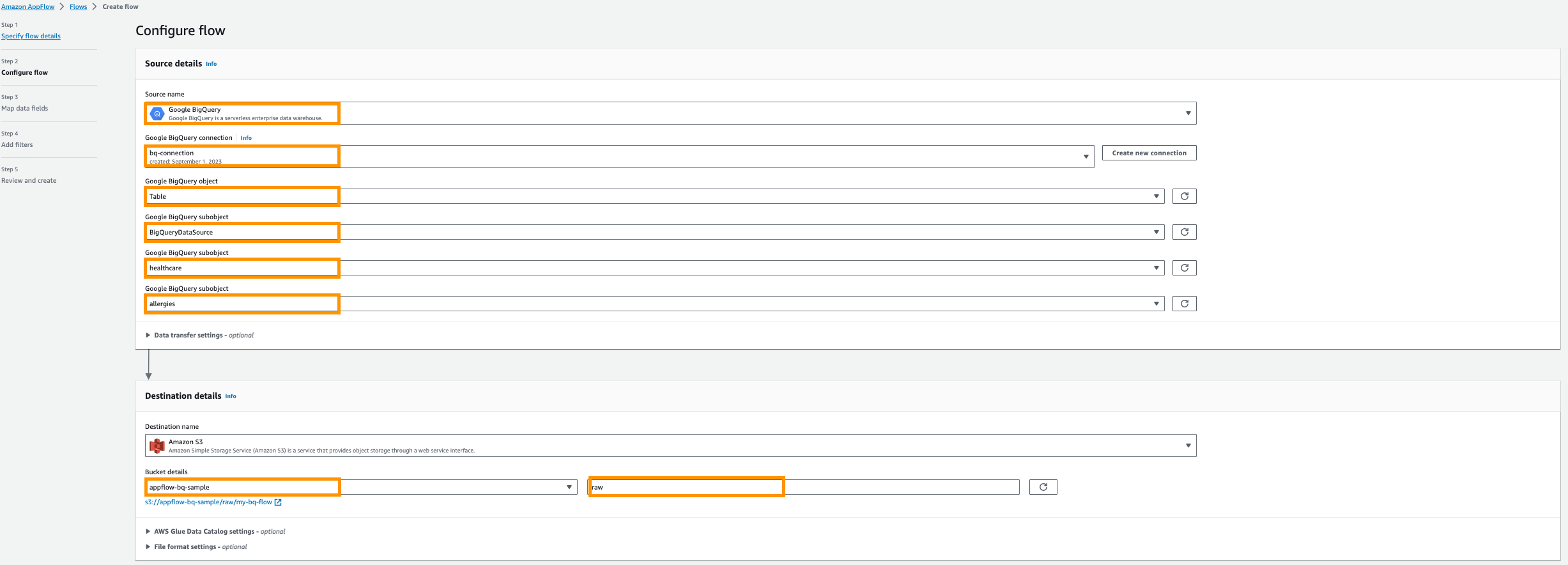
- Что касается Название источника, выберите Google Большой запрос.
- Выберите Создать новое соединение.
- Введите свой OAuth идентификатор клиента и Секрет клиента, затем назовите свое соединение; например,
bq-connection.

- Во всплывающем окне разрешите amazon.com доступ к API Google BigQuery.

- Что касается Выберите объект Google BigQuery., выберите Настольные.
- Что касается Выберите подобъект Google BigQuery., выберите BigQueryProjectName.
- Что касается Выберите подобъект Google BigQuery., выберите Имя базы данных.
- Что касается Выберите подобъект Google BigQuery., выберите ИмяТаблицы.
- Что касается Название места назначения, выберите Amazon S3.
- Что касается Детали ковшавыберите корзину Amazon S3, созданную для хранения результатов Amazon AppFlow, в предварительных требованиях.
- Enter
rawкак префикс.
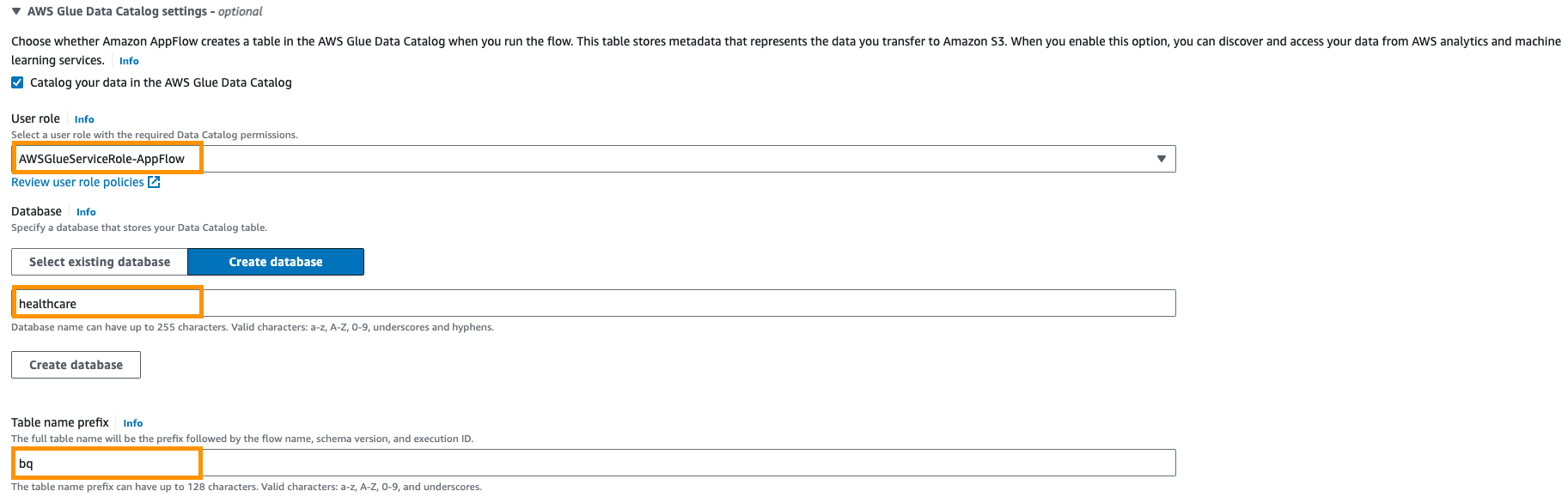
- Далее предоставьте Каталог данных AWS Glue настройки для создания таблицы для дальнейшего анализа.
- Выберите Роль пользователя (роль IAM), созданная в предварительных условиях.
- Создавать новое база данных Например,
healthcare. - Обеспечить префикс таблицы настройка, например,
bq.
- Выберите Запуск по требованию.
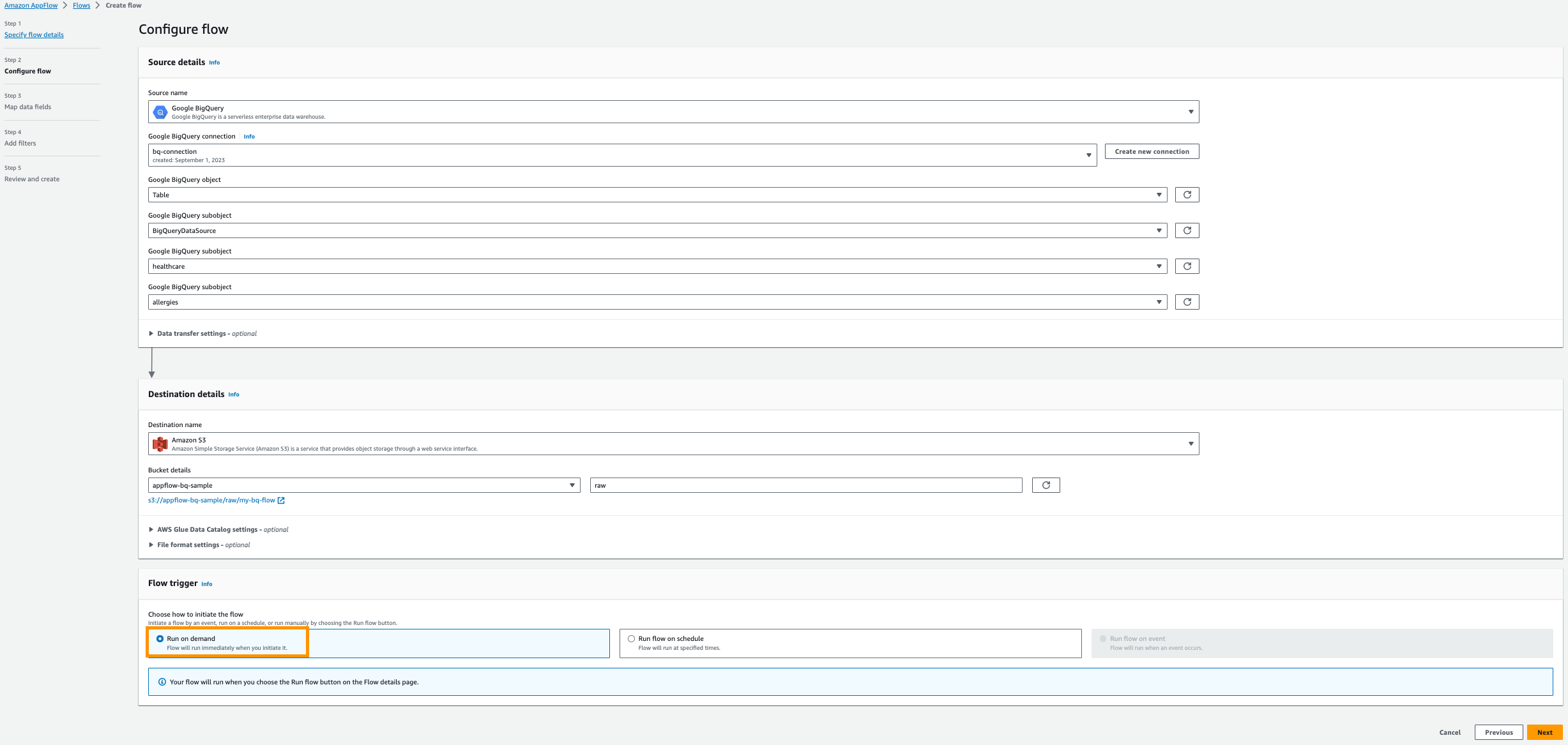
- Выберите Далее.
- Выберите Сопоставление полей вручную.
- Выберите следующие шесть полей для Имя исходного поля Из таблицы Аллергии:
- Start
- Пациент
- Code
- Описание
- Тип
- Категории
- Выберите Непосредственное сопоставление полей.

- Выберите Следующая.
- In Добавить фильтры раздел, выбрать Следующая.
- Выберите Создать поток.
Управляйте потоком
После создания нового потока вы можете запустить его по требованию.
- На Консоль Amazon AppFlow, выберите
my-bq-flow. - Выберите Выполнить поток.

Для простоты понимания в этом пошаговом руководстве выберите «Запускать задание по требованию». На практике вы можете выбрать запланированное задание и периодически извлекать только вновь добавленные данные.
Запрос через Amazon Athena
При выборе дополнительных настроек каталога данных AWS Glue каталог данных создает каталог для данных, позволяя Amazon Athena выполнять запросы.
Если вам будет предложено настроить расположение результатов запроса, перейдите к Настройки и выберите Управление, Под Управление настройками, выберите сегмент результатов Athena, созданный в предварительных условиях, и выберите Сохранить.
- На Консоль Amazon Athena, выберите источник данных как
AWSDataCatalog. - Затем выберите База данных as
healthcare. - Теперь вы можете выбрать таблицу, созданную сканером AWS Glue, и просмотреть ее.

- Вы также можете запустить собственный запрос, чтобы найти 10 наиболее частых аллергий, как показано в следующем запросе.
Внимание: В приведенном ниже запросе замените имя таблицы, в данном случае bq_appflow_mybqflow_1693588670_latest, с именем таблицы, созданной в вашей учетной записи AWS.
- Выберите Выполнить запрос.

Этот результат показывает 10 крупнейших аллергий по количеству случаев.
Убирать
Чтобы избежать взимания платы, очистите ресурсы в своем аккаунте AWS, выполнив следующие действия:
- На консоли Amazon AppFlow выберите Потоки в навигационной панели.
- Из списка потоков выберите поток
my-bq-flow, и удалите его. - Введите «Удалить», чтобы удалить поток.
- Выберите Коммутация в навигационной панели.
- Выберите Google Большой запрос из списка коннекторов выберите
bq-connector, и удалите его. - Введите «Удалить», чтобы удалить соединитель.
- На консоли IAM выберите роли на странице навигации, затем выберите роль, которую вы создали для сканера AWS Glue, и удалите ее.
- На консоли Amazon Athena:
- Удалить таблицы, созданные в базе данных
healthcareс помощью сканера AWS Glue. - Отбросить базу данных
healthcare
- Удалить таблицы, созданные в базе данных
- На консоли Amazon S3 найдите созданный вами сегмент результатов Amazon AppFlow, выберите пустой чтобы удалить объекты, затем удалите ведро.
- На консоли Amazon S3 найдите созданный вами сегмент результатов Amazon Athena, выберите пустой чтобы удалить объекты, затем удалите ведро.
- Очистите ресурсы в своей учетной записи Google, удалив проект, содержащий ресурсы Google BigQuery. Следуйте документации, чтобы очистить ресурсы Google.
Заключение
Коннектор Google BigQuery в Amazon AppFlow упрощает процесс передачи данных из хранилища данных Google в Amazon S3. Эта интеграция упрощает аналитику и машинное обучение, архивирование и долгосрочное хранение, предоставляя значительные преимущества специалистам по данным и организациям, стремящимся использовать аналитические возможности обеих платформ.
Благодаря Amazon AppFlow сложности интеграции данных устраняются, что позволяет вам сосредоточиться на получении практической информации из ваших данных. Архивируете ли вы исторические данные, выполняете сложную аналитику или готовите данные для машинного обучения, этот соединитель упрощает процесс, делая его доступным для более широкого круга специалистов по данным.
Если вам интересно узнать, как осуществляется передача данных из Google BigQuery в Amazon S3 с помощью Amazon AppFlow, ознакомьтесь с пошаговой инструкцией. видео-инструкции. В этом руководстве мы рассмотрим весь процесс: от настройки соединения до запуска потока передачи данных. Для получения дополнительной информации об Amazon AppFlow посетите Поток приложений Amazon.
Об авторах
![]() Картикай Хатор является архитектором решений в области глобальных медико-биологических наук в Amazon Web Services. Он с энтузиазмом помогает клиентам в их переходе к облаку, уделяя особое внимание аналитическим сервисам AWS. Он заядлый бегун и любит пешие походы.
Картикай Хатор является архитектором решений в области глобальных медико-биологических наук в Amazon Web Services. Он с энтузиазмом помогает клиентам в их переходе к облаку, уделяя особое внимание аналитическим сервисам AWS. Он заядлый бегун и любит пешие походы.
 Камен Шарланджиев — старший архитектор больших данных и решений ETL, а также эксперт по Amazon AppFlow. Его миссия — облегчить жизнь клиентам, которые сталкиваются со сложными проблемами интеграции данных. Его секретное оружие? Полностью управляемые сервисы AWS с минимальным кодированием, позволяющие выполнить работу с минимальными усилиями и без необходимости написания кода.
Камен Шарланджиев — старший архитектор больших данных и решений ETL, а также эксперт по Amazon AppFlow. Его миссия — облегчить жизнь клиентам, которые сталкиваются со сложными проблемами интеграции данных. Его секретное оружие? Полностью управляемые сервисы AWS с минимальным кодированием, позволяющие выполнить работу с минимальными усилиями и без необходимости написания кода.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/simplify-data-transfer-google-bigquery-to-amazon-s3-using-amazon-appflow/
- :имеет
- :является
- $UP
- 10
- 100
- 14
- 16
- 17
- 22
- 321
- 8
- 9
- a
- способность
- О нас
- доступ
- управление доступом
- доступной
- Учетная запись
- через
- Добавить
- добавленный
- дополнительный
- продвижение
- выравнивать
- Аллергии
- позволять
- Позволяющий
- позволяет
- причислены
- Amazon
- Амазонка Афина
- Amazon Web Services
- Amazon.com
- an
- анализ
- Аналитические фармацевтические услуги
- аналитика
- анализировать
- и
- любой
- API
- Приложения
- Применить
- соответствующий
- архитектура
- архив
- МЫ
- AS
- At
- автоматически
- автоматизация
- избежать
- AWS
- Клей AWS
- Консоль управления AWS
- было
- до
- ниже
- Преимущества
- между
- большой
- Big Data
- BigQuery
- Блог
- изоферменты печени
- шире
- бизнес
- by
- CAN
- Может получить
- возможности
- возможности
- случаев
- случаев
- каталог
- Категории
- проблемы
- расходы
- Выберите
- клиент
- облако
- Кодирование
- COM
- полный
- комплектующие
- комплекс
- сложности
- связи
- Консоли
- содержит
- гусеничный
- Создайте
- создали
- создает
- Создающий
- изготовленный на заказ
- Клиенты
- ежедневно
- данным
- доступ к данным
- Интеграция данных
- информационное хранилище
- управляемых данными
- База данных
- базы данных
- Наборы данных
- решать
- Спрос
- демократизация
- описание
- назначение
- обнаружить
- Разное
- документации
- сделанный
- простота
- легче
- эффективно
- усилие
- легко
- устранен
- включить
- позволяет
- Весь
- существенный
- Эфир (ETH)
- События
- пример
- Примеры
- существующий
- эксперту
- Больше
- Экспозиция
- извлечение
- всего лишь пяти граммов героина
- несколько
- поле
- Поля
- фильтрация
- Найдите
- Трансформируемость
- поток
- текущий
- Потоки
- Фокус
- следовать
- после
- Что касается
- Передний край
- частота
- часто
- от
- полностью
- далее
- порождать
- генерируется
- получить
- Глобальный
- ГЛОБАЛЬНО
- Google Analytics
- предоставлять
- группы
- упряжь
- Есть
- he
- здравоохранение
- помощь
- пеший туризм
- его
- исторический
- Как
- HTML
- HTTP
- HTTPS
- HubSpot
- IAM
- Личность
- управление идентификацией и доступом
- in
- В том числе
- информация
- размышления
- инструкции
- интегрировать
- интегрированный
- интеграции.
- заинтересованный
- Интерфейс
- Интернет
- в
- интуитивный
- IT
- саму трезвость
- работа
- путешествие
- всего
- изучение
- Лицензия
- ЖИЗНЬЮ
- Наука о жизни
- ОГРАНИЧЕНИЯ
- Список
- загрузка
- расположение
- долгосрочный
- посмотреть
- машина
- обучение с помощью машины
- сделать
- Создание
- управляемого
- управление
- карта
- отображение
- минимальный
- Наша миссия
- БОЛЕЕ
- движение
- двигаться
- должен
- имя
- Откройте
- Навигация
- почти
- необходимо
- необходимый
- потребности
- Новые
- вновь
- нет
- сейчас
- номер
- OAuth
- объект
- объекты
- of
- on
- On-Demand
- только
- с открытым исходным кодом
- or
- заказ
- организации
- за
- страница
- хлеб
- часть
- страстный
- пациент
- выполнять
- выполнения
- Разрешения
- Платформы
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- политика
- сообщения
- население
- возможности,
- После
- практическое
- практика
- подготовка
- предпосылки
- предварительный просмотр
- процесс
- профессионалы
- Проект
- обеспечивать
- обеспечение
- что такое варган?
- Запросы
- ассортимент
- снижение
- замещать
- обязательный
- Требования
- Полезные ресурсы
- ответ
- ограничивать
- результат
- Итоги
- обзоре
- Богатые
- Роли
- Run
- бегун
- Бег
- SaaS
- Salesforce
- живица
- Шкала
- график
- считаться
- Наука
- Поиск
- Secret
- Раздел
- безопасно
- безопасность
- Угрозы безопасности
- посмотреть
- поиск
- обслуживание
- ServiceNow
- Услуги
- набор
- установка
- настройки
- показанный
- Шоу
- значительный
- просто
- упростить
- имитатор
- ШЕСТЬ
- Software
- программное обеспечение как услуга
- Решение
- Решения
- Источник
- Шаги
- диск
- магазин
- хранить
- упорядочение
- такие
- синтетический
- ТАБЛИЦЫ
- взять
- который
- Ассоциация
- их
- тогда
- этой
- угрозы
- Через
- в
- Сегодняшних
- топ
- Топ-10
- перевод
- Передающий
- трансформация
- преобразований
- превращение
- учебник
- напишите
- под
- понимание
- созданного
- Представляет
- использование
- прецедент
- используемый
- Информация о пользователе
- через
- Проверка
- ценностное
- Войти
- от
- прохождение
- хотеть
- Склады
- we
- Web
- веб-сервисы
- еженедельно
- будь то
- КТО
- будете
- окно
- без
- работает
- Мир
- являетесь
- ВАШЕ
- YouTube
- зефирнет