При развертывании модели большого языка (LLM) специалисты по машинному обучению (ML) обычно обращают внимание на два показателя производительности обслуживания модели: задержку, определяемую временем, необходимым для генерации одного токена, и пропускную способность, определяемую количеством сгенерированных токенов. в секунду. Хотя один запрос к развернутой конечной точке будет иметь пропускную способность, примерно равную обратной задержке модели, это не обязательно так, когда в конечную точку одновременно отправляется несколько одновременных запросов. Из-за методов обслуживания модели, таких как непрерывная пакетная обработка одновременных запросов на стороне клиента, задержка и пропускная способность имеют сложную взаимосвязь, которая значительно варьируется в зависимости от архитектуры модели, конфигураций обслуживания, типа оборудования экземпляра, количества одновременных запросов и изменений во входных полезных нагрузках, таких как как количество входных токенов и выходных токенов.
В этом посте эти взаимоотношения рассматриваются посредством комплексного сравнительного анализа LLM, доступных в Amazon SageMaker JumpStart, включая варианты Llama 2, Falcon и Mistral. С помощью SageMaker JumpStart специалисты по машинному обучению могут выбирать из широкого спектра общедоступных базовых моделей для развертывания в специализированных системах. Создатель мудреца Амазонки экземпляров в изолированной от сети среде. Мы предоставляем теоретические принципы того, как характеристики ускорителей влияют на тестирование LLM. Мы также демонстрируем влияние развертывания нескольких экземпляров за одной конечной точкой. Наконец, мы предоставляем практические рекомендации по адаптации процесса развертывания SageMaker JumpStart в соответствии с вашими требованиями к задержке, пропускной способности, стоимости и ограничениям на доступные типы экземпляров. Все результаты сравнительного анализа, а также рекомендации основаны на универсальном ноутбук что вы можете адаптироваться к своему варианту использования.
Развернутое сравнение конечных точек
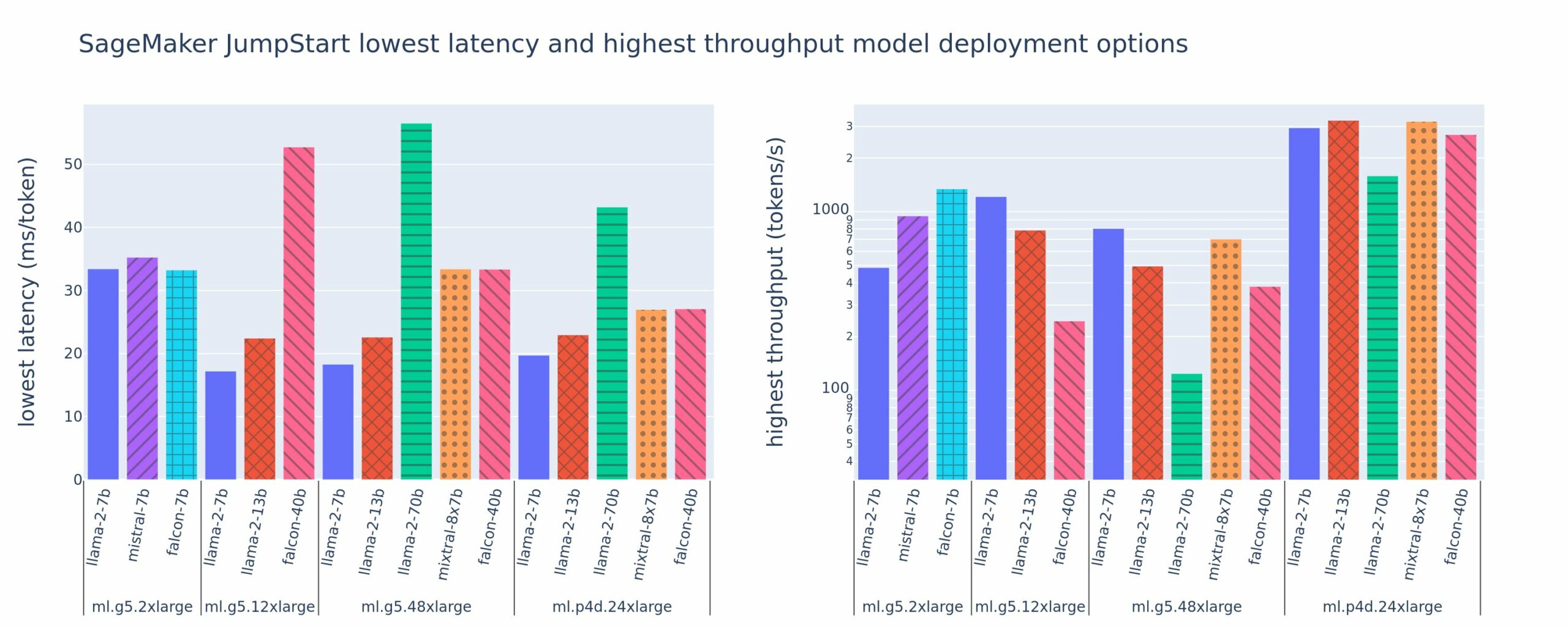
На следующем рисунке показаны значения минимальной задержки (слева) и максимальной пропускной способности (справа) для конфигураций развертывания для различных типов моделей и типов экземпляров. Важно отметить, что в каждом из этих развертываний модели используются конфигурации по умолчанию, предоставленные SageMaker JumpStart, с учетом желаемого идентификатора модели и типа экземпляра для развертывания.
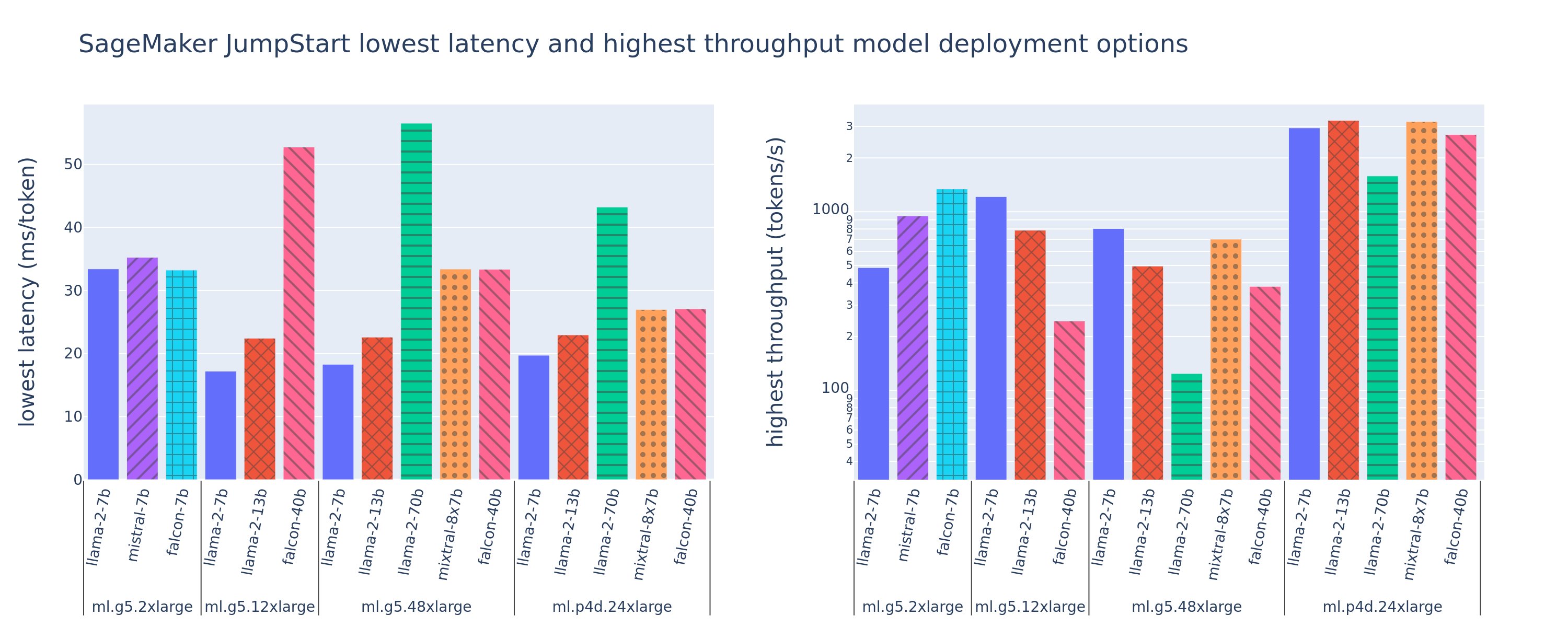
Эти значения задержки и пропускной способности соответствуют полезным нагрузкам с 256 входными токенами и 256 выходными токенами. Конфигурация с наименьшей задержкой ограничивает обслуживание модели одним одновременным запросом, а конфигурация с самой высокой пропускной способностью максимизирует возможное количество одновременных запросов. Как мы видим в нашем сравнительном тестировании, увеличение количества одновременных запросов монотонно увеличивает пропускную способность при уменьшении улучшения для больших одновременных запросов. Кроме того, модели полностью сегментируются на поддерживаемом экземпляре. Например, поскольку экземпляр ml.g5.48xlarge имеет 8 графических процессоров, все модели SageMaker JumpStart, использующие этот экземпляр, сегментируются с использованием тензорного параллелизма на всех восьми доступных ускорителях.
Из этой цифры можно сделать несколько выводов. Во-первых, не все модели поддерживаются во всех экземплярах; некоторые модели меньшего размера, такие как Falcon 7B, не поддерживают сегментирование модели, тогда как более крупные модели имеют более высокие требования к вычислительным ресурсам. Во-вторых, по мере увеличения сегментирования производительность обычно улучшается, но не обязательно улучшается для небольших моделей.. Это связано с тем, что небольшие модели, такие как 7B и 13B, несут значительные накладные расходы на связь при сегментировании по слишком большому количеству ускорителей. Мы обсудим это более подробно позже. Наконец, экземпляры ml.p4d.24xlarge, как правило, имеют значительно лучшую пропускную способность благодаря улучшению пропускной способности памяти A100 по сравнению с графическими процессорами A10G. Как мы обсудим позже, решение об использовании конкретного типа экземпляра зависит от ваших требований к развертыванию, включая ограничения по задержке, пропускной способности и стоимости.
Как получить эти значения конфигурации с минимальной задержкой и максимальной пропускной способностью? Начнем с построения графика зависимости задержки от пропускной способности для конечной точки Llama 2 7B на экземпляре ml.g5.12xlarge для полезной нагрузки с 256 входными и 256 выходными токенами, как показано на следующей кривой. Аналогичная кривая существует для каждой развернутой конечной точки LLM.

По мере увеличения параллелизма монотонно увеличиваются также пропускная способность и задержка. Таким образом, самая низкая точка задержки возникает при значении одновременного запроса, равном 1, и вы можете экономично увеличить пропускную способность системы за счет увеличения количества одновременных запросов. На этой кривой существует отчетливое «колено», где очевидно, что прирост пропускной способности, связанный с дополнительным параллелизмом, не перевешивает связанное с ним увеличение задержки. Точное расположение этого колена зависит от конкретного случая использования; некоторые специалисты могут определить колено в точке превышения заранее заданного требования к задержке (например, 100 мс/токен), тогда как другие могут использовать тесты нагрузочного тестирования и методы теории массового обслуживания, такие как правило половины задержки, а другие могут использовать теоретические характеристики ускорителя.
Также отметим, что максимальное количество одновременных запросов ограничено. На предыдущем рисунке трассировка линии заканчивается 192 одновременными запросами. Источником этого ограничения является ограничение времени ожидания вызова SageMaker, при котором конечные точки SageMaker отключают ответ на вызов по истечении 60 секунд. Этот параметр зависит от учетной записи и не может быть настроен для отдельной конечной точки. Для LLM создание большого количества выходных токенов может занять секунды или даже минуты. Таким образом, большие объемы входных или выходных данных могут привести к сбою запросов на вызов. Кроме того, если количество одновременных запросов очень велико, многие запросы будут находиться в очереди в течение длительного времени, что приводит к ограничению времени ожидания в 60 секунд. В целях данного исследования мы используем ограничение времени ожидания, чтобы определить максимально возможную пропускную способность для развертывания модели. Важно отметить, что хотя конечная точка SageMaker может обрабатывать большое количество одновременных запросов, не соблюдая тайм-аут ответа на вызов, вы можете захотеть определить максимальное количество одновременных запросов относительно перегиба на кривой задержки-пропускной способности. Вероятно, это тот момент, когда вы начинаете рассматривать горизонтальное масштабирование, когда одна конечная точка предоставляет несколько экземпляров с репликами модели и распределяет нагрузку входящих запросов между репликами для поддержки большего количества одновременных запросов.
Продолжая этот шаг, в следующей таблице приведены результаты сравнительного тестирования для различных конфигураций модели Llama 2 7B, включая различное количество входных и выходных токенов, типы экземпляров и количество одновременных запросов. Обратите внимание, что на предыдущем рисунке изображена только одна строка этой таблицы.
| . | Пропускная способность (токенов/сек) | Задержка (мс/токен) | ||||||||||||||||||
| Параллельные запросы | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| Общее количество токенов: 512, Количество выходных токенов: 256 | ||||||||||||||||||||
| мл.g5.2xбольшой | 30 | 54 | 115 | 208 | 343 | 475 | 486 | - | - | - | 33 | 33 | 35 | 39 | 48 | 97 | 159 | - | - | - |
| мл.g5.12xбольшой | 59 | 117 | 223 | 406 | 616 | 866 | 1098 | 1214 | - | - | 17 | 17 | 18 | 20 | 27 | 38 | 60 | 112 | - | - |
| мл.g5.48xбольшой | 56 | 108 | 202 | 366 | 522 | 660 | 707 | 804 | - | - | 18 | 18 | 19 | 22 | 32 | 50 | 101 | 171 | - | - |
| мл.p4d.24xlarge | 49 | 85 | 178 | 353 | 654 | 1079 | 1544 | 2312 | 2905 | 2944 | 21 | 23 | 22 | 23 | 26 | 31 | 44 | 58 | 92 | 165 |
| Общее количество токенов: 4096, Количество выходных токенов: 256 | ||||||||||||||||||||
| мл.g5.2xбольшой | 20 | 36 | 48 | 49 | - | - | - | - | - | - | 48 | 57 | 104 | 170 | - | - | - | - | - | - |
| мл.g5.12xбольшой | 33 | 58 | 90 | 123 | 142 | - | - | - | - | - | 31 | 34 | 48 | 73 | 132 | - | - | - | - | - |
| мл.g5.48xбольшой | 31 | 48 | 66 | 82 | - | - | - | - | - | - | 31 | 43 | 68 | 120 | - | - | - | - | - | - |
| мл.p4d.24xlarge | 39 | 73 | 124 | 202 | 278 | 290 | - | - | - | - | 26 | 27 | 33 | 43 | 66 | 107 | - | - | - | - |
В этих данных мы наблюдаем некоторые дополнительные закономерности. При увеличении размера контекста задержка увеличивается, а пропускная способность снижается. Например, на ml.g5.2xlarge с параллелизмом, равным 1, пропускная способность составляет 30 токенов в секунду, когда общее количество токенов равно 512, по сравнению с 20 токенами в секунду, если общее количество токенов равно 4,096. Это связано с тем, что для обработки более крупного ввода требуется больше времени. Мы также видим, что увеличение возможностей графического процессора и сегментирование влияют на максимальную пропускную способность и максимальное количество поддерживаемых одновременных запросов. Из таблицы видно, что Llama 2 7B имеет заметно разные значения максимальной пропускной способности для разных типов экземпляров, и эти значения максимальной пропускной способности возникают при разных значениях одновременных запросов. Эти характеристики заставят специалиста по ОД оправдывать стоимость одного экземпляра по сравнению с другим. Например, учитывая требования к низкой задержке, практикующий специалист может выбрать экземпляр ml.g5.12xlarge (4 графических процессора A10G) вместо экземпляра ml.g5.2xlarge (1 графический процессор A10G). При наличии высоких требований к пропускной способности использование экземпляра ml.p4d.24xlarge (8 графических процессоров A100) с полным сегментированием будет оправдано только при высоком уровне параллелизма. Однако обратите внимание, что вместо этого часто бывает полезно загрузить несколько компонентов вывода модели 7B в один экземпляр ml.p4d.24xlarge; такая поддержка нескольких моделей обсуждается далее в этом посте.
Предыдущие наблюдения были сделаны для модели Llama 2 7B. Однако аналогичные закономерности остаются верными и для других моделей. Основной вывод заключается в том, что показатели производительности задержки и пропускной способности зависят от полезной нагрузки, типа экземпляра и количества одновременных запросов, поэтому вам необходимо найти идеальную конфигурацию для вашего конкретного приложения. Чтобы сгенерировать предыдущие числа для вашего варианта использования, вы можете запустить связанный ноутбук, где вы можете настроить анализ нагрузочного теста для вашей модели, типа экземпляра и полезной нагрузки.
Разбираемся в спецификациях ускорителя
Выбор подходящего оборудования для вывода LLM во многом зависит от конкретных случаев использования, целей взаимодействия с пользователем и выбранного LLM. В этом разделе предпринята попытка дать представление о изломе кривой задержки-пропускной способности относительно принципов высокого уровня, основанных на спецификациях ускорителя. Одних только этих принципов недостаточно для принятия решения: необходимы реальные ориентиры. Термин устройство здесь используется для обозначения всех аппаратных ускорителей машинного обучения. Мы утверждаем, что перегиб на кривой задержки-пропускной способности обусловлен одним из двух факторов:
- Ускоритель исчерпал память для кэширования матриц KV, поэтому последующие запросы ставятся в очередь.
- Ускоритель по-прежнему имеет запасную память для кэша KV, но использует достаточно большой размер пакета, поэтому время обработки определяется задержкой вычислительных операций, а не пропускной способностью памяти.
Обычно мы предпочитаем ограничиваться вторым фактором, поскольку это означает, что ресурсы ускорителя насыщены. По сути, вы максимизируете ресурсы, за которые заплатили. Давайте разберем это утверждение подробнее.
KV-кэширование и память устройства
Стандартные механизмы внимания преобразователя вычисляют внимание для каждого нового токена по сравнению со всеми предыдущими токенами. Большинство современных серверов машинного обучения кэшируют ключи и значения внимания в памяти устройства (DRAM), чтобы избежать повторных вычислений на каждом этапе. Это называется это КВ-кэш, и он растет с увеличением размера пакета и длины последовательности. Он определяет, сколько пользовательских запросов может обслуживаться параллельно, и определяет изгиб кривой задержки и пропускной способности, если режим с привязкой к вычислениям во втором сценарии, упомянутом ранее, еще не соблюден, учитывая доступную DRAM. Следующая формула представляет собой грубое приближение максимального размера кэша KV.

В этой формуле B — размер партии, а N — количество ускорителей. Например, модель Llama 2 7B в FP16 (2 байта/параметр), обслуживаемая графическим процессором A10G (24 ГБ DRAM), потребляет примерно 14 ГБ, оставляя 10 ГБ для кэша KV. Подключив полную длину контекста модели (N = 4096) и оставшиеся параметры (n_layers=32, n_kv_attention_heads=32 и d_attention_head=128), это выражение показывает, что мы ограничены параллельным обслуживанием пакета из четырех пользователей из-за ограничений DRAM. . Если вы наблюдаете соответствующие контрольные показатели в предыдущей таблице, это хорошее приближение для наблюдаемого излома на этой кривой задержки и пропускной способности. Такие методы, как внимание к сгруппированному запросу (GQA) может уменьшить размер кэша KV, в случае GQA в тот же раз уменьшается количество головок KV.
Интенсивность арифметических вычислений и пропускная способность памяти устройства
Рост вычислительной мощности ускорителей машинного обучения опережал пропускную способность их памяти, а это означает, что они могут выполнять гораздо больше вычислений над каждым байтом данных за то время, которое требуется для доступа к этому байту.
Ассоциация арифметическая интенсивность, или отношение вычислительных операций к обращениям к памяти, поскольку операция определяет, ограничена ли она пропускной способностью памяти или вычислительной мощностью выбранного оборудования. Например, графический процессор A10G (семейство типов экземпляров g5) с производительностью 70 терафлопс FP16 и пропускной способностью 600 ГБ/с может выполнять вычисления примерно со скоростью 116 операций на байт. Графический процессор A100 (семейство типов экземпляров p4d) может выполнять приблизительно 208 операций на байт. Если арифметическая интенсивность модели трансформатора ниже этого значения, она привязана к памяти; если он указан выше, он привязан к вычислениям. Механизм внимания для Llama 2 7B требует 62 операции на байт для размера пакета 1 (объяснение см. Руководство по выводам и эффективности LLM), что означает, что он привязан к памяти. Когда механизм внимания привязан к памяти, дорогостоящие FLOPS остаются неиспользованными.
Есть два способа лучше использовать ускоритель и повысить интенсивность арифметических вычислений: уменьшить требуемые для операции обращения к памяти (именно это и есть FlashAttention фокусируется) или увеличьте размер пакета. Однако мы, возможно, не сможем увеличить размер пакета настолько, чтобы достичь режима с привязкой к вычислениям, если наша DRAM слишком мала для хранения соответствующего KV-кэша. Грубое приближение критического размера пакета B*, которое отделяет режимы с привязкой к вычислениям от режимов с привязкой к памяти для вывода стандартного GPT-декодера, описывается следующим выражением, где A_mb — пропускная способность памяти ускорителя, A_f — FLOPS ускорителя, а N — число ускорителей. Этот критический размер пакета можно получить, определив, где время доступа к памяти равно времени вычислений. Ссылаться на это сообщение в блоге чтобы более подробно понять уравнение 2 и его предположения.

Это то же самое соотношение операций/байт, которое мы ранее рассчитали для A10G, поэтому критический размер пакета для этого графического процессора равен 116. Один из способов приблизиться к этому теоретическому критическому размеру пакета — увеличить сегментирование модели и разделить кэш на большее количество N ускорителей. Это эффективно увеличивает емкость кэша KV, а также размер пакета, привязанного к памяти.
Еще одним преимуществом сегментирования модели является разделение параметров модели и работы по загрузке данных между N ускорителями. Этот тип шардинга представляет собой тип параллелизма моделей, также называемый тензорный параллелизм. Проще говоря, в совокупности пропускная способность памяти и вычислительная мощность в N раз выше. Предполагая отсутствие каких-либо накладных расходов (связь, программное обеспечение и т. д.), это уменьшит задержку декодирования каждого токена на N, если мы ограничены памятью, поскольку задержка декодирования токена в этом режиме ограничена временем, необходимым для загрузки модели. веса и кэш. Однако в реальной жизни увеличение степени сегментирования приводит к расширению связи между устройствами для совместного использования промежуточных активаций на каждом уровне модели. Эта скорость связи ограничена полосой пропускания межсоединения устройства. Точно оценить его влияние сложно (подробнее см. Модель параллелизма), но со временем это может перестать приносить пользу или ухудшить производительность — это особенно актуально для моделей меньшего размера, поскольку меньшие объемы передачи данных приводят к снижению скорости передачи.
Чтобы сравнить ускорители ML на основе их характеристик, мы рекомендуем следующее. Сначала рассчитайте приблизительный критический размер пакета для каждого типа ускорителя согласно второму уравнению и размер KV-кеша для критического размера пакета согласно первому уравнению. Затем вы можете использовать доступную DRAM на ускорителе, чтобы вычислить минимальное количество ускорителей, необходимое для соответствия кэшу KV и параметрам модели. При выборе между несколькими ускорителями расставьте приоритеты в порядке наименьшей стоимости за ГБ/сек пропускной способности памяти. Наконец, протестируйте эти конфигурации и определите, какая стоимость/токен является наилучшей для верхней границы желаемой задержки.
Выберите конфигурацию развертывания конечной точки
Многие программы LLM, распространяемые SageMaker JumpStart, используют вывод-генерации текста (ТГИ) Контейнер SageMaker для модельного обслуживания. В следующей таблице описано, как настроить различные параметры обслуживания модели, чтобы либо повлиять на обслуживание модели, что влияет на кривую задержки и пропускной способности, либо защитить конечную точку от запросов, которые могут перегрузить конечную точку. Это основные параметры, которые вы можете использовать для настройки развертывания конечной точки для вашего варианта использования. Если не указано иное, мы используем значение по умолчанию. параметры полезной нагрузки генерации текста и Переменные среды TGI.
| Переменная среды | Описание | Значение по умолчанию для SageMaker JumpStart |
| Конфигурации обслуживания моделей | . | . |
MAX_BATCH_PREFILL_TOKENS |
Ограничивает количество токенов в операции предварительного заполнения. Эта операция создает кэш KV для новой последовательности ввода подсказок. Он требует большого объема памяти и ограничен вычислительными ресурсами, поэтому это значение ограничивает количество токенов, разрешенных в одной операции предварительного заполнения. Шаги декодирования для других запросов приостанавливаются, пока происходит предварительное заполнение. | 4096 (по умолчанию TGI) или максимальная поддерживаемая длина контекста для конкретной модели (предоставляется SageMaker JumpStart), в зависимости от того, что больше. |
MAX_BATCH_TOTAL_TOKENS |
Управляет максимальным количеством токенов, которые можно включить в пакет во время декодирования или при одном прямом проходе через модель. В идеале это настроено на максимальное использование всего доступного оборудования. | Не указано (по умолчанию TGI). TGI установит это значение относительно оставшейся памяти CUDA во время прогрева модели. |
SM_NUM_GPUS |
Количество осколков, которые можно использовать. То есть количество графических процессоров, используемых для запуска модели с использованием тензорного параллелизма. | Зависит от экземпляра (предоставляется SageMaker JumpStart). Для каждого поддерживаемого экземпляра конкретной модели SageMaker JumpStart предоставляет наилучшие настройки тензорного параллелизма. |
| Конфигурации для защиты вашей конечной точки (настройте их для своего варианта использования) | . | . |
MAX_TOTAL_TOKENS |
Это ограничивает бюджет памяти одного клиентского запроса, ограничивая количество токенов во входной последовательности плюс количество токенов в выходной последовательности ( max_new_tokens параметр полезной нагрузки). |
Максимальная поддерживаемая длина контекста для конкретной модели. Например, 4096 для Ламы 2. |
MAX_INPUT_LENGTH |
Определяет максимально допустимое количество токенов во входной последовательности для одного клиентского запроса. При увеличении этого значения следует учитывать следующее: более длинные входные последовательности требуют больше памяти, что влияет на непрерывную пакетную обработку, и многие модели имеют поддерживаемую длину контекста, которую не следует превышать. | Максимальная поддерживаемая длина контекста для конкретной модели. Например, 4095 для Ламы 2. |
MAX_CONCURRENT_REQUESTS |
Максимальное количество одновременных запросов, разрешенное развернутой конечной точкой. Новые запросы, превышающие этот предел, немедленно вызовут ошибку перегрузки модели, чтобы предотвратить низкую задержку для текущих запросов на обработку. | 128 (по умолчанию TGI). Этот параметр позволяет вам получить высокую пропускную способность для различных вариантов использования, но вы должны закрепить его соответствующим образом, чтобы уменьшить количество ошибок тайм-аута вызова SageMaker. |
Сервер TGI использует непрерывную пакетную обработку, которая динамически объединяет одновременные запросы в пакеты для совместного использования одного прямого прохода вывода модели. Существует два типа прямых проходов: предварительное заполнение и декодирование. Каждый новый запрос должен выполнить один проход предварительного заполнения для заполнения кэша KV для токенов входной последовательности. После заполнения кэша KV прямой проход декодирования выполняет один прогноз следующего токена для всех пакетных запросов, который итеративно повторяется для создания выходной последовательности. Когда на сервер отправляются новые запросы, следующий шаг декодирования должен ждать, чтобы можно было выполнить этап предварительного заполнения для новых запросов. Это должно произойти до того, как эти новые запросы будут включены в последующие этапы непрерывного пакетного декодирования. Из-за аппаратных ограничений непрерывная пакетная обработка, используемая для декодирования, может включать не все запросы. На этом этапе запросы попадают в очередь обработки, и задержка вывода начинает значительно увеличиваться при незначительном приросте пропускной способности.
Анализ сравнительного анализа задержки LLM можно разделить на задержку предварительного заполнения, задержку декодирования и задержку очереди. Время, затрачиваемое каждым из этих компонентов, принципиально разное по своей природе: предварительное заполнение — это одноразовое вычисление, декодирование происходит один раз для каждого токена в выходной последовательности, а организация очереди включает процессы пакетной обработки на сервере. Когда обрабатывается несколько одновременных запросов, становится трудно отделить задержки от каждого из этих компонентов, поскольку задержка, испытываемая любым клиентским запросом, включает в себя задержки в очереди, вызванные необходимостью предварительного заполнения новых одновременных запросов, а также задержки в очереди, вызванные включением запроса в процессах пакетного декодирования. По этой причине в этой статье основное внимание уделяется задержке сквозной обработки. Перелом на кривой задержки-пропускной способности возникает в точке насыщения, когда задержки в очереди начинают значительно увеличиваться. Это явление происходит для любого сервера вывода моделей и обусловлено спецификациями ускорителя.
Общие требования во время развертывания включают соблюдение минимально необходимой пропускной способности, максимально допустимой задержки, максимальной стоимости в час и максимальной стоимости создания 1 миллиона токенов. Вы должны обусловить эти требования полезными данными, которые представляют запросы конечных пользователей. Проект, отвечающий этим требованиям, должен учитывать множество факторов, включая конкретную архитектуру модели, размер модели, типы экземпляров и количество экземпляров (горизонтальное масштабирование). В следующих разделах мы сосредоточимся на развертывании конечных точек, чтобы минимизировать задержку, максимизировать пропускную способность и минимизировать затраты. В этом анализе учитывается всего 512 токенов и 256 выходных токенов.
Минимизируйте задержку
Задержка является важным требованием во многих случаях использования в реальном времени. В следующей таблице мы рассмотрим минимальную задержку для каждой модели и каждого типа экземпляра. Вы можете добиться минимальной задержки, установив MAX_CONCURRENT_REQUESTS = 1.
| Минимальная задержка (мс/токен) | |||||
| Модель ID | мл.g5.2xбольшой | мл.g5.12xбольшой | мл.g5.48xбольшой | мл.p4d.24xlarge | ml.p4de.24xlarge |
| Лама 2 7Б | 33 | 17 | 18 | 20 | - |
| Лама 2 7B Чат | 33 | 17 | 18 | 20 | - |
| Лама 2 13Б | - | 22 | 23 | 23 | - |
| Лама 2 13B Чат | - | 23 | 23 | 23 | - |
| Лама 2 70Б | - | - | 57 | 43 | - |
| Лама 2 70B Чат | - | - | 57 | 45 | - |
| Мистраль 7Б | 35 | - | - | - | - |
| Мистраль 7Б Инструктировать | 35 | - | - | - | - |
| Микстрал 8х7Б | - | - | 33 | 27 | - |
| Сокол 7B | 33 | - | - | - | - |
| Сокол 7Б Инструктировать | 33 | - | - | - | - |
| Сокол 40B | - | 53 | 33 | 27 | - |
| Сокол 40Б Инструктировать | - | 53 | 33 | 28 | - |
| Сокол 180B | - | - | - | - | 42 |
| Сокол 180B Чат | - | - | - | - | 42 |
Чтобы добиться минимальной задержки для модели, вы можете использовать следующий код, заменяя желаемый идентификатор модели и тип экземпляра:
Обратите внимание, что значения задержки меняются в зависимости от количества входных и выходных токенов. Однако процесс развертывания остается прежним, за исключением переменных среды. MAX_INPUT_TOKENS и MAX_TOTAL_TOKENS. Здесь эти переменные среды установлены, чтобы гарантировать требования к задержке конечной точки, поскольку более крупные входные последовательности могут нарушить требования к задержке. Обратите внимание, что SageMaker JumpStart уже предоставляет другие оптимальные переменные среды при выборе типа экземпляра; например, использование ml.g5.12xlarge установит SM_NUM_GPUS до 4 в модельной среде.
Максимальная пропускная способность
В этом разделе мы максимизируем количество генерируемых токенов в секунду. Обычно это достигается при максимальном допустимом количестве одновременных запросов для модели и типа экземпляра. В следующей таблице мы сообщаем о пропускной способности, достигнутой при максимальном значении одновременного запроса, достигнутом до наступления тайм-аута вызова SageMaker для любого запроса.
| Максимальная пропускная способность (токенов/сек), одновременные запросы | |||||
| Модель ID | мл.g5.2xбольшой | мл.g5.12xбольшой | мл.g5.48xбольшой | мл.p4d.24xlarge | ml.p4de.24xlarge |
| Лама 2 7Б | 486 (64) | 1214 (128) | 804 (128) | 2945 (512) | - |
| Лама 2 7B Чат | 493 (64) | 1207 (128) | 932 (128) | 3012 (512) | - |
| Лама 2 13Б | - | 787 (128) | 496 (64) | 3245 (512) | - |
| Лама 2 13B Чат | - | 782 (128) | 505 (64) | 3310 (512) | - |
| Лама 2 70Б | - | - | 124 (16) | 1585 (256) | - |
| Лама 2 70B Чат | - | - | 114 (16) | 1546 (256) | - |
| Мистраль 7Б | 947 (64) | - | - | - | - |
| Мистраль 7Б Инструктировать | 986 (128) | - | - | - | - |
| Микстрал 8х7Б | - | - | 701 (128) | 3196 (512) | - |
| Сокол 7B | 1340 (128) | - | - | - | - |
| Сокол 7Б Инструктировать | 1313 (128) | - | - | - | - |
| Сокол 40B | - | 244 (32) | 382 (64) | 2699 (512) | - |
| Сокол 40Б Инструктировать | - | 245 (32) | 415 (64) | 2675 (512) | - |
| Сокол 180B | - | - | - | - | 1100 (128) |
| Сокол 180B Чат | - | - | - | - | 1081 (128) |
Чтобы добиться максимальной пропускной способности модели, вы можете использовать следующий код:
Обратите внимание, что максимальное количество одновременных запросов зависит от типа модели, типа экземпляра, максимального количества входных токенов и максимального количества выходных токенов. Поэтому вам следует установить эти параметры перед установкой MAX_CONCURRENT_REQUESTS.
Также обратите внимание, что пользователь, заинтересованный в минимизации задержки, часто находится в противоречии с пользователем, заинтересованным в максимизации пропускной способности. Первый заинтересован в ответах в реальном времени, тогда как второй заинтересован в пакетной обработке, чтобы очередь конечной точки всегда была насыщена, тем самым сводя к минимуму время простоя обработки. Пользователи, которые хотят максимизировать пропускную способность при условии соблюдения требований к задержке, часто заинтересованы в работе на изломе кривой задержки-пропускной способности.
Минимизируйте стоимость
Первый вариант минимизации затрат предполагает минимизацию почасовой оплаты. Благодаря этому вы можете развернуть выбранную модель на экземпляре SageMaker с наименьшими затратами в час. Цены на экземпляры SageMaker в реальном времени см. Цены на Amazon SageMaker. В общем, тип экземпляра по умолчанию для LLM SageMaker JumpStart — это самый дешевый вариант развертывания.
Второй вариант минимизации затрат предполагает минимизацию затрат на генерацию 1 миллиона токенов. Это простое преобразование таблицы, которую мы обсуждали ранее, для максимизации пропускной способности, где вы можете сначала вычислить время в часах, необходимое для генерации 1 миллиона токенов (1e6 / пропускная способность / 3600). Затем вы можете умножить это время, чтобы сгенерировать 1 миллион токенов с ценой за час указанного экземпляра SageMaker.
Обратите внимание, что инстансы с наименьшей стоимостью часа — это не то же самое, что инстансы с наименьшими затратами на создание 1 миллиона токенов. Например, если запросы на вызов носят спорадический характер, оптимальным может быть экземпляр с наименьшей стоимостью в час, тогда как в сценариях регулирования более подходящей может быть наименьшая стоимость создания миллиона токенов.
Тензорная параллель и компромисс между несколькими моделями
Во всех предыдущих анализах мы рассматривали развертывание одной реплики модели со степенью тензорной параллельности, равной количеству графических процессоров в типе экземпляра развертывания. Это поведение JumpStart SageMaker по умолчанию. Однако, как отмечалось ранее, сегментирование модели может улучшить задержку и пропускную способность модели только до определенного предела, за которым требования связи между устройствами доминируют над временем вычислений. Это означает, что часто бывает выгоднее развертывать в одном экземпляре несколько моделей с более низкой степенью тензорной параллели, чем одну модель с более высокой степенью тензорной параллели.
Здесь мы развертываем конечные точки Llama 2 7B и 13B на экземплярах ml.p4d.24xlarge со степенями тензорной параллельности (TP) 1, 2, 4 и 8. Для ясности поведения модели каждая из этих конечных точек загружает только одну модель.
| . | Пропускная способность (токенов/сек) | Задержка (мс/токен) | ||||||||||||||||||
| Параллельные запросы | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 256 | 512 |
| Степень ТП | Лама 2 13Б | |||||||||||||||||||
| 1 | 38 | 74 | 147 | 278 | 443 | 612 | 683 | 722 | - | - | 26 | 27 | 27 | 29 | 37 | 45 | 87 | 174 | - | - |
| 2 | 49 | 92 | 183 | 351 | 604 | 985 | 1435 | 1686 | 1726 | - | 21 | 22 | 22 | 22 | 25 | 32 | 46 | 91 | 159 | - |
| 4 | 46 | 94 | 181 | 343 | 655 | 1073 | 1796 | 2408 | 2764 | 2819 | 23 | 21 | 21 | 24 | 25 | 30 | 37 | 57 | 111 | 172 |
| 8 | 44 | 86 | 158 | 311 | 552 | 1015 | 1654 | 2450 | 3087 | 3180 | 22 | 24 | 26 | 26 | 29 | 36 | 42 | 57 | 95 | 152 |
| . | Лама 2 7Б | |||||||||||||||||||
| 1 | 62 | 121 | 237 | 439 | 778 | 1122 | 1569 | 1773 | 1775 | - | 16 | 16 | 17 | 18 | 22 | 28 | 43 | 88 | 151 | - |
| 2 | 62 | 122 | 239 | 458 | 780 | 1328 | 1773 | 2440 | 2730 | 2811 | 16 | 16 | 17 | 18 | 21 | 25 | 38 | 56 | 103 | 182 |
| 4 | 60 | 106 | 211 | 420 | 781 | 1230 | 2206 | 3040 | 3489 | 3752 | 17 | 19 | 20 | 18 | 22 | 27 | 31 | 45 | 82 | 132 |
| 8 | 49 | 97 | 179 | 333 | 612 | 1081 | 1652 | 2292 | 2963 | 3004 | 22 | 20 | 24 | 26 | 27 | 33 | 41 | 65 | 108 | 167 |
Наш предыдущий анализ уже показал значительные преимущества в пропускной способности на экземплярах ml.p4d.24xlarge, что часто приводит к повышению производительности с точки зрения затрат на создание 1 миллиона токенов по сравнению с семейством экземпляров g5 в условиях высокой нагрузки по одновременным запросам. Этот анализ ясно показывает, что вам следует рассмотреть компромисс между сегментированием модели и репликацией модели в пределах одного экземпляра; то есть полностью сегментированная модель обычно не является лучшим вариантом использования вычислительных ресурсов ml.p4d.24xlarge для семейств моделей 7B и 13B. Фактически, для семейства моделей 7B вы получаете лучшую пропускную способность для одной реплики модели со степенью тензорной параллельности 4 вместо 8.
Отсюда можно экстраполировать, что конфигурация с самой высокой пропускной способностью для модели 7B включает степень тензорной параллели 1 с восемью репликами модели, а конфигурация с самой высокой пропускной способностью для модели 13B, вероятно, представляет собой степень тензорной параллели 2 с четырьмя репликами модели. Чтобы узнать больше о том, как это сделать, см. Сократите затраты на развертывание модели в среднем на 50 %, используя новейшие функции Amazon SageMaker., который демонстрирует использование конечных точек на основе компонентов вывода. Из-за методов балансировки нагрузки, маршрутизации серверов и совместного использования ресурсов ЦП вы не можете полностью добиться улучшения пропускной способности, точно равного количеству реплик, умноженному на пропускную способность одной реплики.
Горизонтальное масштабирование
Как отмечалось ранее, каждое развертывание конечной точки имеет ограничение на количество одновременных запросов в зависимости от количества входных и выходных токенов, а также типа экземпляра. Если это не соответствует вашим требованиям к пропускной способности или одновременным запросам, вы можете выполнить масштабирование для использования более одного экземпляра за развернутой конечной точкой. SageMaker автоматически выполняет балансировку нагрузки запросов между экземплярами. Например, следующий код развертывает конечную точку, поддерживаемую тремя экземплярами:
В следующей таблице показан прирост пропускной способности в зависимости от количества экземпляров для модели Llama 2 7B.
| . | . | Пропускная способность (токенов/сек) | Задержка (мс/токен) | ||||||||||||||
| . | Параллельные запросы | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 | 1 | 2 | 4 | 8 | 16 | 32 | 64 | 128 |
| Количество экземпляров | Тип экземпляра | Общее количество токенов: 512, Количество выходных токенов: 256 | |||||||||||||||
| 1 | мл.g5.2xбольшой | 30 | 60 | 115 | 210 | 351 | 484 | 492 | - | 32 | 33 | 34 | 37 | 45 | 93 | 160 | - |
| 2 | мл.g5.2xбольшой | 30 | 60 | 115 | 221 | 400 | 642 | 922 | 949 | 32 | 33 | 34 | 37 | 42 | 53 | 94 | 167 |
| 3 | мл.g5.2xбольшой | 30 | 60 | 118 | 228 | 421 | 731 | 1170 | 1400 | 32 | 33 | 34 | 36 | 39 | 47 | 57 | 110 |
Примечательно, что перегиб на кривой задержки и пропускной способности смещается вправо, поскольку большее количество экземпляров может обрабатывать большее количество одновременных запросов в конечной точке с несколькими экземплярами. В этой таблице значение одновременного запроса относится ко всей конечной точке, а не к числу одновременных запросов, которые получает каждый отдельный экземпляр.
Вы также можете использовать автомасштабирование — функцию для мониторинга рабочих нагрузок и динамической регулировки емкости для поддержания стабильной и предсказуемой производительности при минимальных затратах. Это выходит за рамки данного поста. Дополнительные сведения об автомасштабировании см. Настройка конечных точек логического вывода с автоматическим масштабированием в Amazon SageMaker.
Вызов конечной точки с одновременными запросами
Предположим, у вас есть большой пакет запросов, которые вы хотели бы использовать для генерации ответов из развернутой модели в условиях высокой пропускной способности. Например, в следующем блоке кода мы компилируем список из 1,000 полезных нагрузок, каждая из которых запрашивает генерацию 100 токенов. В целом мы запрашиваем генерацию 100,000 XNUMX токенов.
При отправке большого количества запросов к API среды выполнения SageMaker могут возникнуть ошибки регулирования. Чтобы смягчить это, вы можете создать собственный клиент среды выполнения SageMaker, который увеличивает количество повторных попыток. Вы можете предоставить полученный объект сеанса SageMaker либо JumpStartModel конструктор или sagemaker.predictor.retrieve_default если вы хотите прикрепить новый предиктор к уже развернутой конечной точке. В следующем коде мы используем этот объект сеанса при развертывании модели Llama 2 с конфигурациями SageMaker JumpStart по умолчанию:
Эта развернутая конечная точка имеет MAX_CONCURRENT_REQUESTS = 128 по умолчанию. В следующем блоке мы используем библиотеку параллельных фьючерсов для перебора вызова конечной точки для всех полезных нагрузок со 128 рабочими потоками. В лучшем случае конечная точка обработает 128 одновременных запросов, и всякий раз, когда запрос возвращает ответ, исполнитель немедленно отправляет новый запрос в конечную точку.
В результате всего создается 100,000 1255 токенов с пропускной способностью 5.2 токенов в секунду на одном экземпляре ml.g80xlarge. Обработка занимает около XNUMX секунд.
Обратите внимание, что это значение пропускной способности заметно отличается от максимальной пропускной способности для Llama 2 7B на ml.g5.2xlarge в предыдущих таблицах этого поста (486 токенов/сек при 64 одновременных запросах). Это связано с тем, что входные полезные данные используют 8 токенов вместо 256, количество выходных токенов составляет 100 вместо 256, а меньшее количество токенов позволяет выполнять 128 одновременных запросов. Это последнее напоминание о том, что все значения задержки и пропускной способности зависят от полезной нагрузки! Изменение количества токенов полезной нагрузки повлияет на процессы пакетной обработки во время обслуживания модели, что, в свою очередь, повлияет на время предварительного заполнения, декодирования и очереди для вашего приложения.
Заключение
В этом посте мы представили сравнительный анализ LLM SageMaker JumpStart, включая Llama 2, Mistral и Falcon. Мы также представили руководство по оптимизации задержки, пропускной способности и стоимости конфигурации развертывания конечной точки. Вы можете начать работу, запустив связанный блокнот для сравнения вашего варианта использования.
Об авторах
 Доктор Кайл Ульрих — ученый-прикладник в команде Amazon SageMaker JumpStart. Его исследовательские интересы включают масштабируемые алгоритмы машинного обучения, компьютерное зрение, временные ряды, байесовские непараметрические и гауссовские процессы. Его докторская степень получена в Университете Дьюка, и он опубликовал статьи в NeurIPS, Cell и Neuron.
Доктор Кайл Ульрих — ученый-прикладник в команде Amazon SageMaker JumpStart. Его исследовательские интересы включают масштабируемые алгоритмы машинного обучения, компьютерное зрение, временные ряды, байесовские непараметрические и гауссовские процессы. Его докторская степень получена в Университете Дьюка, и он опубликовал статьи в NeurIPS, Cell и Neuron.
 Dr. Вивек Мадан — ученый-прикладник в команде Amazon SageMaker JumpStart. Он получил докторскую степень в Университете Иллинойса в Урбана-Шампейн и был постдокторантом в Технологическом институте Джорджии. Он является активным исследователем в области машинного обучения и разработки алгоритмов и публиковал статьи на конференциях EMNLP, ICLR, COLT, FOCS и SODA.
Dr. Вивек Мадан — ученый-прикладник в команде Amazon SageMaker JumpStart. Он получил докторскую степень в Университете Иллинойса в Урбана-Шампейн и был постдокторантом в Технологическом институте Джорджии. Он является активным исследователем в области машинного обучения и разработки алгоритмов и публиковал статьи на конференциях EMNLP, ICLR, COLT, FOCS и SODA.
 Доктор Ашиш Хетан является старшим научным сотрудником Amazon SageMaker JumpStart и помогает разрабатывать алгоритмы машинного обучения. Он получил докторскую степень в Университете Иллинойса в Урбане-Шампейне. Он является активным исследователем в области машинного обучения и статистических выводов и опубликовал множество статей на конференциях NeurIPS, ICML, ICLR, JMLR, ACL и EMNLP.
Доктор Ашиш Хетан является старшим научным сотрудником Amazon SageMaker JumpStart и помогает разрабатывать алгоритмы машинного обучения. Он получил докторскую степень в Университете Иллинойса в Урбане-Шампейне. Он является активным исследователем в области машинного обучения и статистических выводов и опубликовал множество статей на конференциях NeurIPS, ICML, ICLR, JMLR, ACL и EMNLP.
 Жоао Моура — старший специалист по архитектуре решений AI/ML в AWS. Жоао помогает клиентам AWS — от небольших стартапов до крупных предприятий — эффективно обучать и развертывать крупные модели, а также более широко создавать платформы машинного обучения на AWS.
Жоао Моура — старший специалист по архитектуре решений AI/ML в AWS. Жоао помогает клиентам AWS — от небольших стартапов до крупных предприятий — эффективно обучать и развертывать крупные модели, а также более широко создавать платформы машинного обучения на AWS.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/machine-learning/benchmark-and-optimize-endpoint-deployment-in-amazon-sagemaker-jumpstart/
- :имеет
- :является
- :нет
- :куда
- $UP
- 000
- 1
- 10
- 100
- 11
- 116
- 12
- 14
- 150
- 16
- 17
- 20
- 24
- 28
- 30
- 32
- 60
- 600
- 70
- 8
- 80
- a
- A100
- в состоянии
- О нас
- выше
- ускоритель
- ускорители
- принятие
- доступ
- выполнять
- По
- Достигать
- достигнутый
- через
- активации
- активный
- приспосабливать
- дополнительный
- Дополнительно
- регулировать
- Преимущества
- влиять на
- После
- против
- совокупный
- AI / ML
- алгоритм
- алгоритмы
- выравнивать
- Все
- позволять
- разрешено
- позволяет
- в одиночестве
- уже
- причислены
- Несмотря на то, что
- всегда
- Amazon
- Создатель мудреца Амазонки
- Amazon SageMaker JumpStart
- Amazon Web Services
- количество
- an
- анализирует
- анализ
- и
- Другой
- любой
- API
- Применение
- прикладной
- подхода
- соответствующий
- приблизительный
- примерно
- архитектура
- МЫ
- AS
- связанный
- предположения
- At
- прикреплять
- попытки
- внимание
- автоматически
- доступен
- в среднем
- избежать
- AWS
- b
- Остатки
- Балансировка
- Пропускная способность
- основанный
- в основном
- дозирующий
- байесовский
- BE
- , так как:
- становится
- до
- поведение
- за
- не являетесь
- верить
- эталонный тест
- бенчмаркинг
- тесты
- полезный
- польза
- Преимущества
- ЛУЧШЕЕ
- Лучшая
- между
- Beyond
- Заблокировать
- Блог
- связанный
- широкий
- широко
- бюджет
- строить
- но
- by
- кэш
- вычислять
- рассчитанный
- под названием
- CAN
- Может получить
- возможности
- Пропускная способность
- крышки
- заботится
- случаев
- случаев
- Вызывать
- ячейка
- определенный
- изменение
- изменения
- характеристика
- Выберите
- выбранный
- ясность
- явно
- клиент
- код
- Связь
- сравнить
- комплекс
- компоненты
- комплексный
- вычисление
- вычислительный
- вычислительная мощность
- расчеты
- Вычисление
- компьютер
- Компьютерное зрение
- параллельный
- состояние
- Условия
- конференции
- Конфигурация
- Рассматривать
- считается
- считает
- ограничения
- потребленный
- содержит
- контекст
- (CIJ)
- непрерывно
- соответствующий
- Цена
- Расходы
- считать
- ЦП
- Создайте
- критической
- сырой
- Текущий
- кривая
- изготовленный на заказ
- Клиенты
- данным
- Решение
- решение
- Декодирование
- снижение
- уменьшается
- преданный
- По умолчанию
- определять
- определенный
- Определяет
- Степень
- демонстрировать
- демонстрирует
- зависимый
- в зависимости
- зависит
- развертывание
- развернуть
- развертывание
- развертывание
- развертывания
- развертывает
- глубина
- Производный
- описано
- Проект
- желанный
- подробность
- подробнее
- Определять
- определяет
- развивать
- устройство
- Устройства
- различный
- трудный
- уменьшающийся
- обсуждать
- обсуждается
- отчетливый
- распределенный
- не
- господствовать
- Dont
- время простоя
- dr
- управлять
- управляемый
- вождение
- два
- Герцог
- Университет Дюка
- в течение
- динамично
- каждый
- Ранее
- фактически
- эффективно
- 8
- или
- охватывала
- встреча
- впритык
- Конечная точка
- конечные точки
- окончания поездки
- достаточно
- Enter
- предприятий
- Весь
- Окружающая среда
- равный
- Равно
- ошибка
- ошибки
- особенно
- оценка
- Эфир (ETH)
- Даже
- со временем
- Каждая
- точно,
- пример
- Превышен
- Кроме
- проявлять
- существует
- дорогим
- опыт
- опытные
- объяснение
- Больше
- исследует
- выражение
- факт
- фактор
- факторы
- FAIL
- сокол
- семей
- семья
- выполнимый
- Особенность
- Особенности
- несколько
- фигура
- окончательный
- в заключение
- Найдите
- обнаружение
- First
- соответствовать
- Фокус
- фокусируется
- после
- Что касается
- Бывший
- формула
- вперед
- Год основания
- 4
- от
- полный
- полностью
- принципиально
- далее
- Более того
- Фьючерсная торговля
- Gain
- Доходы
- Общие
- порождать
- генерируется
- генерирует
- порождающий
- поколение
- ГРУЗИИ
- получить
- данный
- Цели
- хорошо
- есть
- GPU / ГРАФИЧЕСКИЙ ПРОЦЕССОР
- Графические процессоры
- большой
- Растет
- Рост
- гарантия
- Охрана
- инструкция
- обрабатывать
- Аппаратные средства
- Есть
- he
- главы
- сильно
- помощь
- помогает
- здесь
- High
- на высшем уровне
- высший
- наивысший
- его
- держать
- горизонтальный
- час
- ЧАСЫ
- Как
- How To
- Однако
- HTTPS
- i
- ICLR
- ID
- идеальный
- Идеально
- определения
- if
- Иллинойс
- немедленно
- Влияние
- Воздействие
- Импортировать
- важную
- важно
- улучшать
- улучшение
- улучшение
- улучшается
- in
- включают
- включены
- В том числе
- включение
- Входящий
- Увеличение
- расширились
- Увеличивает
- повышение
- individual
- вход
- затраты
- пример
- случаев
- вместо
- заинтересованный
- интересы
- Intermediate
- в
- включает в себя
- IT
- ЕГО
- JPG
- оправданный
- ключи
- Вид
- залив
- язык
- большой
- Крупные предприятия
- больше
- крупнейших
- Задержка
- новее
- последний
- слой
- вести
- УЧИТЬСЯ
- изучение
- уход
- оставил
- Длина
- Библиотека
- ЖИЗНЬЮ
- такое как
- Вероятно
- ОГРАНИЧЕНИЯ
- ограничение
- Ограниченный
- рамки
- линия
- Список
- Лама
- загрузка
- погрузка
- расположение
- дольше
- посмотреть
- Низкий
- ниже
- низший
- машина
- обучение с помощью машины
- сделанный
- поддерживать
- сделать
- многих
- Максимизировать
- максимизирует
- максимизации
- максимальный
- Май..
- смысл
- означает
- размеры
- механизм
- механизмы
- Встречайте
- Память
- упомянутый
- встретивший
- методы
- может быть
- миллиона
- минимизировать
- минимизация
- минимальный
- небольшая
- минут
- смягчать
- ML
- режим
- модель
- Модели
- Модерн
- монитор
- БОЛЕЕ
- самых
- с разными
- должен
- природа
- обязательно
- необходимо
- Необходимость
- НейриПС
- Новые
- следующий
- нет
- особенно
- в своих размышлениях
- отметил,
- номер
- номера
- объект
- наблюдения
- наблюдать
- наблюдается
- получать
- Очевидный
- происходить
- происходящий
- шансы
- of
- .
- on
- ONE
- только
- операционный
- операция
- Операционный отдел
- оптимальный
- Оптимизировать
- Опция
- or
- заказ
- Другое
- Другое
- в противном случае
- наши
- выходной
- за
- бумага
- Параллельные
- параметр
- параметры
- особый
- pass
- проходит
- паттеранами
- Пауза
- для
- выполнять
- производительность
- выполняет
- кандидат наук
- явление
- Платформы
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- плюс
- Точка
- состояния потока
- населенный
- возможное
- После
- мощностью
- практическое
- предшествующий
- Точно
- предсказывать
- предсказуемый
- прогноз
- Predictor
- предпочитать
- представлены
- предотвращать
- предыдущий
- предварительно
- цена
- цены
- первичный
- Принципы
- Расставляйте приоритеты
- процесс
- обрабатываемых
- Процессы
- обработка
- производит
- для защиты
- обеспечивать
- при условии
- приводит
- публично
- опубликованный
- цель
- Запросы
- повышение
- Стоимость
- скорее
- соотношение
- достигать
- реальные
- реальная жизнь
- реального времени
- причина
- получает
- рекомендовать
- рекомендаций
- уменьшить
- снижает
- относиться
- назвало
- режим
- диеты
- отношения
- Отношения
- оставаться
- осталось
- остатки
- напоминание
- повторный
- ответ
- копирование
- отчету
- представлять
- запросить
- запрашивающий
- Запросы
- требовать
- обязательный
- требование
- Требования
- требуется
- исследованиям
- исследователь
- ресурс
- Полезные ресурсы
- уважение
- ответ
- ответы
- в результате
- Итоги
- Возвращает
- правую
- маршрутизация
- РЯД
- Правило
- Run
- Бег
- sagemaker
- то же
- масштабируемые
- Шкала
- масштабирование
- сценарий
- Сценарии
- Ученый
- сфера
- Во-вторых
- секунды
- Раздел
- разделах
- посмотреть
- видел
- выберите
- выбранный
- выбор
- выбор
- Отправить
- отправка
- старший
- смысл
- послать
- отдельный
- Последовательность
- Серии
- служил
- сервер
- серверы
- Услуги
- выступающей
- Сессия
- набор
- установка
- сегментированный
- Sharding
- Поделиться
- разделение
- Смены
- должен
- показал
- Шоу
- значительный
- существенно
- аналогичный
- просто
- одновременно
- одинарной
- Размер
- небольшой
- меньше
- So
- Software
- Решения
- некоторые
- Источник
- специалист
- конкретный
- спецификации
- указанный
- функции
- скорость
- раскол
- спорадический
- стандарт
- Начало
- и политические лидеры
- начинается
- Стартапы
- статистический
- устойчивый
- Шаг
- Шаги
- По-прежнему
- Stop
- Кабинет
- последующее
- существенный
- такие
- подходящее
- поддержка
- Поддержанный
- система
- ТАБЛИЦЫ
- портняжное дело
- взять
- Takeaways
- принимает
- команда
- технологии
- снижения вреда
- Тенденцию
- срок
- terms
- тестXNUMX
- чем
- который
- Ассоциация
- Источник
- их
- тогда
- теоретический
- теория
- Там.
- тем самым
- следовательно
- Эти
- они
- вещи
- этой
- те
- три
- Через
- пропускная способность
- время
- Временные ряды
- раз
- в
- вместе
- знак
- Лексемы
- слишком
- Всего
- tp
- прослеживать
- Train
- перевод
- переводы
- трансформация
- трансформатор
- правда
- ОЧЕРЕДЬ
- два
- напишите
- Типы
- типично
- под
- понимать
- понимание
- Университет
- Применение
- использование
- прецедент
- используемый
- Информация о пользователе
- Пользовательский опыт
- пользователей
- использования
- через
- использовать
- действительный
- ценностное
- Наши ценности
- изменения
- разнообразие
- проверить
- разносторонний
- очень
- с помощью
- видение
- vs
- ждать
- хотеть
- теплый
- законопроект
- Путь..
- способы
- we
- Web
- веб-сервисы
- ЧТО Ж
- были
- Что
- Что такое
- когда
- когда бы ни
- в то время как
- который
- в то время как
- КТО
- будете
- в
- без
- Работа
- работник
- бы
- еще
- уступая
- являетесь
- ВАШЕ
- зефирнет