Изображение по автору
Когда вы начинаете заниматься машинным обучением, логистическая регрессия — это один из первых алгоритмов, который вы добавите в свой набор инструментов. Это простой и надежный алгоритм, обычно используемый для задач двоичной классификации.
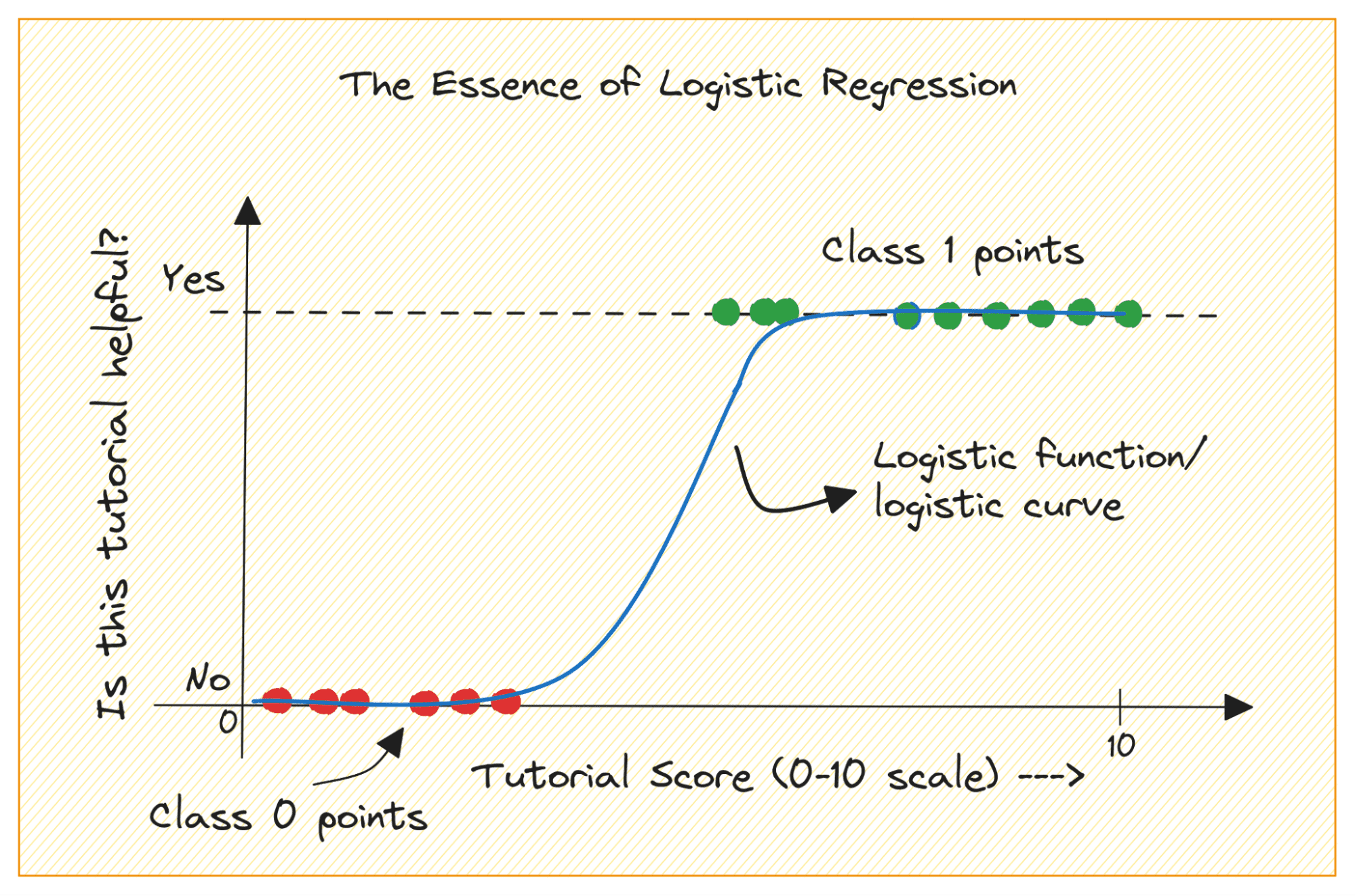
Рассмотрим задачу двоичной классификации с классами 0 и 1. Логистическая регрессия подбирает логистическую или сигмовидную функцию к входным данным и предсказывает вероятность принадлежности точки данных запроса к классу 1. Интересно, да?
В этом уроке мы узнаем о логистической регрессии с нуля, охватив:
- Логистическая (или сигмовидная) функция
- Как мы переходим от линейной к логистической регрессии
- Как работает логистическая регрессия
Наконец, мы построим простую модель логистической регрессии, чтобы классифицировать сигналы РАДАР из ионосферы.
Прежде чем мы узнаем больше о логистической регрессии, давайте рассмотрим, как работает логистическая функция. Логистическая (или сигмовидная функция) определяется как:

Когда вы построите сигмовидную функцию, она будет выглядеть так:
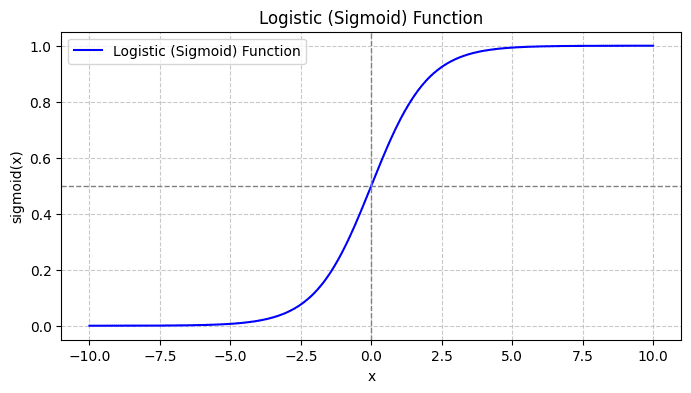
Из сюжета мы видим, что:
- Когда x = 0, σ(x) принимает значение 0.5.
- Когда x приближается к +∞, σ(x) приближается к 1.
- Когда x приближается к -∞, σ(x) приближается к 0.
Таким образом, для всех реальных входных данных сигмовидная функция сжимает их, чтобы они принимали значения в диапазоне [0, 1].
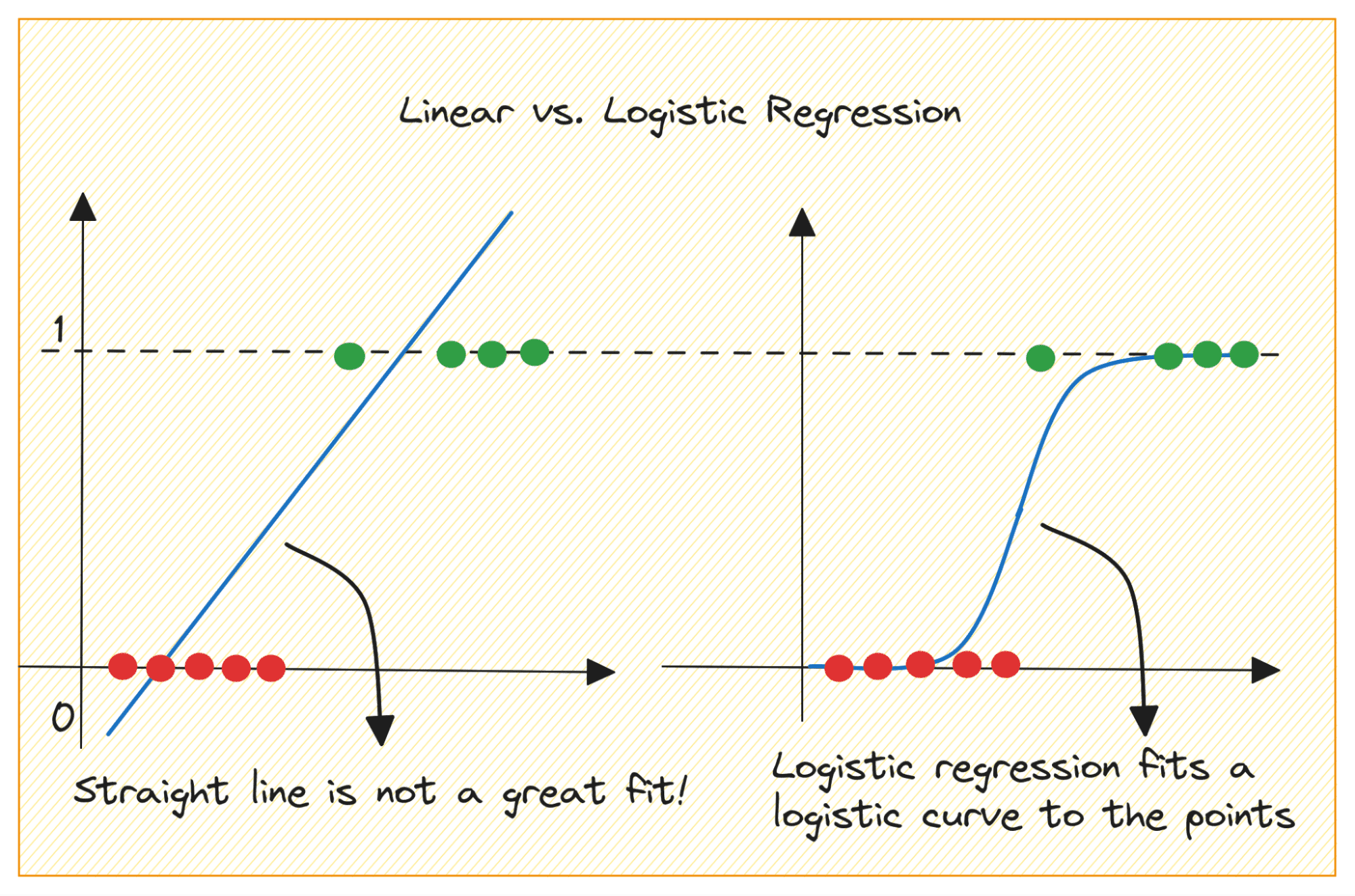
Давайте сначала обсудим, почему мы не можем использовать линейную регрессию для задачи бинарной классификации.
В задаче бинарной классификации результатом является категориальная метка (0 или 1). Поскольку линейная регрессия прогнозирует выходные данные с непрерывными значениями, которые могут быть меньше 0 или больше 1, это не имеет смысла для рассматриваемой проблемы.
Кроме того, прямая линия может оказаться не лучшим вариантом, если выходные метки принадлежат к одной из двух категорий.
Изображение по автору
Так как же нам перейти от линейной к логистической регрессии? В линейной регрессии прогнозируемый результат определяется следующим образом:
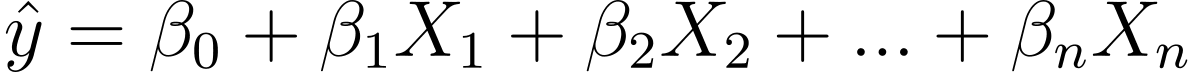
Где βs — это коэффициенты, а X_is — предикторы (или функции).
Без ограничения общности предположим, что X_0 = 1:

Таким образом, мы можем иметь более краткое выражение:
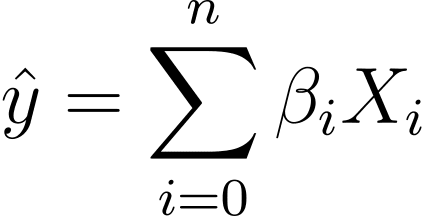
В логистической регрессии нам нужна прогнозируемая вероятность p_i в интервале [0,1]. Мы знаем, что логистическая функция сжимает входные данные так, что они принимают значения в интервале [0,1].
Таким образом, подставив это выражение в логистическую функцию, мы получим прогнозируемую вероятность как:
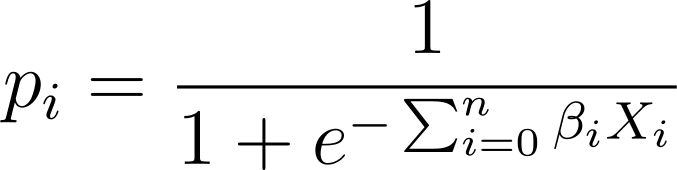
Так как же нам найти наиболее подходящую логистическую кривую для данного набора данных? Чтобы ответить на этот вопрос, давайте разберемся с оценкой максимального правдоподобия.
Оценка максимального правдоподобия (MLE) используется для оценки параметров модели логистической регрессии путем максимизации функции правдоподобия. Давайте разберем процесс MLE в логистической регрессии и то, как формулируется функция стоимости для оптимизации с использованием градиентного спуска.
Разбивка оценки максимального правдоподобия
Как уже говорилось, мы моделируем вероятность возникновения двоичного результата как функцию одной или нескольких переменных-предикторов (или признаков):
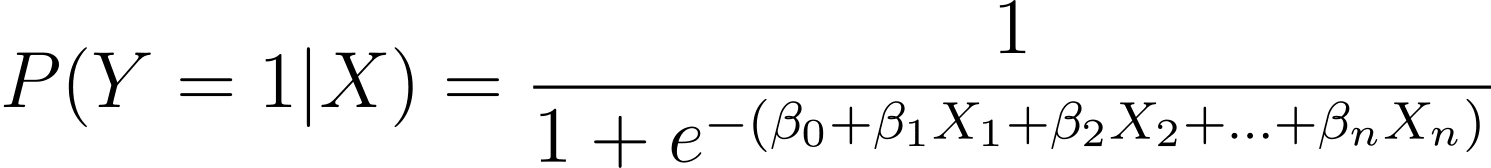
Здесь βs — это параметры или коэффициенты модели. X_1, X_2,…, X_n — переменные-предикторы.
MLE стремится найти значения β, которые максимизируют вероятность наблюдаемых данных. Функция правдоподобия, обозначаемая как L (β), представляет вероятность наблюдения заданных результатов для заданных значений предикторов в рамках модели логистической регрессии.
Формулировка функции логарифмического правдоподобия
Чтобы упростить процесс оптимизации, обычно используют функцию логарифмического правдоподобия. Потому что он преобразует произведения вероятностей в суммы логарифмических вероятностей.
Логарифмическая функция правдоподобия для логистической регрессии определяется следующим образом:
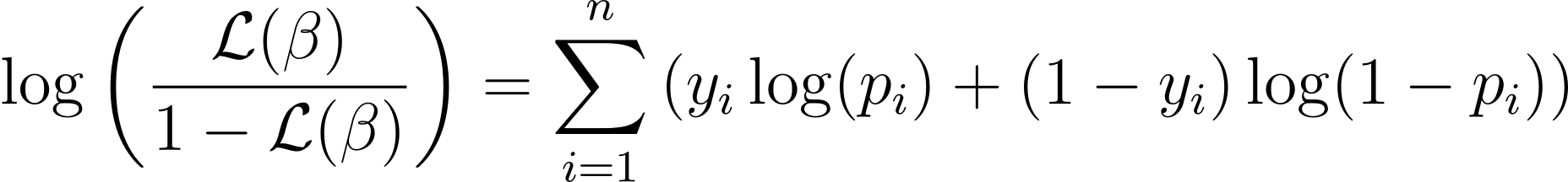
Теперь, когда мы знаем суть логарифмического правдоподобия, давайте перейдем к формулированию функции стоимости для логистической регрессии и последующего градиентного спуска для поиска лучших параметров модели.
Функция стоимости для логистической регрессии
Чтобы оптимизировать модель логистической регрессии, нам нужно максимизировать логарифмическую вероятность. Таким образом, мы можем использовать отрицательный логарифм правдоподобия в качестве функции стоимости для минимизации во время обучения. Отрицательная логарифмическая вероятность, часто называемая логистическими потерями, определяется как:
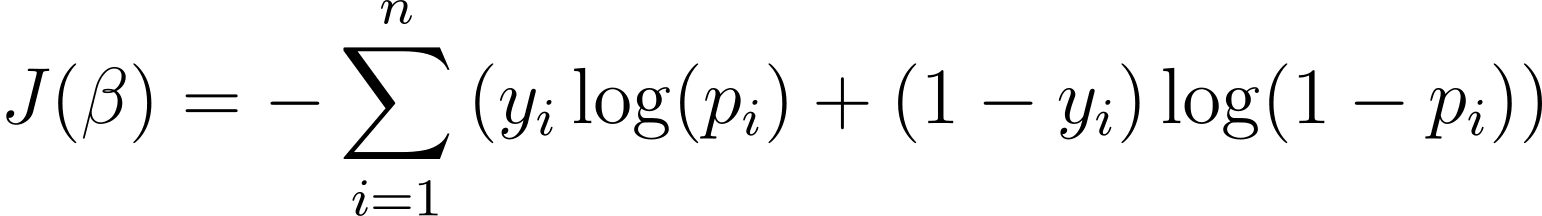
Таким образом, цель алгоритма обучения состоит в том, чтобы найти значения ? которые минимизируют эту функцию стоимости. Градиентный спуск — это широко используемый алгоритм оптимизации для поиска минимума этой функции стоимости.
Градиентный спуск в логистической регрессии
Градиентный спуск — это итерационный алгоритм оптимизации, который обновляет параметры модели β в направлении, противоположном градиенту функции стоимости по отношению к β. Правило обновления на шаге t+1 для логистической регрессии с использованием градиентного спуска выглядит следующим образом:
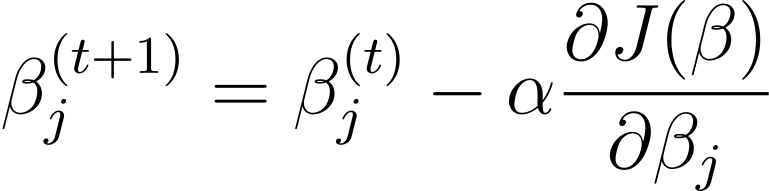
Где α — скорость обучения.
Частные производные можно вычислить с помощью цепного правила. Градиентный спуск итеративно обновляет параметры — до сходимости — с целью минимизировать логистические потери. По мере сходимости он находит оптимальные значения β, которые максимизируют вероятность наблюдаемых данных.
Теперь, когда вы знаете, как работает логистическая регрессия, давайте построим прогнозную модель, используя библиотеку scikit-learn.
Мы будем использовать набор данных ионосферы из репозитория машинного обучения UCI для этого урока. Набор данных содержит 34 числовых объекта. Выходные данные являются двоичными: «хорошие» или «плохие» (обозначаются «g» или «b»). Выходная метка «хорошо» относится к сигналам радара, обнаружившим некоторую структуру в ионосфере.
Шаг 1 – Загрузка набора данных
Сначала загрузите набор данных и считайте его в кадр данных pandas:
import pandas as pd
import urllib
url = "https://archive.ics.uci.edu/ml/machine-learning-databases/ionosphere/iphere.data"
data = urllib.request.urlopen(url)
df = pd.read_csv(data, header=None)Шаг 2 – Исследование набора данных
Давайте посмотрим на первые несколько строк фрейма данных:
# Display the first few rows of the DataFrame
df.head()
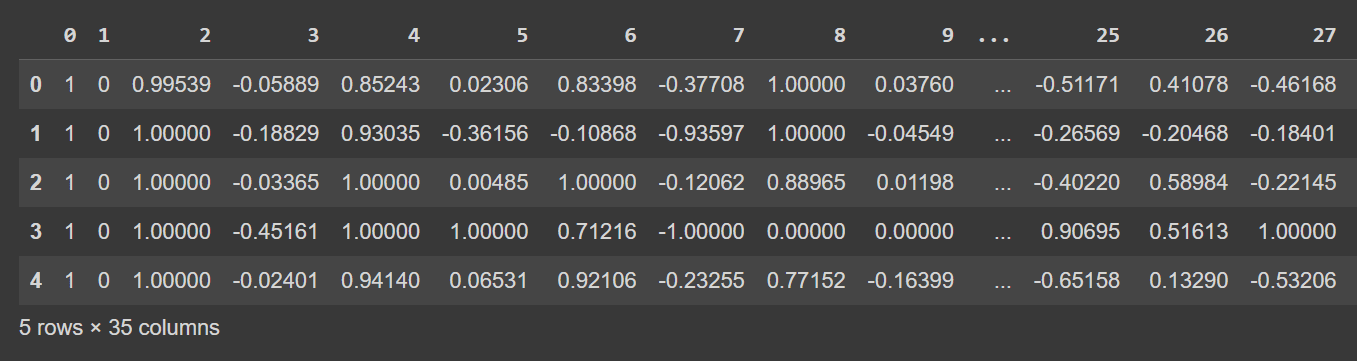
Усеченный вывод df.head()
Давайте получим некоторую информацию о наборе данных: количество ненулевых значений и типы данных каждого из столбцов:
# Get information about the dataset
print(df.info())
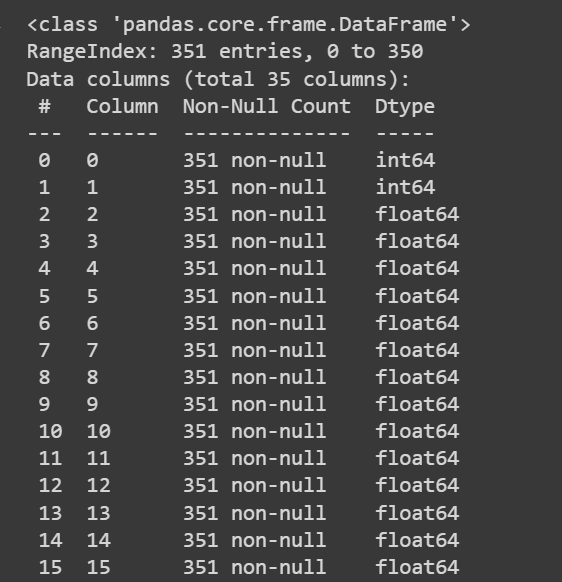 Усеченный вывод df.info()
Усеченный вывод df.info()
Поскольку у нас есть все числовые функции, мы также можем получить некоторую описательную статистику, используя describe() метод в кадре данных:
# Get descriptive statistics of the dataset
print(df.describe())
Усеченный вывод df.describe()
Имена столбцов в настоящее время находятся в диапазоне от 0 до 34, включая метку. Поскольку набор данных не предоставляет описательных имен для столбцов, он просто ссылается на них от атрибута_1 до атрибута_34, если вы хотите переименовать столбцы фрейма данных, как показано:
column_names = [
"attribute_1", "attribute_2", "attribute_3", "attribute_4", "attribute_5",
"attribute_6", "attribute_7", "attribute_8", "attribute_9", "attribute_10",
"attribute_11", "attribute_12", "attribute_13", "attribute_14", "attribute_15",
"attribute_16", "attribute_17", "attribute_18", "attribute_19", "attribute_20",
"attribute_21", "attribute_22", "attribute_23", "attribute_24", "attribute_25",
"attribute_26", "attribute_27", "attribute_28", "attribute_29", "attribute_30",
"attribute_31", "attribute_32", "attribute_33", "attribute_34", "class_label"
]
df.columns = column_names
Примечание. Этот шаг является необязательным. Если хотите, вы можете продолжить с именами столбцов по умолчанию.
# Display the first few rows of the DataFrame
df.head()
Усеченный вывод df.head() [после переименования столбцов]
Шаг 3 – Переименование меток классов и визуализация распределения классов
Поскольку метками выходного класса являются «g» и «b», нам нужно сопоставить их с 1 и 0 соответственно. Вы можете сделать это, используя map() or replace():
# Convert the class labels from 'g' and 'b' to 1 and 0, respectively
df["class_label"] = df["class_label"].replace({'g': 1, 'b': 0})
Давайте также визуализируем распределение меток классов:
import matplotlib.pyplot as plt
# Count the number of data points in each class
class_counts = df['class_label'].value_counts()
# Create a bar plot to visualize the class distribution
plt.bar(class_counts.index, class_counts.values)
plt.xlabel('Class Label')
plt.ylabel('Count')
plt.xticks(class_counts.index)
plt.title('Class Distribution')
plt.show()
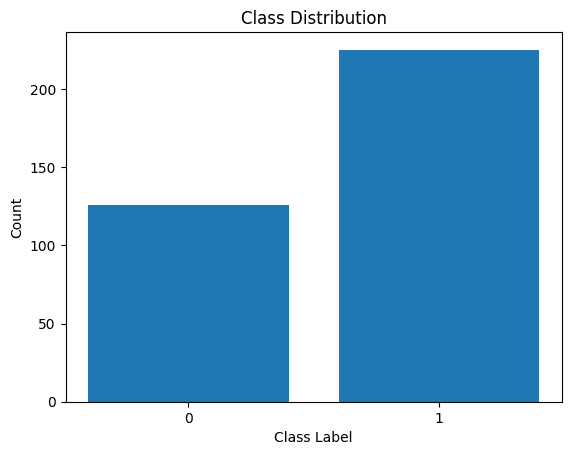
Распределение меток классов
Мы видим, что существует дисбаланс в распределении. Записей, принадлежащих классу 1, больше, чем классу 0. Этот дисбаланс классов мы устраним при построении модели логистической регрессии.
Шаг 5 – Предварительная обработка набора данных
Давайте соберем функции и выходные метки следующим образом:
X = df.drop('class_label', axis=1) # Input features
y = df['class_label'] # Target variable
После разделения набора данных на обучающий и тестовый наборы нам необходимо предварительно обработать набор данных.
Когда имеется много числовых объектов — каждый из которых потенциально имеет разный масштаб — нам необходимо предварительно обработать числовые объекты. Распространенный метод — преобразовать их так, чтобы они соответствовали распределению с нулевым средним значением и единичной дисперсией.
Ассоциация StandardScaler Модуль предварительной обработки scikit-learn помогает нам добиться этого.
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# Split the dataset into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Get the indices of the numerical features
numerical_feature_indices = list(range(34)) # Assuming the numerical features are in columns 0 to 33
# Initialize the StandardScaler
scaler = StandardScaler()
# Normalize the numerical features in the training set
X_train.iloc[:, numerical_feature_indices] = scaler.fit_transform(X_train.iloc[:, numerical_feature_indices])
# Normalize the numerical features in the test set using the trained scaler from the training set
X_test.iloc[:, numerical_feature_indices] = scaler.transform(X_test.iloc[:, numerical_feature_indices])Шаг 6 – Построение модели логистической регрессии
Теперь мы можем создать экземпляр классификатора логистической регрессии. LogisticRegression Класс является частью модуля линейной_модели scikit-learn.
Обратите внимание, что мы установили class_weight параметр на «сбалансированный». Это поможет нам учесть классовый дисбаланс. Путем присвоения каждому классу весов, обратно пропорциональных количеству записей в классах.
После создания экземпляра класса мы можем подогнать модель к набору обучающих данных:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression(class_weight='balanced')
model.fit(X_train, y_train)Шаг 7 – Оценка модели логистической регрессии
Вы можете позвонить в predict() метод для получения прогнозов модели.
В дополнение к показателю точности мы также можем получить отчет о классификации с такими показателями, как точность, полнота и показатель F1.
from sklearn.metrics import accuracy_score, classification_report
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
classification_rep = classification_report(y_test, y_pred)
print("Classification Report:n", classification_rep)
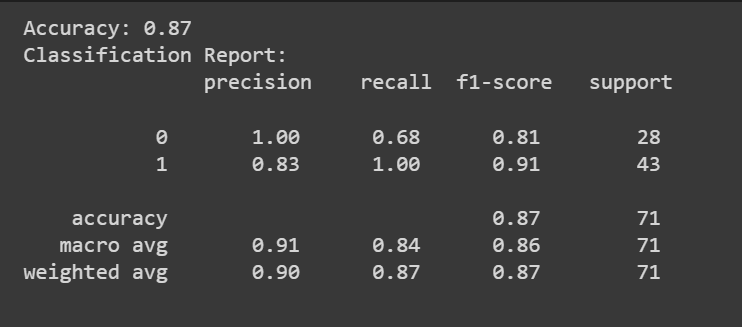
Поздравляем, вы закодировали свою первую модель логистической регрессии!
В этом уроке мы подробно узнали о логистической регрессии: от теории и математики до написания классификатора логистической регрессии.
В качестве следующего шага попробуйте построить модель логистической регрессии для подходящего набора данных по вашему выбору.
Набор данных по ионосфере доступен под лицензией Creative Commons Атрибуция 4.0 Международная (CC BY 4.0) лицензия:
Сигиллито В., Винг С., Хаттон Л. и Бейкер К.. (1989). Ионосфера. Репозиторий машинного обучения UCI. https://doi.org/10.24432/C5W01B.
Бала Прия С — разработчик и технический писатель из Индии. Ей нравится работать на стыке математики, программирования, науки о данных и создания контента. Сферы ее интересов и опыта включают DevOps, науку о данных и обработку естественного языка. Она любит читать, писать, программировать и пить кофе! В настоящее время она учится и делится своими знаниями с сообществом разработчиков, создавая учебные пособия, практические руководства, авторские статьи и многое другое.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://www.kdnuggets.com/building-predictive-models-logistic-regression-in-python?utm_source=rss&utm_medium=rss&utm_campaign=building-predictive-models-logistic-regression-in-python
- :является
- :нет
- $UP
- 1
- 10
- 11
- 13
- 20
- 33
- 7
- 9
- a
- О нас
- Учетная запись
- точность
- Достигать
- Добавить
- дополнение
- После
- Цель
- алгоритм
- алгоритмы
- Все
- причислены
- an
- и
- ответ
- подходы
- МЫ
- области
- AS
- предполагать
- At
- авторинга
- b
- пекарь
- Уравновешенный
- бар
- BE
- , так как:
- принадлежащий
- ЛУЧШЕЕ
- Ломать
- строить
- Строительство
- by
- призывают
- CAN
- не могу
- категории
- цепь
- выбор
- класс
- классов
- классификация
- закодированы
- Кодирование
- собирать
- Column
- Колонки
- Общий
- обычно
- Commons
- сообщество
- состоит из
- краткий
- содержание
- контентного создание
- конвертировать
- Цена
- покрытие
- Создайте
- создание
- В настоящее время
- кривая
- данным
- точки данных
- наука о данных
- набор данных
- По умолчанию
- определенный
- Производные
- подробность
- обнаруженный
- Застройщик
- DevOps
- различный
- направление
- обсуждать
- обсуждается
- Дисплей
- распределение
- do
- приносит
- вниз
- скачать
- в течение
- каждый
- сущность
- оценка
- оценки
- опыта
- Исследование
- выражение
- Особенности
- несколько
- Найдите
- обнаружение
- находит
- First
- соответствовать
- следовать
- следующим образом
- Что касается
- КАДР
- от
- функция
- получить
- получающий
- данный
- Go
- цель
- большой
- земля
- Гиды
- рука
- обрабатывать
- Есть
- помощь
- помогает
- ее
- Как
- HTTPS
- ICS
- if
- дисбаланс
- Импортировать
- in
- включают
- индекс
- Индия
- Индексы
- информация
- вход
- затраты
- интерес
- интересный
- пересечение
- в
- IT
- всего
- КДнаггетс
- Знать
- знания
- этикетка
- Этикетки
- язык
- УЧИТЬСЯ
- узнали
- изучение
- Меньше
- позволять
- Библиотека
- Лицензия
- Лицензирована
- такое как
- вероятность
- нравится
- линия
- погрузка
- журнал
- посмотреть
- выглядит как
- от
- машина
- обучение с помощью машины
- сделать
- многих
- карта
- математике
- Matplotlib
- Максимизировать
- максимизации
- максимальный
- Май..
- значить
- метод
- Метрика
- минимизировать
- минимальный
- модель
- Модели
- модуль
- БОЛЕЕ
- двигаться
- имена
- натуральный
- Естественный язык
- Обработка естественного языка
- Необходимость
- отрицательный
- следующий
- номер
- наблюдается
- of
- .
- on
- ONE
- Обзор
- противоположность
- оптимальный
- оптимизация
- Оптимизировать
- or
- Результат
- Результаты
- выходной
- выходы
- панд
- параметр
- параметры
- часть
- штук
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- Точка
- пунктов
- потенциально
- Точность
- предсказанный
- Predictions
- интеллектуального
- Predictor
- предсказывает
- предпочитать
- вероятность
- Проблема
- продолжить
- процесс
- обработка
- Продукция
- Программирование
- обеспечивать
- чисто
- Питон
- радар
- ассортимент
- Обменный курс
- Читать
- Reading
- реальные
- учет
- назвало
- понимается
- регресс
- отчету
- хранилище
- представляет
- запросить
- уважение
- соответственно
- Возвращает
- обзоре
- надежный
- Правило
- s
- Наука
- scikit учиться
- Гол
- посмотреть
- смысл
- набор
- Наборы
- разделение
- она
- показанный
- просто
- упростить
- So
- некоторые
- раскол
- и политические лидеры
- статистика
- Шаг
- прямой
- Структура
- впоследствии
- такие
- подходящее
- суммы
- взять
- принимает
- цель
- задачи
- Технический
- тестXNUMX
- Тестирование
- чем
- который
- Ассоциация
- Их
- теория
- Там.
- следовательно
- они
- этой
- Через
- в
- Ящик для инструментов
- Train
- специалистов
- Обучение
- Transform
- прообразы
- стараться
- учебник
- учебные пособия
- два
- Типы
- под
- понимать
- Ед. изм
- Обновление ПО
- Updates
- URL
- us
- аккаунт в США
- использование
- используемый
- через
- ценностное
- Наши ценности
- визуализации
- we
- когда
- который
- зачем
- Википедия.
- будете
- Крыло
- Работа
- работает
- работает
- бы
- писатель
- письмо
- X
- Да
- являетесь
- ВАШЕ
- зефирнет
- нуль







