В сообщении Представляем инструмент AWS ProServe Hadoop Migration Delivery Kit TCO, мы представили инструмент совокупной стоимости владения AWS ProServe Hadoop Migration Delivery Kit (HMDK) и рассказали о преимуществах миграции локальных рабочих нагрузок Hadoop в Амазонка ЭМИ. В этом посте мы углубимся в инструмент, пройдя все этапы от приема журналов, преобразования, визуализации и проектирования архитектуры до расчета совокупной стоимости владения.
Обзор решения
Давайте кратко рассмотрим основные функции инструмента HMDK TCO. Инструмент предоставляет сборщик журналов YARN для подключения диспетчера ресурсов Hadoop для сбора журналов YARN. Анализатор рабочей нагрузки Hadoop на основе Python, называемый анализатором журнала YARN, тщательно изучает приложения Hadoop. Amazon QuickSight информационные панели демонстрируют результаты анализатора. Те же результаты также ускоряют проектирование будущих экземпляров EMR. Кроме того, калькулятор совокупной стоимости владения генерирует оценку совокупной стоимости владения оптимизированного кластера EMR для облегчения миграции.
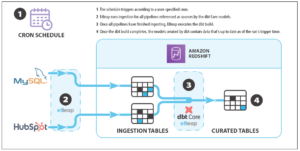
Теперь давайте посмотрим, как работает инструмент. На следующей диаграмме показан сквозной рабочий процесс.

В следующих разделах мы рассмотрим пять основных шагов инструмента:
- Соберите журналы истории заданий YARN.
- Преобразуйте журналы истории заданий из JSON в CSV.
- Проанализируйте журналы истории заданий.
- Разработайте кластер EMR для миграции.
- Рассчитать совокупную стоимость владения.
Предпосылки
Прежде чем приступить к работе, обязательно выполните следующие предварительные условия:
- Клонировать репозиторий hadoop-migration-assessment-tco.
- Установите Python 3 на свой локальный компьютер.
- Иметь учетную запись AWS с разрешением на AWS Lambda, QuickSight (версия для предприятий) и AWS CloudFormation.
Соберите журналы истории заданий YARN.
Сначала вы запускаете Сборщик журналов ПРЯЖИ, start-collector.sh на вашем локальном компьютере. На этом шаге собираются журналы Hadoop YARN и размещаются на вашем локальном компьютере. Сценарий соединяет ваш локальный компьютер с основным узлом Hadoop и взаимодействует с диспетчером ресурсов. Затем он извлекает информацию об истории заданий (журналы YARN из диспетчеров приложений), вызывая API приложения YARN ResourceManager.
Перед запуском сборщика журналов YARN необходимо настроить и установить соединение (HTTP: 8088 или HTTPS: 8090; рекомендуется последний вариант), чтобы проверить доступность YARN ResourceManager и включенного сервера YARN Timeline Server (поддерживается сервер Timeline v1 или более поздней версии). ). Вам может потребоваться определить интервал сбора журналов YARN и политику хранения. Чтобы убедиться, что вы собираете последовательные журналы YARN, вы можете использовать задание cron, чтобы запланировать сборщик журналов через надлежащий интервал времени. Например, для кластера Hadoop с 2,000 ежедневных приложений и значением параметра yarn.resourcemanager.max-completed-applications, установленным на 1,000, теоретически необходимо запустить сборщик журналов как минимум дважды, чтобы получить все журналы YARN. Кроме того, мы рекомендуем собирать журналы YARN как минимум за 7 дней для анализа комплексных рабочих нагрузок.
Дополнительные сведения о том, как настроить и запланировать сборщик журналов, см. репозиторий yarn-log-collector на GitHub.
Преобразование журналов истории заданий YARN из JSON в CSV
После получения журналов YARN вы запускаете организатор журналов YARN, yarn-log-organizer.py, который представляет собой синтаксический анализатор для преобразования журналов на основе JSON в файлы CSV. Эти выходные файлы CSV являются входными данными для анализатора журнала YARN. Парсер также имеет другие возможности, в том числе сортировку событий по времени, удаление выделений и объединение нескольких журналов.
Для получения дополнительной информации о том, как использовать органайзер журнала YARN, см. репозиторий yarn-log-organizer на GitHub.
Анализ журналов истории заданий YARN
Затем вы запускаете анализатор журналов YARN для анализа журналов YARN в формате CSV.
С помощью QuickSight вы можете визуализировать данные журнала YARN и проводить анализ наборов данных, созданных с помощью предварительно созданных шаблонов панели мониторинга и виджета. Виджет автоматически создает информационные панели QuickSight в целевой учетной записи AWS, настроенной в шаблоне CloudFormation.
Следующая диаграмма иллюстрирует архитектуру TCO HMDK.

Анализатор логов YARN предоставляет четыре основные функции:
- Загрузите преобразованные журналы истории заданий YARN в формате CSV (например,
cluster_yarn_logs_*.csv), Чтобы Простой сервис хранения Amazon (Amazon S3) ведра. Эти CSV-файлы являются выходными данными организатора журналов YARN. - Создайте JSON-файл манифеста (например,
yarn-log-manifest.json) для QuickSight и загрузите его в корзину S3: - Разверните панели мониторинга QuickSight с помощью шаблона CloudFormation в формате YAML. После развертывания нажимайте значок обновления, пока не увидите состояние стека как
CREATE_COMPLETE. На этом шаге создаются наборы данных на информационных панелях QuickSight в вашей целевой учетной записи AWS.
- На панели инструментов QuickSight вы можете найти информацию об анализируемых рабочих нагрузках Hadoop из различных диаграмм. Эти сведения помогут вам спроектировать будущие экземпляры EMR для ускорения миграции, как показано на следующем шаге.

Разработка кластера EMR для миграции
Результаты анализатора журнала YARN помогут вам понять фактические рабочие нагрузки Hadoop в существующей системе. Этот шаг ускоряет проектирование будущих экземпляров EMR для миграции с помощью Шаблон Excel. Шаблон содержит контрольный список для проведения анализа рабочей нагрузки и планирования емкости:
- Правильно ли используются приложения, работающие в кластере, с их текущей емкостью?
- Кластер находится под нагрузкой в определенное время или нет? Если да, то когда время?
- Какие типы приложений и механизмов (например, MR, TEZ или Spark) работают в кластере и каково использование ресурсов для каждого типа?
- Выполняются ли циклы выполнения разных заданий (в реальном времени, пакетные, специальные) в одном кластере?
- Выполняются ли какие-либо задания регулярными партиями, и если да, то каковы эти интервалы расписания? (Например, каждые 10 минут, 1 час, 1 день.) Есть ли у вас задания, требующие большого количества ресурсов в течение длительного периода времени?
- Требует ли какая-либо работа повышения производительности?
- Существуют ли какие-либо конкретные организации или отдельные лица, монополизирующие кластер?
- Работают ли какие-либо смешанные задания по разработке и эксплуатации в одном кластере?
Заполнив контрольный список, вы лучше поймете, как проектировать будущую архитектуру. Для оптимизации экономической эффективности кластера EMR в следующей таблице приведены общие рекомендации по выбору надлежащего типа кластера EMR и Эластичное вычислительное облако Amazon (Amazon EC2).

Чтобы выбрать правильный тип кластера и семейство экземпляров, необходимо выполнить несколько раундов анализа журналов YARN на основе различных критериев. Давайте посмотрим на некоторые ключевые показатели.
Лента
Вы можете найти шаблоны рабочей нагрузки на основе количества приложений Hadoop, запущенных во временном окне. Например, ежедневные или часовые диаграммы «Количество записей по времени начала» дают следующую информацию:
- На ежедневных диаграммах временных рядов вы сравниваете количество запусков приложений между рабочими и праздничными днями, а также между календарными днями. Если числа похожи, это означает, что ежедневное использование кластера сопоставимо. С другой стороны, если отклонение велико, значительна доля специальных заданий. Вы также можете выяснить возможные еженедельные или ежемесячные задания в определенные дни. В ситуации вы можете легко увидеть определенные дни в неделе или месяце с высокой концентрацией рабочей нагрузки.
- В часовых диаграммах временных рядов вы лучше понимаете, как приложения запускаются в часовых окнах. Вы можете найти пиковые и непиковые часы в день.
Пользователи
Журналы YARN содержат идентификатор пользователя каждого приложения. Эта информация поможет вам понять, кто отправляет заявку в очередь. На основе статистики отдельных и агрегированных запусков приложений по очереди и по пользователям можно определить существующее распределение рабочей нагрузки по пользователям. Обычно пользователи в одной команде имеют общие очереди. Иногда несколько команд имеют общие очереди. При проектировании очередей для пользователей теперь у вас есть аналитические сведения, которые помогут вам спроектировать и распределить рабочие нагрузки приложений, более сбалансированные между очередями, чем раньше.
Типы приложений
Вы можете сегментировать рабочие нагрузки на основе различных типов приложений (таких как Hive, Spark, Presto или HBase) и запускать механизмы (такие как MR, Spark или Tez). Для ресурсоемких рабочих нагрузок, таких как задания MapReduce или Hive-on-MR, используйте экземпляры, оптимизированные для ЦП. Для рабочих нагрузок с интенсивным использованием памяти, таких как задания Hive-on-TEZ, Presto и Spark, используйте экземпляры, оптимизированные для памяти.
Пройденное время
Вы можете классифицировать приложения по времени выполнения. Встроенный шаблон CloudFormation автоматически создает поле elapsedGroup на информационной панели QuickSight. Это включает ключевую функцию, позволяющую вам наблюдать за длительными заданиями на одной из четырех диаграмм на информационных панелях QuickSight. Таким образом, вы можете разработать индивидуальную архитектуру будущего для этих крупных задач.
Соответствующие информационные панели QuickSight содержат четыре диаграммы. Вы можете детализировать каждую диаграмму, которая связана с одной группой.
| группы Номер регистрации |
Время выполнения/прошедшее время задания |
| 1 | Менее 10 минут |
| 2 | От 10 минут до 30 минут |
| 3 | от 30 минут до 1 часа |
| 4 | Более 1 часа |
На диаграмме группы 4 вы можете сосредоточиться на тщательном анализе больших заданий на основе различных показателей, включая пользователя, очередь, тип приложения, временную шкалу, использование ресурсов и т. д. Исходя из этого соображения, у вас могут быть выделенные очереди в кластере или выделенный кластер EMR для больших заданий. Тем временем вы можете отправлять небольшие задания в общие очереди.
Полезные ресурсы
Основываясь на шаблонах потребления ресурсов (ЦП, памяти), вы выбираете правильный размер и семейство инстансов EC2 для повышения производительности и экономической эффективности. Для ресурсоемких приложений мы рекомендуем экземпляры семейств, оптимизированных для ЦП. Для приложений, интенсивно использующих память, рекомендуются семейства экземпляров, оптимизированные для памяти.
Кроме того, в зависимости от характера рабочих нагрузок приложений и использования ресурсов с течением времени вы можете выбрать постоянный или временный кластер EMR. Amazon EMR на EKSили Amazon EMR без сервера.
После анализа журналов YARN по различным показателям вы готовы к разработке будущих архитектур EMR. В следующей таблице перечислены примеры предлагаемых кластеров EMR. Более подробную информацию вы можете найти в репозиторий GitHub с оптимизированным калькулятором стоимости владения.

Рассчитать совокупную стоимость владения
Наконец, на локальном компьютере запустите tco-input-generator.py, чтобы агрегировать журналы истории заданий YARN на почасовой основе, прежде чем использовать шаблон Excel для расчета оптимизированной совокупной стоимости владения. Этот шаг имеет решающее значение, поскольку результаты моделируют рабочие нагрузки Hadoop в будущих экземплярах EMR.
Обязательным условием моделирования совокупной стоимости владения является выполнение tco-input-generator.py, который создает почасовые агрегированные журналы. Затем вы открываете файл шаблона Excel, чтобы включить макросы, и вводите данные в зеленых ячейках для расчета совокупной стоимости владения. Что касается входных данных, вы вводите фактический размер данных без репликации и спецификации оборудования (виртуальное ядро, память) основного узла Hadoop и узлов данных. Вам также необходимо выбрать и загрузить ранее созданные почасовые агрегированные журналы. После установки переменных моделирования совокупной стоимости владения, таких как регион, тип EC2, высокая доступность Amazon EMR, влияние механизма, скидка Amazon EC2 и Amazon EBS (EDP), скидка на объем Amazon S3, курс местной валюты и соотношение цены задачи/ядра EMR EC2. и цена/час, симулятор совокупной стоимости владения автоматически рассчитывает оптимальную стоимость будущих инстансов EMR на Amazon EC2. На следующих снимках экрана показан пример результатов совокупной стоимости владения HMDK.

Для получения дополнительной информации и инструкций по расчету совокупной стоимости владения HMDK см. репозиторий GitHub с оптимизированным калькулятором стоимости владения.
Убирать
После выполнения всех шагов и завершения тестирования выполните следующие действия, чтобы удалить ресурсы, чтобы избежать дополнительных затрат:
- В консоли AWS CloudFormation выберите созданный стек.
- Выберите Удалить.
- Выберите Удалить стопку.
- Обновляйте страницу, пока не увидите статус
DELETE_COMPLETE. - В консоли Amazon S3 удалите созданную корзину S3.
Заключение
Инструмент AWS ProServe HMDK TCO значительно сокращает усилия по планированию миграции, которые представляют собой трудоемкие и сложные задачи по оценке ваших рабочих нагрузок Hadoop. При использовании инструмента HMDK TCO оценка обычно занимает 2–3 недели. Вы также можете определить расчетную совокупную стоимость владения будущих архитектур EMR. С помощью инструмента HMDK TCO вы можете быстро понять свои рабочие нагрузки и модели использования ресурсов. С выводами, полученными с помощью этого инструмента, вы сможете разработать оптимальную архитектуру EMR будущего. Во многих случаях совокупная стоимость владения оптимизированной рефакторинговой архитектурой в течение 1 года обеспечивает значительную экономию затрат (снижение на 64–80 %) на вычислительные ресурсы и хранилище по сравнению с миграциями Hadoop с переносом и переносом.
Чтобы узнать больше об ускорении миграции Hadoop в Amazon EMR и инструменте HMDK CTO, см. Репозиторий Hadoop Migration Delivery Kit TCO на GitHub, или обратитесь к AWS-HMDK@amazon.com.
Об авторах
 Сунгюль Парк является старшим менеджером практики в AWS ProServe. Он помогает клиентам внедрять инновации в свой бизнес с помощью сервисов AWS Analytics, IoT и AI/ML. Он специализируется на услугах и технологиях для работы с большими данными и заинтересован в совместном достижении бизнес-результатов для клиентов.
Сунгюль Парк является старшим менеджером практики в AWS ProServe. Он помогает клиентам внедрять инновации в свой бизнес с помощью сервисов AWS Analytics, IoT и AI/ML. Он специализируется на услугах и технологиях для работы с большими данными и заинтересован в совместном достижении бизнес-результатов для клиентов.
 Джисон Ким является старшим архитектором данных в AWS ProServe. В основном он работает с корпоративными клиентами, чтобы помочь с миграцией и модернизацией озера данных, а также предоставляет рекомендации и техническую помощь по проектам больших данных, таким как Hadoop, Spark, хранилища данных, обработка данных в реальном времени и крупномасштабное машинное обучение. Он также понимает, как применять технологии для решения проблем с большими данными и построения хорошо спроектированной архитектуры данных.
Джисон Ким является старшим архитектором данных в AWS ProServe. В основном он работает с корпоративными клиентами, чтобы помочь с миграцией и модернизацией озера данных, а также предоставляет рекомендации и техническую помощь по проектам больших данных, таким как Hadoop, Spark, хранилища данных, обработка данных в реальном времени и крупномасштабное машинное обучение. Он также понимает, как применять технологии для решения проблем с большими данными и построения хорошо спроектированной архитектуры данных.
 Джордж Чжао является старшим архитектором данных в AWS ProServe. Он является опытным руководителем отдела аналитики, работающим с клиентами AWS над предоставлением современных решений для обработки данных. Он также является специалистом по предметной области ProServe Amazon EMR, который предоставляет консультантам ProServe передовые методы и комплекты поставки для миграции Hadoop на Amazon EMR. Область его интересов — озера данных и доставка современной облачной архитектуры данных.
Джордж Чжао является старшим архитектором данных в AWS ProServe. Он является опытным руководителем отдела аналитики, работающим с клиентами AWS над предоставлением современных решений для обработки данных. Он также является специалистом по предметной области ProServe Amazon EMR, который предоставляет консультантам ProServe передовые методы и комплекты поставки для миграции Hadoop на Amazon EMR. Область его интересов — озера данных и доставка современной облачной архитектуры данных.
 Кален Чжан был техническим руководителем глобального сегмента партнерских данных и аналитики в AWS. В качестве доверенного консультанта по данным и аналитике она курировала стратегические инициативы по преобразованию данных, руководила программами миграции и модернизации рабочих нагрузок данных и аналитики, а также ускоряла процессы миграции клиентов с партнерами в масштабе. Она специализируется на распределенных системах, управлении корпоративными данными, расширенной аналитике и крупномасштабных стратегических инициативах.
Кален Чжан был техническим руководителем глобального сегмента партнерских данных и аналитики в AWS. В качестве доверенного консультанта по данным и аналитике она курировала стратегические инициативы по преобразованию данных, руководила программами миграции и модернизации рабочих нагрузок данных и аналитики, а также ускоряла процессы миграции клиентов с партнерами в масштабе. Она специализируется на распределенных системах, управлении корпоративными данными, расширенной аналитике и крупномасштабных стратегических инициативах.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/deep-dive-into-the-aws-proserve-hadoop-migration-delivery-kit-tco-tool/
- 000
- 1
- 10
- 100
- 7
- a
- в состоянии
- О нас
- ускорять
- ускоренный
- ускоряет
- ускоряющий
- ускорение
- доступность
- Учетная запись
- через
- Ad
- дополнение
- дополнительный
- Дополнительная информация
- Дополнительно
- продвинутый
- советник
- После
- против
- AI / ML
- Все
- Amazon
- Amazon EC2
- Амазонка ЭМИ
- среди
- анализ
- аналитика
- анализировать
- анализ
- и
- API
- Применение
- Приложения
- Применить
- надлежащим образом
- архитектура
- ПЛОЩАДЬ
- оценки;
- Помощь
- связанный
- автоматически
- свободных мест
- AWS
- AWS CloudFormation
- основанный
- основа
- , так как:
- не являетесь
- Преимущества
- ЛУЧШЕЕ
- лучшие практики
- Лучшая
- между
- большой
- Big Data
- кратко
- строить
- Строительство
- бизнес
- вычислять
- рассчитанный
- исчисляет
- расчет
- Календарь
- под названием
- вызова
- возможности
- Пропускная способность
- случаев
- Клетки
- определенный
- сложные
- График
- Графики
- Выберите
- Выбирая
- облако
- Кластер
- собирать
- Сбор
- лыжных шлемов
- коллектор
- улавливается
- COM
- сравнимый
- сравнить
- сравненный
- полный
- Вычисление
- сконцентрировать
- концентрации
- Проводить
- проведение
- Свяжитесь
- связи
- подключает
- последовательный
- рассмотрение
- Консоли
- Консультанты
- потребление
- содержит
- соответствующий
- Цена
- экономия на издержках
- Расходы
- ЦП
- создали
- создает
- Критерии
- решающее значение
- CTO
- Куратор
- Валюта
- Текущий
- клиент
- Клиенты
- циклы
- ежедневно
- приборная панель
- данным
- Озеро данных
- управление данными
- обработка данных
- Наборы данных
- день
- Дней
- преданный
- глубоко
- глубокое погружение
- доставить
- поставка
- убивают
- развертывание
- Проект
- проектирование
- подробнее
- Определять
- Развитие
- отклонение
- различный
- скидка
- распространять
- распределенный
- распределенные системы
- распределение
- домен
- вниз
- в течение
- каждый
- легко
- EBS
- edition
- эффект
- эффективность
- усилия
- встроенный
- включить
- включен
- позволяет
- впритык
- Двигатель
- Двигатели
- обеспечивать
- Enter
- Предприятие
- корпоративные клиенты
- оборудованный
- установить
- Эфир (ETH)
- События
- Каждая
- пример
- Примеры
- Excel
- существующий
- опытные
- облегчающий
- семей
- семья
- Особенность
- Особенности
- поле
- фигура
- Файл
- Файлы
- Найдите
- окончание
- после
- формат
- от
- функциональные возможности
- далее
- будущее
- Общие
- генерируется
- генерирует
- получить
- получающий
- GitHub
- Глобальный
- Зелёная
- группы
- методические рекомендации
- Hadoop
- Аппаратные средства
- помощь
- помогает
- High
- история
- Hive
- каникулы
- целостный
- ЧАСЫ
- Как
- How To
- HTML
- HTTPS
- ICON
- улучшение
- in
- включают
- В том числе
- individual
- лиц
- информация
- инициативы
- обновлять
- вход
- размышления
- пример
- инструкции
- интерес
- интересы
- выпустили
- КАТО
- IT
- работа
- Джобс
- Путешествия
- JSON
- Основные
- комплект
- озеро
- большой
- крупномасштабный
- запуск
- вести
- лидер
- УЧИТЬСЯ
- изучение
- привело
- Светодиодные данные
- Списки
- загрузка
- локальным
- Длинное
- много времени
- посмотреть
- серия
- машина
- обучение с помощью машины
- Макрос
- Главная
- сделать
- управление
- менеджер
- Менеджеры
- многих
- означает
- Между тем
- Память
- объединение
- Метрика
- миграция
- минут
- смешанный
- Модерн
- модернизация
- Месяц
- ежемесячно
- БОЛЕЕ
- с разными
- природа
- Необходимость
- следующий
- узел
- узлы
- номер
- номера
- наблюдать
- получение
- ONE
- открытый
- операционный
- операция
- оптимальный
- оптимизированный
- оптимизирующий
- оптимальный
- организации
- Другое
- особый
- партнер
- партнеры
- паттеранами
- Вершина горы
- выполнять
- производительность
- период
- разрешение
- Мест
- планирование
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- политика
- возможное
- После
- практика
- практиками
- предпосылки
- предварительно
- цены
- первичный
- Предварительный
- проблемам
- обработка
- Программы
- проектов
- правильный
- предложило
- обеспечивать
- приводит
- Питон
- быстро
- Обменный курс
- соотношение
- достигать
- готовый
- реального времени
- данные в реальном времени
- рекомендовать
- Управление по борьбе с наркотиками (DEA)
- учет
- снижает
- по
- область
- регулярный
- удаление
- копирование
- ресурс
- Полезные ресурсы
- Итоги
- сохранение
- туры
- Run
- Бег
- то же
- экономия
- Шкала
- график
- скриншоты
- разделах
- сегмент
- старший
- Серии
- Услуги
- набор
- установка
- несколько
- общие
- показывать
- демонстрации
- значительный
- существенно
- аналогичный
- просто
- моделирование
- имитатор
- ситуация
- Размер
- небольшой
- So
- Решения
- РЕШАТЬ
- некоторые
- Искриться
- специалист
- специализируется
- Специальные
- конкретный
- спецификации
- стек
- и политические лидеры
- статистика
- Статус:
- Шаг
- Шаги
- диск
- Стратегический
- отправить
- такие
- Поддержанный
- система
- системы
- ТАБЛИЦЫ
- с учетом
- принимает
- цель
- задачи
- команда
- команды
- технологии
- Технический
- технологии
- шаблон
- шаблоны
- Тестирование
- Ассоциация
- Будущее
- их
- следовательно
- Через
- время
- Временные ряды
- кропотливый
- Сроки
- в
- вместе
- инструментом
- Transform
- трансформация
- преобразован
- правда
- надежных
- Типы
- под
- понимать
- понимание
- понимает
- Применение
- использование
- Информация о пользователе
- пользователей
- обычно
- различный
- проверить
- визуализация
- объем
- ходьба
- Складирование
- неделя
- еженедельно
- Недели
- Что
- Что такое
- который
- КТО
- окна
- без
- рабочий
- работает
- работает
- YAML
- ВАШЕ
- зефирнет