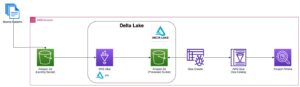
Этот пост написан в соавторстве с Прамодом Наяком, ЛакшмиКантом Маннемом и Вивеком Аггарвалом из группы низкой задержки LSEG.
Анализ транзакционных издержек (TCA) широко используется трейдерами, портфельными менеджерами и брокерами для предторгового и постторгового анализа и помогает им измерять и оптимизировать транзакционные издержки и эффективность своих торговых стратегий. В этом посте мы анализируем спреды опционов бид-аск от История тиков LSEG – PCAP набор данных с использованием Amazon Athena для Apache Spark. Мы покажем вам, как получать доступ к данным, определять пользовательские функции для применения к данным, запрашивать и фильтровать набор данных, а также визуализировать результаты анализа, и все это без необходимости беспокоиться о настройке инфраструктуры или настройке Spark, даже для больших наборов данных.
проверка данных
Управление по отчетности о ценах опционов (OPRA) выступает в качестве важнейшего обработчика информации о ценных бумагах, собирая, консолидируя и распространяя отчеты о последних продажах, котировки и соответствующую информацию для опционов США. Обладая 18 активными биржами опционов в США и более чем 1.5 миллионами соответствующих контрактов, OPRA играет ключевую роль в предоставлении комплексных рыночных данных.
5 февраля 2024 года Корпорация автоматизации индустрии ценных бумаг (SIAC) собирается обновить канал OPRA с 48 до 96 многоадресных каналов. Это усовершенствование направлено на оптимизацию распределения символов и использования емкости линий в ответ на рост торговой активности и волатильности на рынке опционов в США. SIAC рекомендовал фирмам подготовиться к пиковой скорости передачи данных до 37.3 Гбит/с.
Несмотря на то, что обновление не приводит к немедленному изменению общего объема публикуемых данных, оно позволяет OPRA распространять данные значительно быстрее. Этот переход имеет решающее значение для удовлетворения потребностей динамичного рынка опционов.
OPRA выделяется как один из самых объемных каналов с пиком в 150.4 миллиарда сообщений за один день в третьем квартале 3 года и требуемым запасом мощности в 2023 миллиардов сообщений в течение одного дня. Регистрация каждого отдельного сообщения имеет решающее значение для анализа транзакционных издержек, мониторинга ликвидности рынка, оценки торговой стратегии и исследования рынка.
О данных
История тиков LSEG – PCAP — это облачное хранилище объемом более 30 ПБ, в котором хранятся данные мирового рынка сверхвысокого качества. Эти данные тщательно собираются непосредственно в центрах обработки данных обмена с использованием избыточных процессов сбора, стратегически расположенных в основных основных и резервных центрах обработки данных обмена по всему миру. Технология захвата LSEG обеспечивает сбор данных без потерь и использует источник времени GPS для наносекундной точности отметки времени. Кроме того, используются сложные методы арбитража данных для беспрепятственного заполнения любых пробелов в данных. После захвата данные подвергаются тщательной обработке и арбитражу, а затем нормализуются в формат Parquet с использованием Ultra Direct в реальном времени от LSEG (RTUD) обработчики кормов.
Процесс нормализации, который является неотъемлемой частью подготовки данных для анализа, генерирует до 6 ТБ сжатых файлов Parquet в день. Огромный объем данных объясняется всеобъемлющим характером OPRA, охватывающим несколько бирж и содержащим многочисленные опционные контракты, характеризующиеся различными атрибутами. Повышенная волатильность рынка и рыночная активность на биржах опционов также способствуют увеличению объема данных, публикуемых на OPRA.
Атрибуты Tick History – PCAP позволяют фирмам проводить различные анализы, в том числе следующие:
- Предторговый анализ – Оценить потенциальное влияние торговли и изучить различные стратегии исполнения на основе исторических данных.
- Постторговая оценка – Измеряйте фактические затраты на выполнение по сравнению с контрольными показателями для оценки эффективности стратегий исполнения.
- Оптимизированный выполнение – Точная настройка стратегий исполнения на основе исторических рыночных моделей, чтобы минимизировать влияние на рынок и снизить общие торговые издержки.
- Управление рисками – Выявлять модели проскальзывания, выявлять выбросы и активно управлять рисками, связанными с торговой деятельностью.
- Атрибуция производительности – Отделяйте влияние торговых решений от инвестиционных решений при анализе эффективности портфеля.
Тиковая история LSEG – набор данных PCAP доступен в Обмен данными AWS и доступен на Торговая площадка AWS. С Обмен данными AWS для Amazon S3, вы можете получить доступ к данным PCAP непосредственно из LSEG. Простой сервис хранения Amazon (Amazon S3), что избавляет компании от необходимости хранить собственную копию данных. Этот подход упрощает управление и хранение данных, предоставляя клиентам немедленный доступ к высококачественным PCAP или нормализованным данным, а также простоту использования, интеграции и простоты использования. существенная экономия на хранении данных.
Афина для Apache Spark
Для аналитических усилий, Афина для Apache Spark предлагает упрощенный интерфейс записной книжки, доступный через консоль Athena или API-интерфейсы Athena, что позволяет создавать интерактивные приложения Apache Spark. Благодаря оптимизированной среде выполнения Spark Athena помогает анализировать петабайты данных за счет динамического масштабирования количества механизмов Spark менее чем за секунду. Более того, общие библиотеки Python, такие как pandas и NumPy, легко интегрируются, что позволяет создавать сложную логику приложений. Гибкость распространяется на импорт пользовательских библиотек для использования в ноутбуках. Athena for Spark поддерживает большинство форматов открытых данных и легко интегрируется с Клей AWS Каталог данных.
Dataset
Для этого анализа мы использовали набор данных LSEG Tick History – PCAP OPRA от 17 мая 2023 года. Этот набор данных включает в себя следующие компоненты:
- Лучшее предложение и предложение (BBO) – Сообщает о самой высокой цене и самой низкой цене за ценную бумагу на данной бирже.
- Национальное лучшее предложение и предложение (NBBO) – Сообщает о самой высокой цене и самой низкой цене за ценную бумагу на всех биржах.
- Торги – Записывает завершенные сделки на всех биржах
Набор данных включает в себя следующие объемы данных:
- Торги – 160 МБ распределено примерно по 60 сжатым файлам Parquet.
- ВВО – 2.4 ТБ распределено примерно по 300 сжатым файлам Parquet.
- НББО – 2.8 ТБ распределено примерно по 200 сжатым файлам Parquet.
Обзор анализа
Анализ данных тиковой истории OPRA для анализа транзакционных затрат (TCA) включает в себя тщательное изучение рыночных котировок и сделок вокруг конкретного торгового события. В рамках данного исследования мы используем следующие показатели:
- Котируемый спред (QS) – Рассчитывается как разница между аском BBO и бидом BBO.
- Эффективный спред (ES) – Рассчитывается как разница между ценой сделки и средней точкой BBO (бид BBO + (аск BBO – бид BBO)/2)
- Эффективный/котируемый спред (EQF) – Рассчитывается как (ES/QS) * 100
Мы рассчитываем эти спреды до сделки и дополнительно через четыре интервала после сделки (сразу после, через 1 секунду, 10 секунд и 60 секунд после сделки).
Настройка Athena для Apache Spark
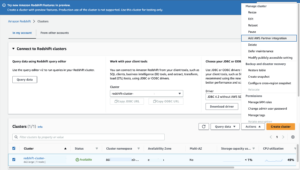
Чтобы настроить Athena для Apache Spark, выполните следующие действия:
- На консоли Athena в разделе Начать, наведите на Анализируйте свои данные с помощью PySpark и Spark SQL..
- Если вы впервые используете Athena Spark, выберите Создать рабочую группу.

- Что касается Имя рабочей группы¸ введите имя рабочей группы, например
tca-analysis. - В Механизм аналитики раздел, выберите Apache Spark.
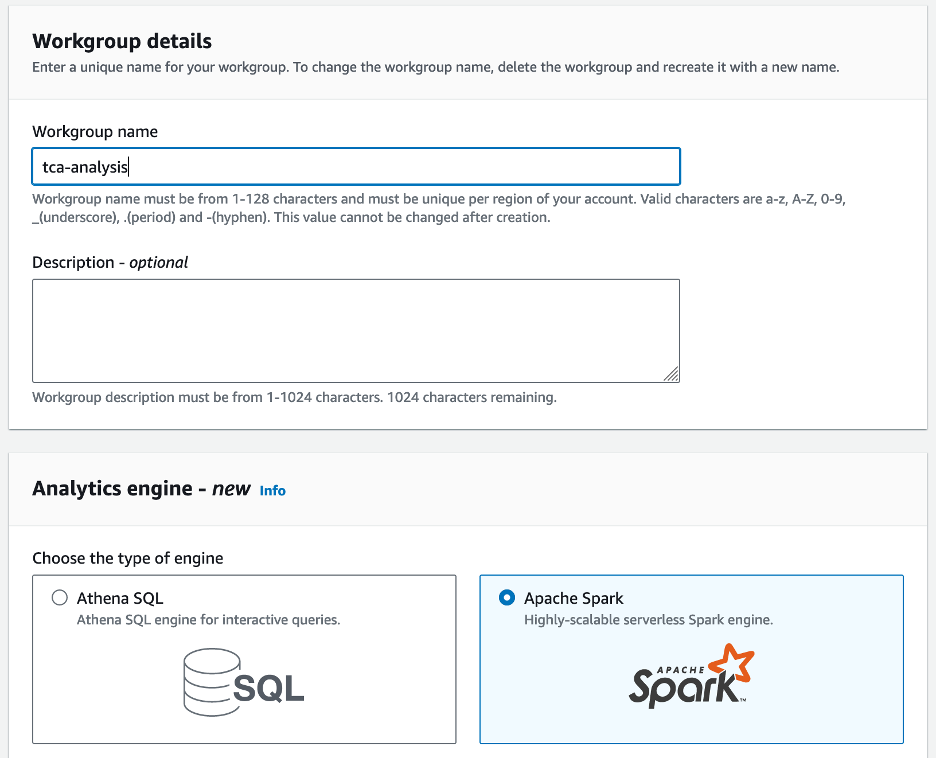
- В Дополнительные конфигурации раздел, вы можете выбрать Использовать значения по умолчанию или предоставить индивидуальный Управление идентификацией и доступом AWS (IAM) и расположение Amazon S3 для результатов вычислений.
- Выберите Создать рабочую группу.
- После создания рабочей группы перейдите к Ноутбуки и выберите Создать блокнот.
- Введите имя для своего блокнота, например
tca-analysis-with-tick-history. - Выберите Создавай для создания своего блокнота.
Запустите свой блокнот
Если вы уже создали рабочую группу Spark, выберите Запустить редактор блокнота под Начать.
![]()
После создания блокнота вы будете перенаправлены в редактор интерактивных блокнотов.
![]()
Теперь мы можем добавить и запустить следующий код в нашем блокноте.
Создать анализ
Для создания анализа выполните следующие шаги:
- Импортируйте общие библиотеки:
- Создайте наши фреймы данных для BBO, NBBO и сделок:
- Теперь мы можем определить сделку, которую будем использовать для анализа транзакционных издержек:
Получаем такой вывод:
В дальнейшем мы используем выделенную торговую информацию для торгового продукта (tp), торговой цены (tpr) и времени торговли (tt).
- Здесь мы создаем ряд вспомогательных функций для нашего анализа.
- В следующей функции мы создаем набор данных, содержащий все котировки до и после сделки. Athena Spark автоматически определяет, сколько DPU запустить для обработки нашего набора данных.
- Теперь давайте вызовем функцию анализа TCA с информацией из выбранной нами сделки:
Визуализируйте результаты анализа
Теперь давайте создадим фреймы данных, которые мы используем для нашей визуализации. Каждый кадр данных содержит котировки для одного из пяти временных интервалов для каждого потока данных (BBO, NBBO):
В следующих разделах мы приводим пример кода для создания различных визуализаций.
Постройте график QS и NBBO перед сделкой
Используйте следующий код, чтобы построить график котируемого спреда и NBBO перед сделкой:
![]()
Постройте QS для каждого рынка и NBBO после сделки
Используйте следующий код, чтобы построить котировочный спред для каждого рынка и NBBO сразу после сделки:
![]()
Постройте QS для каждого временного интервала и каждого рынка для BBO.
Используйте следующий код, чтобы построить котировочный спред для каждого временного интервала и каждого рынка для BBO:
![]()
Постройте график ES для каждого временного интервала и рынка для BBO.
Используйте следующий код, чтобы построить эффективный спред для каждого временного интервала и рынка для BBO:
Постройте EQF для каждого временного интервала и рынка для BBO.
Используйте следующий код, чтобы построить эффективный/котируемый спред для каждого временного интервала и рынка для BBO:
Производительность расчета Athena Spark
Когда вы запускаете блок кода, Athena Spark автоматически определяет, сколько DPU требуется для завершения расчета. В последнем блоке кода, где мы вызываем tca_analysis функции, мы фактически инструктируем Spark обработать данные, а затем преобразуем полученные фреймы данных Spark в фреймы данных Pandas. Это самая интенсивная часть анализа, и когда Athena Spark запускает этот блок, он показывает индикатор выполнения, затраченное время и количество DPU, обрабатывающих данные в данный момент. Например, в следующем расчете Athena Spark использует 18 DPU.
![]()
При настройке ноутбука Athena Spark у вас есть возможность установить максимальное количество DPU, которое он может использовать. По умолчанию установлено 20 DPU, но мы протестировали этот расчет с 10, 20 и 40 DPU, чтобы продемонстрировать, как Athena Spark автоматически масштабируется для проведения нашего анализа. Мы заметили, что Athena Spark масштабируется линейно: 15 минут и 21 секунда, если в ноутбуке установлено максимум 10 DPU, 8 минут и 23 секунды, если в ноутбуке установлено 20 DPU, и 4 минуты и 44 секунды, когда ноутбук был сконфигурирован с 40 DPU. Поскольку Athena Spark взимает плату на основе использования DPU с посекундной детализацией, стоимость этих вычислений аналогична, но если вы установите более высокое максимальное значение DPU, Athena Spark сможет вернуть результат анализа гораздо быстрее. Для получения более подробной информации о ценах на Athena Spark нажмите кнопку здесь.
Заключение
В этом посте мы продемонстрировали, как вы можете использовать высокоточные данные OPRA из Tick History-PCAP от LSEG для анализа транзакционных затрат с помощью Athena Spark. Своевременная доступность данных OPRA в сочетании с инновациями доступности AWS Data Exchange для Amazon S3 стратегически сокращает время анализа для компаний, стремящихся получить полезную информацию для принятия важных торговых решений. OPRA генерирует около 7 ТБ нормализованных данных Parquet каждый день, а управление инфраструктурой для предоставления аналитики на основе данных OPRA является сложной задачей.
Масштабируемость Athena при крупномасштабной обработке данных для Tick History — PCAP для данных OPRA делает ее привлекательным выбором для организаций, которым нужны быстрые и масштабируемые аналитические решения в AWS. В этом посте показано плавное взаимодействие между экосистемой AWS и данными Tick History-PCAP, а также то, как финансовые учреждения могут использовать эту синергию для принятия решений на основе данных для важнейших торговых и инвестиционных стратегий.
Об авторах
![]() Прамод Наяк является директором по управлению продуктами группы с низкими задержками в LSEG. Прамод имеет более чем 10-летний опыт работы в сфере финансовых технологий, специализируясь на разработке программного обеспечения, аналитике и управлении данными. Прамод — бывший инженер-программист, увлеченный рыночными данными и количественной торговлей.
Прамод Наяк является директором по управлению продуктами группы с низкими задержками в LSEG. Прамод имеет более чем 10-летний опыт работы в сфере финансовых технологий, специализируясь на разработке программного обеспечения, аналитике и управлении данными. Прамод — бывший инженер-программист, увлеченный рыночными данными и количественной торговлей.
![]() ЛакшмиКант Маннем является менеджером по продукту в группе низких задержек компании LSEG. Он специализируется на данных и платформенных продуктах для индустрии рыночных данных с малой задержкой. ЛакшмиКант помогает клиентам создавать наиболее оптимальные решения для удовлетворения их потребностей в рыночных данных.
ЛакшмиКант Маннем является менеджером по продукту в группе низких задержек компании LSEG. Он специализируется на данных и платформенных продуктах для индустрии рыночных данных с малой задержкой. ЛакшмиКант помогает клиентам создавать наиболее оптимальные решения для удовлетворения их потребностей в рыночных данных.
![]() Вивек Аггарвал — старший инженер по обработке данных в группе малых задержек компании LSEG. Вивек занимается разработкой и обслуживанием конвейеров данных для обработки и доставки собранных потоков рыночных и справочных данных.
Вивек Аггарвал — старший инженер по обработке данных в группе малых задержек компании LSEG. Вивек занимается разработкой и обслуживанием конвейеров данных для обработки и доставки собранных потоков рыночных и справочных данных.
![]() Алкет Мемушай — главный архитектор группы развития рынка финансовых услуг в AWS. Алкет отвечает за техническую стратегию, работая с партнерами и клиентами над развертыванием даже самых требовательных рабочих нагрузок рынков капитала в облаке AWS.
Алкет Мемушай — главный архитектор группы развития рынка финансовых услуг в AWS. Алкет отвечает за техническую стратегию, работая с партнерами и клиентами над развертыванием даже самых требовательных рабочих нагрузок рынков капитала в облаке AWS.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/mastering-market-dynamics-transforming-transaction-cost-analytics-with-ultra-precise-tick-history-pcap-and-amazon-athena-for-apache-spark/
- :имеет
- :является
- :нет
- :куда
- $UP
- 1
- 10
- 100
- 12
- 15%
- 150
- 16
- 160
- 17
- 19
- 20
- 200
- 2023
- 2024
- 23
- 27
- 30
- 300
- 40
- 400
- 60
- 7
- 750
- 8
- 90
- a
- О нас
- доступ
- Доступ
- доступность
- доступной
- через
- активный
- деятельность
- фактического соединения
- на самом деле
- Добавить
- Дополнительно
- адресация
- плюс
- После
- против
- Аггарваль
- Цель
- Все
- Позволяющий
- уже
- Amazon
- Амазонка Афина
- Amazon Web Services
- an
- анализирует
- анализ
- Аналитические фармацевтические услуги
- аналитика
- анализировать
- анализ
- и
- любой
- апаш
- Apache Spark
- API
- Применение
- Приложения
- Применить
- подхода
- примерно
- арбитраж
- арбитраж
- МЫ
- около
- AS
- спросить
- оценить
- связанный
- At
- Атрибуты
- власть
- автоматически
- автоматизация
- свободных мест
- доступен
- AWS
- Восстановление
- бар
- основанный
- BE
- , так как:
- до
- тесты
- ЛУЧШЕЕ
- между
- предложение
- миллиард
- Заблокировать
- Брокеры
- строить
- но
- by
- вычислять
- рассчитанный
- расчет
- призывают
- CAN
- Пропускная способность
- столица
- Рынки капитала
- захватить
- захваченный
- Захват
- каталог
- Центры
- сложные
- каналы
- отличающийся
- расходы
- выбор
- Выберите
- клиентов
- облако
- код
- Сбор
- Общий
- неотразимый
- полный
- Заполненная
- компоненты
- комплексный
- состоит из
- Проводить
- настроить
- настройка
- Консоли
- консолидации
- содержит
- контрактов
- способствовать
- конвертировать
- КОРПОРАЦИЯ
- Цена
- Расходы
- соавтор
- Создайте
- создали
- создание
- критической
- решающее значение
- В настоящее время
- изготовленный на заказ
- Клиенты
- Dash
- данным
- центров обработки данных
- инженер данных
- Обмен данными
- управление данными
- обработка данных
- хранение данных
- управляемых данными
- Наборы данных
- день
- Принятие решений
- решения
- По умолчанию
- определять
- поставка
- требующий
- запросы
- демонстрировать
- убивают
- развертывание
- подробнее
- определяет
- развивающийся
- Развитие
- Команда разработчиков
- разница
- различный
- непосредственно
- директор
- распределенный
- распределение
- Разное
- двойной
- управлять
- динамический
- динамично
- динамика
- каждый
- простота
- простота в использовании
- экосистема
- редактор
- Эффективный
- эффективность
- право
- уничтожение
- занятых
- используя
- включить
- позволяет
- охватывая
- усилия
- Двигатель
- инженер
- Двигатели
- усиление
- обеспечивает
- Enter
- наращивание
- Эфир (ETH)
- оценивать
- оценка
- Даже
- События
- Каждая
- пример
- обмена
- Биржи
- выполнение
- опыт
- Больше
- экспресс
- продолжается
- быстрее
- Показывая
- февраль
- Фига
- Файлы
- заполнять
- фильтр
- финансовый
- Финансовые институты
- финансовые услуги
- финансовые технологии
- Компаний
- First
- Впервые
- 5
- Трансформируемость
- фокусируется
- фокусировка
- после
- Что касается
- формат
- Бывший
- вперед
- 4
- КАДР
- от
- функция
- Функции
- далее
- пробелы
- генерирует
- получить
- данный
- Глобальный
- глобальный рынок
- Go
- будет
- GPS
- группы
- Управляемость
- Есть
- имеющий
- he
- габаритная высота
- помогает
- высококачественный
- высший
- наивысший
- Выделенные
- исторический
- история
- жилье
- Как
- How To
- HTTP
- HTTPS
- IAM
- определения
- Личность
- if
- немедленная
- немедленно
- Влияние
- Импортировать
- in
- В том числе
- расширились
- промышленность
- информация
- Инфраструктура
- инновации
- размышления
- учреждения
- рефлексологии
- интегрированный
- интеграции.
- взаимодействие
- интерактивный
- в
- запутанный
- инвестиций
- включает в себя
- IT
- JPG
- всего
- большой
- крупномасштабный
- Фамилия
- Задержка
- запуск
- Меньше
- библиотеки
- линия
- Ликвидность
- расположение
- логика
- искать
- Низкий
- низший
- сохранение
- основной
- ДЕЛАЕТ
- Создание
- управлять
- управление
- менеджер
- Менеджеры
- управления
- способ
- многих
- рынок
- Данные рынка
- влияние на рынок
- исследования рынка
- Волатильность рынка
- создание рынка
- Области применения:
- массивный
- Освоение
- максимальный
- Май..
- проводить измерение
- сообщение
- Сообщения
- дотошный
- тщательно
- Метрика
- миллиона
- минимизировать
- минут
- Мониторинг
- БОЛЕЕ
- Более того
- самых
- много
- с разными
- имя
- природа
- Откройте
- Необходимость
- потребности
- Ничто
- ноутбук
- ноутбуки
- номер
- многочисленный
- NumPy
- наблюдается
- of
- предлагают
- Предложения
- on
- ONE
- оптимальный
- Оптимизировать
- оптимизированный
- Опция
- Опции
- or
- организации
- наши
- внешний
- выходной
- за
- общий
- собственный
- панд
- часть
- партнеры
- страстный
- паттеранами
- Вершина горы
- для
- выполнять
- производительность
- основной
- Платформа
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- играет
- пожалуйста
- участок
- «портфель»
- портфельные менеджеры
- расположены
- После
- пост-торговля
- потенциал
- Точность
- Подготовить
- подготовка
- цена
- цены
- первичный
- Основной
- процесс
- Процессы
- обработка
- процессор
- Продукт
- Управление продуктом
- Менеджер по продукции
- Продукция
- Прогресс
- обеспечивать
- обеспечение
- опубликованный
- Питон
- Q3
- количественный
- количество
- запрос
- кавычки
- Обменный курс
- Стоимость
- Читать
- реальные
- реального времени
- Управление по борьбе с наркотиками (DEA)
- учет
- Red
- уменьшить
- снижает
- ссылка
- refinitiv
- Reporting
- Отчеты
- хранилище
- требование
- требуется
- исследованиям
- ответ
- ответственный
- результат
- в результате
- Итоги
- возвращают
- рисках,
- Роли
- Run
- работает
- sale
- Масштабируемость
- масштабируемые
- Весы
- масштабирование
- бесшовные
- легко
- Во-вторых
- секунды
- Раздел
- разделах
- Ценные бумаги
- безопасность
- поиск
- выберите
- выбранный
- старший
- отдельный
- служит
- Услуги
- набор
- установка
- показывать
- Шоу
- существенно
- аналогичный
- просто
- упрощенный
- одинарной
- проскальзывание
- Software
- разработка программного обеспечения
- Инженер-программист
- Решения
- сложный
- напряженность
- Искриться
- конкретный
- распространение
- Спреды
- стоит
- Шаги
- диск
- магазин
- Стратегически
- стратегий
- Стратегия
- тока
- Кабинет
- последующее
- такие
- SWIFT
- символ
- взаимодействие
- взять
- с
- команда
- Технический
- снижения вреда
- Технологии
- проверенный
- чем
- который
- Ассоциация
- информация
- их
- Их
- тогда
- Эти
- этой
- Через
- клещ
- время
- своевременно
- отметка времени
- Название
- в
- Всего
- tp
- TPR
- торговать
- Торговцы
- торги
- Торговля
- Торговые стратегии
- Торговая стратегия
- сделка
- трансакционные издержки
- превращение
- переход
- Ультра
- под
- подвергается
- модернизация
- us
- Применение
- использование
- используемый
- использования
- через
- Использующий
- ценностное
- различный
- визуализация
- визуализации
- Изменчивость
- объем
- тома
- законопроект
- we
- Web
- веб-сервисы
- когда
- который
- широко
- будете
- в
- без
- Рабочая группа
- работает
- работает
- по всему миру
- беспокоиться
- X
- лет
- являетесь
- ВАШЕ
- зефирнет