Pandas — это мощная и широко используемая библиотека с открытым исходным кодом для обработки и анализа данных с использованием Python. Одной из его ключевых функций является возможность группировать данные с помощью функции groupby, разбивая DataFrame на группы на основе одного или нескольких столбцов, а затем применяя различные функции агрегирования к каждому из них.

Изображение из Unsplash
Ассоциация groupby Функция невероятно мощная, так как позволяет быстро обобщать и анализировать большие наборы данных. Например, вы можете сгруппировать набор данных по определенному столбцу и вычислить среднее значение, сумму или количество оставшихся столбцов для каждой группы. Вы также можете группировать по нескольким столбцам, чтобы получить более детальное представление о ваших данных. Кроме того, он позволяет применять пользовательские функции агрегирования, которые могут быть очень мощным инструментом для сложных задач анализа данных.
В этом руководстве вы узнаете, как использовать функцию groupby в Pandas для группировки различных типов данных и выполнения различных операций агрегирования. К концу этого руководства вы сможете использовать эту функцию для анализа и обобщения данных различными способами.
Концепции усваиваются при хорошей практике, и это то, что мы собираемся сделать дальше, т.е. попрактиковаться с функцией Pandas groupby. Рекомендуется использовать Jupyter Notebook для этого руководства, поскольку вы можете видеть результат на каждом шаге.
Генерация демонстрационных данных
Импортируйте следующие библиотеки:
- Pandas: чтобы создать фреймворк данных и применить группу
- Random — для генерации случайных данных
- Pprint — для печати словарей
import pandas as pd
import random
import pprint
Затем мы инициализируем пустой фрейм данных и заполним значения для каждого столбца, как показано ниже:
df = pd.DataFrame()
names = [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard",
] major = [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology",
] yr_adm = random.sample(list(range(2018, 2023)) * 100, 15)
marks = random.sample(range(40, 101), 15)
num_add_sbj = random.sample(list(range(2)) * 100, 15) df["St_Name"] = names
df["Major"] = random.sample(major * 100, 15)
df["yr_adm"] = yr_adm
df["Marks"] = marks
df["num_add_sbj"] = num_add_sbj
df.head()
Бонусный совет — более простой способ выполнить ту же задачу — создать словарь всех переменных и значений, а затем преобразовать его в фрейм данных.
student_dict = { "St_Name": [ "Sankepally", "Astitva", "Shagun", "SURAJ", "Amit", "RITAM", "Rishav", "Chandan", "Diganta", "Abhishek", "Arpit", "Salman", "Anup", "Santosh", "Richard", ], "Major": random.sample( [ "Electrical Engineering", "Mechanical Engineering", "Electronic Engineering", "Computer Engineering", "Artificial Intelligence", "Biotechnology", ] * 100, 15, ), "Year_adm": random.sample(list(range(2018, 2023)) * 100, 15), "Marks": random.sample(range(40, 101), 15), "num_add_sbj": random.sample(list(range(2)) * 100, 15),
}
df = pd.DataFrame(student_dict)
df.head()
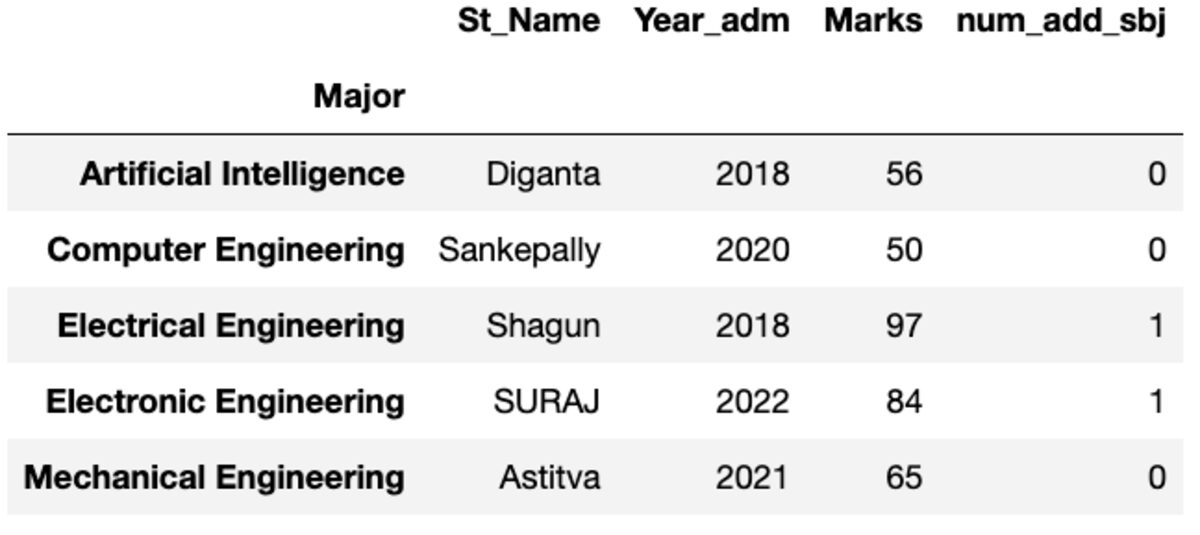
Фрейм данных выглядит так, как показано ниже. При запуске этого кода некоторые значения не будут совпадать, поскольку мы используем случайную выборку.
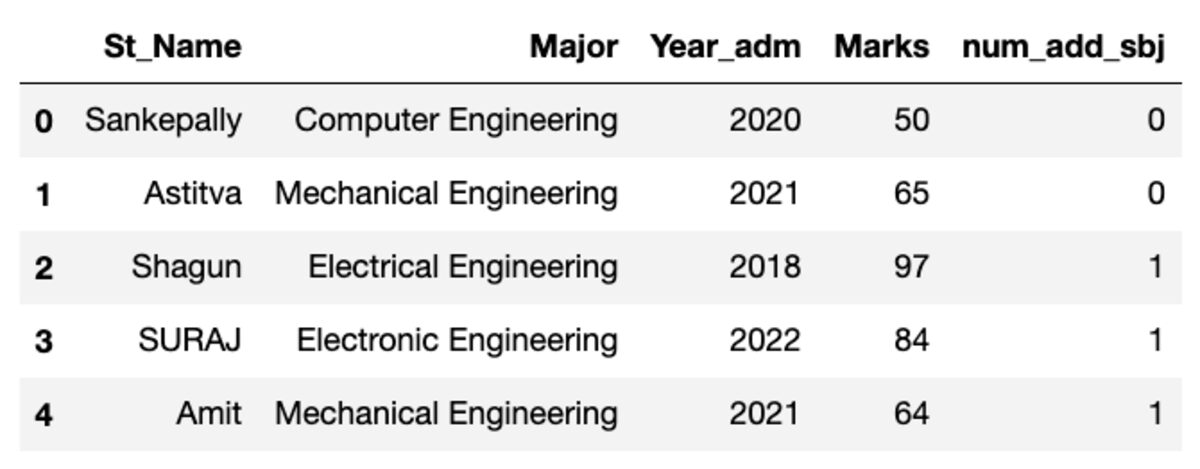
Создание групп
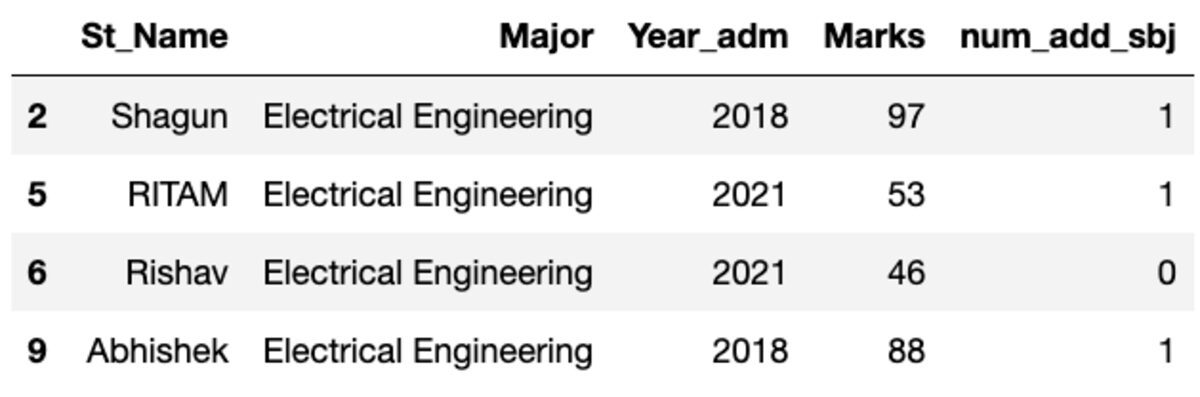
Сгруппируем данные по тематике «Major» и применим групповой фильтр, чтобы посмотреть, сколько записей попадает в эту группу.
groups = df.groupby('Major')
groups.get_group('Electrical Engineering')
Итак, четыре студента относятся к специальности «Электротехника».
Вы также можете группировать по более чем одному столбцу (Major и num_add_sbj в данном случае).
groups = df.groupby(['Major', 'num_add_sbj'])
Обратите внимание, что все агрегатные функции, которые можно применять к группам с одним столбцом, можно применять и к группам с несколькими столбцами. В оставшейся части руководства давайте сосредоточимся на различных типах агрегирования, используя в качестве примера один столбец.
Давайте создадим группы, используя groupby в столбце «Major».
groups = df.groupby('Major')Применение прямых функций
Допустим, вы хотите найти средние оценки по каждому специальному предмету. Что бы вы сделали?
- Выберите столбец «Отметки»
- Применить среднюю функцию
- Примените функцию округления, чтобы округлить знаки до двух знаков после запятой (необязательно)
groups['Marks'].mean().round(2)
Major
Artificial Intelligence 63.6
Computer Engineering 45.5
Electrical Engineering 71.0
Electronic Engineering 92.0
Mechanical Engineering 64.5
Name: Marks, dtype: float64
Совокупный
Другой способ добиться того же результата — использовать агрегатную функцию, как показано ниже:
groups['Marks'].aggregate('mean').round(2)
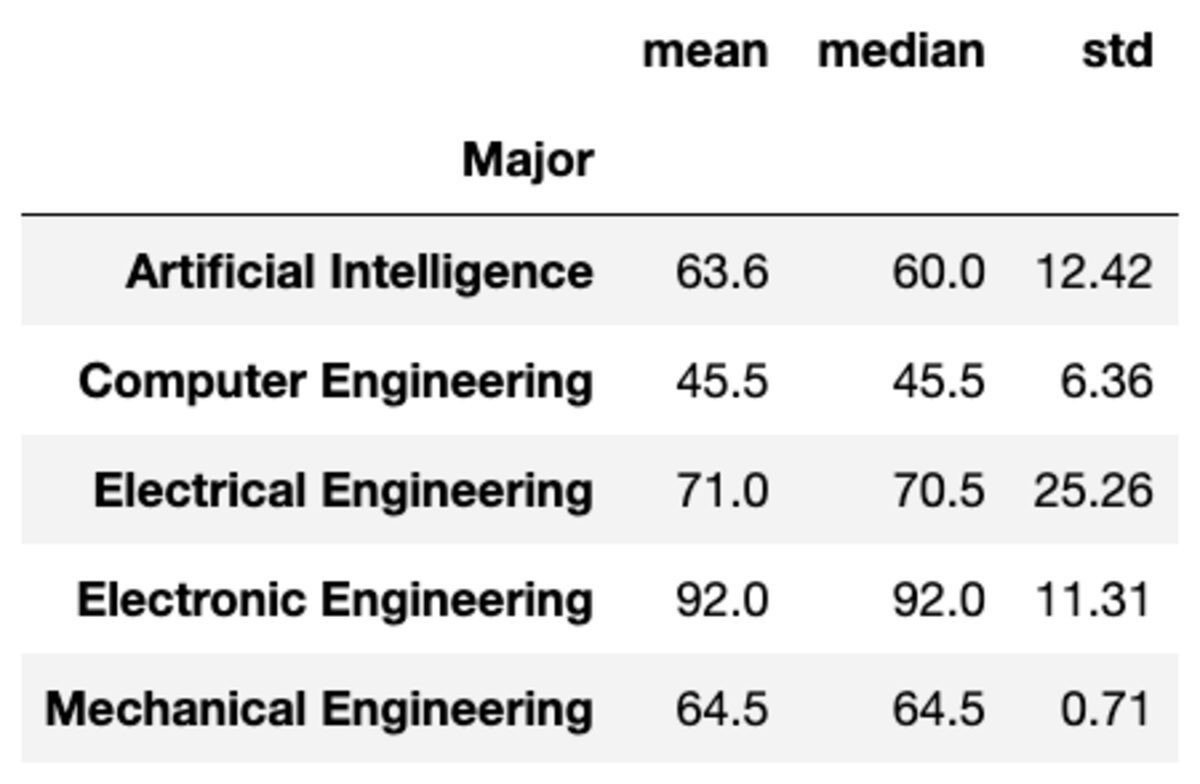
Вы также можете применить несколько агрегаций к группам, передав функции в виде списка строк.
groups['Marks'].aggregate(['mean', 'median', 'std']).round(2)
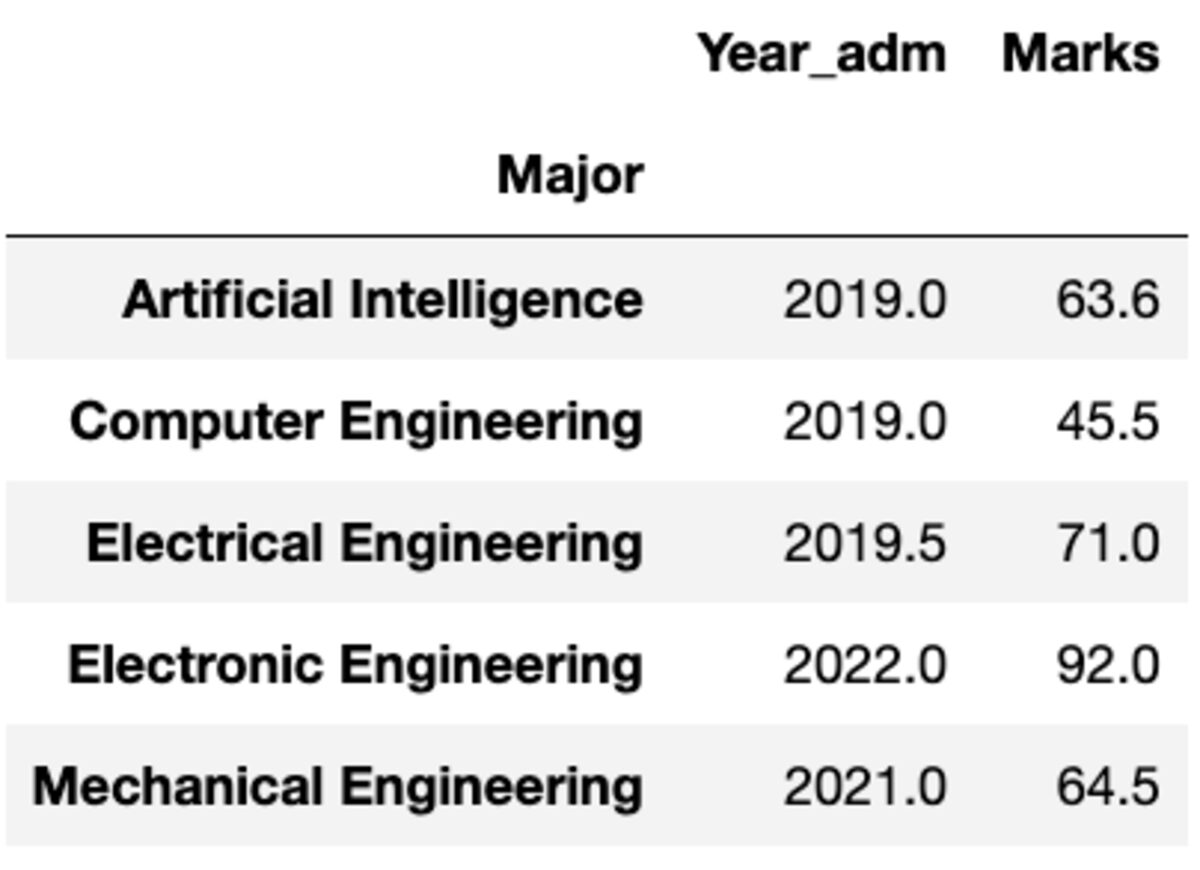
Но что, если вам нужно применить другую функцию к другому столбцу. Не волнуйся. Вы также можете сделать это, передав пару {column: function}.
groups.aggregate({'Year_adm': 'median', 'Marks': 'mean'})
Трансформации
Вам может понадобиться выполнить пользовательские преобразования для определенного столбца, что может быть легко достигнуто с помощью groupby(). Давайте определим стандартный скаляр, аналогичный тому, который доступен в модуле предварительной обработки sklearn. Вы можете преобразовать все столбцы, вызвав метод преобразования и передав пользовательскую функцию.
def standard_scalar(x): return (x - x.mean())/x.std()
groups.transform(standard_scalar)
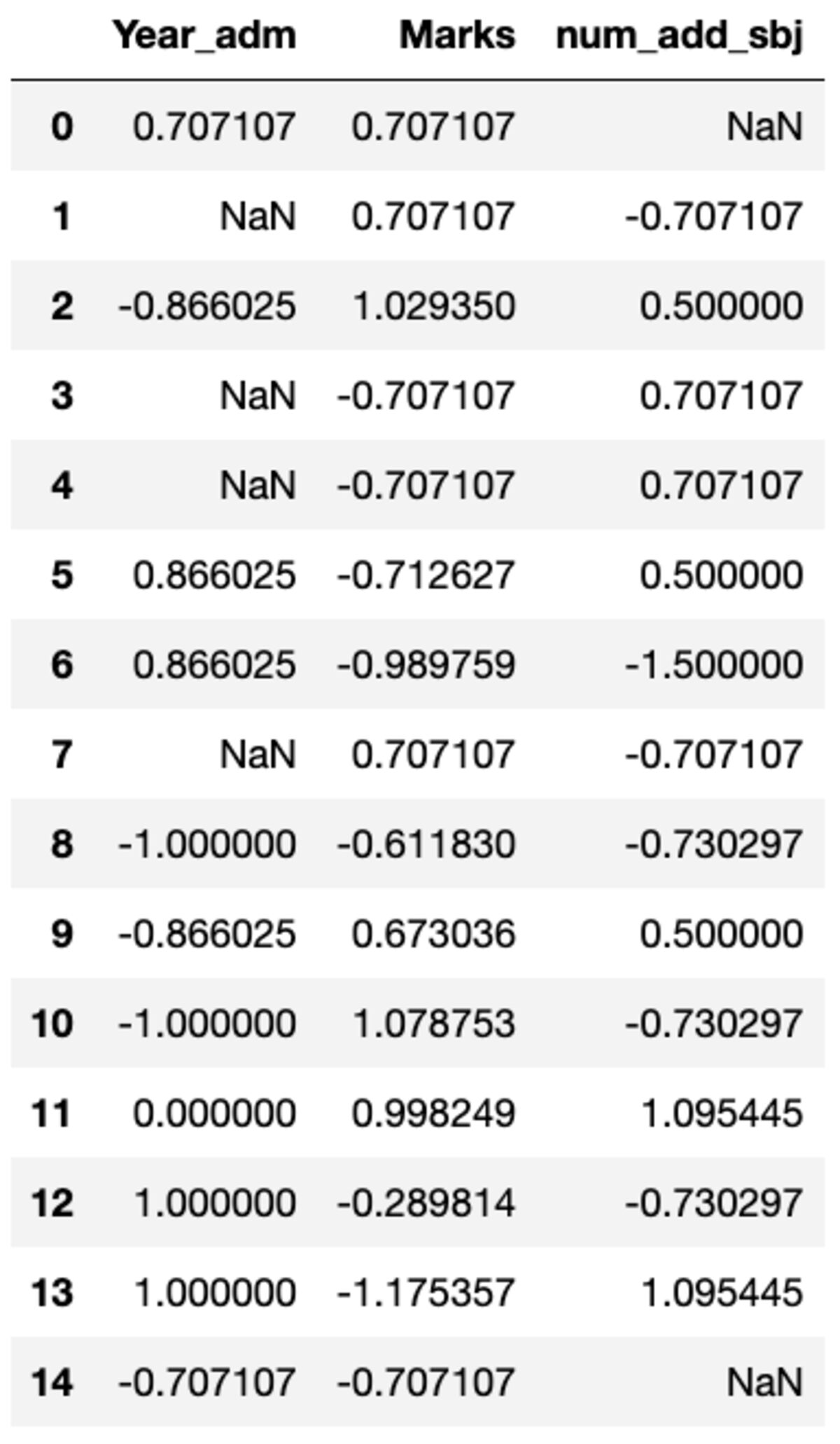
Обратите внимание, что «NaN» представляет группы с нулевым стандартным отклонением.
ФИЛЬТР
Возможно, вы захотите проверить, какая «специальность» неудовлетворительна, т. е. та, в которой средний балл учащегося составляет менее 60. Это требует от вас применения метода фильтрации к группам с функцией внутри него. В приведенном ниже коде используется лямбда-функция для достижения отфильтрованных результатов.
groups.filter(lambda x: x['Marks'].mean() 60)

Во-первых,
Он дает вам свой первый экземпляр, отсортированный по индексу.
groups.first()
Описывать
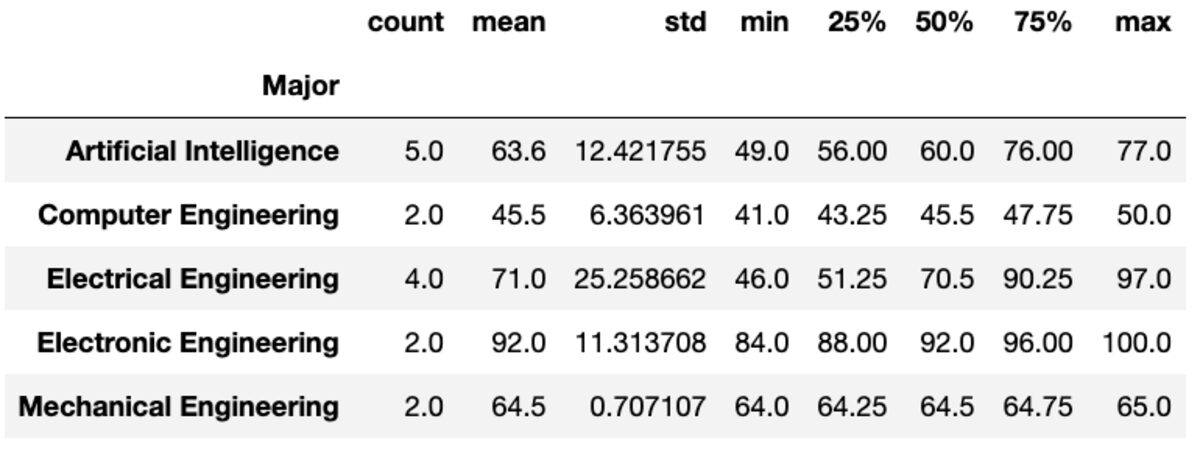
Метод «describe» возвращает базовую статистику, такую как количество, среднее значение, стандартное значение, минимальное, максимальное значение и т. д. для заданных столбцов.
groups['Marks'].describe()
Размер
Size, как следует из названия, возвращает размер каждой группы по количеству записей.
groups.size()
Major
Artificial Intelligence 5
Computer Engineering 2
Electrical Engineering 4
Electronic Engineering 2
Mechanical Engineering 2
dtype: int64Граф и Нуник
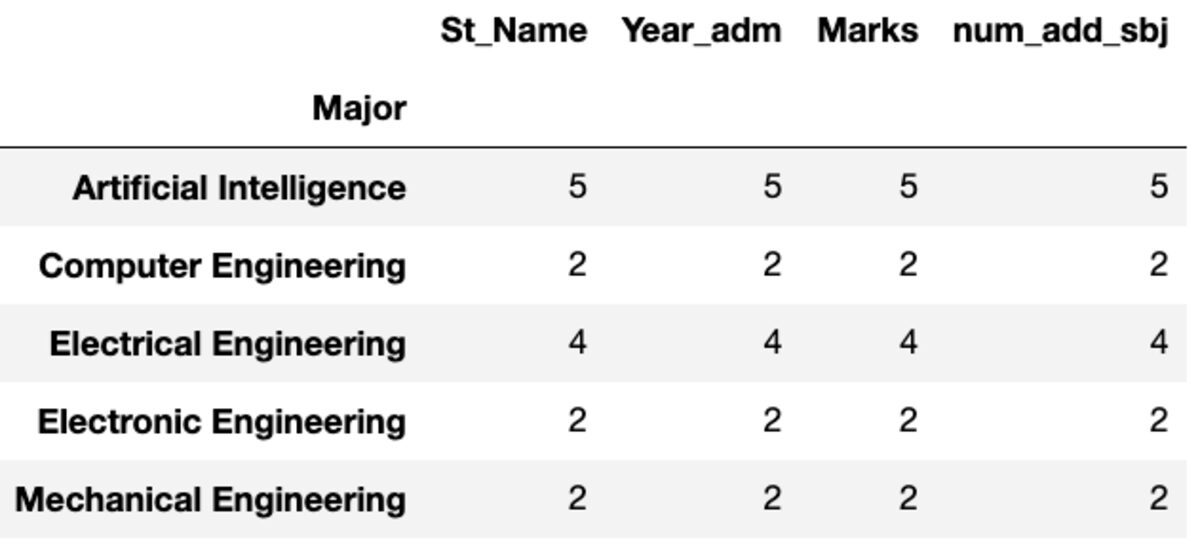
«Count» возвращает все значения, тогда как «Nunique» возвращает только уникальные значения в этой группе.
groups.count()
groups.nunique()
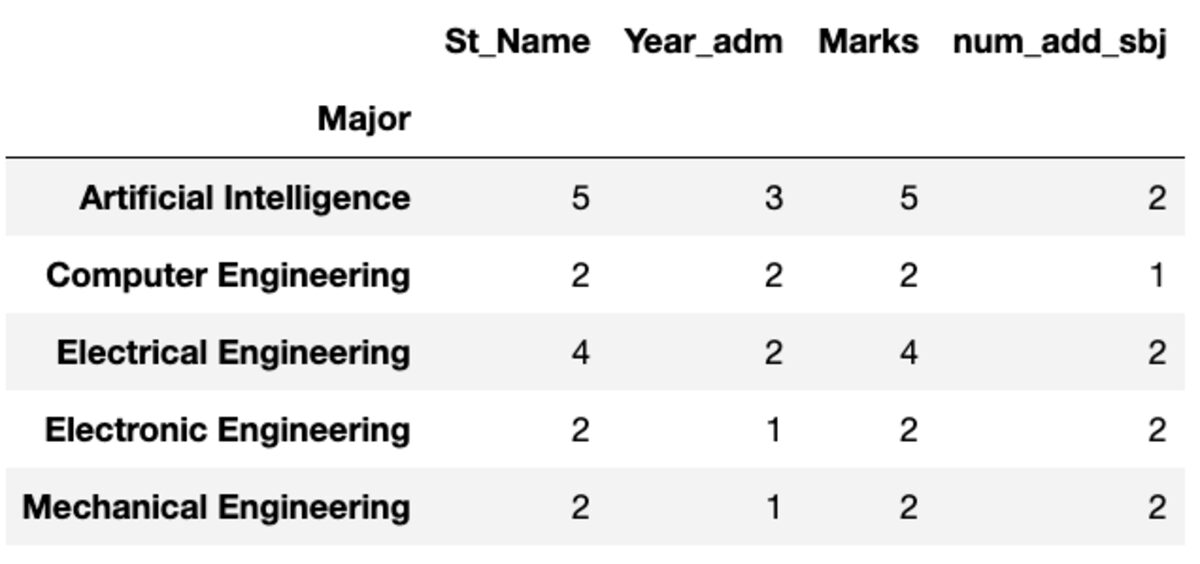
Переименовывать
Вы также можете переименовать имя агрегированного столбца в соответствии с вашими предпочтениями.
groups.aggregate("median").rename( columns={ "yr_adm": "median year of admission", "num_add_sbj": "median additional subject count", }
)
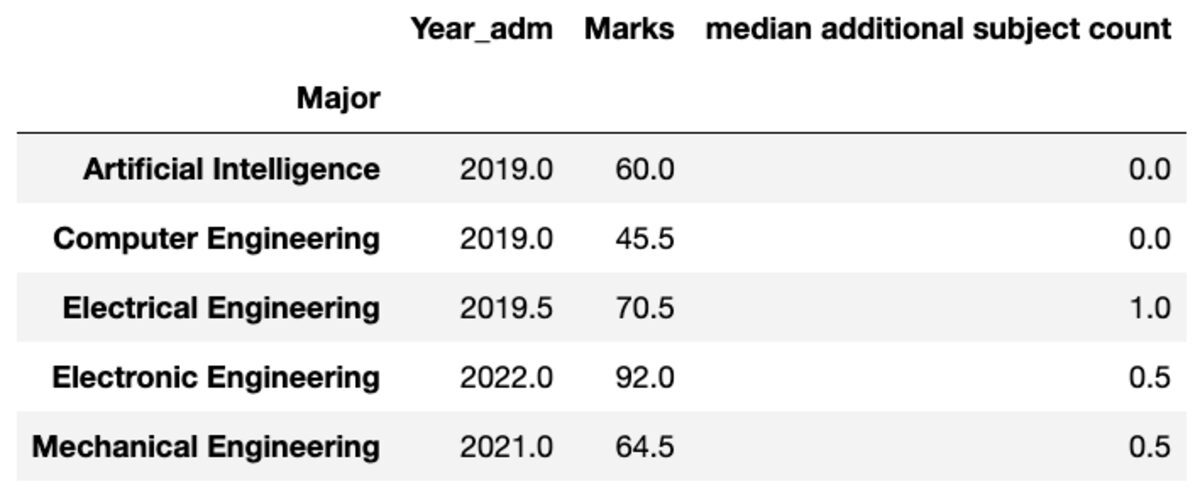
- Четко определите цель groupby: Вы пытаетесь сгруппировать данные по одному столбцу, чтобы получить среднее значение другого столбца? Или вы пытаетесь сгруппировать данные по нескольким столбцам, чтобы получить количество строк в каждой группе?
- Разберитесь с индексацией фрейма данных: Функция groupby использует индекс для группировки данных. Если вы хотите сгруппировать данные по столбцу, убедитесь, что столбец установлен как индекс, или вы можете использовать .set_index()
- Используйте соответствующую агрегатную функцию: его можно использовать с различными функциями агрегирования, такими как mean(), sum(), count(), min(), max().
- Используйте параметр as_index: Если установлено значение False, этот параметр указывает pandas использовать сгруппированные столбцы как обычные столбцы вместо индекса.
Вы также можете использовать groupby() в сочетании с другими функциями pandas, такими как pivot_table(), crosstab() и cut(), чтобы извлечь больше информации из ваших данных.
Функция groupby — это мощный инструмент для анализа данных и манипулирования ими, поскольку он позволяет группировать строки данных на основе одного или нескольких столбцов, а затем выполнять агрегированные вычисления для групп. В руководстве продемонстрированы различные способы использования функции groupby с помощью примеров кода. Надеюсь, это даст вам представление о различных вариантах, которые приходят с ним, а также о том, как они помогают в анализе данных.
Видхи Чаг — специалист по стратегии искусственного интеллекта и лидер цифровой трансформации, работающий на стыке продуктов, науки и техники для создания масштабируемых систем машинного обучения. Она является отмеченным наградами лидером инноваций, автором и международным спикером. Она поставила перед собой задачу демократизировать машинное обучение и сломать жаргон, чтобы каждый мог принять участие в этой трансформации.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- Платоблокчейн. Интеллект метавселенной Web3. Расширение знаний. Доступ здесь.
- Источник: https://www.kdnuggets.com/2023/01/effectively-pandas-groupby.html?utm_source=rss&utm_medium=rss&utm_campaign=how-to-effectively-use-pandas-groupby
- 10
- 100
- 2018
- 2023
- 7
- 9
- a
- способность
- в состоянии
- Достигать
- достигнутый
- дополнительный
- Дополнительно
- агрегирование
- AI
- Все
- позволяет
- анализ
- анализировать
- и
- Другой
- прикладной
- Применить
- Применение
- соответствующий
- искусственный
- искусственный интеллект
- автор
- доступен
- в среднем
- наградами
- основанный
- основной
- ниже
- биотехнология
- Ломать
- строить
- вычислять
- вызова
- случаев
- проверка
- Очистить
- код
- Column
- Колонки
- как
- комплекс
- компьютер
- Компьютерная инженерия
- Создайте
- Создающий
- изготовленный на заказ
- данным
- анализ данных
- Наборы данных
- демократизировать
- убивают
- отклонение
- различный
- Интернет
- цифровое преобразование
- направлять
- Dont
- каждый
- легко
- фактически
- электротехника
- Электронный
- Проект и
- и т.д
- все члены
- пример
- Примеры
- извлечение
- Осень
- Особенности
- заполнять
- фильтр
- Найдите
- Во-первых,
- Фокус
- после
- КАДР
- от
- функция
- Функции
- порождать
- получить
- данный
- дает
- будет
- группы
- Группы
- практический
- помощь
- надежды
- Как
- How To
- HTML
- HTTPS
- Импортировать
- in
- невероятно
- индекс
- Инновации
- размышления
- пример
- вместо
- Интеллекта
- Мультиязычность
- пересечение
- IT
- жаргон
- КДнаггетс
- Основные
- большой
- лидер
- УЧИТЬСЯ
- изучение
- библиотеки
- Библиотека
- Список
- ВЗГЛЯДЫ
- машина
- обучение с помощью машины
- основной
- сделать
- Манипуляция
- многих
- Совпадение
- Макс
- механический
- машиностроение
- средний
- метод
- Наша миссия
- модуль
- БОЛЕЕ
- с разными
- имя
- имена
- Необходимость
- следующий
- номер
- ONE
- с открытым исходным кодом
- Операционный отдел
- Опции
- Другое
- панд
- параметр
- часть
- особый
- Прохождение
- выполнять
- Мест
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- мощный
- Печать / PDF
- Продукт
- приводит
- цель
- Питон
- быстро
- случайный
- Управление по борьбе с наркотиками (DEA)
- учет
- регулярный
- осталось
- представляет
- требуется
- ОТДЫХ
- результат
- Итоги
- возвращают
- Возвращает
- Ричард
- год
- Бег
- то же
- масштабируемые
- НАУКА
- набор
- должен
- показанный
- аналогичный
- одинарной
- Размер
- некоторые
- Динамик
- конкретный
- стандарт
- статистика
- Шаг
- Стратег
- "Студент"
- Студенты
- предмет
- Предлагает
- суммировать
- системы
- Сложность задачи
- задачи
- говорит
- terms
- Ассоциация
- тип
- в
- инструментом
- Transform
- трансформация
- преобразований
- учебник
- Типы
- понимание
- созданного
- использование
- Наши ценности
- различный
- способы
- Что
- который
- будете
- работает
- бы
- X
- год
- ВАШЕ
- зефирнет
- нуль






