Введение
В быстро развивающемся мире генеративного искусственного интеллекта ключевая роль векторных баз данных становится все более очевидной. В этой статье рассматривается динамическое взаимодействие между векторными базами данных и генеративными решениями искусственного интеллекта, а также исследуется, как эти технологические основы формируют будущее творчества в области искусственного интеллекта. Присоединяйтесь к нам в путешествии по тонкостям этого мощного альянса и узнайте о преобразующем влиянии, которое векторные базы данных оказывают на передний план инновационных решений искусственного интеллекта.
Цели обучения
Эта статья поможет вам понять аспекты базы данных векторов, приведенные ниже.
- Значение векторных баз данных и ее ключевых компонентов
- Детальное изучение сравнения базы данных Vector с традиционной базой данных.
- Исследование векторных вложений с точки зрения приложения
- Создание векторной базы данных с использованием Pincone
- Реализация базы данных Pinecone Vector с использованием модели langchain LLM
Эта статья была опубликована в рамках Блогатон по Data Science.
Содержание
Что такое база данных векторов?
База данных векторов — это форма сбора данных, хранящихся в космосе. Тем не менее, здесь они хранятся в математических представлениях, поскольку формат, хранящийся в базах данных, упрощает запоминание входных данных открытыми моделями ИИ и позволяет нашему открытому приложению ИИ использовать когнитивный поиск, рекомендации и генерацию текста для различных случаев использования. отрасли, подвергшиеся цифровой трансформации. Хранение данных и их извлечение называются «векторными внедрениями» или «вложениями». Более того, это представлено в формате числового массива. Поиск намного проще, чем традиционные базы данных, используемые для ИИ, с огромными индексированными возможностями.
Характеристики векторных баз данных
- Он использует возможности этих векторных вложений, что приводит к индексированию и поиску в огромном наборе данных.
- Компактность со всеми форматами данных (изображения, текст или данные).
- Поскольку он адаптирует методы внедрения и высокоиндексированные функции, он может предложить комплексное решение для управления данными и входными данными для данной проблемы.
- База данных векторов организует данные с помощью многомерных векторов, содержащих сотни измерений. Мы можем настроить их очень быстро.
- Каждое измерение соответствует определенной функции или свойству объекта данных, которое оно представляет.
Традиционный против. База данных векторов
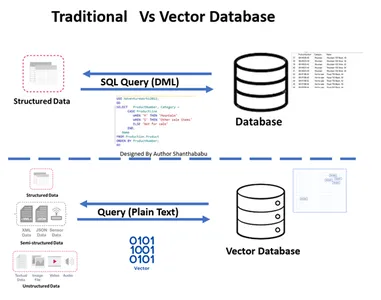
- На рисунке показан высокоуровневый рабочий процесс традиционной и векторной базы данных.
- Формальное взаимодействие с базой данных происходит посредством SQL операторы и данные хранятся в строковом и табличном формате.
- В базе данных Vector взаимодействие происходит посредством обычного текста (например, на английском языке) и данных, хранящихся в математических представлениях.
Сходство традиционных и векторных баз данных
Надо рассмотреть, чем базы данных Vector отличаются от традиционных. Давайте обсудим это здесь. Я могу отметить одно быстрое отличие: оно наблюдается в обычных базах данных. Данные хранятся в том виде, в каком они есть; мы могли бы добавить некоторую бизнес-логику для настройки данных и объединения или разделения данных в зависимости от бизнес-требований или требований. Однако векторная база данных претерпевает масштабную трансформацию, и данные становятся сложным векторным представлением.
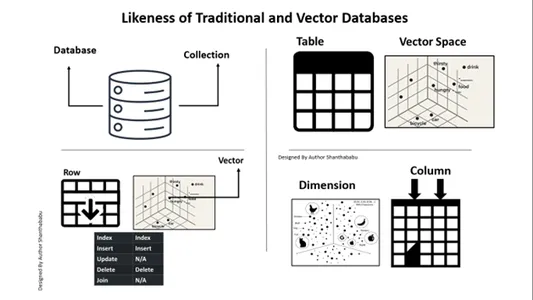
Вот карта для вашего понимания и ясности с точки зрения реляционные базы данных против векторных баз данных. Рисунок ниже не требует пояснений для понимания векторных баз данных с традиционными базами данных. Короче говоря, мы можем выполнять вставки и удаления в векторные базы данных, а не операторы обновления.
Простая аналогия для понимания векторных баз данных
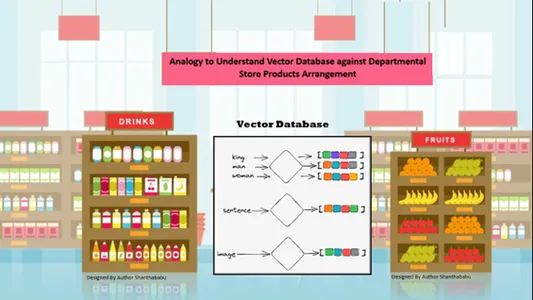
Данные автоматически распределяются в пространстве по сходству содержания хранимой информации. Итак, давайте рассмотрим универмаг по аналогии с векторной базой данных; Все продукты расставлены на полке в зависимости от характера, назначения, производства, использования и количества. При аналогичном поведении данные
автоматически упорядочиваются в векторной базе данных аналогичным образом, даже если жанр не был четко определен при хранении или доступе к данным.
Векторные базы данных обеспечивают высокую степень детализации и размеров конкретных сходств, поэтому клиент ищет желаемый продукт, производителя и количество и сохраняет товар в корзине. База данных Vector хранит все данные в идеальной структуре хранения; здесь инженерам машинного обучения и искусственного интеллекта не нужно вручную маркировать или помечать сохраненный контент.
Основные теории, лежащие в основе векторных баз данных
- Векторные вложения и их область применения
- Требования к индексированию
- Понимание семантического поиска и поиска по сходству
Векторное встраивание и его область применения
Векторное встраивание — это векторное представление в виде числовых значений. В сжатом формате внедрения фиксируют присущие свойства и ассоциации исходных данных, что делает их основным продуктом в сценариях использования искусственного интеллекта и машинного обучения. Разработка вложений для кодирования соответствующей информации об исходных данных в пространство меньшей размерности обеспечивает высокую скорость поиска, эффективность вычислений и эффективное хранение.
Уловить суть данных более идентично структурированным образом — это процесс векторного внедрения, образующий «модель внедрения». В конечном итоге эти модели учитывают все объекты данных, извлекают значимые шаблоны и отношения в источнике данных и преобразуют их в векторные представления. Впоследствии алгоритмы используют эти векторные вложения для выполнения различных задач. Многочисленные высокоразвитые модели внедрения, доступные в Интернете бесплатно или с оплатой по мере использования, облегчают выполнение векторного внедрения.
Область применения векторных вложений с точки зрения приложения
Эти внедрения компактны, содержат сложную информацию, наследуют отношения между данными, хранящимися в векторной базе данных, позволяют проводить эффективный анализ обработки данных для облегчения понимания и принятия решений, а также динамически создавать различные инновационные продукты данных в любой организации.
Методы векторного внедрения необходимы для устранения разрыва между читаемыми данными и сложными алгоритмами. Поскольку типы данных являются числовыми векторами, мы смогли раскрыть потенциал для широкого спектра приложений генеративного ИИ наряду с доступными моделями открытого ИИ.
Несколько заданий с векторным внедрением
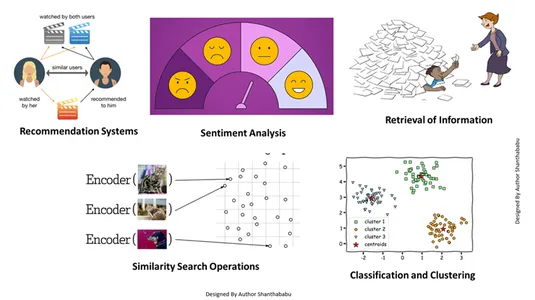
Это векторное встраивание помогает нам выполнять несколько задач:
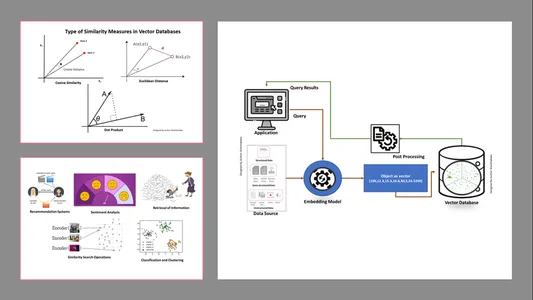
- Получение информации: С помощью этих мощных методов мы можем создать влиятельные поисковые системы, которые помогут нам находить ответы на основе запросов пользователей в сохраненных файлах, документах или мультимедиа.
- Операции поиска по сходству: Это хорошо организовано и проиндексировано; это помогает нам найти сходство между различными вхождениями в векторных данных.
- Классификация и кластеризация: Используя эти методы внедрения, мы можем использовать эти модели для обучения соответствующих алгоритмов машинного обучения, а также группировать и классифицировать их.
- Системы рекомендаций: Поскольку методы внедрения организованы должным образом, это приводит к созданию систем рекомендаций, точно связывающих продукты, средства массовой информации и статьи на основе исторических данных.
- Анализ настроений: Эта модель внедрения помогает нам классифицировать и находить решения по настроениям.
Требования к индексированию
Как мы знаем, индекс улучшит поиск данных из таблицы в традиционных базах данных, аналогичных векторным базам данных, и предоставит функции индексирования.
Базы данных векторов предоставляют «плоские индексы», которые являются прямым представлением векторного встраивания. Возможности поиска являются всеобъемлющими, и при этом не используются предварительно обученные кластеры. Он выполняет вектор запроса для каждого векторного встраивания, и для каждой пары рассчитываются K-расстояния.
- Из-за простоты этого индекса для создания новых индексов требуется минимум вычислений.
- Действительно, плоский индекс может эффективно обрабатывать запросы и обеспечивать быстрое получение данных.
Понимание семантического поиска и поиска по сходству
Мы выполняем два разных поиска в векторных базах данных: семантический поиск и поиск по сходству.
- Семантический поиск: При поиске информации вместо поиска по ключевым словам вы можете найти ее на основе методологии значимого разговора. Оперативное проектирование играет жизненно важную роль в передаче входных данных в систему. Этот поиск, несомненно, обеспечивает более качественный поиск и результаты, которые можно использовать в инновационных приложениях, SEO, генерации текста и подведении итогов.
- Поиск по сходству: Всегда при анализе данных поиск по сходству позволяет получить неструктурированные, гораздо более качественные наборы данных. Что касается векторных баз данных, мы должны выяснить близость двух векторов и то, насколько они похожи друг на друга: таблицы, текст, документы, изображения, слова и аудиофайлы. В процессе понимания сходство между векторами проявляется как сходство между объектами данных в данном наборе данных. Это упражнение помогает нам понять взаимодействие, выявить закономерности, извлечь ценную информацию и принять решения с точки зрения приложения. Поиск по семантике и сходству поможет нам создать приведенные ниже приложения с отраслевой выгодой.
- Поиск информации: Используя открытый искусственный интеллект и векторные базы данных, мы создадим поисковые системы для поиска информации с использованием запросов бизнес-пользователей или конечных пользователей и индексированных документов внутри векторной базы данных.
- Классификация и кластеризация:Классификация или кластеризация схожих точек данных или групп объектов предполагает отнесение их к нескольким категориям на основе общих характеристик.
- Обнаружение аномалии: Обнаружение отклонений от обычных закономерностей путем измерения сходства точек данных и выявления нарушений.
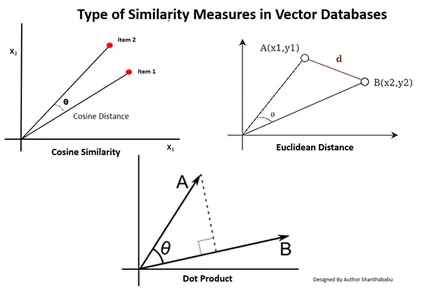
Типы мер сходства в векторных базах данных
Методы измерения зависят от характера данных и особенностей применения. Обычно для измерения сходства и знакомства с машинным обучением используются три метода.
Евклидово расстояние
Проще говоря, расстояние между двумя векторами — это расстояние по прямой между двумя векторными точками, которые измеряют улицу.
Скалярное произведение
Это помогает нам понять выравнивание двух векторов, указывая, указывают ли они в одном направлении, в противоположных направлениях или перпендикулярны друг другу.
Косинусное подобие
Он оценивает сходство двух векторов по углу между ними, как показано на рисунке. В этом случае значения и величина векторов несущественны и не влияют на результаты; при расчете учитывается только угол.
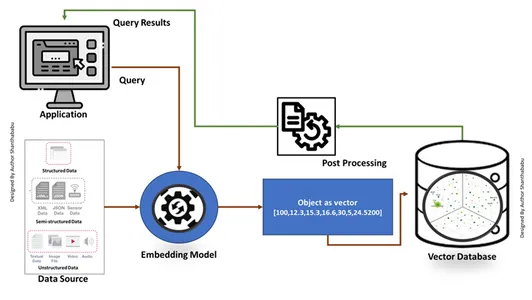
Традиционные базы данных. Поиск точных совпадений операторов SQL и получение данных в табличном формате. При этом мы занимаемся векторными базами данных в поисках максимально похожего на входной запрос вектора на простом английском языке с использованием методов оперативного проектирования. База данных использует алгоритм поиска приблизительного ближайшего соседа (ANN) для поиска похожих данных. Всегда предоставляйте достаточно точные результаты при высокой производительности, точности и времени отклика.
Рабочий механизм
- Базы данных векторов сначала преобразуют данные во встраиваемые векторы, сохраняют их в базах данных векторов и создают индексацию для более быстрого поиска.
- Запрос приложения будет взаимодействовать с вектором внедрения, искать ближайшего соседа или аналогичные данные в базе данных векторов с использованием индекса и получать результаты, переданные в приложение.
- В зависимости от бизнес-требований полученные данные будут точно настроены, отформатированы и отображены на стороне конечного пользователя или в канале запросов или действий.
Создание базы данных векторов
Давайте соединимся с Pinecone.
Вы можете подключиться к Pinecone, используя Google, GitHub или Microsoft ID.
Создайте новый логин пользователя для вашего использования.
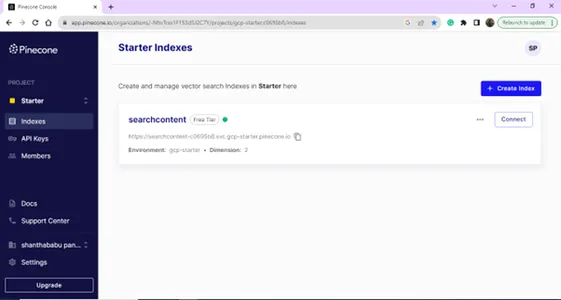
После успешного входа в систему вы попадете на страницу индекса; вы можете создать индекс для целей вашей базы данных векторов. Нажмите кнопку «Создать индекс».
Создайте новый индекс, указав имя и размеры.
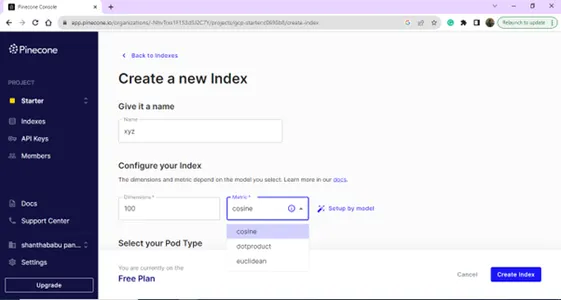
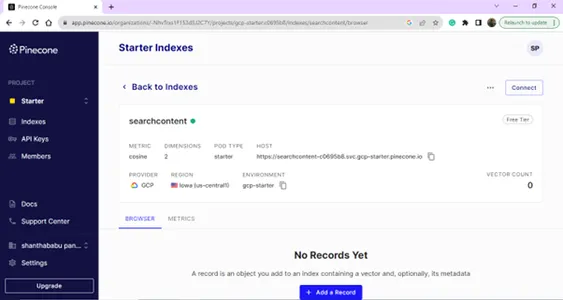
Страница индексного списка,
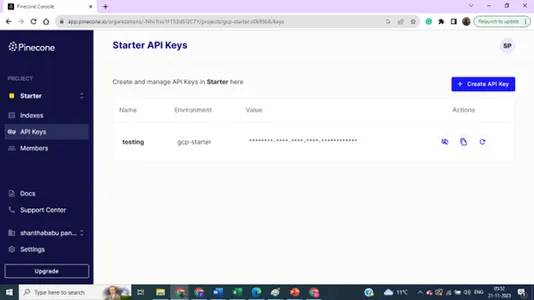
Детали индекса — имя, регион и среда — нам нужны все эти данные, чтобы подключить нашу векторную базу данных из кода построения модели.
Подробности настроек проекта,
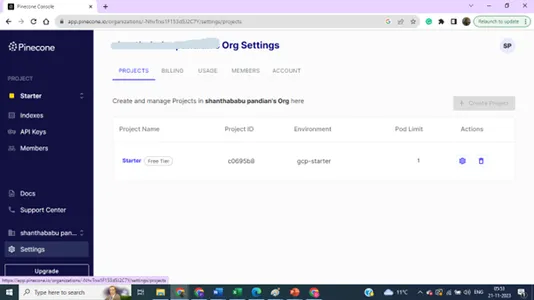
Вы можете обновить свои предпочтения для нескольких индексов и ключей для целей проекта.
До сих пор мы обсуждали создание индекса и настроек базы данных векторов в Pinecone.
Реализация векторной базы данных с использованием Python
Давайте теперь займемся кодированием.
Импорт библиотек
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.llms import OpenAI
from langchain.vectorstores import Pinecone
from langchain.document_loaders import TextLoader
from langchain.chains.question_answering import load_qa_chain
from langchain.chat_models import ChatOpenAIПредоставление ключа API для баз данных OpenAI и Vector
import os
os.environ["OPENAI_API_KEY"] = "xxxxxxxx"
PINECONE_API_KEY = os.environ.get('PINECONE_API_KEY', 'xxxxxxxxxxxxxxxxxxxxxxx')
PINECONE_API_ENV = os.environ.get('PINECONE_API_ENV', 'gcp-starter')
api_keys="xxxxxxxxxxxxxxxxxxxxxx"
llm = OpenAI(OpenAI=api_keys, temperature=0.1)Инициирование LLM
llm=OpenAI(openai_api_key=os.environ["OPENAI_API_KEY"],temperature=0.6)Инициирование Сосновая шишка
import pinecone
pinecone.init(
api_key=PINECONE_API_KEY,
environment=PINECONE_API_ENV
index_name = "demoindex" Загрузка файла .csv для создания базы данных векторов
from langchain.document_loaders.csv_loader import CSVLoader
loader = CSVLoader(file_path="/content/drive/My Drive/Colab_Notebooks/cereal.csv"
,source_column="name")
data = loader.load()Разбить текст на куски
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=20)
text_chunks = text_splitter.split_documents(data)Поиск текста в text_chunk
text_chunksРезультат
[Document(page_content='name: 100% Brannmfr: Nntype: Cnкалории: 70nprotein: 4nfat: 1nsodium: 130nfiber: 10ncarbo: 5nsugars: 6npotass: 280nvitamins: 25nshelf: 3nweight: 1ncups: 0.33nrating: 68.402973 100nрекомендация: детские, метаданные={ 'source': '0% Бран', 'row': XNUMX}), , …..
Встраивание зданий
embeddings = OpenAIEmbeddings()Создайте экземпляр Pinecone для векторной базы данных из «данных».
vectordb = Pinecone.from_documents(text_chunks,embeddings,index_name="demoindex")Создайте ретривер для запроса базы данных векторов.
retriever = vectordb.as_retriever(score_threshold = 0.7)Получение данных из векторной базы данных
rdocs = retriever.get_relevant_documents("Cocoa Puffs")
rdocsИспользование подсказки и получение данных
from langchain.prompts import PromptTemplate
prompt_template = """Given the following context and a question,
generate an answer based on this context only.
,Please state "I don't know." Don't try to make up an answer.
CONTEXT: {context}
QUESTION: {question}"""
PROMPT = PromptTemplate(
template=prompt_template, input_variables=["context", "question"]
)
chain_type_kwargs = {"prompt": PROMPT}
from langchain.chains import RetrievalQA
chain = RetrievalQA.from_chain_type(llm=llm,
chain_type="stuff",
retriever=retriever,
input_key="query",
return_source_documents=True,
chain_type_kwargs=chain_type_kwargs)
Давайте запросим данные.
chain('Can you please provide cereal recommendation for Kids?')Вывод из запроса
{'query': 'Can you please provide cereal recommendation for Kids?',
'result': [Document(page_content='name: Crispixnmfr: Kntype: Cncalories: 110nprotein: 2nfat: 0nsodium: 220nfiber: 1ncarbo: 21nsugars: 3npotass: 30nvitamins: 25nshelf: 3nweight: 1ncups: 1nrating: 46.895644nrecommendation: Kids', metadata={'row': 21.0, 'source': '/content/drive/My Drive/Colab_Notebooks/cereal.csv'}), ..]Заключение
Надеюсь, вы понимаете, как работают векторные базы данных, их компоненты, архитектуру и характеристики векторных баз данных в решениях генеративного искусственного интеллекта. Поймите, чем векторная база данных отличается от традиционной базы данных и сравните ее с обычными элементами базы данных. Действительно, аналогия помогает лучше понять векторную базу данных. База данных векторов сосновых шишек и этапы индексирования помогут вам создать базу данных векторов и предоставить ключ для следующей реализации кода.
Основные выводы
- Компактность со структурированными, неструктурированными и полуструктурированными данными.
- Он адаптирует методы внедрения и высокоиндексированные функции.
- Взаимодействие происходит посредством обычного текста с использованием подсказки (например, на английском языке). И данные хранятся в математических представлениях.
- Калибровка сходства в векторных базах данных осуществляется с помощью евклидова расстояния, косинусного сходства и скалярного произведения.
Часто задаваемые вопросы
А. База данных векторов хранит набор данных в пространстве. Он хранит данные в математических представлениях. поскольку формат, хранящийся в базах данных, облегчает открытым моделям ИИ запоминание предыдущих входных данных и позволяет нашему открытому приложению ИИ использовать когнитивный поиск, рекомендации и точную генерацию текста для различных вариантов использования в отраслях с цифровой трансформацией.
А. Некоторые из характеристик: 1. Он использует возможности векторных вложений, что приводит к индексированию и поиску в огромном наборе данных. 2. Компактность со структурированными, неструктурированными и полуструктурированными данными. 3. База данных векторов организует данные с помощью многомерных векторов, содержащих сотни измерений.
A. База данных ==> Коллекции
Таблица ==> Векторное пространство
Строка==>Цектор
Столбец==>Размер
В базах данных Vector возможны вставка и удаление, как и в традиционной базе данных.
Обновление и присоединение не входят в область действия.
– Быстрый поиск информации для быстрого сбора больших объемов данных.
– Операции семантического поиска и поиска по сходству в документах огромного размера.
– Применение классификации и кластеризации.
– Системы анализа рекомендаций и настроений.
A5: Ниже приведены три метода измерения сходства:
- Евклидово расстояние
– Косинусное подобие
- Скалярное произведение
Материалы, показанные в этой статье, не принадлежат Analytics Vidhya и используются по усмотрению Автора.
Похожие страницы:
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://www.analyticsvidhya.com/blog/2023/12/vector-databases-in-generative-ai-solutions/
- :имеет
- :является
- :нет
- $UP
- 1
- 10
- 12
- 13
- 46
- 7
- 8
- 9
- a
- в состоянии
- О нас
- доступа
- точность
- точный
- точно
- через
- адаптируются
- Добавить
- влиять на
- AI
- AI модели
- алгоритм
- алгоритмы
- выравнивание
- Все
- Альянс
- позволять
- позволяет
- вдоль
- всегда
- среди
- an
- анализ
- аналитика
- Аналитика Видхья
- и
- ответ
- любой
- API
- очевидный
- Применение
- конкретное приложение
- Приложения
- приблизительный
- архитектура
- МЫ
- расположены
- массив
- гайд
- статьи
- искусственный
- искусственный интеллект
- Искусственный интеллект и машинное обучение
- AS
- аспекты
- оценивает
- ассоциации
- At
- аудио
- автоматически
- доступен
- основанный
- BE
- становиться
- становится
- поведение
- за
- не являетесь
- ниже
- Преимущества
- Лучшая
- между
- блогатон
- приносить
- строить
- Строительство
- бизнес
- кнопка
- by
- рассчитанный
- расчет
- под названием
- CAN
- возможности
- возможности
- захватить
- случаев
- случаев
- категории
- цепь
- цепи
- характеристика
- ясность
- классификация
- классифицировать
- нажмите на
- кластеризации
- код
- Кодирование
- познавательный
- лыжных шлемов
- обычно
- компактный
- сравнить
- сравнение
- полный
- комплекс
- компоненты
- комплексный
- вычисление
- вычислительный
- Свяжитесь
- Соединительный
- Рассматривать
- считается
- содержать
- содержание
- контекст
- обычный
- Разговор
- конвертировать
- соответствует
- может
- Создайте
- Создающий
- креативность
- клиент
- данным
- анализ данных
- точки данных
- обработка данных
- База данных
- базы данных
- Наборы данных
- сделка
- Принятие решений
- решения
- запросы
- выводить
- проектирование
- желанный
- подробнее
- обнаружение
- развитый
- отличаться
- разница
- различный
- цифровой
- Размеры
- размеры
- направлять
- направление
- инструкция
- обнаружение
- усмотрение
- обсуждать
- обсуждается
- отображается
- расстояние
- do
- Документация
- приносит
- Дон
- DOT
- динамический
- динамично
- e
- каждый
- простота
- легче
- фактически
- затрат
- эффективный
- или
- элементы
- вложения
- включить
- конец
- Проект и
- Инженеры
- Двигатели
- Английский
- обеспечивает
- Окружающая среда
- сущность
- существенный
- Эфир (ETH)
- Даже
- развивается
- выполнять
- Упражнение
- Исследование
- извлечение
- содействовал
- фамильярность
- далеко
- Особенность
- Особенности
- ФРС
- фигура
- Файл
- Файлы
- Найдите
- Во-первых,
- плоский
- после
- Что касается
- Передний край
- форма
- формат
- Бесплатно
- от
- будущее
- разрыв
- порождать
- поколение
- генеративный
- Генеративный ИИ
- жанре
- GitHub
- Дайте
- данный
- группы
- Группы
- обрабатывать
- происходить
- Есть
- помощь
- помогает
- здесь
- High
- на высшем уровне
- очень
- исторический
- Как
- Однако
- HTTPS
- огромный
- Сотни
- i
- ID
- определения
- if
- изображений
- Влияние
- реализация
- Импортировать
- улучшать
- in
- все больше и больше
- индекс
- индексированный
- Индексы
- с указанием
- Индексы
- промышленности
- промышленность
- влиятельный
- информация
- свойственный
- инновационный
- вход
- затраты
- Вставки
- внутри
- размышления
- пример
- вместо
- Интеллекта
- взаимодействовать
- взаимодействие
- взаимодействие
- в
- тонкости
- включает в себя
- IT
- ЕГО
- Джобс
- присоединиться
- Присоединяйтесь к нам
- путешествие
- всего
- Основные
- ключи
- ключевые слова
- Дети
- Знать
- этикетка
- Земля
- пейзаж
- большой
- ведущий
- Лиды
- изучение
- Кредитное плечо
- рычаги
- такое как
- Список
- загрузчик
- логика
- Войти
- машина
- обучение с помощью машины
- основной
- сделать
- ДЕЛАЕТ
- Создание
- управления
- способ
- вручную
- ПРОИЗВОДИТЕЛЬ
- карта
- массивный
- спички
- математический
- значимым
- проводить измерение
- меры
- измерение
- механизм
- Медиа
- идти
- Методология
- методы
- Microsoft
- минимальный
- модель
- Модели
- БОЛЕЕ
- Более того
- самых
- много
- с разными
- должен
- имя
- природа
- Необходимость
- Новые
- сейчас
- многочисленный
- объект
- объекты
- of
- предлагают
- on
- ONE
- те,
- онлайн
- только
- открытый
- OpenAI
- Операционный отдел
- противоположность
- or
- организация
- Организованный
- организует
- оригинал
- OS
- Другое
- наши
- принадлежащих
- страница
- пара
- часть
- Прошло
- Прохождение
- паттеранами
- ИДЕАЛЬНОЕ
- выполнять
- производительность
- выполнены
- выполняет
- перспектива
- перспективы
- картина
- основной
- одноцветный
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- играет
- пожалуйста
- Точка
- пунктов
- возможное
- потенциал
- мощностью
- мощный
- практическое
- Практическое применение
- необходимость
- Точно
- предпочтения
- предыдущий
- Проблема
- процесс
- Продукт
- Продукция
- Проект
- видный
- наводящие
- должным образом
- свойства
- собственность
- обеспечивать
- обеспечение
- обеспечение
- опубликованный
- пуфы
- цель
- целей
- количество
- Запросы
- вопрос
- САЙТ
- быстрее
- быстро
- быстро
- Рекомендация
- рекомендаций
- по
- область
- отношения
- Отношения
- соответствующие
- представление
- представленный
- представляет
- обязательный
- Требования
- ответ
- ответы
- результат
- Итоги
- Показали
- Роли
- РЯД
- s
- то же
- Наука
- сфера
- Поиск
- Поисковые системы
- поиск
- поиск
- настроение
- поисковая оптимизация
- настройки
- Форма
- формирование
- общие
- полка
- Короткое
- показанный
- Шоу
- сторона
- аналогичный
- сходство
- просто
- с
- одинарной
- Размер
- So
- Решение
- Решения
- некоторые
- Источник
- Space
- конкретный
- скорость
- раскол
- обнаружение
- SQL
- Область
- заявление
- отчетность
- Шаги
- По-прежнему
- диск
- магазин
- хранить
- магазины
- Структура
- структурированный
- Кабинет
- впоследствии
- успешный
- взаимодействие
- система
- системы
- T
- ТАБЛИЦЫ
- TAG
- задачи
- снижения вреда
- технологический
- terms
- текст
- генерация текста
- чем
- который
- Ассоциация
- Будущее
- их
- Их
- Эти
- они
- этой
- три
- Через
- время
- раз
- в
- традиционный
- Train
- Transform
- трансформация
- преобразующей
- преобразован
- стараться
- два
- Типы
- В конечном счете
- понимать
- понимание
- несомненно
- отпереть
- отпирающий
- Обновление ПО
- модернизация
- us
- Применение
- использование
- используемый
- Информация о пользователе
- использования
- через
- обычный
- Наши ценности
- разнообразие
- различный
- очень
- жизненный
- vs
- законопроект
- we
- WebP
- вполне определенный
- были
- Что
- Что такое
- будь то
- который
- в то время как
- будете
- в
- слова
- Работа
- работает
- бы
- являетесь
- ВАШЕ
- зефирнет