Введение
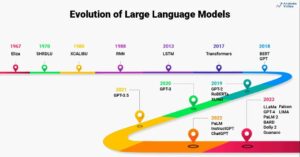
Представьте себе, что вы стоите в тускло освещенной библиотеке и пытаетесь расшифровать сложный документ, одновременно жонглируя десятками других текстов. Таков был мир Трансформеров до того, как в статье «Внимание — это все, что вам нужно» была представлена революционная идея — механизм внимания.
Содержание
Ограничения RNN
Традиционные последовательные модели, такие как Рекуррентные нейронные сети (RNN), обрабатывал язык слово за словом, что приводило к нескольким ограничениям:
- Краткосрочная зависимость: RNN изо всех сил пытались уловить связи между далекими словами, часто неправильно интерпретируя смысл таких предложений, как «человек, который вчера был в зоопарке», где подлежащее и глагол находятся далеко друг от друга.
- Ограниченный параллелизм: Последовательная обработка информации по своей сути медленная, что препятствует эффективному обучению и использованию вычислительных ресурсов, особенно для длинных последовательностей.
- Сосредоточьтесь на местном контексте: RNN в первую очередь учитывают непосредственных соседей, потенциально пропуская важную информацию из других частей предложения.
Эти ограничения препятствовали способности Трансформеров выполнять сложные задачи, такие как машинный перевод и понимание естественного языка. Затем появился механизм внимания, революционный прожектор, который освещает скрытые связи между словами, меняя наше понимание языковой обработки. Но что именно решило внимание и как оно изменило игру «Трансформеров»?
Давайте сосредоточимся на трех ключевых областях:
Долгосрочная зависимость
- Проблема: Традиционные модели часто спотыкались о такие предложения, как «женщина, которая жила на холме, вчера вечером видела падающую звезду». Они изо всех сил пытались связать слова «женщина» и «падающая звезда» из-за их расстояния, что приводило к неверным толкованиям.
- Механизм внимания: Представьте, что модель освещает предложение ярким лучом, напрямую связывая слово «женщина» со словом «падающая звезда» и понимая предложение в целом. Эта способность фиксировать взаимоотношения независимо от расстояния имеет решающее значение для таких задач, как машинный перевод и обобщение.
Читайте также: Обзор долговременной кратковременной памяти (LSTM)
Мощность параллельной обработки
- Проблема: Традиционные модели обрабатывали информацию последовательно, как если бы вы читали книгу страницу за страницей. Это было медленно и неэффективно, особенно для длинных текстов.
- Механизм внимания: Представьте себе, что несколько прожекторов одновременно сканируют библиотеку, параллельно анализируя разные части текста. Это значительно ускоряет работу модели, позволяя ей эффективно обрабатывать огромные объемы данных. Эта мощность параллельной обработки необходима для обучения сложных моделей и прогнозирования в реальном времени.
Глобальное понимание контекста
- Проблема: Традиционные модели часто фокусировались на отдельных словах, упуская из виду более широкий контекст предложения. Это приводило к недопониманию в таких случаях, как сарказм или двойной смысл.
- Механизм внимания: Представьте себе, как прожектор проносится по всей библиотеке, рассматривая каждую книгу и понимая, как они связаны друг с другом. Такое понимание глобального контекста позволяет модели учитывать весь текст при интерпретации каждого слова, что приводит к более богатому и тонкому пониманию.
Устранение неоднозначности многозначных слов
- Проблема: Такие слова, как «банк» или «яблоко», могут быть существительными, глаголами или даже компаниями, создавая двусмысленность, которую традиционные модели пытались разрешить.
- Механизм внимания: Представьте себе, что модель освещает все случаи появления слова «банк» в предложении, а затем анализирует окружающий контекст и отношения с другими словами. Рассматривая грамматическую структуру, близлежащие существительные и даже прошлые предложения, механизм внимания может определить предполагаемое значение. Эта способность устранять неоднозначность многозначных слов имеет решающее значение для таких задач, как машинный перевод, обобщение текста и диалоговые системы.
Эти четыре аспекта — долгосрочная зависимость, мощность параллельной обработки, понимание глобального контекста и устранение неоднозначности — демонстрируют преобразующую силу механизмов внимания. Они выдвинули Трансформеры на передний план обработки естественного языка, что позволило им решать сложные задачи с поразительной точностью и эффективностью.
Поскольку НЛП и, в частности, LLM продолжают развиваться, механизмы внимания, несомненно, будут играть еще более важную роль. Они являются мостом между линейной последовательностью слов и богатым разнообразием человеческого языка и, в конечном счете, ключом к раскрытию истинного потенциала этих лингвистических чудес. В этой статье рассматриваются различные типы механизмов внимания и их функциональные возможности.
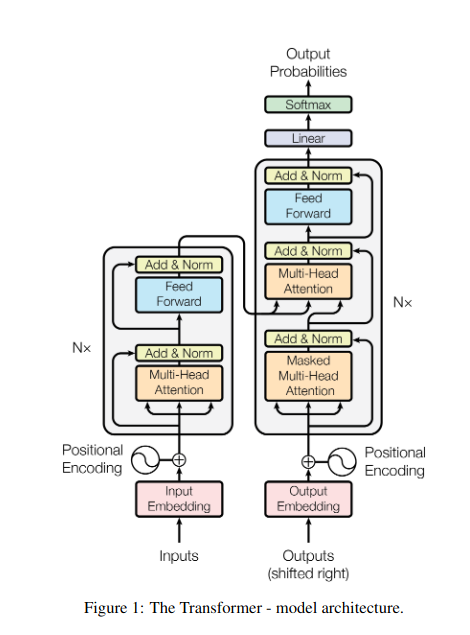
1. Внимание к себе: путеводная звезда трансформера
Представьте себе, что вы жонглируете несколькими книгами и вам нужно ссылаться на определенные отрывки в каждой при написании резюме. Самовнимание или внимание масштабированного скалярного произведения действует как интеллектуальный помощник, помогая моделям делать то же самое с последовательными данными, такими как предложения или временные ряды. Это позволяет каждому элементу последовательности обрабатывать каждый другой элемент, эффективно фиксируя долгосрочные зависимости и сложные отношения.
Вот более детальный взгляд на его основные технические аспекты:
Векторное представление
Каждый элемент (слово, точка данных) преобразуется в многомерный вектор, кодирующий его информационное содержание. Это векторное пространство служит основой для взаимодействия между элементами.
Трансформация QKV
Определены три ключевые матрицы:
- Запрос (В): Представляет «вопрос», который каждый элемент задает другим. Q фиксирует информационные потребности текущего элемента и направляет его поиск соответствующей информации в последовательности.
- Ключ (К): Содержит «ключ» к информации каждого элемента. K кодирует суть содержимого каждого элемента, позволяя другим элементам определять потенциальную релевантность на основе их собственных потребностей.
- Значение (В): Хранит фактический контент, которым каждый элемент хочет поделиться. V содержит подробную информацию, к которой другие элементы могут получить доступ и использовать ее на основе их показателей внимания.
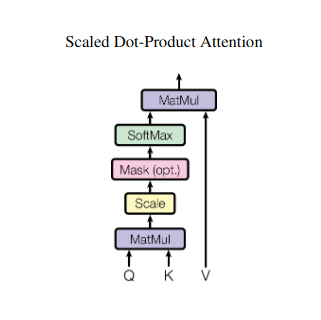
Расчет оценки внимания
Совместимость между каждой парой элементов измеряется посредством скалярного произведения между их соответствующими векторами Q и K. Более высокие баллы указывают на более сильную потенциальную связь между элементами.
Масштабированные веса внимания
Чтобы обеспечить относительную важность, эти оценки совместимости нормализуются с использованием функции softmax. В результате получаются веса внимания в диапазоне от 0 до 1, представляющие взвешенную важность каждого элемента для контекста текущего элемента.
Взвешенное агрегирование контекста
К матрице V применяются веса внимания, по существу выделяющие важную информацию из каждого элемента на основе ее релевантности текущему элементу. Эта взвешенная сумма создает контекстуализированное представление текущего элемента, включающее информацию, полученную из всех других элементов последовательности.
Улучшенное представление элементов
Благодаря расширенному представлению элемент теперь обладает более глубоким пониманием своего собственного содержания, а также своих отношений с другими элементами в последовательности. Это преобразованное представление формирует основу для последующей обработки в модели.
Этот многоэтапный процесс позволяет сосредоточиться на:
- Захват долгосрочных зависимостей: Отношения между удаленными элементами становятся очевидными, даже если они разделены множеством промежуточных элементов.
- Моделирование сложных взаимодействий: Выявляются тонкие зависимости и корреляции внутри последовательности, что приводит к более глубокому пониманию структуры и динамики данных.
- Контекстуализируйте каждый элемент: Модель анализирует каждый элемент не изолированно, а в более широких рамках последовательности, что приводит к более точным и детальным прогнозам или представлениям.
Внимание к себе произвело революцию в том, как модели обрабатывают последовательные данные, открыв новые возможности в различных областях, таких как машинный перевод, генерация естественного языка, прогнозирование временных рядов и многое другое. Его способность раскрывать скрытые связи внутри последовательностей представляет собой мощный инструмент для раскрытия информации и достижения превосходной производительности в широком спектре задач.
2. Внимание нескольких голов: взгляд через разные линзы
Внимание к себе обеспечивает целостное представление, но иногда решающее значение имеет сосредоточение внимания на конкретных аспектах данных. Вот тут-то и приходит на помощь внимание нескольких голов. Представьте себе, что у вас есть несколько помощников, каждый из которых оснащен разными объективами:
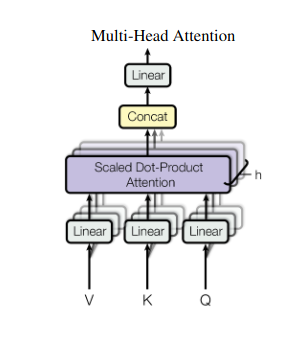
- Несколько «голов» создаются, каждый из которых обрабатывает входную последовательность через свои собственные матрицы Q, K и V.
- Каждый руководитель учится концентрироваться на различных аспектах данных, таких как долгосрочные зависимости, синтаксические отношения или локальные взаимодействия слов.
- Выходные данные каждой головы затем объединяются и проецируются в окончательное представление, отражающее многогранный характер входных данных.
Это позволяет модели одновременно учитывать различные точки зрения, что приводит к более глубокому и детальному пониманию данных.
3. Перекрестное внимание: наведение мостов между последовательностями
Способность понимать связи между различными частями информации имеет решающее значение для многих задач НЛП. Представьте себе, что вы пишете рецензию на книгу: вы не просто суммируете текст слово в слово, а, скорее, вырисовываете идеи и связи между главами. Входить перекрестное внимание, мощный механизм, который строит мосты между последовательностями, позволяя моделям использовать информацию из двух разных источников.
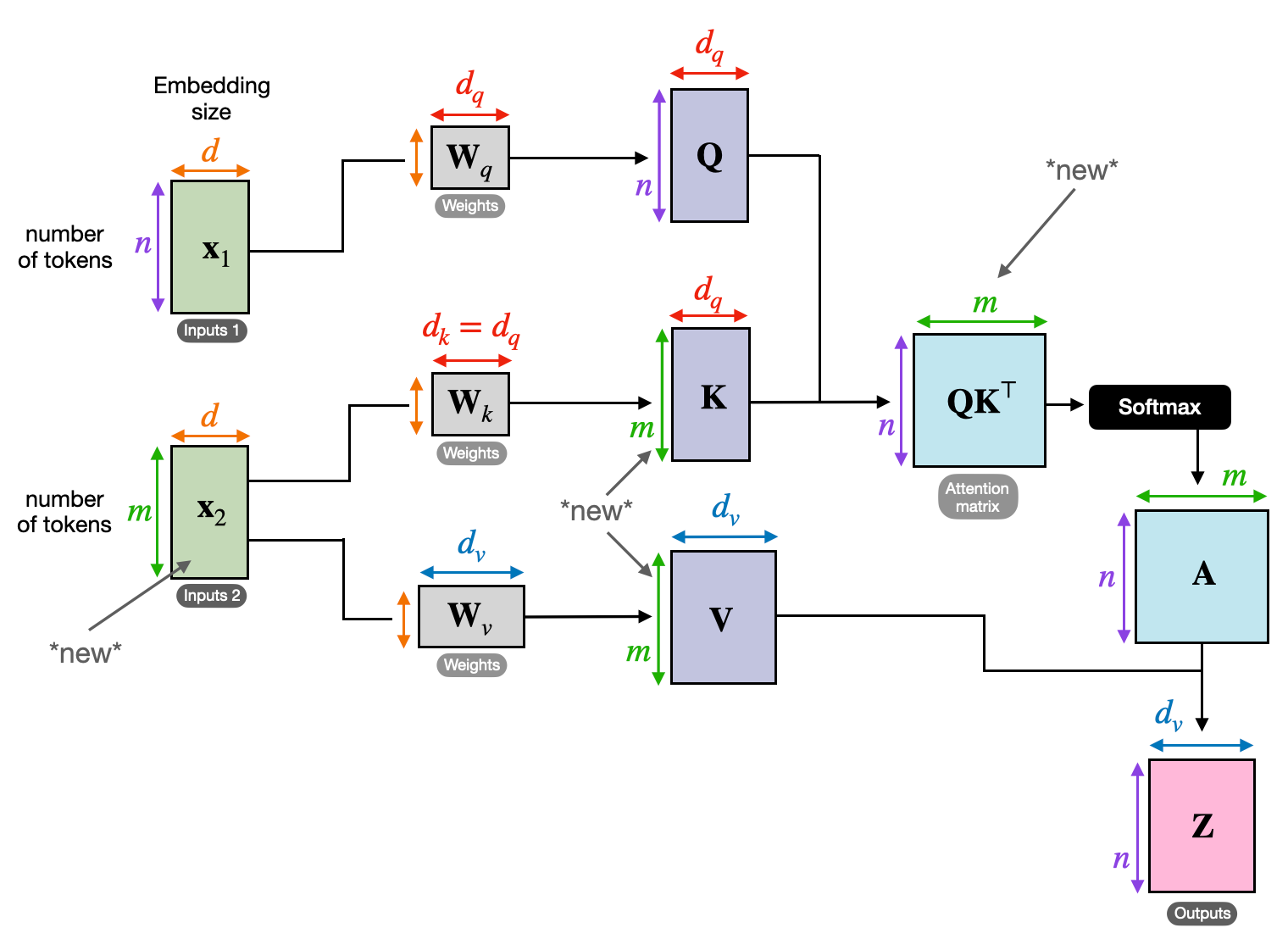
- В архитектурах кодировщика-декодера, таких как Transformers, кодер обрабатывает входную последовательность (книгу) и генерирует скрытое представление.
- Ассоциация декодер использует перекрестное внимание, чтобы следить за скрытым представлением кодировщика на каждом этапе при создании выходной последовательности (обзор).
- Матрица Q декодера взаимодействует с матрицами K и V кодера, позволяя ему сосредоточиться на соответствующих частях книги при написании каждого предложения обзора.
Этот механизм неоценим для таких задач, как машинный перевод, обобщение и ответы на вопросы, где понимание взаимосвязей между входными и выходными последовательностями имеет важное значение.
4. Причинное внимание: сохранение течения времени
Представьте себе, что вы предсказываете следующее слово в предложении, не заглядывая вперед. Традиционные механизмы внимания не справляются с задачами, требующими сохранения временного порядка информации, такими как генерация текста и прогнозирование временных рядов. Они охотно «заглядывают вперед» в последовательности, что приводит к неточным предсказаниям. Причинное внимание устраняет это ограничение, гарантируя, что прогнозы зависят исключительно от ранее обработанной информации.
Вот как это работает
- Механизм маскировки: К весам внимания применяется определенная маска, эффективно блокирующая доступ модели к будущим элементам последовательности. Например, при прогнозировании второго слова в слове «женщина, которая…» модель может учитывать только «the», а не «кто» или последующие слова.
- Авторегрессионная обработка: Информация течет линейно, при этом представление каждого элемента строится исключительно из элементов, появляющихся перед ним. Модель обрабатывает последовательность слово за словом, генерируя прогнозы на основе контекста, установленного к этому моменту.
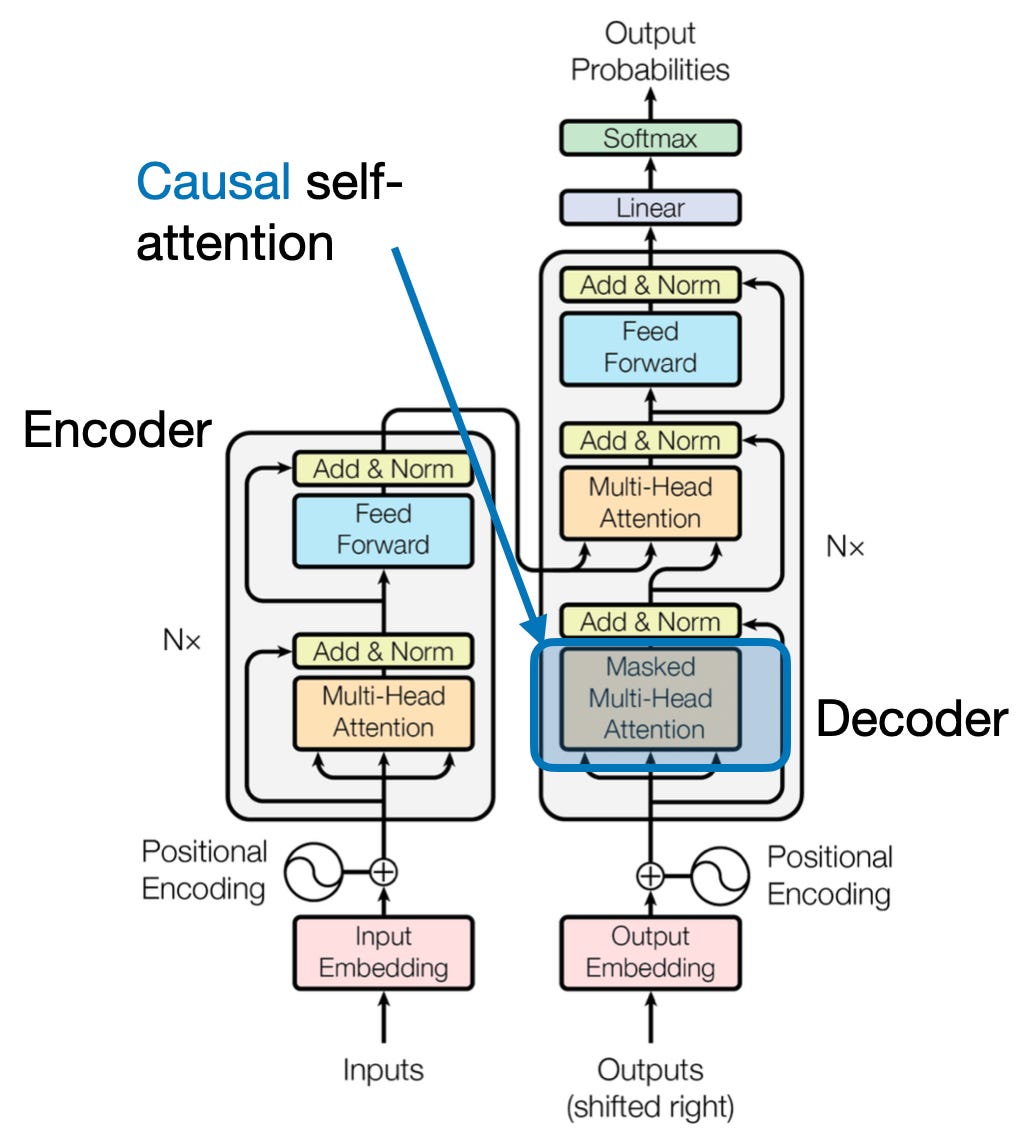
Причинно-следственная связь имеет решающее значение для таких задач, как генерация текста и прогнозирование временных рядов, где поддержание временного порядка данных жизненно важно для точных прогнозов.
5. Глобальное и локальное внимание: достижение баланса
Механизмы внимания сталкиваются с ключевым компромиссом: фиксировать долгосрочные зависимости вместо поддержания эффективных вычислений. Это проявляется в двух основных подходах: глобальное внимание и местное внимание. Представьте себе, что вы читаете всю книгу, а не сосредотачиваетесь на конкретной главе. Глобальное внимание обрабатывает всю последовательность сразу, тогда как локальное внимание фокусируется на меньшем окне:
- Глобальное внимание фиксирует долгосрочные зависимости и общий контекст, но для длинных последовательностей может требовать больших вычислительных затрат.
- Местное внимание более эффективен, но может упустить возможность удаленных отношений.
Выбор между глобальным и локальным вниманием зависит от нескольких факторов:
- Требования к задаче: такие задачи, как машинный перевод, требуют выявления отдаленных связей, отдавая предпочтение глобальному вниманию, тогда как анализ настроений может способствовать сосредоточению локального внимания.
- Длина последовательности: Более длинные последовательности делают глобальное внимание дорогостоящим в вычислительном отношении, что требует локальных или гибридных подходов.
- Емкость модели: Ограничения ресурсов могут потребовать внимания на местном уровне даже для задач, требующих глобального контекста.
Для достижения оптимального баланса модели могут использовать:
- Динамическое переключение: используйте глобальное внимание для ключевых элементов и локальное внимание для других, адаптируясь в зависимости от важности и расстояния.
- Гибридные подходы: объединить оба механизма на одном уровне, используя их сильные стороны.
Читайте также: Анализ типов нейронных сетей в глубоком обучении
Заключение
В конечном счете, идеальный подход лежит в диапазоне между глобальным и местным вниманием. Понимание этих компромиссов и принятие подходящих стратегий позволяет моделям эффективно использовать соответствующую информацию в разных масштабах, что приводит к более глубокому и точному пониманию последовательности.
Рекомендации
- Рашка, С. (2023). «Понимание и кодирование самовнимания, многоголового внимания, перекрестного внимания и причинно-следственного внимания в LLM».
- Васвани А. и др. (2017). «Внимание — это все, что вам нужно».
- Рэдфорд А. и др. (2019). «Языковые модели — это многозадачные ученики без присмотра».
Похожие страницы:
Я любитель данных, мне нравится извлекать и понимать скрытые закономерности в данных. Я хочу учиться и расти в области машинного обучения и науки о данных.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://www.analyticsvidhya.com/blog/2024/01/different-types-of-attention-mechanisms/
- :имеет
- :является
- :нет
- :куда
- $UP
- 1
- 2017
- 2019
- 2023
- 302
- 320
- 321
- 7
- a
- способность
- доступ
- точность
- точный
- Достигать
- достижение
- через
- акты
- фактического соединения
- адреса
- Принятие
- впереди
- AL
- Все
- Позволяющий
- позволяет
- am
- Двусмысленность
- суммы
- an
- анализ
- анализы
- анализ
- и
- ответ
- кроме
- очевидный
- прикладной
- подхода
- подходы
- МЫ
- области
- гайд
- AS
- аспекты
- помощник
- помощники
- At
- посещать
- посещение
- внимание
- осведомленность
- Баланс
- основанный
- основа
- BE
- Ширина
- становиться
- до
- между
- Beyond
- блокирование
- книга
- Книги
- изоферменты печени
- МОСТ
- мосты
- Яркие
- шире
- принес
- Строительство
- строит
- построенный
- но
- by
- пришел
- CAN
- захватить
- перехватывает
- Захват
- случаев
- изменение
- Глава
- главы
- выбор
- ближе
- Кодирование
- объединять
- выходит
- Компании
- совместимость
- комплекс
- вычисление
- вычислительный
- Свяжитесь
- Соединительный
- Коммутация
- Рассматривать
- принимая во внимание
- ограничения
- содержит
- содержание
- контекст
- продолжать
- Основные
- корреляции
- создали
- создает
- Создающий
- критической
- решающее значение
- Текущий
- данным
- наука о данных
- расшифровывать
- глубоко
- более глубокий
- определенный
- копается
- зависеть
- зависимость
- Зависимости
- Зависимость
- зависит
- подробный
- Диалог
- DID
- различный
- непосредственно
- расстояние
- отдаленный
- отчетливый
- Разное
- do
- документ
- DOT
- двойной
- множество
- драматично
- рисовать
- два
- динамика
- Е & Т
- каждый
- фактически
- затрат
- эффективный
- эффективно
- элемент
- элементы
- расширение прав и возможностей
- позволяет
- позволяет
- кодирование
- обогащенный
- обеспечивать
- обеспечение
- Enter
- Весь
- цельность
- оборудованный
- особенно
- сущность
- существенный
- по существу
- установленный
- Даже
- Каждая
- развивается
- точно,
- дорогим
- Эксплуатировать
- извлечение
- Face
- факторы
- далеко
- в пользу
- поле
- Поля
- окончательный
- поток
- Потоки
- Фокус
- внимание
- фокусируется
- фокусировка
- Что касается
- Передний край
- формы
- Год основания
- 4
- Рамки
- от
- функция
- функциональные возможности
- будущее
- игра
- генерирует
- порождающий
- поколение
- Глобальный
- глобальный контекст
- схватывание
- Расти
- Гиды
- руководящий
- обрабатывать
- Есть
- имеющий
- помощь
- Скрытый
- High
- высший
- выделив
- имеет
- целостный
- Как
- HTTPS
- человек
- Гибридный
- i
- идеальный
- определения
- if
- картина
- немедленная
- значение
- важную
- in
- неточный
- включения
- указывать
- individual
- неэффективное
- информация
- по существу
- вход
- размышления
- пример
- Умный
- предназначенных
- взаимодействие
- взаимодействие
- взаимодействует
- вмешиваясь
- в
- неоценимый
- изоляция
- IT
- ЕГО
- JPG
- всего
- Основные
- Ключевые области
- язык
- Фамилия
- слой
- ведущий
- УЧИТЬСЯ
- Учиться и расти
- учащихся
- изучение
- привело
- объектив
- линзы
- Кредитное плечо
- Используя
- Библиотека
- лежит
- легкий
- такое как
- ограничение
- недостатки
- локальным
- Длинное
- дольше
- посмотреть
- любят
- машина
- обучение с помощью машины
- машинный перевод
- сохранение
- сделать
- Создание
- человек
- многих
- маска
- матрица
- макс-ширина
- смысл
- значения
- измеренный
- механизм
- механизмы
- Память
- может быть
- скучать
- отсутствующий
- модель
- Модели
- БОЛЕЕ
- более эффективным
- многогранный
- с разными
- натуральный
- Естественный язык
- Генерация естественного языка
- Обработка естественного языка
- Изучение естественного языка
- природа
- Необходимость
- нуждающихся
- потребности
- соседи
- сетей
- нервный
- нейронные сети
- Новые
- следующий
- ночь
- НЛП
- существительные
- сейчас
- нюансы
- of
- .
- on
- консолидировать
- только
- оптимальный
- or
- заказ
- Другое
- Другое
- наши
- внешний
- выходной
- выходы
- общий
- обзор
- собственный
- страница
- пара
- бумага & картон
- Параллельные
- части
- отрывки
- мимо
- паттеранами
- выполнять
- производительность
- перспективы
- штук
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- Играть
- Точка
- представляет
- обладает
- возможности,
- мощный
- потенциал
- потенциально
- мощностью
- мощный
- прогнозирования
- Predictions
- консервирование
- предупреждение
- предварительно
- в первую очередь
- первичный
- процесс
- обрабатываемых
- Процессы
- обработка
- Вычислительная мощность
- Продукт
- прогнозируемых
- приводимый в движение
- приводит
- вопрос
- ассортимент
- ранжирование
- скорее
- Читать
- легко
- Reading
- реального времени
- ссылка
- Несмотря на
- Отношения
- относительный
- актуальность
- соответствующие
- замечательный
- представление
- представляющий
- представляет
- требовать
- решение
- ресурс
- Полезные ресурсы
- те
- Итоги
- обзоре
- революционный
- революция
- Богатые
- Роли
- s
- то же
- Сарказм
- видел
- Весы
- сканирование
- Наука
- Гол
- множество
- Поиск
- Во-вторых
- видя
- предложение
- настроение
- Последовательность
- Серии
- служит
- несколько
- Поделиться
- сияющий
- стрельба
- Короткое
- демонстрации
- одновременно
- медленной
- меньше
- только
- РЕШАТЬ
- иногда
- Источники
- Space
- конкретный
- конкретно
- Спектр
- скорость
- Прожектор
- положение
- Звезда
- Шаг
- магазины
- стратегий
- сильные
- сильнее
- Структура
- Бороться
- Борющийся
- предмет
- последующее
- такие
- подходящее
- сумма
- суммировать
- РЕЗЮМЕ
- топ
- окружающих
- системы
- снасти
- с
- гобелен
- задачи
- Технический
- срок
- текст
- генерация текста
- который
- Ассоциация
- мир
- их
- Их
- тогда
- Эти
- они
- этой
- три
- Через
- время
- Временные ряды
- в
- инструментом
- традиционный
- Обучение
- преобразующей
- преобразован
- трансформатор
- трансформеры
- превращение
- Переводы
- правда
- два
- Типы
- В конечном счете
- понимать
- понимание
- несомненно
- отпирающий
- открывать
- представила
- использование
- использования
- через
- различный
- Огромная
- Против
- Вид
- посетили
- жизненный
- vs
- хотеть
- хочет
- законопроект
- ЧТО Ж
- Что
- когда
- в то время как
- КТО
- все
- широкий
- Широкий диапазон
- будете
- окно
- в
- без
- женщина
- Word
- слова
- Работа
- Мир
- письмо
- вчера
- являетесь
- зефирнет
- ZOO