Амазонка Redshift — это быстрое, полностью управляемое облачное хранилище данных петабайтного масштаба, которое позволяет легко и экономично анализировать все ваши данные с помощью стандартного SQL и существующих инструментов бизнес-аналитики (BI). Сегодня десятки тысяч клиентов используют Amazon Redshift для анализа эксабайтов данных и выполнения аналитических запросов, что делает его наиболее широко используемым облачным хранилищем данных. Amazon Redshift доступен как в бессерверной, так и в подготовленной конфигурации.
Amazon Redshift позволяет получить прямой доступ к данным, хранящимся в Простой сервис хранения Amazon (Amazon S3) с помощью SQL-запросов и объединения данных в хранилище данных и озере данных. С помощью Amazon Redshift вы можете запрашивать данные в озере данных S3, используя центральный Клей AWS Metastore из вашего хранилища данных Redshift.
Amazon Redshift поддерживает запросы к широкому спектру форматов данных, таких как CSV, JSON, Parquet и ORC, а также к форматам таблиц, таким как Apache Hudi и Delta. Amazon Redshift также поддерживает запросы к вложенным данным со сложными типами данных, такими как структура, массив и карта.
Благодаря этой возможности Amazon Redshift экономически эффективным способом расширяет ваше хранилище данных петабайтного масштаба до озера данных эксабайтного масштаба на Amazon S3.
Apache Iceberg — это новейший формат таблиц, который сейчас поддерживается в предварительной версии Amazon Redshift. В этом посте мы покажем вам, как выполнять запросы к таблицам Iceberg с помощью Amazon Redshift, а также рассмотрим поддержку и варианты Iceberg.
Обзор решения
Апач Айсберг — это формат открытой таблицы для очень больших наборов аналитических данных размером в петабайты. Iceberg управляет большими коллекциями файлов в виде таблиц и поддерживает современные аналитические операции с озером данных, такие как вставка, обновление, удаление и запросы на перемещение во времени на уровне записей. Спецификация Iceberg обеспечивает плавную эволюцию таблицы, такую как эволюция схемы и разделов, а ее конструкция оптимизирована для использования в Amazon S3.
Iceberg хранит указатель метаданных для всех файлов метаданных. Когда запрос SELECT читает таблицу Iceberg, механизм запросов сначала обращается к каталогу Iceberg, а затем извлекает запись о местоположении последнего файла метаданных, как показано на следующей диаграмме.
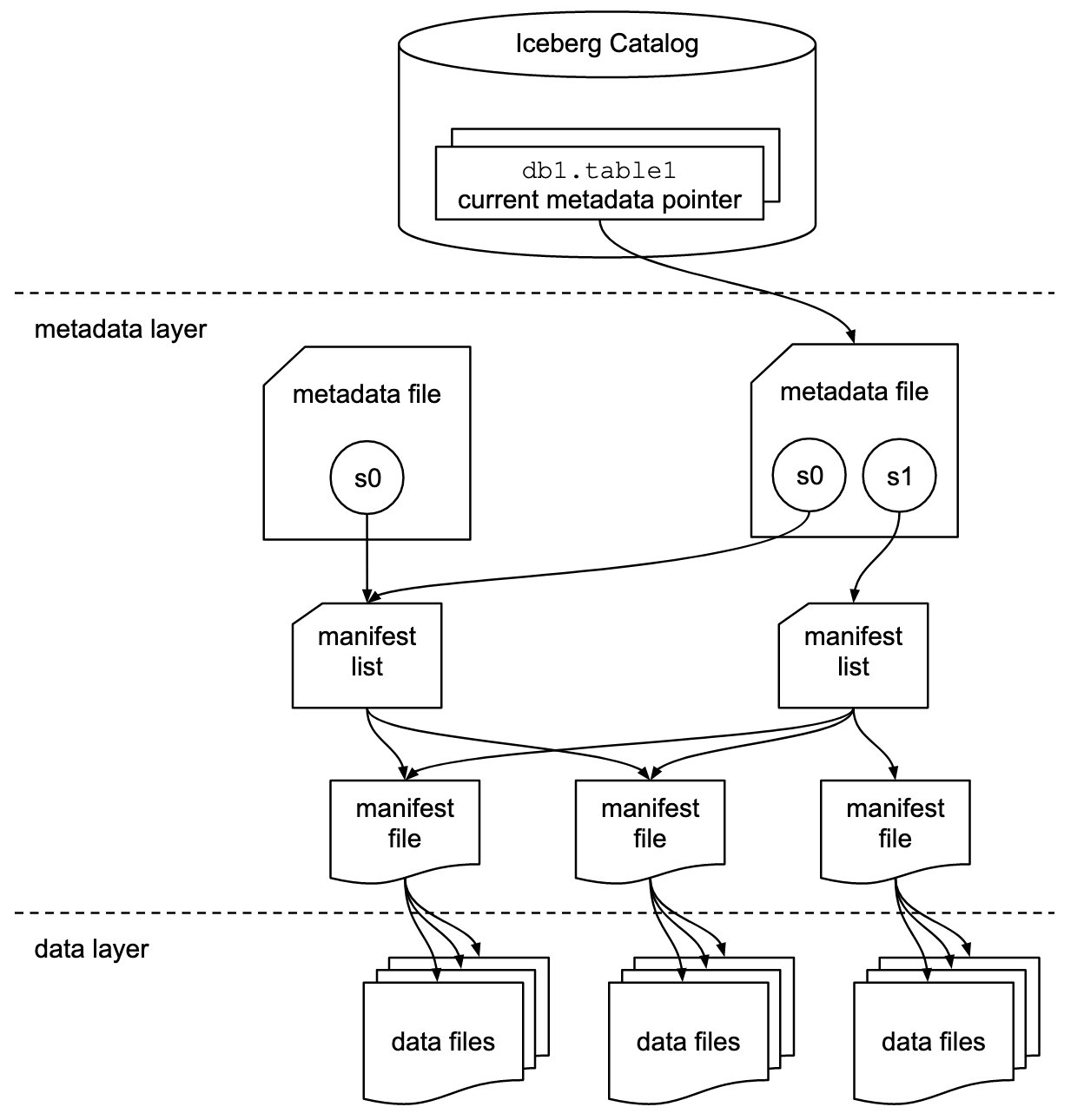
Amazon Redshift теперь обеспечивает поддержку таблиц Apache Iceberg, что позволяет клиентам озера данных выполнять аналитические запросы только для чтения транзакционно-согласованным способом. Это позволяет вам легко управлять и обслуживать таблицы в озерах транзакционных данных.
Amazon Redshift поддерживает собственную схему Apache Iceberg и возможности эволюции разделов с помощью Каталог данных AWS Glue, что устраняет необходимость изменять определения таблиц для добавления новых разделов или перемещения и обработки больших объемов данных для изменения схемы существующей таблицы озера данных. Amazon Redshift использует статистику столбцов, хранящуюся в метаданных таблицы Apache Iceberg, для оптимизации планов запросов и сокращения количества проверок файлов, необходимых для выполнения запросов.
В этом посте мы используем Публичный набор данных о желтых такси от Комиссии по такси и лимузинам Нью-Йорка. как наши исходные данные. Набор данных содержит файлы данных в Паркет Apache формат на Amazon S3. Мы используем Амазонка Афина чтобы преобразовать этот набор данных Parquet, а затем использовать Спектр красного смещения Амазонки для запроса и объединения с локальной таблицей Redshift, выполнения удалений и обновлений на уровне строк, а также эволюции разделов — все это координируется через каталог данных AWS Glue в озере данных S3.
Предпосылки
У вас должны быть следующие предпосылки:
Преобразование данных Parquet в таблицу Iceberg
Для этого поста вам понадобится Публичный набор данных о желтых такси от Комиссии по такси и лимузинам Нью-Йорка. доступен в формате Айсберг. Вы можете загрузить файлы, а затем использовать Athena для преобразования набора данных Parquet в таблицу Iceberg или обратиться к Создайте озеро данных Apache Iceberg с помощью Amazon Athena, Amazon EMR и AWS Glue. сообщение в блоге о создании таблицы Iceberg.
В этом посте мы используем Athena для преобразования данных. Выполните следующие шаги:
- Загрузите файлы по предыдущей ссылке или воспользуйтесь Интерфейс командной строки AWS (AWS CLI), чтобы скопировать файлы из общедоступной корзины S3 за 2020 и 2021 годы в корзину S3, используя следующую команду:
Для получения дополнительной информации обратитесь к Настройка интерфейса командной строки Amazon Redshift.
- Создать базу данных
Icebergdbи создайте таблицу, используя Athena, указывающую на файлы формата Parquet, используя следующий оператор: - Проверьте данные в таблице Parquet, используя следующий SQL:

- Создайте таблицу Iceberg в Athena с помощью следующего кода. Свойства типа таблицы можно увидеть в виде таблицы Iceberg с форматом Parquet и мгновенным сжатием ниже.
create tableзаявление. Вам необходимо обновить местоположение S3 перед запуском SQL. Также обратите внимание, что таблица Iceberg разделена с помощьюYear. - После создания таблицы загрузите данные в таблицу Iceberg, используя ранее загруженную таблицу Parquet.
nyc_taxi_yellow_parquetсо следующим SQL: - Когда оператор SQL будет завершен, проверьте данные в таблице Iceberg.
nyc_taxi_yellow_iceberg. Этот шаг необходим перед переходом к следующему шагу. - Вы можете проверить, что таблица nyc_taxi_yellow_iceberg находится в таблице формата Iceberg и разбита на разделы по столбцу «Год», используя следующую команду:



Создайте внешнюю схему в Amazon Redshift
В этом разделе мы покажем, как создать внешнюю схему в Amazon Redshift, указывающую на базу данных AWS Glue. icebergdb запросить таблицу Iceberg nyc_taxi_yellow_iceberg что мы видели в предыдущем разделе, используя Athena.
Войдите в Redshift через Редактор запросов v2 или клиент SQL и выполните следующую команду (обратите внимание, что база данных AWS Glue icebergdb и используется информация о регионе):

Дополнительную информацию о создании внешних схем в Amazon Redshift см. создать внешнюю схему
После создания внешней схемы spectrum_iceberg_schemaвы можете запросить таблицу Iceberg в Amazon Redshift.
Запрос таблицы Iceberg в Amazon Redshift
Запустите следующий запрос в редакторе запросов версии 2. Обратите внимание, что spectrum_iceberg_schema — это имя внешней схемы, созданной в Amazon Redshift, и nyc_taxi_yellow_iceberg — это таблица в базе данных AWS Glue, используемая в запросе:
Вывод данных запроса на следующем снимке экрана показывает, что таблица AWS Glue в формате Iceberg доступна для запроса с использованием Redshift Spectrum.

Ознакомьтесь с планом объяснения запроса к таблице Iceberg.
Вы можете использовать следующий запрос, чтобы получить выходные данные плана объяснения, которые показывают, что формат ICEBERG:

Проверка обновлений на предмет согласованности данных
После завершения обновления таблицы Iceberg вы можете запросить Amazon Redshift, чтобы просмотреть транзакционно-согласованное представление данных. Давайте выполним запрос, выбрав vendorid и для определенного посадки и высадки:

Затем обновите значение passenger_count к 4 и trip_distance до 9.4 за vendorid и определенные даты получения и возврата в Афине:

Наконец, запустите следующий запрос в редакторе запросов версии 2, чтобы увидеть обновленное значение passenger_count и trip_distance:
Как показано на следующем снимке экрана, операции обновления таблицы Iceberg доступны в Amazon Redshift.

Создайте единое представление локальной таблицы и исторических данных в Amazon Redshift.
В качестве стратегии современной архитектуры данных вы можете организовать исторические данные или менее часто используемые данные в озере данных и хранить часто используемые данные в хранилище данных Redshift. Это обеспечивает гибкость для управления аналитикой в масштабе и поиска наиболее экономически эффективного архитектурного решения.
В этом примере мы загружаем данные за 2 года в таблицу Redshift; Остальные данные остаются в озере данных S3, поскольку этот набор данных запрашивается реже.
- Используйте следующий код, чтобы загрузить данные за 2 года в
nyc_taxi_yellow_recentтаблица в Amazon Redshift, источник из таблицы Iceberg:
- Затем вы можете удалить данные за последние 2 года из таблицы Iceberg с помощью следующей команды в Athena, поскольку на предыдущем шаге вы загрузили данные в таблицу Redshift:

После выполнения этих шагов в таблице Redshift будут данные за 2 года, а остальные данные будут в таблице Iceberg в Amazon S3.
- Создайте представление с помощью
nyc_taxi_yellow_icebergСтол Айсберг иnyc_taxi_yellow_recentтаблица в Amazon Redshift: - Теперь запросите представление. В зависимости от условий фильтра Redshift Spectrum будет сканировать либо данные Iceberg, либо таблицу Redshift, либо и то, и другое. Следующий пример запроса возвращает несколько записей из каждой исходной таблицы путем сканирования обеих таблиц:

Эволюция перегородки
Айсберг использует скрытое разделение, что означает, что вам не нужно вручную добавлять разделы для таблиц Apache Iceberg. Новые значения разделов или новые характеристики разделов (добавление или удаление столбцов разделов) в таблицах Apache Iceberg автоматически обнаруживаются Amazon Redshift, и для обновления разделов в определении таблицы не требуется никаких ручных операций. Следующий пример демонстрирует это.
В нашем примере, если таблица Iceberg nyc_taxi_yellow_iceberg первоначально был разделен по годам, а затем по столбцу vendorid был добавлен в качестве дополнительного столбца раздела, то Amazon Redshift сможет легко запрашивать таблицу Iceberg. nyc_taxi_yellow_iceberg с двумя разными схемами разделов в течение определенного периода времени.

Что следует учитывать при запросе таблиц Iceberg с помощью Amazon Redshift
В период предварительной версии при использовании Amazon Redshift с таблицами Iceberg учитывайте следующее:
- Поддерживаются только таблицы Iceberg, определенные в каталоге данных AWS Glue.
- Команды внешней таблицы CREATE или ALTER не поддерживаются. Это означает, что таблица Iceberg уже должна существовать в базе данных AWS Glue.
- Запросы о путешествиях во времени не поддерживаются.
- Поддерживаются версии Iceberg 1 и 2. Более подробную информацию о версиях формата Iceberg см. Форматирование версий.
- Список поддерживаемых типов данных с таблицами Iceberg см. Поддерживаемые типы данных с таблицами Apache Iceberg (предварительная версия).
- Стоимость запроса к таблице Iceberg такая же, как и за доступ к любым другим форматам данных с помощью Amazon Redshift.
Дополнительные сведения о предварительном просмотре таблиц формата Iceberg см. Использование таблиц Apache Iceberg с Amazon Redshift (предварительная версия).
Отзыв заказчика
«Tinuiti, крупнейшая независимая фирма по маркетингу, ежедневно обрабатывает большие объемы данных и должна иметь надежную стратегию озера и хранилища данных, чтобы наши команды по анализу рынка могли хранить и анализировать все данные наших клиентов в простой, доступной и безопасной форме. и надежный способ», — говорит Джастин Манус, технический директор Tinuiti. «Поддержка Amazon Redshift таблиц Apache Iceberg в нашем озере данных, которое является единственным источником достоверной информации, решает критическую задачу оптимизации производительности и доступности, а также еще больше упрощает наши конвейеры интеграции данных для доступа ко всем данным, полученным из разных источников, и для поддержки наших потенциал бренда клиентов».
Заключение
В этом посте мы показали вам пример запроса к таблице Iceberg в Redshift с использованием файлов, хранящихся в Amazon S3, каталогизированных в виде таблицы в каталоге данных AWS Glue, и продемонстрировали некоторые ключевые функции, такие как эффективное обновление и удаление на уровне строк, а также опыт эволюции схемы, позволяющий пользователям раскрыть возможности больших данных с помощью Athena.
Amazon Redshift можно использовать для выполнения запросов к таблицам озера данных в различных файлах и форматах таблиц, например Апач Худи и Дельта Лейки теперь с Апач Айсберг (предварительная версия), который предоставляет дополнительные возможности для удовлетворения потребностей современных архитектур данных.
Мы надеемся, что это станет для вас отличной отправной точкой для выполнения запросов к таблицам Iceberg в Amazon Redshift.
Об авторах
 Рохит Бансал является специалистом по аналитике, архитектором решений в AWS. Он специализируется на Amazon Redshift и работает с клиентами над созданием аналитических решений следующего поколения с использованием других сервисов AWS Analytics.
Рохит Бансал является специалистом по аналитике, архитектором решений в AWS. Он специализируется на Amazon Redshift и работает с клиентами над созданием аналитических решений следующего поколения с использованием других сервисов AWS Analytics.
 Сатиш Сатья является старшим инженером по продуктам в Amazon Redshift. Он страстный энтузиаст больших данных, который сотрудничает с клиентами по всему миру, чтобы добиться успеха и удовлетворить их потребности в хранилищах данных и архитектуре озера данных.
Сатиш Сатья является старшим инженером по продуктам в Amazon Redshift. Он страстный энтузиаст больших данных, который сотрудничает с клиентами по всему миру, чтобы добиться успеха и удовлетворить их потребности в хранилищах данных и архитектуре озера данных.
 Ранджан Бурман является специалистом по аналитике, архитектором решений в AWS. Он специализируется на Amazon Redshift и помогает клиентам создавать масштабируемые аналитические решения. Он имеет более чем 16-летний опыт работы с различными технологиями баз данных и хранилищ данных. Он увлечен автоматизацией и решением проблем клиентов с помощью облачных решений.
Ранджан Бурман является специалистом по аналитике, архитектором решений в AWS. Он специализируется на Amazon Redshift и помогает клиентам создавать масштабируемые аналитические решения. Он имеет более чем 16-летний опыт работы с различными технологиями баз данных и хранилищ данных. Он увлечен автоматизацией и решением проблем клиентов с помощью облачных решений.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Автомобили / электромобили, Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- ЧартПрайм. Улучшите свою торговую игру с ChartPrime. Доступ здесь.
- Смещения блоков. Модернизация права собственности на экологические компенсации. Доступ здесь.
- Источник: https://aws.amazon.com/blogs/big-data/query-your-iceberg-tables-in-data-lake-using-amazon-redshift-preview/
- :имеет
- :является
- :нет
- :куда
- $UP
- 1
- 10
- 100
- 16
- 17
- 2020
- 2021
- 22
- 26
- 28
- 30
- 385
- 46
- 500
- 53
- 7
- 8
- 9
- a
- О нас
- доступ
- Доступ
- доступность
- доступа
- Достигать
- через
- Добавить
- добавленный
- дополнительный
- адреса
- доступной
- Все
- позволяет
- уже
- причислены
- Amazon
- Амазонка Афина
- Амазонка ЭМИ
- Amazon Web Services
- суммы
- an
- аналитический
- Аналитические фармацевтические услуги
- аналитика
- анализировать
- и
- любой
- апаш
- архитектура
- МЫ
- около
- массив
- AS
- At
- автоматически
- Автоматизация
- доступен
- AWS
- Клей AWS
- основа
- , так как:
- до
- не являетесь
- большой
- Big Data
- переплет
- Блог
- изоферменты печени
- марка
- строить
- бизнес
- бизнес-аналитика
- by
- CAN
- возможности
- возможности
- каталог
- центральный
- определенный
- вызов
- изменение
- главный
- Главный технический директор
- клиент
- облако
- код
- Коллекции
- Column
- Колонки
- полный
- комплекс
- Условия
- Рассматривать
- соображения
- последовательный
- содержит
- конвертировать
- согласованный
- рентабельным
- Создайте
- создали
- Создающий
- критической
- клиент
- данные клиентов
- Клиенты
- ежедневно
- данным
- Интеграция данных
- Озеро данных
- информационное хранилище
- База данных
- Наборы данных
- Финики
- По умолчанию
- определенный
- определение
- Определения
- Delta
- демонстрировать
- убивают
- демонстрирует
- в зависимости
- Проект
- подробнее
- обнаруженный
- Дев
- различный
- непосредственно
- Dont
- двойной
- скачать
- каждый
- легко
- легко
- редактор
- эффективный
- или
- уничтожение
- позволяет
- Двигатель
- инженер
- энтузиаст
- запись
- Эфир (ETH)
- эволюция
- пример
- существовать
- существующий
- опыт
- Объяснять
- Больше
- продолжается
- и, что лучший способ
- дополнительно
- БЫСТРО
- Особенности
- Файл
- Файлы
- фильтр
- Найдите
- Фирма
- Во-первых,
- Трансформируемость
- после
- Что касается
- формат
- часто
- от
- полностью
- далее
- получить
- дает
- земной шар
- идет
- большой
- группы
- Ручки
- Есть
- he
- помогает
- исторический
- надежды
- Как
- How To
- HTML
- HTTP
- HTTPS
- if
- in
- независимые
- информация
- интеграции.
- Интеллекта
- в
- IT
- ЕГО
- присоединиться
- JPG
- JSON
- Джастин
- Сохранить
- Основные
- озеро
- большой
- крупнейших
- Фамилия
- новее
- последний
- УЧИТЬСЯ
- Меньше
- такое как
- ОГРАНИЧЕНИЯ
- линия
- LINK
- Список
- загрузка
- локальным
- расположение
- поддерживать
- ДЕЛАЕТ
- Создание
- управлять
- управляемого
- управляет
- способ
- руководство
- вручную
- карта
- рынок
- Маркетинг
- означает
- Встречайте
- Метаданные
- Модерн
- БОЛЕЕ
- самых
- двигаться
- перемещение
- должен
- имя
- родной
- Необходимость
- необходимый
- потребности
- Новые
- следующий
- следующее поколение
- нет
- в своих размышлениях
- сейчас
- номер
- Нью-Йорк
- of
- сотрудник
- on
- открытый
- операция
- Операционный отдел
- Оптимизировать
- оптимизированный
- оптимизирующий
- Опции
- or
- первоначально
- Другое
- наши
- выходной
- за
- страница
- страстный
- выполнять
- производительность
- период
- план
- Планы
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- Точка
- После
- потенциал
- мощностью
- предпосылки
- предварительный просмотр
- предыдущий
- предварительно
- проблемам
- процесс
- Продукт
- свойства
- приводит
- что такое варган?
- Запросы
- Reading
- учет
- уменьшить
- область
- удаление
- замещать
- обязательный
- ОТДЫХ
- Возвращает
- надежный
- Run
- Бег
- то же
- видел
- говорит
- масштабируемые
- Шкала
- сканирование
- сканирование
- сканирует
- схемы
- бесшовные
- легко
- Раздел
- безопасный
- посмотреть
- старший
- Serverless
- Услуги
- набор
- должен
- показывать
- показал
- показанный
- Шоу
- просто
- одинарной
- Решение
- Решения
- Решение
- некоторые
- Источник
- Источники
- Об
- специалист
- специализируется
- Спецификация
- функции
- Спектр
- SQL
- стандарт
- Начало
- заявление
- статистике
- Шаг
- Шаги
- диск
- магазин
- хранить
- магазины
- Стратегия
- строка
- успех
- такие
- поддержка
- Поддержанный
- Поддержка
- ТАБЛИЦЫ
- команды
- технологии
- Технологии
- десятки
- чем
- который
- Ассоциация
- Источник
- их
- тогда
- Эти
- этой
- тысячи
- Через
- время
- путешествие во времени
- отметка времени
- в
- сегодня
- инструменты
- транзакционный
- путешествовать
- Правда
- два
- напишите
- Типы
- унифицированный
- союз
- отпереть
- Обновление ПО
- обновление
- Updates
- Применение
- использование
- используемый
- пользователей
- использования
- через
- VALIDATE
- ценностное
- Наши ценности
- разнообразие
- различный
- очень
- с помощью
- Вид
- тома
- Склады
- Складирование
- законопроект
- Путь..
- we
- Web
- веб-сервисы
- когда
- , которые
- КТО
- широкий
- широко
- будете
- работает
- год
- лет
- являетесь
- ВАШЕ
- зефирнет