Изображение по автору
Существует множество курсов и ресурсов по машинному обучению и науке о данных, но очень мало по инженерии данных. Это вызывает некоторые вопросы. Это сложная сфера? Предлагает низкую зарплату? Разве это не так же интересно, как и другие технические роли? Однако реальность такова, что многие компании активно ищут талантливых специалистов по обработке данных и предлагают солидные зарплаты, иногда превышающие 200,000 XNUMX долларов США. Инженеры по обработке данных играют решающую роль в качестве архитекторов платформ данных, проектируя и создавая основополагающие системы, которые позволяют ученым, работающим с данными, и экспертам по машинному обучению эффективно функционировать.
Чтобы устранить этот пробел в отрасли, DataTalkClub представил преобразующий бесплатный учебный курс».Инжиниринг данных Zoomcamp«. Этот курс предназначен для того, чтобы дать новичкам или профессионалам, желающим сменить карьеру, необходимые навыки и практический опыт в области разработки данных.
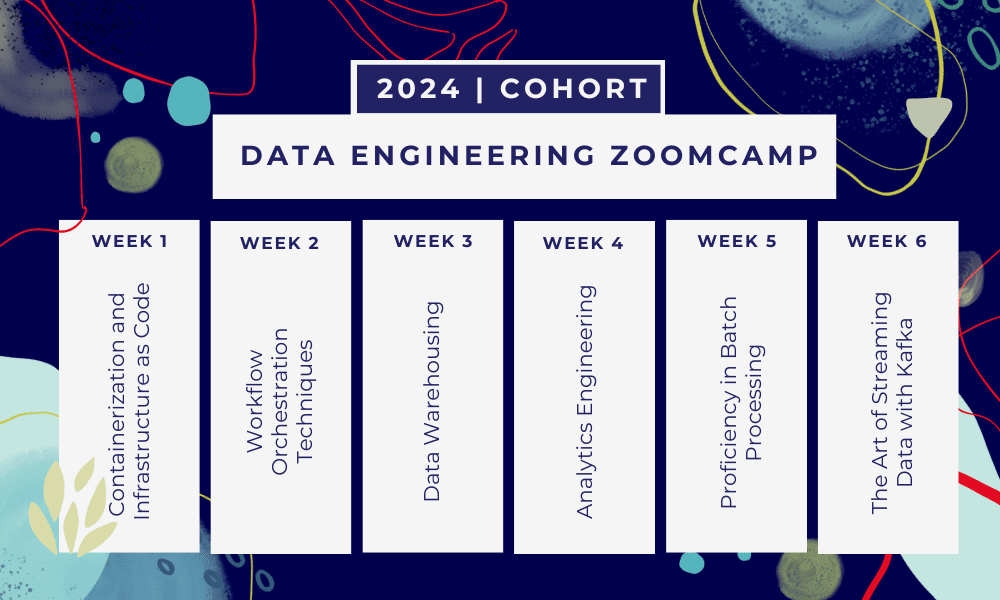
Это 6-недельный буткемп где вы будете учиться с помощью нескольких курсов, материалов для чтения, семинаров и проектов. В конце каждого модуля вам будет дано домашнее задание для закрепления полученных знаний.
- Неделя 1: Введение в GCP, Docker, Postgres, Terraform и настройку среды.
- Неделя 2: Оркестрация рабочего процесса с помощью Mage.
- Неделя 3: Хранилище данных с помощью BigQuery и машинное обучение с помощью BigQuery.
- Неделя 4: Инженер-аналитик с dbt, Google Data Studio и Metabase.
- Неделя 5: Пакетная обработка с помощью Spark.
- Неделя 6: Стриминг с Кафкой.
Изображение из DataTalksClub / data-engineering-zoomcamp
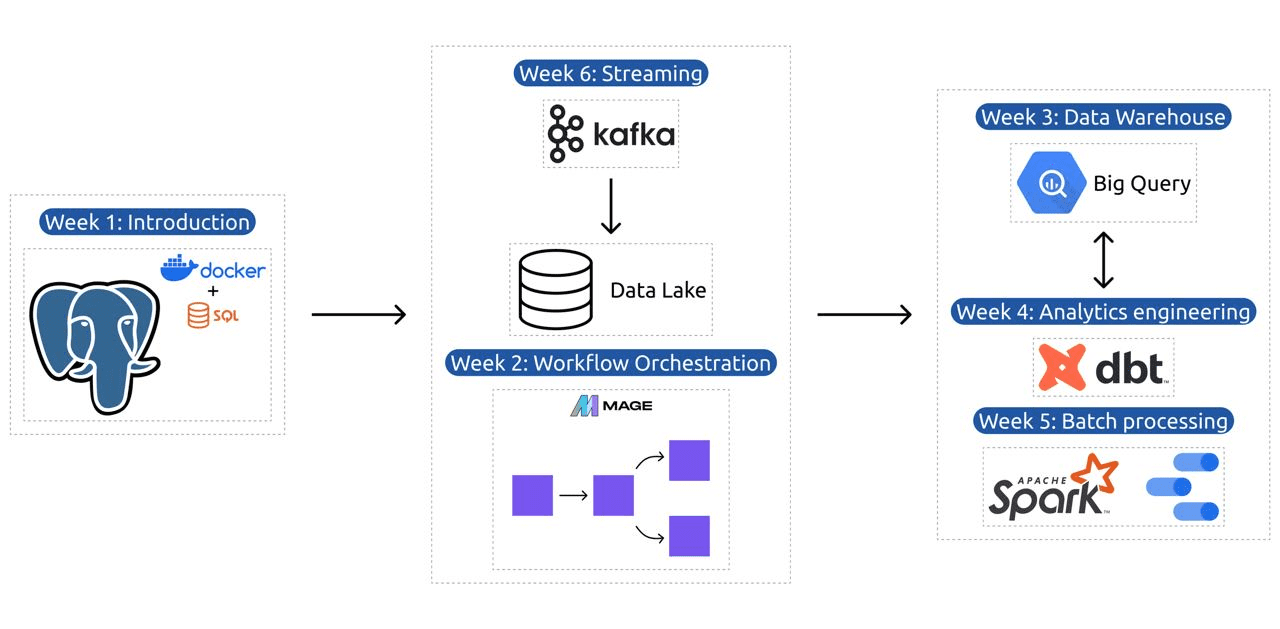
Программа содержит 6 модулей, 2 семинара и проект, который охватывает все необходимое для того, чтобы стать профессиональным инженером по данным.
Модуль 1: Освоение контейнеризации и инфраструктуры как кода
В этом модуле вы узнаете о Docker и Postgres, начиная с основ и заканчивая подробными руководствами по созданию конвейеров данных, запуску Postgres с Docker и многому другому.
В модуле также рассматриваются основные инструменты, такие как pgAdmin, Docker-compose и темы повышения квалификации по SQL, а также дополнительный контент по сети Docker и специальное пошаговое руководство для пользователей подсистемы Windows Linux. В конце курс познакомит вас с GCP и Terraform, предоставив целостное понимание контейнеризации и инфраструктуры как кода, необходимого для современных облачных сред.
Модуль 2: Методы оркестрации рабочих процессов
Модуль предлагает углубленное изучение Mage, инновационной гибридной среды с открытым исходным кодом для преобразования и интеграции данных. Этот модуль начинается с основ оркестрации рабочих процессов, переходит к практическим упражнениям с Mage, включая его настройку через Docker и построение конвейеров ETL от API к Postgres и Google Cloud Storage (GCS), а затем к BigQuery.
Сочетание видео, ресурсов и практических заданий в модуле обеспечивает всесторонний опыт обучения, давая учащимся навыки управления сложными рабочими процессами с данными с помощью Mage.
Семинар 1: Стратегии приема данных
На первом семинаре вы освоите построение эффективных конвейеров приема данных. Семинар посвящен таким важным навыкам, как извлечение данных из API и файлов, нормализация и загрузка данных, а также методы поэтапной загрузки. После завершения этого семинара вы сможете создавать эффективные конвейеры данных, как старший инженер по обработке данных.
Модуль 3: Хранилище данных
Модуль представляет собой углубленное исследование хранения и анализа данных с упором на хранение данных с использованием BigQuery. В нем рассматриваются ключевые понятия, такие как секционирование и кластеризация, а также лучшие практики BigQuery. Модуль переходит к более сложным темам, в частности к интеграции машинного обучения (ML) с BigQuery, освещению использования SQL для ML и предоставлению ресурсов по настройке гиперпараметров, предварительной обработке функций и развертыванию моделей.
Модуль 4: Аналитическая инженерия
Модуль аналитической инженерии фокусируется на создании проекта с использованием dbt (инструмента построения данных) с существующим хранилищем данных BigQuery или PostgreSQL.
Модуль охватывает настройку dbt как в облачной, так и в локальной среде, знакомит с концепциями аналитической инженерии, ETL и ELT, а также моделированием данных. Он также охватывает расширенные функции dbt, такие как инкрементные модели, теги, перехватчики и снимки.
В конце модуль знакомит с методами визуализации преобразованных данных с использованием таких инструментов, как Google Data Studio и Metabase, а также предоставляет ресурсы для устранения неполадок и эффективной загрузки данных.
Модуль 5: Навыки пакетной обработки
В этом модуле рассматривается пакетная обработка с использованием Apache Spark, начиная с введения в пакетную обработку и Spark, а также инструкций по установке для Windows, Linux и MacOS.
Он включает в себя изучение Spark SQL и DataFrames, подготовку данных, выполнение операций SQL и понимание внутреннего устройства Spark. Наконец, он завершается запуском Spark в облаке и интеграцией Spark с BigQuery.
Модуль 6: Искусство потоковой передачи данных с помощью Kafka
Модуль начинается с введения в концепции потоковой обработки, за которым следует углубленное изучение Kafka, включая его основы, интеграцию с Confluent Cloud и практические приложения с участием производителей и потребителей.
Модуль также охватывает конфигурацию и потоки Kafka, затрагивая такие темы, как объединение потоков, тестирование, управление окнами и использование Kafka ksqldb и Connect. Кроме того, он расширяет свое внимание на среды Python и JVM, включая Faust для потоковой обработки Python, Pyspark — структурированная потоковая передача и примеры Scala для Kafka Streams.
Семинар 2: Потоковая обработка с помощью SQL
Вы научитесь обрабатывать потоковые данные и управлять ими с помощью RisingWave, который представляет собой экономичное решение в стиле PostgreSQL, расширяющее возможности ваших приложений потоковой обработки.
Проект: Реальное приложение для обработки данных
Целью этого проекта является реализация всех концепций, которые мы изучили в этом курсе, для построения сквозного конвейера данных. Вы будете создавать информационную панель, состоящую из двух плиток, выбирая набор данных, создавая конвейер для обработки данных и сохраняя их в озере данных, создавая конвейер для передачи обработанных данных из озера данных в хранилище данных, преобразуя данные в хранилище данных и подготовка их для информационной панели и, наконец, создание информационной панели для визуального представления данных.
Подробности о когорте 2024 года
- Регистрация: Зарегистрируйтесь сейчас
- Дата начала: 15 января 2024 г., 17:00 CET.
- Самостоятельное обучение с сопровождением
- Папка когорты с домашними заданиями и сроками
- Интерактивное Сообщество Slack для взаимного обучения
Предпосылки
- Базовые навыки программирования и командной строки
- Основы SQL
- Python: полезно, но не обязательно
Опытные инструкторы, ведущие ваше путешествие
- Анкуш Ханна
- Виктория Перес Мола
- Алексей Григорьев
- Мэтт Палмер
- Луис Оливейра
- Майкл Шумейкер
Присоединяйтесь к нашей когорте 2024 года и начните учиться вместе с замечательным сообществом инженеров данных. Благодаря обучению под руководством экспертов, практическому опыту и учебной программе, адаптированной к потребностям отрасли, этот учебный лагерь не только дает вам необходимые навыки, но и ставит вас в авангарде прибыльной и востребованной карьеры. Зарегистрируйтесь сегодня и воплотите свои стремления в реальность!
Абид Али Аван (@ 1abidaliawan) — сертифицированный специалист по анализу данных, который любит создавать модели машинного обучения. В настоящее время он занимается созданием контента и ведением технических блогов по технологиям машинного обучения и обработки данных. Абид имеет степень магистра в области управления технологиями и степень бакалавра в области телекоммуникаций. Его видение состоит в том, чтобы создать продукт искусственного интеллекта с использованием графовой нейронной сети для студентов, борющихся с психическими заболеваниями.
- SEO-контент и PR-распределение. Получите усиление сегодня.
- PlatoData.Network Вертикальный генеративный ИИ. Расширьте возможности себя. Доступ здесь.
- ПлатонАйСтрим. Интеллект Web3. Расширение знаний. Доступ здесь.
- ПлатонЭСГ. Углерод, чистые технологии, Энергия, Окружающая среда, Солнечная, Управление отходами. Доступ здесь.
- ПлатонЗдоровье. Биотехнологии и клинические исследования. Доступ здесь.
- Источник: https://www.kdnuggets.com/the-only-free-course-you-need-to-become-a-professional-data-engineer?utm_source=rss&utm_medium=rss&utm_campaign=the-only-free-course-you-need-to-become-a-professional-data-engineer
- :имеет
- :является
- :нет
- :куда
- $UP
- 000
- 1
- 15%
- 17
- 2024
- a
- в состоянии
- О нас
- активно
- Дополнительно
- адресация
- продвинутый
- опережения
- После
- AI
- Все
- вдоль
- причислены
- удивительный
- an
- анализ
- Аналитические фармацевтические услуги
- аналитика
- и
- и инфраструктура
- апаш
- Apache Spark
- API
- API
- Приложения
- Архитекторы
- МЫ
- Искусство
- AS
- At
- доступен
- Основы
- BE
- становиться
- становление
- Новичкам
- полезный
- ЛУЧШЕЕ
- лучшие практики
- BigQuery
- Бленд
- блоги
- изоферменты печени
- строить
- Строительство
- но
- by
- Карьера
- карьера
- Сертифицированные
- облако
- облачного хранения
- кластеризации
- код
- Кодирование
- когорта
- сообщество
- Компании
- комплектующие
- комплексный
- понятия
- заключает
- Конфигурация
- Переход
- Свяжитесь
- считается
- Состоящий из
- строить
- Потребители
- содержит
- содержание
- контентного создание
- курс
- курсы
- чехлы
- Создайте
- Создающий
- создание
- решающее значение
- В настоящее время
- Учебный план
- приборная панель
- данным
- инженер данных
- Озеро данных
- наука о данных
- ученый данных
- хранение данных
- информационное хранилище
- Время
- Степень
- развертывание
- предназначенный
- проектирование
- подробный
- трудный
- Docker
- каждый
- фактически
- эффективный
- или
- расширение прав и возможностей
- включить
- конец
- впритык
- инженер
- Проект и
- Инженеры
- зачислять
- обеспечивает
- Окружающая среда
- средах
- существенный
- Эфир (ETH)
- многое
- Примеры
- захватывающий
- существующий
- опыт
- эксперты
- исследование
- Исследование
- продолжается
- Особенность
- Особенности
- Показывая
- несколько
- поле
- Файлы
- в заключение
- Во-первых,
- Фокус
- фокусируется
- фокусировка
- следует
- Что касается
- Передний край
- основополагающие
- Рамки
- Бесплатно
- от
- функция
- Основы
- разрыв
- GCP
- данный
- Google Cloud
- график
- Графическая нейронная сеть
- управляемый
- практический
- Есть
- he
- выделив
- его
- имеет
- целостный
- домашнее задание
- Крючки
- Однако
- HTTPS
- Гибридный
- Настройка гиперпараметра
- болезнь
- осуществлять
- in
- углубленный
- включает в себя
- В том числе
- дополнительный
- промышленность
- Инфраструктура
- инновационный
- установка
- инструкции
- Интегрируя
- интеграции.
- в
- выпустили
- Представляет
- введение
- Введение
- введения
- с участием
- IT
- ЕГО
- январь
- Играя
- Кафка
- КДнаггетс
- Основные
- озеро
- ведущий
- УЧИТЬСЯ
- узнали
- учащихся
- изучение
- такое как
- линия
- Linux
- погрузка
- локальным
- искать
- любит
- Низкий
- прибыльный
- машина
- обучение с помощью машины
- MacOS
- управлять
- управление
- обязательный
- многих
- мастер
- Освоение
- материалы
- психический
- Психические заболевания
- ML
- модель
- моделирование
- Модели
- Модерн
- модуль
- Модули
- БОЛЕЕ
- с разными
- необходимо
- Необходимость
- необходимый
- потребности
- сеть
- сетей
- нервный
- нейронной сети
- цель
- of
- предлагающий
- Предложения
- on
- только
- с открытым исходным кодом
- Операционный отдел
- or
- оркестровка
- Другое
- наши
- Паломник
- особенно
- путь
- ОПЛАТИТЬ
- вглядываться
- выполнения
- трубопровод
- Платформы
- Платон
- Платон Интеллектуальные данные
- ПлатонДанные
- Играть
- позиции
- Postgresql
- практическое
- Практическое применение
- практика
- практиками
- подготовка
- представить
- процесс
- обрабатываемых
- обработка
- Производители
- Продукт
- профессиональный
- профессионалы
- прогрессирующий
- Проект
- проектов
- приводит
- обеспечение
- Питон
- Вопросы
- повышения
- Reading
- реальный мир
- Реальность
- Полезные ресурсы
- Роли
- роли
- Бег
- s
- зарплаты
- масштаб
- Наука
- Ученый
- Ученые
- поиск
- выбор
- старший
- установка
- установка
- навыки
- слабина
- Решение
- некоторые
- иногда
- сложный
- Искриться
- особый
- SQL
- Начало
- Начало
- диск
- поток
- потоковый
- потоки
- структурированный
- Борющийся
- Студенты
- студия
- существенный
- такие
- поддержка
- Коммутатор
- системы
- с учетом
- Талант
- задачи
- технологии
- Технический
- снижения вреда
- технологии
- Технологии
- телекоммуникация
- Terraform
- Тестирование
- который
- Ассоциация
- Основы
- тогда
- этой
- Через
- в
- сегодня
- инструментом
- инструменты
- Темы
- Обучение
- Передающий
- Transform
- трансформация
- преобразующей
- преобразован
- превращение
- учебные пособия
- два
- понимание
- USD
- использование
- пользователей
- через
- Ve
- очень
- с помощью
- Видео
- видение
- визуально
- vs
- Склады
- Складирование
- we
- Что
- который
- КТО
- будете
- окна
- рабочий
- Рабочие процессы
- семинар
- Семинары
- письмо
- являетесь
- ВАШЕ
- зефирнет










